
본 포스팅은 항해 DEV LAB 미니 학술회에서 발표했던 내용을 바탕으로 작성하였습니다.
최근 프론트엔드 개발에서 주목받는 FSD 아키텍쳐 폴더 구조를 주제로 소프트웨어 공학 관점에서의 관심사의 분리라는 원칙을 통해 설명하고자 했습니다. 프론트엔드 외 다른 직군도 함께 하는 자리였던 만큼 FSD보다는 관심사의 분리에 조금 더 초점이 맞춰져 FE를 설명하는 내용이 되었습니다.
이 글은 그동안 프론트엔드가 복잡성을 관리하기 위한 방법을 발전시켜가는 과정을 함께 살펴보면서 프론트엔드뿐만 아니라 전체 소프트웨어 개발 과정에서 소프트웨어 공학 이론들이 어떻게 적용이 되는지 설명해보려고 합니다. 이 글이 더 나은 구조를 만들기 위한 고민과 적용에 도움이 되기를 바랍니다.
우리는 언어를 3개나 배운다! 😆
웹 개발을 하기 위해서 우리는 3가지 언어를 배우게 됩니다. HTML과 CSS 그리고 Javascript 죠. 다른 분야들은 다들 하나의 언어를 통해서 개발을 한다는데 어쩌다가 웹 개발은 언어를 3개나 하게 되었을까요?

HTML과 CSS가 programming language가 아닐지는 몰라도 (웃음) HTML은 웹을 표현하는데 있어서 상당히 유용한 언어입니다. 한번 HTML없이 javascript만으로 웹페이지를 만든다고 생각해볼까요?
<div>hello, world</div>const div = document.createElement("div")
const textContent = document.createTextNode("hello, world")
div.appendChild(textContent)
document.body.appendChild(div)웹 개발자에게는 화면을 만들기 위해 HTML과 CSS가 필수적입니다. 그러나 대부분의 UI를 다루는 언어들은 JavaScript와 같은 화면 처리 API를 통해 개발되어 왔습니다. 최근에는 다른 플랫폼에서도 UI를 만들 때 구조와 스타일을 프로그래밍 언어가 아닌 다른 방식으로 표현하는 것이 더 효과적이라는 인식이 확산되었습니다. 이것이 바로 웹의 영향이라고 할 수 있겠습니다!
웹은 문서를 만들기 위해서 시작했어요!
사실 처음부터 이렇게 구조, 표현, 동작을 분리해서 만드려고 한 것은 아니었습니다. 원래는 기능 없이 문서로만 보여주기 위해 구조를 잘 표현할 수 있는 언어(HTML)를 사용했고, 여기에 서식을 추가하며 서식 전용 언어(CSS)가 등장했습니다. 이후 동적으로 콘텐츠를 수정할 수 있는 언어(Javascript)가 결합되면서 현재의 HTML, CSS, JavaScript가 탄생한 것입니다. 각 언어는 그 목적에 따라 자연스럽게 발전해왔습니다.
HTML(1993): 문서의 구조를 보여주는 역할을 위한 언어를 만들어서 사용하자.
CSS(1996): HTML을 꾸미기 역할을 담당하는 언어를 만들어서 사용하자.
JS(1995): 동적으로 문서를 변화시키는 역할을 하는 언어를 사용하자.
이렇게 하나의 웹을 만들때 HTML, CSS, JavaScript로 각자의 관심사에 맞게 분리하여 사용하는 것을 관심사의 분리라고 하며 개발에서 아주 중요한 원칙입니다. 그 예시로 주로 HTML, CSS, Javascript가 등장하곤 하죠.
각 언어가 구조, 표현, 동작이라는 고유한 역할을 담당하면서 개발의 복잡성을 관리할 수 있게 되었습니다. 그리고 이러한 방식은 실제로 효과가 있었고 하나의 언어로 개발하는 방식에 비해 엄청 큰 효율성을 가져다주며 웹 개발이 매력적으로 만드는데 한 몫을 합니다.
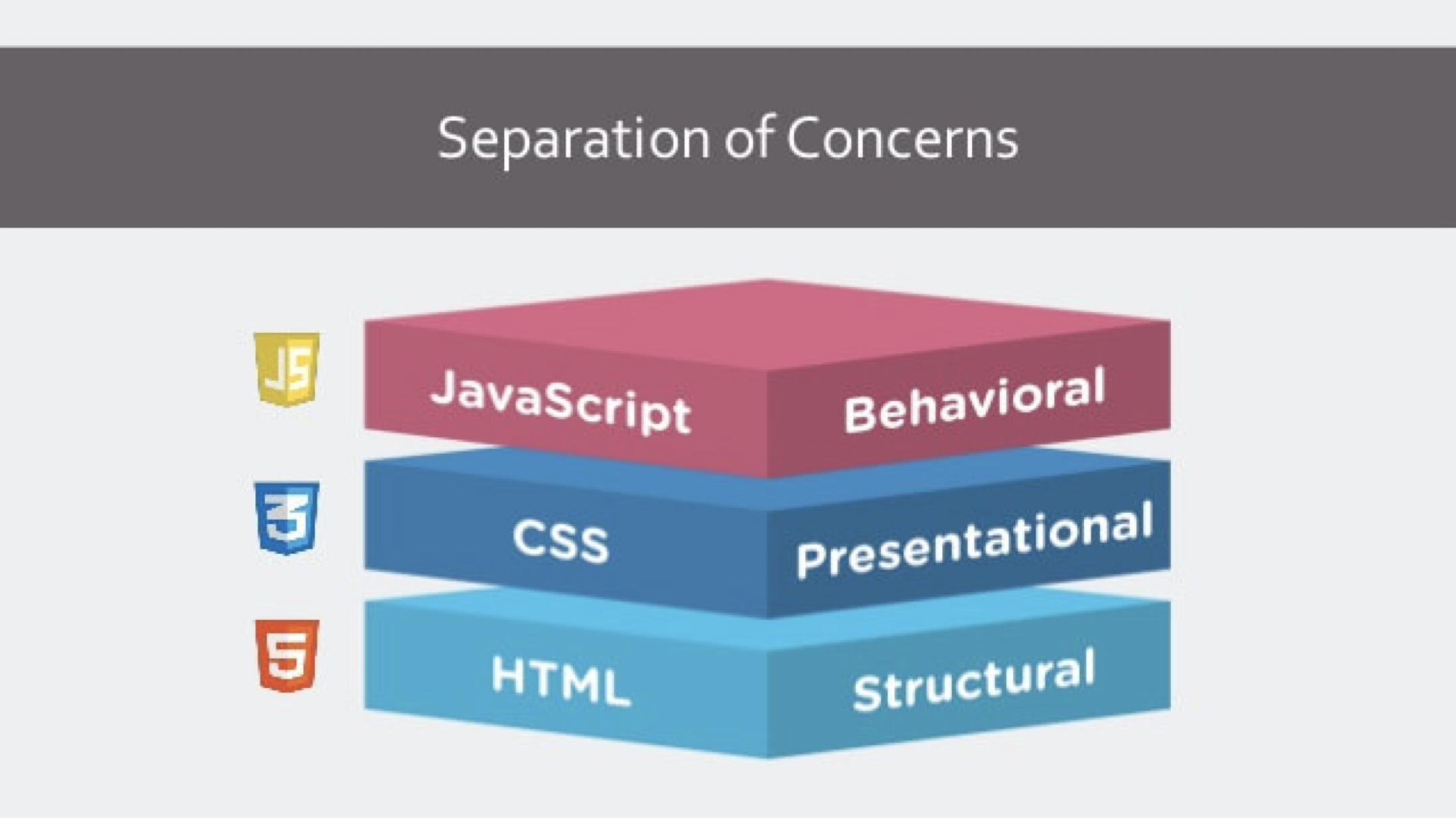
관심사의 분리: 각자 맡은 역할이 다른데 역할에 유리한 방식대로 각자의 관심을 분리하여 개발해보자!
관심사의 분리, 왜 해야할까요?
출처: 어쩌다 어른 김경일 - 사람은 멀티태스킹을 어려워한다.

우선 감각적으로 한번 이해해봅시다. 아래 그림을 봐주세요. 왼쪽 그림에서 <빨간 사각형>을 찾아보고 이제 오른쪽에서도 빨간 사각형을 한번 찾아보세요.
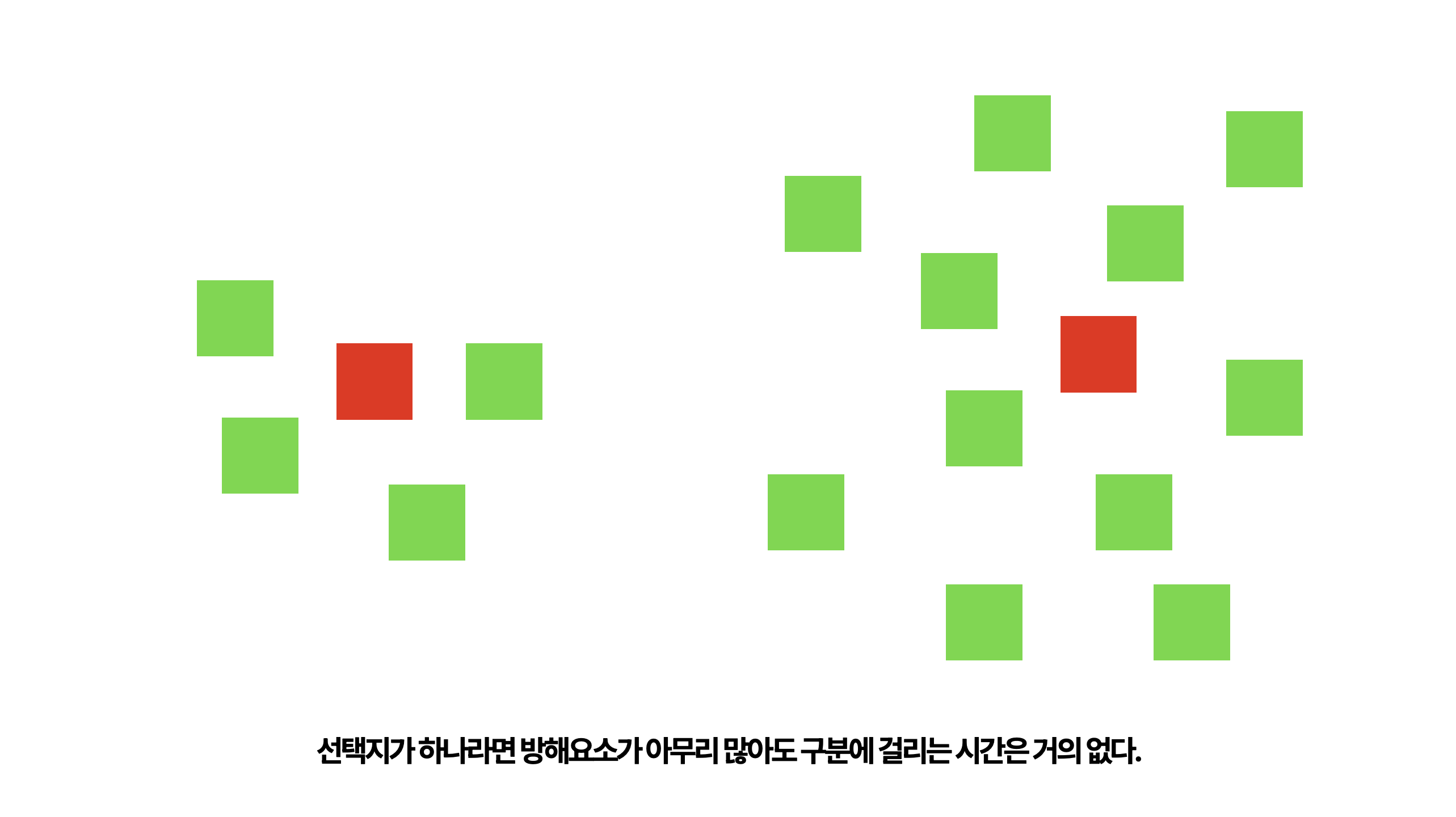
왼쪽과 오른쪽에서 각자 빨간사각형을 찾는데의 어려움은 별 차이가 없습니다. 녹색 사각형이 찾는 것을 방해하는 방해요소가 되겠죠. 내가 비교해야하는 조건이 하나라면 방해요소가 아무리 많아져도 구분하는데 시간차이는 거의 없죠.
