Chapter 1. Introduction


수업 목표입니다.
-
FPGA의 architecture에 대한 설명
-
HLS 디자인의 성능에 대한 특성화
-
CPU와, FPGA가 하는 computation의 차이에 대한 설명

- HLS(High-level synthesis) tool?
- High Level 언어(C/C++ 등)으로 작성된 설계를 받아서, 세부적인 RTL micro-architecture(베릴로그 같은)를 생성해줍니다.
- 디자이너가 귀찮은 세부적인(각각의) 레지스터와 cycle to cycle 연산보다는, 전체적인 구조에 대한 의문(설계)에만 집중할 수 있게 해줍니다.
자잘하고 세부적인 설계는 HLS가 자동으로 해주기 때문입니다.
- HLS에 의해 나온 결과물(RTL file)은, on-board에서 작동하는 FPGA bitstream로 합성될 수 있습니다.

HLS가 자동으로 해주는 것들
- 알고리즘에서의 동시성, 평행성을 분석해내고, 이를 악용(적용)해줍니다.
- 중요한 경로에서 레지스터를 넣어 원하는 clock frequency를 도달해줍니다.
- control logic을 생성하고, datapath를 이어줍니다.
- 시스템의 나머지에 대한 인터페이스를 구현해줍니다.
- 데이터를 저장된 요소에 매핑해줍니다.
- computation을 논리 요소에 매핑해줍니다.

하지만 gcc 같은 c언어 컴파일러와는 다르게, 한계가 존재 합니다.
HLS의 한계
- 직접 메모리 할당은 불가능합니다.(malloc, free, new 등)
- 시스템 콜이 불가능합니다.(exit(), printf() 등)
- 재귀호출이 불가능합니다.
- 포인터 사용이 불가능합니다.
- 스탠다드 라이브러리에 대한 사용이 굉장히 제한적입니다. (math.h 같은 일부 라이브러리만 사용이 가능합나, 알고리즘 라이브러리는 사용불가)
etc) 이런 곳에서 사용 가능한 것들에 대해 관심이 있으면 google scholar에서 검색해서 알아볼 수 있습니다.
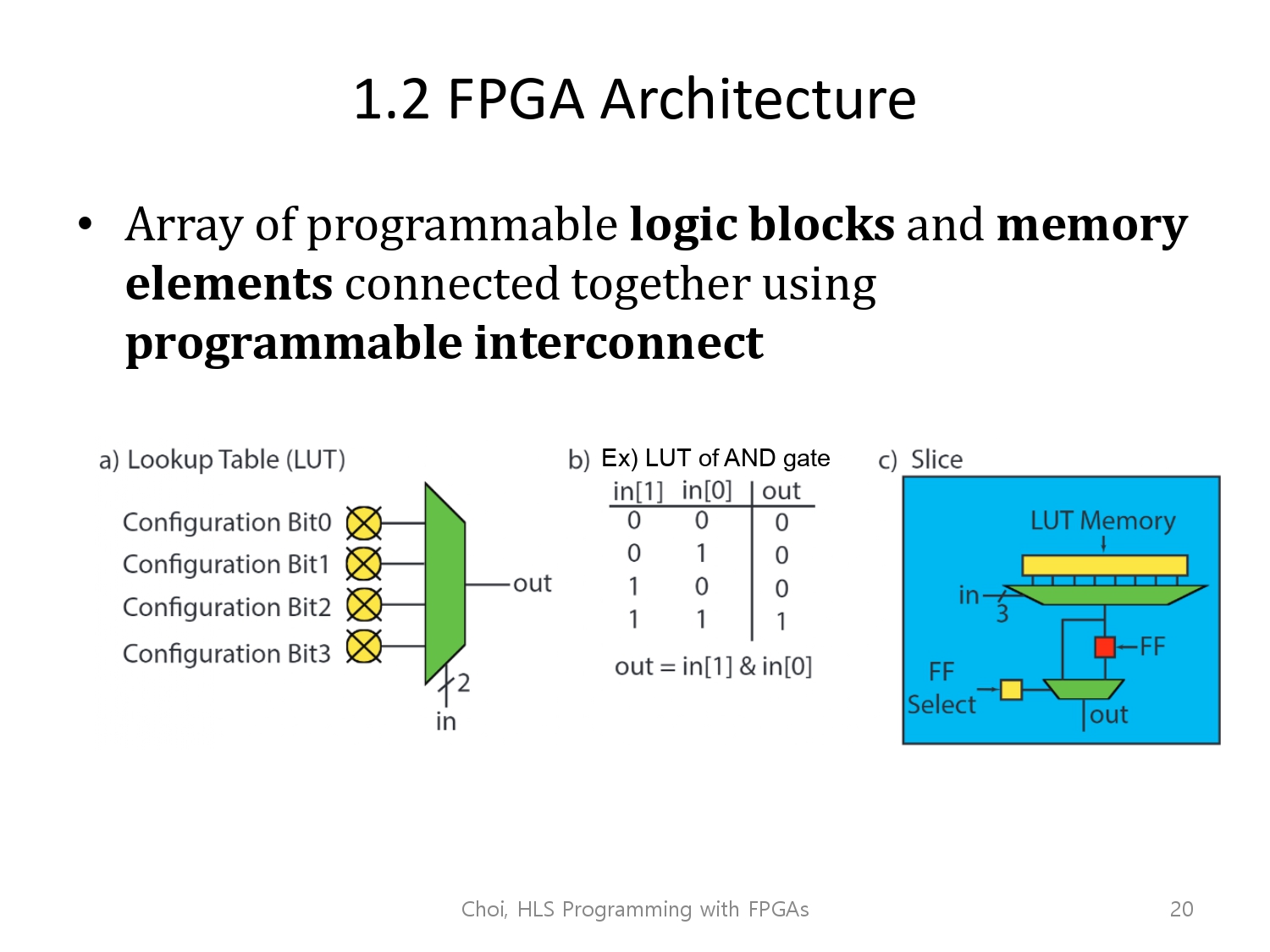
FPGA Architecture
프로그래밍 가능한 논리 블럭과 메모리 요소들의 배열이 있고,
프로그래밍 가능한 연결 방식을 통해서 이들이 이어져 있습니다.
