🧑🏻💻 안녕하세요! 토스터 서버파트의 리드를 맡은 흠냐입니다..!
TOASTER가 어느덧 300명을 넘어 400명에 가까워지고 있습니다.🎉 (작성시기는 실유저 399명..!) 분명 우리 서비스를 이용 잘해주는 유저들이 있다는 것에 공부에도 동기부여가 많이 되어가고 있습니다. 그래서 우리 토스터에서 있었던 아찔했던 기억들을 정리하고, 어떻게 해결해왔고, 앞으로의 토스터 서버는 어떻게 유지보수해갈지를 생각해왔습니다.
🥪 이야기 첫번째, 우리 고래🐳가 숨을 안셔..ㅜ
솝트 데모데이날 트래픽이 몰려서 dbConnectionTimeOut이 떴던 사건이 있었습니다.
우리가 8명 정도만 타이머 서비스를 설계해도 우리 도커가 dbConnectionTimeOut이 뜨면서 죽어버리는 사건이 있었습니다. 그래서 결국 도커를 계속 모바일로 CI/CD로 살리는 지경에 이르렀는데요. 데모데이 때는 어찌저찌 임시방편으로 살렸지만 원인과 그것을 해결하는 과정이 중요했습니다.
🍞: 발생 원인이 뭘까..?
🍞: 아.. 우리 타이머가 돼진데? 스레드를 다 잡아먹고 있어..
발생원인은 다음과 같았습니다. 우리 토스터 서비스에서는 매 분 마다 우리 서비스를 이용해주는 유저들의 타이머를 설계해줘야했습니다. 유저마다 각자 다른 시간에 5개씩 설계할 수 있도록 되어있어서 분까지 고려해주는 것이 중요했고 우리 디자이너들과 앱 개발자들이 만들고 있는 예쁜 ui를 살리고 싶어서 못 하겠다는 말은 하고싶지 않았습니다.
저희가 고민했던 이 문제에 대한 해결책으로는 두 가지가 있었습니다.
- 서버를 1분마다 스케줄링하여 타이머 시간들을 조회한다.
- 각 시간들을 cron 문자열로 변경하여 엔티티에 저장하고 그 string을 기준으로 실행시킨다.
저희는 1번 방법보다 2번 방법이 조금 더 좋아보였습니다. 실시간으로 계속 polling 작업을 하는 것보다는 차라리 그 때 그 때 시간마다 생성되고 없애는 것이 조금 더 효율적으로 보였기 때문입니다.
하지만 이 점이 문제였습니다. 데모데이 때 순간적으로 많은 동접자들이 발생했고, 8명 정도만 타이머를 맞춰도 타이머가 생성될 때마다 새로운 스레드를 생성했고,
한정된 우리의 자원이 바닥나 고래가 말라 비틀어지고 말았습니다.😢
🐳 고래야.. 숨 좀 셔봐..ㅜ 심폐소생술 하는 방법 찾기.
이에 대한 해결책을 찾기위해서 현업 개발자님과 멘토링을 진행했습니다.
멘토님은 보통 스케줄링과 같은 작업을 한 개의 서버에서 진행하는 것은 다른 RestAPI들과 함께 사용하기에는 자원이 부족할 것이기에 스케줄링 서버를 따로 분리해서 스케줄링만 관리하게 만드는 것이 구조적으로 더 좋을 것이다.
또한, 지금 Cron String을 이용해서 만드니 타이머가 생성될 때마다 스레드를 새로 점유하는 것으로 보이는데 오히려 1분마다 Cron으로 체크하는 과정이 조금 더 자원을 아끼고 스레드 하나로 계속 일을 시킬 수 있기에 현재 한정된 상황에서의 대처로는 이 방법이 더 좋은 방법일 것이다.라는 피드백을 받고 후자의 방식으로 로직을 변경하고 알림서버를 분리해보자는 결론을 내리게 되었습니다.
🍞: 우리의 알림 서버를 어떻게 구현하는 게 좋을까?
🍞: AWS lambda를 써보는 건 어떻게 생각해?

