AutoML이란?
시간 소모적이고 반복적인 기계 학습 모델 개발 작업을 자동화하는 프로세스이다.
AutoML의 발전에 따라 NAS(neural architecture search)같은 모델링에서 AutoML을 적용하는 등 여러 형태의 AutoML이 등장하고 있는데 이런 내용을 data augmentation에서 적용한 논문을 소개한다.
AutoAugment:Learning Augmentation Strategies from Data
RandAugment: Practical automated data augmentation with a reduced search space
AutoAug
Data augmentation은 지금까지 특정 데이터에 특화적으로 발전해왔다.
예를들어 horizontal flipping은 Cifar10에서 효과적일지 몰라도 MNIST 데이터셋에서는 역효과를 낳는다.
이 논문에서는 강화학습을 search algorithm으로 사용하여 data augmentation의 조합을 자동으로 찾아주는 방법을 제시한다.
논문에서는 autoaug의 장점을 다음과 같이 말한다.
1) AutoAugment can be applied directly on the dataset of interest
to find the best augmentation policy (AutoAugment-direct)
2) learned policies can be transferred to new datasets
(AutoAugment-transfer)
AutoAug에는 두가지 개념이 필요하다 (search space,search algorithm)
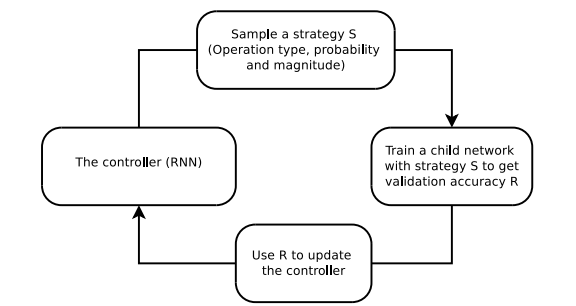
search alogorithm은 (rnn controller을 활용하여) data augmentation policy s를 sampling 한다.(어떤 operation을 사용할지, 그 operation을 사용할 확률, 정도 등에대한 정보가 담겨있다.)
test-algorithm: TranslateX/Y,Rotate,AutoContrast,Invert,Equalize,Solarize,Posterize,Contrast,Color,Brightness,Shaprness,Cutout,Sample Pairing
1. search space
하나의 policy는 5개의 sub-policy로 구성되는데, sub-policy는 두 개의 순차적으로 적용되는 operation이 들어있다. 이 operation에는 또 두개의 hyper-parameter가 필요한데 적용 확률과 적용 정도이다.
각 probability 와 magnitude 는 값을 10,11개로 나누어서 진행하였다.
-> subpolicy_search_space_size=
여기서 5개의 sub-policy를 찾는 것이 목적임으로->
->cost가 굉장히 높기 때문에 실용적이지 못하다.
2.search algorithm
search algorithm은 Proximal Policy Optimization 강화학습 알고리즘을 사용하는 RNN Controller을 사용한다.
Training Rnn controller
controller는 child model의 generalization의 정도에 따른 reward signal에 의해 학습되고 child model은 5-sub_policy중 하나가 mini-batch 마다 확률적으로 적용된다. 그 후 validation set으로 accuracy를 구한 후 그 값을 reward signal로 사용한다.
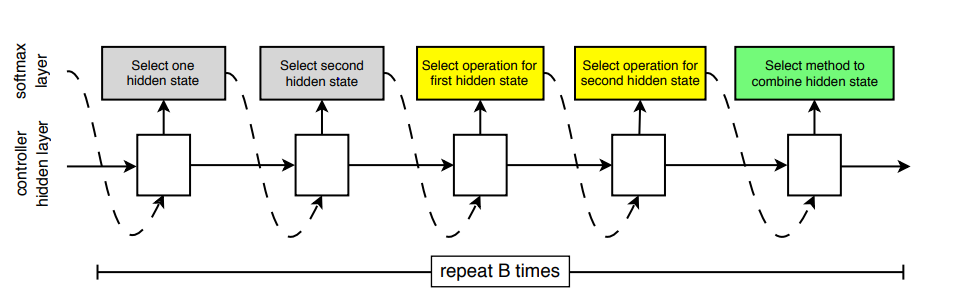
hyper parameter을 학습 하는 방식은 Learning Transferable Architectures for Scalable Image Recognition 에서 소개된 위와 같은 방식을 사용한다.
Augment transfer test
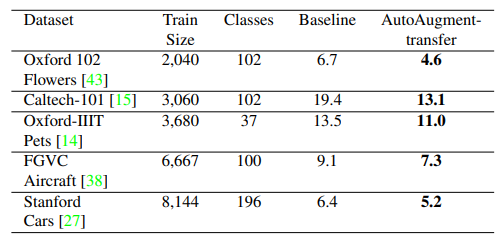
이런 autoaug 과정은 cost가 굉장히 높다. 그렇기 때문에 학습된 autoaug가 다른 데이터셋에도 적용 될 수 있는지 실험해 본 것이다. 만약에 다른 데이터셋에서도 효과적이라면, autoaug가 transferable 하면서도 overfitting 되지 않았음을 말하는 것이다.