그렇다면 다음 그림을 살펴볼까요? 왼쪽에서도 <빨간 사각형>을 한번 찾아보세요. 그리고 오른쪽에서도 한번 <빨간 사각형>을 찾아보세요.
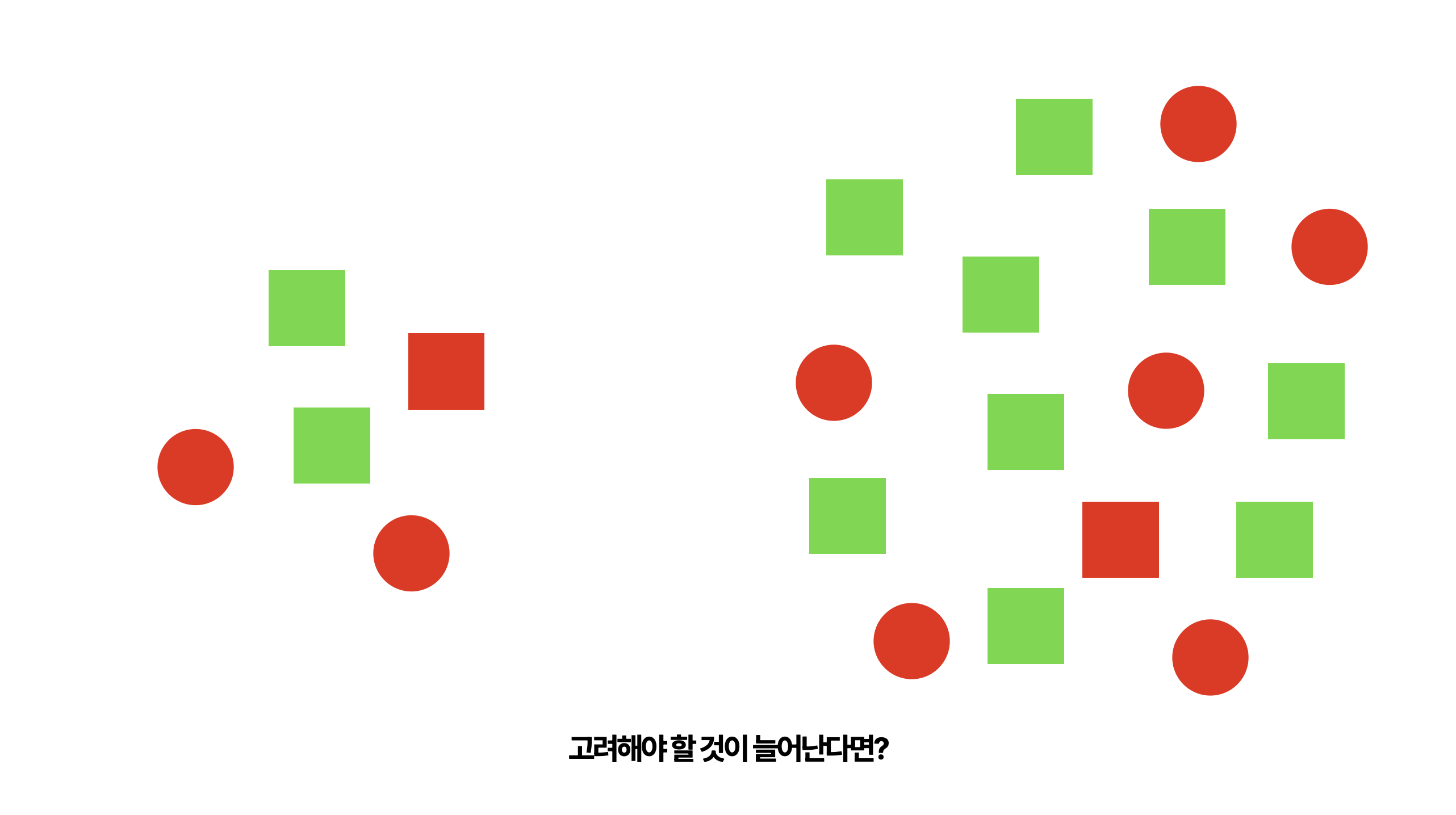
어려운 문제는 아니므로 금세 빨간 사각형을 찾았겠지만 그래도 조건이 하나 늘어나니까 뭔가 살짝 멈칫하게 되지 않나요? 조건이 늘어나게 되면 분명 이전보다는 방해요소가 많아질 수록 시간이 소요된다는 걸 느낄 수 있었습니다.
조금 더 복잡한 걸 해볼까요? 아래 그림은 2개의 같은 그림이 있습니다. 어떤 그림이 같은지 한번 찾아보세요.

이번에는 꽤 시간이 오래걸렸을거라 생각합니다. 찾는 걸 포기하고 그냥 스크롤을 내렸을 수도 있겠네요. 분명 맨 처음<빨간 사각형>은 금방 구분할 수 있었지만 비슷비슷한 것들을 구분없이 모아두고 그걸 찾으라고 하면 구분을 하기 위한 인지 소모량은 상당합니다. (다음 그림에서도 같은 그림을 2개를 찾아볼까요? ㅎㅎ)

비슷비슷한 것들을 구분없이 모아두고 그걸 찾으라고 하면 구분을 하기 위한 인지 소모량은 상당합니다. 라는 말에서 뭔가 개발에서 떠오르는 게 있나요? 버그가 발생했고 분명 이 파일인건 알겠지만 라인은 정확하게 알지 못해서 파일을 처음부터 하나씩 살펴보는데...
앗, 이런... 그래서 전체 코드를 확인해보려는데... 아뿔싸...

한 파일에 비슷한 코드가 구분도 없이 섞여있는 채로 모여있다면 어떤 느낌인지 다들 아시죠? 인간은 한번에 여러개의 관점을 동시에 처리하기 어려워합니다. 따라서 관심사의 분리는, 언어, 모듈, 파일, 함수, 클래스 등 특정 계층이 구분가능한 하나의 명확한 역할만을 수행하도록 설계함으로써, 코드의 가독성과 유지보수성을 향상시키고자 하는 행위인 것이죠.
관심사를 분리한다는 것은 조건에 따른 구분을 하는 과정에서 인지부하를 최소화하기 위함입니다. 그렇기에 맨 처음 <빨간 사각형>과 같이 명확한 하나의 기준으로 선명하게 분리되는게 중요합니다.
관심사 분리와 프론트엔드의 탄생
Ajax(Asynchronous JavaScript and XML)의 등장은 웹에서 서버와 클라이언트의 역할을 명확히 구분하게 되었습니다. 서버는 데이터를 처리하는 역할을 맡고, 클라이언트는 이 데이터를 화면에 그리는 역할을 하게 되었습니다. Ajax를 통한 개발이 표준화됨에 따라 JavaScript의 역할도 정립되었습니다. 서버와 통신하고, DOM을 선택하며, 이벤트를 제어하고, DOM을 조작하는 역할을 수행합니다. 이러한 역할을 해주는 라이브러리인 jQuery가 탄생하죠.

그리고 이 역할들이 발전하면서 서버와 통신을 담당하는 역할과, (알아서) DOM과 Event를 제어하고 데이터를 선언한대로 그려주는 역할이 강화가 됩니다.

이후 프론트엔드는 서버와 데이터 통신, 콘텐츠, 화면 디자인, 사용자의 인터랙션, 데이터 변화에 따른 자동 렌더링 등 다양한 역할이 발전하며 Frontend라는 하나의 관심사가 형성되었습니다. 이처럼 관심사의 분리는 각 요소가 맡은 <역할>을 중심으로 시작하게 됩니다.
웹 프레임워크가 가져온 새로운 패러다임의 변화: 컴포넌트 <희망편>
웹 개발은 API, HTML, CSS, JavaScript 등 여러 계층으로 나누어 관심사를 분리하는 방식으로 발전해왔습니다. 이러한 접근은 각 기술의 역할을 명확히 구분하는 데 큰 도움이 되었으나, 개발 과정에서는 하나의 기능을 구현하기 위해 동시에 여러 계층을 오가며 작업해야 하는 불편함이 발생하곤 했습니다.
이런 인식은 컴포넌트라는 새로운 개념으로 이어졌습니다. 컴포넌트는 특정 기능이나 UI 요소를 구현하기 위한 모든 요소—HTML 구조, CSS 스타일, JavaScript 동작—를 하나의 단위로 묶어 다루는 방식입니다. 즉, 함께 사용하고 모아두는 것이 핵심이죠.
