※ 본 포스트는 인하대학교 지능형반도체 연구실의 최영규 교수님의 허가 하에 작성되었습니다.
※ 교수님의 설명에 해당하는 내용을 제외하고, 제 의견은 노란색 글씨로 작성 하겠습니다.
※ solution에 대한 코드는 절대 제공되지 않으며, 수업진행에 필요한 모든 도움은 최영규 교수님의 자료 및 이메일을 참고하길 바랍니다.

1장 . Introduction
본 과정은 High Level Synthesis Programming의 세부과정을 배울 것이며 이 과정은 학부생 4학년, 혹은 대학원 1학년에 해당합니다.
본 과정은 C언어와 논리 회로에 대한 이해를 갖추고 있다는 전제 하에 수업을 진행하며, 디지털 시스템 디자인(설계) 및 컴퓨터조직(컴퓨터구조)를 수료하고 있으면 더 좋습니다.
Aws와, Linux 사용법에 대해 알고 있으면 더 좋습니다.

해당 수업에서는 이런 것들을 배웁니다.
- HLS(High Level Synthesis) 코드를 프로그래밍하는 방법
HLS에 대한 설명, 정의는 추후에 나옵니다.
- HLS 코드를 최적화하는 방법
- HLS 코드로부터 FPGA bitstream을 생성하고, FPGA 보드에서 이를 실행하는 방법
저는 FPGA는 우리가 사용하고자하는 회로보드의 명칭이며, 비트스트림은 이를 설정하고 구동시켜주는 커널파일이라고 이해했습니다.
- Amazon Web Service로 F1 인스턴스를 생성하는법
인스턴스는 클라우드로 사용할 컴퓨터를 의미하며, F1은 그 컴퓨터의 종류입니다.
해당 수업에서는 이런 것들은 배우지 않습니다.
- HLS 컴파일러를 개발하는법(개선하는법)
- FPGA를 빌드하는법
본 강의는 HLS의 사용자 지향의 코스이며, HLS 도구 개발자들을 위해 의도된 강의가 아니 때문입니다.
FPGA 보드 자체의 빌드에 대해 배우진 않는다는 의미입니다.
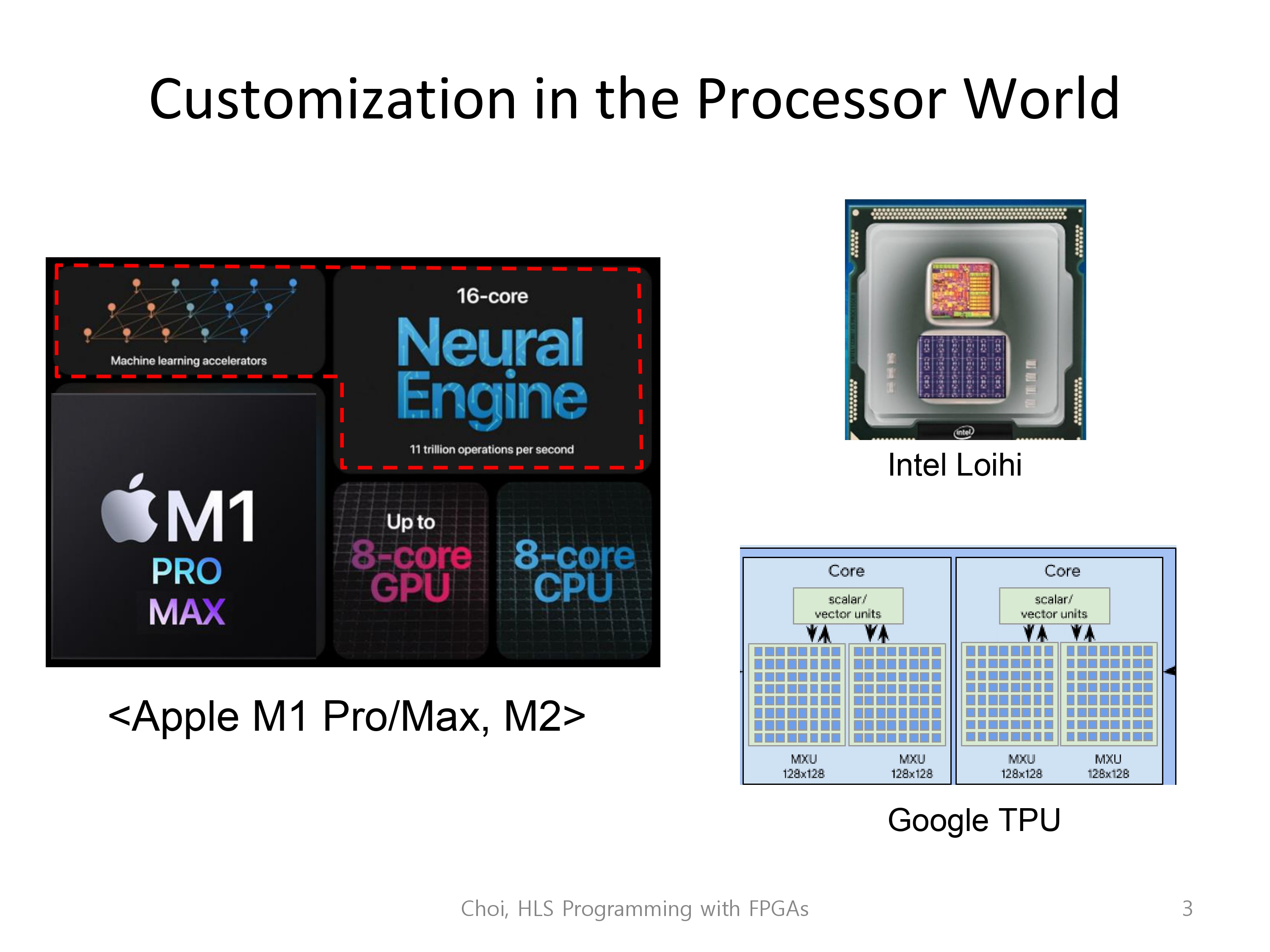
최근 2년 간의 칩 트렌드를 보면, 많은 칩이 생산되었고, 많은 칩들의 그들만의 커스텀 가속화를 탑재하고 있습니다.
