

클린코드(Clean Code)
: 읽기 쉽고 이해하기 쉬운 좋은 코드를 작성하는 것
코드 자체가 가독성이 뛰어나고 유지 보수가 쉽도록 작성되어야 한다는 원칙
프롤로그
클린 코드가 필요한 이유
소프트웨어 개발에서 '클린 코드'란 읽기 쉽고 이해하기 쉬운 코드를 말합니다. 반면 '나쁜 코드'는 복잡하고 이해하기 어려운 코드를 의미합니다. 흔히 개발 과정에서 시간에 쫓기거나 생각 없이 코드를 작성하다 보면 ~안타깝게도 자연스럽게 나쁜 코드가 만들어지게 됩니다.~

개발 초기에는 이렇게 작성된 나쁜 코드도 프로젝트를 빠르게 진행시키는 것처럼 보일 수 있습니다. 하지만 시간이 지남에 따라 그 단기적인 이득은 빠르게 사라지고, 장기적인 문제가 드러나기 시작합니다.
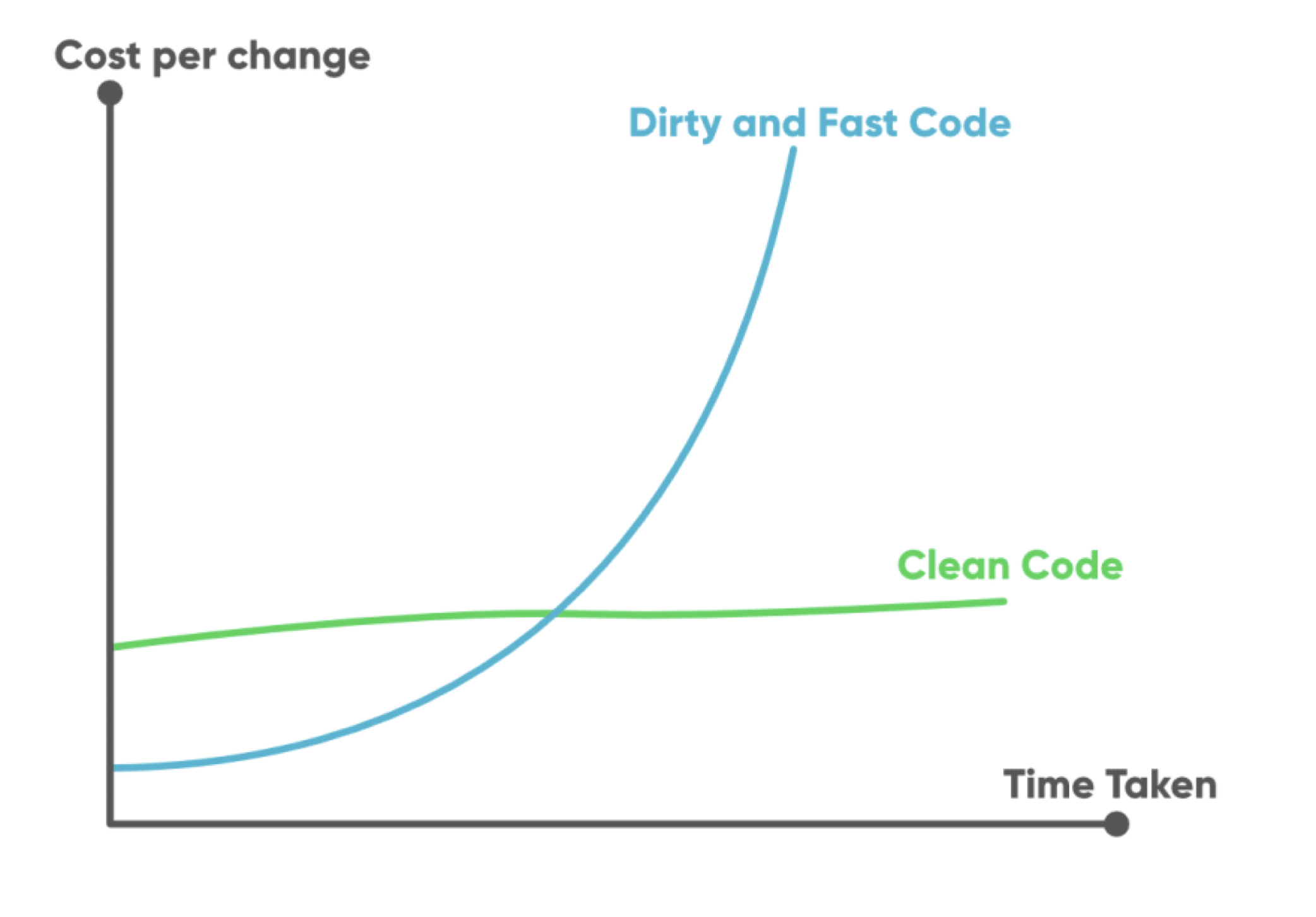
빨리 가는 길은, 언제나 코드를 깨끗하게 유지하는 습관이다.
클린 코드는 초기 작성에 시간이 걸리지만, 유지보수성과 확장성이 뛰어나기 때문에 장기적으로는 더 효율적입니다. 이는 코드가 복잡해질수록 클린 코드의 중요성을 더욱 부각시킵니다. 결과적으로, 깨끗한 코드는 지속 가능한 개발을 가능하게 하며, 프로젝트의 성공을 보장합니다.
이러한 클린 코드의 개념은 로버트 C. 마틴의 저서 "Clean Code"에서 처음 소개되어 소프트웨어 개발 커뮤니티에서 큰 반향을 일으켰습니다. 이는 읽기 쉽고 이해하기 쉬운 코드를 작성하는 방법에 초점을 맞추고 있으며, 많은 개발자들에게 좋은 코드를 만들 수 있는 지침이 되어주고 있습니다. 그렇다면 우리가 클린코드를 통해 추구해야 할 좋은코드란 과연 무엇일까요?
좋은 코드란 과연 무엇일까요?
'좋다'라는 것은 주관적인 감정인데 어떻게 좋은 코드라 판단할 수 있을까요? 맛을 예로 들어보면, 누구에게는 인생맛집이라고 불리는 곳도 나에게는 맛이 없을 수 있습니다. 그러나 맛이 주관적이라고 해서 맛집이라는 개념이 없는 것은 아닙니다. 이는 코드도 마찬가지입니다.
코드의 좋고 나쁨은 개발자마다 다르게 느껴질 수 있지만, 대부분의 사람들이 인정하는 좋은 코드는 존재합니다. 예를 들어, 다음과 같은 두 코드를 작성해보았습니다.
const c = (i) = i.reduce((a,{p,q})=>a+p*q,0)function calculateCartTotal(items) {
return items.reduce((total, item) => {
return total + item.price * item.quantity;
}, 0);
}두 번째 코드가 더 좋아 보이지 않나요? ~하지만 왜 그런지 정확히 설명하기는 쉽지 않습니다.~ 단순히 "더 이해하기 쉽다"라고 말하기에는 뭔가 부족하다고 느껴집니다.
절대적으로 좋은 코드라는 것은 없지만, 대체로 좋은 코드들에서 드러나는 일반적인 특징들은 존재합니다. 좋은 코드의 일반적인 특징들을 자세히 알아보면서, 우리가 막연하게 느끼는 ~'좋은 코드'의 모습을 더 선명하게~ 그려보도록 하겠습니다.
좋은 코드의 일반적인 특징들
- 가독성: 좋은 코드는 읽기 쉽고 이해하기 쉽습니다.
- 유지보수성: 좋은 코드는 수정사항에 대응하기 쉬우며, 수정에 독립적이고 찾기 쉽습니다.
- 확장성: 좋은 코드는 새로운 기능을 추가할 때, 기존 코드를 크게 수정하지 않을 수 있습니다.
- 견고성: 좋은 코드는 에러가 발생했을 경우에도 동작하거나 대응하고, 에러를 발견하기 쉽습니다.
- 테스트 가능성: 좋은 코드는 테스트를 작성하기 쉬우며, 단위별 테스트를 할 수 있습니다.
- 자기문서화: 좋은 코드는 요구사항을 코드 자체로 이해할 수 있게 합니다.
- 일관성: 좋은 코드는 같은 규칙과 철학으로 작성되어 예측이 가능합니다.
1. 가독성
<좋은 코드는 읽기 쉽고 이해하기 쉬워야 합니다>가독성은 코드를 얼마나 쉽게 읽고 이해할 수 있는지를 나타냅니다. 이는 코드의 구조와 로직이 명확하게 파악되는 정도를 의미합니다. 가독성 높은 코드는 변수명과 함수명이 그 역할을 잘 설명하고 있으며, 각 코드의 역할과 로직들을 적절한 간격과 순서로 배치되어 각 부분의 기능을 쉽게 읽히기에 이해하기 쉬워집니다.
2. 유지보수성
<좋은 코드는 수정사항에 대응하기 쉬우며, 수정에 독립적이고 찾기 쉽습니다>: 유지보수성은 코드를 얼마나 쉽게 수정하고 업데이트할 수 있는지를 나타냅니다. 이는 코드의 구조적 특성과 관련이 있습니다. 유지보수가 쉬운 코드는 특정 부분을 수정할 때 다른 부분에 미치는 영향이 최소화되며, 각 부분의 역할이 명확히 분리되어 있어 필요한 변경을 쉽게 적용할 수 있습니다.
3. 확장성
<좋은 코드는 새로운 기능을 추가할 때, 기존 코드를 크게 수정하지 않을 수 있습니다.>: 확장성은 새로운 기능을 추가하거나 기존 기능을 확장할 때 코드를 얼마나 쉽게 변경할 수 있는지를 나타냅니다. 이는 유지보수성과는 달리 미래의 변화에 대한 대비에 초점을 맞춥니다. 확장성이 좋은 코드는 새로운 기능을 추가할 때 기존 코드의 변경을 최소화할 수 있는 구조를 가집니다.
4. 견고성
<좋은 코드는 에러가 발생했을 경우에도 동작하거나 대응하고, 에러를 발견하기 쉬워야 합니다.>: 견고성은 코드가 예상치 못한 상황이나 잘못된 입력에 대해 얼마나 잘 대응하는지를 나타냅니다. 견고한 코드는 다양한 오류 상황을 예측하고 적절히 처리하며, 시스템의 안정성과 신뢰성을 높입니다.
5. 테스트 가능성
<좋은 코드는 단위별 테스트를 할 수 있으며 테스트를 작성하기 쉬워야 합니다>: 테스트 가능성은 코드를 얼마나 쉽고 효과적으로 테스트할 수 있는지를 나타냅니다. 이는 코드의 각 부분을 독립적으로 테스트할 수 있도록 설계되었는지를 의미합니다. 테스트 가능한 코드는 각 기능을 명확히 분리하여 단위 테스트와 통합 테스트를 용이하게 합니다.
6. 자기문서화
<좋은 코드는 요구사항을 코드 자체로 이해시킬 수 있어야 합니다>자기문서화는 코드 자체가 그 기능과 목적을 얼마나 잘 설명할 수 있는지를 나타냅니다. 자기문서화된 코드는 별도의 문서 없이도 코드만으로 그 기능과 동작 방식을 이해할 수 있게 합니다. 이는 코드의 구조와 네이밍이 코드의 의도를 명확히 전달하는 것을 의미합니다.
7. 일관성
<좋은 코드는 같은 규칙과 철학으로 작성되어 예측이 가능해야 합니다>일관성은 코드 전반에 걸쳐 동일한 패턴, 규칙, 스타일이 적용되는 정도를 나타냅니다. 이는 코딩 스타일의 통일성뿐만 아니라 문제 해결 방식, 설계 패턴 사용, 에러 처리 방식 등이 일관되게 적용되는 것을 의미합니다. 일관성 있는 코드는 예측 가능성을 높여 코드의 이해와 유지보수를 용이하게 합니다.
각 특성은 독립적으로 평가할 수 있지만 서로 밀접하게 연관되어 있습니다. 가독성은 좋은 코드의 출발점이며, 일관성은 이 모든 특성들을 뒷받침하는 기반이 되어, 전체적으로 높은 품질의 코드를 만드는 데 기여합니다.
개발을 공부하면서 이러한 좋은 코드의 특징들은 익히 들어왔고, 실제로 좋은 코드를 만들고자 많은 노력을 기울이고 있습니다. 그런데도 왜 좋은 코드를 작성하는 것이 여전히 어려울까요?
좋은 코드를 작성하기 어려운 이유
좋은 코드의 특징을 알고 있더라도 실제로 그러한 코드를 작성하는 것은 쉽지 않습니다. 우리가 생각하는 '좋은 코드'가 다른 사람에게는 그렇지 않을 수 있기 때문입니다. 코드를 작성할 때 우리는 종종 자신만의 관점에 갇혀, 다른 개발자의 입장을 고려하지 못하는 경우가 많습니다.
좋은 코드란, 다른 사람이 보았을 때 좋은 코드다
좋은 코드의 정의는 주관적일 수 있지만, 결국 다른 사람이 보았을 때 이해하기 쉽고 유지보수가 용이한 코드가 진정한 의미의 좋은 코드입니다. 우리가 작성한 코드는 우리뿐만 아니라 다른 개발자들, 심지어 미래의 우리 자신까지도 읽고 이해해야 합니다. 따라서 '다른 사람의 관점'을 항상 고려하는 것이 중요합니다.
지식의 저주: 좋은 코드 작성을 방해하는 요인
이러한 현상은 '지식의 저주'라고 불리는 인지적 편향과 관련이 있습니다. 우리는 무언가를 알고나면, 알지 못한다는 상태로 돌아갈 수 없고 상상할 수 없게 됩니다. "안본눈 삽니다" 라는 밈과 유사한 맥락이죠. 그래서 지식의 저주는 우리가 알고 있는 것을 다른 사람도 알고 있을 것이라고 무의식적으로 가정하게 만듭니다. 개발 맥락에서 보자면 이는 우리가 작성한 코드의 의도와 맥락이 ~내가 쉽게 이해가 되면 다른 사람도 쉽게 이해할 수 있을 것~이라고 착각하게 만듭니다.
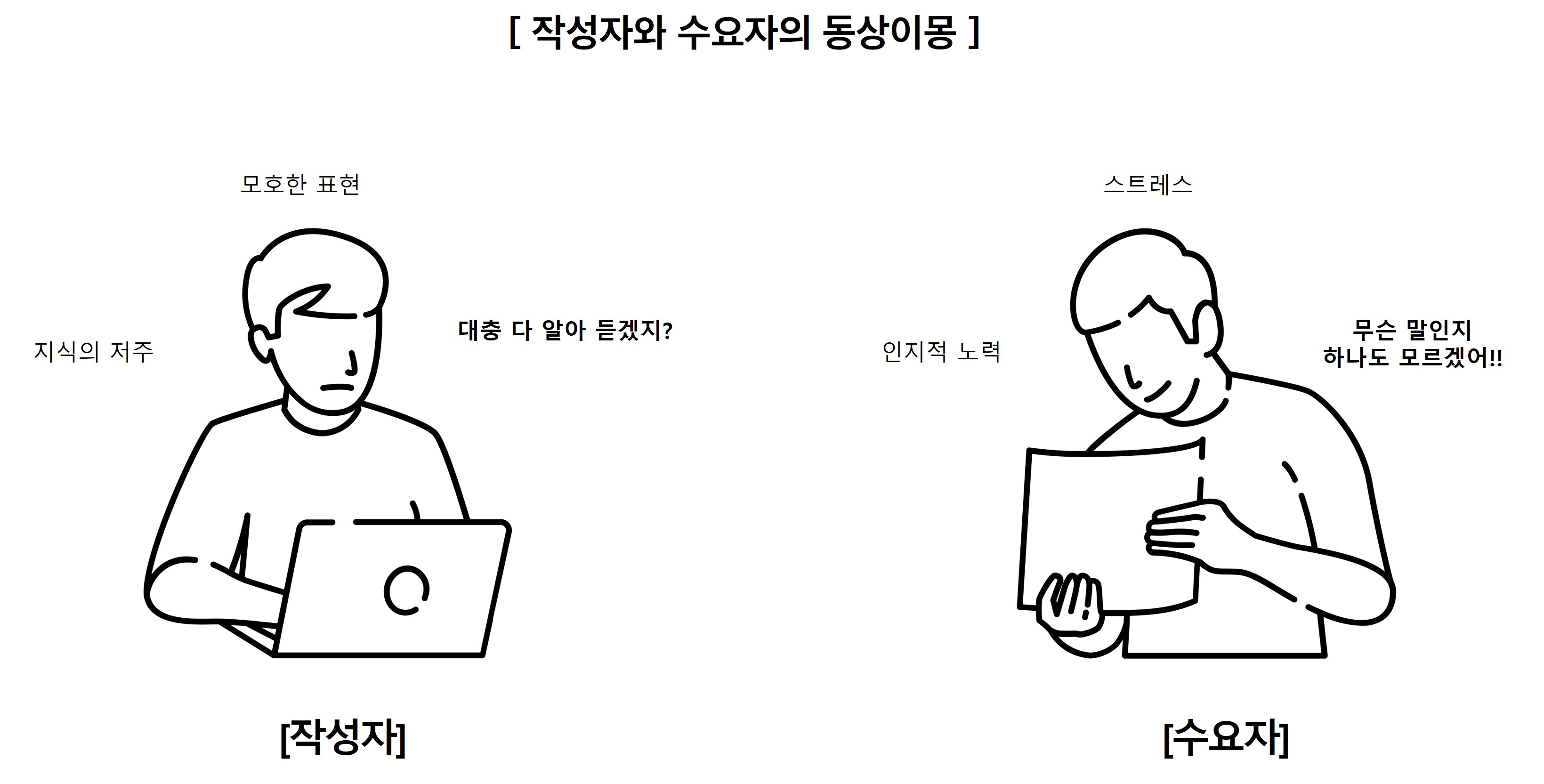
예를 들어, 내가 작성한 변수명이나 함수명이 ~나에게는 너무나 명확하지만~ 다른 사람은 그 의미를 제대로 모를 수 있습니다. 또는 우리가 당연하게 여기는 알고리즘이나 디자인 패턴이 다른 사람에게는 생소할 수 있습니다. 이러한 편향은 실제로 작성된 코드가 나쁜코드임에도 내가 잘 이해하기 때문에 좋은 코드라고 생각하게 만듭니다.
특히 이러한 경향은 혼자 코드를 작성해야 할 때 더 두드러집니다. 팀으로 일할 때는 다른 사람의 피드백을 받을 수 있지만, 혼자 작업할 때는 그렇지 않기 때문입니다.
좋은 코드를 만들기 위한 개발 문화
이러한 문제를 해결하기 위해 많은 개발팀에서는 코드 리뷰, 팀 컨벤션, 자동화된 테스트와 같은 개발 문화들을 도입하고자 합니다. 이러한 과정을 통해 개발자들은 서로의 코드를 이해하고 개선할 수 있으며, '지식의 저주'를 극복할 수 있습니다.
특히 코드 리뷰는 다른 개발자의 관점에서 코드를 바라볼 수 있게 해주는 중요한 과정입니다. 코드 리뷰를 통해 우리는 자신의 코드가 다른 사람에게 어떻게 보이는지 직접 확인할 수 있고, 동시에 다른 사람의 코드를 읽고 이해하는 능력을 기를 수 있습니다. 이는 팀 전체의 코드 품질을 향상시키는 데 큰 도움이 됩니다.
또한, 팀 컨벤션을 정립하고 따르는 것도 중요합니다. 일관된 코딩 스타일과 규칙은 코드의 가독성을 높이고, 팀원 간의 이해를 촉진합니다. 자동화된 테스트의 도입은 코드의 신뢰성을 높이고, 리팩토링을 용이하게 만들어 지속적인 코드 개선을 가능하게 합니다.
좋은 코드의 특징을 알아야 하는 진짜 이유
좋은 코드의 기준을 이해하면 코드를 바라보는 시각이 달라집니다. 막연히 '이 코드가 좋아 보인다'는 느낌에서 벗어나, 왜 그 코드가 좋은지 구체적으로 알 수 있게 됩니다. "이 부분이 가독성이 뛰어나구나", "저 구조가 확장성을 높여주는구나"라는 생각의 방향성을 만들어줍니다. 좋은 코드의 특징을 많이 알면 알수록, 코드의 품질을 평가하는 기준이 더욱 선명해집니다.
이러한 선명한 기준은 다른 사람에게 코드에 대해 더 잘 설명할 수 있게 만들어줍니다. 코드 리뷰 과정에서 "좋네요", "제가 보기에는 별로예요"와 같은 말보다, "이러이러해서 확장성이 떨어지니 구조를 수정해야 합니다. 저러저러해서 테스트가 더 용이해진 것이 좋습니다."와 같이 구체적이고 근거 있는 피드백을 제공할 수 있어야 합니다. 이렇게 구체적으로 설명하는 능력은 '지식의 저주'를 극복하고, 동료 개발자들의 관점을 이해하는 데 큰 도움이 됩니다.
결국, 좋은 코드의 특징을 알고 이를 설명할 수 있는 능력은 개발자의 코딩 철학을 형성하는 데 중요한 역할을 합니다. 이를 통해 좋은 코드에 대한 우리의 이해는 더욱 선명해지고, 코드 품질에 대한 '해상도'가 높아집니다. 이는 개인의 성장뿐만 아니라 팀 전체의 코드 품질 향상과 효율적인 협업으로 이어져, 궁극적으로 프로젝트의 성공 가능성을 높이는 핵심 요소가 됩니다.
혼자 개발하더라도 함께 한다는 생각으로 개발하자.
개발을 혼자서 진행하는 경우가 많습니다. 특히 프론트엔드 개발자들처럼 프로젝트를 독립적으로 수행하는 상황에서는, 좋은 코드를 작성하려는 노력이 소홀해지기 쉽습니다. 그러나 혼자 개발하더라도 좋은 코드를 작성하는 습관은 매우 중요합니다.
혼자서 개발할 때에도 내 코드를 남에게 보여준다는 생각을 가지는 것이 중요합니다. 이를 통해 코드의 가독성과 유지보수성을 높이는 데 신경 쓸 수 있습니다. 또한, 시간을 내어 다른 개발자의 코드를 읽는 시간을 가지면, 다양한 접근 방식과 해결 방법을 배우며 자신의 코드 스타일을 개선할 수 있습니다.
무엇보다도, 좋은 코드의 특징을 제대로 이해하고 그 바탕으로 자신의 코드 철학을 깊게 탐구하는 것이 중요합니다. 이를 통해 코드의 품질을 지속적으로 향상시키고, 혼자서도 뛰어난 코드를 작성하는 능력을 키울 수 있습니다.
혼자서 개발하더라도 좋은 코드를 작성하려는 노력은 장기적으로 볼 때 개발자 본인에게 큰 이익이 됩니다. 그렇다면 좋은 코드의 가장 기본이 되는 요소는 무엇일까요?
좋은 코드의 기본은 가독성!
좋은 코드의 여러 특징 중에서 가장 기본이 되는 것은 단연코 가독성입니다. 코드가 읽기 쉬우면 팀에서도, 혼자 일할 때도 큰 도움이 됩니다. 가독성이 높으면 자연스럽게 유지보수성, 확장성, 테스트 용이성 등 다른 좋은 특성들도 따라오게 됩니다.
가독성 높은 코드는 버그를 찾고 수정하는 데 드는 시간을 크게 줄여줍니다. 또한, 새로운 기능을 추가하거나 기존 기능을 수정할 때도 작업 속도를 높여줍니다. 특히 팀 프로젝트에서는 다른 개발자들이 코드를 빠르게 이해하고 작업을 이어갈 수 있게 해줍니다.
가독성이 높은 코드를 보고 가독성이 높다고 말하는 것은 쉽습니다. 하지만 가독성이 낮은 코드를 보고 왜 가독성이 낮은지, 어떻게 해야 더 가독성이 높아지는지 설명하는 것은 어려울 수 있습니다. 이는 가독성이 주관적인 개념이기 때문입니다. 그래서 우리는 좋은 코드를 만드는 방법을 더 객관적이고 체계적으로 접근할 필요가 있습니다.
그래서 이 글에서는 클린코드를 만들기 위한 핵심인 코드의 가독성을 높이는 방법을 알아보고자 합니다. 특히 가독성이라는 추상적이고 느낌적인 개념을 잘 설명하고자 흥미로운 UX 이론을 클린코드에 접목시켜 이해를 돕고자 했습니다. 이 글이 클린코드와 가독성에 대한 이해에 도움이 되기를 바랍니다.
게슈탈트 법칙으로 이해하는 가독성 높은 코드 만들기
"좋은 코드에서 가독성이 중요하다는 것을 잘 압니다. 그리고 가독성이 좋은 코드가 뭔지도 알겠어요. 그런데 코드 가독성이 좋다는 것 자체를 설명하기가 참 어렵습니다. 뭔가 느낌은 알겠는제 실제로 어떻게 해야 가독성이 좋아지는 건지는 잘 모르겠어요."
좋은 코드의 시작 : 가독성!
좋은 코드의 출발은 그래서 가독성입니다. 가독성 좋은 코드를 작성한다는 것은 소프트웨어 개발에서 가장 중요한 요소 중 하나입니다. 경험이 많은 개발자는 느낌적으로 가독성이 좋은 코드를 판별하고 작성할 수 있습니다. 그러나 대부분 개발자들에게 왜 이 코드가 더 가독성 좋은가를 설명하기는 참 어렵습니다. 그러던 중 <게슈탈트 법칙>이라는 흥미로운 UI/UX 이론을 발견하고 이 개념을 빗대 클린코드와 가독성을 잘 설명할 수 있겠다 생각이 들었습니다.
참고 : 인터넷에 게슈탈트 법칙을 검색하면 UI/UX와 관련된 이론만 나오지 ~실제 가독성과 클린코드에 대한 이론은 아니므로~ 여기서는 클린코드의 이해를 돕기 위한 장치로 사용하고 있다는 점 참고해주세요.

