2018년에 출간된 논문이다. 2019년 교수님이 논문을 찾아오라 했을 때 발견도 못 했었는데..
학교 선배가 현업에서 자주 쓰이는 기술이라 귀띔해주어서 리뷰한다.
paper link
code link(not mine)
Abstract
-
거친(coarse) 라벨만 있는 weakly supervised learning은 gradient의 역전파를 통해 attention map과 같은 DNN의 시각적 설명을 얻을 수 있다.
-
이런 attention map은 object localization, semantic segmentation의 사전 작업으로 사용될 수 있다.
-
하나의 일반적인 프레임워크에서 본 논문은 기존의 attemtnion map과 같은 접근이 가지는 세 가지 단점을 아래의 방법으로 해결한다.
- attention map 만드는 능력까지 한 번에 학습시킴.
- model의 self guidance를 이용해 성능을 향상시키도록 함.
- 가능하다면(?) weak/extra supervision 사이의 차이?간극?을 이어줌.
-
간단한 방법임에도, semantic segmentation에 대한 실험에서 본 논문에서 제안하는 방법의 효율성을 보인다.
-
PASCAL VOC에 대해 SOTA를 추월했다.
-
게다가, 본 논문에서 제안하는 framework는 모델의 focus만을 설명하지 않고 segmentation, localization과 같은 특정 task에 대한 피드백도 제공할 수 있다.
01. Introduction
- Weakly supervised learning은 라벨링된 데이터의 부족함을 해결할 방법으로서 주목받았다.
- image level의 라벨을 이용해 CNN에서의 back propagation을 통해 attention map을 얻을 수 있다.
- attention map에서의 픽셀값은 input image와 같은 위치의 픽셀이 해당 이미지의 최종 출력에 얼마나 기여했는지를 나타낸다.
- 별도의 추가적인 라벨링 없이 localization, segmentation정보를 얻어낼 수 있음이 알려졌다.
- 하지만 classification loss에만 지도를 받을 경우 attention map이 작고 가장 결정적인 ROI만 다루는 일이 일어났다.
- attention map은 segmentation과 같은 task의 사전 작업의 역할을 안정적으로 수행할 수 있기에 foreground object의 가능한 완전히 덮는 attention map을 만드는 것은 그러한 task들의 성능을 향상시킬 수 있다.
- 이를 위해 최근의 연구에선 하나의 network의 여러 attention map을 만들어 조합해 iterative하게 지우거나, 여러 network에서 attention map을 만들어 조합하는 방법을 사용했다.
- 대신, 필자는 하나의 network를 통해 training stage에서 한 번에 task-specific한 supervision을 제공할 수 있는 framework를 제안한다.
- attention map은 또한 어떤 foreground object가 특정한 background object와 반복하여 등장하는 bias를 파악하는 데에도 훌륭한 방법이다.
(예를 들면 학습 데이터에 있는 배의 사진은 강/바다와 등장할 확률이 매우 높으니 바다, 강과 배가 correlate되는 bias가 존재할 것이다.) - train data를 re-balancing하여 dataset의 bias를 제거하려는 노력은 많았지만 본 논문에서는 좋은 attention map을 만드는 과정을 학습하는 방법을 제안한다.
- 본 논문에서 제안하는 self-guided attention model이 extra supervision 없이 모델의 generalization 성능을 개선했다!
- PASCAL VOC에서 성능이 잘 나왔다!
- SOTA를 재꼈다!
2. Related work
- ~~
- 우리의 모델은 dataset bias에 강인하다!