- 애플의 M1, M1 Pro/Max, M2에 탑재된 뉴럴네트워크와 머신러닝
- 인텔의 Loihi 칩이 가진 스파이킹 뉴럴 네트워크 가속화
- 구글의 TPU의 systalic array architecture
들이 그 예시이며, 전부 사용자화를 통해 적은 영역과 파워를 소모하며 고성능을 냅니다.
이에 대한 설명은 8page에서 설명하겠습니다.
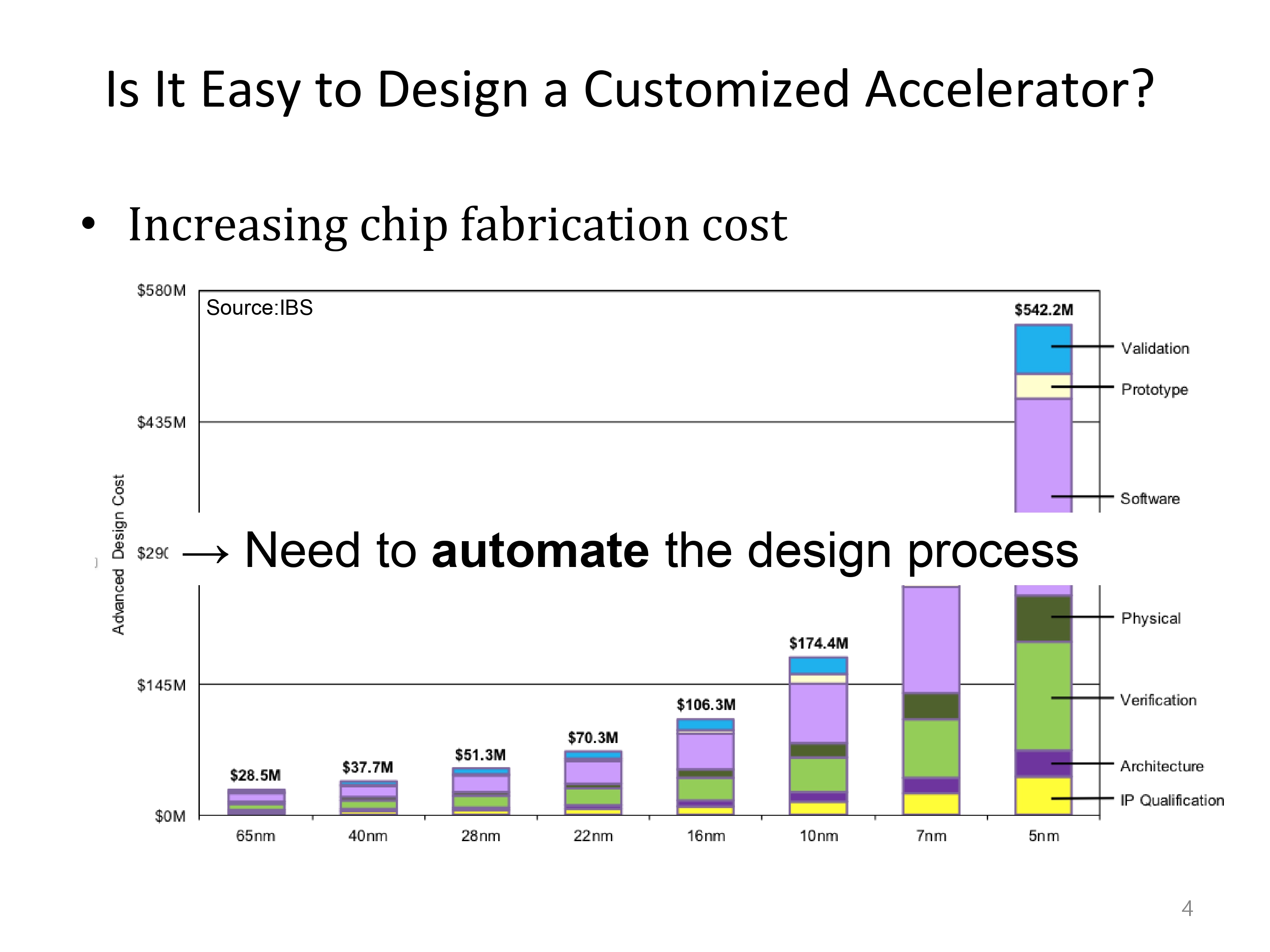
하지만, 이러한 사용자화는 굉장히 높은 비용을 수반합니다.