왜 오른쪽 그림이 더 가독성이 더 좋을까요?
게슈탈트 법칙 소개
게슈탈트 법칙은 20세기 초 독일에서 시작된 심리학 이론으로, 인간이 시각적 정보를 어떻게 조직하고 해석하는지를 설명합니다. 이 이론은 우리가 개별 요소를 단순히 보는 것이 아니라, 이 요소들을 종합하여 전체적으로 의미 있는 형태로 인식하는 경향이 있음을 강조합니다. 게슈탈트 심리학의 창시자들은 우리가 세계를 어떻게 인식하는지에 대한 법칙들을 연구하면서, 시각적 정보의 해석에 관한 여러 가지 법칙을 제안했습니다.

폐쇄성의 법칙 (Closure)
모든 정보가 존재하지 않더라도 형태로 인식할 수 있다.
위 그림은 여러개의 점일뿐이지만 우리는 강아지로 인식합니다.

그밖에도 게슈탈트 법칙에는 다음과 같은 법칙들이 존재합니다.
근접성의 법칙 (Proximity)
- 근접한 개체들은 동일한 개체로 인식된다

공통영역의 법칙 (Common Region)
- 공통영역 내에 배치된 요소들은 그룹으로 인식된다

유사성의 법칙 (Similarity)
- 유사하게 생긴 요소들은 같은 종류로 보인다

연속성의 법칙 (Continuation)
- 연속되는 요소는 하나의 흐름으로 인식된다

이러한 시각적 정보를 인식하는 과정에서 발생하는 인지적 현상은 내가 의도하는 것이 아니라 인간이라면 자동적으로 이루어지는 것이 특징입니다. 이 법칙들은 단순한 시각적 패턴 인식뿐만 아니라, 코드 가독성에도 동일하게 적용될 수 있습니다.
코드도 일종의 시각적 정보로, 개발자는 이를 어떻게 조직하고 해석할지를 고려해야 합니다. 가독성 높은 코드는 이 법칙들을 잘 활용하여, 코드의 구조와 배치가 자연스럽고 일관되게 인식될 수 있도록 합니다. 이를 통해 코드의 이해와 유지보수를 용이하게 만들 수 있습니다.
가독성이 떨어지는 이유
우리는 글을 읽는 체계를 가지고 있습니다. 글은 단순한 시각적 요소가 아니라, 언어이자 말의 표현이기에 우리는 글을 언어를 이해하는 방식으로 해석합니다. 그래서 글자를 개별적으로 읽기보다는, 단어와 문장 단위로 묶어서 읽어가며, 이 과정에서 패턴을 인식하고, 의미를 빠르게 추출합니다.
그러나 글은 시각적인 존재이기도 합니다. 그래서 우리는 글을 읽을 때, 그림을 보는 것처럼 시각적으로도 인식합니다. 예를 들어, 글자들이 어떻게 배치되어 있는지, 단어들 간의 간격이 어떤지 등을 시각적으로 처리합니다. 이러한 시각적 정보와 우리의 글 읽는 방식이 충돌할 때, 우리의 뇌는 추가적인 인지 노력을 필요로 하게 되어 가독성이 떨어지게 됩니다.

가령띄어쓰기가없는이러한문장은글자하나하나마다붙어있기때문에각글자들을하나씩분해해서읽어야하므로추가적인인지적노력이필요하기에가독성이떨어지게됩니다.

그러나 이렇게 띄어쓰기가 잘 되어 있는 문장의 경우에는단어단위로 읽히기 때문에 가독성이 훨씬 높아집니다.

또한 이렇게 볼드체로 중요한 내용을 달리 표기해준다면 글자를 개별로 읽는 것보다 패턴으로 인식하는데 도움을 주기에 정보를 시각적으로 잘 구조화 할 수록 인지부하가 낮아지게 되어 가독성이 향상이 됩니다.

그렇다고 글
의 의미와 무관하게시각적 효과가 적용이된다면 -> 사람은 시각적
인지효
과를 따라가기에이
를방해요소로 인식하고 주의를 빼앗겨 가독
성이 떨어지게 됩니다.
결국, 글의 가독성을 높이기 위해서는 시각적 배치와 문맥적 의미가 조화를 이루도록 하는 것이 중요합니다. 이는 읽는 사람의 인지 부하를 줄여주고, 정보를 더 쉽게 처리할 수 있도록 돕는 배려입니다. 좋은 코드를 작성하는 데 있어서도 이러한 법칙을 적용하면 가독성을 높이고 유지보수를 용이하게 만들 수 있습니다.
좋은 코드를 만들기 위해 알아야할 3가지 : 좋은 모양, 좋은 구조, 좋은 이름
좋은 코드를 작성하기 위해 알아야 할 중요한 세 가지 요소를 기억해 봅시다:
좋은 모양, 좋은 이름, 좋은 구조.
- 좋은 모양: 가독성, 유지보수성, 일관성
- 좋은 구조: 가독성, 확장성, 견고성, 테스트 가능성, 일관성
- 좋은 이름: 가독성, 유지보수성, 자기문서화, 일관성
첫번째, 좋은 모양 만들기!
근접성의 법칙 (Proximity)
근접성의 법칙 (Proximity)
- 근접한 개체들은 동일한 개체로 인식된다
띄어쓰기를하지않은문장의가독성이떨어지는것은근접한개체를동일한개체로인식하는데실제로는동일한개체가아니기때문에띄어쓰기를해야하는인지적부하를떠넘기게됩니다.
그래서 우리가 코드에서 의미 있는 개체 간 분리를 통해 인지적 노력을 돕기 위해 할 수 있는 것은 의미 단위로 구분해 주는 일입니다. 그렇기에 코드의 가독성에서 가장 중요한 것이 바로 Whitespace입니다.
Whitespace는 좋은 모양을 만들어주는 역할을 합니다. 코드에서 의미 단위를 구분 짓는 유일한 방법으로, 시각~적 단서로 작용하여 코드의 구조와 흐름을 명확히 합니다.~ 이는 읽는 사람의 인지적 부담을 줄여주고, 코드의 이해도를 높이며, 유지보수를 용이하게 만듭니다. 적절한 Whitespace 사용은 코드의 가독성을 높여, 개발자들이 코드를 빠르고 정확하게 파악할 수 있도록 도와줍니다.
띄어쓰기를 하지 않는 코드의 글자들은 근접성의 법칙에 따라 동일한 개체로 인식하나 실제 의미와 맞지 않게 띄어쓰기가 되어 있는 경우 가독성이 떨어집니다.
// Bad Code
function calculate(a,b){
let result=a+b;if(a>b){result +=10;}else{result-=5;}
return result;
}
// Good Code
function calculate(a, b) {
let result = a + b;
if (a > b) {
result += 10;
} else {
result -= 5;
}
return result;
}그래서 개발 초창기 시절부터 코드의 가독성을 높이기 위해서 ~어디를 띄어쓰고 어디를 줄바꿈해야 하는지는 아주 중요한 의미였고~ 중요한 논쟁거리였다.
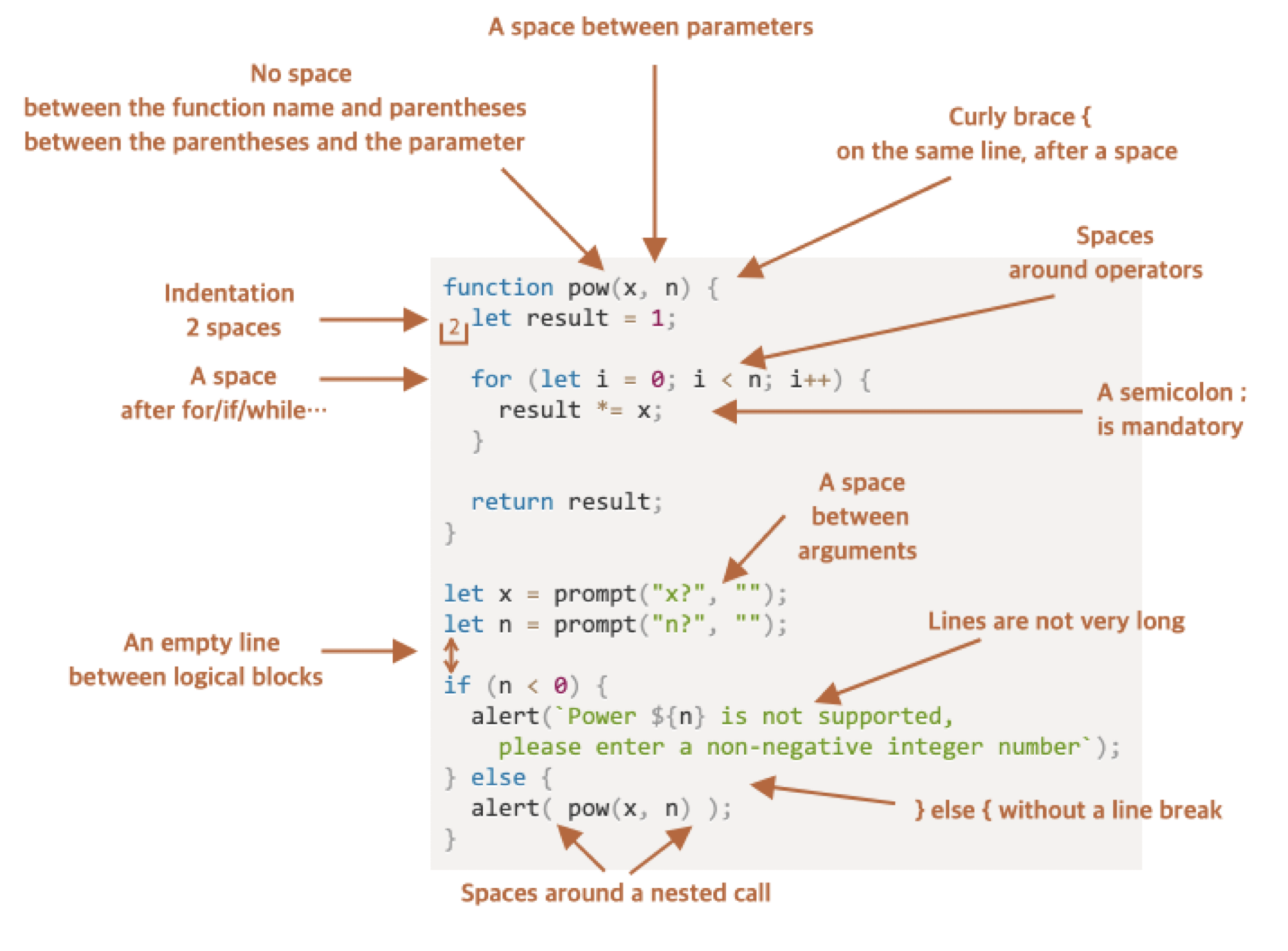
이처럼 Whitespace 사용은 단순히 예쁜 모양의 문제가 아니라, 코드의 가독성과 유지보수성을 높이는 중요한 요소입니다. 초기 개발자들은 어떠한 띄어쓰기를 했을때 왜 더 좋은 코드가 되는지 이해하는 것이 중요했고, 자기만의 철학을 가지며 이를 신경쓰면서 코딩을 하는 것이 중요했습니다.
이러한 이유로 코딩 스타일을 자동으로 맞춰주는 편의를 제공하는 포맷터가 등장하였습니다. 이러한 포맷터는 코드의 일관성을 유지하고 가독성을 높이기 위해 등장했지만, 사람마다 선호하는 스타일이 다르기 때문에 이를 맞추느라 어려움이 많았습니다. 그래서 프로젝트를 시작하기 전 이러한 규칙들을 정하는 팀 컨벤션을 맞추는 것이 중요한 과제였습니다.
어떤 띄어쓰기가 좋은 모양일까? 그러나 FE라면 고민말고 그냥 Prettier를 쓰세요.