그래서 AWS lambda를 써본 적이 없었던 필자를 lambda에 대해서 어떤 서비스인지 사전조사를 하게 됩니다. lambda는 나름 요약해보자면 어떤 이벤트 트리거가 발생하면 간단하게 작성한 코드를 실행시킬 수 있는 서버리스 컴퓨팅 시스템입니다. 그리고 사용한 컴퓨팅 리소스의 양에 따라 가격이 나가게됩니다.
AWS Lambda VS Aws free tier EC2 1대 추가..
돈 없는 대학생들인 우리..😢 어떤게 더 경제적일까?💰
사실 어떻게 보면 제일 중요한 것은 바로 돈💰문제였습니다.
저희 서비스를 이용하는 사람들이 아무리 적더라도 cron문자열로 그 시간이 되었을 때 매일매일 알림을 쏠 때마다 드는 비용과 프리티어로 t2.micro로 서버를 따로 띄워서 컴퓨팅하는 것 중 어떤 것이 더 경제적일까를 따져봤을 때 역시 프리티어 기간 동안은 EC2로 쓰는 것이 더 경제적이지 않을까 판단 했습니다.
(아무래도 지금은 무료니까.. 나중에 가격비교하고 변경해보자!)
그리고 조사하다보니 cpu사용량이 높은 작업을 하는 과정들을 lambda에 적용시켰다가 엄청난 과금 폭탄을 맞은 사람들의 후기들도 보이는 것을 보면 현재 바꾼 로직인 cron으로 1분마다 돌리는 로직을 그대로 올리기에도 cpu사용량을 고려했을 때 무리일 것 같고, 당장 좋은 방법으로 스레드를 고려하며 이벤트 트리거를 작동시킬 예쁜 방법이 떠오르지 않아서 알림 스케줄링 서버를 프리티어 EC2로 분리시키자는 결론을 내렸습니다.
그 결과..!
CPU 사용량이 100프로를 점유해서 죽어버렸던 고래가 30프로 정도로 내려와 숨을 편히 쉴 수 있게 되었습니다. 아찔하기도 했고 자꾸 죽는 고래로 인해 조마조마 가슴 졸였던 팀원들에게 미안하고 고마운 마음도 들었습니다.😢
그래서 저희 토스터는 알림서버를 위와 같이 분리하였고, 이를 통해 조금은 안정적인 실시간 알림 서비스를 구축할 수 있게 되었습니다.🍞
🥪 이야기 두번째, 메시지 큐 왜 써보고 사용한다면 어떤 서비스를 사용해볼까?
필자는 전에 다른 서비스에서도 RabbitMQ를 도입하여 사용해서 소셜 커뮤니케이션 앱의 푸시알림을 관리해본 경험이 있었습니다. 때문에 이번 우리 타이머에서도 푸시알림 서비스를 이용하기에 메시지 큐 도입을 생각하고 있었습니다.
🍞: 오빠, 근데 이거 왜 쓰는거야?
🍞: 흠냐..!
메시지 큐 도입을 생각했던 이유는 다음과 같았습니다.
첫번째로 서버가 받는 부하를 줄일 수가 있습니다. 만약 많은 메시지 요청들이 우리 서버의 좁은 문으로 몰려와서 우리가 요청을 받고, 파이어 베이스 서버와 연결하고, 커넥션을 닫고 이런 과정들을 반복한다고 가정을 해봤습니다.
우리 토스터에서는 현재 타이머에서만 푸시알림을 사용하고 있지만, 다른 푸시알림 기능도 사용한다면 요청들이 몰려서 병목현상이 일어나게 될 가능성이 높을 것이라고 생각했습니다.
하지만 내가 만약 요청을 우체통에 넣어두고 나중에 내가 그 요청을 처리할 수 있는 환경일 때 받아서 처리한다면?
마치 우리가 사용하는 버퍼처럼 처리등을 지연시키고 놀고있는 리소스를 이용해 조금 더 일처리 효율이 늘릴 수 있는 가능성도 있고 객체 생성, 전송 과정과 같은 부분적인 기능들의 결합을 느슨하게 만들어 사용할 수 있다는 점에서 좋은 장점을 가지고 있다고 생각했습니다.