3. Proposed method - GAIN
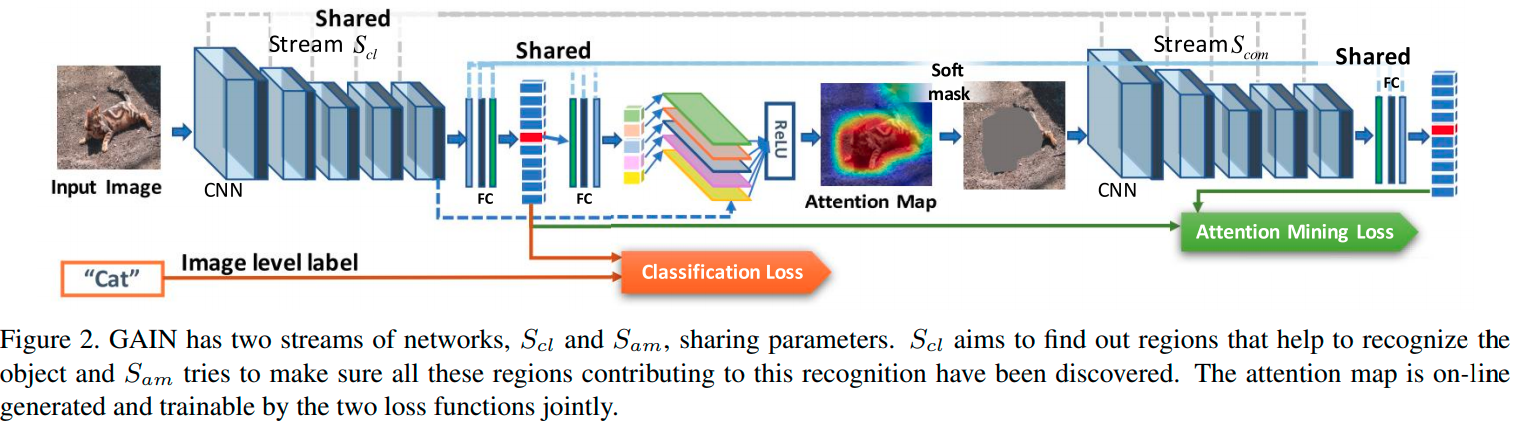
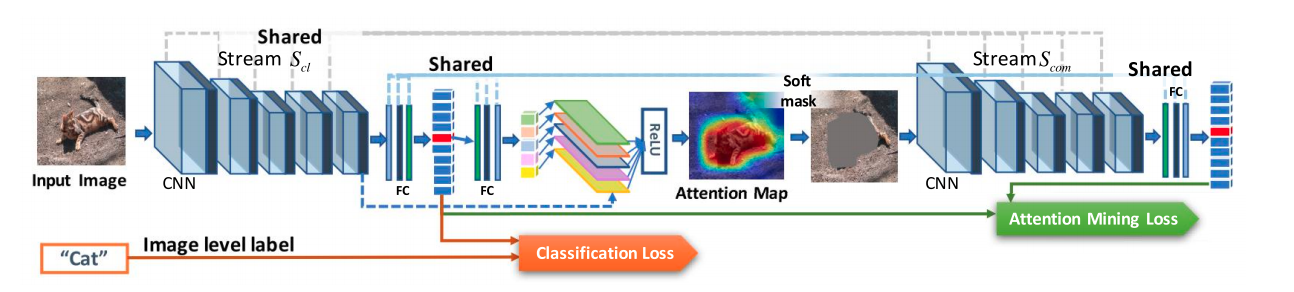
- guided attention inference network (GAIN) 을 제안한다!
- 이 방법을 통해 network의 inference는 network가 초점을 맞출 것으로 기대되는 곳에 근거해 이루어진다.
- 본 논문에서는 기존의 방법에선 사용되지 않은 network의 attention을 학습시킬 수 있게 하여 목적을 달성한다.
3-1. self-guidance on the network attention
- section1에서도 언급되었지만 attention map은 weakly supervised segmentation의 사전 작업으로 사용될 수 있다.
- 하지만 classification loss만으로 supervised된 경우 attention map은 국지적이고 매우 좁은 부분만을 cover하는 경우가 대부분이다. (cover의 의미를 모르겠네.. 덮다? 다루다?)
- 이것도 segmentation의 사전 작업으로 충분히 도움이 되지만, foreground object 전체를 cover한다면 segmentation의 성능을 더 향상시킬 수 있지 않을까!
