※ 본 포스트는 인하대학교 지능형반도체 연구실의 최영규 교수님의 허가 하에 작성되었습니다.
※ 교수님의 설명에 해당하는 내용을 제외하고, 제 의견은 노란색 글씨로 작성 하겠습니다.
※ solution에 대한 코드는 절대 제공되지 않으며, 수업진행에 필요한 모든 도움은 최영규 교수님의 자료 및 이메일을 참고하길 바랍니다.
요약 + 간단한 의견으로 구성됩니다.
자세한 내용은 반드시 강의를 참고해주시길 바랍니다.
해당 챕터는 저의 이해도가 강의 내용을 제대로 전달할만할 수준이 아니어서, 제가한 결과물만 간단하게 명시한 후 글을 마무리하겠습니다.
이론적인 설명은 반드시 강의를 참고하시길 바랍니다.
이에 대해 공부하신 분은 결과물의 비교만을 참고하시길 바랍니다.
제 실행 결과에 문제점이 있을 수 있습니다. 해당 경우는 댓글 남겨주시면 친절하게 답변하겠습니다.

HLS로 벡터곱을 연산해봅시다.
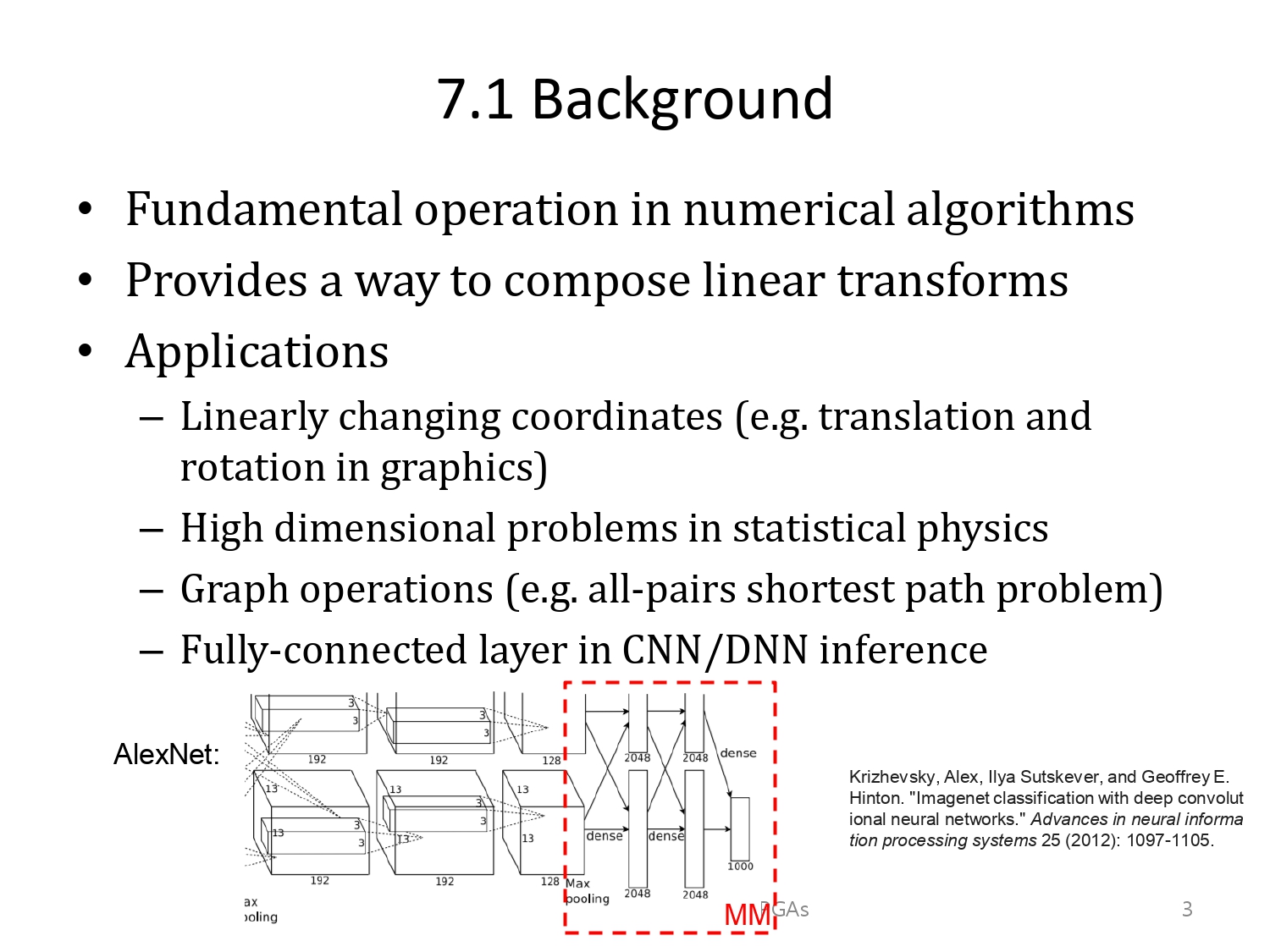
벡터곱은 수학적 알고리즘의 기본적인 요소 중 하나로, 여러군데에 쓰입니다.