두번째로는 MSA로 확장시킬 수 있다고 생각했습니다.
사실 MSA라는 말을 꺼내기에 조금 무서운 감은 있지만..ㅎㅎ
만약 우리가 유저들이 더 늘어나고 다른 추가적인 기능들의 서비스도 독립시켜서 운영할 수 있는 기회가 온다면..!
우리 서비스의 다른 서버와 통신을 하는 과정에서 이러한 경험이 현재 상황에서는 오버엔지니어링이어도 그런 상황에서 중요한 도움을 줄 것이라고 생각했습니다.
이렇게 메시지 큐를 통해서 서로 통신하는 과정을 설계하면 서버 장애가 나더라도 어떤 기능에서 문제가 있는지를 빠르게 찾아내서 대응할 수 있고, 만약 꼭 이뤄져야하는 중요한 요청이라면 데드레터 큐등을 통해 실패한 요청의 재요청을 보내는 식으로 대응할 수 있는 장점이 있다고 생각했습니다.
이와 같이 현재로서는 오버 엔지니어링이라고 할 수 있어도 미래의 확장성과 이후의 잠재 되어있는 장애들에 유연하게 대처할 수 있다는 점에서 다음과 같은 메시지 큐의 사전 도입은 괜찮을 것이라고 생각했고 나중에 릴리즈 후에 붙이는 것은 아직 서버 꼬꼬마인 우리들 입장에서 쉽게 갈 일을 더 어렵게 만들 수 있다고 생각을 했기에 이 메시지큐를 도입하기로 결정했습니다.
다음으로는 이제 어떤 메시지큐를 도입할지에 대해서 고민하게되었습니다.
RabbitMQ vs SQS
RabbitMQ를 사용할 것인지, SQS를 사용할 것인지에 대해서 고민을 하게되었습니다. 먼저 RabbitMQ는 필자는 저번 프로젝트에서 사용했을 때 생각보다 괜찮기도 하고 server 자체에 설치하고 모니터링을 할 수있는 GUI환경도 있어서 좋았으며 무료여서 더 좋았던 점이 생각났습니다.
하지만 SQS에 대한 경험도 한번 해보고 싶었고, RabbitMQ와 같은 경우에는 설치하는 등의 리소스도 드는것이 있었기에 아직 프로덕션 서버와 개발서버를 분리하지 않은 상태에서는 오히려 AWS 서비스에 위임해서 기능 개발 하는데에 집중을 할 수 있게 사용하는 것이 더 좋다고 생각하여 SQS를 도입하게 되었습니다.
(🐰RabbitMQ와 비교했을 때, 좀 더 이해하기에도 좋고 가독성면에서도 더 좋았던 것 같습니다.)
🥪 이야기 세번째, 토스트 JSoup에 찍어먹기.
저희 토스터 서비스에서 링크를 저장하면 가끔씩 그 사이트의 이미지를 가져오는 것을 볼 수 있습니다. 이 이미지 썸네일을 가져오는 기능은 처음이기도 해서 어떻게 기능을 구현해야할지 막막했지만, 이쁜 디자인을 위해서는 꼭 가져오고 싶다는 욕심이 생기는 서버 파트였습니다.
크롤링이 필요할까? 크롤링이 뭘까?
사실 필자는 예전에도 크롤링을 해봤다고 생각을 했었습니다. 코딩을 대학교에 들어와서 거의 처음 접한 비전공자에 가깝던 저는 파이썬을 배우고 LMS라는 코로나에 대응하기 위한 온라인 시스템 안에서 대학교 수업을 듣게 되는데요.
너무 수업이 졸린 교양수업이 있어서 강의를 틀어놓고 잠을 자기위한 코딩을 시작해 2학년 1학기 때 교양수업들을 beautiful soup와 selenium을 이용해서 자동으로 강의 틀어놓기 프로그램을 만들었던 기억이 새록새록나네요..(교수님 죄송해요..)
