ResNet은 다음 세 가지 특징을 갖는다.
- skip connection을 사용한다.
- skip connection을 사용하면서 모델의 깊이가 깊어졌다.
- 이 논문내의 실험의 결과로 어느 한 layer를 지워도 성능면에서 차이가 크지 않다
(기존의 VGG나 AlexNet은 성능 차이가 심하다)
이 논문은 실험적으로 이런 현상들을 설명해본다.
- ResNet은 하나의 네트워크가 아닌 여러 path의 집합으로 볼 수 있다.(unraveled view)
- path들이 서로 독립적인지 의존적인지 실험해본다.(lesion study)
- ResNet은 지금까지의 network들과 다르게 path의 길이가 서로 다르다.
- ResNet에서 effective path는 10~34 정도 거리에 존재한다.
결론적으로 이 논문은 ResNet에서 skip connection이 gradient vanishing 문제를 근본적으로 해결하는 것이 아니라 effective layer까지의 path를 shorten함으로써 deep network를 가능하게 함을 말한다.
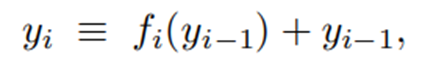
- 이 식은 skip connection의 기본이 되는 식이다.
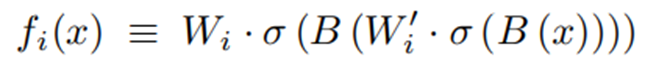
- f(x)의 결과물은 convolution , batch norm , relu 의 결과물이다.
Unraveld view
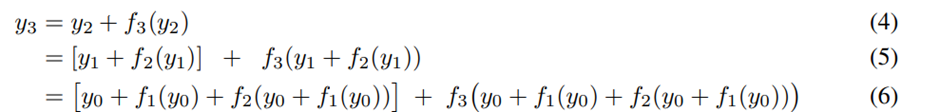
- Residual network에서 third layer 까지의 식을 unraveled view에서 바라본 식이다.
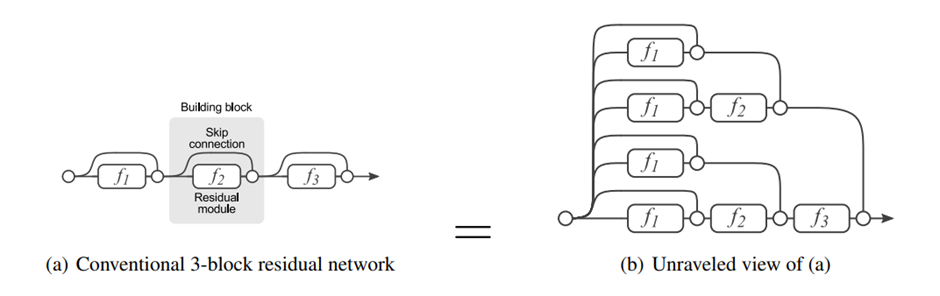
- unraveled view로 해석한 resnet과 기존 네트워크의 차이이다.
위 그림에서 각각의 unique path는 binary code인 B={0,1}로 나타낼 수 있는데,
residual module f가 skip되면 0 그렇지 않다면 1로 표현 할 수 있다.
-> 그렇다면 residual network는 총 2의 n승개의 path를 지닌다.
기존의 네트워크가 이전 layer의 output에 의존적인 것과 달리 ResNet은 이런 inherent structure를 갖고있다는 점에서 기존 네트워크와 다르다.
i번째 residual module은 이전 i-1개의 layer에서 만들어진 개의 path에 영향을 받게 된다.
위 그림에서 알 수 있듯이 feed-forward network에서 path의 길이는 모두 일정하지만 ResNet은 모두 다르다 즉 ResNet에서 각각의 output은 서로 다른 이전까지의 layer의 subset의 집합이 된다.
이 논문의 다음 질문으로는, ResNet에서 path들은 그렇다면 서로 의존적인가? 그렇다면 path들이 ensemble처럼 동작하는가? 에 대한 질문이다.
Lesion study(손상 연구)
실험은 완전히 학습된 ResNet에서 (skip connection or downsampling projection)을 제외한 block을 제거시키고 test해보는 방식으로 진행되었다.
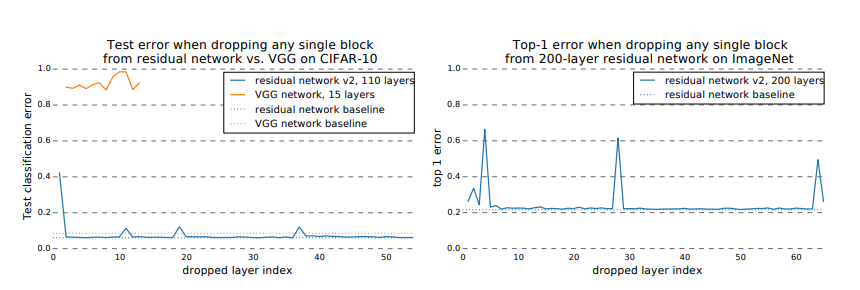
위 실험 결과로 vgg같은 경우는 layer의 손실이 극적인 error의 증가로 이어졌지만 resnet의 경우에는 downsampling layer를 제외하고는 큰 변화가 없었다.