수백만 달러의 비용이 발생하며, 공정의 집적도에 따라 그 비용은 기하급수적으로 비용이 증가하기에, 디자인과정을 자동화시킬 필요가 있습니다.
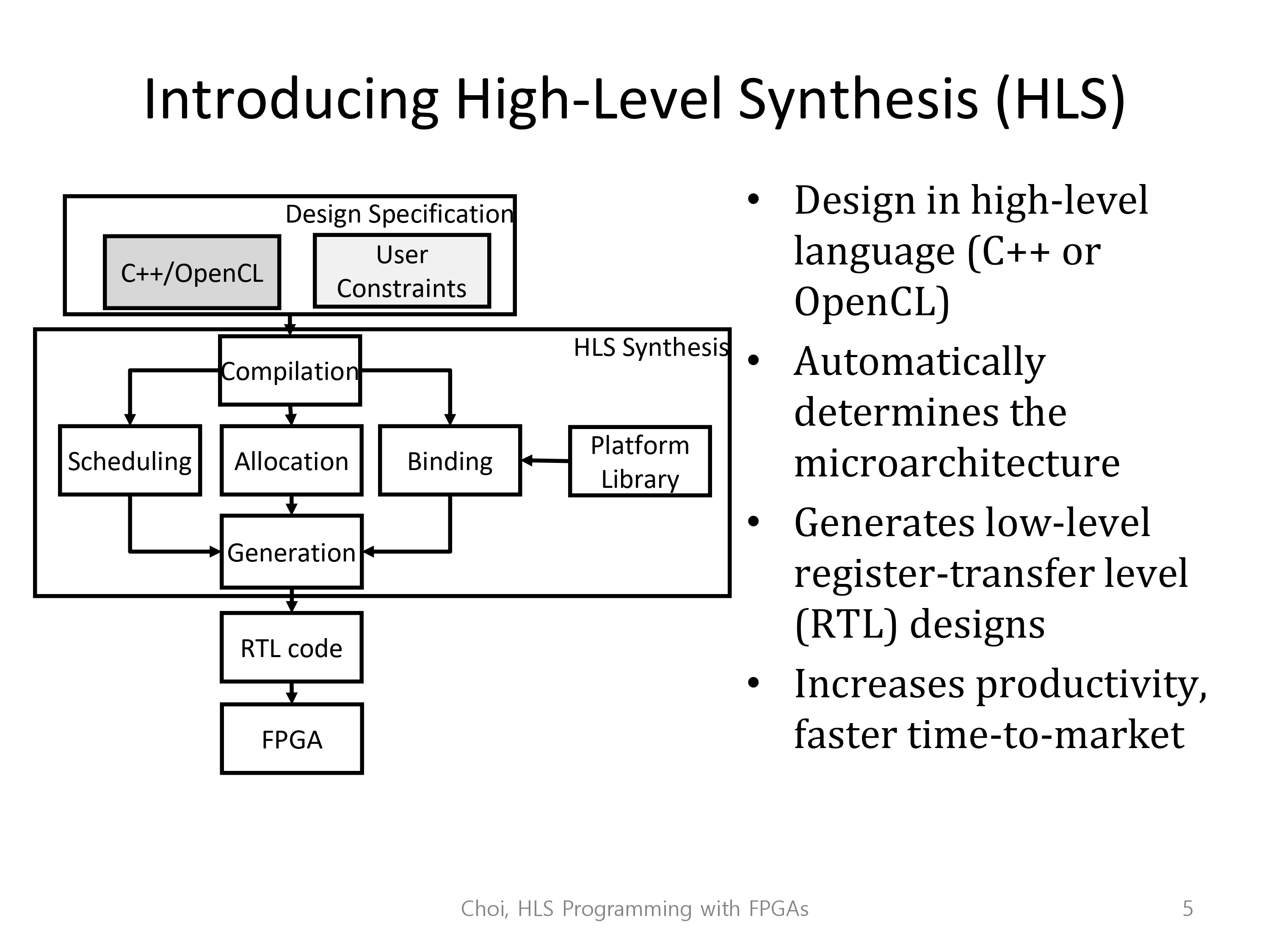
디자인적 수고를 덜기 위해서 HLS 혹은 High Level Synthesis 둘을 사용하기로 약속했습니다.
이는 C++이나 OpenCl 같은 하이레벨 언어로 작성이 가능하며, 자동으로 미세공정을 정의해주고, RTL(register-transfer level) 디자인을 생성해줍니다.
