데이터베이스(DB) 인덱스에 대해서 학습해보고, 실제로 모아모아 프로젝트에서 적용한 내용을 정리한다.
이론적인 내용에 대해서 참고한 책은 백은이, 이성욱 님이 지으신 Real MySQL 8.0이다.
데이터베이스와 디스크
데이터베이스에서 데이터를 읽을 때, 어떻게 읽을까?
데이터베이스는 ACID 중 트랜잭션이 성공적으로 진행된 내용에 대해서 영구적으로 저장한다는 D 에 해당하는 Durability 를 위해 휘발성 저장 공간인 메모리가 아닌 디스크에 데이터를 저장한다.
하지만 이러한 디스크는 전기적 특성을 띄는 장치라 아닌 기계적 장치이다. 여기서 기계적 장치라고 이야기한 이유는, 우선 SSD를 제외하고 생각해보면 디스크는 원판을 기계적으로 회전하고 헤더를 움직임으로써 원하는 데이터를 읽을 수 있기 때문이다.
(물론 SSD를 사용하면 HDD를 사용할 때에 비해 훨씬 속도가 빠르다. 하지만 그럼에도 불구하고 SSD는 메모리에 비해서 훨씬 느리다.(약 1000배 차이))
디스크의 헤더를 움직이지 않고 한 번에 많은 데이터를 읽는 순차 I/O 에서는 SSD 와 HDD 비슷한 성능을 보이지만, 랜덤 I/O 에서는 그 차이가 분명하다. 즉, SSD 가 훨씬 빠르다.
데이터베이스 입장에서 바라보면 결국 순차 I/O 작업에 대해서는 크게 고려할 사항이 없다. 왜냐하면 충분히 빠르기 때문이기도 하고, 그 비중이 크지가 않다. 결국 고려해야할 사항은 랜덤 I/O를 통한 데이터의 읽기 및 쓰기이다.
DB 성능에 핵심 사항이 되는 랜덤 I/O 는 DB의 대부분의 작업에 해당하고, 순차I/O에 비해서 속도가 느리다.
디스크의 랜덤 I/O 와 순차 I/O
랜덤 I/O와 순차 I/O 에 대해서 조금 더 구체적으로 살펴보자.
랜덤 I/O 는 디스크의 원판을 돌려서 읽어야할 데이터의 위치로 디스크의 헤더를 이동시킨 다음 데이터를 읽는 것이다. 물론 순차 I/O 에서도 데이터를 읽기 위해서는 동일하게 헤더를 움직여야한다. 그럼 어떤 차이점이 있을까?
만약 우리가 3개의 페이지(3 * 16KB) 를 디스크로 부터 읽어오고 싶다.
만약 3개의 페이지가 연달아서 저장되어 있다면 우리는 디스크에서 데이터를 읽어오기 위해 디스크 헤드를 한 번만 움직이면 될 것이다. 즉, 순차 I/O 에서는 디스크 헤더를 한 번 움직이게 된다. 그런데 반대로 디스크의 순서대로 저장되어 있지 않고 랜덤한 위치에 3개의 페이지가 저장되어 있다고 해보자. 그러면 총 3번 디스크 헤드를 움직여줘야 할 것이다. 즉, 랜덤 I/O 에서는 디스크 헤더를 3번 움직인다.
그런데 여기서 디스크 헤더를 움직이는 작업은 물리적인 작업이다. 어떻게 더 이상 빠르게 해줄 수가 없고, 아무래도 전자적으로 동작하는 컴퓨터와 달리 시간이 많이 소요된다.
즉, 디스크의 성능은 디스크 헤더의 이동 없이 얼마나 많은 데이터를 한 번에 저장하고 가져오느냐에 의해 결정된다고 볼 수 있다.
인덱스란
데이터베이스에서는 그럼 순차I/O 를 사용할까? 순차I/O 를 주로 사용하고 가끔 한 번씩만 랜덤 I/O 가 발생한다면 좋겠지만 그렇지 않다.
DB 대부분의 작업은 작은 데이터를 빈번하게 읽고 쓰는 작업이다. 그리고 읽기를 원하는 데이터의 위치는 항상 변하게 될 것이다. 또한 우리가 연속된 데이터를 저장한다고 해도 빈번하게 읽고 쓰기 때문에 비어있는 디스크 공간이 연속되지 않아 흩어져 저장될 수도 있다. 즉, 앞서 언급한 것과 같이 랜덤 I/O 가 굉장히 빈번하게 일어난다. (InnoDB 에서는 쓰기 작업에서 이러한 단점을 극복하기 위해서 바로바로 커밋을 디스크에 반영하는 것이 아니라 버퍼에 저장해놓고 한 번에 디스크에 저장하는 버퍼 기능을 제공한다.)
여기서 생각해볼 점은 우리는 DB만을 쓰지 않는다는 것이다. 보통 DB 를 사용하는 WAS를 함께 사용하는데 사용자 요청이 많이 들어오고 빠른 응답을 내보내 주고 싶다고 하자. 그럼 병목이 어디서 발생할까? 물론 네트워크를 통해 연결된 WAS 와 DB 라면 네트워크상에서도 병목이 발생할 수 있지만 이는 우리가 제어할 수 없는 사항이므로 WAS와 DB 가 하나의 인스턴스에 함께 올려져 있다고 해보자. 그럼 당연히 디스크를 읽어오고 쓰는 데에서 병목이 발생할 것이라고 쉽게 예측할 수 있다.
그럼 다음 단계로 우리는 해당 병목을 해결하기 위해서 DB 성능을 끌어올리기 위해 고민을 하게 될 것이고, 쿼리 수를 줄여보기도 하고 쿼리를 튜닝해보기도 할 것이다. 하지만 쿼리 수를 줄이는 것은 실질적으로 도움이 되겠지만 쿼리를 튜닝하는 것으로 랜덤 I/O 를 순차 I/O 로 바뀌고 성능상 이점을 얻는 것은 거의 불가능하다. 따라서 우리는 랜덤I/O 자체를 줄이는 방향으로 DB 성능을 개선해야한다.
(즉, 꼭 필요한 데이터만 디스크에서 읽도록 쿼리를 개선하는 것)
(풀 테이블 스캔의 경우에는 순차 I/O 를 사용한다. 따라서 테이블의 대부분을 읽는 작업에서는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용하도록 옵티마이저가 판단하는데, 보통 전체 테이블 레코드의 20 ~ 25%를 넘어서면 인덱스를 타는 것이 아니라 테이블의 전체를 모두 직접 읽어온 후 필터링한다.)