이 현상에 대해 논문에서는 이렇게 해석한다.
VGG 같은 경우에 layer사이의 path가 unique 하기 때문에 하나의 layer를 지운다해도 큰 차이가 생길것이다.
ResNet에서 layer를 하나 지운다는 것은, unraveled view에서 봤을 때 가능한 path를 절반으로 줄인다는 것이다. 그럼에도 결과의 차이가 크지 않다는것은, path들이 서로 independent 하다는 뜻이다.
위에서 보았듯이 path들이 서로 독립적이라면 ensemble처럼 동작하는 것일까?
ensemble의 특징은 model의 output이 ensemble하는 model의 개수에 대해 'smooth'하게 dependent 한다는 것이다.
즉 ResNet이 ensemble처럼 동작한다면, valid path의 number에 대해 smooth dependent 해야한다.
이를 증명하기 위해 논문에서는 layer를 하나씩 지워보면서 error의 증가율을 관찰했다.
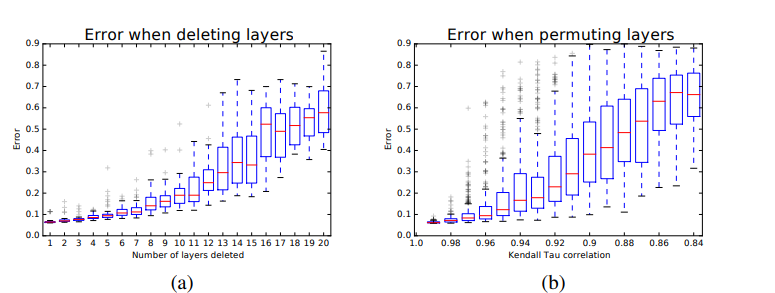
실제로 실험에서 error은 smooth하게 증가하였고, residual network가 ensemble 처럼 동작한다고 말한다.
추가적으로 오른쪽 그래프는 임의로 resnet의 layer을 shuffle한 경과를 관측 한 것인데,layer을 섞는다는 것은 기존의 path를 제거하고 새로운 path를 만든다는 뜻이다.
PATH의 특징
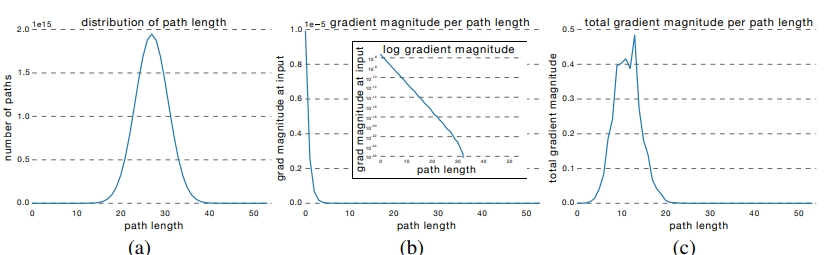
-(a) 그래프를 보면 path의 len은 mean이 n/2인 bionomial distribution을 따른다.(skip or not skip 두가지 경우만 존재하기 때문에)
-(b) 그래프는 특정 길이의 path를 sampling하여 input 까지 미치는 gradient가 어느정도인지 측정한 것이고, 굉장히 expotental하게 감소하는것을 알 수 있다.
-(c) 그래프는 a와 b를 곱해서 어느 길이의 path가 gradient에 영향을 미치는지 분석한 결과이다.
즉 gradient의 update는 그 입력값으로 부터 5~17정도 떨이진 path에 의해서 바뀌는데 이런 path를 effective path로 부른다. 이런 effecitve path는 전체 path의 약 0.45%에 불과하며, 상대적으로 shallow한 위치에 존재한다.
이 논문에서 effective path로만 훈련시키는 model을 시험해보았을 때 effective path의 error가 5.96% full training한 model이 6.10%의 error을 보였다고 한다.
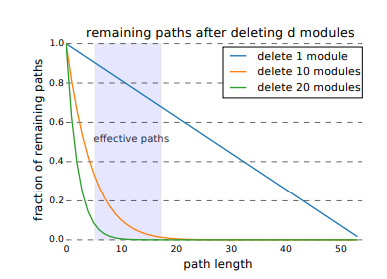
- ResNet내에서 layer를 몇 개 지우는 실험을 한 결과이다.
즉 layer를 지웠을 때 주로 long-path에 영향을 준다. 실험에서 layer를 10개까지 지웠을 때 까지는 error가 크게 증가하지 않았지만 effective path가 거의 다 죽은 20개의 layer를 지웠을 때는 error가 크게 증가하였다고 한다.
