로버트 C 마틴(Robert C. Martin) 은 소프트웨어를 아래의 2가지 영역으로 구분하고 있다.
애플리케이션 영역
-> 고수준 정책 및 저수준 구현을 포함메인 영역
-> 애플리케이션이 동작하도록 각 객체들을 연결
어플리케이션 영역과 메인 영역
메인(main) 영역은 애플리케이션 영역에서 사용될 객체를 생성해주고, 각 객체간의 의존 관계를 설정하며 애플리케이션을 실행하는 책임을 가진 영역이다.
위의 로버트 C 마틴이 이야기한 메인 영역과도 일맥상통하는 내용이다.
public class Main {
private static final InputView inputView = new InputView();
private static final OutputView outputView = new OutputView();
public static void main(String[] args) {
// BlackJack이라는 상위 수준 모듈에서 사용할 하위 수준 모듈을 생성하며 생성자 DI으로 주입해주고 있다.
BlackJack blackJack = BlackJack.from(getPlayerInfo(), new ShuffledDeckGenerateStrategy());
blackJack.setInitCardsPerPlayer();
printInitCardInfo(blackJack);
drawAdditionalCard(blackJack);
printFinalResult(blackJack);
}
...
}예를 들어 위와 같은 코드가 메인영역의 코드라고 볼 수 있는데, 객체의 초기화(BlackJack.from()), 의존 처리(blackJack.setInitCardPerPlayer()), 실행을 담당하고 있음을 알 수 있다.
메인 영역은 애플리케이션 영역의 객체를 생성하고, 설정하고, 실행하는 책임을 갖기 때문에, 애플리케이션 영역에서 사용할 하위 수준의 모듈을 변경하고 싶다면 메인 영역을 수정하게 된다.
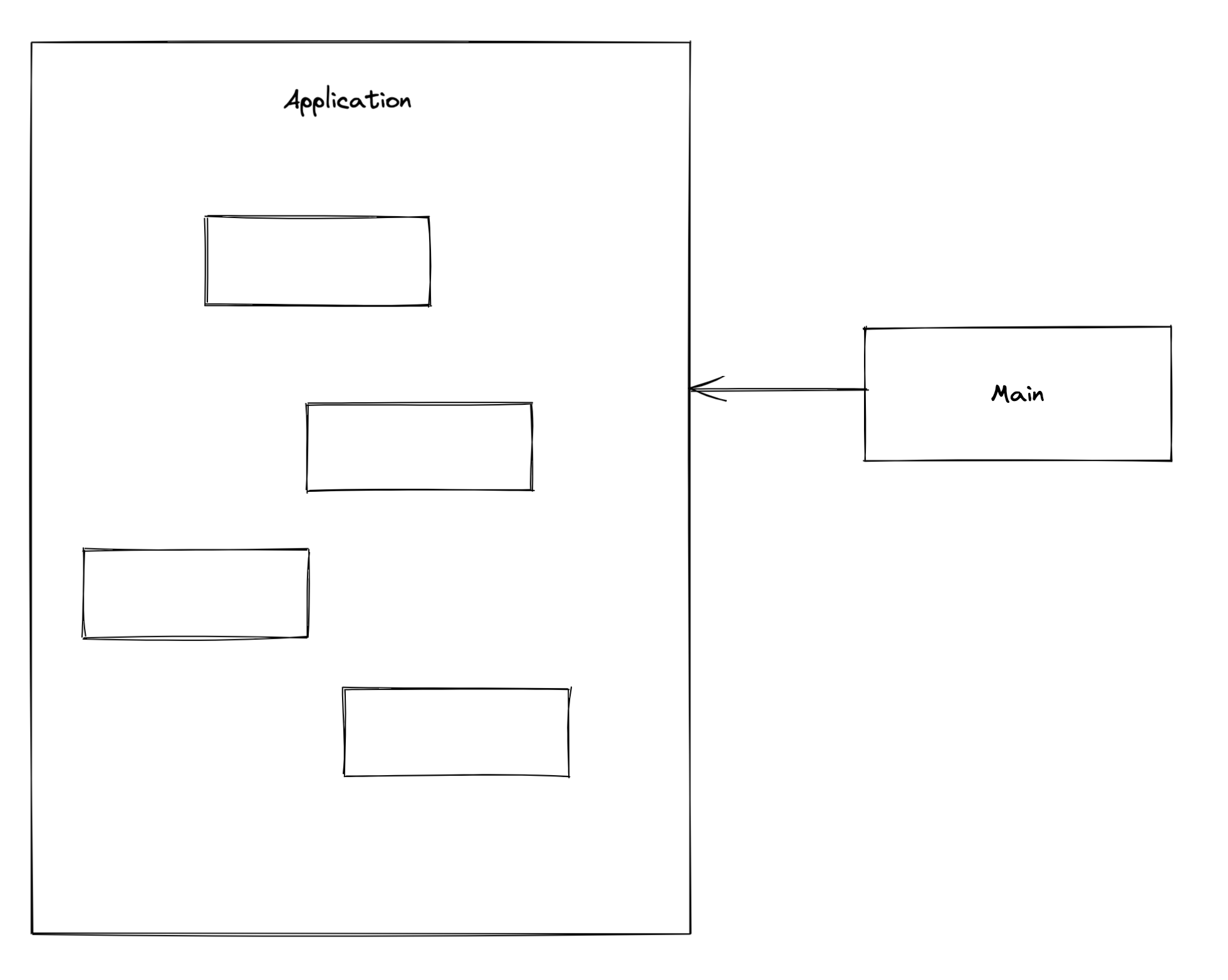