그래서 저는 이를 크롤링이라고 생각하고 방법을 찾아보다가
지금까지의 제가 했던 것들은 크롤링이 아니라는 것을 알게되었습니다.
크롤링이라는 것은 이해한대로 요약을 나름 해보자면 원하는 사이트에서 특정 html의 태그를 찾아서 파싱하는데에 멈추는 것이 아니라 그 사이트의 html의 구조가 변하더라도 dfs등을 통해서 합법적으로 긁어도 되는 사이트들을 들어가서 데이터를 수집하는 과정이라고 공부하게되었습니다.
즉, 제가 원하는 활동은 크롤링이 아니라 합법적인 parsing이 목적이었습니다. 그렇다면 합법적으로 긁는다는 것은 무슨뜻일까요?
robots.txt의 필요성
robots.txt라고 각 사이트들마다 있는 곳, 없는 곳이 있습니다만, 사이트주소/robots.txt 등을 쳐보면 긁어도되는 페이지등을 기록해놓습니다. 하지만 만약에 Disallow: / 이런식으로 표시되어있는 경우는 모든 페이지에서 데이터 긁는 것을 동의하지 않습니다. 라는 의미로 크롤링해서는 안되는 것이죠. 그래서 실제로 어떤 회사에서 위를 근거로 패소한 사례도 있다고 합니다.
참고해서 공부했던 글은 밑에 남겨두겠습니다.
공부할 때 읽었던 velog 글
🍞: 그러면 우리가 이미지 썸네일을 찾아내려고 하면 어떻게 해야할까? 그렇다고 합법적으로 크롤러를 만들려면 너무 리소스가 큰 것 같아.. ㅜ
🍞: 그럼 우리가 이미 합법적으로 긁어놓은 이미지를 찾아내는 것은 어떨까?
이 때 저희 TL이 개발자가 아님에도 이런 데이터가 존재한다는데? 하면서 레퍼런스를 툭 던져줍니다. 굶주렸던 서버파트는 그 레퍼런스를 스태프들과 함께 맛있게 나눠먹었습니다.
Open graph Data
오픈 그래프는 웹 페이지의 메타 데이터를 표준화하여 소셜 미디어 플랫폼에서 공유할 때 일관된 정보를 제공하는 프로토콜입니다. 쉽게 말해, 웹 페이지의 제목, 설명, 이미지 등을 정의하여 SNS에서 공유할 때 원하는 정보가 제대로 표시되도록 하는 기술이라고 할 수 있습니다.
출처: -바드의 친구 AI젬미니-
Open Graph, OG 데이터라고 불리는 이 오픈 그래프는 쉽게 말해 합법적으로 공유할 때 원하는 정보가 제대로 표시되도록 하는 기술을 의미합니다. 즉, 우리 썸네일 정보를 이미 합법적으로 가지고 있는 것이죠. 아..! 그러면 우리가 저 정보를 가져올 수 있다면 쓰고 없다면..! 우리 디자이너들의 이쁜 디자인을 보여주는 식으로 구현하면 합법적으로 로직을 구현할 수 있겠군요!
🍞다양한 예외처리들: Jsoup에 찍었더니.. 달달한 토스트를 위한 재료 필터링
Jsoup를 이용해서 parsing을 하는 과정에서 많은 역경이 있었습니다. 경우의 수가 많았는데 프로토콜이 안맞는 경우, 로그인을 해야지 볼 수 있는 사이트의 경우, 예전에 사용하고 있는 정책을 쓰는 페이지여서 우리 정책과 안맞는 사이트인 경우 등 테스트 케이스가 매우 많았습니다.
TDD를 스터디에서 공부하고 있긴 했지만 익숙하지 않기도 했고 아직 릴리즈하기 전 개발단계였기 때문에 직접 오류가 나면 그 때마다 예외처리를 하는 식으로 작성했습니다.
🛠️ 필자가 미처 생각하지 못했던 다양한 예외 케이스들을 다른 팀원들의 꼼꼼한 QA를 통해 추가할 수 있었고 그 과정에서 처음 보는 에러들을 공부하며 대처할 수 있었습니다.