- 논리 블럭은 LUT라 불리는 look up table로 구현되어 있습니다. 이는 입력 신호와 출력 신호간의 매핑을 해줍니다.
예를 들어, and gate에 대해서 모든 입력의 경우의 수에 대해서
결과가 0이 나오는 0 and 0, 0 and 1, 1 and 0 input을 Configuration BIT 1,2,3에 할당하고, 그리고 이 논리 소자를 실행하려 할 때, mux가 원하는 값을 입력 신호 및 제어신호를 통해서만 결정할 것입니다.
LUT의 출력은 플립플롭(메모리 역할)과 연결배치되어 결과를 내보낼 지, 저장할 지 정할 수 있습니다.
Lut, FlopFlop, Mux의 세트가 합쳐 Slice라 불리고, fpga의 구성요소입니다.
(building block)
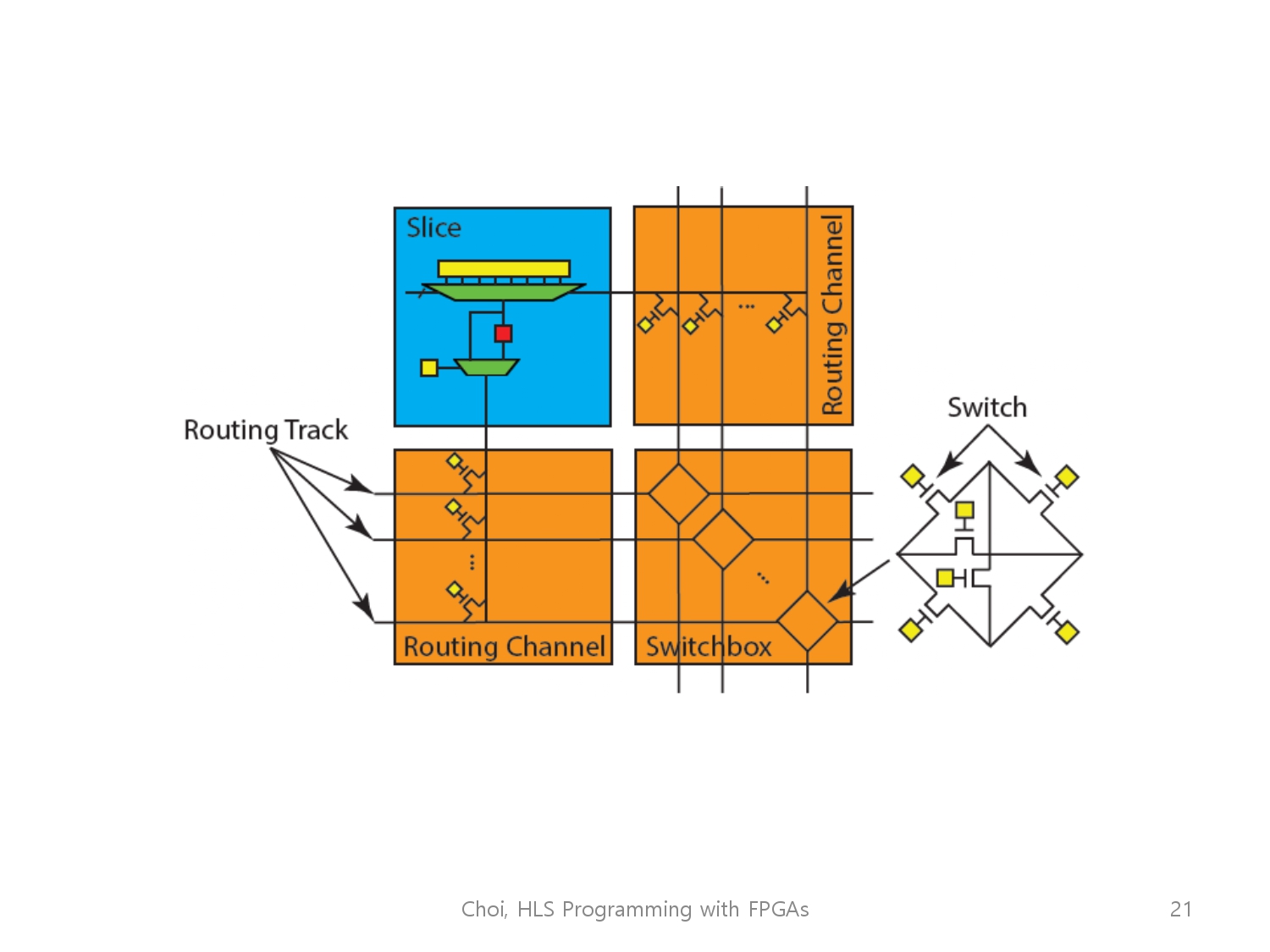
Fpga는 많은 slice로 이루어져 있습니다. slice의 입출력은 Routing tracks에 연결되어 있습니다.
그 slice와 Routing tracks의 연결은 Path Transister로 구성되어 있습니다. Rrouting Tracks 각각은 Routing Channel로 묶여 있으며, Switch Box를 통해 다른 Routing Tracks로 연결되어 구성되고 있습니다.