킹치만... 2024년 FE는 다 부질없는 논쟁이다.
사실상 표준으로 Prettier가 자리매김하면서 우리는 Prettier를 좋든 싫든 써야만 한다.
개발자들은 전통적으로 코드 포맷터가 등장한 후에도 저마다의 코딩 철학을 고수하며 옵션 설정 과정에서 팀마다 다른 컨벤션을 두고 논쟁이 계속되었습니다. 포맷터들은 이러한 개발자들의 모든 철학들을 반양하기 위해서 다양한 옵션들을 제공했고 옵션이 다양해질수록 이러한 합의과정이 어려워져갔습니다.
그러던 중, 프리티어(Prettier)가 등장했습니다. 특이하게도 Prettier는 이러한 옵션의 다양성 문제를 해결하고자, 과감하게 대부분의 옵션을 제거해버리고는 일방적이고 강제적인 코드 포맷을 제공했습니다. 이러한 접근 방식은 처음에는 다소 일방적으로 느껴졌지만, ~선택의 여지가 없다는 점~이 결과적으로 팀 컨벤션을 통일시키는 역할을 했습니다.
2024년 현재, 프론트엔드 개발 씬에서는 다른 포맷터들이 거의 사용되지 않고 있으며, Prettier가 사실상 표준으로 자리 잡았습니다. 심지어 ESLint 마저도 포맷터 개발을 하지 않겠다고 선언했습니다. 결국 지금은 컨벤션의 역할로써, 그리고 포맷터의 역할로써 Prettier를 좋아하든 좋아하지 않던간에 javascript를 쓴다면 사용해야만 하는 상황이 되었습니다.
개인적으로 Prettier의 몇몇 강제적인 옵션들은 정말로 상당히 마음에 들지 않습니다. (특히나 else와 catch를 }와 함께 한줄에 적는 것 같은거 말이죠!) 하지만 싫어도 시대가 바뀌었네요. 종종 Prettier로 만든 코드가 되려 못생긴 코드를 만들어 줄때가 있습니다. 그러나 Prettier는 포맷터라기보다는 컨벤션의 역할을 하는 만큼, 이제는 Prettier를 통해 코드를 정리했을 때, 코드가 좋은 모양으로 나올 수 있도록 코드를 작성하는 것이 더 중요해졌다고 생각을 합니다.
Prettier의 강제적인 스타일에 익숙해지도록 노력하는 것이 중요합니다. 초기에는 불편할 수 있지만, 일관된 스타일의 장점을 이해하고 받아들이면 코드 품질과 팀의 협업 효율성이 크게 향상될 것입니다. 그러니 아직 Prettier를 사용하고 있지 않다면 도입을 해보는 것을 추천합니다.
Prettier 공식 사이트
https://prettier.io/
그러나 Prettier도 못 해주는 코드 포맷팅 : 줄바꿈과 주석!
우리가 이제 Prettier와 같은 자동 코드 포맷팅 도구를 사용하여 코드의 일관성을 유지하고, 가독성을 높이는 데 많은 도움을 받고 있지만 Prettier도 못 해주는 부분이 있습니다. 바로 줄바꿈과 주석입니다.
- 빈줄을 자동으로 생성하는 것은 매우 어렵다는 공식 사이트의 입장
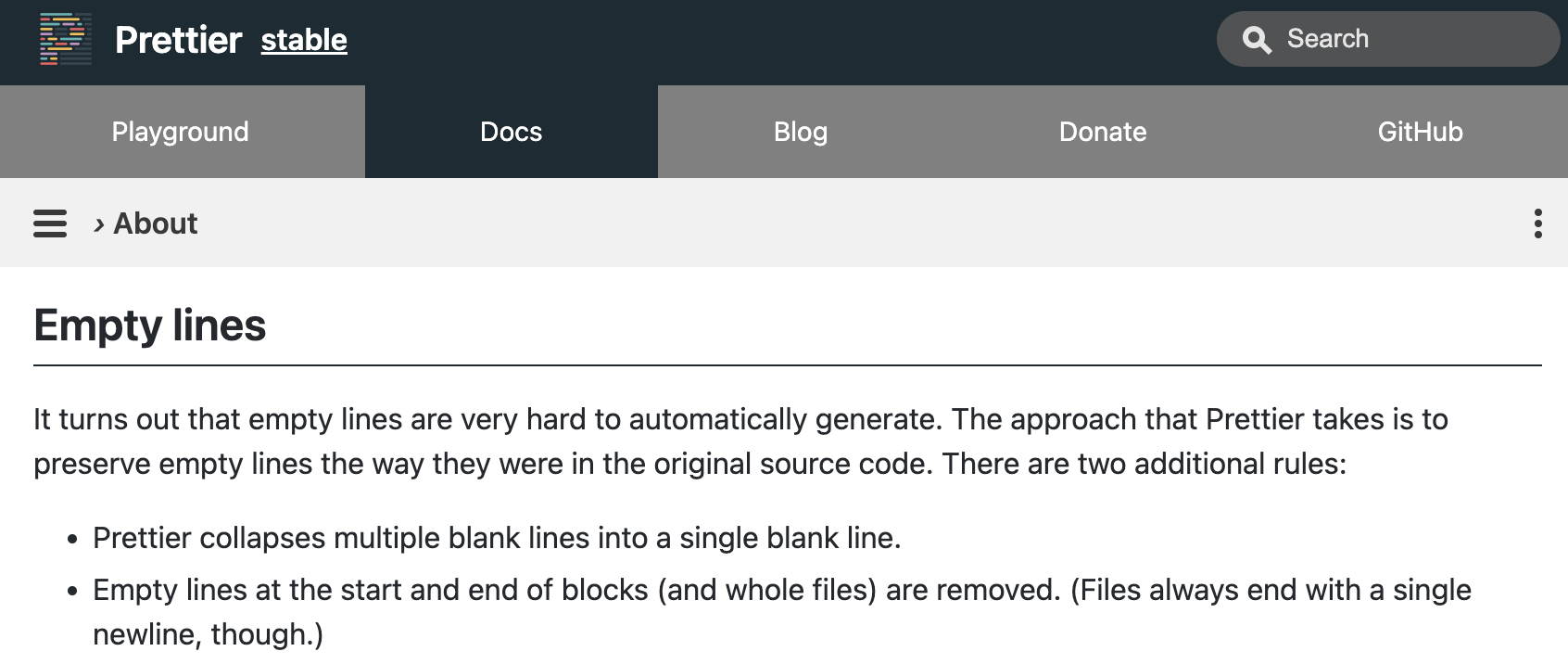
다음 예시를 보면 코드의 엔터를 입력하지 않으면 이 모든 코드를 동일한 하나의 개체로 인지하게 되어 코드를 파악하는데 어려움을 줍니다.
const processOrder = (items, discountCode) => {
const TAX_RATE = 0.1;
const DISCOUNTS = { SAVE10: 0.1, SAVE20: 0.2, HALFOFF: 0.5 };
let subtotal = 0;
for (let item of items) {
subtotal += item.price * item.quantity;
}
const tax = subtotal * TAX_RATE;
const total = subtotal + tax;
let finalPrice = parseFloat(total.toFixed(2));
if (discountCode in DISCOUNTS) {
finalPrice *= (1 - DISCOUNTS[discountCode]);
}
return parseFloat(finalPrice.toFixed(2));
};예시 코드라서 코드가 짧아서 와닿지 않을수도 있지만 엔터가 없는 코드는 띄어쓰기가없는글처럼 그룹의 구분을 해야하는 인지적 부담을 읽는 사람이 떠안게 됩니다.
그렇다면 빈줄과 주석을 잘 활용해서 충분히 구분해주고, 충분히 설명해 주면 코드는 어떻게 될까요?
const processOrder = (items, discountCode) => {
// 상수 정의
const TAX_RATE = 0.1;
const DISCOUNTS = {
SAVE10: 0.1,
SAVE20: 0.2,
HALFOFF: 0.5
};
// 소계 계산
let subtotal = 0;
for (let item of items) {
subtotal += item.price * item.quantity;
}
// 세금 계산 및 총액 계산
const tax = subtotal * TAX_RATE;
const total = subtotal + tax;
let finalPrice = parseFloat(total.toFixed(2));
// 할인 적용 (해당되는 경우)
if (discountCode in DISCOUNTS) {
finalPrice *= (1 - DISCOUNTS[discountCode]);
}
// 최종 가격 반환 (소수점 둘째자리까지)
return parseFloat(finalPrice.toFixed(2));
};
// 사용 예시
const orderItems = [
{ name: '상품A', price: 1000, quantity: 2 },
{ name: '상품B', price: 500, quantity: 3 }
];
const discountCode = 'SAVE20';
const finalPrice = processOrder(orderItems, discountCode);
console.log(`최종 가격: ${finalPrice}원`);빈줄을 통해 코드를 떨어뜨려 놓는 것만으로 인지적 부담이 줄어 가독성이 올라가며, 그룹마다 주석을 통해 간단한 레이블이 있다면 의미를 파악하기 위한 인지적 부담이 줄어 코드를 훨씬 더 가볍게 읽을 수 있게 됩니다. 이때 중요한 것은 정말로 ~실제로 동일한 개체끼리 근접~하게 만들고 ~그렇지 않은 코드간의 간격~을 만들어주는 것입니다.

