
PostgreSQL에서는 다양한 index를 제공하는데 이에 대한 차별성을 알아보고자 합니다.
인덱스의 의미는 다음 영상 참고 바랍니다.
PostgreSQL은 B-tree, Hash, GIST, SP-GiST, GIN, BRIN 그리고 bloom 확장자 등 여러 개의 인덱스 유형을 제공합니다.
이번 실험에서는 성능의 편차를 확실하게 측정하기 위해서 JS코드를 활용하여 반복실행하는 작업을 수행하였습니다. 깃허브 링크 주소를 활용하면 될 것 같습니다.
해당 글에서 사용한 테이블 구조는 다음과 같습니다.
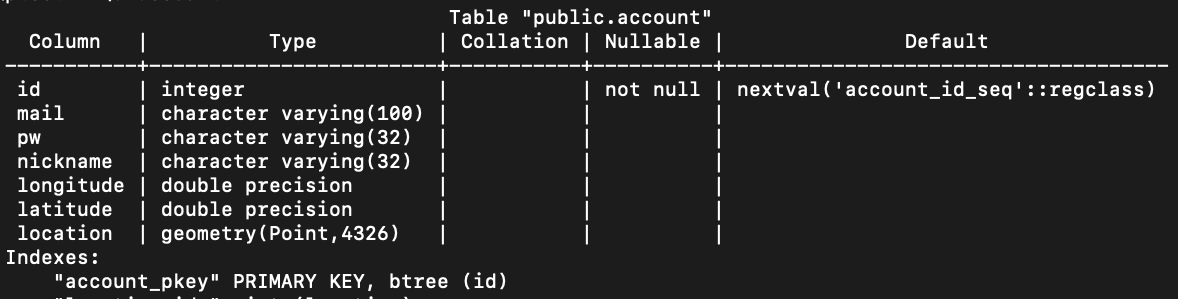
다음과 같은 형식의 데이터를 500만개 삽입하였습니다.

1. B-tree
개요
기본적으로 PostgreSQL과, MariaDB 모두 인덱싱에 기본적으로 사용하는 알고리즘(자료형)은 B-tree 형식입니다.
해당 알고리즘의 저장방식은 Balanced Tree 구조기 때문에, 보통의 CRUD 작업을 수행하는 데에 O(Log N)의 시간복잡도를 소모한다는 특징 존재합니다.
위와 같은 성질로 인해, 모든 작업을 수행하는데 적당한 (흔히 평타(?)는 치는) 성능을 보여주며, 한 작업에 대해서만 특화된 성능을 보여주지는 않습니다.
즉, 일반적으로 가장 많은 상황에서 적합한 알고리즘(자료형)이며, 이는 인덱싱을 설정하면 디폴트값으로 설정되는 이유라 분석하였습니다.
실험
이전 글과 전전 글에서 해당 내용에 대한 결과 (unique key, primary key)를 보여준 바가 존재하기 때문에, 추가적인 실험을 진행하지는 않겠습니다.
2. Hash
개요
자료구조형이 가지는 특성까지 설명하면 길이 너무 길어지기 때문에, 다음 글을 참고하시길 바랍니다.
주요 부분만 발췌하자면,
범위를 검색하거나 ( >= , BETWEEN AND, < > ,LIKE), 원본값을 기준으로 정렬(ORDER BY , DESC ...)을 할 수 없는 대신 동등비교조건(==, IN, IS NULL, IS NOT NULL, <==>)일 경우에는 B-tree보다 훨씬 빠른 장점을 이용할 수 있다.
실제로 범위 검색이 불가능하지는 않을 것이라 예상하고, 아마 매우 느린 Latency가 나올 것입니다. (index가 없어도 동작은 가능하기 때문)
실험
500만개의 단순 데이터가 존재하는 테이블에서 해당 실험을 진행하였습니다.