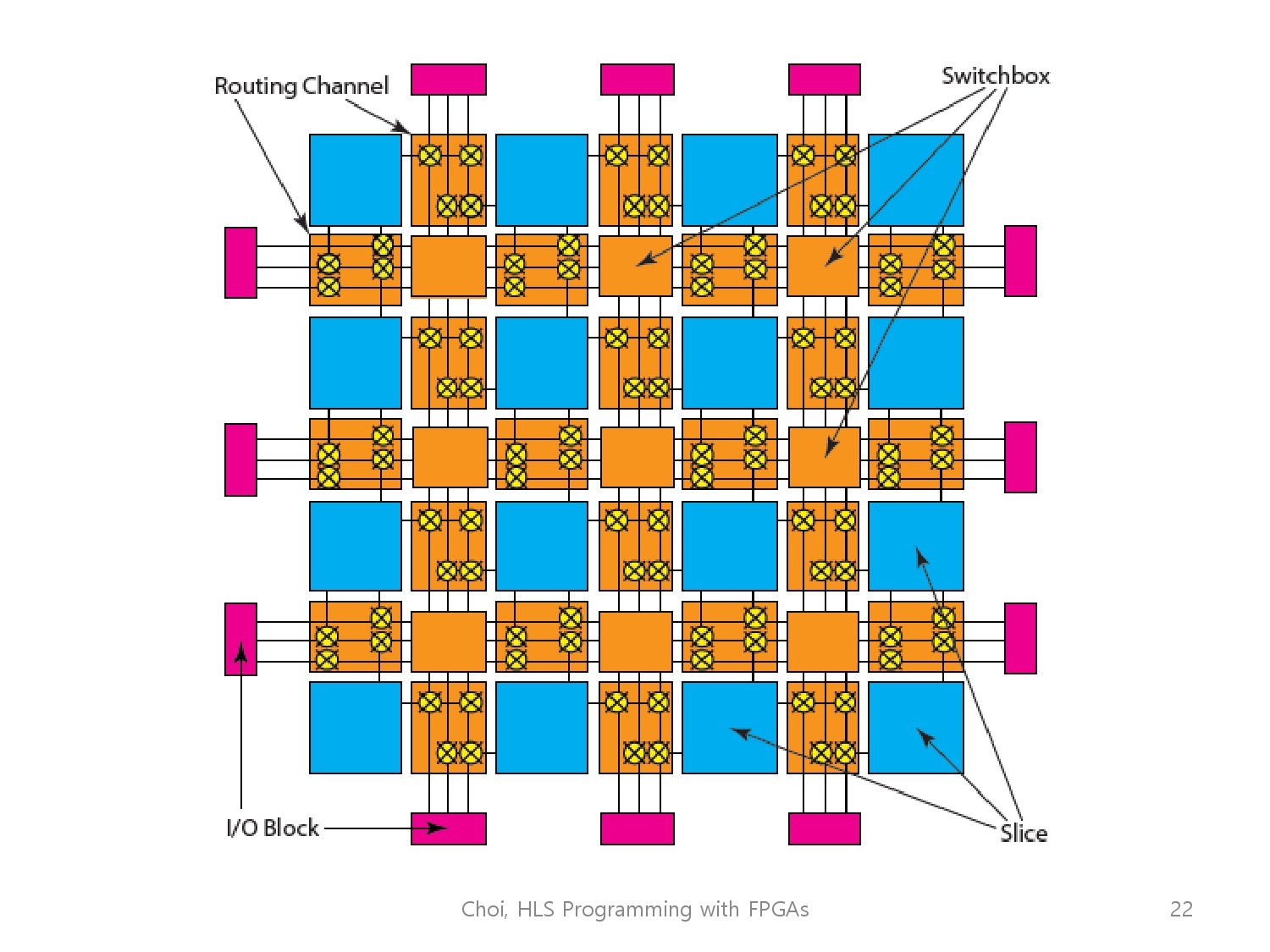
그래서 slice들은 Routing channel에 연결된 logic 섬 같이 생겼습니다. (평면 상에서)
Routing channel은 Switch Box에 따라 아마 상하좌우로 연결됐을 것이고, 뿐만 아니라 I/O block을 통해 dram이나 cpu 같은 외부 장치들과 통신 또한 가능합니다.
결과적으로는 fpga는 memory와 그들 사이의 연결을 사용자화(customize)해서 컴퓨팅이 가능하게 해줍니다.
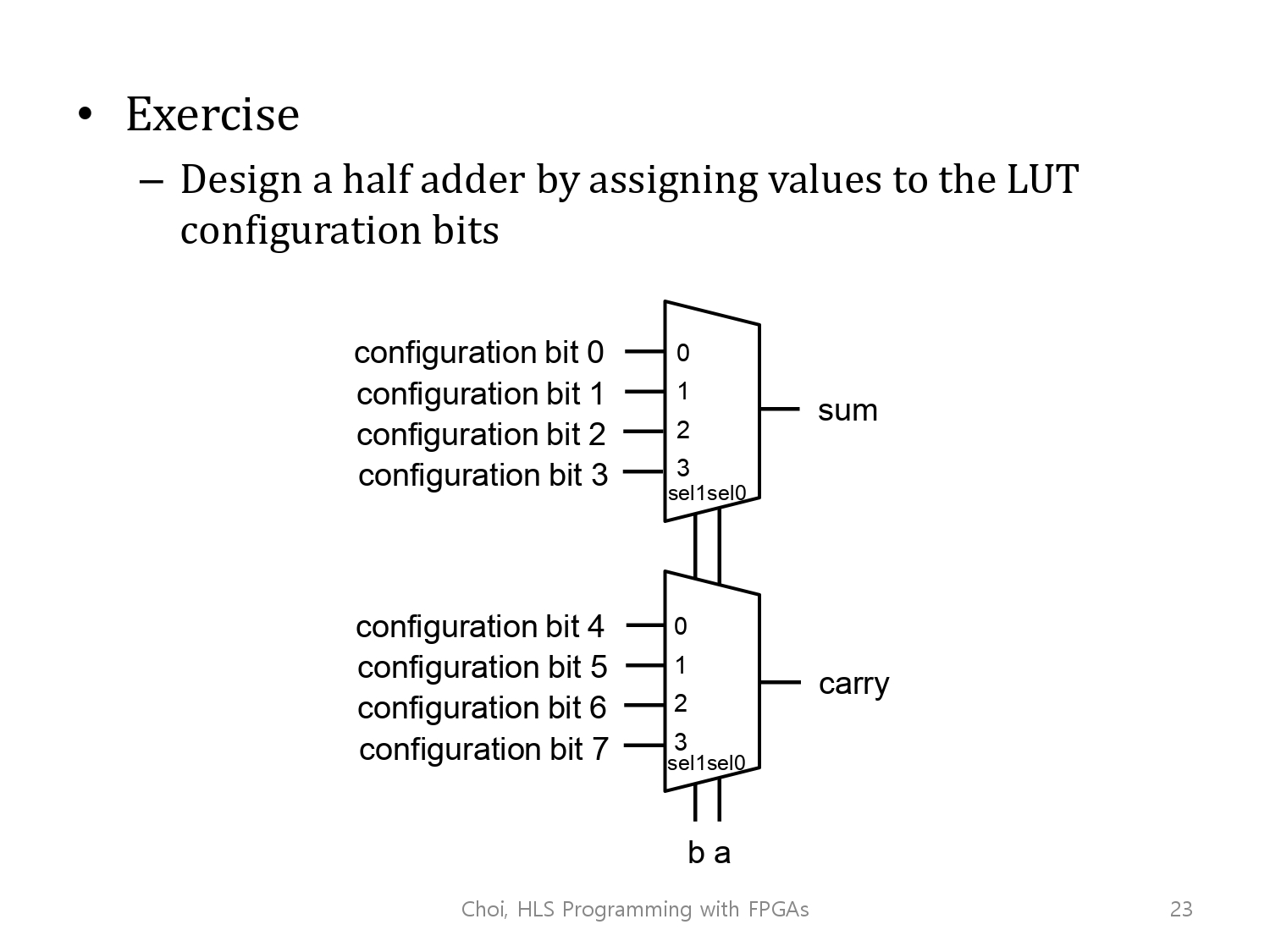
연습문제 :
Design half adder by assigning values to the LUT configuration bits.