메인 영역과 애플리케이션 간의 의존은 다음 그림과 같게 되는데, 여기서 알 수 있는 점은 모든 의존은 메인 영역에서 애플리케이션 영역으로 향한다는 것이다. (즉, 반대의 경우인 애플리케이션 -> 메인 으로의 의존은 존재하지 않는다.)
이는 메인 영역을 변경하더라도 애플리케이션 영역은 변경되지 않는다는 것을 뜻하며 따라서 애플리케이션에서 사용할 객체를 교체하기 위해 메인 영역의 코드를 수정하는 것은 애플리케이션 영역에는 어떠한 영향을 주지 않는 효과를 얻을 수 있다.
사용할 객체를 제공하는 책임을 가지는 객체를 우리는 서비스 로케이터(Service Locator) 라고 부른다.
서비스 로케이터 방식은 로케이터를 통해서 필요한 객체를 직접 찾는 방식인데, 이 방식에는 몇가지 단점이 존재한다. 따라서 서비스 로케이터를 사용하기 보다는 외부에서 사용할 객체를 주입받는 DI(Dependency Injection) 방식을 사용하는 것을 추천한다.
이어지는 내용에서 DI 와 서비스 로케이터를 비교해가면서 알아본다.
DI(Dependency Injection)을 이용한 의존 객체 사용
사용하려고 하는 객체를 직접 생성해서 사용하는 경우, 저수준 모듈 즉 구체(Concrete) 클래스에 대한 의존이 발생하게 된다.
public Class Player {
private final BettingMoney money;
public Player() {
this.money = new BettingMoney();
...
}
...
}위와 같이 구체(Concrete) 클래스를 직접 사용해서 객체를 생성하게 되면 DIP(의존 역전 원칙)을 위반하게 되며 결과적으로 확장 폐쇄 원칙(OCP)를 위반하게 된다. 그리고 이는 결과적으로 변경에 유연하지 못한 코드가 되게 된다.
위 코드는 DI을 사용하여 다음과 같이 개선할 수 있다.
public Class Player {
private final BettingMoney money;
// 구체적으로 어떤 체스 기물인지를 외부에서 주입받고 있다.
public Player(BettingMoney money) {
this.money = money;
...