RTL은 논리회로적으로 레지스터와 로직회로로 세부 시스템을 설계하는 단계를 말합니다.
이는 과감하게 디자인 비용을 줄여줄 뿐만 아니라(시간, 돈 등), 시장으로의 진출 또한 빠르게 만들어줍니다.
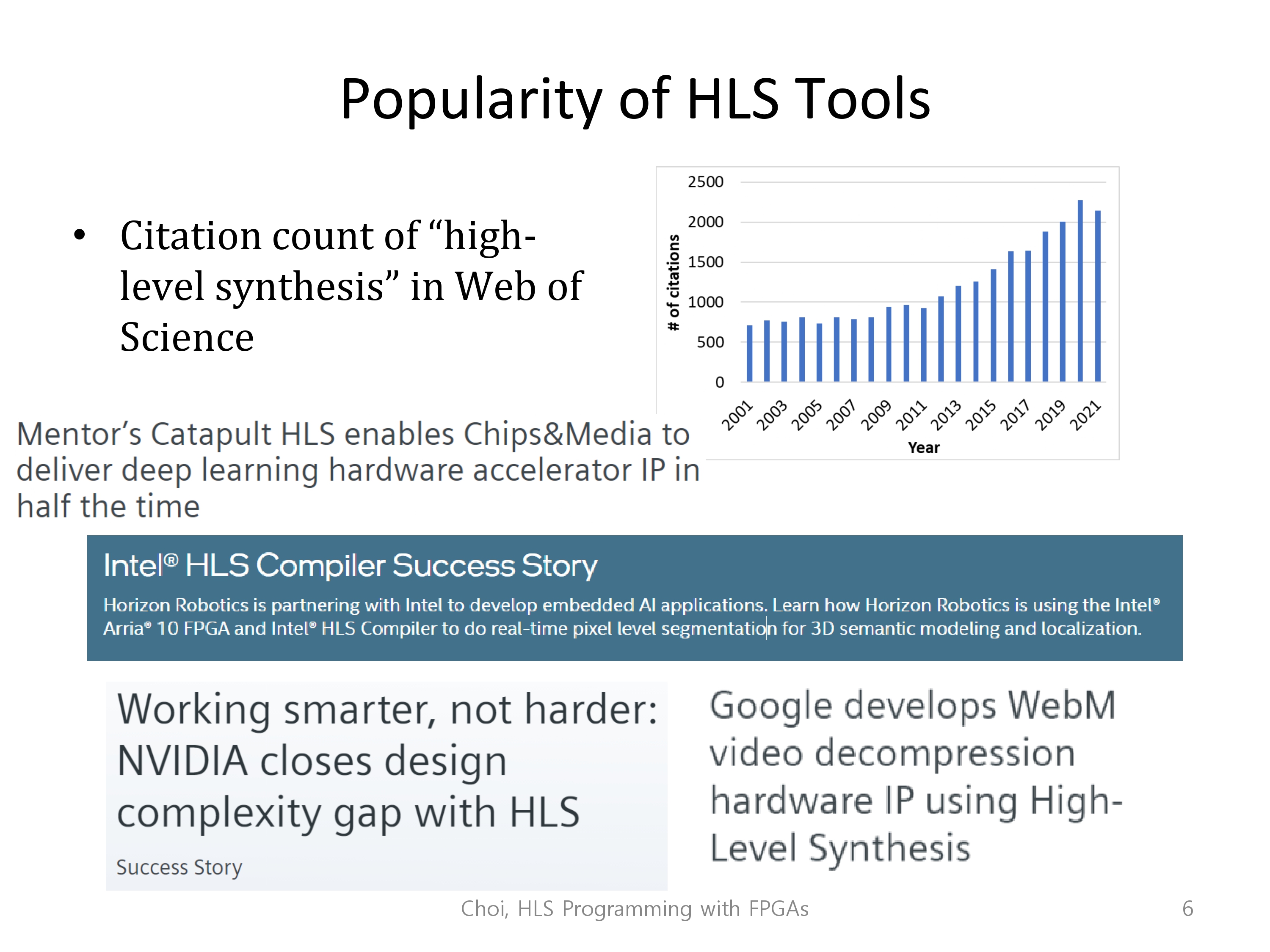
이런 장점 때문에, 학계에서 HLS툴을 사용하는 빈도가 굉장히 늘고 있습니다. 실제로 인텔, 엔비디아, 구글에서 많은 성공사례(적용사례)를 보여주고 있습니다.

다음 사례는 Matrix-vector multification(행렬곱)에 대한 코드입니다.
HLS는 기존의 C언어 기반의 코드를 그대로 사용가능하고, 단자 #pragma라는 코드를 추가함으로서 간단하게 최적화를 진행해 20줄 내외의 코드로 작성이 가능합니다.
다만, 코드를 작성하는 스타일이 HLS 툴의 자체적인 최적화에 영향을 미칠 수 있는데, 이에 대해선 수업에서 다룰 예정입니다.
각 pragma 명령어가 의미하는 바는 추후에 다룰 예정입니다.