강의 참고
위에서 했던 예시 참고하면 쉽게 풀 수 있습니다.
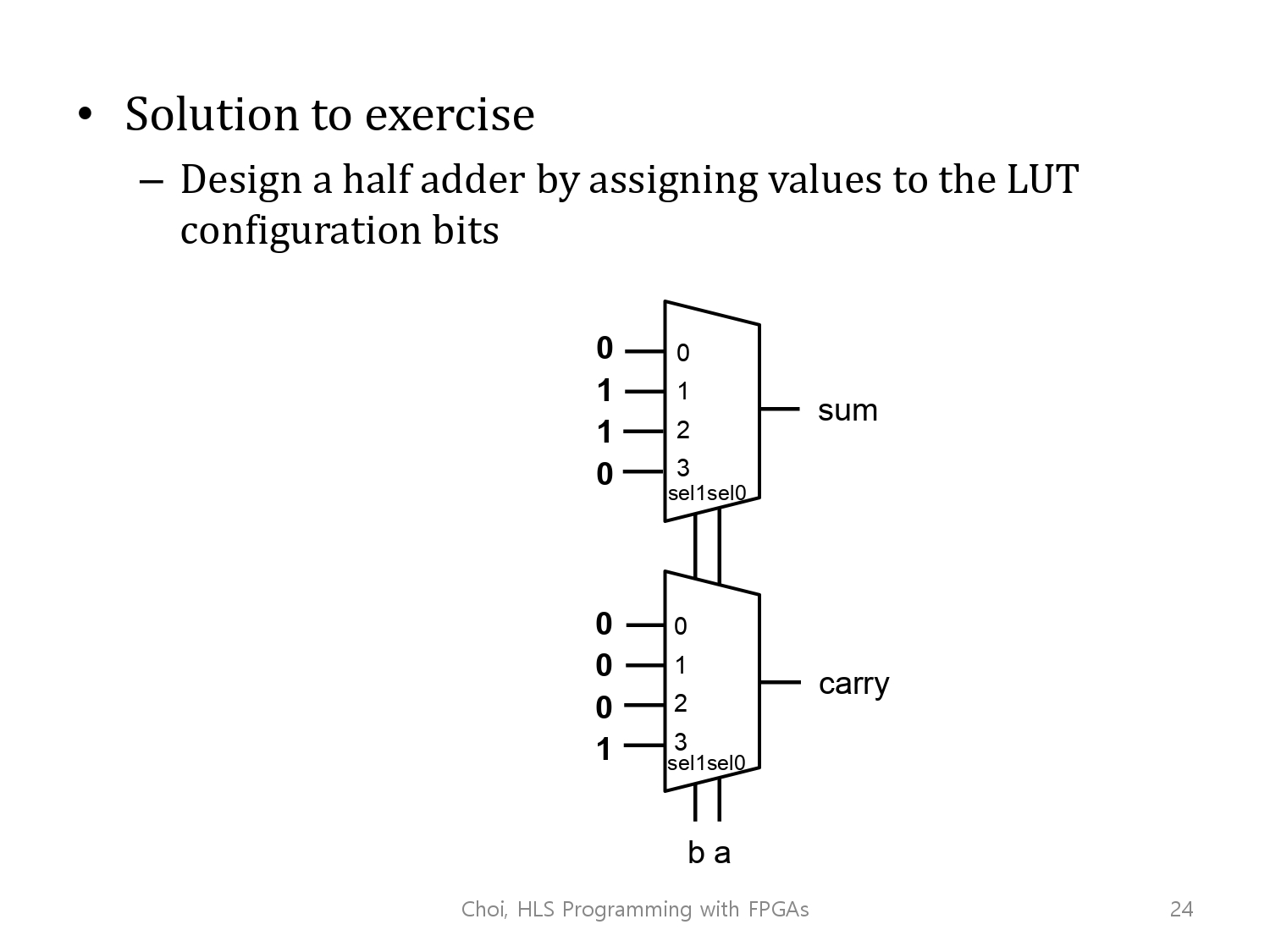
풀이 : sum값을 출력하는 0,1,2,3의 configuration bit와, carry값을 출력하는 0,1,2,3의 configuration bit는 2개는,각각 동일 input(a,b)에 대해 대응되는 configuration bit(이하 C.B)값입니다.
0, 0 => sum = 0, carry = 0이 되어야함.
0, 1 => sum = 1, carry = 0이 되어야함.
1, 0 => sum = 1, carry = 0이 되어야함.