}
...
}DI(Dependency Injection: 의존 주입)은 위에서 언급되었던 단점을 극복하기 위한 방법으로 필요한 객체를 직접 생성하거나 찾지 않고, 외부에서 넣어주는 방식을 말한다.
위에서 보았다시피 DI 구현 자체는 매우 간단한데, 사용할 객체를 주입받을 수 있는 방법을 제공하면 된다. (그리고 이는 우리가 자주 보는 생성자 방식이다.)
수정된 ChessBoard 클래스를 보면 생성자를 호출할 때 외부에서부터 기물(Piece) 객체를 전달받고 있다. 이들 자체에서는 스스로 의존하고 있는 객체를 찾거나 생성하지 않고, 외부로부터 주입(injection)을 받고 있다.
조립기
DI를 통해서 의존 객체를 관리할 때에는 객체를 생성하고 각 객체들을 의존 관계에 따라 연결해주는 조립 기능이 필요할 수 있다. -> 그렇지 않으면 메인이 조립기의 역할도 함께 하여야한다.
조립기를 별도로 분리하면 향후에 조립기 구현 변경의 유연함을 얻을 수 있어 분리해주면 좋다.
public class Assembler {
private final Player player;
public void Assembler() {
createAndWire();
}
public void createAndWire() {
BettingMoney money = new BettingMoney();
this.player = new Player(money);
}
public Plyaer getPlayer() {
return this.player;
}
}
public class Main {
public static void main(String[] args) {
Assembler assembler = new Assembler();
assembler.createAndWire();
Player player = assembler.getPlayer();
}
}이렇게 객체 조립에 대한 기능이 분리되게 되면 향후에 XML 파일을 이용해서 객체 생성 및 조립에 대한 설정이 가능하며 이 XML 파일을 읽어와 초기화 해주도록 구현을 변경할 수 있다.
백엔드에서 자주 사용하고 언급되는 SpringFramework 도 객체를 생성하고 조립해주는 기능을 제공하는 DI 프레임워크이다.
생성자 방식과 설정 메소드 방식
DI를 통해서 의존하는 객체를 주입받을 수 있는 방법은 생성자 방식과 Setter 두가지 방식이 있다.
그리고 우리가 앞서 보인 방식이 바로 생성자를 통해서 주입을 받는 방법으로 다음과 같은 형태이다.
생성자를 통해 전달받은 객체를 필드에 보관한 뒤 메소드에서 사용하게 된다.
public class Player {
private BettingMoney money;
public Player(BettingMoney money) {
this.money = money;
}
public void someMethod() {
money.method();
...
}
...
}두번째로는 Setter를 사용하는 방식인데 개인적으로 굳이 추천하지 않으며 본인의 경우 100% 사용하지 않는 주입 방식이다.
public class Player {
private BettingMoney money;
public Player() {
}
public void setBettingMoney(BettingMoney money) {
this.money = money;
}
public void someMethod() {
money.method();
...
}
...
}왜 본인이 100% 사용하지 않는 방식이라고 이야기하는지 설득해보겠다.
Q. 만약 Player를 생성한 이후 setBettingMoney() 메소드를 호출하지 않은 상태에서 someMethod()를 실행하게 되면 어떻게 될까?
A. money.method() 호출과정에서 NullPointerException 예외가 발생하게 될것이다.
왜냐하면 아직 money에 대한 할당이 제대로 이루어지지 않았기 때문이다. 즉, Player 객체를 사용하는 클라이언트 입장에서는 생성자 호출 이후 setter 를 먼저 호출한 이후에 여러 기능(메소드)들이 실행가능하며 제대로 기능한다는 것을 알아야만이 Player를 제대로 사용할 수 있게 된다.
객체 설계 자체에 대해서도 스스로 고민해 볼 수 있다.