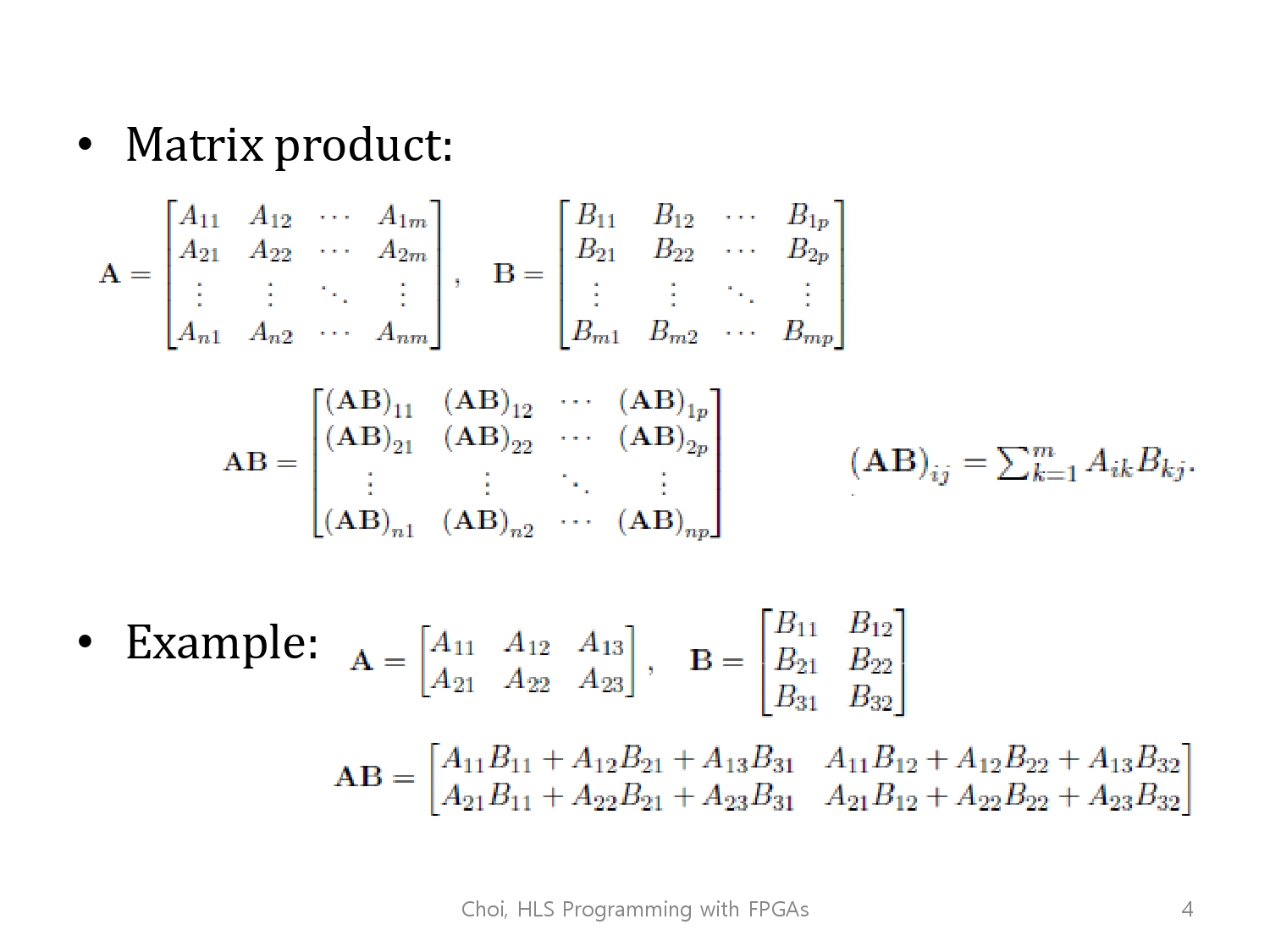
벡터곱의 연산 방식 (구글링 참조)

이론적으로 단순한 코드며, 시간복잡도는 N x P x M으로 이루어집니다
전부 동일하다면 O(n^3) 인데, 많이 빡센 복잡도입니다
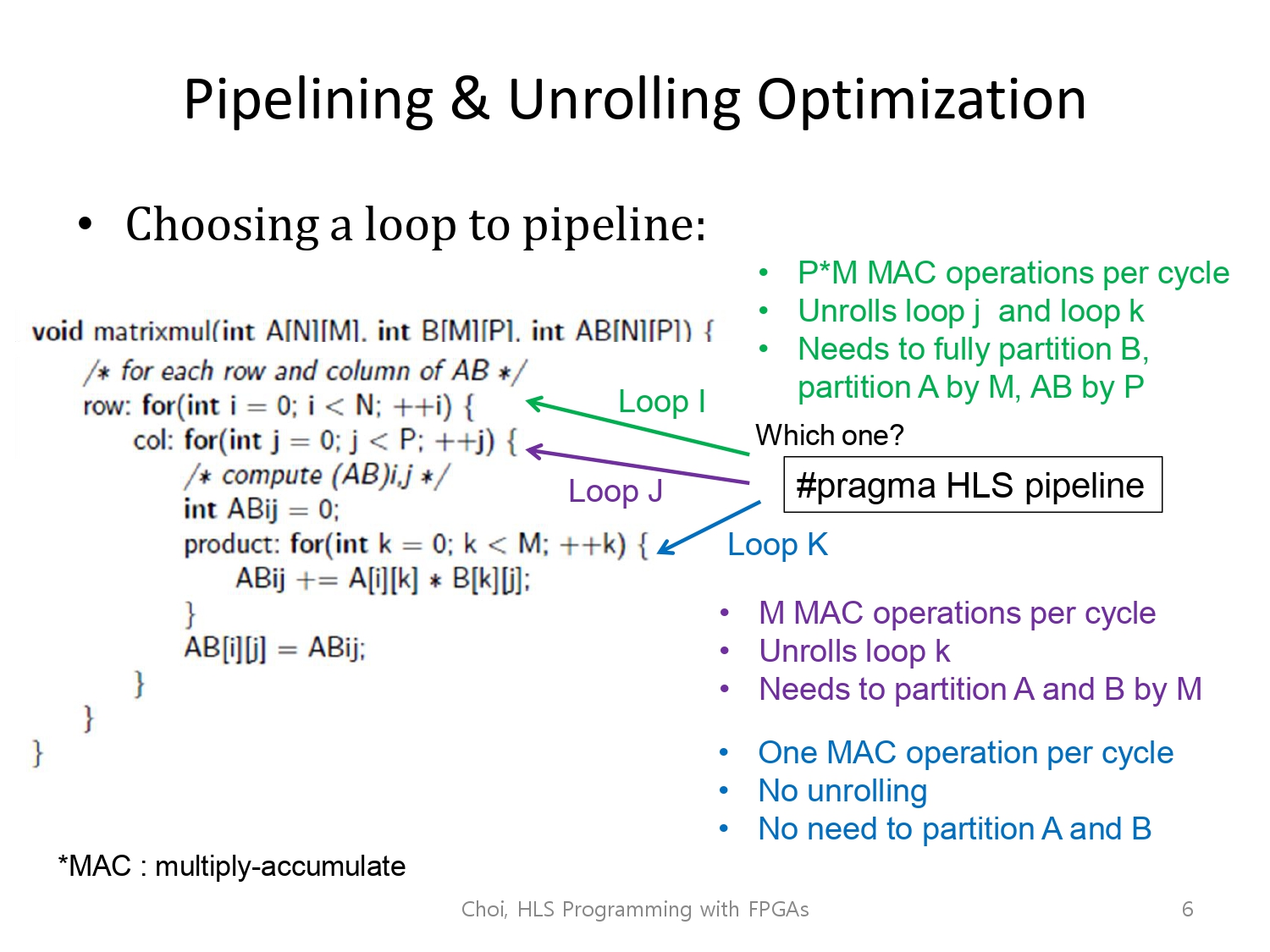