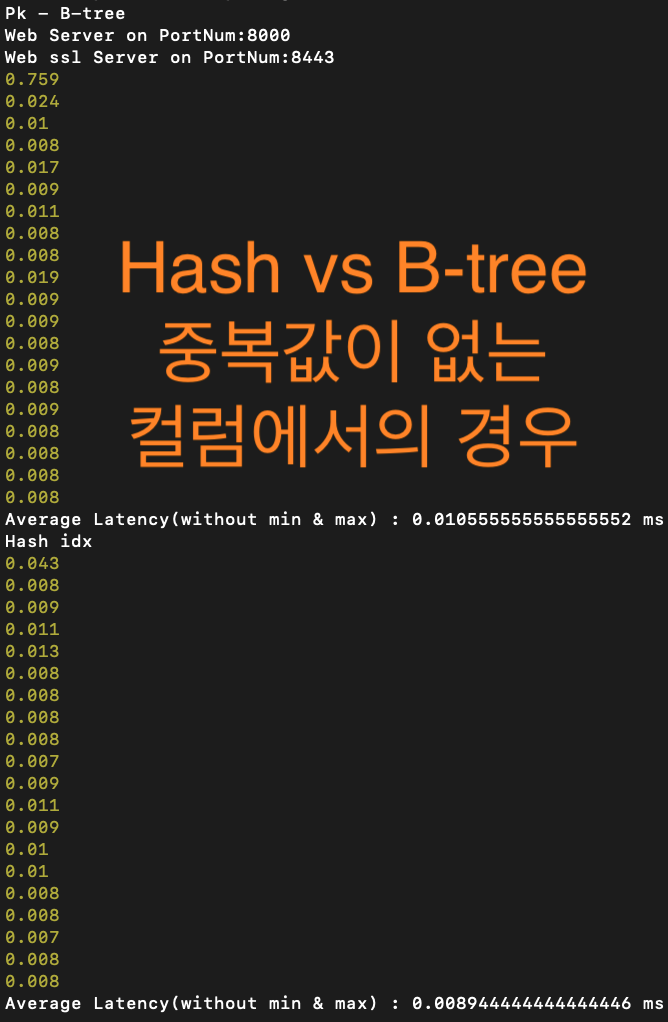
1. 단순 서칭 측정
다음 쿼리를 사용하여 진행하였습니다.
EXPLAIN ANALYZE
SELECT
*
FROM
account
WHERE
longitude=-48.35523039348061;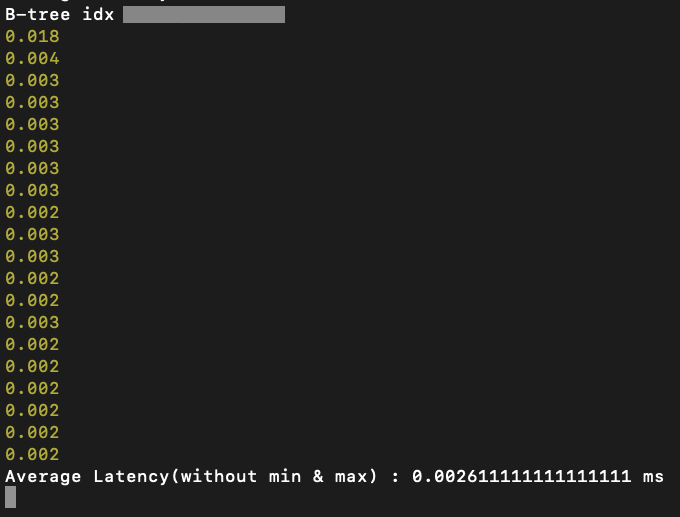
Btree - 0.00261 ms
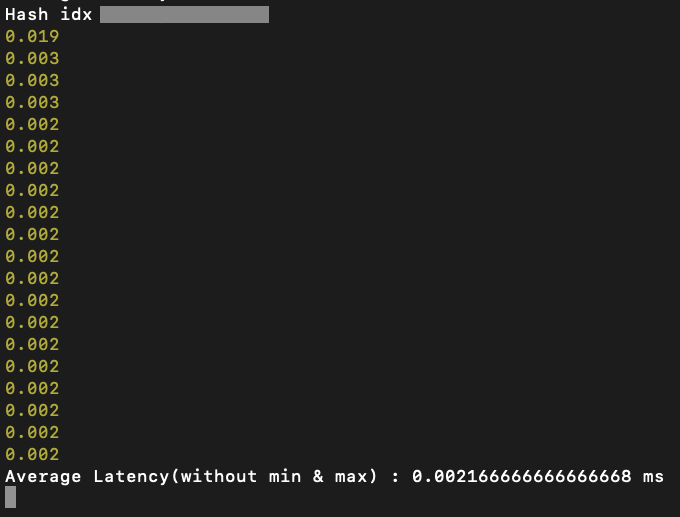
Hash - 0.00216 ms
단순하게 하나의 값에 대한 일치 여부를 Searching 해내는 부분은 평균적으로 20회를 수행하였을 때, Hash index의 속도가 좀 더 빠른 것을 관찰 가능했습니다. (압도적이지는 않았습니다.)
