
노란색 글씨가 있으니 검은색 배경에서 보시는 걸 추천드립니다
0. 결론
혼자서 삽질한 내용이라 쿼리나 코드를 직접 올리지는 않습니다. 궁금하신 부분은 댓글 달아주세요
실제로 서비스를 위해 관련 기능을 구현하기 위해서는 Elastic Search 기술스택을 배워서 적극적으로 활용하시는 것을 권장드립니다.
1. 서론
캡스톤 종합설계를 수행하였고, 주제는 다음과 같았습니다.
자신이 소유하고 있는 가전제품이 가지는 '상대적' 에너지효율을 산정하여 새로운 등급을 매겨서 보여주는 것이었습니다.
단순하게 생각하면, 테이블에 등록할 때 등급을 같이 저장하면 될 것 같았습니다.
근데 모든 기기를 기준으로 상대적인 등급을 추천하면 의미없는 값일 수도 있습니다. 그 까닭은,
1. 소득 수준에 따른 가전제품 격차
2. 산업용 제품들에 대한 배제가 불가함
이기 때문입니다.
이에 대해 해결방법으로, 자신의 근처의 이용자들과 비교하기로
생활권과 소득수준은 어느정도 비례하기 때문입니다.

(굳이 논문까지 보여줘야하나 싶긴 하지만...ㅎㅎ;;)
결론 : 모든 사용자의 위치 정보가 저장되어 있는 데이터베이스로부터, 내 근처 100명이 소유한 전자제품 정보를 추출하고자 하는 쿼리문을 작성하자
Naive하게 떠올릴 수 있는 쿼리 알고리즘
1. 모든 데이터셋과 자신의 거리를 계산함
2. 이에 대한 거리로 ASC로 정렬
3. 정렬한 데이터 중 100개를 추출하여 가져오기
PostgreSQL에서 50만개의 데이터 기준으로 실행해보니 쿼리호출에만 2300ms 정도의 시간이 걸렸는데, 자주쓰는 쿼리기 때문에 시간을 줄여야만 합니다.
2-1. 첫번째 시행착오 (POSTGIS)
PostgreSQL에 데이터베이스를 저장하는 데에 있어, 이용자의 위치정보를 저장하기 위한 외부 라이브러리로 대표적인 POSTGIS가 존재해서 이를 사용해보았습니다.
POSTGIS에는 자체적으로 거리를 측정해주는 라이브러리가 존재하는데, 처음에는 이렇게 측정하는 것에 대해 실행시간을 줄여주지 않을까...하고 생각했습니다.
하지만, POSTGIS가 지원하는 역할은 좌표 간 거리 계산에 대해 지구의 곡률에 대한 보정역할이었습니다.
즉, 시간을 줄이는데에는 큰 도움을 주지 않는 기능입니다.
오히려 한국이라는 좌표 범위 안에서만 사용할 것이면 곡률보정이 필요없기 때문에, 보정함수 없이 직접 피타고라스 법칙으로 구현한 것보다 시간이 더 소요될 것입니다.
1. 피타고라스 원리로 한 경우 : 2244.115ms
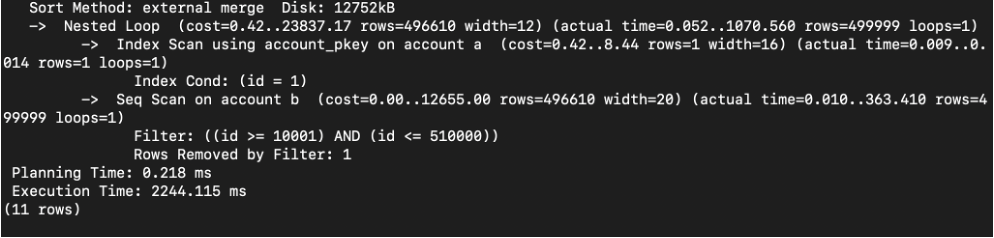
2. POSTGIS 원리로 한 경우 : 2516.424ms
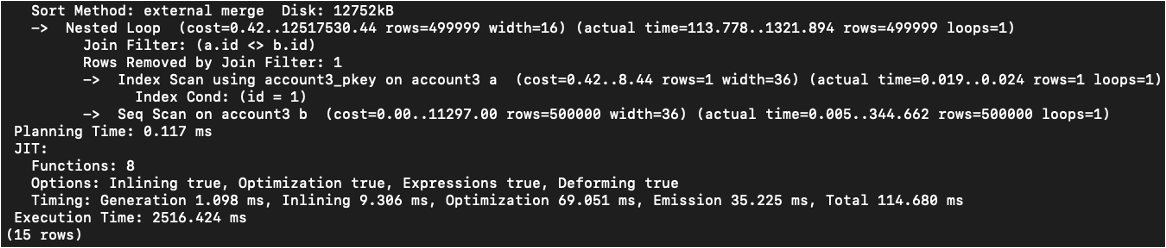
2024.01.25. 추가:
해당 자료형에 대해서 indexing과 관련기능을 지원하는 바 있습니다.
제가 작성한 다음 글을 참고하시길 바랍니다.
2-2. 두번째 시행착오 (calculation overhead)
가장 큰 삽질입니다. 건너뛰시길 추천드립니다.
해당 쿼리를 수행하는 과정은 결과적으로 연산이 발생하기 때문에, 학부연구생과정과 컴퓨터구조론 수업시간에 배운 부분을 응용해보기로 하였습니다.
- 부동소수점 연산 overhead 줄이기
HLS를 비롯한 특정 플랫폼에서는 부동소수점에 대한 연산과, 정수타입 연산을 수행하는 것에 실행시간에 크게 차이가 날 수 있습니다. 하지만 postgreSQL은 그러한 플랫폼이 아닐 것이라 생각하여서 의미 없는 시도라 예측하였습니다.
- 연산숫자 길이에 따른 overhead
한국 좌표의 길이를 저장하는 것에 있어 전체 좌표 범위에서 한국의 좌표 범위가 차지하는 부분이 상당히 작은 영역이기 때문에, 좌표 연산에 사용되는 좌표의 공통 부분을 제거하여, 숫자길이를 줄이면 아주 조금은 시간을 줄일 수 있을 것이라 예측하였습니다.
- 루트연산 따른 overhead
거리를 구하는 방식은 제곱의 합의 루트인데, mapping table같은 방식을 사용하지 않는 이상 해당 연산은 굉장히 큰 overhead일 수도 있겠다는 생각을 했고, 어차피 거리순 정렬만을 위한 것이라면 루트 연산을 제거해도 될 것이라고 생각하였습니다.