어떻게 랜덤 I/O 횟수를 줄일 수 있을까? 일반적으로 쿼리 성능을 높이기 위해서 사용하는 인덱스 라는 개념을 살펴보자.
인덱스는 책에서 보이는 인덱스(색인)과 비슷한 역할을 한다. 우리는 원하는 내용에 바로 접근하기 위해 우선 책의 목차나 색인을 바고 바로 해당 페이지로 가서 원하는 책의 내용을 읽는다. DB 에서 사용하는 인덱스도 비슷하다.
DBMS에서 DB 테이블의 모든 데이터를 검색해서 원하는 결과를 가져오려면 시간이 오래 걸리기 때문에 컬럼의 값과 해당 레코드가 저장된 주소를 키&값의 쌍으로 인덱스를 만들어 두고 원하는 데이터를 인덱스를 통해서 접근하여 조회 성능을 빠르게 해주게 된다.
다음으로 DB의 인덱스는 정렬되어 있다는 특징이 있다.
책의 색인도 "ㄱ, ㄴ, ㄷ ..." 순과 같이 정렬되어 있는데, DB에서도 동일하게 인덱스에 대해서 정렬이 되어 있다. 저장된 순서대로 유지하는 것이 아니라 값을 항상 정렬된 상태로 유지하는 것이다.
이렇게 정렬된 상태로 유지하는 것에는 trade off 가 존재한다. 새로운 값이 저장되거나 기존의 저장된 값이 수정될 때 항상 값을 재정렬 해주어야 한다. 만약 저장되는 순서를 유지한다면 이러한 작업은 불필요할 것이다. 하지만 정렬된 상태를 유지하면 원하는 결과는 빠르게 조회해올 수 있다. 즉 조회의 성능을 끌어올리는 대신 쓰기 작업에 대한 성능은 조금 손해를 보게 되는 것이다.
이러한 인덱스의 저장방식은 다양할텐데 보통 B-Tree 구조의 인덱스와 Hash 인덱스를 이야기한다.
B-Tree 구조의 인덱스는 가장 일반적으로 사용되는 인덱스 알고리즘으로, 상당히 오래된 역사를 가진다. B-Tree 인덱스는 컬럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱하는 알고리즘이다.
반면 Hash 인덱스는 원래의 컬럼 값을 통해서 해시 값을 계산하고 이를 통해서 인덱싱을 하게 된다. 매우 빠른 검색을 지원해줄 수 있지만 값을 변형하기 때문에 Prefix 가 일치하는 것에 대한 조회 혹은 값의 일부만을 통해서 검색하는 것이나 해시의 특성 때문에 범위 검색에서 인덱스를 사용할 수 없다는 단점이 있다. (주로 메모리 기반의 DB에서 많이 사용된다.)
여기서 정리하려고 하는 것은 인덱스의 이론적인 내용이 중심이라기 보다는 실제로 프로젝트에서 인덱스를 어떻게 적용하였는지에 대해서 정리하려고 하는 것이므로 인덱스가 무엇인지에 대해서 간단하게만 이론적인 내용을 정리하려고 하고 이제 실제 프로젝트에서 어떻게 적용하였는지에 대해서 정리해보려고 한다.
모아모아 인덱스 적용하기 (쿼리 분석)
실행계획을 확인하기 위해서는 실행계획 Type 을 일차적으로 확인한다.
- const : 조회되는 데이터가 단 1건 일 때
- eq_ref : 조인에서 처음 읽은 테이블의 컬럼 값을, 그 다음 읽어야 할 테이블의 PK 혹은 UK 컬럼의 검색 조건에 사용할 때 (단 1건의 데이터가 존재)
- ref : 인덱스의 종류와 관계없이 동등(=) 조건으로 검색할 때
- range : 인덱스를 이용하여 범위 검색을 할 때
- index : 인덱스 전체를 스캔할 때
- all : 테이블 전체를 스캔할 때
일반적으로 다음과 같은 순서로 const 가 가장 빠르고 all 이 가장 느리다.
const < eq_ref < ref < range < index < all
(참고: 우리 팀은 위에서 우선적으로 테이블을 풀 스캔 하는 쿼리를 최적화하려고 하였고, 다음으로 index도 최대한 레인지 스캔으로 개선하려고 노력하였다.)
그리고 이러한 실행 계획을 확인하기 위해서는 EXPLAIN 을 활용한다. 그리고 여기에는 possible_keys 항목과 Key 항목이 존재하는데, 그 내용은 다음과 같다.
- possible_keys : 옵티마이저는 쿼리를 처리하기 위해 여러가지 처리 방법을 고려해 비용이 가장 낮을 것으로 예상되는 실행 계획을 선택해 쿼리를 실행한다. possible_keys 컬럼에 내용은 옵티마이저가 최적의 실행계획을 만들기 위해 후보로 선정했던 인덱스 목록이다. 이 컬럼은 무시해도 된다.
- key : Key 컬럼에 표시되는 인덱스는 최종 선택되어 실행 계획에 사용된 인덱스를 의미한다. 쿼리 튜닝 시 Key 컬럼에 의도했던 인덱스가 나타나는지 확인해야 한다. Key 컬럼이 PRIMARY 인 경우 PK 를 사용했다는 의미이며 그 이외의 값은 모두 테이블이나 인덱스 생성시 부여한 고유 이름이다.
테스트 환경은 약 15만개의 데이터가 있는 DB 를 사용하였다.
또한 현재 모아모아 백엔드에서는 명령을 위한 조회(JPA 이용)와 정말 조회해서 클라이언트로 바로 전달하는 조회를 분리(jdbcTemplate 이용)하고 있어, 조회를 위한 조회에 대해서만 쿼리 분석을 진행하였다. (jpa 를 이용해서 명령을 위해서 조회하는 쿼리에 대해서는 분석을 진행하지 않았다.)
우리팀 내에서는 도메인별로 쿼리를 나눠서 분석을 진행하엿고, 나는 study 를 조회해오는 부분에 대한 쿼리를 맡아서 진행하였다.
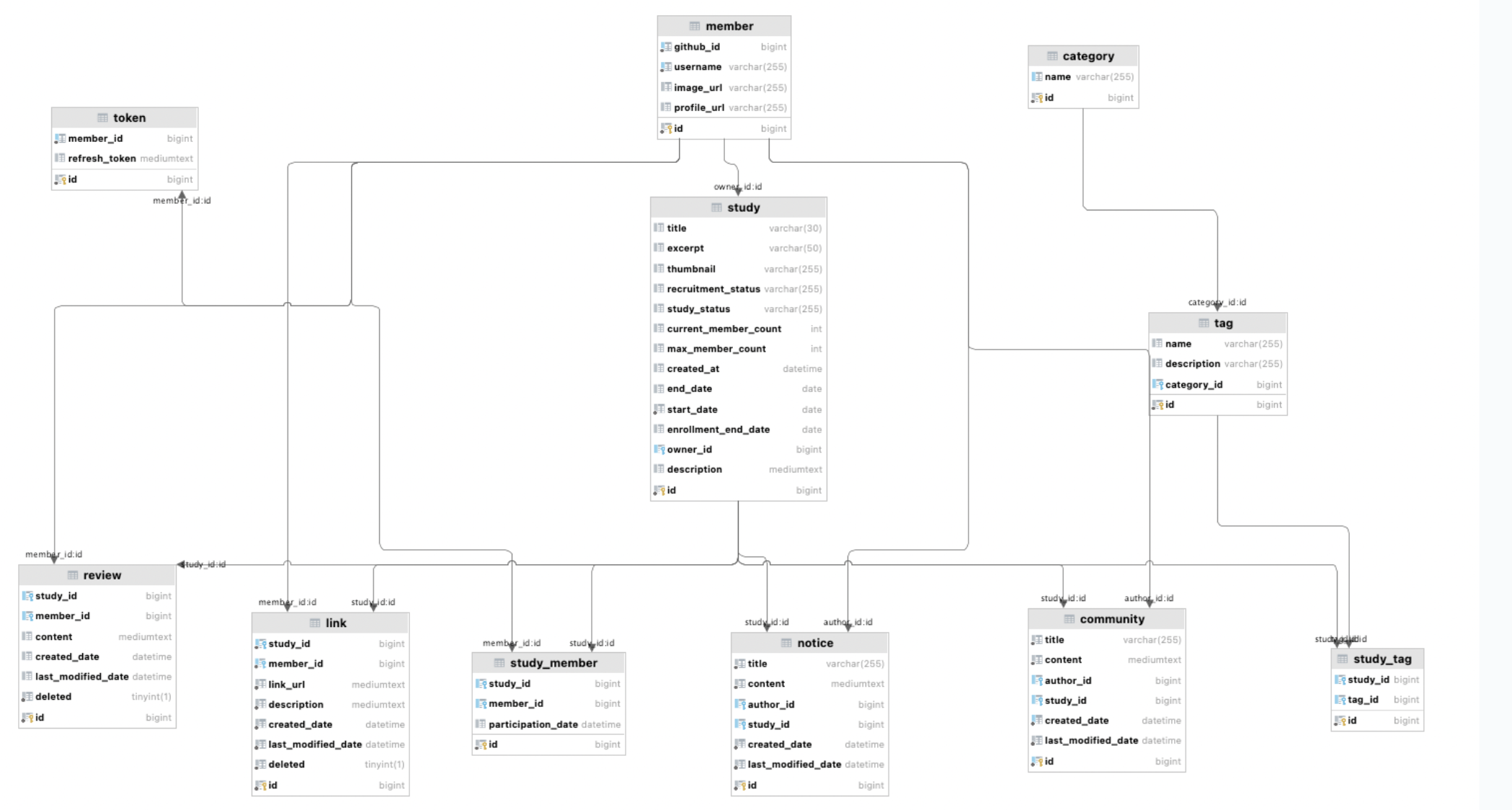
당시 모아모아팀 ERD
회원 id 를 통한 가입한 스터디 조회(findMyStudyByMemberId)