MalformedUrlException,
UnKnownHostException,SSLHandShakeException 등등..
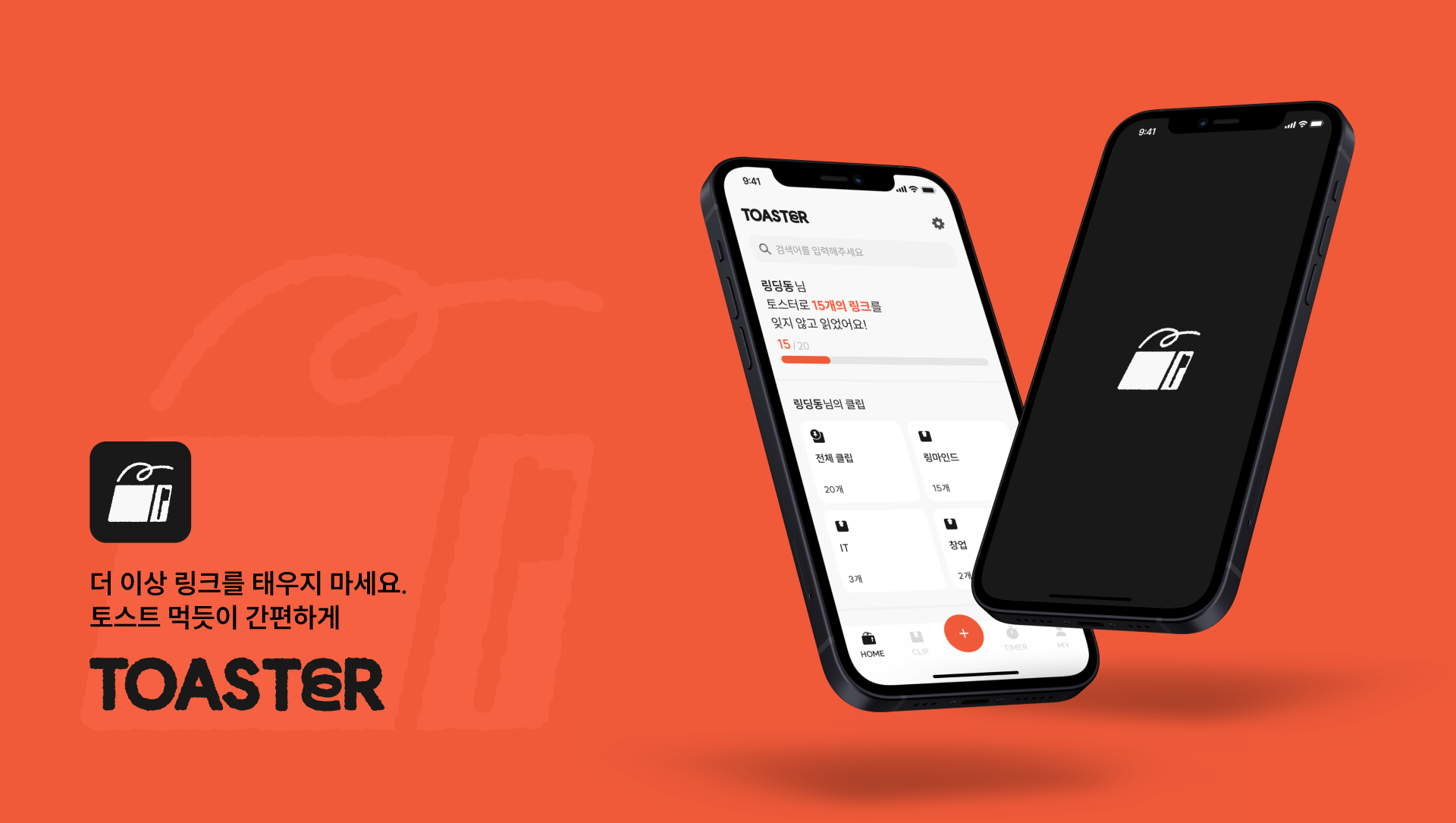
그렇게 했더니 다음과 같이 썸네일이 이쁘게 저장되는 모습을 볼 수 있었습니다.