결론
부동소수점 2216ms

연산숫자 길이 2290ms
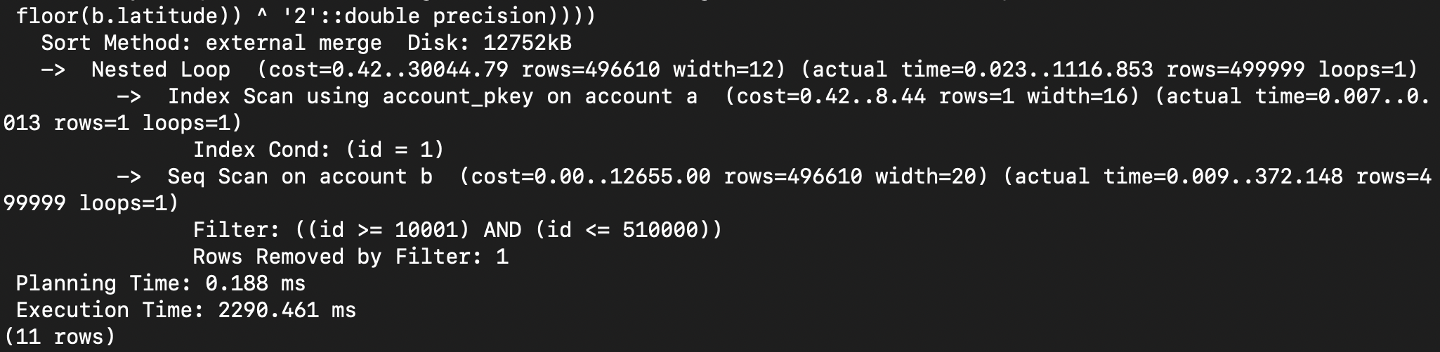
루트 연산 2314ms

여러번 측정하고 가장 평균에 가까운 사진을 첨부하였습니다.
결과적으로는 거의 의미없는 성능향상을 보여주었습니다.
2-3. 세번째 시행착오 (탐색범위제한 자동확장 쿼리)
검색범위가 50만개인 이상 결국 시간은 계속해서 문제가 될 것이라는 결론에 다달았습니다.
(사실, 이 부근에서 Elastic search 같은 기술스택을 활용하는게 떠올랐지만, 구현으로 해결해보고자 하였음)
검색범위를 줄이면 쿼리 실행시간이 줄어들 것은 너무나도 자명한 사실입니다.
-
검색범위 500,000개

-
검색범위 10만개

-
검색범위 1만개

그렇다면 검색범위를 줄이기 위해서 어떻게 해야할 지를 고민해봐야 합니다.
제 생각에는 검색범위를 자신이 속한 좌표 범위를 기준으로 제한하여 가까운 유저들의 정보로부터 쿼리문을 추출하는 것이 옳아보입니다.
이는 데이터베이스에서 정보를 추출하는 쿼리에서 latitude 컬럼과 longitude 컬럼에 대해서 WHERE문으로 범위를 제한한다는 의미입니다.
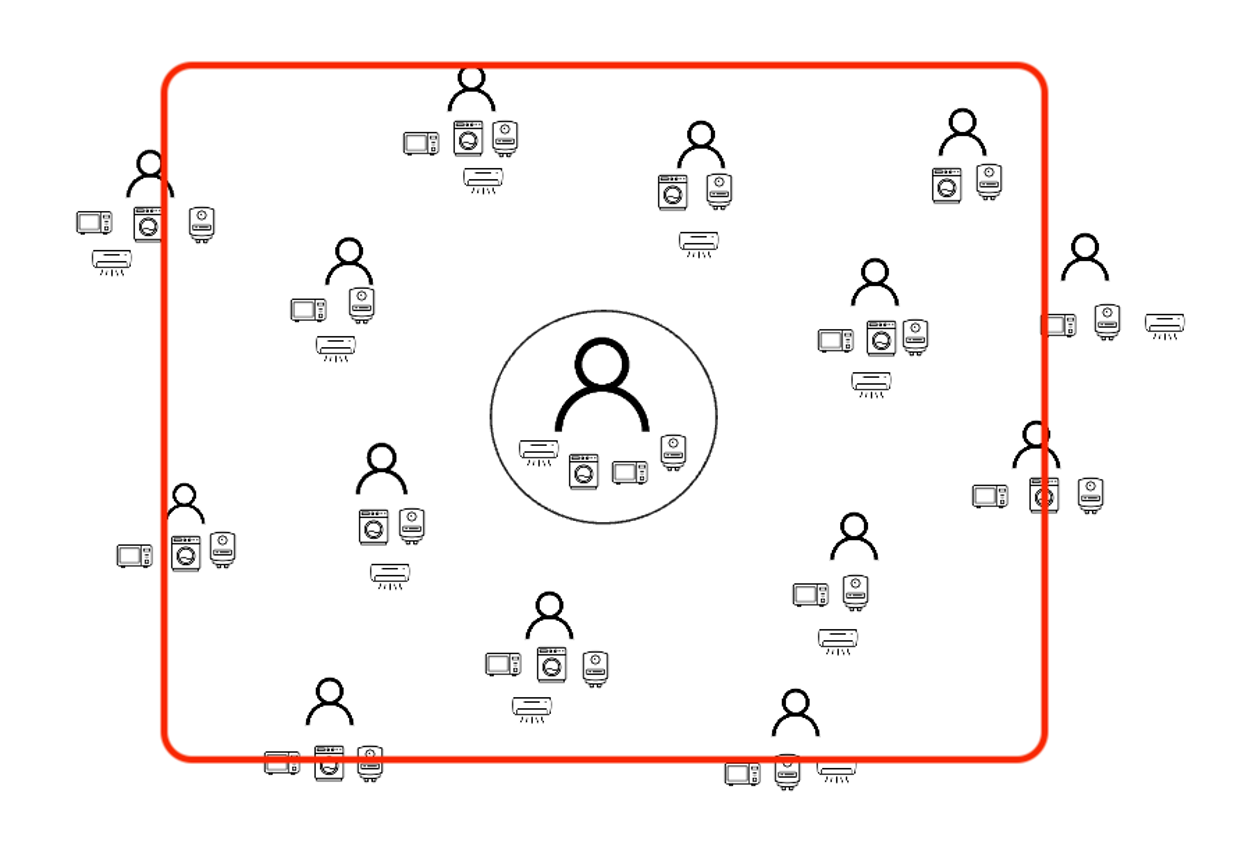
이런식으로 범위를 지정하여 정보를 얻으면 되겠죠?
근데 작은 범위에서 데이터가 원하는 개수만큼 안나올 수 있기 때문에, 데이터가 충분하지 않으면 범위를 확장하여 원하는 dataset을 얻을 때까지 다시 search하는 방식을 적용할 수 있을 것이라 생각했습니다.