기존의 쿼리는 위와 같이 DISTINCT 를 사용하고 있었다. EXPLAIN 키워드를 통해서 확인해보니 테이블 전체를 스캔하고 있었으며, 테이블 전체를 스캔하는데 메모리의 공간이 부족하니 Extra 에 보면 Using temporary 를 사용하고 있음을 확인할 수 있다. 즉 스토리지 엔진으로부터 우선 전체 레코드를 가져오고 Mysql 엔진이 이를 정렬하거나 그룹핑할 목적으로 가상의 임시 테이블을 만들어 쿼리를 실행한다는 것이다.

쿼리를 직접 실행해보니 쿼리의 실행시간은 1초에 가까운 꽤나 긴 시간을 소요하고 있었다.
그래서 쿼리를 GROUP BY 에 id 를 사용하는 쿼리로 수정을 진행해보았다. 실제로 우리가 조회해오는 내용은 study 이고, DISTINCT 를 이용해서 중복을 제거해서 조회를 해오고 있었는데, GROUP BY 에 study의 pk인 id를 주면 논리적으로 동일한 결과를 얻을 수 있기 때문이다.
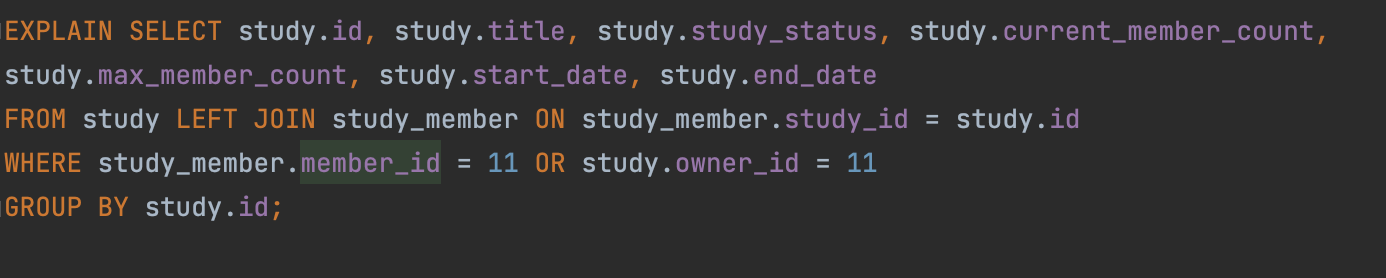

이와 같이 쿼리를 변경하고 나니 key 에서 PRIMARY 라고 표시되어 있었다. 즉, PK 를 활용해주고 있었고, type은 index 인 것으로 보아 우선 클러스터링 인덱스를 활용해서 레코드가 저장되어 있는 실제 디스크까지 가지 않고 index내에서 필터링해서 조회해오고 있다는 것을 알 수 있었다.

하지만 실제로 쿼리를 실행해보았을 때에는 큰 개선 점을 찾아볼 수 없었다.
여러번 쿼리를 실행하면 할 수록 평균 실행 시간은 정말 비슷했다.
조금 찾아보니 GROUP BY 와 DISTINCT 모두 동일한 로직을 이용하기에 성능의 차이는 없지만, GROUP BY 의 경우 정렬을 수행하기에 조금 더 느릴 수 있다라는 것이 지배적인 의견인 것 같았다.
(DISTINCT = 컬럼 내 데이터를 중복을 제거해 조회한다. GROUP BY = 컬럼 내 데이터를 유니크한 값을 기준으로 그 결과를 가져온다.)
하지만 우리의 경우 위에서 볼 수 있다시피 Extra의
Using filesort키워드가 포함되지 않은 것으로 보아 내부적으로 sort를 진행하지 않아 성능에서 차이가 없었던 것 같다.
따라서 현재 GROUP BY 로 변경할 이유가 크게 없기 때문에, 그리고 현재 EXPLAIN 으로 분석시 sort를 하고 있지 않기는 하지만 향후에 정렬을 사용할 수도 있는데 현재 쿼리는 정렬이 불필요하므로 기존 쿼리를 유지해주었다.
스터디의 방장 조회

스터디 아이디를 받아서 해당 스터디의 방장들을 찾는 쿼리이고, EXPLAIN 결과는 다음과 같다.

STUDY 테이블에 대해서는 range 가 걸려있다. 즉, 인덱스 레인지 스캔을 하게 된다.(인덱스 스킵 스캔 x) 그리고 MEMBER 테이블에는 조인을 해오기 때문에 eq_ref 타입이 걸려있는 것을 확인할 수 있다.
그런데 여기서 range 스캔에 대해서 Using where 임을 Extra 를 통해서 확인할 수 있는데, 이는 스토리지 엔진에서 먼저 읽어온 이후에 MySQL 엔진에서 where 조건을 활용하여 필터링해 결과를 내뱉어 주는 것을 의미한다.
또한 IN 절이므로 다르게도 조건을 조합해 쿼리를 날려보았다.

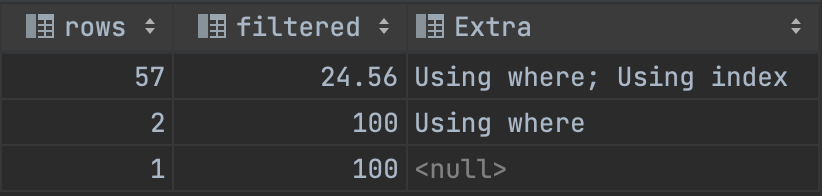
위의 쿼리는 전체 데이터가 57개인 곳에서 별도로 진행하였고, 분석 결과는 다음과 같았다.