엔터만 잘 쳐줘도 코드가 훨씬 더 좋은 모양을 하게 된다.
빈 줄을 통해 코드를 떨어뜨려 놓는 것만으로 인지적 부담이 줄어 가독성이 올라가며, 그룹마다 주석을 통해 간단한 레이블이 있다면 의미를 파악하기 위한 인지적 부담이 줄어 코드를 훨씬 더 가볍게 읽을 수 있게 됩니다. 이때 중요한 것은 정말로 동일한 개체끼리 근접하게 만들고 그렇지 않은 코드 간의 간격을 만들어주는 것입니다.
나머지 모양은 Prettier가 만들어줍니다. 그러니 이제 정말로 잘해야 하는 것은 줄바꿈과 주석입니다. 다른 사람의 인지적 부하를 줄여주기 위한 간격을 두고 설명하여 배려해보세요.
그러기 위해서는 어떤 코드끼리는 의미적으로 연관이 있고, 어떤 코드는 그렇지 않은지 아는 것이 정말로 정말로 중요합니다. 정말 중요하니까 꼭 꼭 연습을 하시기를 바랍니다.
두번째, 좋은 구조 만들기!
Prettier가 해주지 못하는게 또 하나 있습니다.
그것은 바로 코드의 배치 입니다.
글과는 다른 코드 가독성의 특징: 실행순서와 데이터의 흐름
코드는 읽는 방법은 글과는 다른 특징을 가지고 있습니다. 코드는 글과 달리 실행순서와 데이터의 흐름을 가지고 있기 때문에 읽는 방향이 일정하지 않습니다.
기본적으로 코드는 글과 같이 왼쪽에서 오른쪽으로 그리고 위에서 아래로 읽기는 하지만 글과는 달리 한방향으로만 읽는 것이 아니라 데이터의 흐름에 따라서 그리고 실행순서에 따라서 읽는 흐름을 여러개를 가지고 있습니다.
이때 코드를 읽어내려가는 흐름과 코드의 순서와 시각적인 효과가 충돌한다면 코드의 가독성이 떨어지게 됩니다. 그렇기에 좋은 코드는 모양뿐만이 아니라 좋은 구조를 가져야 합니다.
공통영역의 법칙 (Common Region)
공통영역의 법칙 (Common Region)
- 공통영역 내에 배치된 요소들은 그룹으로 인식된다
import React, { useState } from 'react';
const UserComponent = () => {
const [username, setUsername] = useState('');
const randomVariable = "This shouldn't be here"; // Bad Code
const [email, setEmail] = useState('');
const handleUsernameChange = (e) => {
setUsername(e.target.value);
};
// Bad Code
const randomFunction = () => {
console.log("This function is out of place");
};
const handleEmailChange = (e) => {
setEmail(e.target.value);
};
const anotherRandomVariable = 42;
const handleSubmit = (e) => {
e.preventDefault();
console.log(`Submitting: ${username}, ${email}`);
};위 예제에서 보듯이 빈 줄을 통해 그룹을 만들거나, 함수를 통해서 구역을 만들면 연관된 내용이 담겨 있을 거라고 기대하게 됩니다.
그러나 실제 코드의 논리적 블록이 그러하지 않을 때 우리는 혼란을 겪게 됩니다. 또한, 비슷한 장소에는 유사한 기능이 있을 것이라고 예측하지만, 그 예측이 빗나가면 혼란스럽게 됩니다.
유사성의 법칙 (Similarity)
유사성의 법칙 (Similarity)
- 유사하게 생긴 요소들은 같은 종류로 보인다
use로 시작하면 hook일 거라 생각합니다.
handle로 시작하면 이벤트 핸들러일 거라 예상합니다.
이렇듯 이름이 유사하면 유사할거라 생각합니다. 다음 코드에서 이상한 점을 찾아보세요
import React, { useState, useEffect } from 'react';
const UserComponent = () => {
// State 변수
const [username, setUsername] = useState('');
const [email, setEmail] = useState('');
// 핸들러 함수들
const handleUsernameChange = (e) => {
setUsername(e.target.value);
};
const handleEmailChange = (e) => {
setEmail(e.target.value);
};
const handleNameImportant = (name) => {
return name + "!"
}; // Bad Code
const handleSubmit = (e) => {
e.preventDefault();
console.log(`Submitting: ${username}, ${email}`);
};
함정을 눈치채셨나요?
같은 handle이라는 이름을 사용하지만 이벤트 핸들러가 아닌 함수가 존재합니다. 이런 경우 유사한 이름을 가졌기 때문에 쉽게 지나쳐버리게 됩니다.
일관성이 이래서 중요합니다. 일관성 없는 이름을 지으면 역할을 유추하기 위해 인지적 노력을 쓰게 되거나 인지적 노력을 덜하기 위해서 착각하고 대충 이해하도록 만들기도 합니다. 좋은 이름을 짓는 규칙에 대해서는 다음에 더 상세하게 다뤄보겠습니다.
연속성의 법칙 (Continuation)
연속성의 법칙 (Continuation)
- 연속되는 요소는 하나의 흐름으로 인식된다
코드를 작성할 때, 그 배치와 그룹핑을 어떻게 하느냐는 매우 중요한 실력입니다. 우리는 주로 두 가지 방법으로 코드를 그룹핑할 수 있습니다: 역할에 따라 분리하는 방법과 로직에 따라 분리하는 방법입니다.
1. 역할에 따라 그룹핑하는 방법
먼저, 역할에 따라 그룹핑하는 방법이 있습니다. 이 방법은 코드의 각 부분을 그 역할에 따라 분류하여 그룹핑하는 것입니다. 예를 들어, 상태를 관리하는 훅, 값을 계산하는 변수, 이벤트를 처리하는 핸들러 등을 각각 따로 그룹핑합니다. 이렇게 하면 각 코드 블록이 무엇을 하는지 명확히 구분할 수 있어, 필요한 부분을 쉽게 찾고 이해할 수 있습니다. 역할에 따라 그룹핑하면 코드의 의도가 명확해져 가독성이 높아집니다.
import React, { useState, useEffect } from 'react';
const RoleBasedComponent = () => {
// Hooks
const [count, setCount] = useState(0);
const [data, setData] = useState(null);
// Computed values
const doubledCount = count * 2;
const isEven = count % 2 === 0;
// Handlers
const handleIncrement = () => setCount(count + 1);
const handleFetchData = async () => {
const response = await fetch('https://api.example.com/data');
const result = await response.json();
setData(result);
};
// Effects
useEffect(() => {
handleFetchData();
}, []);2. 로직에 따라 서로 연관된 데이터끼리 그룹핑 하는 방법
다음으로, 로직에 따라 그룹핑하는 방법이 있습니다. 이 방법은 관련된 로직을 하나의 그룹으로 묶어 데이터의 흐름을 따라갈 수 있게 하는 것입니다. 예를 들어, 카운트 관련 로직을 하나의 그룹으로, 데이터 가져오기 로직을 또 다른 그룹으로 묶습니다. 이렇게 하면 서로 관련된 코드가 가까이 있어, 코드의 흐름을 쉽게 파악할 수 있습니다. 로직에 따라 그룹핑하면 디버깅이나 기능 추가 시 관련된 부분을 한눈에 볼 수 있어 효율적입니다.
import React, { useState, useEffect } from 'react';
const LogicBasedComponent = () => {
// Count-related logic
const [count, setCount] = useState(0);
const doubledCount = count * 2;
const isEven = count % 2 === 0;
const handleIncrement = () => setCount(count + 1);
// Data fetching logic
const [data, setData] = useState(null);
const handleFetchData = async () => {
const response = await fetch('https://api.example.com/data');
const result = await response.json();
setData(result);
};
useEffect(() => {
handleFetchData();
}, []);실제 디버깅 과정에서는 코드의 흐름을 따라갈 수 있도록 만들어내는 코드가 훨씬 더 인지적 부담이 적습니다. 또한, 이러한 코드가 해당 그룹 밖에서 사용되지 않을 것이라는 생각에도 부합합니다.
하지만 예제와 달리 더 길이가 긴 코드에서는 이렇게 작업하다가는 그룹이 매우 복잡해지고 길어지면서 오히려 시각적으로 그룹핑이 되어 보이지 않아 시각적 안정감을 잃고 읽기가 어려워집니다.
결론적으로, 코드 배치 전략은 역할에 따라 그룹핑할 것인지, 로직에 따라 그룹핑할 것인지에 따라 달라집니다. 각각의 방법은 장단점이 있으며, 코드의 성격과 목적에 따라 적절하게 선택해야 합니다. 역할 기반 그룹핑은 코드의 의도를 명확히 하고, 로직 기반 그룹핑은 코드의 흐름을 쉽게 파악할 수 있게 합니다. 이러한 전략을 잘 활용하면 코드의 가독성과 유지보수성을 크게 향상시킬 수 있습니다.
균형감각이 중요하다 : 모두 만족시킬 방법을 찾기
코드의 배치의 전략의 방향성을 설명했지만 이 둘을 서로 베타적이지 않으며 얼마든지 둘다 만족하는 형태의 코드를 작성할 수 있습니다. 어느 한쪽을 타협하는 것이 아니라 모두의 법칙을 만족하는 방법을 찾아내겠다고 하는 시각이 중요합니다.
아래 코드는 왜 안 좋은 코드일까요?
const [token, setToken] = useState();
const [userInfo, setUserInfo] = useState();
useEffect(()=>{
start();
},[])
const start =async()=>{
const response = await getToken();
setToken(response.data);
}
useEffect(()=>{
if(token) start2();
},[token])
const start2 = async()=>{
const response = await getUserInfo();
setUserInfo(response.data);
}
return <>
{token && <div>토큰이 있을 때 보여야 하는 부분</div>}
{userInfo && <div>유저정보가 있을 때 보여야 하는 부분</div>}
</>흐름을 따라가는 듯 코드를 작성한것 같지만 실제 코드의 흐름을 이해하기 위해서는 실행순서의 흐름을 찬찬히 따져보고 의존성을 따져가며 흐름을 추적해야 합니다. 관련된 로직이 어떻게 연결이 되어 있는지 시각적으로 드러나지 않게 때문에 좋지 못한 코드입니다.
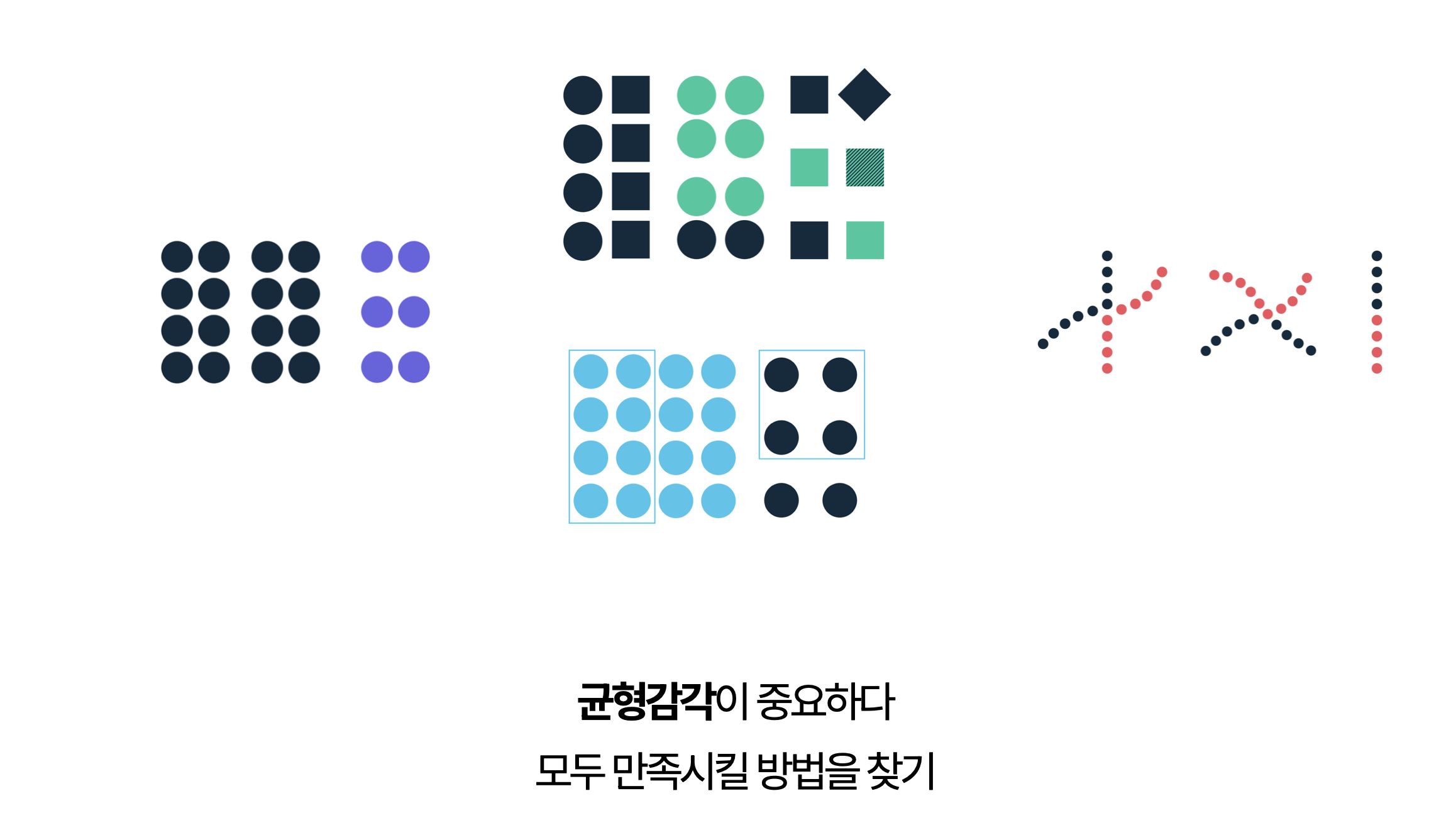
하나의 방법이 아니라 여러가지 법칙들을 종합해서 목표하고자 하는 바를 이룰 수 있는 방법을 찾아봅시다.
- 결국 token과 userInfo 만 있으면 된다.
- 서로 연관된 데이터끼리 묶고 함수로 공통영역을 만들자.
- 유사한 이름과 구성으로 예측 가능하게 작성한다.
- 전체적인 흐름을 유지할 수 있도록 순서를 배치
const useToken = () => {
const [token, setToken] = useState()
useEffect(() => {
const fetchToken = async => {
....
setToken(token)
}
fetchToken()
}
return [token]
}
const useUserInfo = (token) => {
const [useInfo, token] = useState()
useEffect(() => {
const fetchUserInfo = async => {
....
setUserInfo(userInfo)
}
fetchUserInfo()
}, [token])
return userInfo
}
function Component(props) {
const token = useToken()
const userInfo = useUserInfo(token)
return <div>
{token}
{userInfo}
</div>
}분명히 좋은 코드의 특징이 드러나도록 법칙들을 적절히 적용하여 만들 수 있는 방법이 존재합니다. 균형감각을 유지하는 것은 코드의 가독성과 유지보수성을 높이는 데 중요합니다. 위 예제처럼 관련된 데이터와 로직을 그룹핑하고, 흐름을 자연스럽게 유지하면서 코드의 예측 가능성을 높이면 좋은 코드가 될 수 있습니다. 코드 배치와 그룹핑은 항상 균형을 고려하여 진행해야 합니다.
셋째, 좋은 이름 짓기!
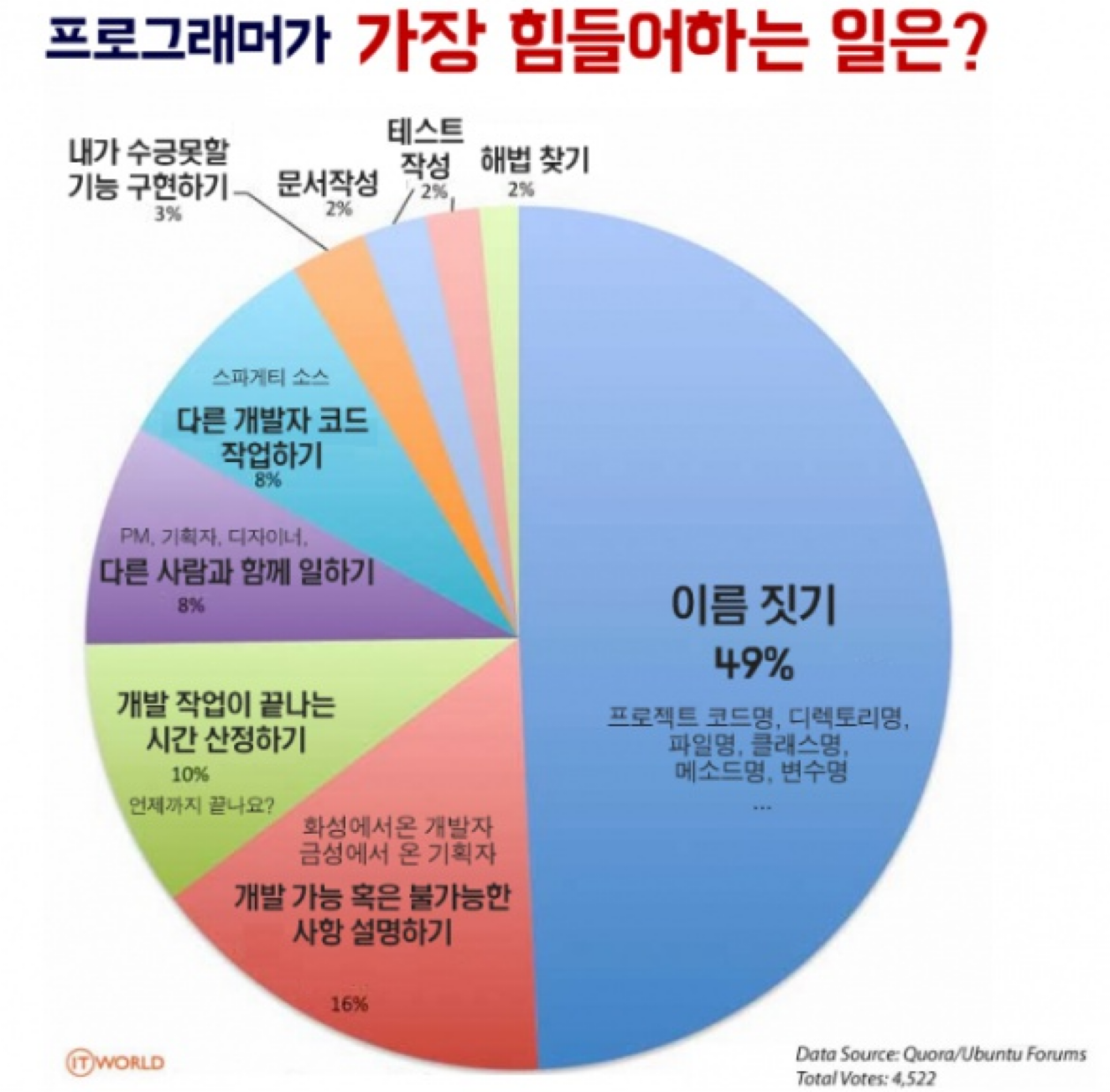
프로그래밍에서 가장 어려운 두 가지 중 하나가 '이름 짓기'라고 합니다. 왜 이렇게 이름 짓기가 어려울까요? 이름이 단순한 식별자를 넘어 코드의 의도와 목적을 전달하는 핵심 요소이기 때문입니다. 좋은 이름은 코드를 문서화하고, 버그를 예방하며, 유지보수를 용이하게 만듭니다. 이제 이 '이름 짓기'의 효과적인 방법에 대해 살펴보겠습니다.
좋은 이름 짓기: 상세함과 간결함의 균형
코드의 가독성을 높이기 위해서라면 어떻게 이름을 지어야 할까요? 이 코드를 읽는 다른 사람들의 인지적부담을 줄여주기 위해 최대한 상세하게 설명적으로 만들어봅시다.
function calculateTotalPriceOfAllItemsInTheShoppingCart() { // ... }위 함수 이름은 매우 매우 설명적이지만, 너무 긴 이름을 다음과 같은 문제가 있습니다:
- 길이가 너무 길어 한 눈에 파악하기 어렵습니다.
- 코드의 줄 길이를 늘려 전체적인 구조를 보기 힘들게 만듭니다.
- 타이핑하고 기억하기 어려워집니다.
- 오히려 너무 많은 정보로 인해 핵심을 놓칠 수 있습니다.
이렇듯 설명적인 이름이더라도 꼭 필요하지 않는 정보들은 오히려 방해요소가 되어 코드의 가독성을 해칩니다. 단순한 지도보다 보다 상세한 항공사진이 되려 길을 더 찾기가 어려운 이유입니다.
폐쇄성의 법칙 (Closure)
폐쇄성의 법칙 (Closure)