1, 1 => sum = 1, carry = 1이 되어야함(올림 때문)
이를 풀어서 정리하면, 입력이 0,0일 때, 이 입력 조건에 해당하는 Configuration Bit인 C.B0(sum)과 C.B4(carry)에 각각 0,0대입되어야 하고, 나머지도 같은 방식으로
input(0,1)'s configuration bit - C.B1(sum) : C.B5(carry) = 1:0
input(1,0)'s configuration bit - C.B2(sum) : C.B6(carry) = 1:0
input(0,1)'s configuration bit - C.B3(sum) : C.B7(carry) = 1:1이 된다고 볼 수 있습니다.
이해가 가지 않는 부분이 있다면 댓글 달아주시면 답변해드리겠습니다.

다음으로, fpga 메모리 자원에 대해서 알아보겠습니다.
20page에서 말한 Flip Flop 뿐만 아니라, B(lock)RAM이라 불리는 전용메모리를 가지고 있습니다.
이는 랜덤 접근 메모리이며, 사용자는 이곳에 주소 신호를 보내고, 메모리의 특정 부분에 대해서 접근할 수 있습니다.
이는 fpga 내부에 탑재하고 있는 SRAM의 개념으로 이해하면 편합니다. 이런 BRAM은 여러가지 형태로 구성되어 있습니다.(크기 면에서)
마지막으로, DRAM은 fpga 내부의 메모리가 아닌, 외부에 탑재되어 있는 메모리입니다 자료의 비교표를 보면, 각각의 메모리가 크기와 성능이 반비례하는 모습들을 보여줍니다.
- 플립플롭은 수백테라바이트의 bandwidth(속도)를 보여주지만 고작 수백 킬로바이트만을 저장할 수 있습니다.
- 그에 반해 외부메모리는 수 기가바이트나 저장하는데에 반해 초당 기가바이트 정도의 bandwidth를 지닙니다. (BRAM은 그 사이에 있습니다.)
그래서 보편적으로 사용하길, 자주 사용하는 데이터는 FF와 BRAM에 저장하고, 나머지는 External memory에 저장합니다.
etc) 컴퓨터구조론(Architecture) 수업을 들은 사람들은 cash 유무에 대해서 의문을 가질 수 있는데, 몇fpga는 가지기도 하지만 대부분은 없습니다. 대부분의 fpga 디자이너들은 데이터 재사용이나 (데이터의)locality를 수동으로 제어하기 위해서 Bram의 사용을 꺼립니다. 작업을 예측할 수 없는 캐시에 남겨두는 것보다 낫다고 생각하기 때문에. - 의역하였습니다
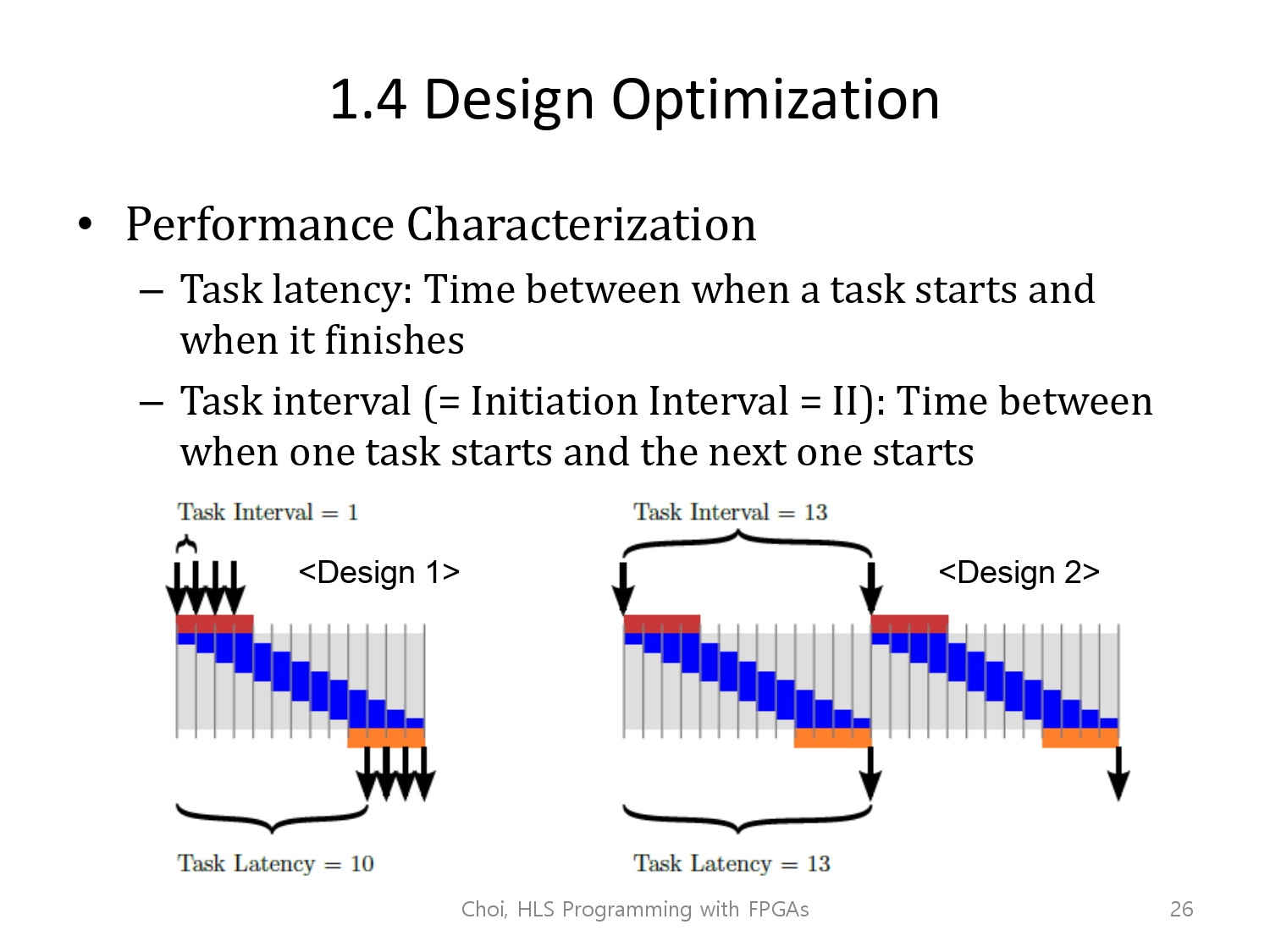
그럼 이제 fpga의 설계 최적화에 대한 기본적인 개념부터 알아봅시다.