총 57개 중에 14개를 IN 절 조건으로 사용하였기 때문에 24.56 filtered 가 표시되고 Using where, Using index 라고 표시된다.
(마찬가지로 STUDY는 index 타입에 MEMBER는 eq_ref 타입이었다.)
Readl MySQL 8.0 에 의하면 "전체 테이블 레코드의 20 ~ 25% 를 넘어서면 인덱스를 이용하지 않고 테이블을 모두 직접 읽어서 필요한 레코드만 가려내는 필터링 방식으로 처리하는 것이 효츌적"이라서 옵티마이저가 실행계획을 위와 같이 세운 것이라고 보여진다. 그런데 여기서 ALL 이 아닌 INDEX인 이유는 STUDY 테이블의 다른 컬럼은 필요하지 않고, 클러스터링 인덱스인 study의 id만 필요하기 때문이라고 보여진다. (커버링)
스터디의 태그 조회하기

위의 쿼리는 스터디의 태그를 조회하는 쿼리이다. IN절을 활용하는 앞서와 거의 동일한 상황이라고 보면 된다.

EXPLAIN 을 통한 실행계획 역시 마찬가지로 STUDY 에 대해서는 range, STUDY_TAG 중간 테이블에는 동등 조건으로 검색하고 있으므로 ref, TAG 테이블에 대해서는 eq_ref 를 사용하고 있다.
앞서와 동일하게 57개의 스터디를 가지는 DB에 대해서 테스트해보면 index 풀 스캔을 하면서 24.56% 를 필터링하고 Extra 에는 Using where, Using index 를 사용하고 있음을 알 수 있다.

스터디 상세 정보 조회하기
스터디의 요약 정보가 아닌 스터디의 상세 정보(가입한 회원, 스터디 소개 글 포함)를 조회하는 쿼리이다.
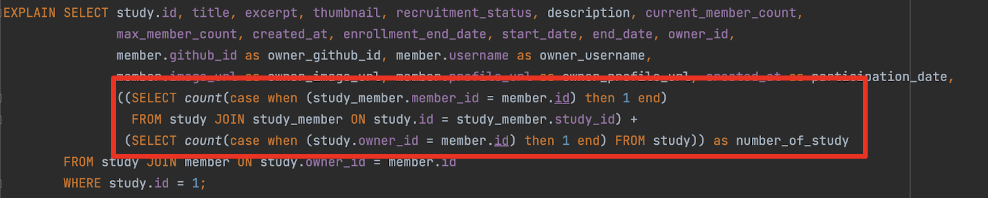

해당 쿼리는 현재 case when then end 구문을 사용해서 스터디에 가입한 인원을 스터디 정보와 함께 조회해오고 있다.
실행계획을 보면 study_member 테이블을 inner query 에서 활용할 때 테이블 풀 스캔이 일어나느 것을 확인할 수 있다. (여기서 사용한 case 문은 매 로우마다 when 절에 값을 대입해 비교하기 때문에 인덱스를 탈 수 없어 테이블을 전체 스캔해야 한다.)

실행시간을 살펴보면 약 0.5초(500ms) 의 실행시간이 걸린다는 것을 확인할 수 있다.
하지만 위의 쿼리는 충분히 count 쿼리로도 논리적으로 동일한 결과를 얻어올 수 있으며 count 쿼리를 사용하면 where 절을 타게 되기 때문에 다음과 같이 index 를 타게끔 쿼리를 수정할 수 있게 되고 실행시간은 약 10배의 향상을 이뤄낼 수 있게 된다.


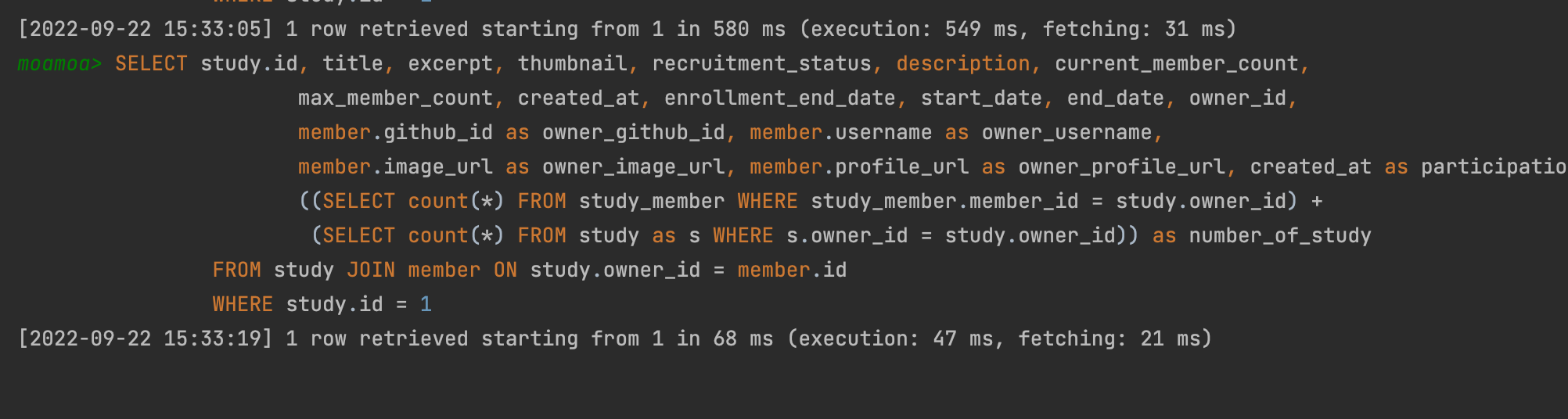

스터디 요약 정보 조회하기
스터디 요약 정보 조회하기는 가장 많은 테이블을 조인해서 가져오고 있는 쿼리이다. 태그 정보나 카테고리 정보 등을 통해서도 필터링해 정보를 조회해 와야 하고 이를 위해선 다대다 매핑의 연관관계 테이블에 대해서도 조인을 진행해주어야 하기 때문에 꽤나 많은 테이블에 대한 조인을 진행해오는 어떻게 보면 복잡하다고 느낄 수 있는 쿼리이다. 그리고 현재는 OFFSET 기반의 페이징 처리를 함께 해주고 있다. (다른 내용이기는 하지만 기회가 된다면 커서 기반으로 변경하여 조회 성능이 데이터(n개)에 따라 저하되는 것을 방지하여 쿼리 성능을 개선해보고 싶다.)
(위의 쿼리 이외에도 카테고리 조합이나 페이징 처리 등등 다양한 상황에서의 쿼리 실행계획을 분석하였었는데 여기서는 생략하겠다.)
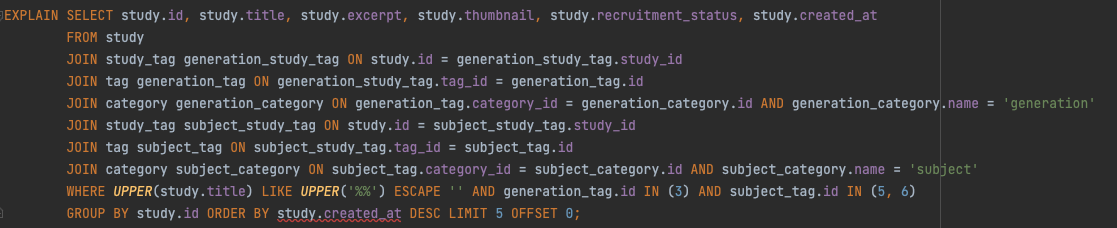
쿼리는 위와 같고, EXPLAIN 을 통해서 옵티마이저의 실행계획을 분석한 내용은 아래와 같다.
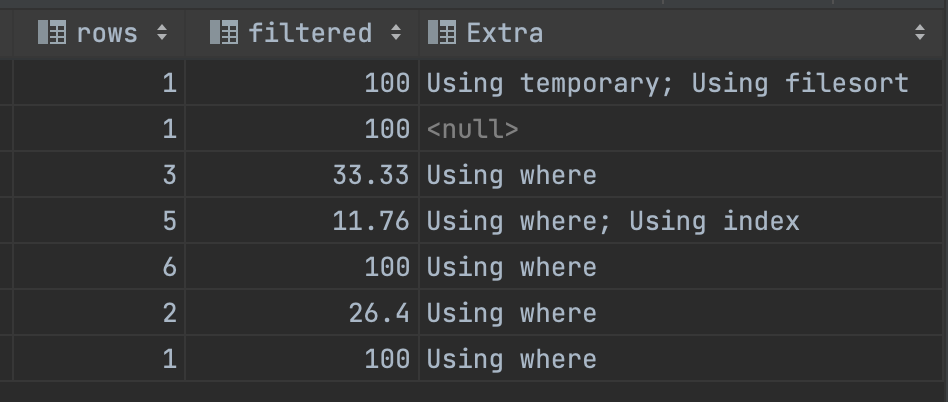

