※ 본 포스트는 인하대학교 지능형반도체 연구실의 최영규 교수님의 허가 하에 작성되었습니다.
※ 교수님의 설명에 해당하는 내용을 제외하고, 제 의견은 노란색 글씨로 작성 하겠습니다.
※ solution에 대한 코드는 절대 제공되지 않으며, 수업진행에 필요한 모든 도움은 최영규 교수님의 자료 및 이메일을 참고하길 바랍니다.
요약 + 간단한 의견으로 구성됩니다.
자세한 내용은 반드시 강의를 참고해주시길 바랍니다.

오늘은 DRAM 최적화입니다.

이전 강의에서 했던 hello, world 프로젝트입니다.
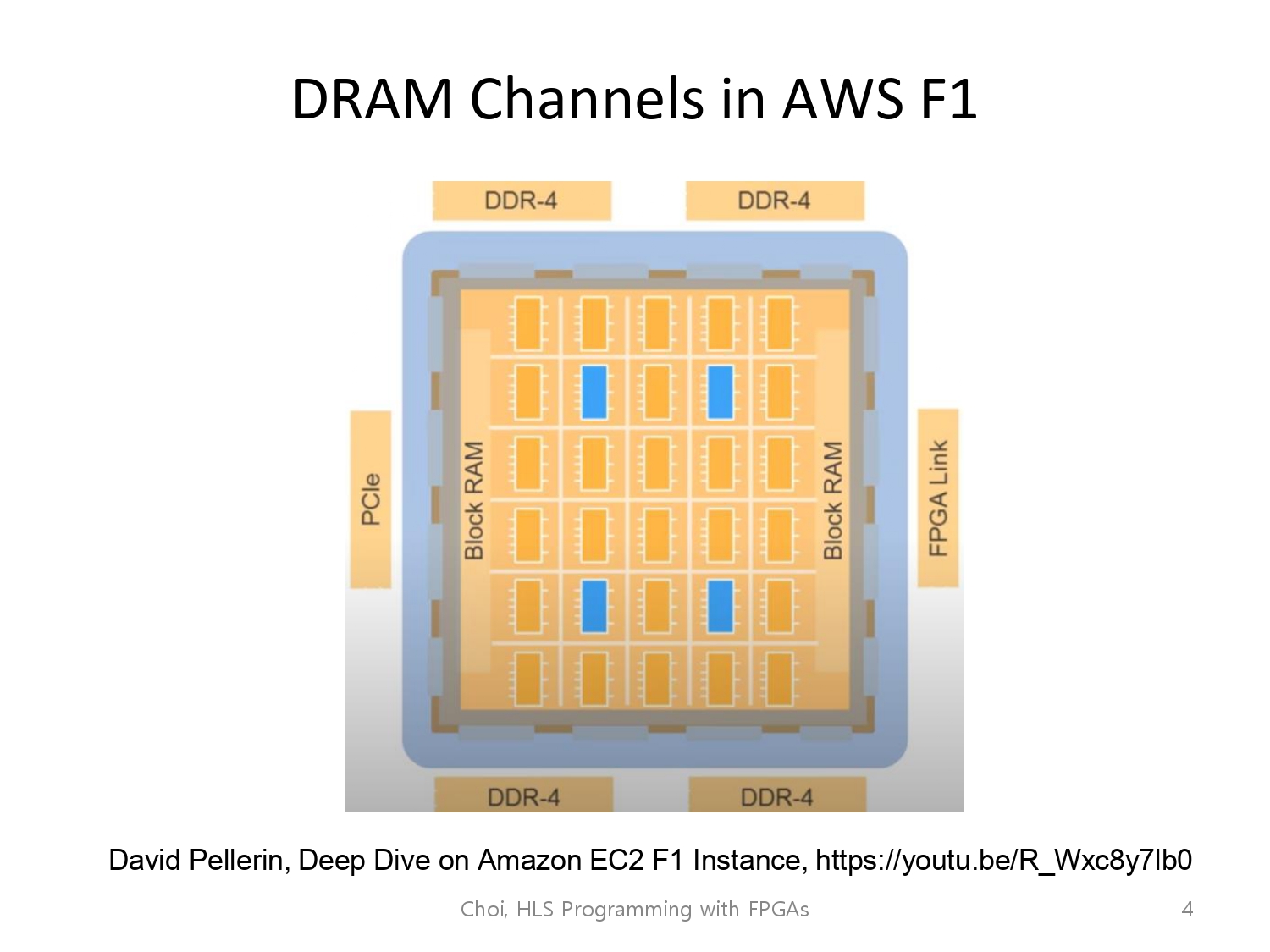
이전에 aws F1의 구조를 설명할 때, 인스턴스에 FPGA가 PCIe슬롯을 통해 꽂혀있고, FPGA에는 외부 메모리가 장착이 가능하다 배웠습니다.