단, Hash는 범위를 검색하는 방식의 성능이 매우 뒤떨어지기 때문에, 범위 검색을 지정해보도록 하겠습니다.
EXPLAIN ANALYZE
SELECT
count(*)
FROM
account
WHERE
longitude > 150;`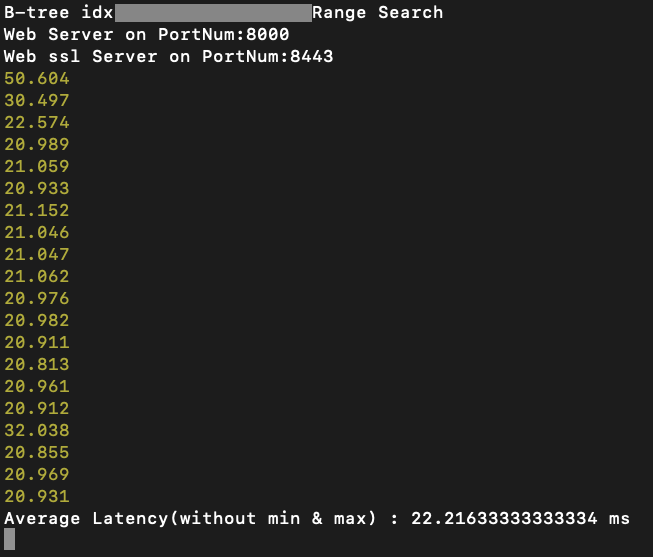
B-tree 범위 검색 - 22.2163 ms
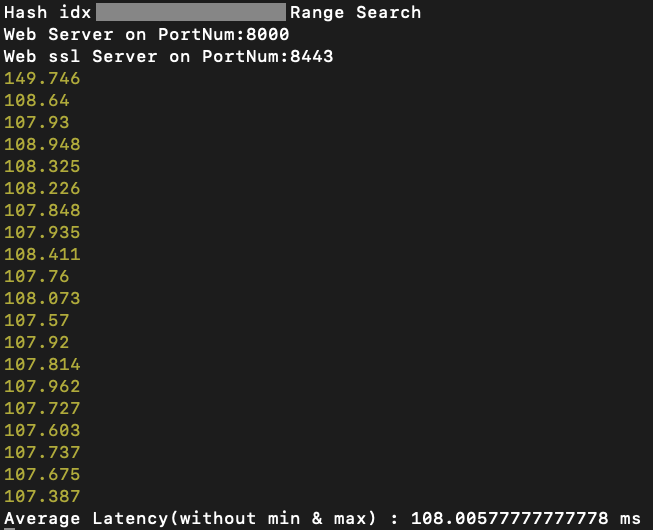
Hash 범위 검색 - 108 ms
확실하게 Hash가 성능이 모자른 모습을 관찰할 수 있습니다.
B-tree indexing은 대부분의 작업에 대해 O(log N) 시간복잡도를 따르는 성능을 보여줍니다.
하지만 Hash indexing이 적용된 컬럼에서는 특정 작업에서는 O(1)의 성능이지만, 어떠한 작업에서는 O(N)의 시간 복잡도를 지닙니다.
이는 O(1)작업에서는 O(log N)보다 '약간' 빠르지만, O(N)을 소요하는 작업에서는 O(log N)보다 '현저히' 느린 성능을 가지게 됩니다.
예시를 하나 들자면, N = 1000000이고, log의 밑을 10이라 가정하면
O(1) = 1,
O(N) = 1000000,
O(log N) = 6
의 값을 지니게 됩니다...
3. GiST
개요
사용자의 위치를 데이터베이스에 저장하는 방식에는 여러가지가 존재합니다.
가장 쉬운 방식은 longitude, latitude (경도, 위도)를 저장하는 방식입니다.
해당 방식을 활용하여, 가까운 순으로 유저 N명을 데이터베이스로부터 추출하는 로직을 만든 경험이 있습니다.