하지만 그 전에, 성능과 연관된 metric?(용어?)를 먼저 정의하겠습니다.
task latency는 task가 시작하고 끝나는 사이의 간극을 의미하고,
task interval 혹은 Initiation interval이라는 한 task가 시작하고, 다음 task가 시작하기 까지의 간극을 의미합니다.
오른쪽 그림에서 x축은 시간이고, y축은 수행하는 연산입니다.(다른 연산의 진행)
즉, 시간이 지남에 따라 업무가 계속해서 다른 연산을 하게 되는 그림인데(-y축 진행), y축의 range가 10개니, 10개의 operation을 실행합니다.
이런 상황에서 task latency 혹은 simply latency는 10cycle이라 정의합니다.
- 만약 4개를 batch해서 실행한다면 13 사이클을 의미합니다.(우측 그림)
우측 그림에서는 4개를 하나의 task로 보는 것 같습니다.
만약 전의 task가 끝날 때까지 기다리기를 선택한다면 task interval은 13cycle이 될 것입니다.
- 혹은 전의 업무가 끝나기 전에 미리 실행을 하게 된다면, task latency는 10cycle 그대로인 반면, task interval은 1cycle이 됩니다.(좌측 그림)
좌측 그림에서는 4개를 각각 다른 task로 보는 것 같습니다.그래서 그림은 4개만 있지만, 실제로는 계속해서 있을 것입니다. (Interval이 1이기 때문)
etc) 컴퓨터 구조론(Architecture) 수업을 들은 사람은 이를 5개의 pipeline을 가진 구조라 볼 수 있는 것이라 말할 수 있는데, 이는 사실이며, 차이점이 있다면 5개의 스테이지로 제한될 필요가 없는 것입니다.
HLS tool은 pipline stages를 area와 throughtput trade-off에 따라 사용자화해줄 것입니다.
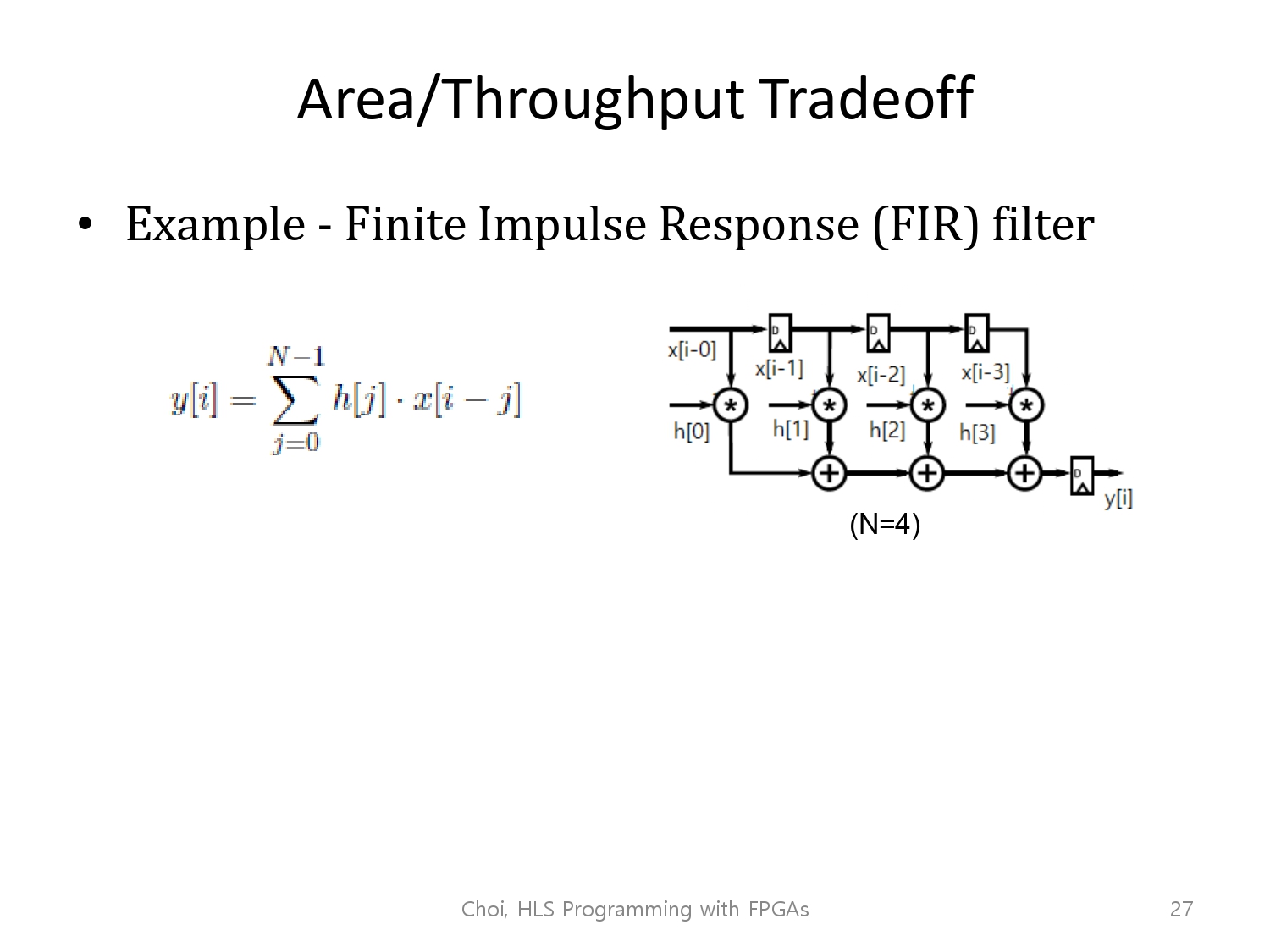
HLS 툴이 하는 것에 대한 더 나은 이해를 위해 현실에 존재하는 예시인 FIR 필터 예시를 들겠습니다.