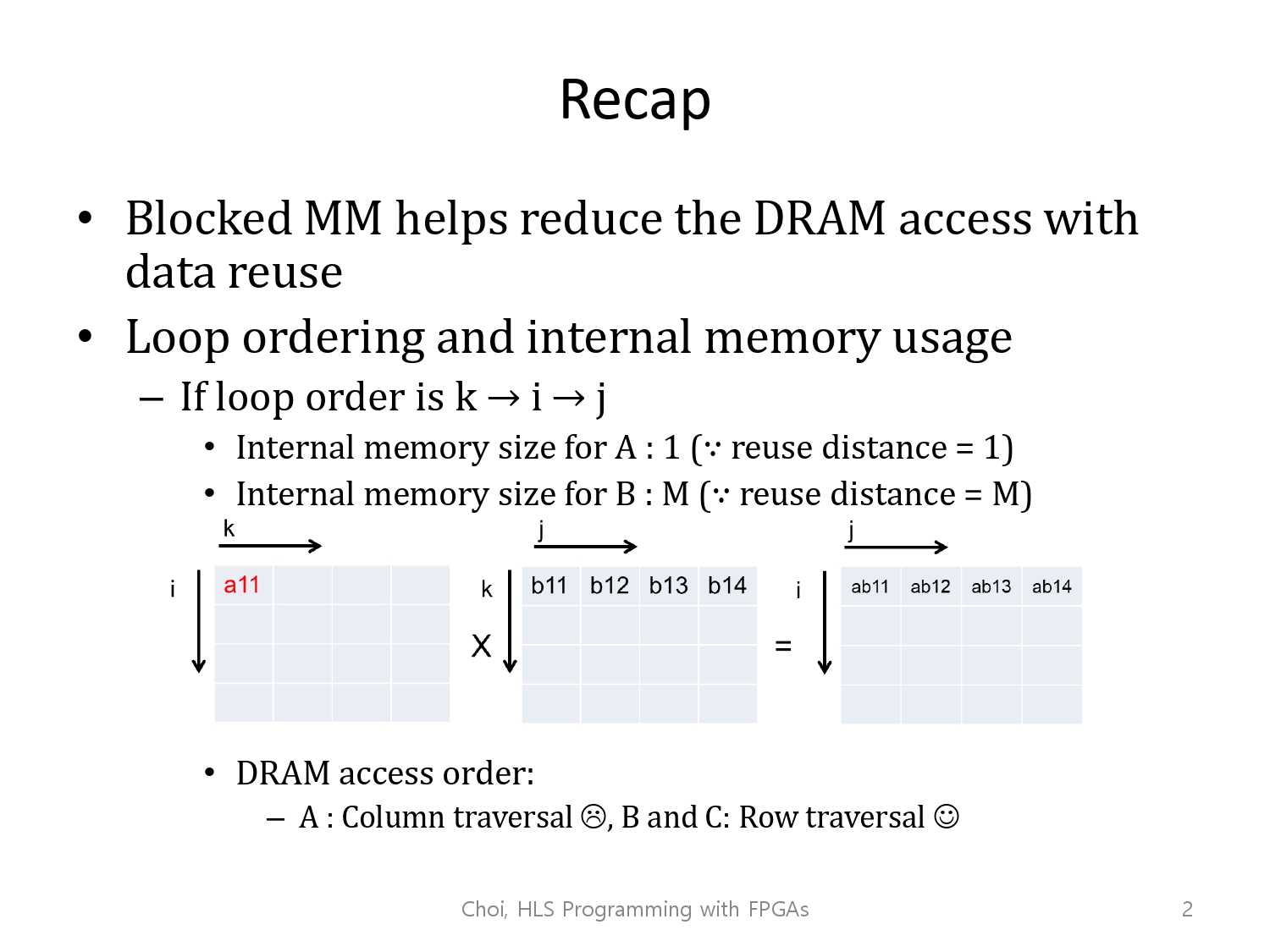
위는 참고하면 좋은 이미지
sol1. pipelining and unrolling
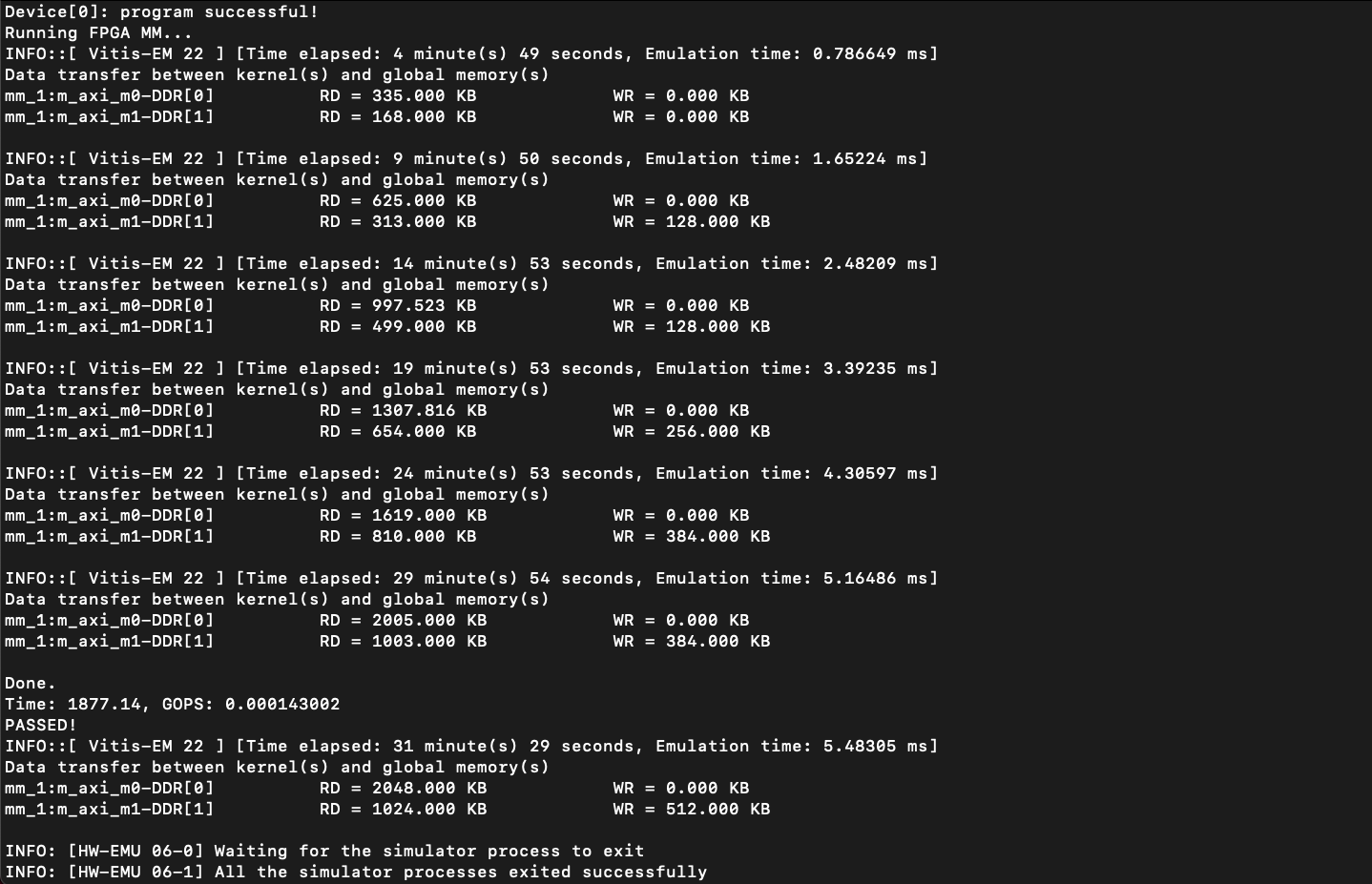
GOPS: 0.000143002 (성능)
Time: 1877 (소요시간)