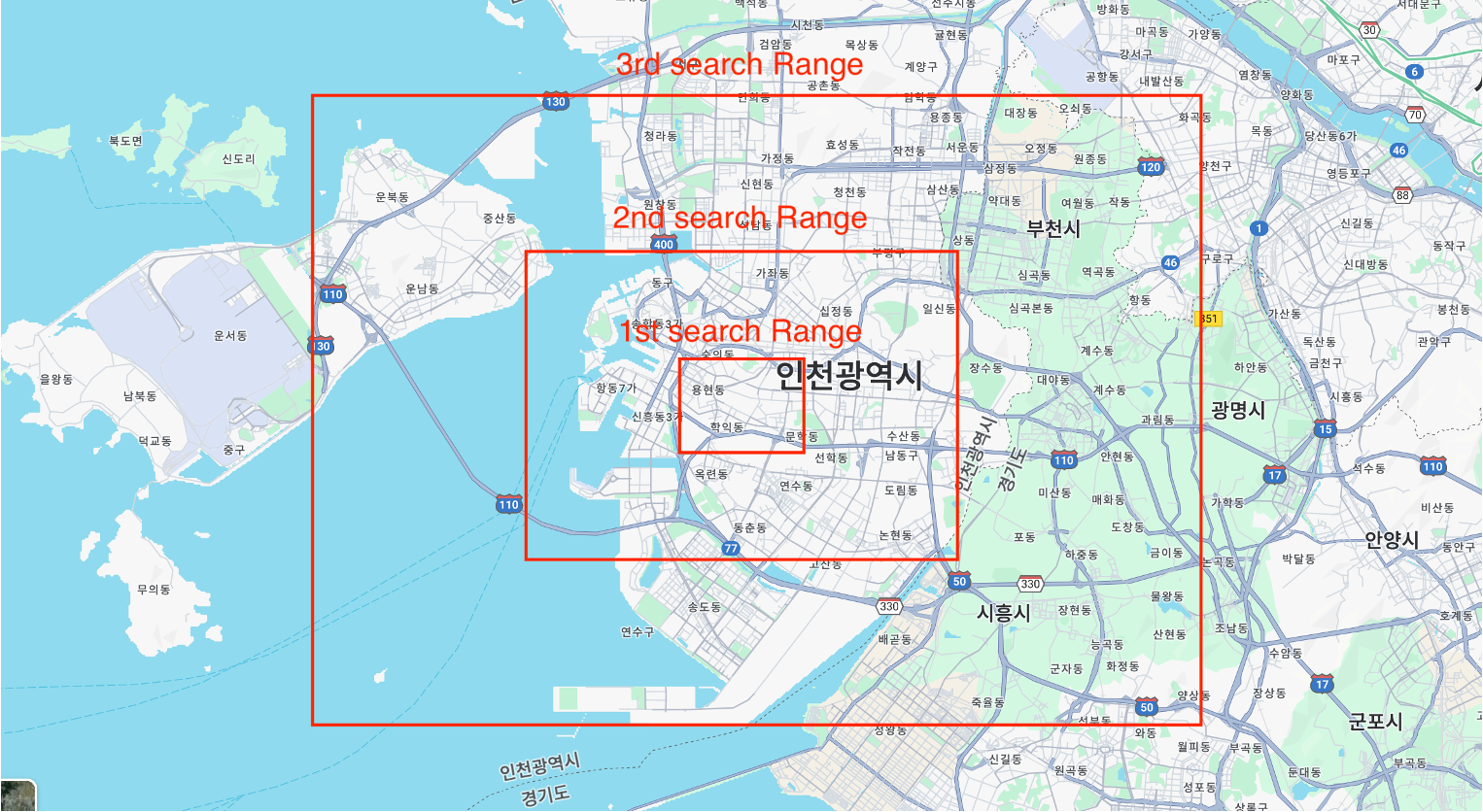
하지만 여기서 중요한 문제가 발생합니다.
50만개의 전체범위에서 탐색할 일은 발생하지 않겠지만, query를 여러번 호출한다는 것은 호출 횟수에 따른 큰 overhead를 야기합니다.
그러면 적당히 범위를 지정하여 쿼리 횟수가 1~2회가 되도록 하면 되는 것이 아닌가? 라는 생각이 들게 됩니다.
하지만, 인구 밀도라는 것은 심각한 차이를 보이기 마련입니다.
같은 크기의 범위를 지정하더라도, 도심은 한번의 탐색으로 원하는 개수의 dataset을 확보할 수 있지만, 지방같은 경우는 여러번의 탐색을 해야 원하는 개수의 dataset을 확보할 수 있는 문제가 발생합니다.
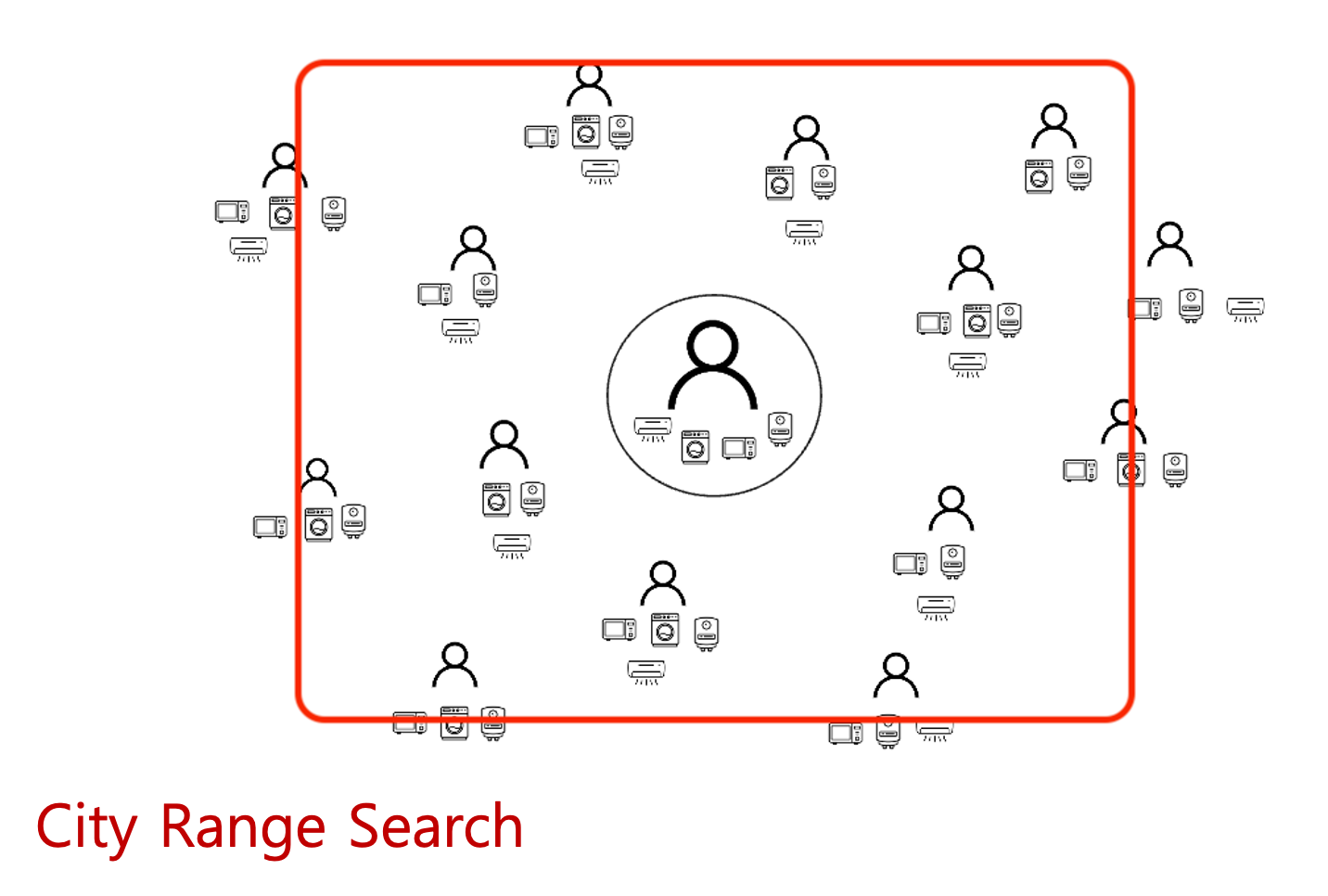
즉, 인구밀도가 적은 지방에서 해당 API를 호출하면 반복횟수에 따른 overhead로 인해 호출시간이 커질 수 있다는 것입니다.