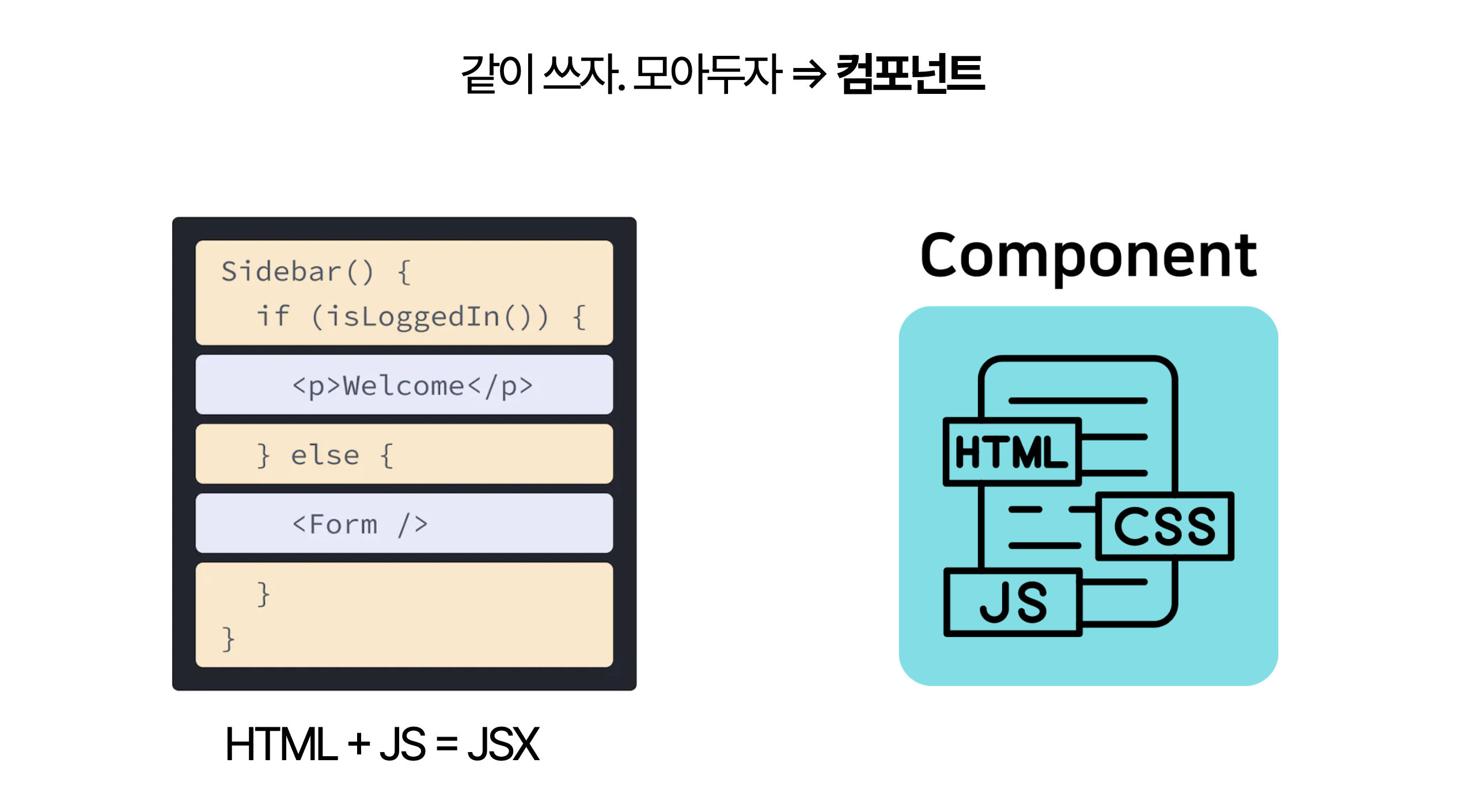
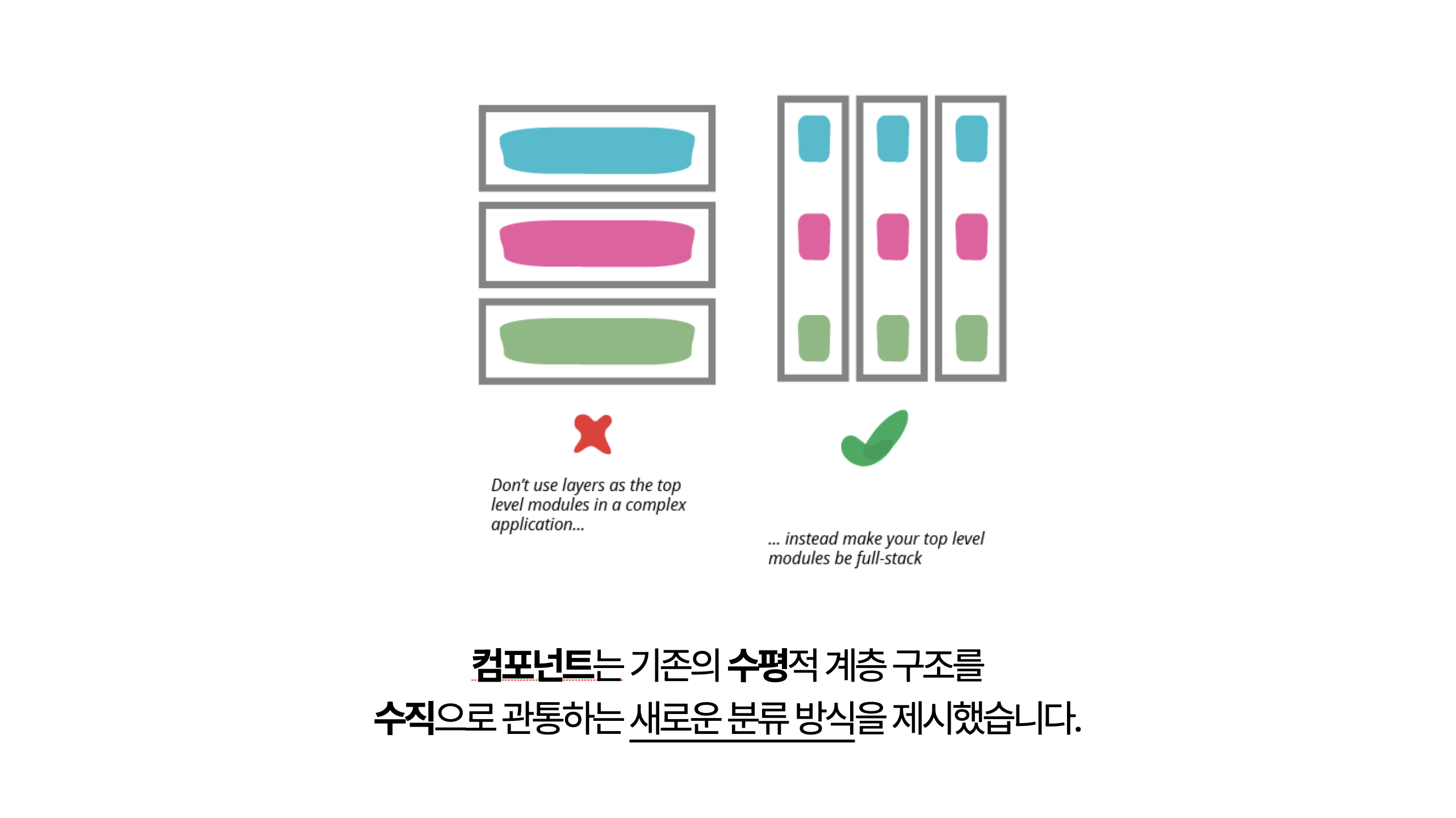
컴포넌트는 기존의 수평적 계층 구조를 수직으로 관통하는 새로운 분류 방식을 제시합니다. 이를 통해 UI 요소와 관련 로직이 하나의 단위로 결합되어 재사용성이 증가하고, 독립적인 개발과 테스트가 가능해집니다. 이는 역할이 아닌 기능 중심의 모듈화를 의미합니다.
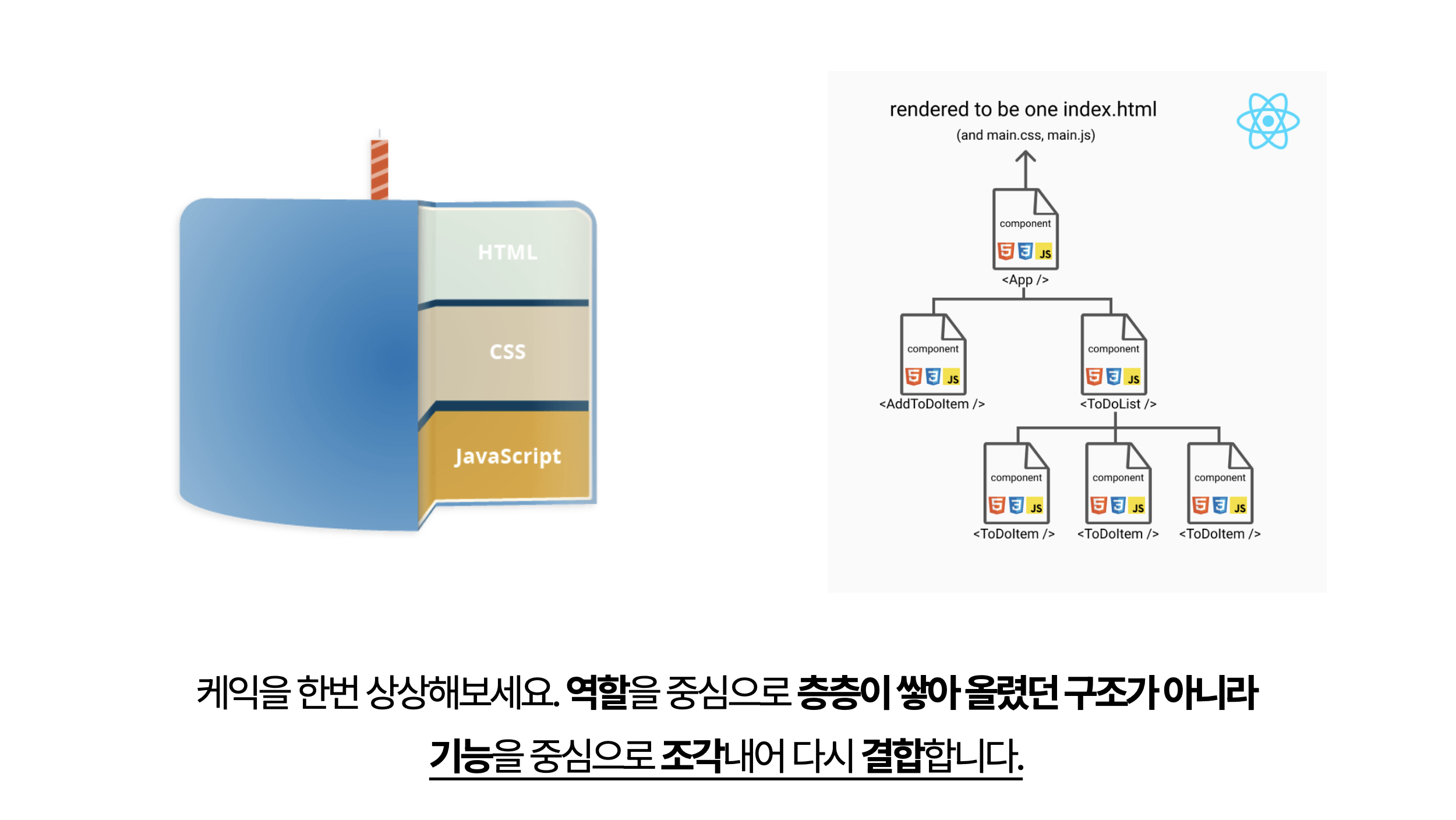
케이크를 한 번 상상해보세요. 기존의 구조는 역할을 중심으로 층층이 쌓아 올린 계층구조였다면, 이제는 기능을 중심으로 조각내어 다시 결합하는 방식으로 발전했습니다. 각 UI 요소와 관련 로직이 하나의 단위로 묶이게 되면서, 재사용성이 증가하고 독립적인 개발과 테스트가 가능해집니다. 프론트엔드의 관심사는 프레임워크를 기점으로 역할이 아닌 기능 중심으로 변화하기 시작했습니다.
컴포넌트 기반 아키텍처의 도입은 기능 중심의 관심사 분리를 통해 개발 프로세스의 효율성을 대폭 향상시켰습니다. 특히, 코드의 재사용성과 모듈화가 크게 개선되어 개발 생산성이 증대되었으며, HTML, CSS, JavaScript의 통합적 관리를 통해 개발 복잡성이 감소했습니다.
더불어, 컴포넌트 단위의 격리된 개발 환경은 유지보수성, 테스트 용이성, 그리고 협업 효율성을 현저히 개선시켰습니다. 이러한 이점들로 인해 컴포넌트 기반 개발 방식은 현대 프론트엔드 엔지니어링의 핵심 방법론으로 자리잡게 되었으며, 웹 애플리케이션 구조의 패러다임 전환을 이끌어냈습니다.
컴포넌트 <절망편>
그러나 컴포넌트 기반 개발이 모든 문제를 해결해준 것은 아니었습니다. 오히려 새로운 형태의 복잡성을 마주하게 되었죠. 우리가 생각했던 이상적인 컴포넌트 구조와 실제 개발 과정에서 마주한 현실 사이에는 상당한 괴리가 있었습니다.