sol2. Wide Bus Data Type

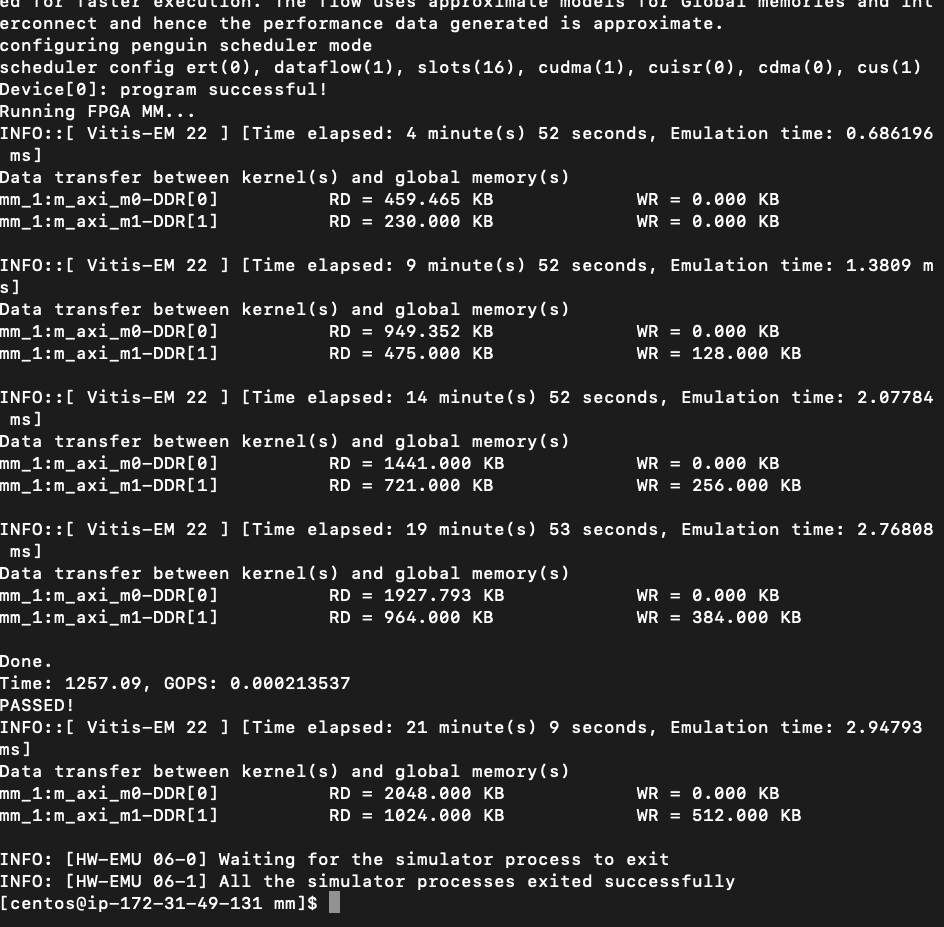
GOPS: 0.000213537
Time: 1257.09
sol3. transposed Matrix
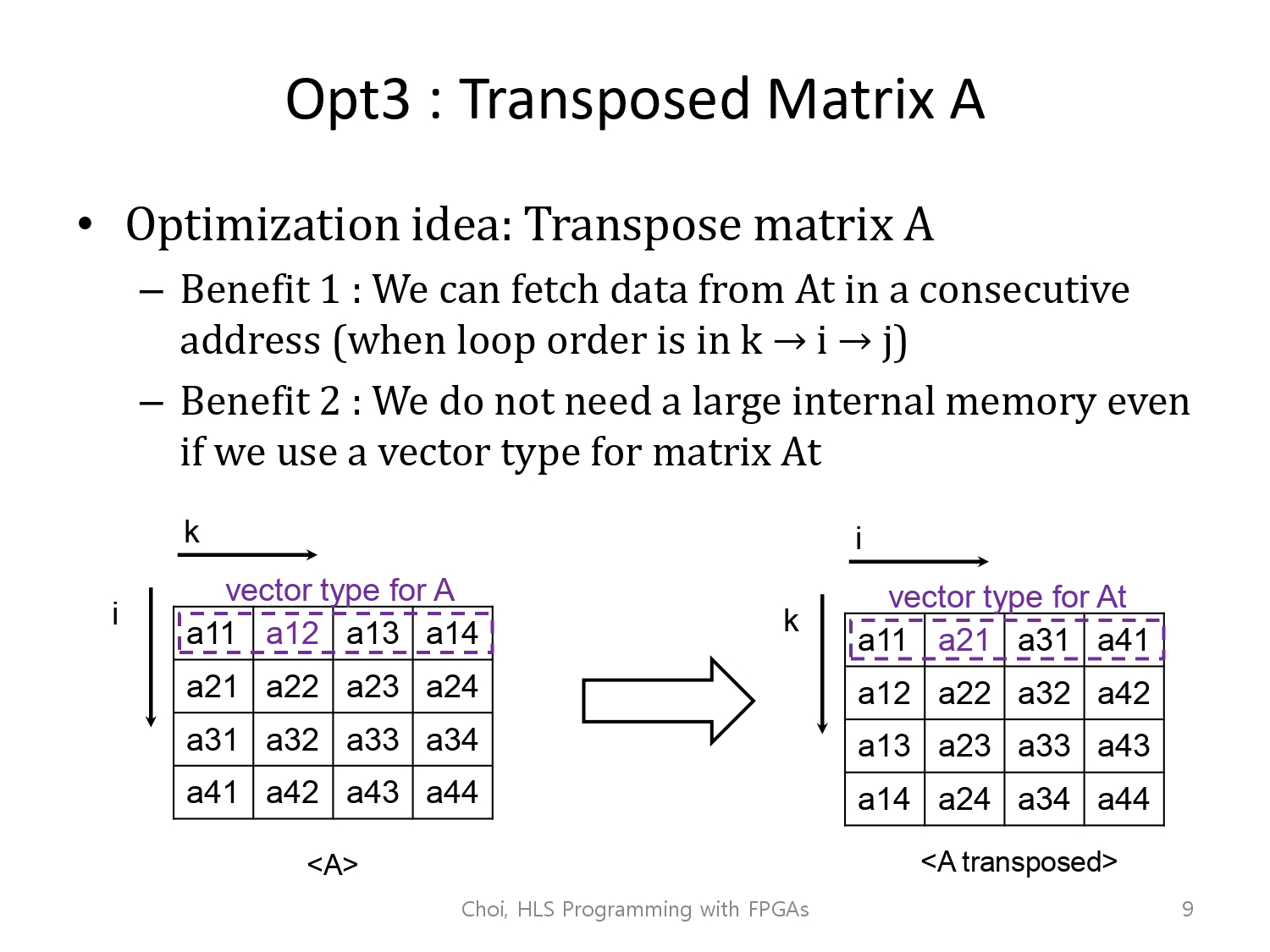