사진은 첨부 못했지만, 지방의 경우 1600ms 정도까지 시간이 걸리기도 하였습니다. 이에 대해 확실하게 해결할 필요가 있어보입니다.
2-4. 네번째 시행착오 (적응형 메모리 테이블)
가장 중요한 것은 시골과 수도권의 간극차이를 줄일 것입니다. 하지만, 좌표가 주어졌을 때, 그 좌표가 시골 지역인지 서울지역인지 명확하게 판별하기는 어렵습니다.
이를 수치적으로 표현하는 것은 더더욱 어렵습니다.
이에 대해 각 지역을 나누고, 각 지역에 대해 대한민국 인구분포(인구밀집) 계수를 적용할까 생각하였습니다.
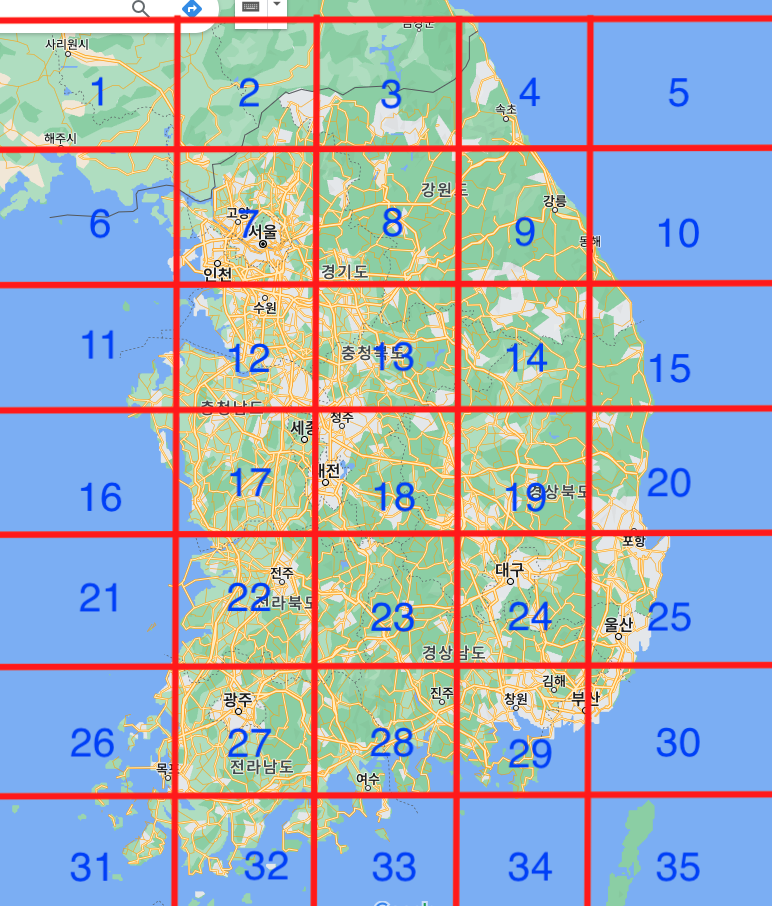
각 범위에 지정된 밀도 계수를 활용하여, 밀집도가 더 높을 수록 작은 범위에서 탐색을 시작하게 해볼까 생각하였습니다.
하지만 실제 어떤 지역에서 서비스가 가장 활성화될 것인지는 구별할 수 없고, 이에 대해 계속해서 코드를 변경하여 계수를 변경해줄 수는 없는 노릇입니다.
이에 대해서 고정된 값의 인구밀집 계수가 아니라, 적응형 계수를 적용할 수 없을까 생각하였습니다. (서비스의 양상에 따라 값이 변화함)
이에 대해 2가지 아이디어가 떠올랐습니다.
- 사용자 데이터가 생성될때마다 실제 테이블에 존재하는 데이터를 기준으로 인구밀집도 계수 부여하기
- 근래에 가장 API를 가장 많이 호출한 구역에 더 높은 가중치(밀도 계수)를 부여하기
유령유저들이 존재할 가능성이 높기 때문에 2번째 방법을 채택하였습니다.
실제 이용중인 유저들의 실시간 정보를 이용하여 밀도계수를 부여하도록 하겠습니다.
API를 호출하는 모든 순간마다 위의 그림에서 보여준 구역 중, 어떤 그룹에 속하는지를 확인하고, 해당 그룹에 대한 가중치를 증가시켜 REDIS(주 기억장치 = RAM)에 저장합니다.
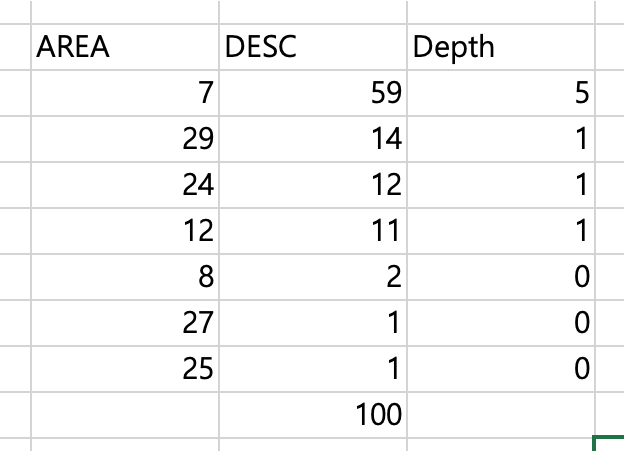
List 자료구조를 활용하여 100개의 자료가 넘어가면 오래된 순으로 데이터를 삭제할 것입니다. (최근 이용한 100명의 유저의 기록만 남긴다는 뜻입니다.)