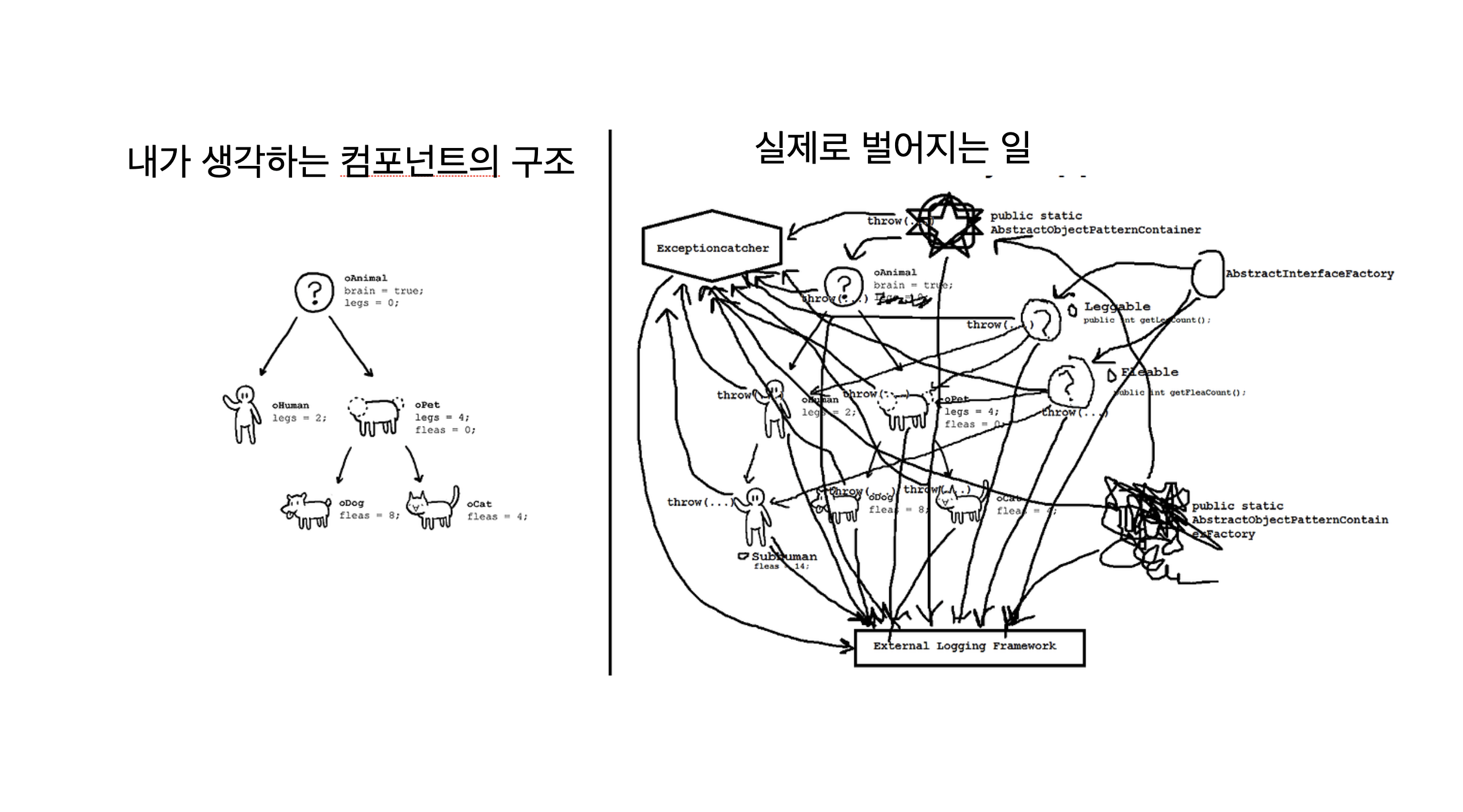
가장 큰 문제는 컴포넌트 간의 높은 결합도였습니다. 이른바 'props drilling' 문제입니다. 독립성을 강조하는 컴포넌트에게 정보를 전달하기 위해서 인터페이스를 두는 것은 분명 좋은 구조입니다. 그러나 데이터를 사용하지 않는 컴포넌트에게도 데이터를 그저 전달하기 위해 중간에 있는 모든 컴포넌트에도 props를 뚫어야 하는 상황이 빈번히 발생했습니다. 이렇게 만들어진 컴포넌트는 상위와 하위 컴포넌트에 끼이에 되면서 오히려 독립적인 컴포넌트로 보기도 어려워졌죠.
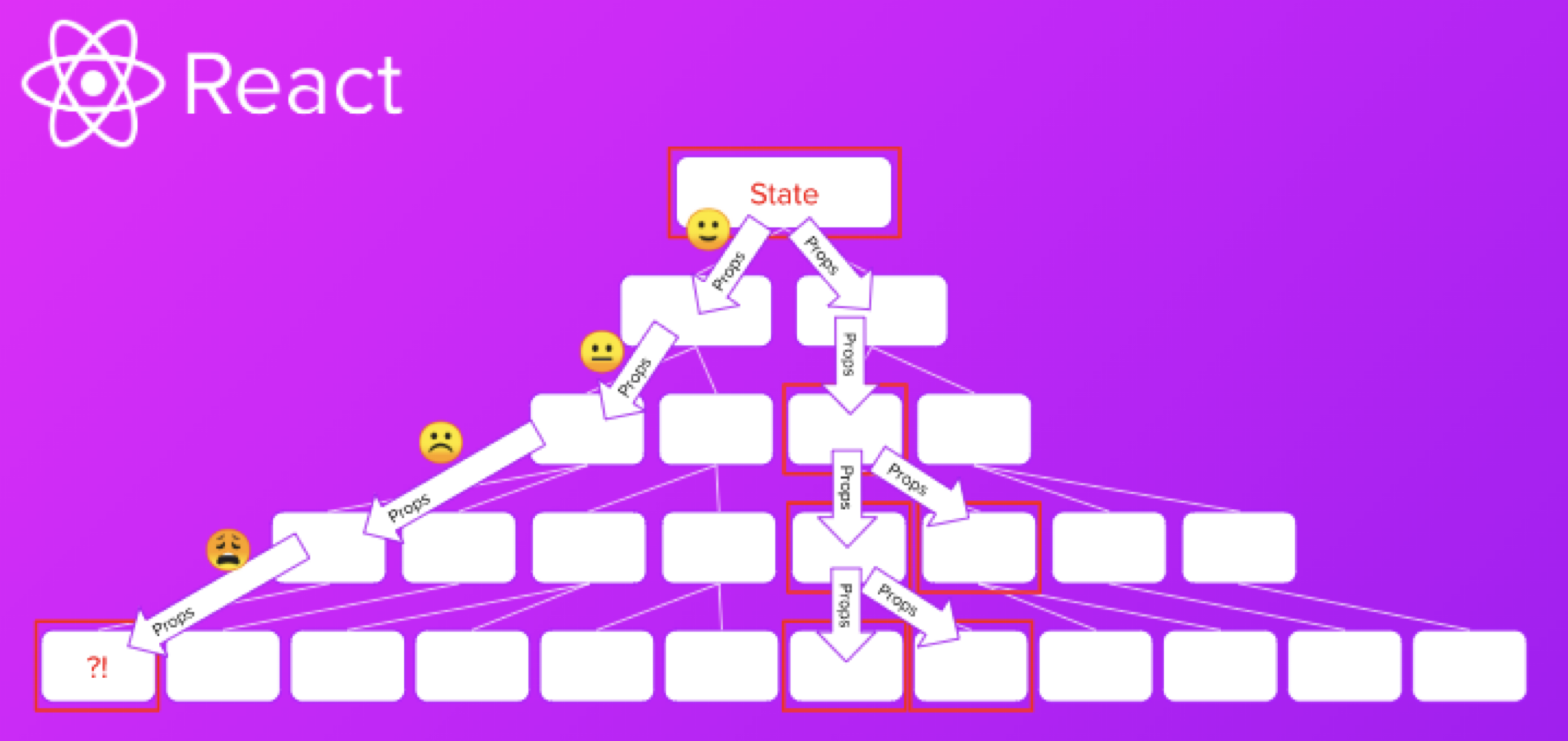
이렇게 컴포넌트를 늘리다 보니 /components 라는 폴더 아래에 수많은 컴포넌트들이 그냥 보관되게 되었습니다. 정리가 되지 않은채로 수가 늘어나다보니 이들을 어떻게 효과적으로 관리하고 찾을 것인지가 새로운 과제로 대두되었죠.

이때의 문제점들을 한번 정리해보자면 다음과 같습니다.
-
컴포넌트의 비대화: 하나의 컴포넌트 안에 데이터 관리, 표현 로직, 비즈니스 로직 등 너무 많은 책임이 집중되었습니다. 이는 단일 책임 원칙(SRP)을 위반하는 결과를 낳았죠.
-
높은 결합도: 앞서 언급한 props drilling 문제로 인해 컴포넌트 간 결합도가 높아졌습니다. 이는 컴포넌트의 재사용성과 유지보수성을 저해하는 요인이 되었습니다.
-
관리의 어려움: 컴포넌트의 수가 늘어나면서 이들을 어떻게 효율적으로 구조화하고 관리할 것인지가 큰 도전 과제가 되었습니다.
결과적으로, 우리는 기능을 중심으로 분리하게 위해서 컴포넌트를 만들어 관심사의 분리를 성공했으나, 결국 하나의 컴포넌트가 너무 많은 역할을 수행하게 되자 다시 문제가 찾아왔습니다. 그리고 느끼게 되죠. '다시 관심사를 분리할 때가 왔구나' 하고 말이죠. 이제는 컴포넌트 기반 개발의 장점을 유지하면서도, 이러한 문제들을 해결할 수 있는 새로운 접근 방식을 모색하게 되었습니다.
컴포넌트의 잘못은 아니야. 그렇지만 다시 계층적 관심사로 돌아가자.
컴포넌트 기반 개발은 분명 혁신적인 접근 방식이었지만, 모든 문제를 해결해주지는 못했습니다. 오히려 새로운 형태의 복잡성을 마주하게 되었죠. 컴포넌트로 인해 더 크고 복잡한 프로젝트를 할 수 있게 되면서 대규모의 프로그램에서는 이상적인 컴포넌트 구조와 실제 개발 과정에서의 현실 사이에 괴리가 커져갔습니다.
이러한 문제들을 해결하기 위해, 우리는 컴포넌트 내부와 컴포넌트 간의 구조를 더 체계적으로 정립하는 방향으로 진화하게 됩니다. 즉, 컴포넌트라는 큰 틀은 유지하되, 그 안에서 다시 한번 계층적 관심사로 돌아가는 접근을 시도하게 되죠.
이를 위해 우리는 컴포넌트를 다시 여러 계층으로 나누고, 각 계층별로 명확한 역할과 책임을 부여하는 방식을 택하게 됩니다. 이러한 접근은 컴포넌트의 복잡성을 관리하면서도, 더 나은 구조화와 유지보수성을 확보하는 데 도움을 주었습니다. 구체적으로 어떤 방식들을 시도했는지 살펴보겠습니다.
1. UI 컴포넌트의 계층구조 만들기
: Atomic Design Pattern
UI 컴포넌트의 계층 구조를 만들기 위해 Atomic Design Pattern을 도입했습니다. 이를 통해 UI 컴포넌트의 역할과 계층을 분명하게 만들어 관심사를 분리할 수 있었죠. Atomic Design Pattern은 단순히 atoms - molecules - organisms 의 이름과 분리가 중요한게 아닙니다. 한 곳에 모여있던 컴포넌트들을 분리할 수 있는 보다 세밀한 기준이 생긴 것이 주요하죠.