(물론 로직 리팩토링도 필요해서 테스트 코드 체계를 제대로 잡은 이후 로직 개선을 진행하려고 합니다.🍴)
아래의 사진은 필자가 공부하고 있는 토스터 앱의 링크 저장 상태입니다.
🥪 오늘의 마지막 이야기, 신메뉴 토스트 고민하기
우리 손님들께 맛있는 토스트를 대접하기 위해서 토스터 서버는 성장에 목말라하고 있습니다. 앞으로의 신메뉴를 위해 현재 토스터 서버가 가지고 있는 고민들은 무엇일까요?
안정적인 데이터 저장을 위한 데이터베이스 replication.
테스트 코드 구축하여 더 안정적인 개발 환경 설계.
성능테스트 후 성능 최적화.
그 외 추가 기능 업데이트에 대한 고민 중..
🍞데이터베이스 replication
토스터에서는 안정적인 고객들의 링크들을 유지하기 위해서 현재 Rds에 저장하고 있습니다. 나중에 점차 유저들이 늘어나고(행복 회로긴 하지만..?) 결국 나중에 저희의 데이터베이스의 용량이 부족한 상황이 일어나게 된다면 소중한 데이터들이 위험해지게 될 수 있습니다. 또한 어떠한 실수로 데이터베이스가 먹통이 될 수도 있습니다. 그렇다면 replication을 통해서 원래 데이터 베이스의 소스를 복사해서 slave-db를 만들어서 백업을 해둔다면 그래도 그 전보다는 위와 같은 위협들로부터 안전할 수 있겠죠? 다만 이렇게 복사하는 과정은 조금 시간이 걸려서 자칫하면 에러가 날 수 있습니다. 그래서 이 때 서버 점검시간을 띄운다든가 다른 방안을 더 생각해봐야합니다.
(크흠 ㅋㅋ 1000명 달성하는 행복한 상상 중.. 흠냐..🙈)
🍞테스트 코드 구축하여 더 안정적인 개발 환경 설계.
저희가 앱잼이라는 짧은 기간동안 최소기능을 디벨롭하여 릴리즈를 해서 빠르게 토스터를 잘 사용하는 유저들의 반응을 보는 것은 물론 즐겁기도 했지만 안정적인 서비스를 제공하고 싶다는 욕심도 있어 마음 한 구석에서는 걱정도 가지고 있었습니다.💦
그래서 이러한 변수들을 차단하기 위해 QA를 많이 해가면서 잡아가고 있지만 앞으로도 잠재적인 위협을 제거하면서 개발하기 위해서는 견고하게 받춰줄 테스트코드가 필요할 것입니다. 그래서 현재 진행중이기도 하지만 여러가지 단위 테스트를 시작으로 현재 기능들에 대해서 문제를 일으키는 경우의 수들이 없는지 테스트 코드들을 작성할 것이고, 그 이후에는 성능테스트, 부하테스트 등 천천히 디벨롭해 나가는 방향으로 작성해보고자 합니다.🔥
🥪 마무리 하며
처음으로 팀 블로그를 작성해봤습니다. 뭔가 특별한 경험이기도 하고 작성하다보니 토스터를 만들며 밤새워 고민하던 이슈들과 즐거웠던 추억들이 새록새록나네요.
물론 아직은 많이 부족한 서버파트지만 꾸준히 성장하는 모습을 그려나가고 싶습니다.🌱
앞으로도 저희 토스터 서버의 성장기는 계속 됩니다.

덕분에 람다,replication, 파싱 등 다양한 인사이트 얻어갑니다~
크롤링 해봐서 안다고 생각했는데 크롤링 너머에 html 구조가 바뀌어도 가능한 파싱이 있었군요..후덜덜
더욱 깊은 개발 해봐야겠다는 생각이 드는군요! 토스터 화이팅!!!