하지만, Verilog같은 전통적인 HDL 언어로 작성하게 될 경우, 인터페이스를 정의하는데만 수천 줄의 코드가 필요하고, 다른 부분에서 또 수천줄의 코드를 필요로 합니다.
HDL은 Hardware Description Language의 약자로, low레벨부터 세부적으로 설계를 해야만 하는 언어이며, 학습하기 어려운 언어라고 이해하고 넘어갔습니다.
결과적으로, HLS는 사용자화에 있어 획기적으로 개발시간을 줄여줍니다.
그렇다면, HDL로 작성된 것에 비해 HLS로 작성된 코드의 성능이 뒤떨어지는 것이 아니냐?는 의문이 들 수 있습니다.
하지만, 최근의 HLS 컴파일러에 이르러서는 이는 사실이라 할 수 없습니다.
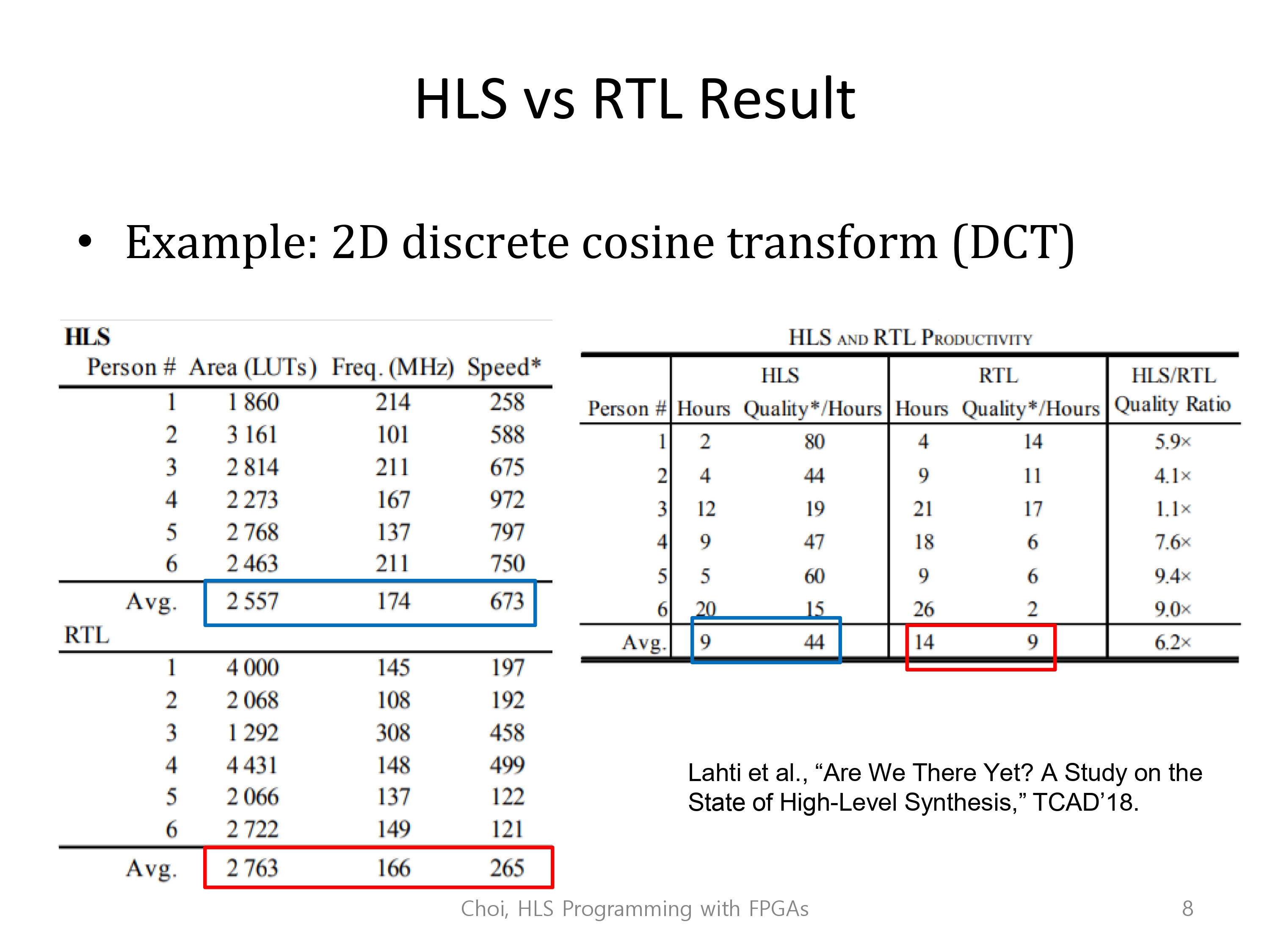
DCT(2D discrete cosign transform) 연산에 대한 설계에서의 비교를 따르면,
HLS tool을 사용한 프로그래머가 사용한 영역(LUT등)이나 자원은 비슷하게 사용하면서, 2배는 빠르게 프로그램을 실행할 수 있었습니다.