이렇게 하면 각 구역에 대한 이용밀도가 나오게 되는데, 이를 활용하도록 하겠습니다.
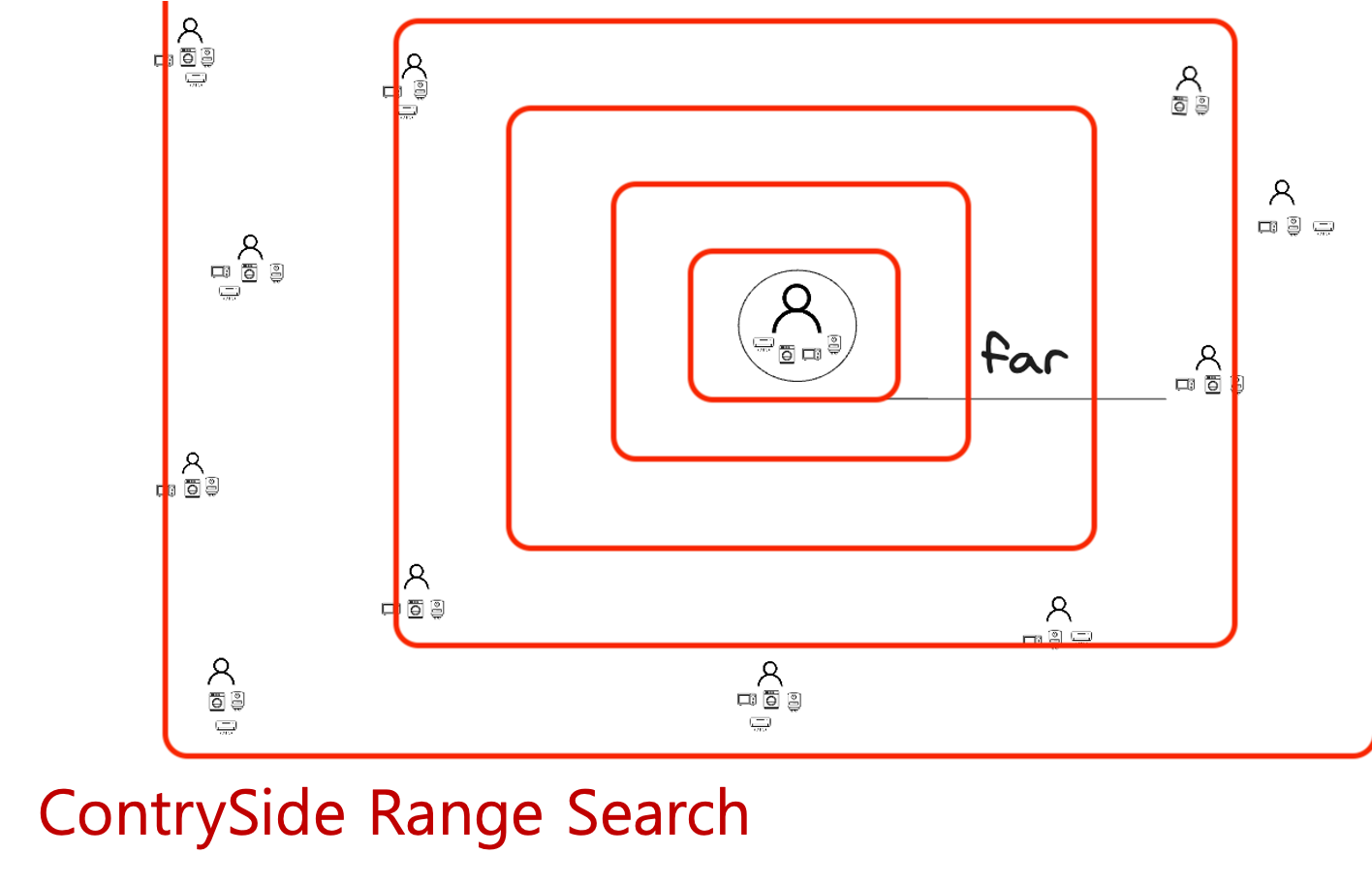
도심에서 호출하면 높은 이용밀도에서 호출하였기 때문에, 그대로 작은 범위에서 호출이 됩니다. 그와는 반대로 지방에서는 이용밀도가 현저히 낮기 때문에, 더 넓은 범위에서 첫번째 탐색을 진행하게 됩니다.
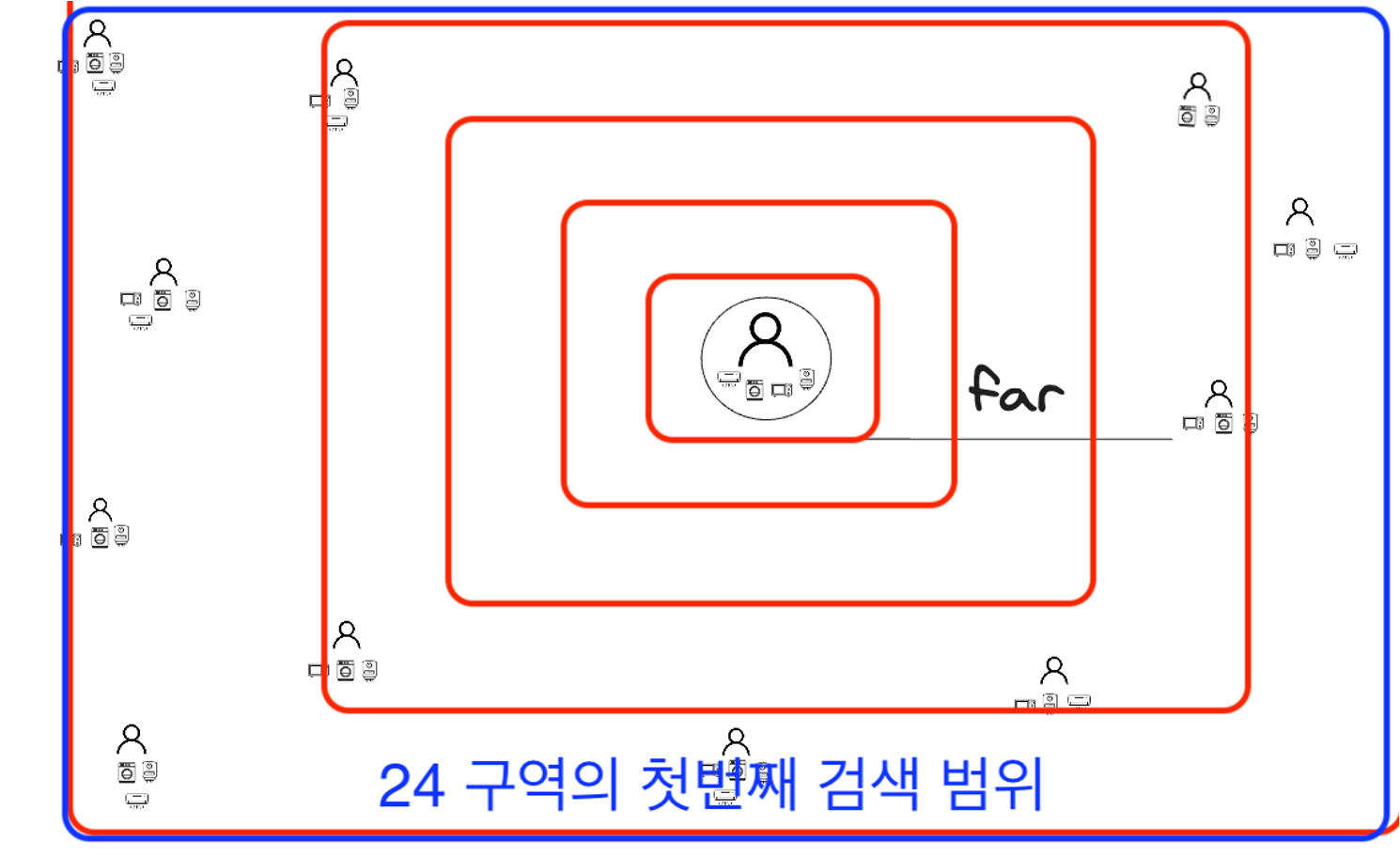
기존에는 붉은색 범위에서 첫 탐색을 하였는데, 적용한 이후로는 푸른색 범위에서 첫번째 탐색을 진행합니다.