모든 정보가 존재하지 않더라도 형태로 인식할 수 있다.
게슈탈트 심리학의 폐쇄성의 법칙은 우리에게 중요한 통찰을 제공합니다. 이 법칙에 따르면, 우리의 뇌는 불완전한 정보가 있어도 전체 형태를 인식할 수 있습니다.
이 법칙에 따르면 우리는 이름을 지을 때 모든 세부 사항을 포함하지 않아도 됩니다. 대신, 핵심적인 정보만을 담아 간결하면서도 의미 있는 이름을 만들 수 있습니다. 이는 다음과 같은 이점을 제공합니다:
- 읽기 쉽고 빠르게 이해할 수 있습니다.
- 전체 코드 구조를 파악하기 쉬워집니다.
- 작성과 유지보수가 용이합니다.
- 핵심 아이디어를 더 명확히 전달할 수 있습니다.
그렇다면 어디까지 간결하게 해야 할까요? : 적절한 간결함의 기준
그렇다면 어디까지 간결하게 해야 할까요? 답은 "최대한 간결하게 단, 형체를 알아볼 수 있을 만큼" 입니다.
즉, 간결함과 예측 가능성이 좋은 코드를 만들어 내는 척도가 됩니다.
변수명은 이름에서 값의 역할과 타입을 모두 알 수 있어야 합니다. 만약 역할과 타입이 예측이 되지 않는 이름이라면 is-, has-, -s 등을 붙여서 타입을 예측가능하게 만들면 좋은 이름이 됩니다.
/// Good Code
const age = 25; // number type
const name = "John"; // string type
const isActive = true; // boolean type
const users = ["Alice", "Bob", "Charlie"]; // array type
const userInfo = { id: 1, name: "John", age: 25 }; // object type
/// Bad Code
const u = 25; // 의미를 알 수 없는 변수명
const str = "John"; // 타입만 알 수 있고 의미를 알 수 없음
const flag = true; // boolean이지만 무엇을 나타내는 flag인지 알 수 없음
const arr = ["Alice", "Bob", "Charlie"]; // 배열이지만 무엇의 배열인지 알 수 없음함수 이름은 동작, 반환값, 입력값, 맥락을 모두 암시해야 합니다.
- 동사: 함수의 동작 (예: calculate, get, set)
- 명사: 처리하는 대상이나 반환값 (예: Total, Items)
- 전치사: 입력값이나 조건 (예: By, For, With)
- 형용사: 추가적인 맥락 (예: Active, Latest)
// Good Code 예시
function getActiveUsersByGroup(groupId) { /* ... */ }
function calculateTotalPrice(items) { /* ... */ }
function setUserPreferences(userId, preferences) { /* ... */ }
function fetchLatestPosts() { /* ... */ }
function validateEmailFormat(email) { /* ... */ }
// Bad Code 예시
function process(data) { /* ... */ } // 너무 모호함
function doStuff() { /* ... */ } // 무엇을 하는 함수인지 알 수 없음
function handleIt(x) { /* ... */ } // 무엇을 처리하는지, 입력이 무엇인지 알 수 없음
function returnObjects() { /* ... */ } // 어떤 객체를 반환하는지 불분명
function checkAndUpdate() { /* ... */ } // 무엇을 체크하고 업데이트하는지 불분명예를 들어, getActiveUsersByGroup(groupId)라는 함수 이름은 동작(get), 대상(Users), 조건(Active, ByGroup), 입력값(groupId)을 모두 예측이 가능하므로 좋은 이름입니다.
간결하게 만들어보기
이제 앞서 본 긴 함수 이름을 줄여보겠습니다:
function calculateTotalPriceOfAllItemsInTheShoppingCart() { // ... }- calculate: 함수의 동작을 나타냅니다. 계산하는 역할을 합니다.
- TotalPrice: 반환값을 예측할 수 있도록 합니다. 하지만 Total로 충분히 같은 의미를 전달할 수 있습니다.
- OfAllItems: Total과 중복되는 의미를 가집니다. All과 Items는 생략 가능합니다.
- InTheShoppingCart: ShoppingCart는 중요한 의미를 가집니다. 그러나 Cart만으로도 충분히 예상 가능합니다. Shopping과 The는 생략 가능합니다.
이를 다음과 같이 줄일 수 있습니다:
function calculateCartTotal() { // ... }-
동작을 나타내는 동사 유지: calculate는 함수가 무엇을 하는지 명확히 설명합니다. 계산하는 동작을 나타내므로 유지합니다.
-
반환값을 예측할 수 있도록: TotalPrice 대신 Total을 사용하여 반환값이 전체 금액임을 예측할 수 있도록 합니다. Price는 Total로 대체 가능합니다.
-
중복 제거: OfAllItems는 Total과 의미가 중복됩니다. 이미 전체를 의미하므로 생략합니다.
-
중요한 정보는 유지, 불필요한 부분은 제거: ShoppingCart에서 Cart만으로도 충분히 의미가 전달됩니다. Shopping과 The는 생략 가능합니다.
맥락에 따른 이름 짓기
for문에서는 i 로 변수명을 지어도 충분하지만 경우에 따라 index로 분명하게 적어주여야 하거나, 다음과 같이 selected- 까지 붙여서 더 명확한 맥락을 제공해야 하는 경우도 있습니다.
const selectedIndex = items.findIndex(item => item.id === selectedId);얼마나 구체적인 이름을 가져야 하는지, 혹은 얼마나 간결한 이름을 가져도 되는지는 그 이름이 쓰이고 있는 맥락에 따라 달라집니다.
// 로컬 함수 내부에서는 간단한 이름으로 충분합니다.
function updatePagination() {
let page = 1;
// ...
}
// 더 넓은 스코프에서는 맥락을 추가해 이름을 지어줍니다.
function handlePageChange(newPage) {
const currentPage = newPage;
// ...
}
// 전역 변수나 상수는 맥락에 대한 정보가 없으므로 매우 구체적으로 이름을 지어야 합니다.
const MAX_ITEMS_PER_PAGE = 20;
const PAGINATION_VISIBLE_PAGES_COUNT = 5;이처럼 맥락에 따라 이름의 구체성을 조절할 수 있습니다. 로컬 스코프에서는 간단한 이름으로 충분하지만, 스코프가 넓어질수록 더 많은 맥락 정보를 이름에 포함시켜야 합니다.
보편적인 이름 사용하기 : 자주 쓰는 코드 이름들은 사실 정해져 있다.
맛집 이론을 기억하세요. 보편적으로 좋아하는 데는 다 이유가 있습니다. 좋은 것은 특이한 게 아니라 보편적이어서 좋은 것입니다. 코드에 쓰이는 보편적인 이름을 추구하려고 합시다.
- create~(), add~(), push~(), insert~()
- parse~(), make~(), build~(), split~()
- query~(), mutation~(), fetch~(), update~(), delete~()
- save~(), put~(), send~(), dispatch~(), receive~()
- validate~(), calc~(), serialize~()
- init~(), configure~(), start~(), stop~()
- generate~(), transform~(), log~()
변수나 속성 이름도 마찬가지입니다:
- count~, sum~, num~
- is~, has~
- ~ing, ~ed
- min~, max~, total
- ~name, ~title, ~desc, ~data
- item, temp
- ~at, ~date, ~index
- selected~, current~
- ~s (복수형)
- ~type, ~code, ~ID, ~text
- params, error
이러한 원칙들을 따르다 보면, 자연스럽게 좋은 이름들이 반복해서 사용되는 것을 발견할 수 있습니다. 이는 우연이 아닙니다. 좋은 이름은 보편성을 가지며, 이를 통해 코드의 일관성과 가독성이 향상됩니다.
이러한 보편적인 이름들을 사용하면 다른 개발자들이 코드를 읽을 때 더 쉽게 이해할 수 있습니다. 하지만 단순히 사용하는 것에 그치지 말고, 각 이름이 가진 정확한 의미와 용도를 알고 사용해야 합니다.
보편적인 이름들의 정확한 뉘앙스 파악하고 있기
좋은 코드를 작성할 때는 보편적으로 사용되는 이름들의 정확한 뉘앙스를 파악하는 것이 중요합니다. 예를 들어, 'create()', 'add()', 'push()', 'insert()' 등은 모두 새로운 요소를 추가하는 의미를 가지지만, 각각의 사용 맥락이 다릅니다. 'create()'는 새로운 객체를 생성할 때, 'add()'는 기존 집합에 요소를 추가할 때, 'push()'는 주로 배열이나 스택의 끝에 요소를 추가할 때, 'insert()'는 특정 위치에 요소를 삽입할 때 사용합니다.
마찬가지로 'fetch()', 'retrieve()', 'load()', 'get()' 등도 모두 데이터를 가져오는 의미를 가지지만 사용 맥락이 다릅니다. 'fetch()'는 주로 원격 데이터를 가져올 때, 'retrieve()'는 저장된 데이터를 검색할 때, 'load()'는 파일이나 리소스를 불러올 때, 'get()'은 일반적인 데이터 접근 시 사용합니다.
유사하지만 미묘한 차이를 지니는 단어들도 있습니다. 가령 'current'는 현재 활성화된 항목을, 'selected'는 사용자에 의해 선택된 항목을 의미합니다.
이러한 미묘한 차이를 이해하고 적절히 사용하면, 코드의 의도를 더 명확히 전달할 수 있으며, 다른 개발자들이 코드를 더 쉽게 이해하고 유지보수할 수 있게 됩니다.
각 이름들은 어떤 차이들이 있을까요?
- create(), add(), push(), insert()
- fetch(), retrieve(), load(), get()
- update(), modify(), edit(), change()
- remove(), delete(), clear(), erase()
- find(), search(), lookup(), query()
- check(), validate(), verify(), test()
- convert(), transform(), parse(), format()
- render(), display(), show(), present()
- toggle(), switch(), flip(), alternate()
- mount(), attach(), append(), connect()
- unmount(), detach(), remove(), disconnect()
- subscribe(), listen(), observe(), watch()
- unsubscribe(), unlisten(), ignore(), stopWatching()
- dispatch(), emit(), trigger(), fire()
- handle(), process(), manage(), deal()
- isOpen, isVisible, isActive, isEnabled
- onSubmit, onSend, onConfirm, onApply
- setState, updateState, setProps, updateProps
- useEffect, useCallback, useMemo, useRef
끝으로...
맛은 주관적인것이지만, 분명 맛집은 존재한다.
분명 맛집은 존재하지만, 맛은 주관적인 것이다.
제가 좋아하는 표현입니다. '맛은 주관적이지만 맛집은 존재합니다. 그리고 맛집이 존재하지만 맛은 여전히 주관적입니다.' 앞서 좋은 코드에 대한 여러가지 기준들을 여러가지 기준과 특성들을 설명했지만 이 코드가 좋은지 좋지 않은지 점수를 매기는 것은 나의 주관적인 판단입니다. 나에게 잘 읽히고 나의 기준으로 좋은 구조이며 나는 이러한 방식으로 확장하거나 유지보수하기가 좋다면 분명 좋은 코드입니다.
하지만 맛이 주관적이라도 맛집은 존재하듯이 좋은 코드의 기준은 사람마다 미묘하게 달라도 앞서 설명한 7가지 특성을 갖춘 코드는 대개 모두가 좋은 코드라고 생각을 합니다. 좋은 코드를 작성하기 어려운 이유는 나만 만족시키면 되는게 아니라 대부분을 만족시켜야 하기 때문입니다. 결국 좋은 코드를 만들어내기 위해서는 나의 주관적인 기준을 만족시키는 코드를 작성하면서도 팀의 합의를 바탕으로 작성할 수 있어야 합니다. 그래서 어렵습니다.
결국 팀 내에서 일관성을 유지하는 것이 중요합니다. 맛집은 존재해도 맛은 주관적이기에 내가 보기에는 그러한 규칙과 일관성들이 완벽해 보이지 않더라도, 어쩄든 팀원 모두가 예측 가능하고 합의한 규칙이라면 그 코드가 좋은 코드라고 할 수 있습니다. 내 주관과 다른 코드와 함께 하는 건 개발자에게는 참 힘든 경험이지만 결국 좋은 코드는 팀 내에서 합의를 통해 정립되고 유지되는 과정에서 만들어집니다. 어쨌든 팀 내에서 모두가 동의하고 일관성을 유지하는 코드는 결국 좋은 코드로 인정받게 됩니다. 그래서 어렵습니다.
좋은 코드를 만들기 위해 존재하는 개발 문화들
좋은 코드를 작성하기 위해 우리는 다양한 개발 문화를 도입합니다. 다음은 좋은 코드를 작성하기 위해 도입하는 대표적인 개발 문화들입니다.
팀 컨벤션
팀 컨벤션은 팀 내에서 코드 작성 규칙을 정하고 일관성 있게 유지하는 것입니다. 이는 모든 팀원이 동일한 스타일로 코드를 작성하게 하여 예측 가능하고 일관성 있는 코드를 유지하게 합니다. 팀 컨벤션을 통해 팀 전체의 코드 품질을 높일 수 있습니다.
리팩토링
리팩토링은 기존 코드를 개선하는 과정입니다. 이는 코드의 가독성, 유지보수성, 확장성을 높이는 데 필수적입니다. 리팩토링은 좋은 코드를 유지하기 위한 수단으로 이해해야 합니다. 프로젝트 일정과 자원의 제한 속에서 리팩토링을 적절히 수행하여 코드의 품질을 높이는 것이 중요합니다.
코드 리뷰
코드 리뷰는 팀원 간의 코드 스타일을 맞추고, 서로의 코드를 보면서 배우는 과정입니다. 코드 리뷰의 목적은 단순히 코드의 오류를 찾는 것이 아니라, 팀의 코드 품질을 높이고 일관성을 유지하는 것입니다. 코드 리뷰를 통해 서로의 코드를 보고, 피드백을 주고받으며, 좋은 코드를 작성하려는 노력을 지속하는 것이 중요합니다.
하지만, 현실은 어떨까? Welcome to Real-World!