프로그램이 구동하는 시간(성능)을 의미하는 듯합니다.
개발하는데 걸리는 시간 또한, HLS tool을 사용한 사용자가 3분의 2정도의 시간밖에 걸리지 않았다고 나옵니다.
why?
개발속도에서 HLS tool이 월등한, 개발해야하는 코드의 줄 수가 훨씬 짧게 때문이라 설명이 가능합니다.
뿐만 아니라 프로그램의 성능조차도 hls가 월등한데, 이는 HLS에서 해주는 High level에서의 최적화가 사용자가 직접하는 최적화보다 월등하기 때문이라 설명됩니다.
High level 수준에서 사용 가능한 기술과 플랫폼을 보다 잘 활용한다고 설명해주셨습니다. 제 해석은, 사람이 최적화를 할 때는 모든 경우의 수를 고려하기 힘들지만, hls는 모든 상황에 사용가능한 모든 경우의 수의 최적화 기술이 '자동적으로' 사용되기 때문이라고 생각합니다.
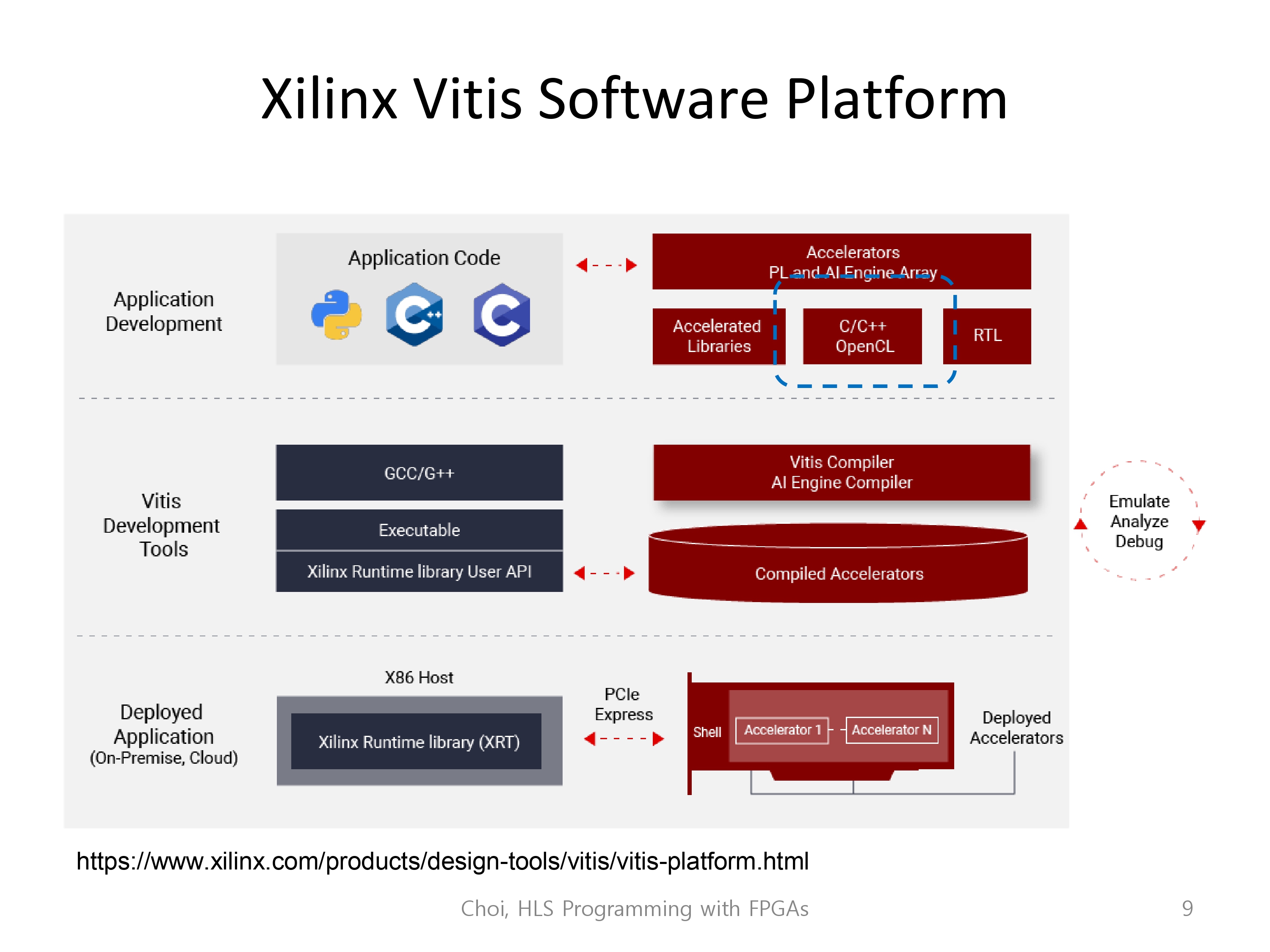
우리가 수업에서 사용할 소프트웨어는 xilinx vitis software platform 입니다.