위의 실행계획을 살펴보면 가장 눈에 띄는 것은 아무래도 type 이 ALL 인, 즉 테이블을 전체 조회하는 JOIN 의 조건에 포함되어 있는 category 테이블이다.
따라서 가장 먼저 category 테이블의 name 컬럼에 대해서 인덱스를 추가해주었다.
ALTER TABLE dev.category ADD INDEX category_name (name);여기서 주저없이 카테고리에 대해서 인덱스를 추가해줄 수 있었던 이유는 카테고리에 대해서는 현재 새로운 카테고리를 사용자가 직접 추가하거나 수정하지 못하기 때문에 조회 성능 이외에 CUD 와 관련된 성능은 고려할 필요가 없었기 때문이다. 변경된 실행계획은 아래와 같다.

다음으로는 ORDER BY 쪽을 주목하였다.
별도의 인덱스를 추가하지 않고 created_at 으로 정렬시 평균 100ms 이상의 실행 시간을 보이는 것을 확인할 수 있다.

그래서 여기서 고민이 들었는데, Auto Increment 로 PK, 즉 id 를 사용하고 있기 때문에 created_at 에 대한 인덱스 등록없이 id를 DESC 로 조회하면 결국 최신순으로 정렬하는 결과를 가져오기 때문에 이와 같이 쿼리를 변경할까하는 것에 대한 고민이었다.

실제로 이전에 100ms 이상이 걸리던 쿼리가 평균 35ms 로 약 3배 빨라졌다는 것을 확인해볼 수 있었다.
하지만 향후에 DB 를 여러개로 분산(source DB 분산)하고 각각의 DB가 같은 study 테이블이지만 서로 다른 id를 증감시키고 있을 경우에는 각 DB마다 id 가 겹칠 수도 있고, 값이 서로 다를 것이므로 확실하게 최신순으로 정렬하려면 created_at 을 사용해야겠다는 생각을 하였고, 따라서 created_at 에 대해 인덱스를 등록해주기로 최종결정하였고, 실행 결과는 다음과 같다.

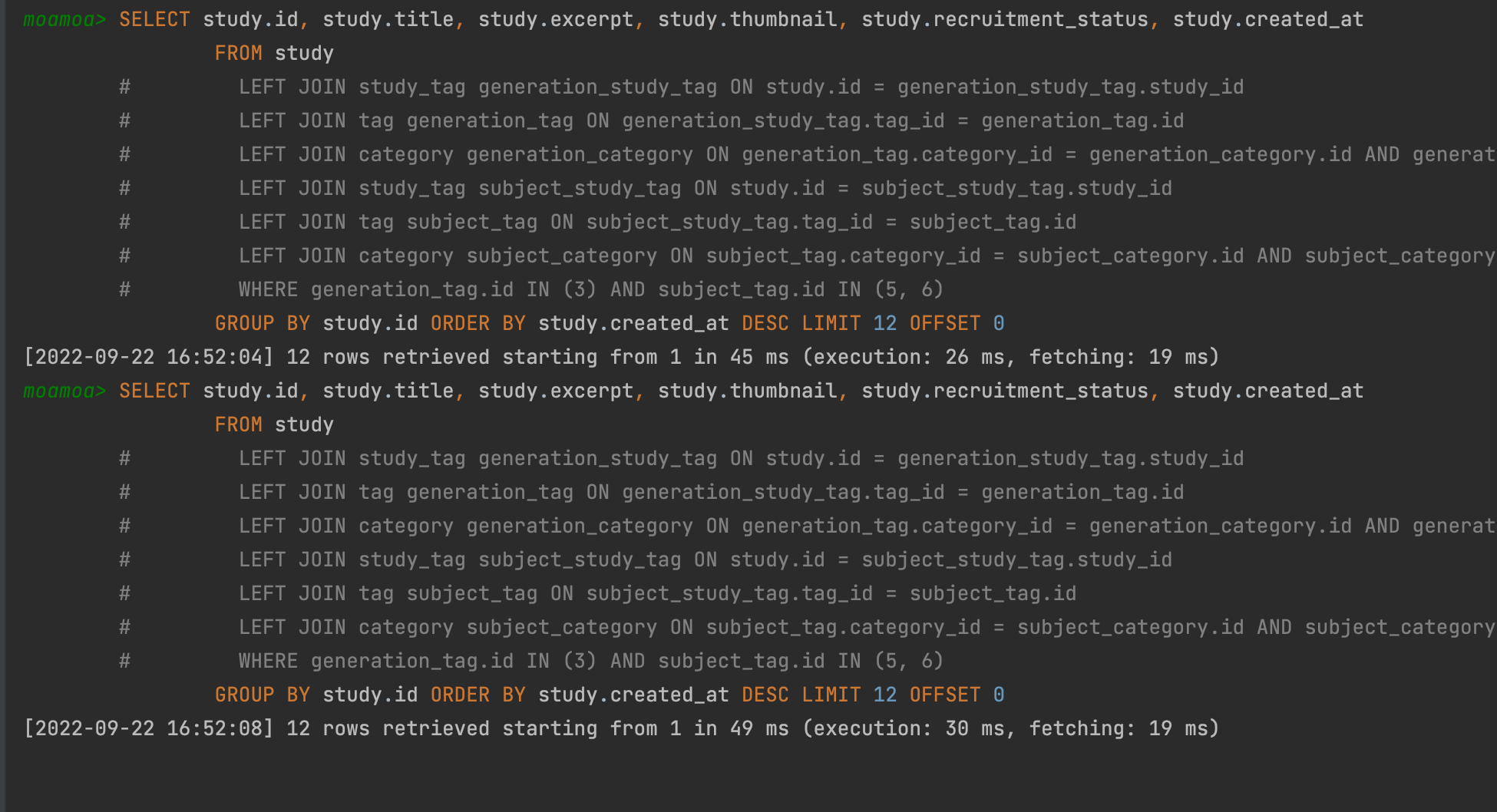
created_at 컬럼에 대해 추가해준 idx_created_at 인덱스를 잘 타고 있고, 실행시간은 평균 25 ~ 30 ms 정도로 id 를 사용할 때와 거의 비슷하게 최적화할 수 있었다.
다음으로 고려해볼 수 있을만 한 것이 WHERE 절에 있는 UPPER(study.title) LIKE UPPER() 문이었다. 즉, 스터디 제목으로 함께 검색하기 위해 존재하는 문장인데, 여기에 대해서 전문 검색 인덱스 를 적용해보았다.
전문 검색 인덱스를 사용하기 위해서는 쿼리 문장이 전문 검색을 위한 문법인 MATCHE ... AGAINST ... 을 사용해야하며 테이블이 전문 검색 대상 컬럼에 대해서 전문 인덱스를 보유해야 한다.
ALTER TABLE study ADD FULLTEXT INDEX study_title(title);전문 인덱스를 study의 title에 추가해주고 다음과 같이 쿼리를 테스트해보았다.
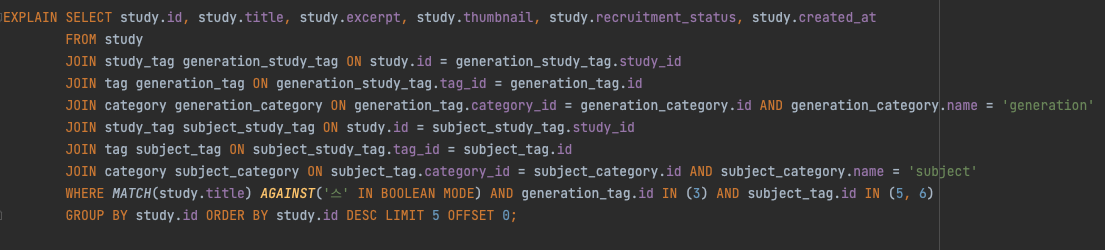