FIR 필터는 합성곱(convolution)을 수행해주는 필터입니다.
자세한 내용은 신호 및 시스템 혹은 signal and system에서 다루고 있습니다. 여기서는 단순하게 '곱셈과 나눗셈을 병렬적으로 많이 하는 연산필터'라고 이해하고 넘어가면 되겠습니다.
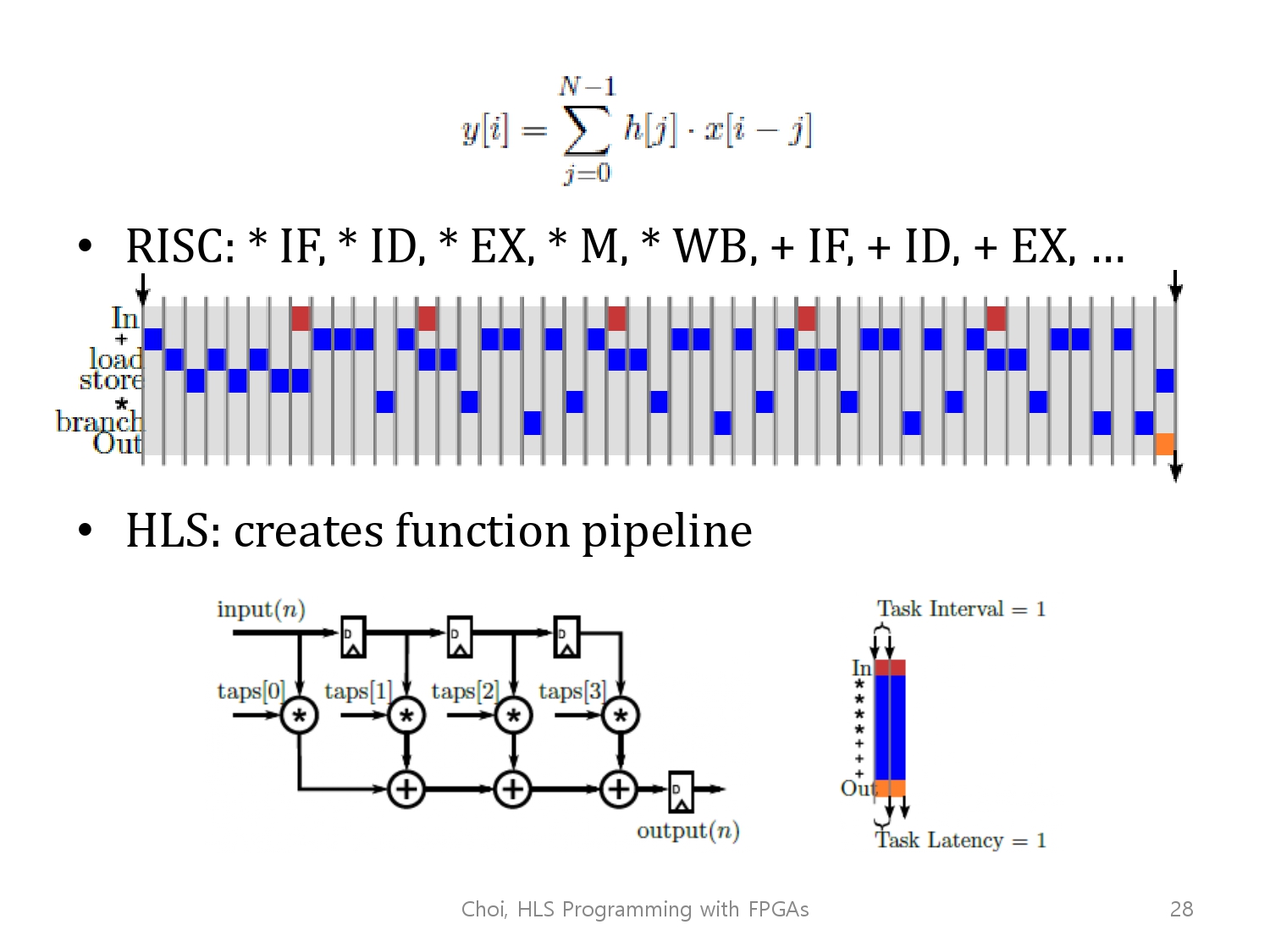
만약이 convolution 연산을 pipelined RISC processor에서 수행한다면,
RISC processor는 앞서 말했듯이 5개의 처리로 이루어진 프로세서라고 이해하면 되겠습니다.
5개의 처리(Instruction fetch, Instruction Decode, Excution, Memory Access, Write Back)의 과정이 반복해서 계속 이어집니다.
그에 반해 HLS는 고성능의 pipelined, parallel된 구조를 생성해줍니다.
이는 function pipeline이라 불리며, 이는 Instruction fetch와 Instruction Decode의 과정보다는 Excution과 resister access만을 훨씬 더 많이 하게(비중있게 하게) 됩니다.
이는 효율적으로 사용자화된 fir filter 회로를 얻게 해줍니다.
좌측하단의 그림은 HLS가 만들어준 회로의 모습이고, 오른쪽은 그 회로의 scheduling을 표현한 그림입니다.
그 scheduling의 각각의 task에서, 4번의 곱과 3번의 더하기를 수행하고 결과를 출력합니다.
이를 모든 사이클에 대해 수행이 가능하고, task interval은 자연스레 1이 됩니다.
우측하단의 그림은 우리가 모든 computation을 한 사이클 안에 한다고 추정한 그림입니다. 그래서 latency 또한 1입니다.