이 소프트웨어는 application level의 코드를 가져와 가속기로 변환합니다. Vitis는 그 외에도 다양한 개발툴을 지원하는데, emulate, analyze, debug 모두를 지원합니다.
우리가 가장 자주 사용할 도구는 vitis의 High-Level syntehsis routine 입니다만, 모든 software stack을 사용하긴 할 겁니다.

Xilinx Vitis HLS는 실제로 Vivado HLS의 후속작이고, 자일링스는 이름을 2020년에 바꿨습니다.
C, C++, openCL언어에 대해서 컴파일, 시뮬레이트, 디버깅하며, RTL code를 생성해줍니다.
RTL 코드 - 5page 개인설명 참고
우리가 지금 Vitis의 HLS를 사용하는 까닭은 가장 인기 있는 HLS 툴이기 때문이고, 2018년도의 조사에 따르면 3분의 1정도의 학술지가 Vivado HLS(이름이 바뀌기 전의 Vitis HLS)로 작성되었습니다.
이는 큰 점유율이며, 2등과는 꽤 격차가 큽니다.
그래서 확실한 것은 Vitis HLS 툴이 근래에 들어 학계에서 가장 인기 있는 HLS툴이라고 할 수 있습니다.
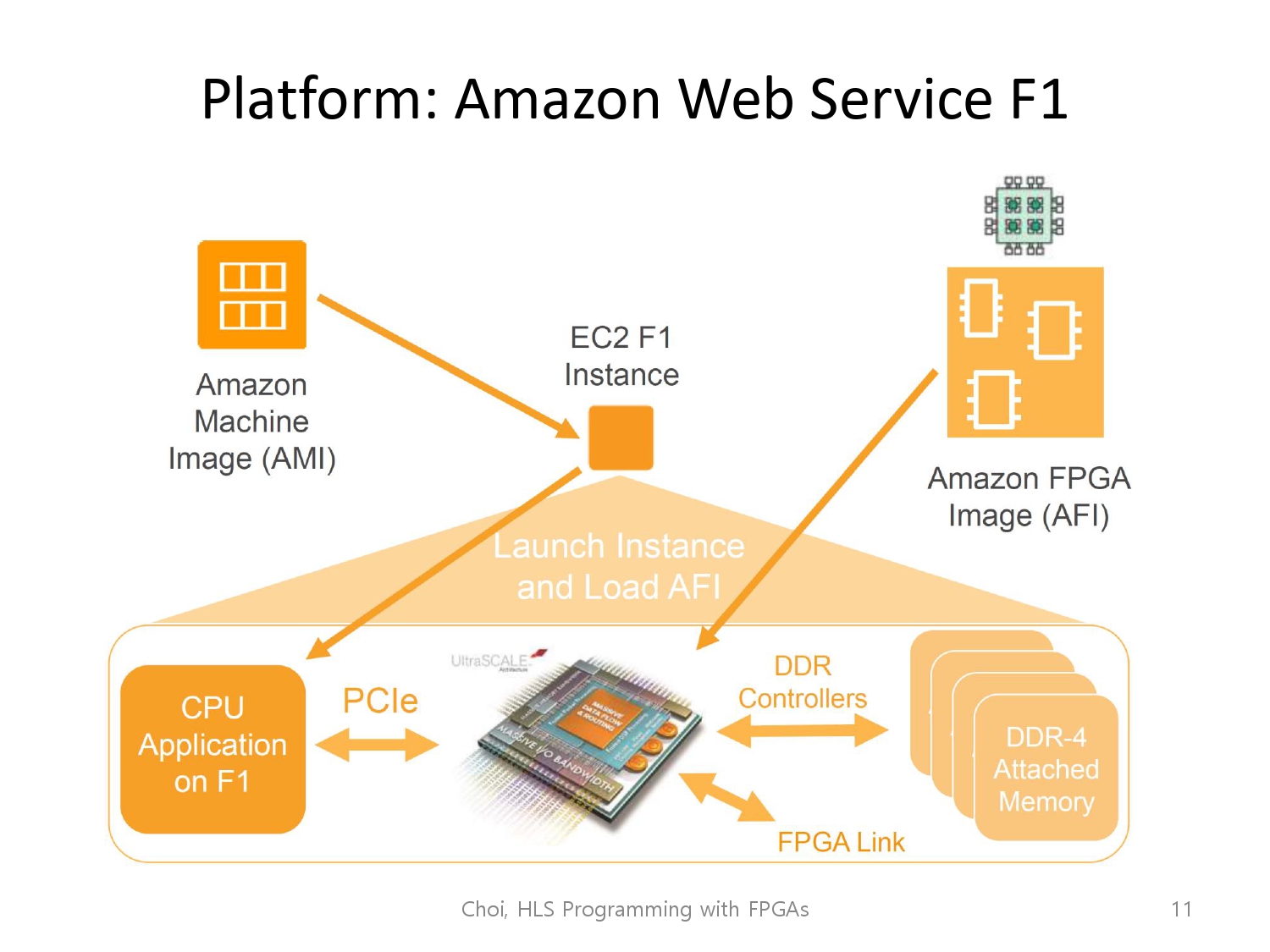
우리가 수업에서 사용할 플랫폼은 Amazon Web Service의 f1 instance를 사용할 것입니다.