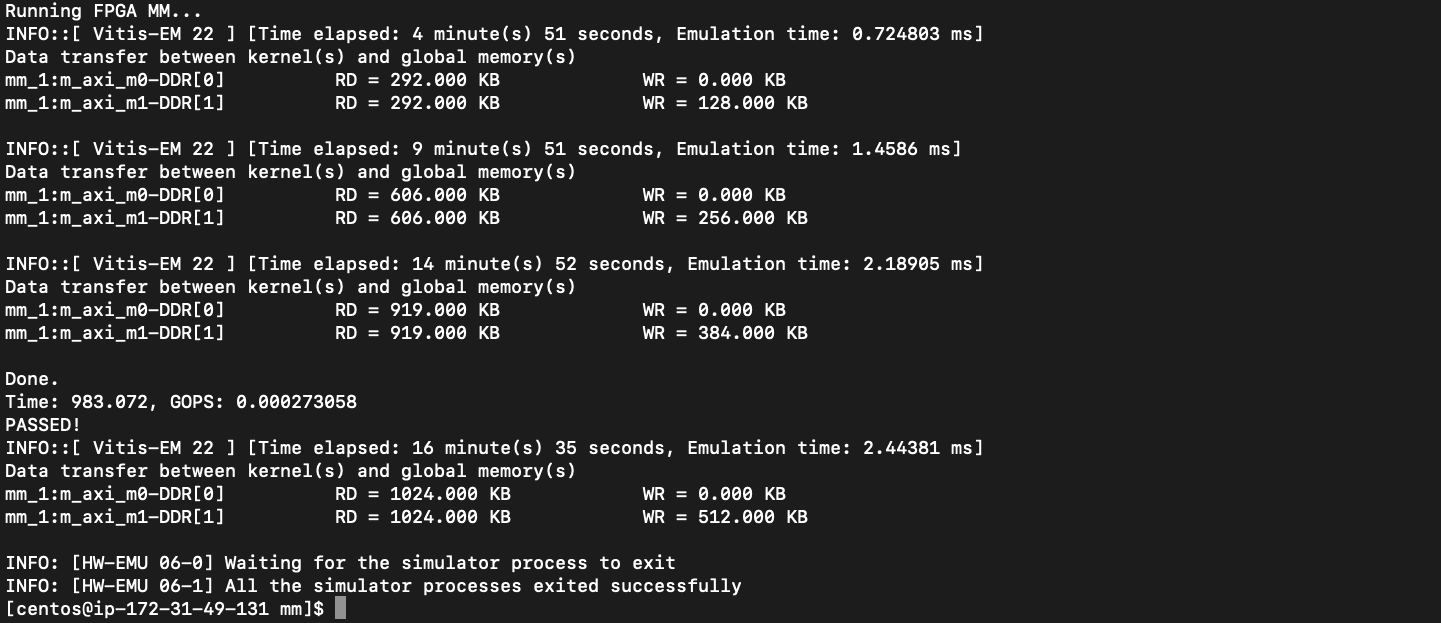
GOPS : 0.000273
Time : 983.072
sol4. Dataflow

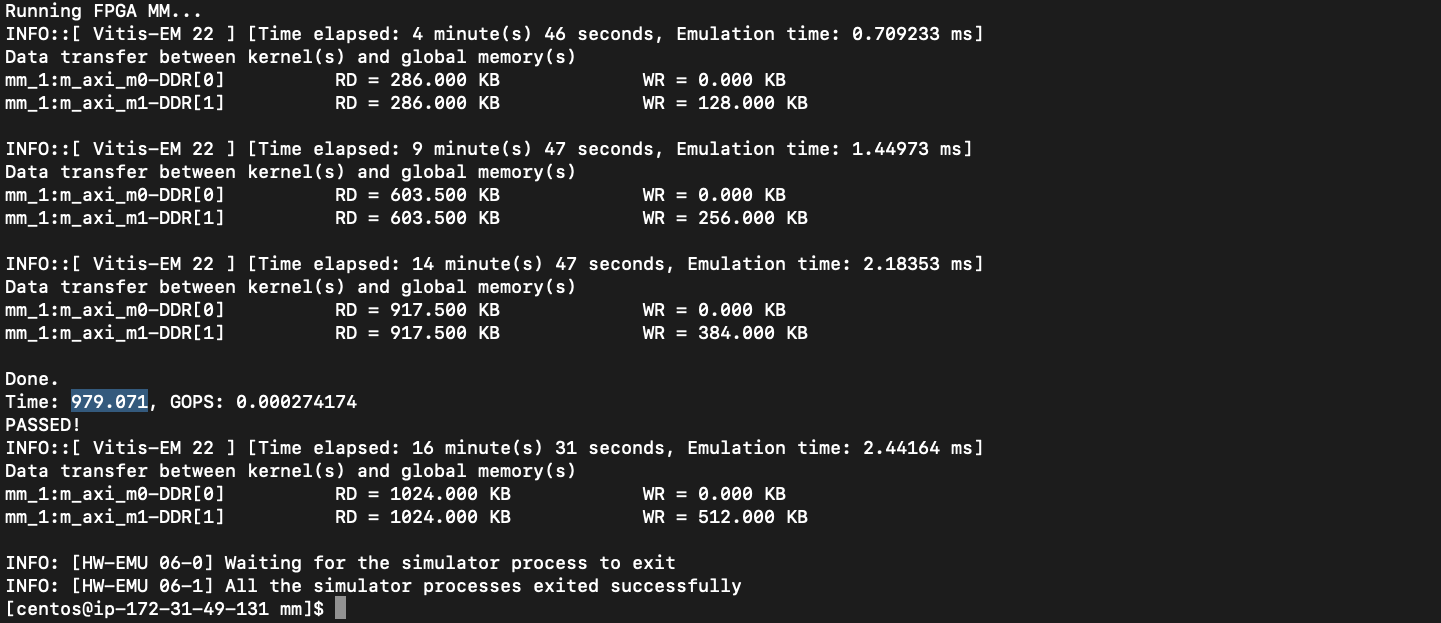
GOPS : 0.000274174
TIME: 979.071
dataflow 전과 큰 차이가 없습니다.
why?
일단 Time과 GOPS는 커널 레벨이 아닌, host파일에서의 출력코드라는 것을 알고 있어 오차가 발생할 수 있다는 것을 감안하면, 최적화가 더 진행되지 않은 것으로 볼 수 있습니다.
emulation time을 이용하여 계산을 하게 된다면, 약 110의 GOPS가 나오게 됩니다.
수업에서 이상적인 최종 GOPS로 113이 나온 점을 고려했을 때, 거의 동등한 수치라고 볼 수 있어, dataflow 수행 전에 해당 최적화가 된 상태라고 예상했습니다.
그에 따라 교수님께 문의를 드렸습니다.
Dataflow는 mem-compute overlapping을 잘 하지 못할 때 manual하게 해주는 것입니다.
는 답변을 받았고, 이미 잘되고 있다면 굳이 필요 없다는 답변을 받았습니다.
이상으로 HLS-FPGA에 대한 모든 작성글을 마무리하겠습니다.
공부하다 모르는 부분이 있거나, 해당 분야에 관심이 있다면, 글 상단의 교수님의 의견을 구하길 바랍니다.
감사합니다.