2-5. 최적화 - 구현 완료
사실 원리로는 그렇게 어려운게 아니지만, 이에 대한 값을 어떻게 '자세히' 선정할 지는 굉장히 중요한 이슈입니다.
-
범위 확장 계수를 어떻게 설정하였는가?
사실 대한민국의 인구밀집 양상이 어떠한 함수의 모양에 가까운지는 모릅니다. 그래서 무작성 인구밀집에 대한 함수를 여러개 찾아봤는데, 대부분 밀집을 위해 사용하는 함수가
 와 같은 exponential 함수였습니다. 이에 대해서 범위확장 쿼리를 만드는 것에 있어서, 대한민국의 지도의 최대범위를 기준으로 2's exponential 하게 범위를 나눴고, 그 안에서 범위를 확장하였습니다.
와 같은 exponential 함수였습니다. 이에 대해서 범위확장 쿼리를 만드는 것에 있어서, 대한민국의 지도의 최대범위를 기준으로 2's exponential 하게 범위를 나눴고, 그 안에서 범위를 확장하였습니다.
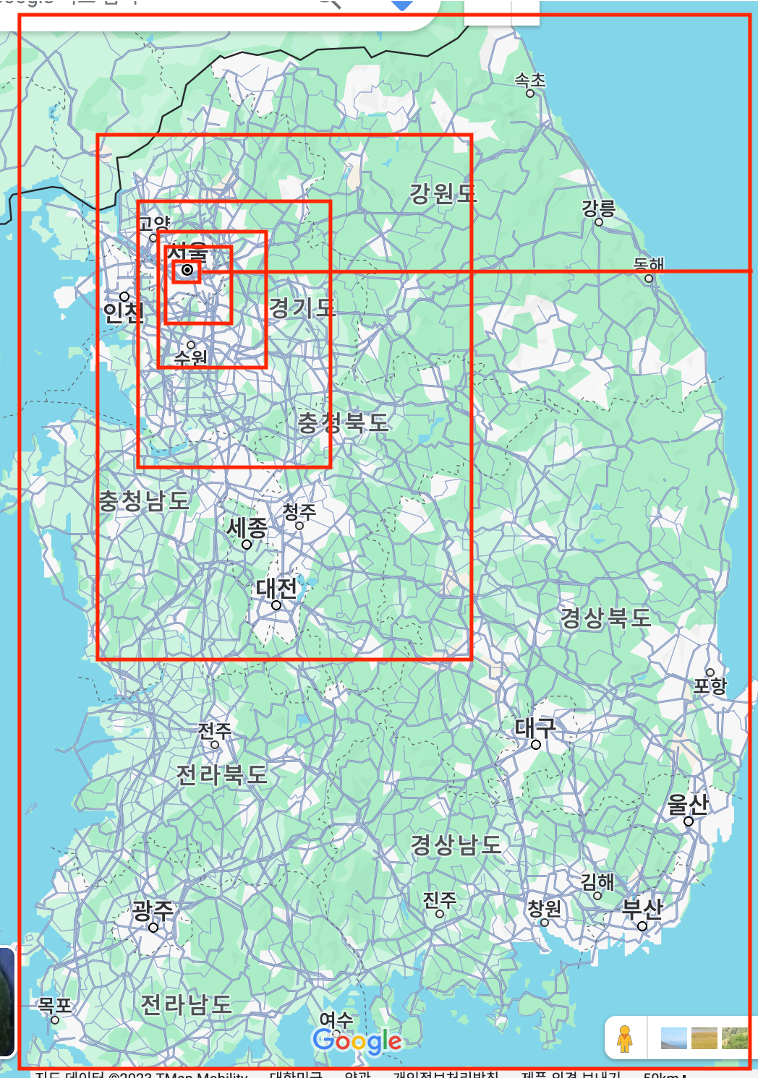 이 사진을 보면, 시작범위를 기준으로, 4변의 극 범위를 기준으로 절반을 나누고... 또 절반을 나누고...를 반복하고 있음을 볼 수 있습니다.
이 사진을 보면, 시작범위를 기준으로, 4변의 극 범위를 기준으로 절반을 나누고... 또 절반을 나누고...를 반복하고 있음을 볼 수 있습니다.
(+ 이 방식은 다른 장점 또한 존재하는데, 2의 제곱으로 나누는 횟수 = 탐색횟수기 때문에, 나누는 계수만 정해지면 그 계수 범위 안에서만 쿼리반복을 수행하고, 마지막 쿼리에는 모든 범위에 대한 탐색까지 가능하단 장점이 존재합니다.) -
시작범위를 어떻게 지정하였는가?(나중에 수정하겠습니다. 설명을 이상하게 함)
시작범위도 비슷한 논리로 exponential 계수를 활용하여 지정하였습니다. 다만 시작범위는 예상보다 좀 더 크게 지정할 필요가 있습니다. 대용량 데이터에서 쿼리시간은 데이터 수에 비례하여 선형적으로 늘어나게 됩니다.