인스턴스명인 F1의 f는 fpga 혹은 field programmable gate arrays를 의미합니다.
aws는 클라우드 컴퓨터 서비스이며, 사용자는 번거롭게 자가소유의 서버를 직접 관리할 필요 없이 손쉽게 fpga를 탑재하고 있는 원격 서버 컴퓨터를 사용할 수 있습니다.
사용자는 이를 이용해서 실제 fpga를 탑재한 컴퓨터에서 사용자의 소프트웨어(fpga 커널 소프트웨어)를 구동해볼 수 있습니다. 우리는 이를 통해 생성한 회로의 에뮬레이션, 디버깅, 성능분석을 해볼 것입니다.
제가 이해한 바로 정리를 해보겠습니다.
실제로 프로그래밍을 하는데 있어서 자신의 컴퓨터(로컬)에서 모든 것을 하기엔 굉장히 제약이 큽니다.
따라서 클라우드 컴퓨터를 원격으로 연결해서 사용해야하는데, aws를 리눅스 기반의 클라우드 컴퓨터(인스턴스)라고 불리는 컴퓨터를 빌릴 것입니다.
이 컴퓨터는 실제로 해외, 혹은 국내에 존재하는 물리적인 컴퓨터이며, 이 컴퓨터는 모델이름(F1 등)에 따라 하드웨어의 차이가 존재합니다.
이 중 저희가 필요한 기능과 칩을 탑재한 컴퓨터(이하 인스턴스)를 선정하고, AWS회사 측에서 제공해주는 여러 환경이 설치된 인스턴스에서 (이하 플랫폼) 저희가 사용하기로 한 Vitis HLS 소프트웨어를 구동할 예정입니다.
뿐만 아니라 aws에서 이용가능한 컴퓨터는 실제 fpga칩이 있는 컴퓨터도 있기에, 저희가 만든 소프트웨어를 그 칩에서 직접 구동해볼 수 있습니다.

HLS를 이용해서 설계를 하는 이유는 위에서 언급했는데, 회로를 설계하는데 있어 HLS를 사용하는 장치로 어째서 FPGA를 사용하는지에 대해 알아보겠습니다.
HLS(high-level synthesis)로 ASIC(application-Specific Integrated Circuit)을 직접 만들면 되는 것 아닌가?에 대한 의문이 드는데, 이는 맞는 말이지만 실제로 회로를 제작하는데에는 보통 몇달은 걸릴 뿐더러, 비용도 굉장히 비싸서 이를 고려하면 asic에 대한 시뮬레이션만 진행이 가능합니다.
그에 반해, fpga는 회로에 대해 synthesize하고 reprogramming 하는 것이 고작 몇 시간 안에 가능하기에, 한번 회로를 직접 실행해보고 다른 의견을 얻는 것이 가능합니다.
또한 HLS를 연구하는 목적 자체에 FPGA의 특성이 부합하는 것도 이유 중 하나입니다. 이후 fpga의 특징에 대해서 더 자세하게 배울 예정입니다.
FPGA와 ASIC의 차이에 대해 쉬운 설명을 덧붙이자면, FPGA는 회로 자체에 기본적으로 용도가 정해져 있지 않고, 원하는 대로 내부 구조를 손쉽게 설정하여 사용하는 칩이지만, ASIC은 생성이되는 순간 용도가 정해지고 다른 용도로 사용하기 위해선 칩 자체를 새로 생산해야합니다.
더 쉽게 설명을 드리자면, FPGA는 레고브릭 같은 경우고, 회로는 건담 프라모델 같은 경우라 보스면 되겠습니다. 레고는 다른 목적으로 재조립이 가능하지만, 건담은 틀로 찍어서 나오기 때문에 다른 틀로 새로 찍어내지 않는 이상 다른 목적이 불가능합니다.

저희가 수업에서 사용할 교재의 이름은 Parallel Programming for FPGAS 혹은 짧게는 HLS Book라 불리는 책으로, 해당 링크에서 무료로 전체 책을 다운받을 수 있습니다.
최영규 교수님을 비롯한 작성자는 이 책의 저자이신 Ryan Kastner, Janarbek Matai, Stephen Neuendorffer 분들에게 이 책을 무료로 배포해주신 것에 대한 감사를 표합니다.

최영규 교수님께서는 AWS korea로부터 이 수업을 하는 것에 대한 지원을 받으셨습니다.또한, 이 환경을 세팅하는데 도움을 주신 김정한, 원유훈 님께 감사를 표합니다.
이 코스는 상단의 4분들과 협력을 하고 있습니다.
마지막으로 인하대의 전인성분께, 슬라이스 자료를 모아주신 것에 대한 감사를 표하겠습니다.
이상으로 0장 강의에 대한 정리를 마치겠습니다.
읽어주셔서 감사드리고, 오타 지적 및 피드백, 질문 환영입니다!!
1장에서 뵙겠습니다.
