
지난 포스팅에서는 Kafka Cluster의 불균형의 유형은 아래와 같이 나눌 수 있으며,
1. 리더 분포의 불균형 ( leader Skew ) - leader partition이 각 브로커 마다 골고루 분포되지 않은 상태
2. 브로커 불균형 ( Broker skew ) - 각 브로커 별 파티션 개수, message in/out, bytes in/out, throughput 등이 균형있게 분포되지 않은 상태
이 중, 주로 리더 분포의 불균형(leader Skew) 에 대한 상세 내용과 해결 방법에 대해 알아보았습니다.
이번 포스팅에서는 브로커 불균형 ( Broker Skew )에 대한 상세 내용과 해결방법에 대해 알아보도록 하겠습니다.
2. 브로커 불균형(Broker Skew) 상세 / 해결법
브로커 불균형은 앞서 설명한 리더 불균형을 포함하는 조금 더 복합적인 개념입니다. 브로커 당 프로세서/쓰레드 사용량, disk 사용률, 네트워크 throughput을 시작으로 replication factor 및 replica의 배치,rack 설정/배치, 로드 분산, 리더십, topic 및 partition에 대한 메트릭 등 여러 복합적인 요소를 고려해야할 수 있습니다.
Kafka-Manager 에서 카프카 클러스터를 운영한다면 토픽 상세 페이지 내 Broker Skew 여부를 확인할 수 있습니다. 다만 이는 단순히 특정 토픽의 브로커별 파티션 개수의 불균형을 체크 할 뿐, 이외의 요소는 고려하지 않습니다.
아래 예시는 특정 토픽의 파티션들이 불균형하게 분포되어 있는 상황입니다.(그림 출처 : https://hashedin.com/blog/re-balance-your-kafka/)
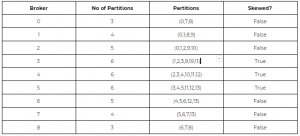
어떤 토픽에 대하여 특정 브로커의 파티션 수가 평균(토픽 전체 파티션 수÷브로커 수) 보다 클 때, kafka-manager에서는 브로커가 편향되었다. 또는 불균형하다(Broker Skew) 라고 표현합니다.
위 표에서는 3,4,5번 브로커 당 파티션 수가 불균형한 상태입니다.
브로커 당 파티션 수 불균형 및 디스크 사용율, 리더 수 등은 상태 값을 바로 알 수 있지만
프로세서/쓰레드 사용량, 네트워크 throughput, 로드 분산, 브로커 별 request 수 등은 일정 기간의 통계 데이터 분석을 통해 불균형 여부를 판단할 수 있습니다.
해결법 1. Plan을 토대로 reassignment 툴 사용
가장 기본적인 해결법은 수집된 메트릭 데이터를 기반으로 전체 Kafka Cluster 내 Broker 간 균형을 맞추기 위한 Plan을 세운 후 카프카 토픽 Reassignment tool을 사용하여 파티션을 재배치시키는 것입니다. 해결 순서는 다음과 같습니다.
- 위에서 설명한 Broker 불균형 요인들을 고려하여 Plan을 세운 후 reassignment 용 json 파일을 생성합니다.
# reassign-partition.json
{"version":1,
"partitions":[
{"topic":"sh-test-topic-1",
"partition":0,
"replicas":[5,2,3],
"log_dirs":["any","any","any"]
},
{"topic":"sh-test-topic-1",
"partition":1,
"replicas":[2,4,1],
"log_dirs":["any","any","any"]
},
{"topic":"sh-test-topic-1",
"partition":2,
"replicas":[3,4,1],
"log_dirs":["any","any","any"]
}
]
}- kafka-reassign-partition.sh를 실행시킵니다.
kafka/bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --reassignment-json-file reassign-partition.json --executereassignment의 진행상황은 아래 명령어를 통해 확인할 수 있습니다.
kafka/bin/kafka-reassign-partitions.sh --bootstrap-server BROKER:9092 --reassignment-json-file reassign-partition.json --verify
Status of partition reassignment:
Reassignment of partition sh-test-topic-1-0 is complete.
Reassignment of partition sh-test-topic-1-1 is complete.