해당 외부 메모리(DRAM)에 대한 스펙 명세입니다.
BandWidth = 채널개수 x 클럭 주파수 x byte
중재 오버헤드 때문에, 실제 성능이 이렇다는게 아니라
버스에서 감당가능한 이론상 최대라는 뜻.

vector add에서 효과적인 DRAM bandwidth는?

앞선 vadd 연산에서 수행한 결과, 속도는 1GB/s도 안됩니다.

원인 1. 물리적인 bus(통로) data bitwidth는 물리적으로 512b이나,
합성된(작성한) bus data bitwidth는 32b임(int가 32bit 정수이므로)
못해도 16배는 손해보는 중입니다.

해결안 1. 넓은 데이터 타입 사용하기
1. top kernel function에서 512bit를 가지는 변수 선언
2. 범위 연산자를 사용하여 512bit안에 32bit데이터(16개겠죠?)가 들어가게 나눠주기

3. 쪼개진 원래의 데이터타입에서 더해줍니다.
4. 연쇄적인 결과를 다시 512bit짜리 인수에 넣어줍니다.

해결안 2. Vector data type 사용하기
vitis 자체가 vector를 지원하기 때문에 그냥 사용해주면 됩니다.
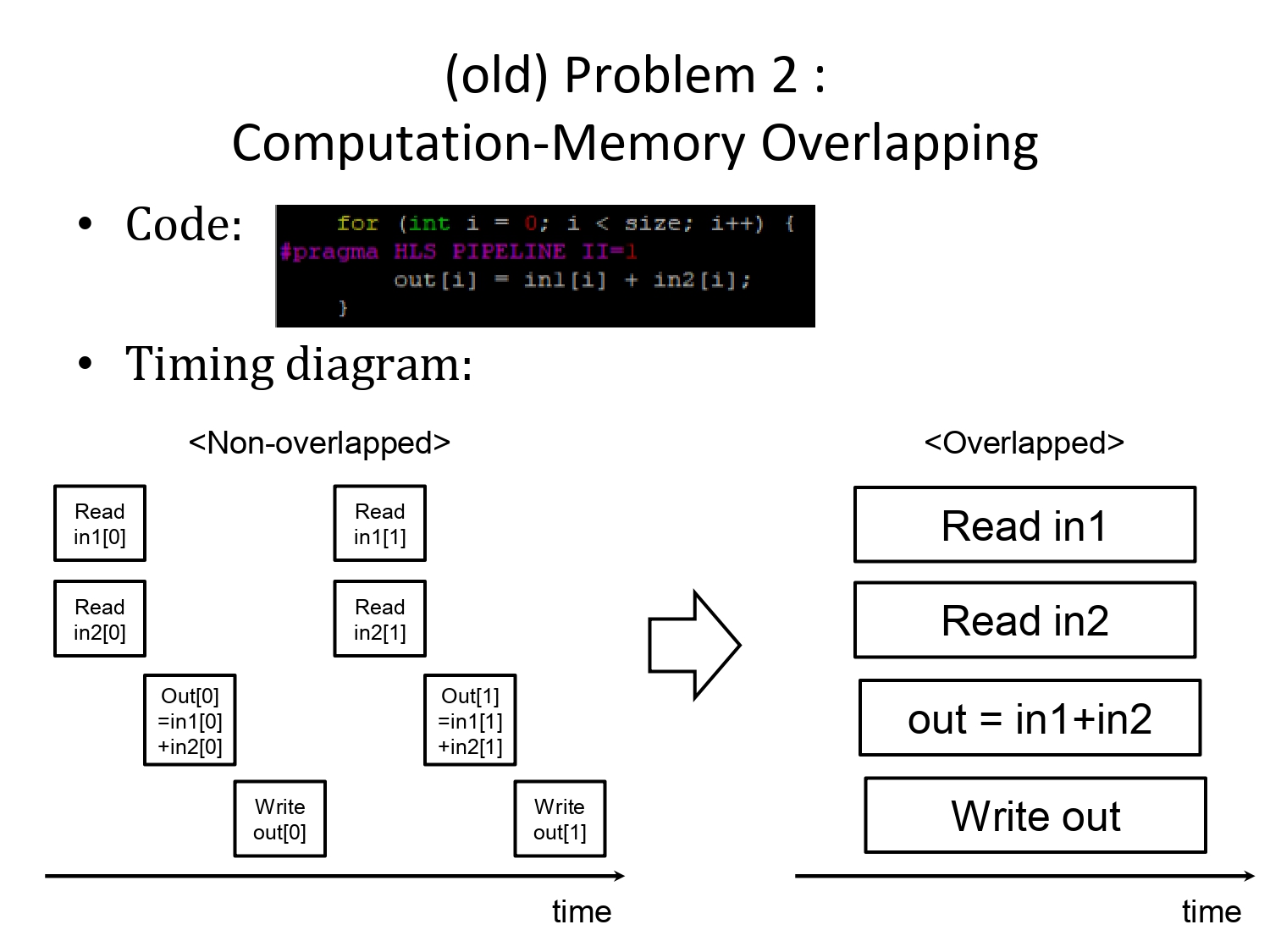
문제는 벡터 사용시
패러렐하게 움직이지 않는다는 것.(벡터 간에)
위에선 정수 전체가 각각이라 바로 적용이 되는데,
여기선 벡터를 사용해서 안됩니다.
그래서 FIFO를 수행하는 버퍼를 만들어서 평행화되게 사용하면 됩니다.



근데 사실 문제 1,2는 자동적으로 hls가 해결해줍니다.

16배 손해 보고 있는 걸 줄여 10배 이상 빠르게 해도, 5배이상의 손해를 보고 있습니다.