- 이 issue를 해결하기 위해 우리가 제안하는 모델 GAIN은 regularized bootstraping한 방법으로 attention map으로 부터 loss를 구한다.
- Figure2에서 볼 수 있듯이, GAIN은 classification stream S_cl, attention mining stream S_am 을 가진다.
- S_cl에서 얻어진 loss는 class를 판별하는 영역을 찾는 데에 초점을 맞추고, S_am에서 얻어진 loss는 classification 결정에 기여하는 모든 영역이 network의 attention에 포함되도록 보장하는 데에 초점을 맞춘다.
And the stream S_am is making sure that all regions which can contribute to the classification decision will be included in the network’s attention.
(내가 이해한 바로는 아래와 같다.
고양이 사진이 있고, 고양이 사진에서 attention map을 얻는다고 가정하면!
all regions which contribute to the classification decision : 실제 고양이가 존재하는 모든 pixel
network's attention : network가 고양이를 고양이라 판단하는 데에 초점을 맞춘 영역, attention.
이 둘을 같게끔 학습시킨다.) - 이런 방법을 통해 attention map은 더욱 segmentation task에 특화되고, 완전해진다.
- 여기서 핵심은 필자가 attention map을 만드는 데에 학습 가능한 두 개의 loss function을 jointly하게 사용했다는 점이다.
- Grad-CAM의 근본적인 틀에 기초하여 필자는 attention map의 생성을 간소화시켰다.
- 하나의 input에 대한 attention map이 매 inference마다 생성됨으로써 attention map을 생성하는 network가 training stage에 동시에 학습될 수 있다.
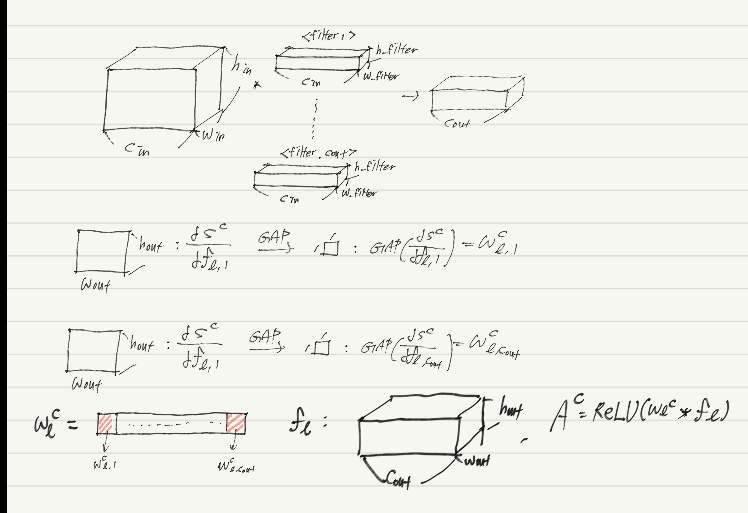
- 위 그림의 과정을 통해 attention map 을 생성한다.
- 위의 과정을 통해 생성된 attention map , masking fucntion T(A)를 통해 soft mask 를 생성한다.
- mask function T(A) :
- soft masked attention map
- 는 threshold에 기초한 masking function이다. 미분 가능하기 위해 이러한 형태의 함수를 사용하였는데, 가 보다 크면 1에 근사하고, 아니면 0에 근사하므로 threshold와 유사한 역할을 수행한다.
- 는 모든 성분이 인 threshold matrix이다.
- 는 class prediction score를 얻기 위해 attention mining stream 의 입력으로 사용된다.
- 본 논문의 목적은 network가 foreground 객체의 모든 부분에 주의를 기울일 수 있게(focus) 하는 것이므로 target class에 해당하는 feature를 가능한 적게 포함되게 하였다. 즉, attention map에서 class c의 객체임을 인지할 수 있는 pixel은 이상적으로 하나도 남지 않아야 한다.
- loss function의 관점에서 class c에 대해 의 prediction score를 최소화 시켜야 한다.
- 이를 달성하기 위해 본 논문에서는 Attention mining Loss를 아래와 같이 설계했다.