0~100ms와 같은 낮은 쿼리 수행시간에서는, 쿼리를 제외한 다른 실행시간의 overhead로 인해 쿼리 시간의 차이를 느끼기 어렵습니다. 1000ms 이상의 시간이 되야 실제로 API의 속도에 대해 큰 불편함을 느끼게 됩니다.
이에 대해 좀만 더 생각해보면, 시작범위라고 무작정 작을 필요는 없고, 시작 범위가 가장 넓을 때를 기준으로 5만개 이하 정도의 데이터가 되는 경향성을 유지해주면, 쿼리 반복횟수에 의한 overhead가 대폭줄고, 데이터 개수에 의한 overhead가 소폭 증가하여 좋은 실행속도를 낼 수 있습니다.
(기타 다른 과정들도 겪었지만, 나중에 정리해서 올리겠습니다.)
결과적으로는 이런방식으로 API를 완성하였고, 다음과 같은 결과를 도출해낼 수 있었습니다.
다음은 실제로 인구 밀도를 고려한 500,000개의 데이터셋에서 알고리즘을 수행한 결과입니다.
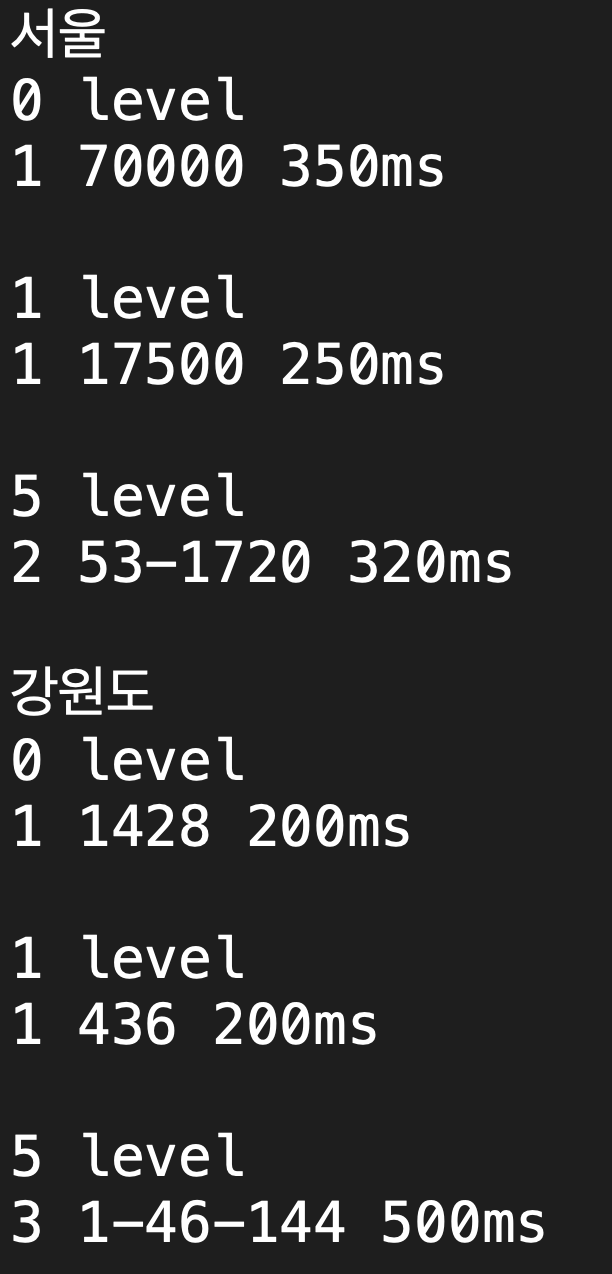
0 level => 적응형 메모리 테이블에서 최근 이용자가 없을 때(넓은 범위에서 탐색)
1 70000 350ms => 1번의 쿼리문 수행, 7만개의 데이터셋, 350ms소요
5 level => 적응형 메모리 테이블에서 최근 이용자가 많을 때(좁은 범위에서 탐색)
1 70000 350ms => 2번의 쿼리문 수행, 53->1720개의 데이터셋, 320ms소요
실제로는 서울은 5레벨, 강원도는 1레벨에 형성될 것임
=> 서울은 320ms, 강원도는 200ms 안에 쿼리가 호출될 것
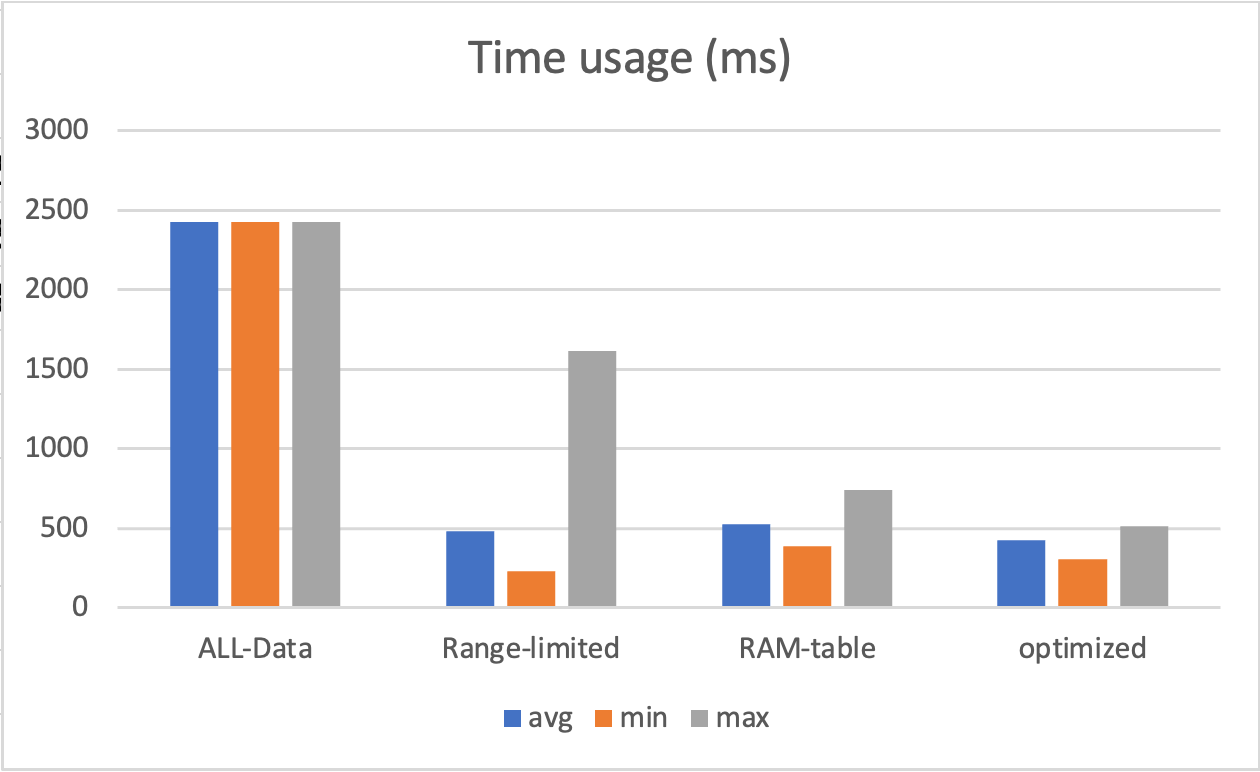
정확한 값은 아니지만, 대략 이런 경향을 보입니다.