대다수의 신입 개발자들은 대부분의 개발 회사들이 TDD를 하고, 코드 리뷰를 철저히 하는 줄 압니다. 그런데, 막상 현업에 들어와 보면 그렇지 않은 경우가 많습니다. 실제로 팀의 분위기, 문화, 프로젝트의 특수성 등 여러 가지 이유로 그런 상상하는 이상적인 환경을 갖추는게 현실적으로 어려운 것이지만, 대개 신입 개발자분들이 현실을 마주하게 되면 다음과 같은 생각들을 하곤 합니다.
"우리 회사는 리팩토링 할 시간을 안 줘요"
아니, 왜 리팩토링 시간을 안 주는 걸까요? 신규 기능을 추가할 때마다 과거에 쌓인 '기술 부채'와 맞서 싸워야 하잖아요. 새 코드를 추가할 때마다 옛날 코드와 충돌해서 해결하느라 진땀을 빼고, 결국 수정한 코드가 또 다른 문제를 일으키는 악순환을 겪을 텐데요. 이렇게 쌓여가는 문제들이 결국 프로젝트의 발목을 잡을 텐데, 리팩토링할 시간을 주지 않으면, 어떻게 코드 품질을 유지할 수 있겠어요?
"우리 회사는 테스트를 안 해요"
아니, 왜 테스트를 안 하는 걸까요? 새로 작성한 코드가 제대로 동작하는지 확인할 때마다 불안할 텐데요. 코드를 수정할 때마다, "이게 다른 부분에 영향을 주진 않을까?"라는 걱정이 끊이지 않겠죠. 배포 전날 밤마다 불면증에 시달리며 수동으로 테스트를 반복하는 상황, 도대체 언제까지 계속해야 하는 걸까요? 물론, 모두가 바쁜 프로젝트 일정 속에서 테스트 코드를 작성할 시간이 없다는 점은 이해하지만, 그래도 이렇게 불안한 상태로 코딩을 계속해야 한다니요.
"우리 회사는 코드 리뷰를 안 해요"
아니, 왜 코드 리뷰를 안 하는 거죠? 그러면 팀원들이 각자 자신의 코드만 바라보며 일하는 거잖아요. 새로운 기능이 배포될 때마다 예상치 못한 버그가 터질 텐데요. 서로의 코드를 읽어볼 기회가 없으니, 코드 스타일도 제각각이고, 나중에는 누구 코드인지도 기억나지 않겠죠. 가끔은 내가 예전에 쓴 코드조차 낯설게 느껴질 수도 있어요. 팀워크가 중요한데, 코드 리뷰 없이 각자 알아서 코딩하면, 이래서야 어떻게 협업을 하겠어요?
어떻게 하느냐가 중요한게 아니라 한다는 사실이 중요하다
특히 많은 주니어분들이나 취준생분들이 코드 리뷰는 어떻게 해야 잘 하는거냐고 물어보곤 합니다. 그리고 우리 회사는 혹은 우리팀은 이런게 제대로 되어 있지 않다며 분통을 터뜨리고는 합니다. 그러나 사실 팀마다 문화가 달라서 어떤 팀은 엄격한 규칙을 가지고 코드 리뷰를 하고, 어떤 팀은 거의 하지 않습니다. 그렇다고 말해줘도 대개 잘 믿지는 않더라구요. TDD나 리팩토링만 하는 시기를 따로 가지는 피트인과 같은 문화 또한 회사마다 팀마다 다르기 마련입니다.
결국 중요한 것은 코드 리뷰를 통해서라도 남의 코드를 읽어보는 경험을 하고, 좋은 코드인지 판단해보는 경험을 쌓는 것입니다. 이를 통해 내 코드 역시 누군가에게 보여질 경우 어떻게 보일지 생각할 수 있게 됩니다. 코드 리뷰가 특정한 방법으로 행해지지 않더라도 뭔가 팀에서 제대로 이루어지지 않는다고 생각이되어도 사실 어떤 이유로든간에 남의 코드를 읽어보는 것, 그리고 내 코드 역시 남들에게 이렇게 읽혀지겠구나만 인식할 수 있어도 충분히 의미가 있습니다.
항상 내 코드는 남에게 보여주기 위해 작성된다는 사실을 인지하면 더 좋은 코드를 작성할 수 있게 됩니다. 팀 컨벤션, 코드리뷰, TDD등은 이러한 인식을 하기 위한 장치이며 좋은 코드를 작성하기 위한 수단이나 일종의 매뉴얼입니다. 결국 이 도구들이 중요한 것은 개발문화 그 자체라기보다는 좋은 코드를 작성하려는 의지와 노력이 중요합니다. 때로는 잘못된 인식이 과장되어 주객이 전도되는 바람에 코드리뷰, 테스트를 위한 문화나 장치들이 되어 오히려 좋은 코드를 만들지 못하게 하거나 경직된 개발문화를 가져오는 경우도 있습니다.
결국 좋은 코드를 만들이 위한 일환이라는 것을 이해하면 TDD는 아니지만 테스트를 하기 좋은 형태로 코드를 만들어 본다거나, 좋은 코드에 대해서 각자 수다를 떨어보는 시간을 가지거나, 페어 프로그래밍을 해보거나 필요한 피드백이나 도움 요청들을 통해서 얼마든지 현실적인 상황에서 좋은 코드를 만들어가려는 노력들을 얼마든지 할 수 있습니다. 결국 중요한 것은 좋은 코드를 만들어 내는 것이니까요.
테스트, 코드리뷰는 헬스 같은 거에요
좋은거 아는데 그래서 해보고 싶은데 막상 하면 귀찮고 하기 힘듭니다.
왜 코드 리뷰를 문화로 만드는 걸까요? 그렇게 안하면 안하기 때문입니다. (웃음)
내가 먼저 해보자고 하세요.
다들 여러분과 비슷한 마음일거에요.아니면 혼자라도 해보세요.
일단 해본 것과 안해보는 것은 다릅니다.