한 사용자와 비교대상 군을 모두 비교해야하는 과정이 발생해 큰 Latency가 발생합니다.
당시에는 PostgreSQL의 오픈소스 확장 프로그램인 PostGIS를 사용해보았지만, 레이턴시에 큰 개선이 발생하지 않았습니다.
그래서 당시에는 지구의 곡률 만을 보정한다는 섣부른 판단을 했습니다.
하지만 이에 대해 INDEX를 적용하면 전혀 다른 결과를 보여줍니다.
실험
1. 단순 거리 측정
실제로 실험에서 사용한 쿼리는 서브쿼리와 JOIN을 활용하였습니다만, 핵심적인 탐색쿼리는 다음과 같이 표현 할 수 있습니다.
SELECT *,
((latitude - 11.994151854243498 )^2 +
(longitude + 48.35523039348061)^2) AS distance_squared
FROM account
ORDER BY distance_squared
LIMIT 10;(거리는 제곱의 합의 루트지만, 단순 비교를 위해 루트는 생략하였습니다.)
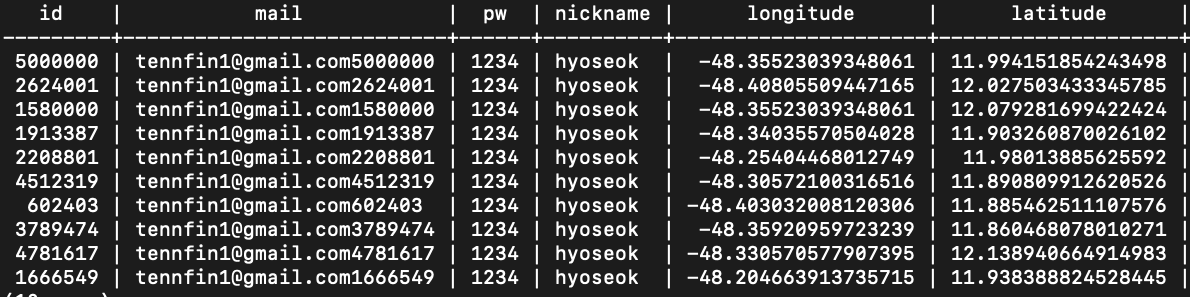
다음과 같은 결과가 나오고, 다음 쿼리를 20회정도 자동화 하여 JS로 수행하였을 때, latency는 다음과 같습니다.
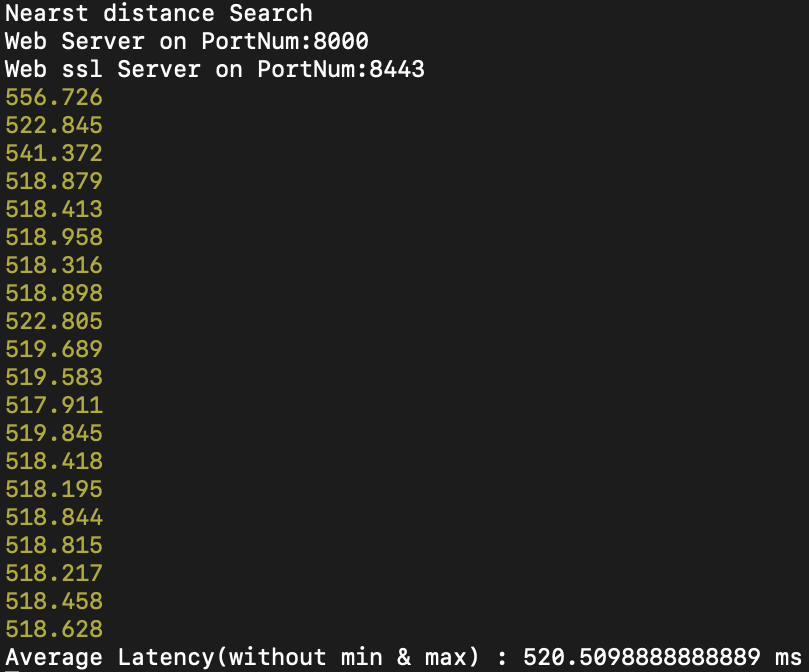
평균 520ms의 Latency가 발생합니다.
2. PostGIS 데이터 활용
- Brew를 활용하여 PostGIS를 설치한 후(mac 기준), PostgreSQL에 extension을 확장설치해줍니다.