Q. Player는 BettingMoney를 가질 수도 있고 갖지 않을 수도 있는가?
A. Player의 생성시점에 BettingMoney가 없다. 즉, BettingMoney가 없는 Player 그리고 BettingMoney가 있는 Player 가 생기게 되는데, BettingMoney가 없는 경우 BettingMoney 생성 시점에 '0' 이라는 값을 가지고 BettingMoney는 Player들이 항상 가지고 있도록 일관성을 가질 수 있지 않을까? 또 이렇게 되면 NPE을 피할 수 있다.(물론 생성자 방식을 사용하는 경우에도 넘겨져오는 BettingMoney도 null 일수는 있지만 생성시점에 valite를 할 수는 있다.)
Q. Setter는 생성 시점 이외의 시점에도 호출 가능하다. 이것이 갖는 문제점은 없을까?
A. 프로그램이 돌아가는(프로세스) 도중에 Player 가 가지는 BettingMoney 객체 자체가 변경될 가능성이 있다. 그리고 이는 여러 Exception의 발생 가능성을 열어두는 것이 된다. 또한 Player가 불변성을 가질 수 없어 Player를 사용할 때 여러 검증 코드가 추가되어야만 할 것이다. (이외에도 Setter를 두지 않는 여러 이유가 있을 것인데, 지금 생각나는 정도는 이정도이다. 만약 이와 관련하여 궁금하다면 여러 좋은 블로그글을 참고해보는 것을 추천한다.)
책에서는 생성자 방식의 경우 객체를 생성하는 시점에 필요한 모든 의존 객체를 준비할 수 있고, 생성 시점에 의존 객체가 정상인지 확인할 수 있기 때문에 '생성자 방식'을 선호한다고 이야기한다.
이 말에는 동의하지만, "생성자 방식을 사용하려면 의존 객체가 먼저 생성되어 있어야 하므로 의존 객체를 생성할 수 없다면 생성자 방식을 사용할 수 없고, 설정 메소드 방식을 사용해야 한다. (의존할 객체가 나중에 생성된다면 설정 메소드 방식을 사용해야 한다.)"고 이야기 하고 있다. 하지만 이말에는 동의하지 않는다.
과연 의존 객체가 준비되어 있지 않은 상태에서 객체를 생성하는 것이 맞을까? 그 객체를 제대로 생성하는 것일까?
DI와 테스트
단위 테스트는 어떤 클래스의 하나의 단위 기능을 테스트 하는데 초점이 맞춰져 있다. 하지만 다른 객체에 의존하고 있는 경우, 즉 의존 객체를 사용하는 경우에는 제대로된 단위 테스트 작성이 힘들 수 있다. 하지만 우리는 DI를 사용하고, Mock 객체를 전달함으로써 테스트 코드를 작성해 낼 수 있다.
public class Car {
private static final int POSITION_INITIAL_VALUE = 0;
private static final int PROGRESS_CONDITION_VALUE = 4;
private int position = POSITION_INITIAL_VALUE;
public void progress() {
int randomNumber = getRandomNumber();
if (randomNumber > PROGRESS_CONDITION_VALUE) {
position ++;
}
}
...
}위와 같은 코드가 있다고 가정해보자. 그런데 우리는 progress() 메소드 호출 시 어떤 기준(PROGRESS_CONDITION_VALUE)을 넘으면 position이 제대로 증가하는지를 확인하고 싶다고 가정하자.
Q. 프로덕트 코드(위의 코드)를 변경하지 않고 제대로된 테스트 코드를 작성할 수 있을까??
아마 위의 대한 대답은 '아니오' 일 것이다.