쿼리의 실행결과는 위와 같다. type 에서 볼 수 있다시피 fulltext 가 결려있다. 하지만 아래와 같이 스터디 의 스 로만 검색했을 때 검색되지 않는 문제가 발견되었다.

이를 제대로 적용하기 위해서 n-gram 알고리즘이 있다는 것을 확인할 수 있었다. 해당 알고리즘은 본문으 무조건 몇 글자씩 잘라서 인덱싱하는 방법이었다. 따라서 최소 2글자 이상으로 쿼리를 조회해야지만 제대로된 결과를 도출할 수 있다. 그리고 이렇게 2근자 단위로 키워드를 쪼개서 인덱싱하는 것을 2-gram 이라고 한다고 한다.
ALTER TABLE study ADD FULLTEXT INDEX study_title(title) WITH PARSER ngram;따라서 n-gram 알고리즘을 탈 수 있도록 수정해주었고, 다시 테스트를 진행해보았다.
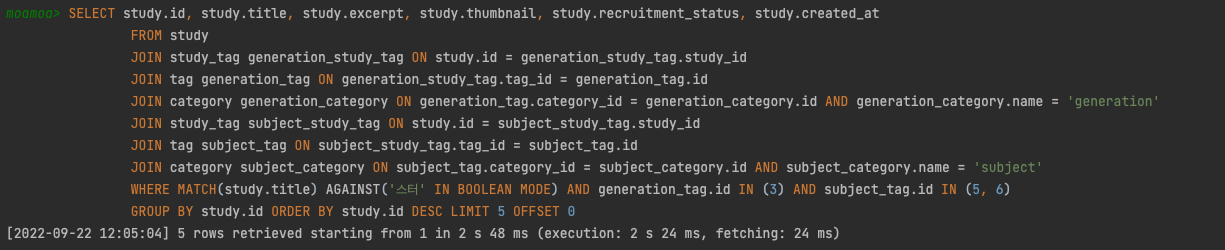
약 2초가 넘는 실행시간이 걸리는 것을 확인할 수 있었는데, 아래와 같이 전문 검색 인덱스 없이 검새할 때에 비해서 너무 많은 실행시간이 걸리는 것을 보였다.
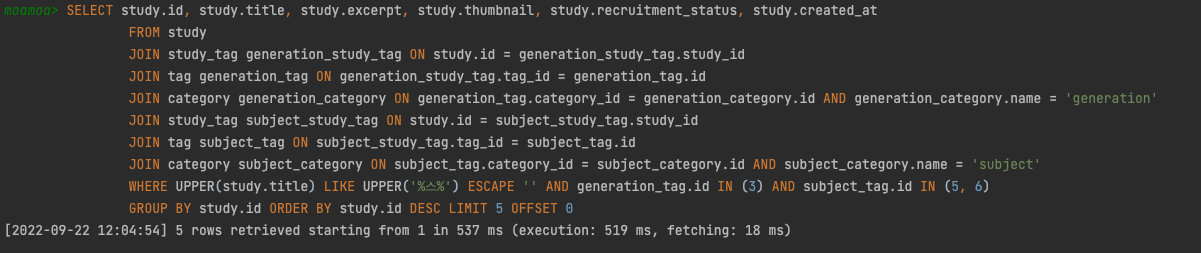
혹시나 JOIN 이 너무 많이 걸려이썽서 그런가? 하는 생각도 들어서 JOIN 문 없이 study의 title 만 비교하는 쿼리를 통해서 확인해보았다.
하지만 아래 결과에서 볼 수 있다시피 그 실행결과는 너무나도 많은 차이를 보여줬다.
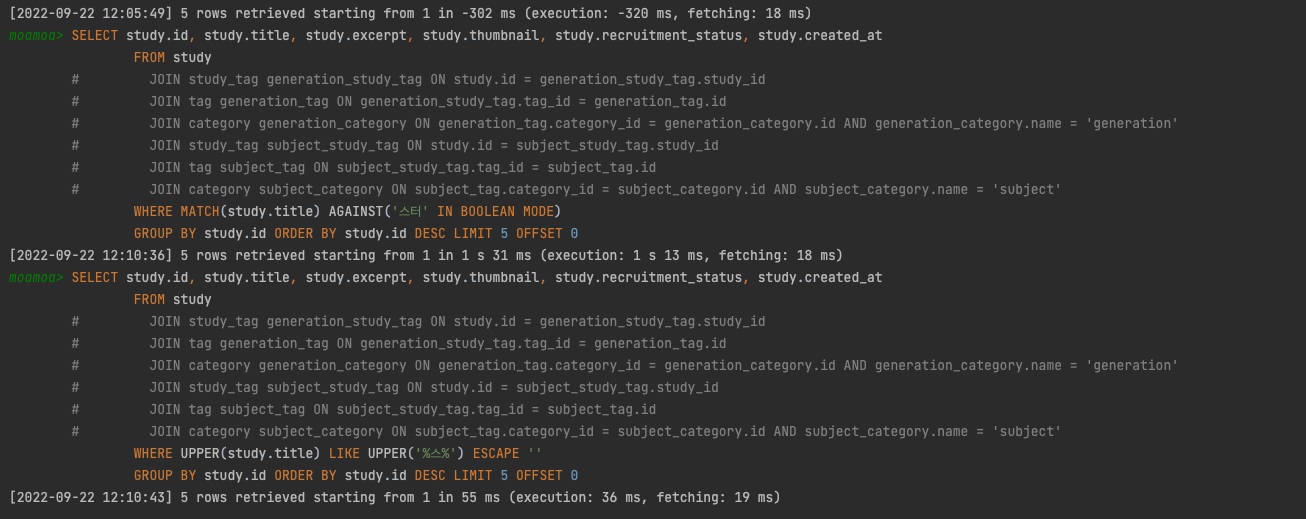
아직 원인을 찾지는 못했지만, 전문 검색 인덱스를 사용했을 때 원하는 것에 비해서 너무 많이 느려지고 있었기 때문에 이를 사용하지 않는 것으로 결정하였다.
개인적으로 전문 검색 인덱스의 활용법(?)에 대해서 잘 모르기 때문이라는 생각도 들기는 하지만 인덱스를 거는 것이 무조건적으로 좋은 것은 아닐 수도 있다? 라는 생각이 들게끔 하는 쿼리이기도 했다.
커서 기반 페이징
기존의 오프셋 기반의 페이징에서 커서 기반의 페이징으로 개선을 진행해보았다.
오프셋 기반의 페이징의 경우 만약 LIMIT 5 OFFSET 10000 이라고 하면 총 10,005 개의 데이터를 디스크로부터 읽어와야한다. 그런데 여기서 디스크로부터 레코드를 읽을 때에는 랜덤I/O 가 발생하게 되므로 뒤쪽을 읽으려고 하면 실행시간은 선형적으로 계속해서 증가하게 된다는 문제가 있다.
(스토리지 엔진에서 일단 읽어온 이후에 MySQL 엔진에서 조건을 처리해 필터링해서 반환하는 방식이다.)
그런데 WHERE 절을 통해서 페이지 조건을 넘겨주는 커서 기반의 페이징에서는 LIMIT 5 처럼 필요한 데이터가 5개라고 하면 몇번째 데이터를 읽던지 간에 관계없이 5개만 디스크로 부터 읽어오게 된다.
(스토리지 엔진에서 데이터를 읽어 올 때 조건에 대한 필터링을 하게 된다. 인덱스도 적용시킬 수 있게 된다.)
[BE] issue467: 스터디 목록 조회 커서 기반 페이징
기존의 존재하는 오프셋 기반의 페이징을 모두 변경하기에는 비용이 크기 때문에(프론트와 API변경에 대해서 이야기 해보아야하고, production 코드와 test 코드 모두에서 변경이 발생하기 때문에) 우선 가장 많은 조회가 이루어질 것으로 기대되는 메인페이지 의 스터디 목록 조회에 대해서 우선적으로 적용해보았다.
production 코드의 조건절 부분은 다음과 같이 변경된다.
private String whereCondition(final Long id, final LocalDateTime createdAt, final String title,
final SearchingTags searchingTags) {
if (!hasCondition(id, createdAt, title, searchingTags)) {
return "";
}
final String cursorClause = filtersInCursorClause(id, createdAt);
final String titleClause = filtersTitleClause(title);