하지만, 사용되는 기술과 데이터의 bitwidth를 고려해봤을 때, latency가 수사이클이 걸린다고 생각하는 것이 아마 더 합리적일 것입니다.
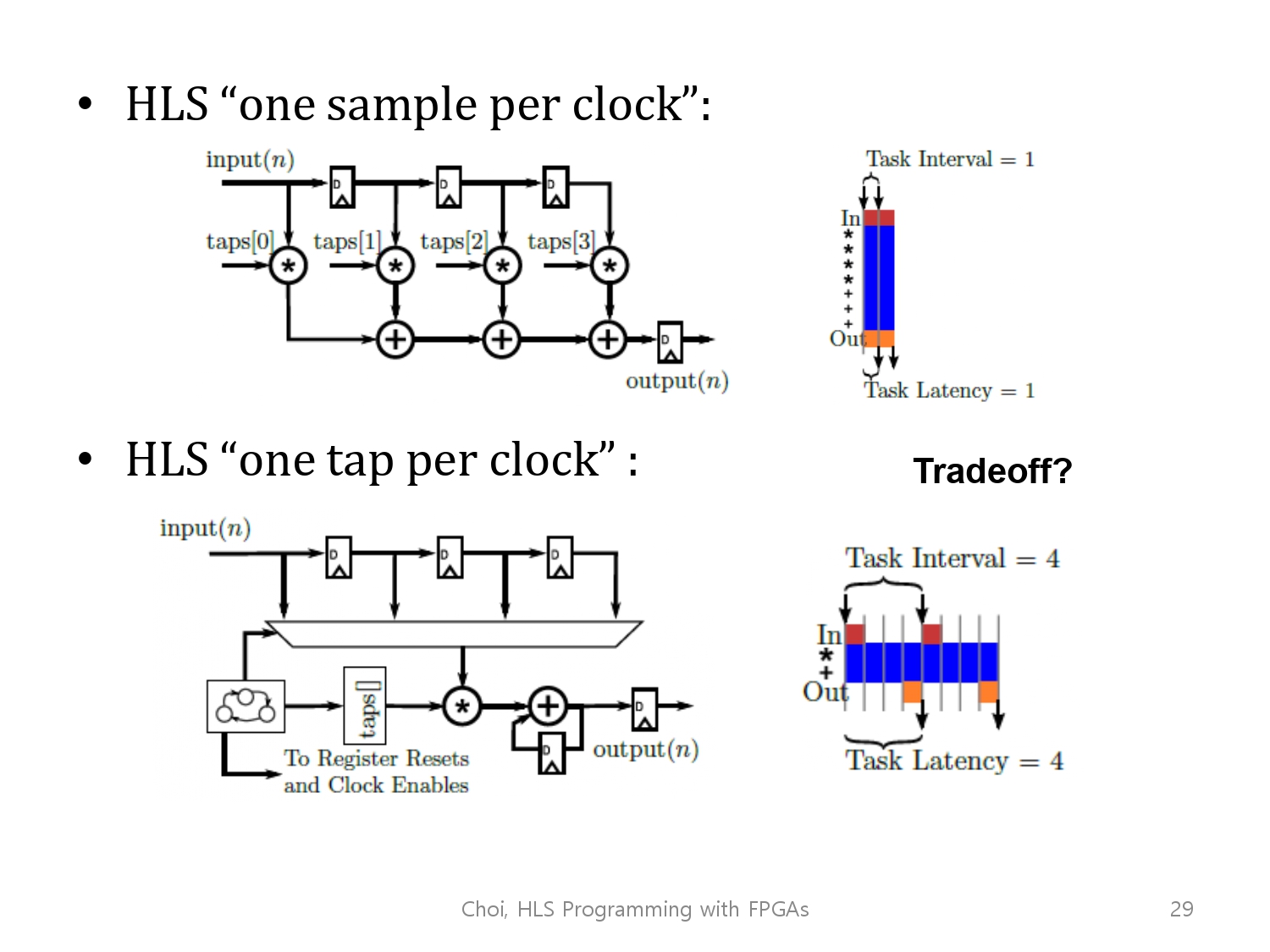
우리가 본 예시는 한 사이클당 하나의 결과를 출력합니다.
하지만하나의 탭을 계산하거나, 사이클당 곱하고 더하는 것 또한 가능합니다.
아래의 구조는 한 번에 1개의 탭을 연산하고, adder와 multiplier을 공유합니다.
이런 상황에서는 하나의 출력을 위해 4개의 사이클이 사용되고 ii(Initiation interval)는 4가 됩니다.
여기서의 trade-off에 대해 알아보겠습니다.
한 번에 한 탭을 컴퓨팅함으로서, throughput이 4배나 감소했습니다.
그러나 4개의 multiplier과 3개의 adder를 사용한 전자와는 다르게, 각각 1개씩만을 사용하게 됩니다.( area 부분에서의 benefit)
즉, throughput과 area 부분에서의 trade-off가 일어났습니다.
어떤 것을 사용하는 것이 맞는 결정인지는 상황에 따라 다릅니다. 이는 bound가 성능면에 달렸는지, resource 면에 달렸는지를 알아야 합니다.
이런 모든 면에서 스스로 변형하고(설계를), 모든 design point에 대해서 탐색하기에는 굉장히 어렵습니다.
이것이 HLS가 유용한 이유입니다.
HLS는 원하는 구조를 묘사하는데 있어 상대적으로 쉬운 방법을 제공합니다.
우리는 compiler directive라고 불리는 것을 사용하여, HLS에게 원하는 버전(area vs throughput)의 설계를 생성하게 명령합니다.
다음 챕터에서 다른 예시들을 보도록 하겠습니다.

요약
- LUT를 사용해 fpga의 computation을 사용자화 할 수 있습니다.
- FPGA는 사용자화 가능한 메모리 자원과 프로그래밍 가능한 연결로 이루어져 있습니다.
- Task latency와 Task interval(ii)의 차이점
- 마지막으로 HLS는 function pipeline을 생성해줍니다.
2장에서 뵙겠습니다.
읽어주셔서 감사합니다.