하지만 여기에 전략 패턴과 함께 DI을 사용해서 위의 코드를 다음과 같이 개선했다고 생각해보자.
public interface MovingStrategy {
boolean isMovable();
}
public class RandomMovingStrategy implements MovingStrategy {
private static final int PROGRESS_CONDITION_VALUE = 4;
private static final int RANDOM_RANGE = 10;
@Override
public boolean isMovable() {
int randomNumber = getRandomNumber();
return randomNumber >= PROGRESS_CONDITION_VALUE;
}
private static int getRandomNumber() {
return (int) Math.floor(Math.random() * RANDOM_RANGE);
}
}
public class Car {
private static final int POSITION_INITIAL_VALUE = 0;
private static final int PROGRESS_CONDITION_VALUE = 4;
private int position = POSITION_INITIAL_VALUE;
public void progress(MovingStrategy movingStrategy) {
if (movingStrategy.isMovable()) {
position ++;
}
}
...
}그러면 여러분은 다음과 같은 테스트 코드를 작성할 수 있고, 제대로된 테스트를 해볼 수 있을 것이다.
@SuppressWarnings("NonAsciiCharacters")
class CarTest {
@Test
@DisplayName("자동차에 기준값 보다 큰 값을 주면 전진 하는지 확인")
public void 자동차_진행_테스트() {
//given
Car car = new Car("woo");
//when
car.progress(() -> true);
//then
assertThat(car.getPosition()).isEqualTo(1);
}
@Test
@DisplayName("자동차에 기준값 보다 작은 값을 주면 정지 하는지 확인")
public void 자동차_정지_테스트() {
//given
Car car = new Car("woo");
//when
car.progress(() -> false);
//then
assertThat(car.getPosition()).isEqualTo(0);
}
...
}서비스 로케이터를 이용한 의존 객체 사용
프로그램 개발 환경이나 사용하는 프레임워크의 제약으로 인해 DI 패턴을 적용할 수 없는 경우가 있다. 예를 들어, 안드로이드 플랫폼을 개발하는 모바일 앱의 경우 화면을 생성할 때 Activity 클래스를 상속받도록 하는데 이 경우에는 DI처리를 할 수 없다.
이러한 경우 우리는 의존 객체를 찾는 다른 방법을 모색해야 하는데, 어플리케이션에서 필요로 하는 객체를 제공하는 책임을 가지는 서비스 로케이터(Service Locator) 가 바로 그 예이다.
서비스 로케이터는 다음과 같이 의존 대상이 되는 객체별로 제공 메소드를 정의하고, 의존 객체가 필요한 코드에서는 ServiceLocator가 제공하는 메소드를 활용해서 알맞은 객체를 의존한 뒤 기능을 수행할 수 있다.
public class ServiceLocator {
public 작업 get작업() {...}
public 의존객체 get의존객체() {...}
}서비스 로케이터가 올바르게 동작하기 위해서는 서비스 로케이터 스스로 어떤 객체를 제공해야할지에 대해서 알고 있어야 한다.
DI를 사용할 때 메인 영역에서 객체를 생성했던 것과 비슷하게 서비스 로케이터를 사용하는 경우에도 메인 영역에서 서비스 로케이터가 제공할 객체를 초기화해준다.
서비스 로케이터는 어플리케이션 영역의 객체에서 직접 접근하기 때문에, 애플리케이션 영역에 위치하게 된다.

객체 등록 방식과 상속 방식
객체 등록 방식
- 서비스 로케이터를 생성할 때 사용할 객체를 전달한다.
- 서비스 로케이터 인스턴스를 지정하고 참조하기 위한 static 메소드를 제공한다.
public class ServiceLocator {
private static ServiceLocator instance;
private 작업 job;
private 의존객체 dependency;
public ServiceLocator(작업 job, 의존객체 dependency) {
this.job = job;
this.dependency = dependency;
}
public 작업 getJob() {
return job;
}
public 의존객체 getDependency() {
return dependency;
}
public static void load(ServiceLocator locator) {
ServiceLocator.instance = locator;
}
public static ServiceLocator getInstance() {
return instance;
}
}메인 영역의 코드에서는 위 서비스 로케이터의 생성자를 사용해서 제공할 객체를 설정해주고, load() 메소드를 이용해서 메인 영역에서 사용할 ServiceLocator 객체를 초기화한다.
public static void main(String[] args) {
ServiceLocator locator = new ServiceLocator(job, dependency);
ServiceLocator.load(locator):
...