final String filtersInQueryClause = filtersInQueryClause(searchingTags);
final String combinedClause = combineClause(cursorClause, titleClause);
if (combinedClause.isBlank()) {
return "WHERE " + filtersInQueryClause.replaceFirst("AND ", "");
}
return "WHERE " + combineClause(cursorClause, titleClause) + filtersInQueryClause;
}
private boolean hasCondition(final Long id, final LocalDateTime createdAt,
final String title, final SearchingTags searchingTags) {
return id != null || createdAt != null || !title.isBlank() || !searchingTags.isEmpty();
}
private String filtersInCursorClause(final Long id, final LocalDateTime createdAt) {
if (id != null && createdAt != null) {
return "(study.created_at < :createdAt OR (study.created_at = :createdAt AND id < :id)) ";
}
return "";
}
private String filtersTitleClause(final String title) {
if (title.isBlank()) {
return "";
}
return "UPPER(study.title) LIKE UPPER(:title) ESCAPE '\' ";
}
private String filtersInQueryClause(final SearchingTags searchingTags) {
String sql = "AND {}_tag.id IN (:{}) ";
return Stream.of(CategoryName.values())
.filter(searchingTags::hasBy)
.map(name -> sql.replaceAll("\\{\\}", name.name().toLowerCase()))
.collect(Collectors.joining());
}
private String combineClause(String... clauses) {
final List<String> notBlankClauses = Arrays.stream(clauses)
.filter(it -> !it.isBlank())
.collect(Collectors.toList());
if (notBlankClauses.isEmpty()) {
return "";
}
StringBuilder stringBuilder = new StringBuilder(notBlankClauses.get(0));
for (int i = 1; i < notBlankClauses.size(); i++) {
stringBuilder.append("AND " + notBlankClauses.get(i));
}
return stringBuilder.toString();
}id 와 createdAt 유무에 따라 새롭게 filtersInCursorClause() 조건이 추가된다. 여기서 해당 값의 유무에 따라서 조건을 추가해주거나 추가해주지 않는 이유는 cursor 기반의 페이징의 경우 첫 페이지 요청에서는 id와 createdAt 조건으로 완성되는 페이징 조건을 알 수 없고, 처음부터 limit 개수의 데이터만 조회해오면 되므로 이와 같이 구성해주었다.
오프셋 기반의 실행을 했을 때의 모습이다.
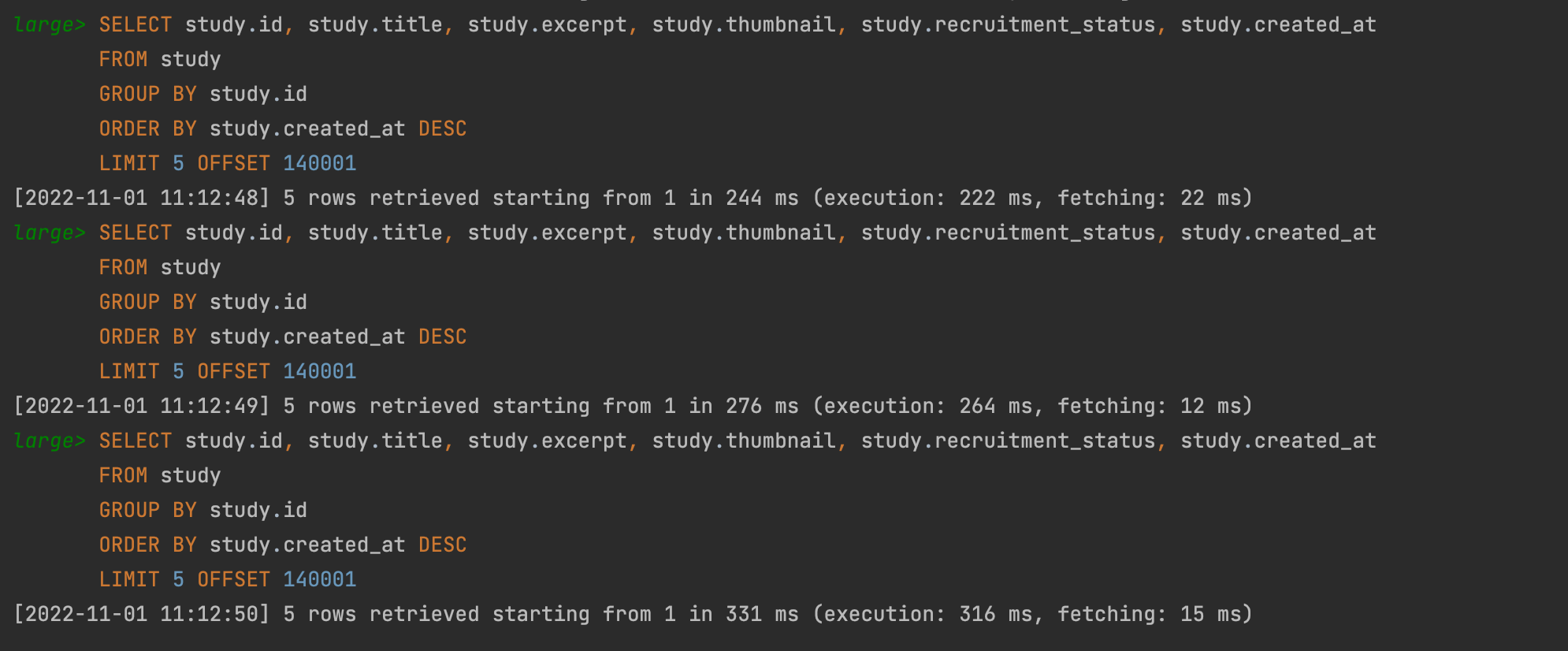
평균적으로 200ms 를 넘으며 심지어는 316ms 의 execution time 을 보이기도 하는 것을 확인할 수 있다.