3. 한계와 개선점
개선점 1.
아까 말한 것처럼 유령인구 또한 반영하는 계수를 만들어 복합함수를 만들 수 있지 것 같습니다.
탐색범위를 2's exponential 하게 나누는데 인구가 많아질 수록 탐색 회수를 결정하는 범위를 촘촘하게 나눌 수 있으면 좋을 것 같습니다. (지금은 고정)
개선점 2.
메모리 테이블의 가중치에 의해서만이 아닌, 전체 이용자 수에 따라 초기 탐색범위에 반영되면 좋을 것 같음
기타 개선점도 있었지만, 기억이 나지 않습니다. 차차 추가하겠습니다.
한계점 1. 부정확함
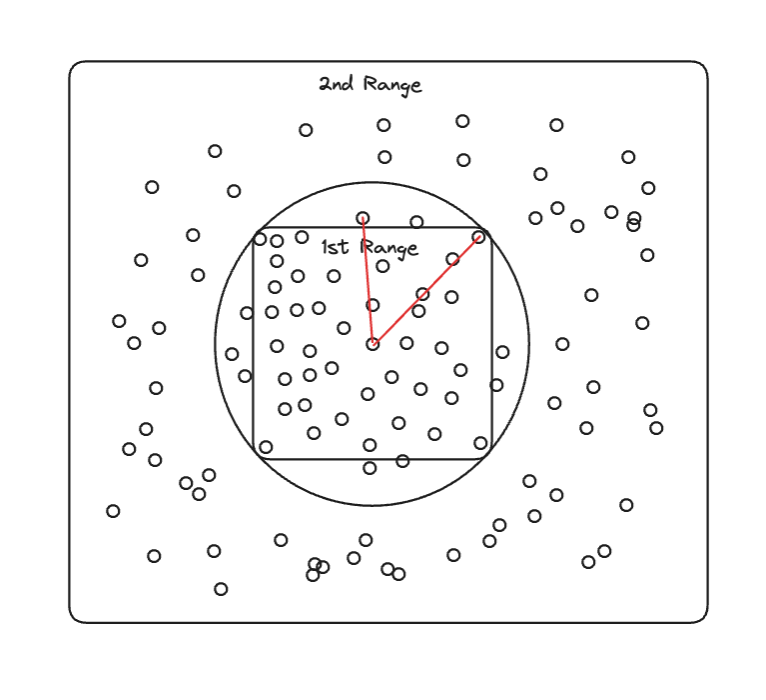
범위를 지정한다는 것은, Latitude, Longitude를 기준으로 정하기 때문에 사각형의 범위로서 지정됩니다. 하지만 동일한 거리 범위라는 것은 원의 모양을 가집니다.
자료를 보면 알 수 있듯이, 특정 자료는 다른 자료보다 더 가까이 있음에도, 1번째 검색 범위에 속하지 못합니다.
이게 문제인 이유는, 2번째 검색의 범위로 가게 되었을 때는 더 가까웠지만 1번째 검색에서는 포함되지 못했던 데이터가 새로 포함되며 가까운 100명의 데이터가 바뀌게 됩니다(바뀌면 안 됨). 이는 정확성 문제를 야기합니다.
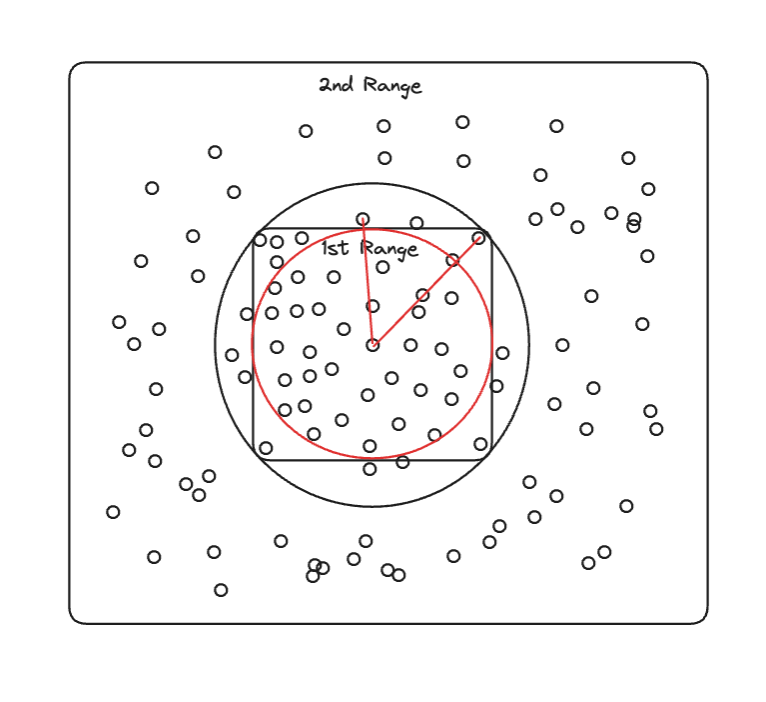 다시 한번 내접하는 원의 범위를 생성하여 해결할 수 있을 것으로 보입니다만, 이것까지 구현하기에는 너무 overhead가 커서(개발에 들어가는 시간의 overhead) 구현하지 않았습니다.
다시 한번 내접하는 원의 범위를 생성하여 해결할 수 있을 것으로 보입니다만, 이것까지 구현하기에는 너무 overhead가 커서(개발에 들어가는 시간의 overhead) 구현하지 않았습니다.
정확한 등수가 아닌, 등급을 보여주는 지표기 때문에 이러한 부분에 결과 경향성에 큰 영향을 주지 않는다고 판단한 부분도 어느정도 존재합니다.
한계점 2. Elastic search 같은 외부 서비스를 이용하는 것이 더 나을 수 있음
=> 개선점 : PostgreSQL 의 자체적인 라이브러리인 PostGIS를 제대로 활용한다면 원하는 기능을 만들 수 있음
이상입니다. 읽어주셔서 감사합니다. 글은 보완하도록 하겠습니다.