single 램 채널을 쓰고 있기 때문입니다.
모든 top function이 하나의 dram 채널에 연결되어있기 때문.
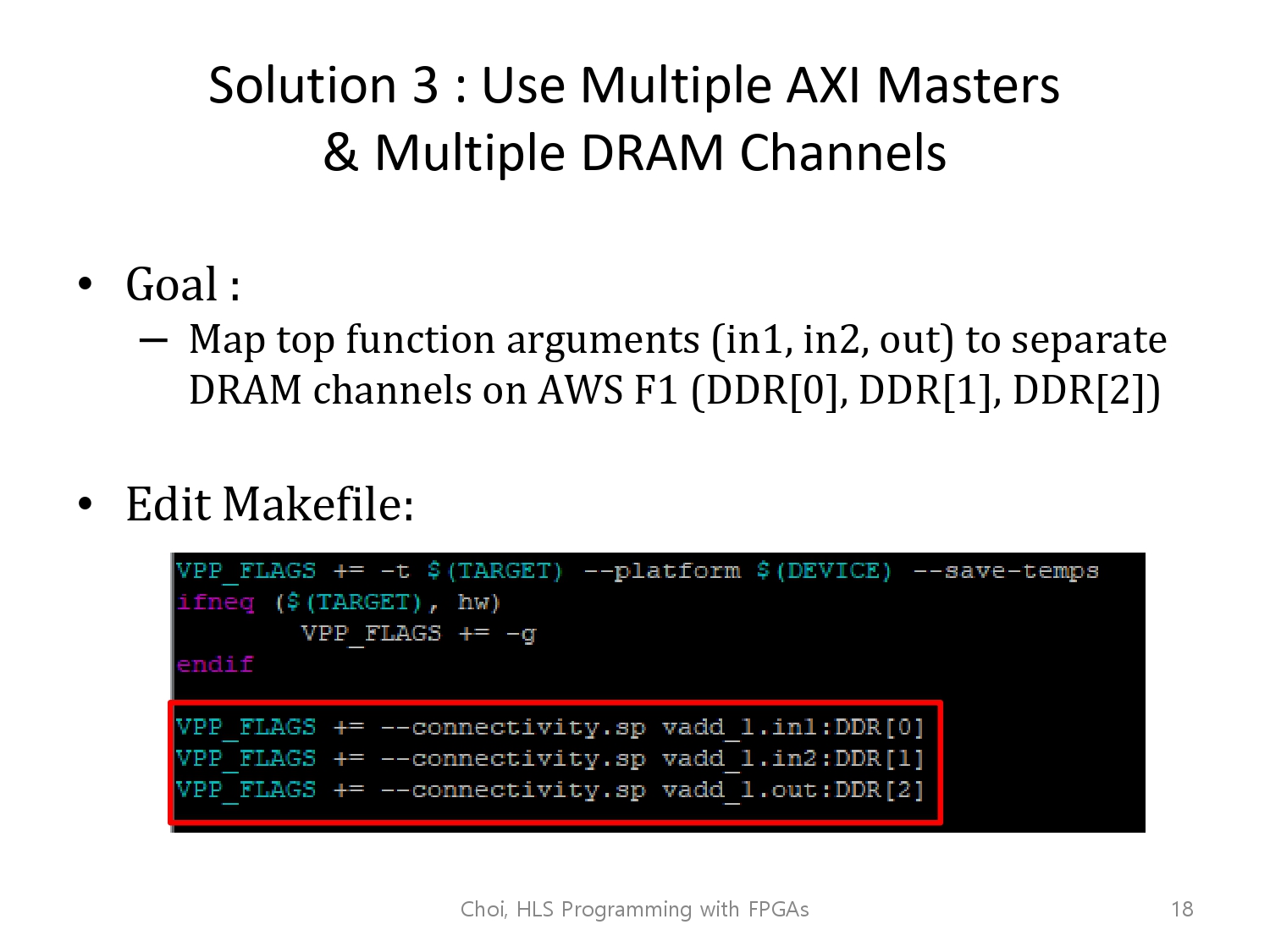
4개 중 1개의 채널로 하는 것이 아니라,
3개의 채널에 각 in1 in2 out을 할당시켜봅시다.
makefile에서 메모리 할당을 해주고,
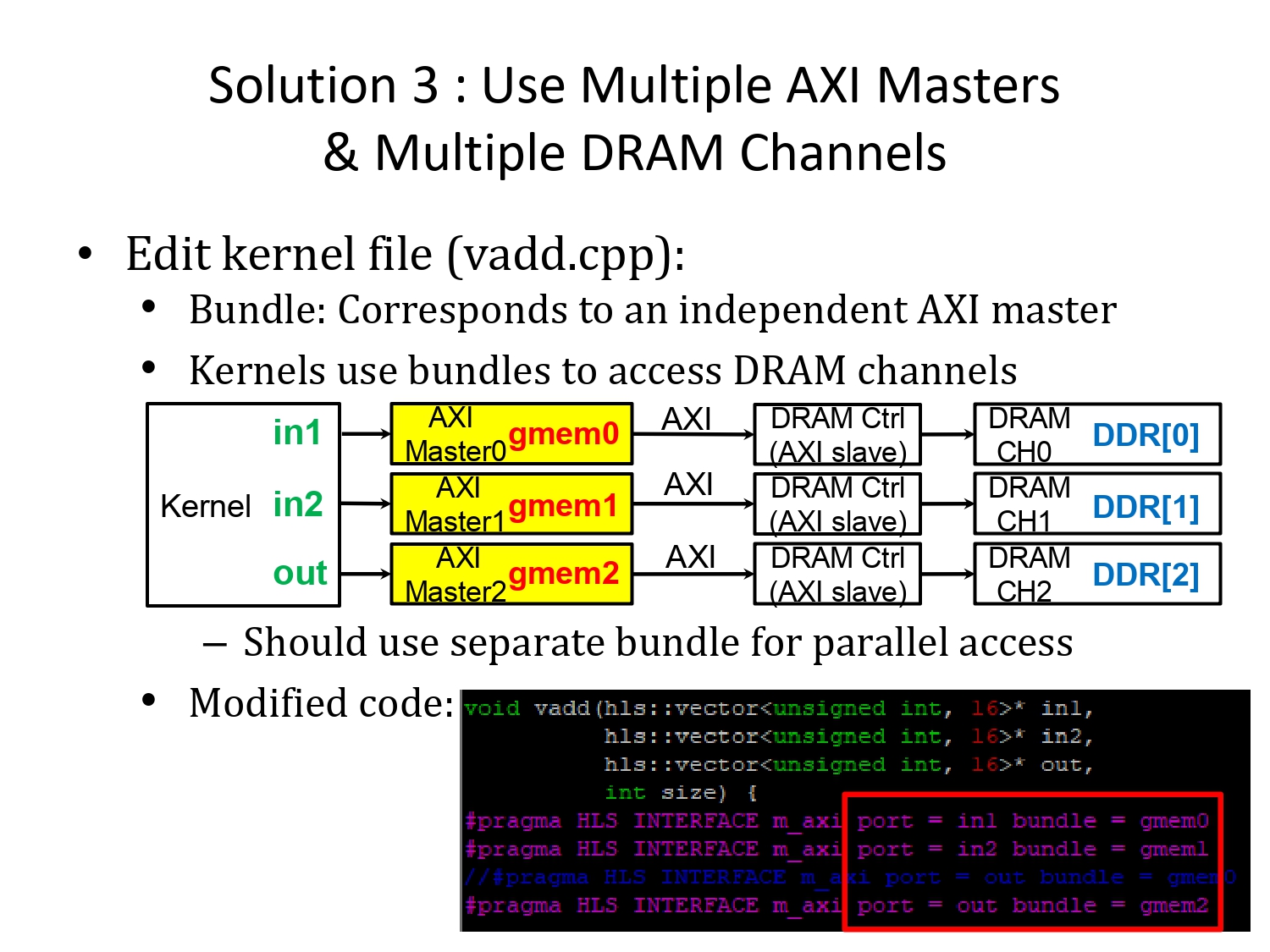
커널 파일에서 DRAM과 연결되기 위해 번들을 사용하므로, 번들을 수정합니다.
할당을 따로 해주기 위해선
각 번들의 이름을 다르게 해줘야 합니다.
다 하고 난 제 결과는,

0.288533ms의 수행시간이 나옵니다.
Data_size = 1M
time = 0.288533 ms
3 x 1000000 x 4B
1200만 바이트 /
0.000288533초
= 120억 바이트 / 0.288533초
= 11.17587GB/0.288533
38.73 GB/s = 39.2GB/s와 거의 유사합니다.
 이 멀티채널 방식을 이용할 때, 주의해야할 점입니다. 참고하도록 합시다.
이 멀티채널 방식을 이용할 때, 주의해야할 점입니다. 참고하도록 합시다.