Reassignment of partition sh-test-topic-1-2 is complete.- kafka-reassign-partition.sh 실행 완료 후 앞선 포스팅에서 설명한 kafka-leader-election.sh를 실행시켜 브로커 별 리더 분포 균형을 맞춰줍니다.
$ bin/kafka-leader-election.sh --bootstrap-server BROKER:9092 --election-type preferred --path-to-json-file sample.json
# sample.json
{
"version" : 1,
"partitions" :[
{"topic":"sh-test-topic-1", "partition":0},
{"topic":"sh-test-topic-1", "partition":1},
{"topic":"sh-test-topic-1", "partition":2}
]
}kafka-reassign-partition.sh 툴 내 --genterate 옵션을 사용하여 현재 partition 별 replica 구성과 reassignment 툴에서 제안하는 replica 할당 구성을 보여줍니다만, 브로커 별 Partition 수 균형 등 가장 기본적인 요소들만을 고려하기 때문에 원하는 결과를 얻지 못할 수 있습니다.

해결법 2. 오픈소스 / 상용 제품 사용을 통한 브로커 리밸런스
카프카 클러스터 운영 간 브로커 불균형을 감지하고 맞춰주는 도구가 몇가지가 있습니다만,
오늘은 크게 linkedin 사의 CruiseControl (오픈소스) 와 Confluent 사의 Controlcenter(상용제품) 내 Self-balancing clusters 기능을 소개해볼까 합니다.
2.1. Cruise Control
Cruise Control은 큰규모의 Kafka Cluster에 대한 운영 관리를 단순화해 주는 오픈소스 도구입니다. 기본적인 클러스터 상태의 모니터링은 물론, 이상징후 감지, 알람, 카프카 클러스터에 대한 self healing도 지원합니다.
특히 Kafka 클러스터를 운영하는 입장에서 중요한 목표(goal)을 설정하여 리밸런스 전략을 세울수 있습니다.
위에서 설명한 주요 goal은 아래와 같습니다.
- 랙 인식을 통한 파티션 분산 관리 (Rack-awareness)
- 시스템 자원 사용 안정성 (Resource capacity violation checks (CPU, DISK, Network I/O))
- 브로커 별 replica 수 안정성 (Per-broker replica count violation check)
- 브로커 별 균형있는 시스템 자원 사용률 (Resource utilization balance (CPU, DISK, Network I/O))
- 브로커 별 리더 partition을 향한 트래픽 분산 (Leader traffic distribution)
- 토픽 가용성을 위한 replica 분산 배치 (Replica distribution for topics)
- 브로커 별 replica 수 분산 배치 (Global replica distribution)
- 브로커 별 leader replica 분산 배치 ( Global leader replica distribution )
- 사용자 정의 목표 (Custom goals that you wrote and plugged in)
Cruise Control에 대한 보다 상세한 내용은 아래 github page에서 확인하실 수 있습니다.
https://github.com/linkedin/cruise-control
2.2. Self-balancing clusters
Self-balancing clusters(SBC) 기능은 Confluent 사의 상용 제품인 Controlcenter 내 내장되어 있는 기능입니다.
Confluent 플랫폼 내 내부토픽을 통해 브로커들의 메트릭을 수집/분석을 하며 내부 알고리즘을 통해 클러스터의 불균형 상태를 감지하고 자동으로 리밸런싱을 수행할 수 있습니다.
문서상으로는 self-balancing clusters 기능도 cruise Control을 활용하는 것으로 보이며 차이점은 Cruise Control은 Kafka와 별도로 관리해야 하지만, self-balancing은 브로커에 내장되어있어 관리 point가 줄어든다는 이점이 있습니다.
Self-balancing clusters에 대한 보다 상세한 내용은 아래 페이지에서 확인하실 수 있습니다.
https://docs.confluent.io/platform/current/kafka/sbc/
Reference :
https://kafka.apache.org/documentation/
https://hashedin.com/blog/re-balance-your-kafka/
https://sleeplessbeastie.eu/2022/01/05/how-to-reassign-kafka-topic-partitions-and-replicas/
https://www.slideshare.net/JiangjieQin/introduction-to-kafka-cruise-control-68180931
https://github.com/linkedin/cruise-control
https://docs.confluent.io/platform/current/kafka/sbc/