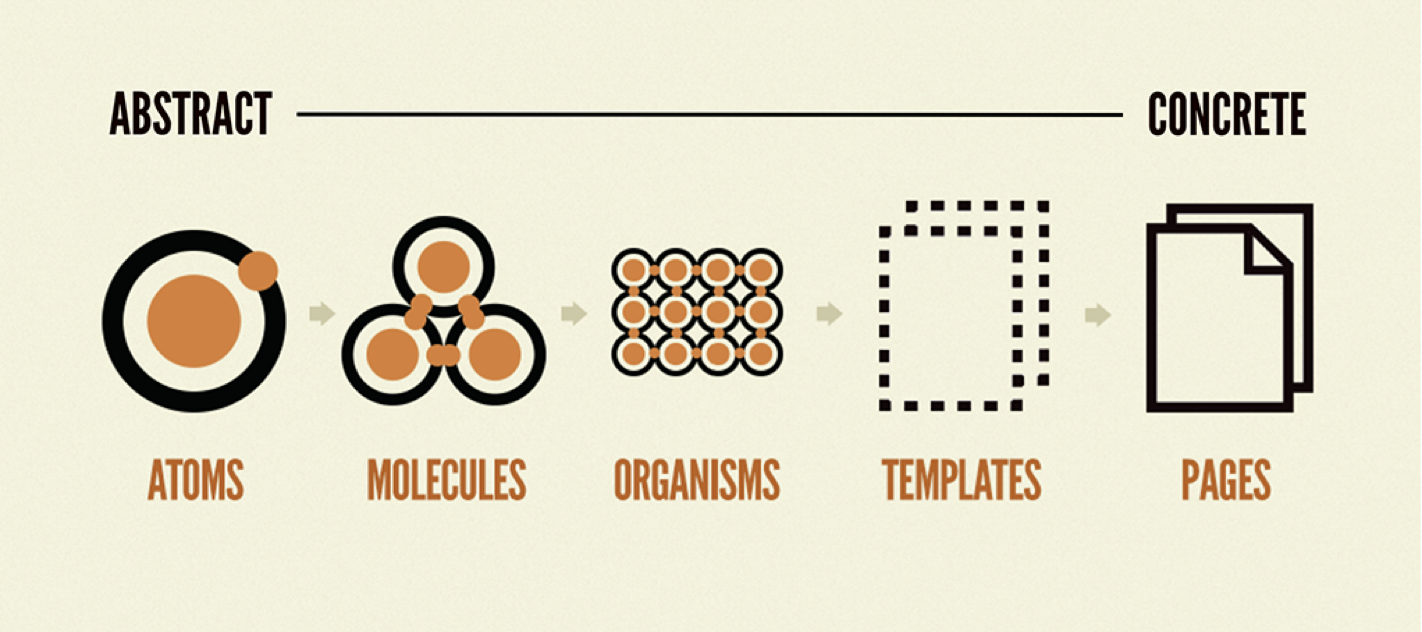
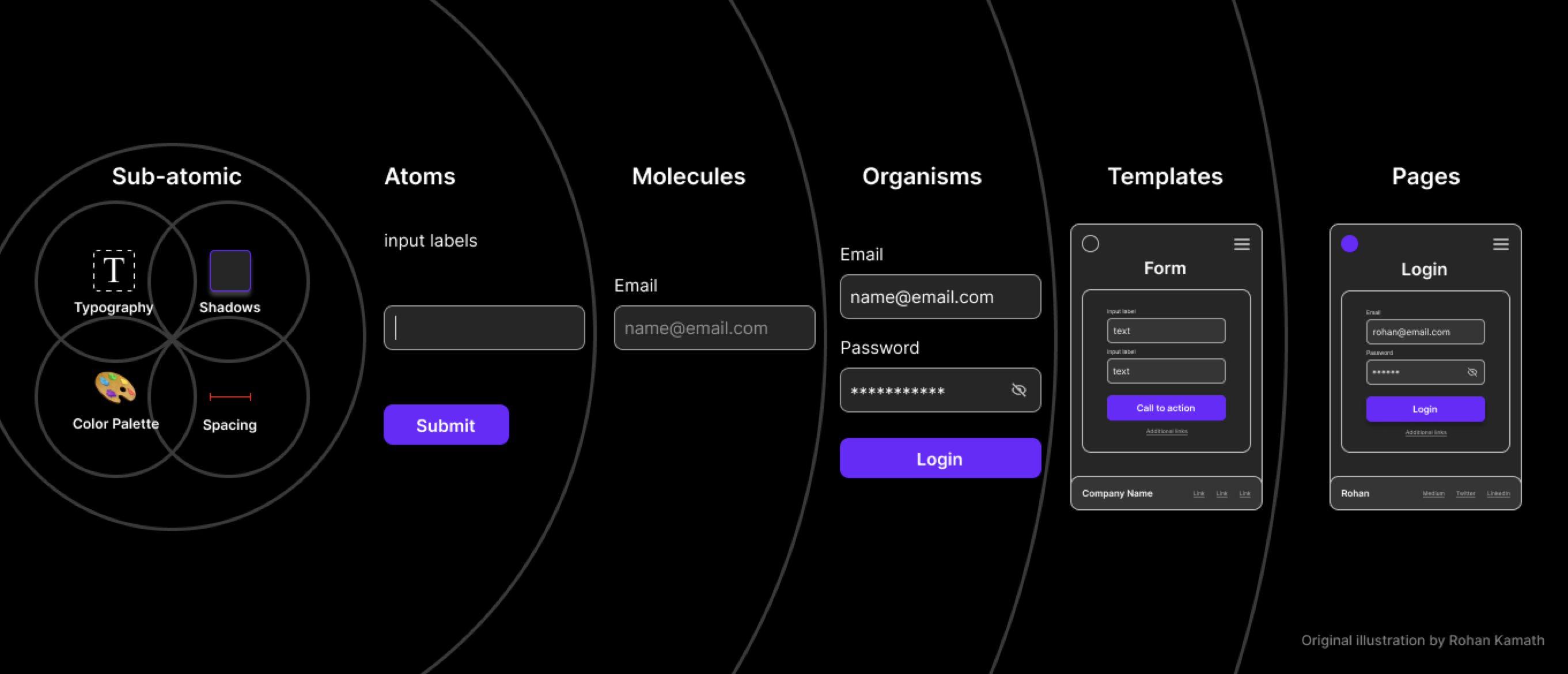
이러한 새로운 계층을 통해서 복잡한 컴포넌트들을 다시 역할과 범주를 분리하여 정돈하기 쉽도록 만들어주었습니다.
2. HTML-CSS 의존성 해결하기
: CSS가 HTML을 따라가도록
CSS와 HTML의 관계는 웹 개발에서 항상 중요하고 논쟁적인 주제였습니다. 웹이 문서가 아니라 어플리케이션의 역할까지 확대가 되면서 결국 이 둘의 관계는 근본적인 문제가 있었다는게 정론이 됩니다. CSS와 HTML은 서로 다른 역할을 하여 분리했지만, 실제로는 양방향으로 강하게 의존하는 구조입니다. 그렇기에 HTML을 수정하면 CSS가 깨지고, CSS를 변경하면 HTML 구조에 예기치 않은 영향을 미치는 일이 다반사였고 이게 CSS의 가장 큰 문제로 지목이 되었습니다.

이를 해결하기 위한 해법으로 의존성의 방향을 단방향으로 만들고자 했습니다. 단순히 역할만 분리하는 것이 아니라 의도적으로 한쪽 방향으로만 의존하도록 하여 관리하기 쉬운 구조를 만드는 것이죠. 최소한 어느 한쪽은 수정을 해도 문제가 없었어야 했으니까요.
이 경우 CSS가 HTML을 따라가도록 만들었습니다. 디자인은 한번 만들어지고 나면 자주 바뀌지는 않지만 컨텐츠의 구조는 자주 바뀌니까요. 이로 인해 HTML 구조 변경 시 CSS가 자동으로 따라가게 되어, 스타일 깨짐이나 예기치 않은 영향을 최소화할 수 있게 되었습니다.
이를 위해 여러 기술과 방법론이 등장했습니다:
1. BEM(Block Element Modifier): CSS의 구조와 우선순위를 HTML 구조에 맞춰 정의합니다.
2. CSS Modules: CSS를 JavaScript 모듈처럼 다루어, 컴포넌트와 1:1로 연결합니다.
3. CSS-in-JS: CSS를 완전히 JavaScript 안에 포함시켜, 컴포넌트와 스타일을 하나의 단위로 만듭니다.
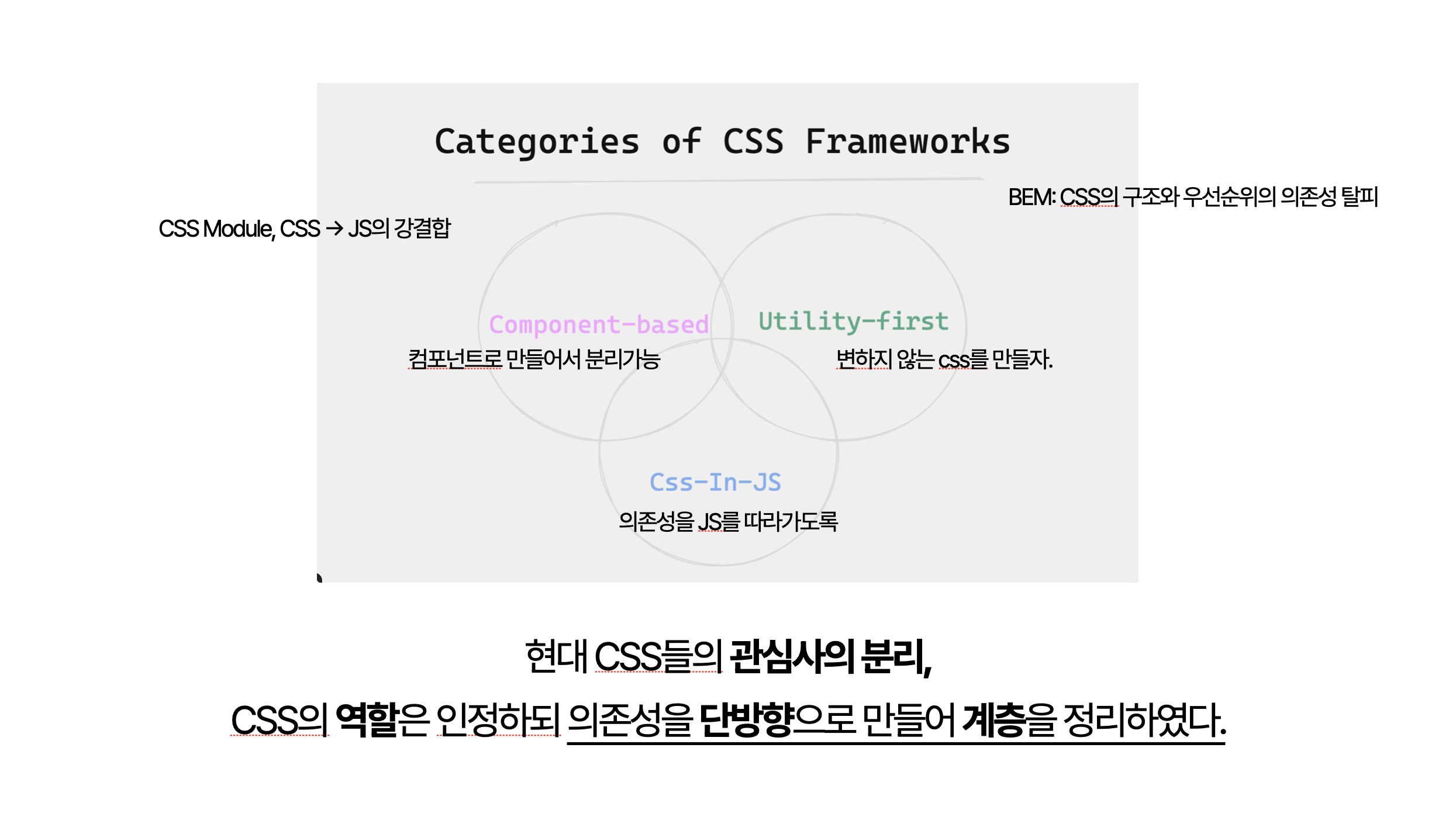
이러한 접근법들은 모두 CSS를 HTML과 JavaScript 구조에 맞추는 철학을 공유합니다. 이를 통해 우리는 예측 가능하고 관리하기 쉬운 단방향 의존성 구조를 만들어낼 수 있게 되었습니다.
