Data Augmentation for Scene Text Recognition
Introduction
STR 연구는 현재 모델중심적으로 이루어지고 있다. 한정적으로 수집된 데이터 내에서 학습을 진행하게 되면서 distribution shift가 쉽게 일어나게 된다. 이런 distribution shift를 해결하기 위한 방법 중 하나인 data augmentation에 집중하여, 어떤 방식의 augmentation이 효과적일지에 대해서 생각해 본다.
현재 연구들은 이런 augmentation에 대한 정량적 비교가 없이 rotation,perspective,affine transform, gaussian noise, motion blur, resize, padding, distortion등의 방법들을 임의로 조합하여 사용하고 있다.
아직 augmentation에 대한 연구가 없었기 때문에 이런 방식이 효과적인지 또한 다른 augmentation 방법이 존재하는지 연구한다.
+) mixup/cutmix 같은 방식은 text 데이터 특징상 오히려 성능의 저하를 일으킨다.
Proposed method

해당 저자는 이런 현실에 있을 text 데이터들에 대해 먼저 정의해보고 이런 데이터를 만들 수 있는 augmentation을 고안해 본다.
Warp
현실에서는 글자가 휘어진 형태로 존재하는 경우가 많다. 그렇기 때문에 warp라는 그룹 안에 curve,distort,stretch라는 3가지 경우를 고려해 적용한다.
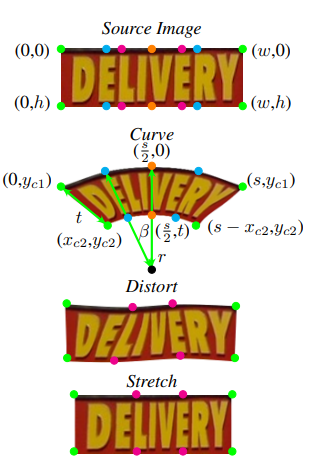
이런 warp는 Thin-Plate-Spline을 이용하여 구현되있다고 한다.
(코드를 뜯어보면 cv2 contrib version에 해당 코드가 구현되어 있다)
Geometry
현실 데이터는 항상 글자가 중심이 맞는다고 생각할 수 없다. 조금씩은 다 삐둘어져있는 경우가 많을 것이다. 그렇기 때문에 geometry라는 그룹을 만들고 perspective,shrink,rotate 라는 element를 추가한다.
Pattern
Regional dropout 방식이 text recognition에서는 예상과 다른 결과를 불러올 수 있기 때문에 이를 대체할 방법으로 grid pattern을 제시한다. grid 처리를 함으로써 최대한 이미지 label에 영향을 안주는 방식으로 pixel을 drop한다.
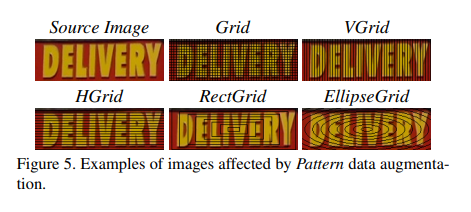
Noise / Blur /weather
현실 데이터에서 noise는 굉장히 흔하다. 그렇기 때문에 여러 종류의 noise를 범주 안에 넣고, 사람이 읽을 수 있을 만큼의 magnitude를 이용하여 noise를 준다. blur,weather또한 마찬가지이다!
Camera
데이터는 모두 카메라로 찍은 데이터기 때문에 카메라의 특성으로 인해 노이즈가 생길 수 있다. 이런 카메라 설정에 대한 augmentation을 생각해보자
1) Contrast: 대비를 통해 글자 이미지를 더 강조할 수 있다.
2) Brightness: 밝기는 직접적으로 사진에 영향을 줄 수 있다.
3) JpegCompression: 사진 자체에 성능이 안좋을 수 있다.
4) Pixelate: 반대로 해상도를 높여서 성능이 좋아질 수 있다.
Process
추가적으로 text에 영향을 안주면서도 일반적으로 자주 쓰이는 augmentation들을 process 그룹에 추가해주었다.1) Posterize, 2) Solarize, 3) Invert, 4) Equalize, 5) AutoContrast, 6) Sharpness and 7) Color
Experiment
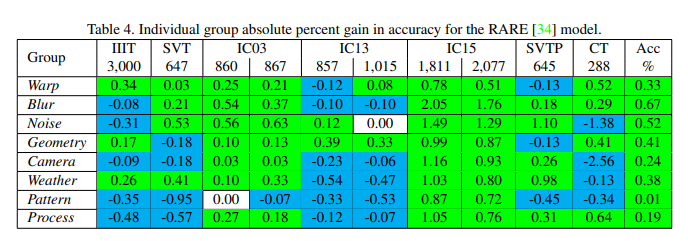
-> individual group performance
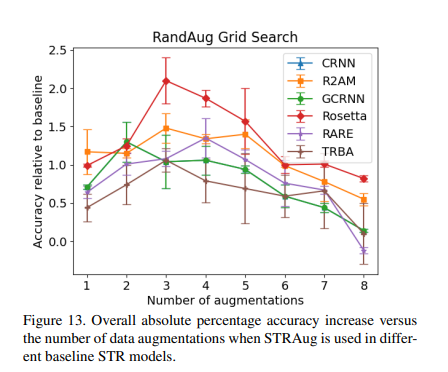
-> multi group performace by random augment
random augment의 n을 2~4로 설정했을 때 성능이 좋음을 알 수 있었다.