3-2. GAIN_ext : integrating extra supervision
- 본 논문에서는 GAIN에 약간의 추가적인 supervision을 제시해 attention map learning process를 조절했다.
- 필자들은 이를 라 부르기로 했다.
- section 4에서 밝히겠지만, 이는 weakly supervised segmentation의 성능을 높였다.
- 또한 필자들은 network가 dataset의 bias에 강인해지도록 를 사용했다.
- 이를 위해 외에 를 도입했다.
- 는 위에서 보였던 attention map, 는 pixel level의 segmentation mask라 할 때, 으로 정의된다.
- pixel-level segmentation을 생성하는 데에는 많은 비용이 들기 때문에 필자는 아주 적은 양의 추가적인 supervision을 이용해 이득을 취하는 데에 관심을 가졌다.
- 실험에선 오직 1% ~ 10%의 data에만 pixel-level label을 도입했는데, 에서는 오직 image-level의 label만을 사용했다.
- 의 최종 loss function은 아래와 같이 정의된다.
- 실험에서는 를 10으로 두었다.
4. Semantic segmentation experiments
- SOTA를 달성했다!
4-1. Dataset and experimental settings
Dataset and evaluation metrics
- 필자들은 해당 성능을 평가하기 위해 PASCAL VOC 2012를 사용했다.
- train/validation/test set에 각각 1464/1449/1456 장을 사용했다.
- augmentation을 통해 10582장의 trainset을 만들었다?-> 모르겠음
- evaluation metric으로는 mIoU를 사용했다.
Implementation details
- ImageNet으로 학습된 VGG를 base network로 사용했다.
- initial lr은 , 2000 iteration마다 0.1배 하여 까지 낮춤.
- optimizer는 SGD를 사용하였고, batch size는 15를 사용함.(16이 낫지 않았을까?)
4-2. Comparision with SOTA
- 좋더라.
- 보다 가 약 3% 정도의 성능 향상을 보였다.
- 2%의 pixel-level label만으로도 더 좋은 attention map을 만들었다.
More Discussion of the
- SEC보다 mIoU에서 10%, 보다는 약 4%의 성능 향상을 보였다.
5. Guided learning with biased data
Boat Experiment
- 앞서 논의된 boat-water bias문제가 있었다.
- 이 문제로 model이 boat를 인지할 수 있는 올바른 패턴/성질을 인식하지 못 하였다.
- 이를 검증하기 위해 필자들은 'Biased Boat' dataset을 만들었다.
- 이 데이터셋에는 물 없는 보트, 보트 없는 물이 있다.
- GRAD-CAM이나 GAIN에서는 물만 있으면 boat로, boat만 있으면 boat가 아닌 걸로 인식하는 경우가 있었다.
- 는 아니었다.
Industrial camera experiment
- 이 실험은 model의 generalization 성능을 검증하기 위해 설계되었다.
- industrial camera의 방향은 아주 작은 부분으로 판단할 수 있는데, 를 학습시킬 때만 클래스마다 5%정도의 데이터에 BB를 함께 주어 학습시켰다.
- 가 GRAD-CAM보다 좋은 성능을 보이더라.
- 에는 dataset bias가 model에 미치는 영향을 줄이고, generalization할 수 있는 잠재력이 있단 결과.
6. Conclusion
- 더 정교하고 완벽한 attention map을 만들어낼 수 있는 model 를 제안해보았다.
- attention map을 학습 후에 만드는 것이 아닌 attention map을 만들도록 학습시켜 목적을 달성할 수 있었다. (기존 CAM, GRAD CAM의 경우 학습시킨 후 activation map만 만들었음)
- 한 번에 classification, attention mining 모두를 학습시켜 시간을 줄일 수 있었다.
- GAIN을 사용함으로서 model의 generality, dataset bias에 대한 강인함을 키우고, localization, segmentation의 개선된 사전작업으로 사용할 수 있게 되었다.
- 나중엔 classification보다 수준 높은 작업이나 regression-task에도 적용할 수 있을 것!