}객체를 등록하는 방식의 장점은 서비스 로케이터 구현이 쉽다는데에 있다. 하지만 구현이 쉬운 만큼 단점은 많은 법이라고 생각한다.
이 경우에는 서비스 로케이터에 객체를 등록하는 인터페이스가 노출되어 있기 때문에 애플리케이션 영역의 코드에서 얼마든지 의존 객체를 변경할 수 있다는데에 있다. 그리고 이는 고수준 모듈에서 저수준 모듈인 구체(concrete) 클래스에 직접 접근하도록 유도할 수 있기 때문에, DIP(의존 역전 원칙)을 어기게 만드는 원인이 된다.
상속을 통한 서비스 로케이터 구현
- 객체를 구하는 추상 메소드를 제공하는 상위 타입 구현
- 상위 타입을 상속받은 하위 타입에서 사용할 객체 설정
public abstract class ServiceLocator {
private static ServiceLocator instance;
public abstract 작업 job;
public abstract 의존객체 dependency;
protected ServiceLocator() {
ServiceLocator.instance = this;
}
public static ServiceLocator getInstance() {
return instance;
}
}위 추상 클래스는 2개의 의존객체를 구할 수 있다.
ServiceLocator를 이용해서 의존 객체를 필요로 하는 코드는 ServiceLocator.getInstance() 메소드를 이용해서 ServiceLocator 객체를 얻은 뒤, getter를 써서 필요한 의존객체를 구할 수 있다.
이렇게 함으로써 의존 객체를 교체해야할 때, 어플리케이션 영역의 코드 수정 없이 메소드인 영역의 코드만 수정할 수 있다.

ServiceLocator 클래스를 상속 받은 클래스의 객체를 생성할 때마다 ServiceLocator 클래스의 static 필드인 instance가 참조하는 객체가 변경된다. 일반적으로는 ServiceLocator를 상속받은 클래스의 객체를 한 번만 생성하기 때문에 문제되는 경우가 거의 없지만 실수로 여러번 만들 경우 문제가 발생할 수 있다.
서비스 로케이터의 단점은 ISP(인터페이스 분리 원칙)을 위반한다는 것이다. 만약 위의 코드에서 "작업" 이라는 인스턴스만 필요한 경우에도 "의존 객체" 라는 객체에 대한 의존이 함께 발생하게 된다.
이 문제를 해결하기 위해서는 의존 객체마다 서비스 로케이터를 작성해주어야 한다. 하지만 이는 서비스 로케이터 구현(concrete) 클래스에 대한 중복 코드를 유발하게 된다.
다행히도 자바에서는 Generic이라는 문법을 제공하고 Generic 기반의 객체 등록 방식 서비스 로케이터를 구현할 수 있다.
public class ServiceLocator {
private static Map<Class<?>, Object> objectMap = new HashMap<Class<?>, Object>();
public static <T> T get(Class<T> instance) {
return (T) objectMap.get(instance);
}
public static void regist(Class<?> instance, Object obj) {
objectmap.put(instance, obj);
}
}서비스 로케이터의 단점
- 동일 타입의 객체가 다수 필요한 경우, 각 객체별로 제공 메소드를 만들어 주어야 한다.
- 조건에 따라 서로 다른 객체를 사용해야 한다면 조건에 따라 ServiceLocator의 다른 메소드를 호출하는 코드가 들어가게 되고, OCP를 지키지 못하게 된다.
- 서비스 로케이터는 ISP(인터페이스 분리 원칙)을 위배하게 된다.
- 서비스 로케이터를 사용하는 입장에서는 자신이 필요한 타입 뿐 아니라 다른 타입에 대한 의존이 함께 발생하기 때문에 다른 의존 객체에 의해서 발생하는 서비스 로케이터의 수정의 영향을 받을 수 있게 된다.
