Abstract
일반적으로 우리는 모델의 성능을 끌어 올리기 위해 서로 다른 모델들을 테스트해보고 결과가 좋은 모델들을 선정해 ensemble을 하는 방법을 이용한다.
이 논문은 ensemble 처럼 추가적인 inference나 cost 없이 모델의 parameter를 평균냄으로써 성능이 좋아질 수 있음을 증명한다.
Introduction
최근 연구들은 large/diverse dataset에 대한 pretrained model을 이용한 transfer learning이 기존의 방법보다 좋다고 예기하며, 이를 이용한 fine-tuning이나 large pre-trained model에 대해 연구하는 경향이 있다.
이런 fine tuning 과정은 여러 pretrain 모델에 대해서 test를 한 뒤 제일 성능이 좋은 모델만 남기고 나머지 모델은 버리게 된다(ensemble을 해도 되지만 현실에서는 추가적인 inference cost가 발생해 이용할 수 없다)
이 논문에서는 이런 단점을 해결하면서도 더욱 robust/accurate model을 만들기 위해서 model weight들을 average 하는 model soup이라는 방법을 제안한다.
-> no additional training / no additional inference
그리고 이렇게 model을 average하는 시도를 할 수 있었던 것은 What is being transferred in transfer learning? 이라는 논문에서 같은 pretrained로 initialize한 모델들은 비슷한 loss landscape를 갖고있음을 증명했기 때문이다.
추가적으로 No One Representation to Rule Them All: Overlapping Features of Training Methods 해당 논문에서 서로다른 파라미터로 학습한 모델의 ensemble이 성능을 향상시킴을 말한 논문도 참고한다.
직관적으로 생각했을 때는 모든 모델을 한번에 uniform하게 average 하는 방법이 생각나지만 이 논문에서는 순차적으로 평균을 내는 greedy soup 방식을 제안하고 이 방법이 서로 다른 loss landscape를 가지는 error를 피할 수 있다고 말한다.
Method
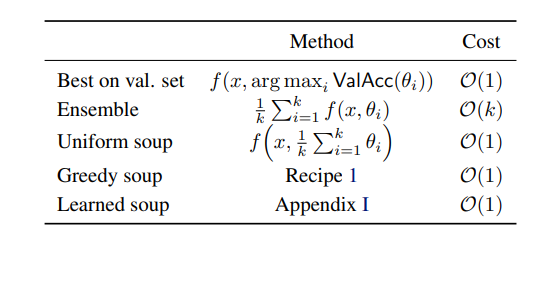
여기서 hyper parameter configuration은 optimizer,data augmentation, training iteration, random seed등을 포괄적으로 뜻한다.
uniform하게 average 했을 때 오히려 accuracy가 감소하는 문제가 생겼는데, 이를 다음과 같이 해결한다
1. validation set에 대한 acc에 대해 내림차순으로 정렬한다
2. 연속된 모델을 하나씩 model soup 했을 때 성능이 낮아지는 모델은 버린다
Error landscape visualizations
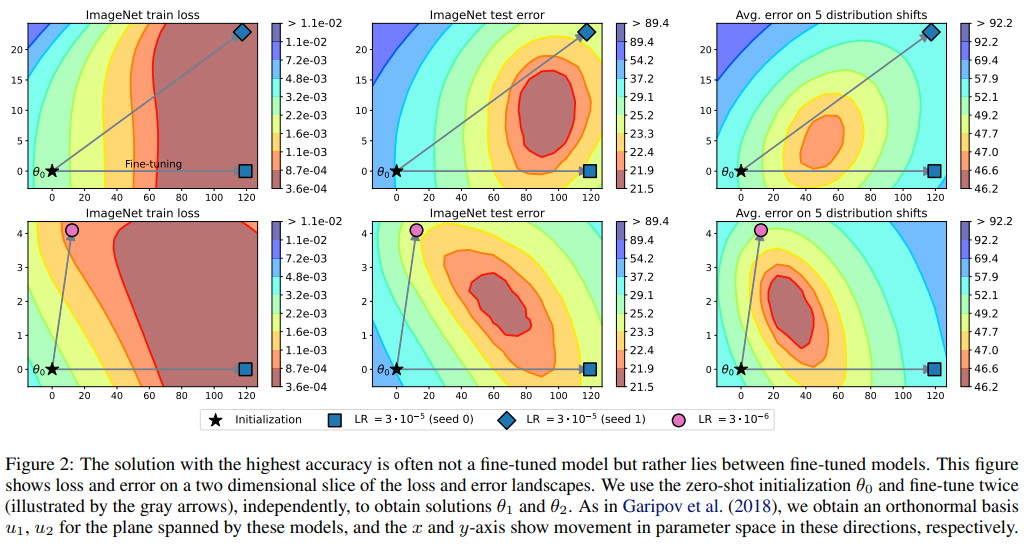
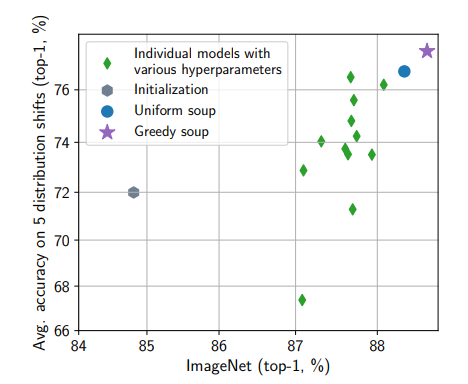
model soup accuracy-ensemble accuracy를 평가 지표로 활용 했을 때 위 사진과 같이 다양한 hyper parameter에 대해서 성능 향상을 관찰 할 수 있었다.