내 코드를 설명하고 남의 코드를 읽고 본인의 코드 철학을 정립해나가봐요
좋은 코드에 대한 해상도를 높여나가는게 중요합니다. 남의 코드를 많이 읽어보면서 잘 읽히는 배려를 받았다면 혹은 그렇지 못한 순간을 느꼈다면 왜 그런가에 대해서 이러한 개념들을 바탕으로 고민해보고 더 선명해지고자 해봅습니다. 내 철학에 탑재하고 잘 읽히지 않았다면 왜 그런지 한번 찬찬히 파악하면서 남이 봤을때의 가독성의 의미를 새겨볼 수 있느 시간이 되기를 바랍니다.
좋은 코드를 만드는 것은 단순한 기술적 스킬이 아닙니다. 그것은 우리 자신과 동료를 위한 배려이자 프로젝트의 지속 가능성을 위한 미래에 대한 투자입니다. 완벽한 환경이나 이상적인 개발 문화가 없더라도, 우리 각자가 할 수 있는 작은 노력들이 모여 큰 변화를 만들어 냅니다.
남의 코드를 읽어보고, 내 코드를 설명해보고, 팀원들과 좋은 코드에 대해 이야기를 나누어 보세요. 그 과정에서 여러분의 코드 철학은 더욱 선명해지고, 좋은 코드에 대한 '해상도'는 높아질 것입니다.
이 글이 좋은 코드란 무엇인지 조금 더 시각적으로 그리고 철학적으로 생각해볼 수 있는 계기가 되기를 바랍니다. 감사합니다.
ps. 그리고 뭐니 뭐니 해도 일단 정석을 아는게 중요합니다. 실제로 클린코드를 어떻게 해야하는지 더 궁금한 사람은 <클린코드>와 <리팩토링 2판>을 추천합니다. 꼭 책을 사지 않아도 인터넷에 좋은 자료들이 참 많아요.
https://prettier.io/
Refactoring and Design Patterns
https://github.com/Youngerjesus/refactoring-2nd-edition?tab=readme-ov-file
https://refactoring.com/catalog/