-결론적으로 이 논문에서 중요한점은
Data augmentation 기법의 전이가 가능함을 보인 것이다.
Random Aug
방대한 양의 data set에서 autoaug를 적용한다는 것은 거의 불가능 한다.
그렇다면 두 과정을 거쳐야 하는데,
1. 데이터셋을 작은 데이터 셋으로 나눈다. (proxy task)
2. 작은 데이터셋에서 학습된 auto aug를 전체 데이터셋에서도 효과적인지 확인한다.
proxy task는 computing resource 측면에서 굉장히 비효율적이고 그 결과도 sub-optimal 하기 때문에 본 논문은 이 과정을 제거하는 목적을 가진다.
->이를 위해선 parameter의 수를 줄여야 한다.
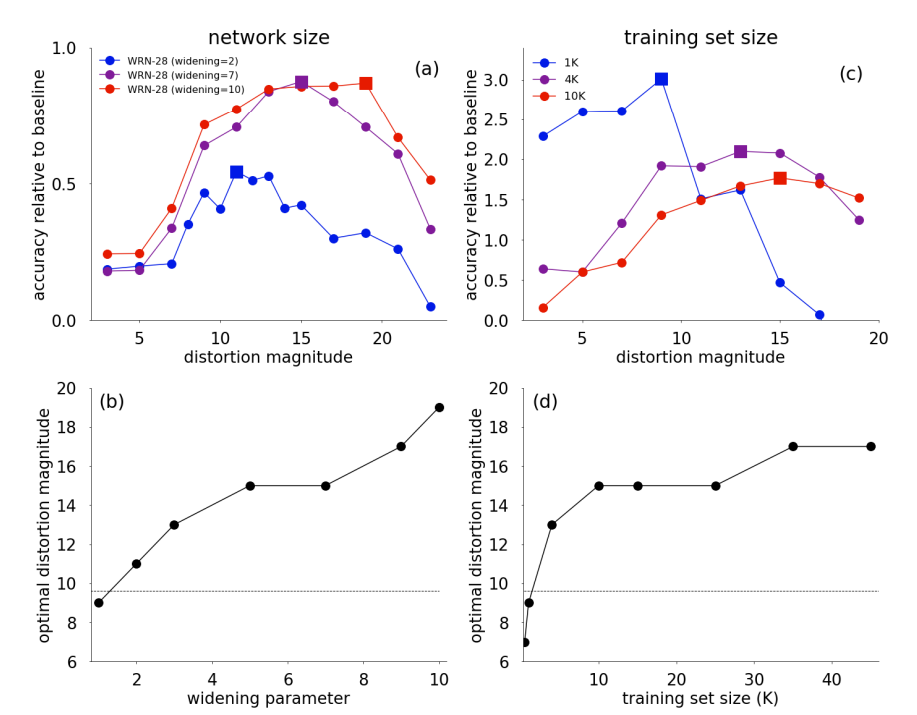
그림과 같이 data set의 크기에 따라 parameter의 효율성이 변하기 때문에 proxy task에 대한 결과가 항상 optimal 할 수 없음을 보여준다.
parameter의 수를 줄이기 위해 다음과 같은 방식을 사용한다.
1.모든 data augmentation의 적용 확률을 로 고정한다.
2.훈련 과정에서 적용할 transformation의 개수 N을 두고 N을 조절하는 방식으로 진행된다.
-> policy개수가 으로 auto aug보다 굉장히 작음을 알 수 있다.
이제 data augmentation의 magnitude를 정해야 한다.
논문은 scale 값을 0~10으로 두고 시험을 했다.

m에 따라 0.1정도의 정확도 차이가 남을 알 수 있다.
parameter n, m은 이제 bayesian optimization등의 hyper parameter tuning 방식을 적용하여 구하면 된다.
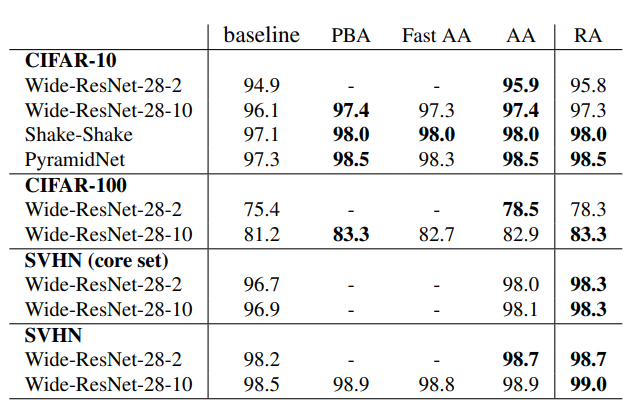
결과적으로 autoaug와 큰 차이가 없을을 알 수 있다
