Introduction
기존 딥러닝의 단점은 label된 데이터가 굉장히 많이 필요하다는 점이다. Semi-supervised learning(SSL)은 이런 단점을 해결하기 위한 가장 유망한 방법중 하나이다. 최근 SSL의 연구는 consistency training에 중점을 두었다.
consistency training은 model prediction을 정규화 하여 작은 노이즈에도 prediction이 불변성을 갖도록 만드는 것이다.
이 논문에서는 consistency training 에서의 noise injection의 역할을 알아내고, 좀더 발전된 data augmentation 방법들을 찾아본다.
Unsupervised Data Augmentation(UDA)
notation
supervised data augmentation
지도학습에서 data augmentation은 원본 데이터로부터 변형을해 새로운 진짜 같은 훈련 데이터를 만드는 것이다.
이 분포에서 sampling된 값 는 원래 분포와 똑같은 ground-truth label x를 가져야 한다.
이렇게 구성된 data augmentation은 model에 추가적이고 더 효율적인 inductive bias를 제공해야함으로 data aug를 어떻게 구성할지가 굉장히 중요하다.
concepts
기존의 SSL은 다음과 같은 방식을 따른다
1) input data x가 주어졌을 때 output distribution 와 noised version 을 계산하다.
2) 두 분포 사의의 divergence metrics 을 최소화 한다.
이런 과정은 noise에 둔감해지게 한다. 다른 관점에서 보면, consistency loss를 minimize 한다는 뜻은 ,label 정보를 labeled data로부터 unlabeled data로 전달해준다는 뜻이다.
이 논문에서는 input x에 inject되는 noise에 관심이 있고, 특히 어떻게 noising operation의 퀄리티가 consistency training에 영향을 미치는지에 관심이 있다.
이전 논문들은 단순히 gaussian noise나 간단한 augmentation을 사용하였는데, 이와 다르게 더 강력한 augmentation을 사용하여도 지도학습처럼 좋은 효과가 있을 것이라고 가정한다
그리고 labeled 와 unlabveled data간의 균형을 맞추기 위해 weight factor 를 사용한다
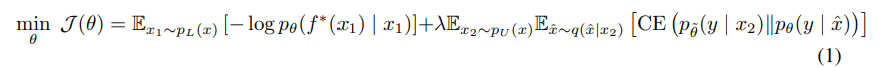
1) labeled data에 대한 loss 를 구한다
2) unlabeled data로 부터 consistency loss를 구한다
3) 두 loss를 더해 final loss를 구한다.
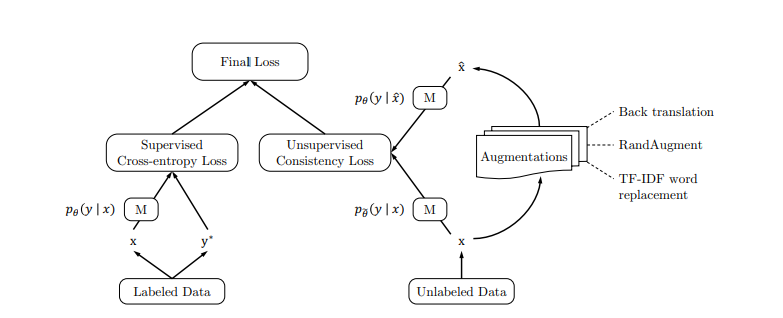
- data augmentation으로 rand aug를 사용한다(vision task)
additional training techniques
confidence-based masking
parameter 보다 더 작은 확률 값을 가지는 데이터는 무시한다.
sharpening predictions
prediction 값을 낮은 엔트로피 값을 갖도록 정규화 하는것이 득이 된다는것이 연구들로 증명되고 있기 때문에 이 논문에서는 unlabeled data 분포를 계산할 때 low softmax temparature 를 사용하여 sharpen 한다.
이 방법론이 confidence-based masking에 결합된다면 다음과 같다. (gamma=0.4로 설정했다.)
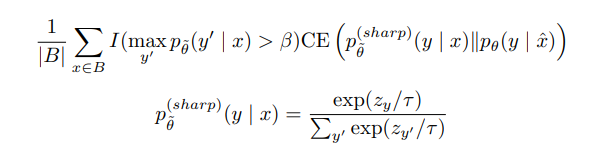
Domain-relevance Data Filtering
unlabeled dataset의 out of damain data는 in domain data와 match되지 않기 때문에 성능에 손실이 생길 수 있다. 이 논문에서는 이런 값들을 걸러내기 위해 trained base model을 사용하였다.
Theoretical Analysis
simplistic assumption:

1) in-domain: data augmentation으로 생성된 data는 0이 아닌 확률값을 가지고 있다.
2) label-preserving: 원래 값 x와 augmented value x는 perfect classifier에 대하여 같은 결과값을 갖는다.