16개의 댓글

다양한 요구를 반영해서 포맷팅 옵션을 늘려줬더니 합의가 더 어려워지고 강제로 맞추니 다들 (반강제로?) 고분고분해지는 인생의 아이러니..

피곤한 퇴근길 집중하고 다읽어버렸네요
1년차 개발자로 일하며 코드에대한 발전적인 시각이 없는 회사에 일한다 생각하고 혼자라도 이런 클린코드를 공부하고있었습니다
그래서 오늘 본 이 글이 너무 반갑다라고 해야할까요 아무튼 정신없이 보다가 마지막 글에서 울컥 하네요 선배(?)님의 조언을 새겨들어 조급해 하지않고 꾸준히 노력하겠습니다.
결국 좋은코드를 만들기위한 본질적인 이유를 상기시켜주셔서 감사합니다


좋은 글 발행해주셔서 감사합니다 :)
게슈탈트 법칙으로, 클린코드 연결시켜서 설명한 부분이
이해를 크게 도와준 글이네요.
독후감으로,
사람의 인지하는 원리를 기반으로 좋은 코드를 생각하면, 더우더 다양한 가독성을 좋아질 수 있는 다양한 방법들이
나올 수도 있을 것 같다는 느낌을 받았습니다 ^^

진짜 정말로 유익한 글이네요 항상 짧은 코드를 짜면 더 좋은 코드라 생각했는데 협업할 때 그래도 상대방이 이해 할 수 있는 코드를 짜야겠습니다. 감사합니다.

글이 긴데도 불구하고 정말 잘 읽히네요! 좋은 글 발행해주셔서 감사드립니다 :)
덕분에 '클린코드' 라는 다소 주관적일 수 있는 개념을 최대한 객관적으로 평가할 수 있게 해주는 방법을 알게 되었습니다.
글의 핵심과는 상관없는 마이너한 부분이긴 한데, 혹시나 해서 질문드립니다!
"좋은 코드란 과연 무엇일까요?" 섹션을 읽다가 든 생각인데요 예시로 들어주신
f(x , y)함수와calculateDifference(firstNumber, secondNumber)함수의 body를 보면x + y와firstNumber + secondNumber라는 표현식이 보이는데, 함수의 맥락을 고려한다면 이 부분이x - y와firstNumber - secondNumber가 되어야 하는게 아닌가? 하는 생각이 들더라구요!