3. 비지니스로직 뷰로직의 분리
: State management
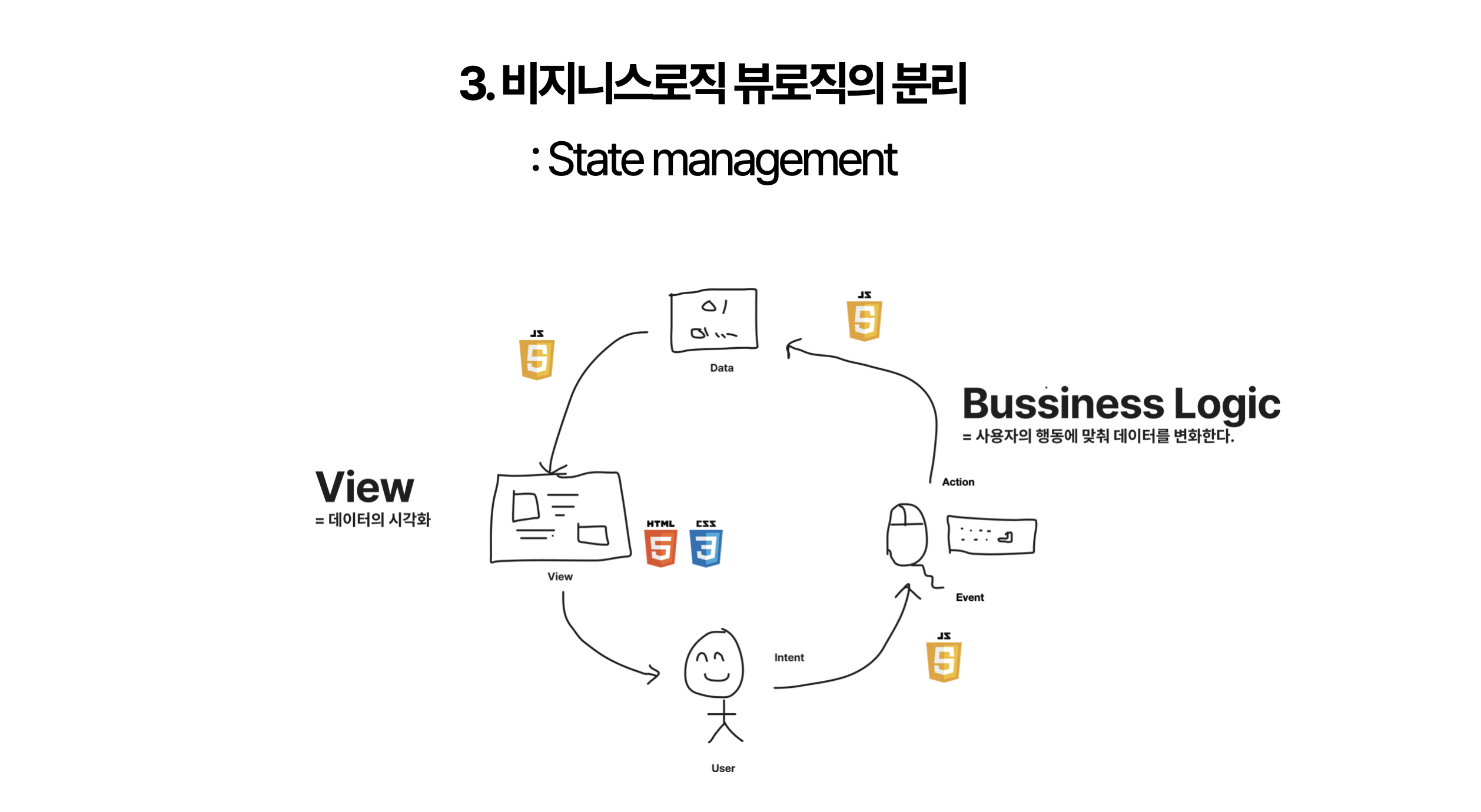
컴포넌트의 계층적 구조가 복잡해지면서, 데이터를 효율적으로 관리하고 전달하는 문제가 대두되었습니다. 이를 해결하기 위해 등장한 것이 바로 상태 관리(State Management)였습니다.
상태 관리의 핵심 목적은 다음과 같았습니다:
- 컴포넌트의 역할 축소: 컴포넌트는 오직 화면을 그리고 사용자 이벤트를 받는 역할만 수행하도록 했습니다.
- 데이터 로직의 분리: 복잡한 데이터 관련 로직은 별도의 계층으로 위임하였습니다.
이러한 접근은 entity(데이터 모델)와 view(화면) 사이의 의존성을 정리하고 관심사를 명확히 분리하는 데 큰 도움이 되었습니다.
여기서 중요한 점은 데이터와 화면의 특성 차이였습니다. 데이터 구조는 비교적 안정적이었지만, 화면 구성은 자주 변경될 수 있었습니다. 따라서 우리는 '데이터 → 화면'의 단방향 의존성을 구축하고자 했습니다. 이를 위해 데이터 관련 로직을 별도의 계층으로 분리하고, 이를 통해 단방향 데이터 흐름을 만들어냈습니다. 이렇게 함으로써 데이터의 일관성은 유지하면서도, 화면의 유연한 변경이 가능한 구조를 얻을 수 있었습니다.
4. 서버 상태 관리
: 특수한 계층은 역할에 더 충실하기
상태 관리 패러다임이 등장한 이후, 많은 개발자들이 비즈니스 로직의 핵심 계층인 서버 데이터를 상태 관리 문법으로 다루려는 시도를 했습니다. 한때 모든 서버데이터 관리들을 Redux등으로 만드는 것이 유행했었죠. 그러나 이 과정은 컴포넌트가 비대해지는 것과 유사한 실수를 하게 됩니다. 예상과는 달리 상태 관리 스토어가 당연히 적어줘야 하는 보일러플레이트로 인해서 의도와는 달리 비대해지는 현상을 마주하게 되었습니다.
서버 상태는 클라이언트와 달리 기본적으로 비동기와 예외를 항상 가지다 보니 다양한 문제들을 마주하게 됩니다. 가령:
- 비동기 처리
- 캐싱
- 로딩 상태 관리
- 재시도 메커니즘
- 낙관적 업데이트
- 페이지네이션
- 무한 스크롤
이러한 기능들은 서버 상태를 관리할 때 필연적으로 다루게 되는 부분들이지만, 엄밀히 말해 비즈니스 로직이라고 보기는 어렵습니다. 결국 같은 관점으로 문제점을 발견하게 됩니다. 모든 것을 하나의 기능이나 패러다임(즉, 상태 관리)으로 해결하려 하기보다는, 관심사를 더 세부적으로 나누어 계층을 분리하는 것이 효과적이라는 것입니다.
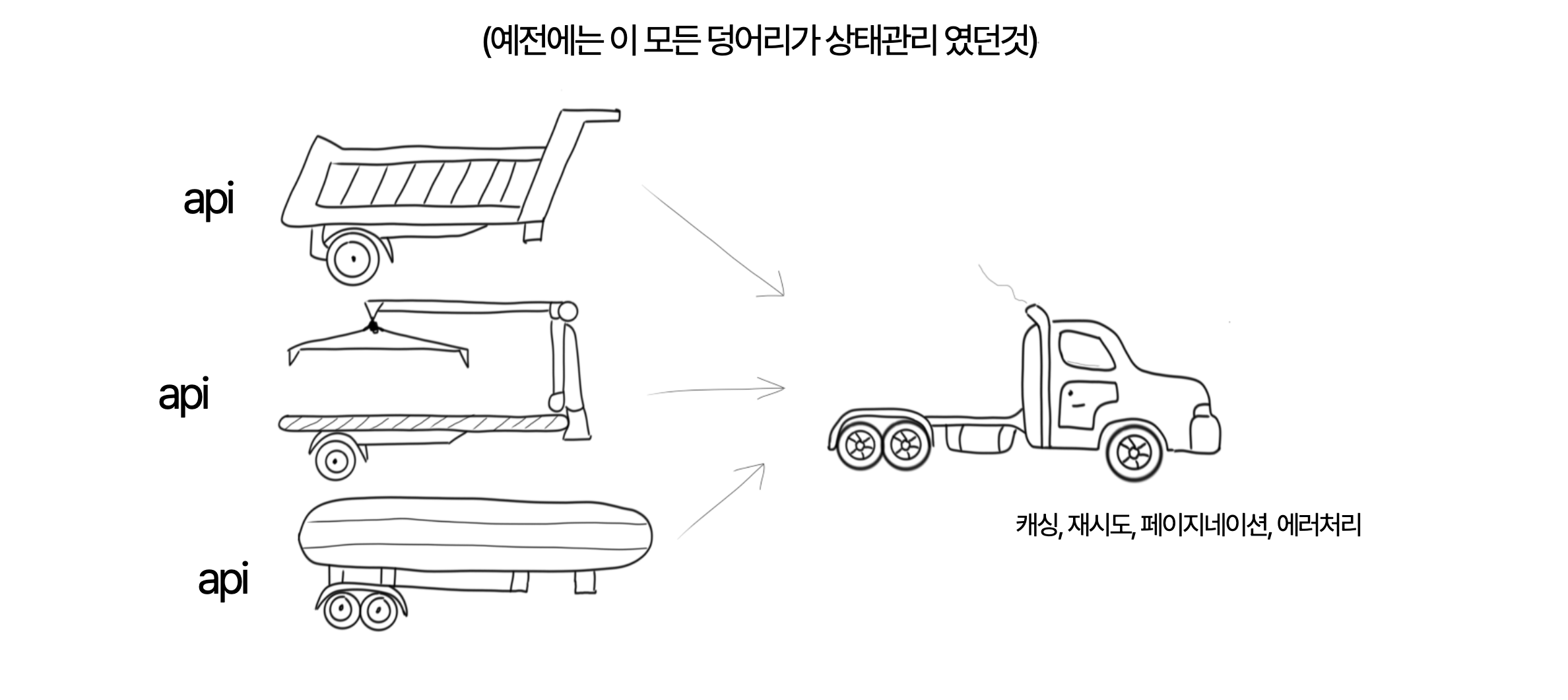
우리는 서버상태관리라는 개념을 가지고 와서 API 호출, 캐싱, 재시도, 페이지네이션, 에러 처리 등의 기능을 별도의 계층으로 분리했습니다. 이전에는 이 모든 기능이 하나의 상태 관리 시스템 안에 뭉뚱그려져 있었지만, 이제는 각각의 역할과 기능을 제공해서 서버 상태관리를 더 잘게 쪼개어 관리를 할 수 있게 되었습니다.
이러한 접근 방식을 통해 우리는 더 명확하고 관리하기 쉬운 코드 구조를 만들 수 있게 되었습니다. 각 계층이 자신의 역할에 더욱 집중할 수 있게 되면서, 전체적인 시스템의 복잡성도 줄일 수 있었습니다.
이렇게 만들어진 현대 프론트엔드의 폴더구조
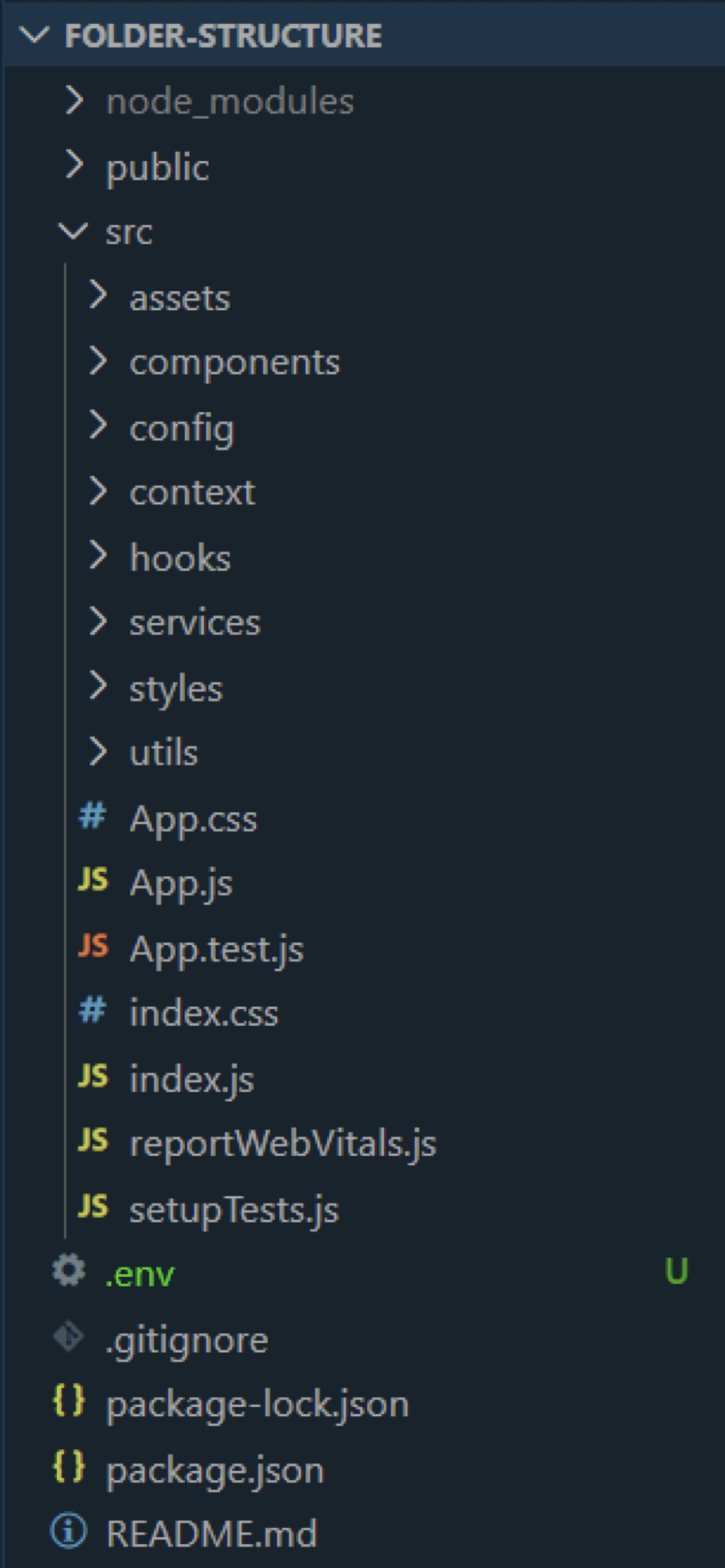
/api : 백엔드와의 통신을 담당하는 코드
/assets : 사용되는 에셋 파일
/components : 공통으로 쓰이는 컴포넌트
/config : 애플리케이션의 설정 파일들
/contents : 문서나 파일
/model : 데이터 구조를 정의하는 인터페이스나 타입
/hooks : 컴포넌트에서 사용되는 hook 파일들
/i18n : 다국어 지원을 위한 번역 파일들
/layout: 전체 애플리케이션의 구조를 정의하는 컴포넌트들
/libs : 공통으로 사용되는 라이브러리
/store : 상태 관리 로직과 관련 파일들
/service : 비즈니스 로직을 처리하는 서비스 레이어
/utils : 공통으로 사용되는 유틸리티 함수들
/pages : 실제 라우팅되는 페이지 컴포넌트들을 포함
/routes : 라우팅 설정과 관련된 코드
/server : 서버관련 파일들
/styles : 전역 스타일이나 스타일 관련 설정
/types : 전역으로 사용되는 타입 정의
...