실행계획을 살펴보면 type 이 ALL 로 테이블 전체를 스캔해서 읽어오는 것을 알 수 있다.
그런데 여기서 동일한 결과를 보이는 쿼리를 커서 기반으로 해서 조회를 해올 때를 비교해보면 확실한 성능 개선을 알 수 있다.
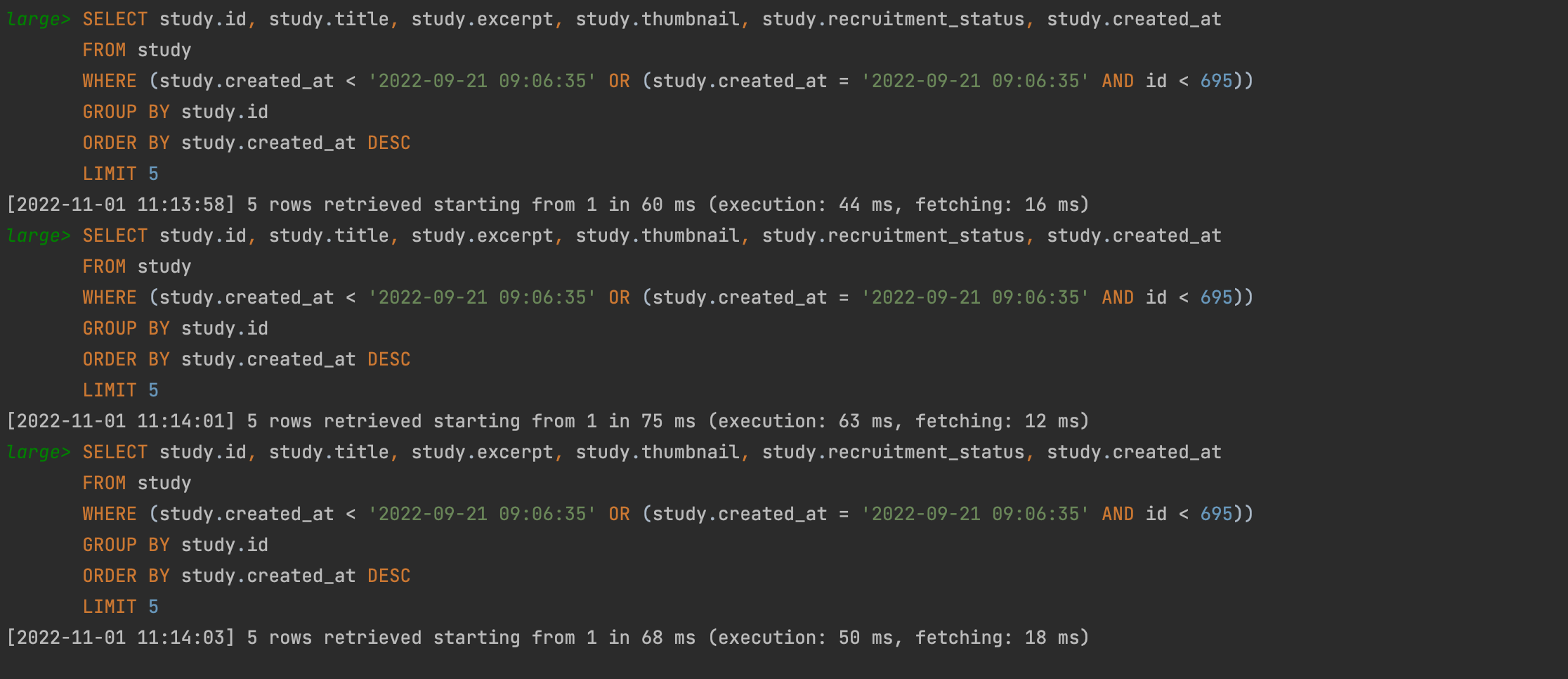
앞서 적어도 200ms 를 넘는 실행시간을 보였던 반면 평균적으로 50ms 정도의 실행시간으로 적어도 4배 이상의 성능 개선이 일어났음을 확인할 수 있다.
실행계획을 살펴보면 인덱스로 앞서 정렬을 위해 만들어 두었던 idx_created_at 을 사용하고 있는 것을 알 수 있고, Extra 부분에 Using index condition 으로 볼 때 인덱스 컨디션 푸쉬다운(ICP: Index Condition Pushdown) 즉 스토리지 엔진 쪽으로 검색 조건이 푸쉬된 것을 확인할 수 있다.
(앞서 언급한 것과 같이 스토리지 엔진에서 부터 읽어올 때 필요한 갯수만큼의 데이터를 조회해오므로 검색 조건(condition)을 스토리지 엔진쪽으로 push해준 것이라고 볼 수 있다.)

여기서 (created_at, id) 조합으로 생성된 인덱스가 필요하지 않을까? 하는 생각을 할 수 있을 것 같다. 하지만 실제로 해당 인덱스를 추가해도 possible_keys 즉 인덱스 후보로는 오르지만 실제로 사용되지는 않는 것을 확인해볼 수 있다.

그 이유는 created_at 의 경우에는 세컨더리 인덱스이기 때문에 리프 노드에서 레코드 주소를 직접 가지는 것이 아니라 PK 인 id를 가지고 있기 때문에 해당 인덱스만을 이용해서도 id 에 대해서 조건을 검사해줄 수 있는 것이다.
이렇게 해서 모아모아 서비스에서 조회를 하는 쿼리들에 대해서 최적화를 진행해보았는데, 아직 부족한 점이 많다고 생각한다. 앞서 잠깐 언급한 것과 같이 현재 오프셋 기반의 조회가 아직 남아있다. 앞으로도 점진적으로 쿼리들을 개선해보는 경험을 해나가볼 수 있을 것 같다.
또한 처음 해보는 쿼리 최적화 과정이 신기하기도 하고 진행하는 과정이 매우 흥미로웠다.

저 메일을 보내고 기다리고 있었는데 잘못보냈었네요 ㅠㅠ 방금 메일 보냈습니다 확인하시면 메일에 오픈카톡 한번만 부탁드려요... 저도 바로 확인하려구요 ㅠㅠ 시간이 없으실 것 같은데.. 죄송합니다ㅠㅠㅠ