CREATE EXTENSION postgis;-
그러면 geometry라는 컬럼형을 사용이 가능하게 되며, Point라는 좌표를 저장할 수 있는 자료형이 생기게 됩니다.
-
location이라는 geometry 자료형 컬럼을 생성한 후, longitude와 latitude에 존재했던 데이터들을 Point로 변환하여 넣어줍니다.
ALTER TABLE account ADD COLUMN location geometry(Point, 4326);
UPDATE account SET location = ST_SetSRID(ST_MakePoint(longitude, latitude), 4326);- 서칭 쿼리문을 사용합니다. (새로운 연산자인 <-> 사용하기)
SELECT * FROM account ORDER BY location <-> Point '($1, $2)' LIMIT 10;Type casting이 불가능하다는 메시지가 나오므로, 수정해주면 다음과 같습니다.
SELECT * FROM account ORDER BY location::geometry <-> 'SRID=4326;POINT($1 $2)'::geometry LIMIT 10;
위와 동일한 서칭 결과입니다.
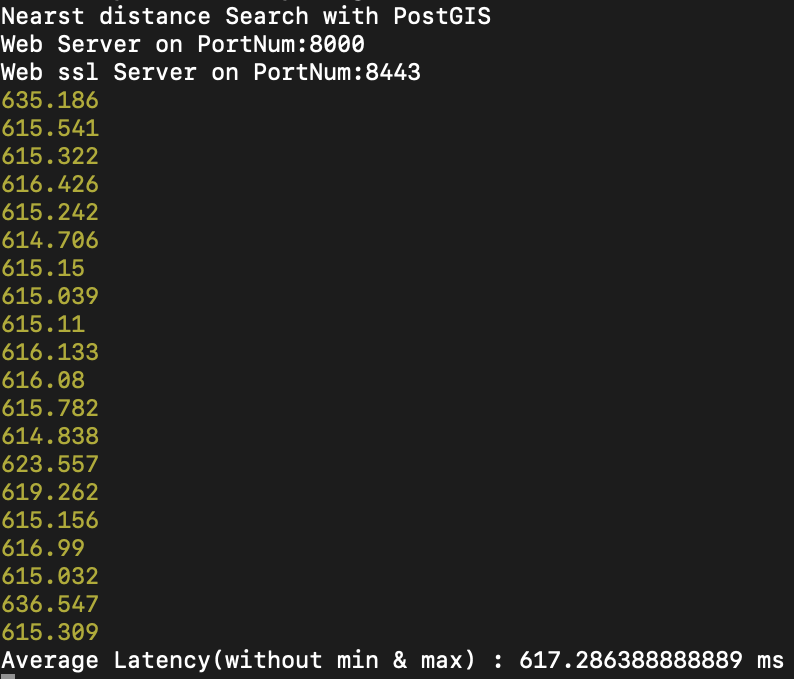
실행시간이 비슷한 수준에서 발생한 것을 확인할 수 있습니다.
3. GiST 인덱스 추가
CREATE INDEX location_idx ON account USING GiST (location);위와 동일한 쿼리를 사용하면,

동일한 결과가 나오며,

20회를 수행하면 평균 0.1ms로 확연하게 단축된 것을 확인할 수 있습니다.
해당 방식이 왜 빠른지에 대해서 알고 싶으면, GeoHash방식에 대한 글을 읽기를 바랍니다.
4. 결론
PostgreSQL, 판정승!
위에서 언급한 이외에도 다양한 INDEX를 활용할 수 있다는 점은, PostgreSQL에서의 압도적인 장점으로 보여집니다.
그 뿐만이 아니라, 확장성과 읽기능력까지 고려하면, 1인 개발자들에게 PostgreSQL이 MariaDB보다 더욱 추천할 만한 오픈소스 데이터베이스라고 생각합니다.
(+ 더 많은 INDEX를 사용하는 글은, 다음에 기회가 되면 작성하도록 하겠습니다.)
다음 글에는 해당 Gist Indexing과, <-> 문법을 활용하여 기존에 했던 프로젝트의 성능을 개선함과 동시에, TypeScript를 활용하는 리팩터링을 시도하는 글로 찾아뵙도록 하겠습니다. 읽어주셔서 감사합니다.