이렇게 여러번의 시행착오를 거쳐 보통의 프로젝트의 스타트 킷은 위와 같이 다양한 세부 역할을 만들어내었고 이렇게 관심사의 분리를 통해 폴더구조를 만들어내었습니다. 아마 여러분들도 이와 크게 다르지 않은 폴더 구조를 하고 있을거에요. 잘 구분을 해둬야 원하는 것을 보관하고 찾기 쉬우니까요.
그렇다면 지금의 폴더구조는 문제가 없는 걸까요?
관점에 따라 달라진다. 관심사의 방향성: 모듈과 레이어
폴더구조에 대한 이야기를 하기에 앞서 관심사에 대한 이야기를 조금 더 깊이 해보려고 합니다. 우리는 최초 역할에 따라서 HTML-JS-CSS로 분리되는 관심사의 분리를 시작했습니다.
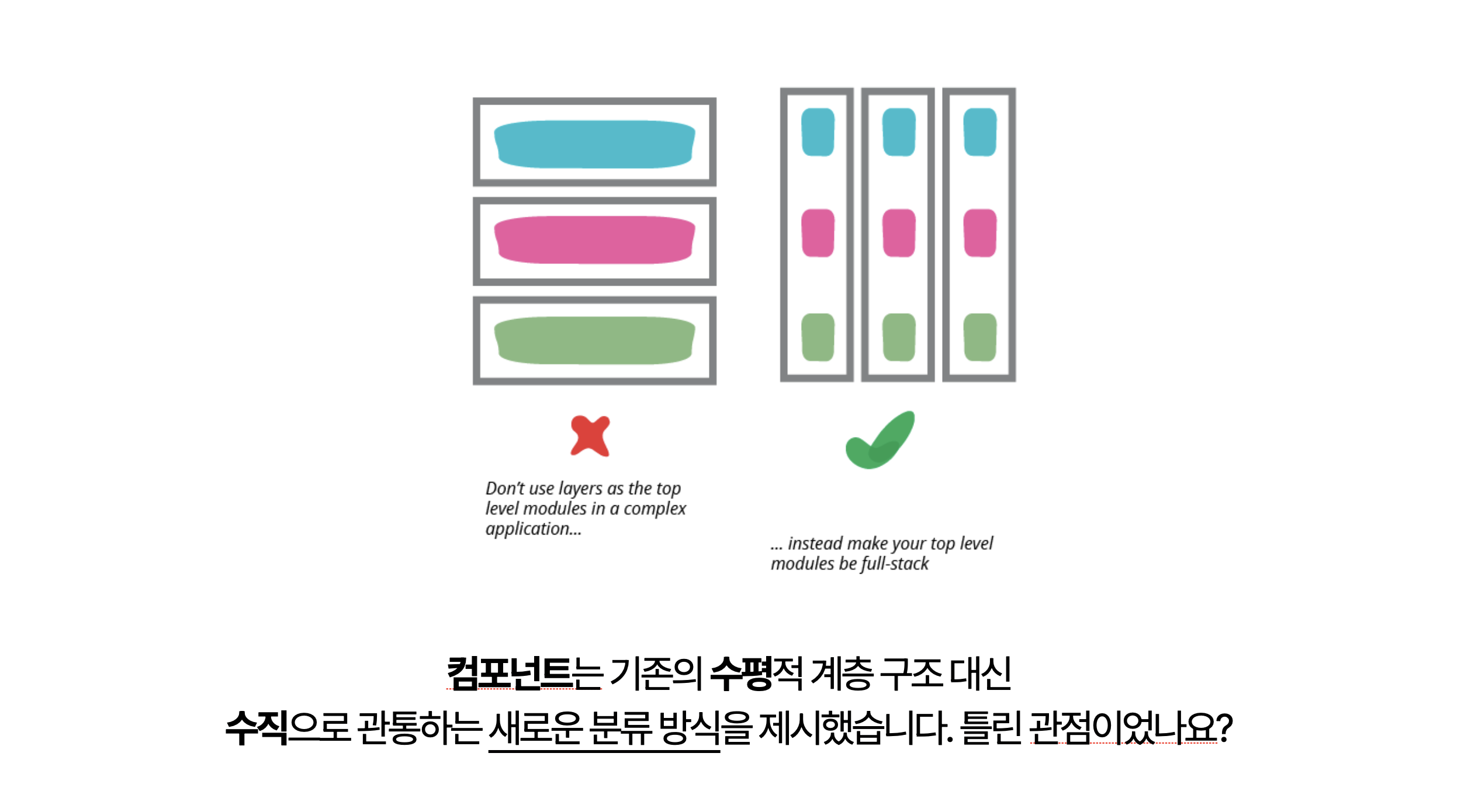
이후 수평적 계층구조가 아닌 수직으로 관통하는 컴포넌트라고 하는 분류방식을 채택하게 되었죠. 그렇지만 컴포넌트 역시 곧 한계를 맞이 하였습니다.
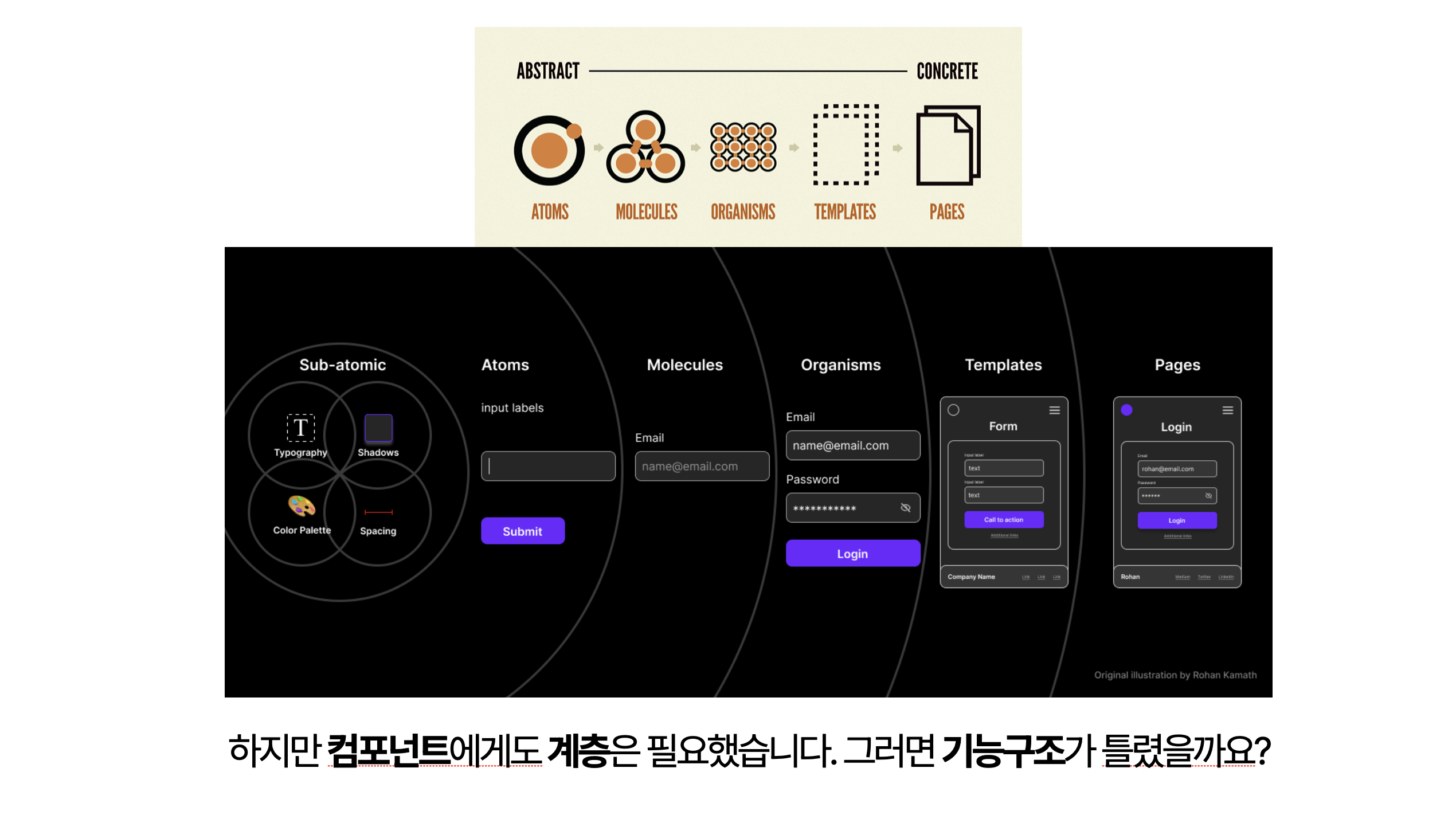
수직으로 잘랐더니 컴포넌트에게도 수평으로 분리하는 계층이 필요했습니다. 그러면 기능구조가 틀렸을까요?

그렇지 않습니다. 필요에 의해서 계층을 수평으로도 분리했고 수직으로도 분리했습니다. 지금 무엇이 필요한가 어떤 관심사로 나누어야하는가에 따라서 관심사를 보는 기준은 달라집니다.
계층적 구조로 분리를 하다보면 독립적인 기능 구조가 필요하고, 독립적인 기능구조로 만들면 계층을 분리해야 할 필요가 느껴집니다. 관심사의 방향은 하나가 여러개였습니다. 이러한 2가지의 구조를 Module과 Layer 라고 합니다.
One more thing... 데이터의 흐름
관심사의 방향은 사실 하나 더 있습니다. 바로 데이터의 흐름이라는 관점입니다.
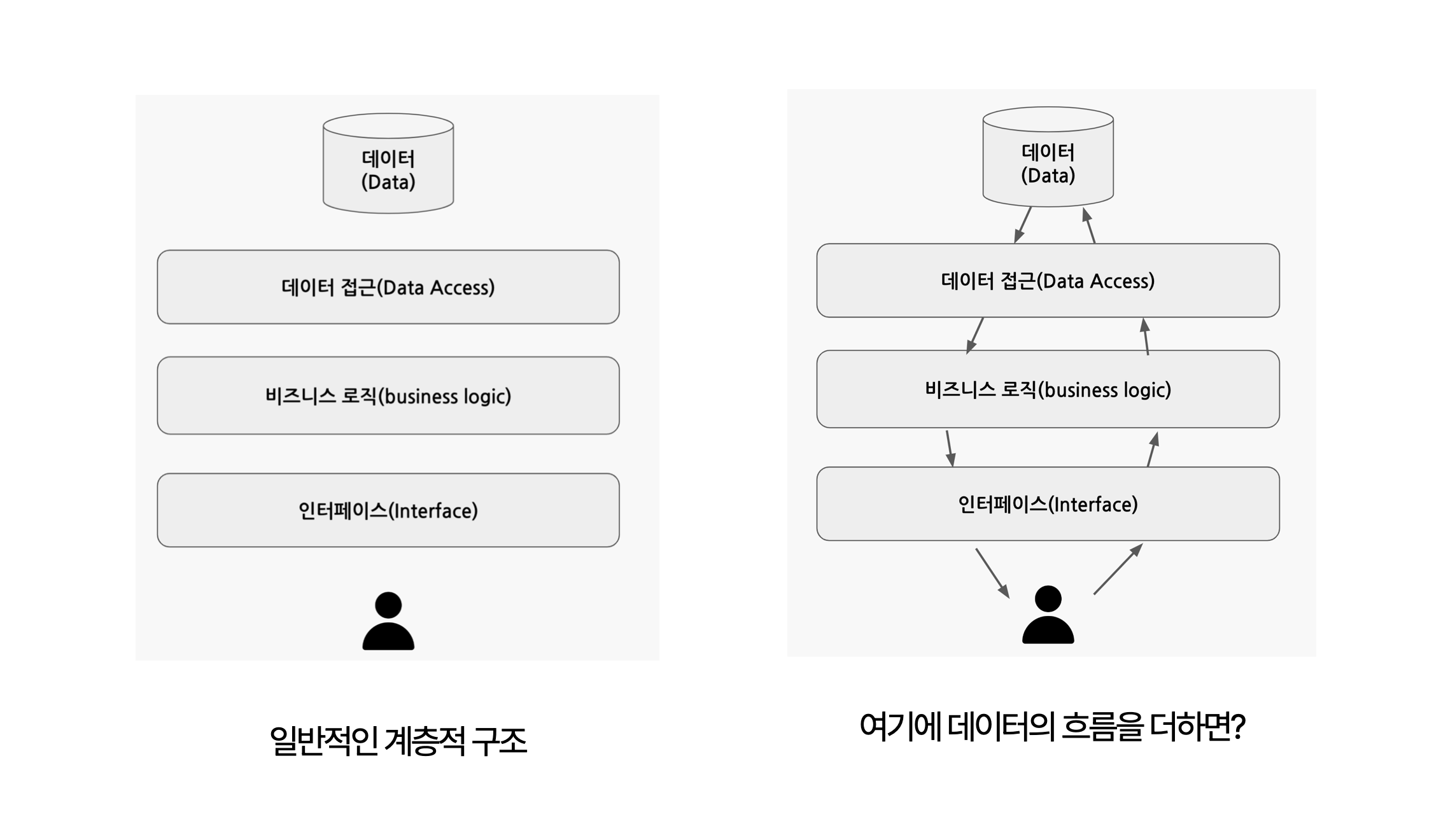
우리가 아는 일반적인 계층구조가 존재하지만 계층은 함수와도 같아서 항상 IN과 OUT이 있습니다. 그러면 자연스럽게 사용자로부터 시작해서 데이터가 전달되어 다시 반환하기까지의 데이터의 흐름이 만들어지게 되며 이러한 데이터의 흐름을 관심으로 하는 새로운 계층구조도 만들어지게 됩니다. 이러한 관심사와 계층구조는 여러분도 잘 알고 있는 클린 아키텍쳐의 모양새입니다.
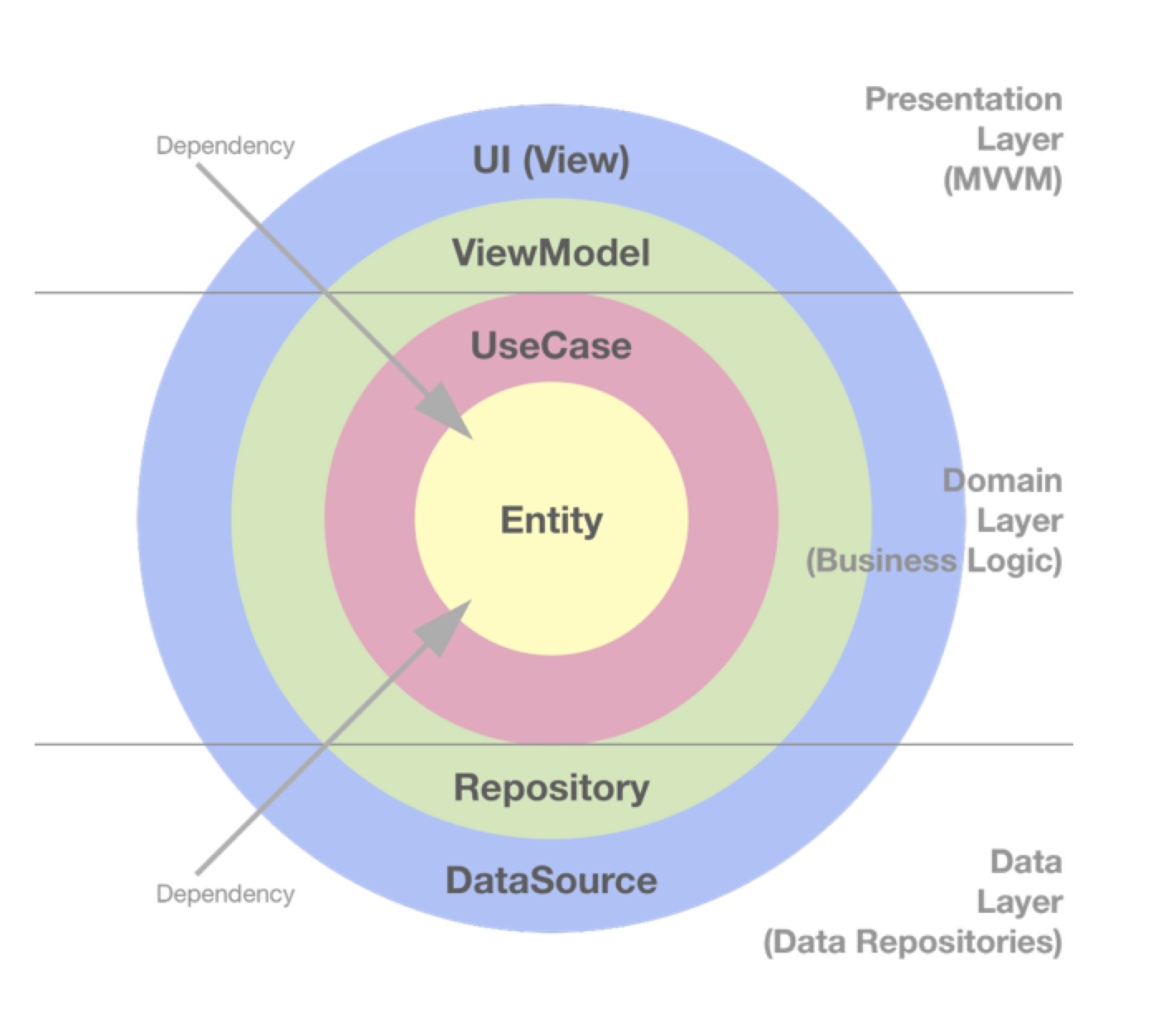
관심사는 수평적으로도, 수직적으로도, 데이터의 흐름을 기준으로 얼먀든지 관점에 따라서 분리할 수 있습니다.
킹치만 폴더 구조는 1개뿐인걸? cart/api vs api/cart
관심사는 우리가 원하는 대로 나눠서 볼수 있지만 우리가 폴더 구조를 고민하는 것은 폴더구조는 태그와 같은 방식이 아니라서 하나밖에 선택할 수 밖에 없기 때문입니다. 그리고 이렇게 만들어진 구조는 모두에게 영향을 주게 되죠. 그래서 필연적으로 각 관심사의 우선순위에 따라서 /cart/api 와 /api/cart 중에 하나만 선택할 수 있게 되는 것입니다.
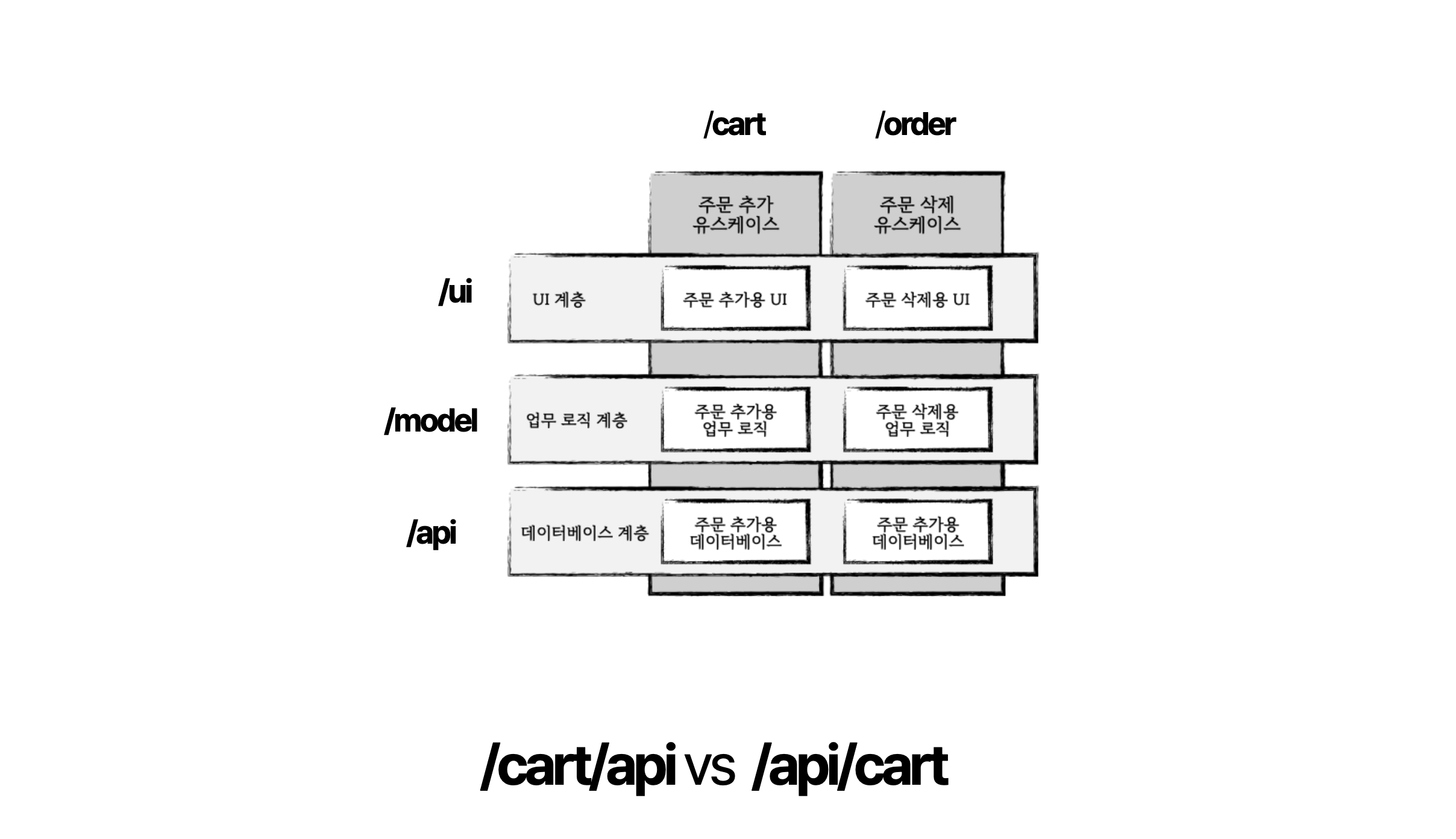
그렇다면 무엇을 중심으로 분리를 하는게 더 좋을까요? 현대 프론트엔드의 폴더구조에 대한 고민은 여기에 있습니다.
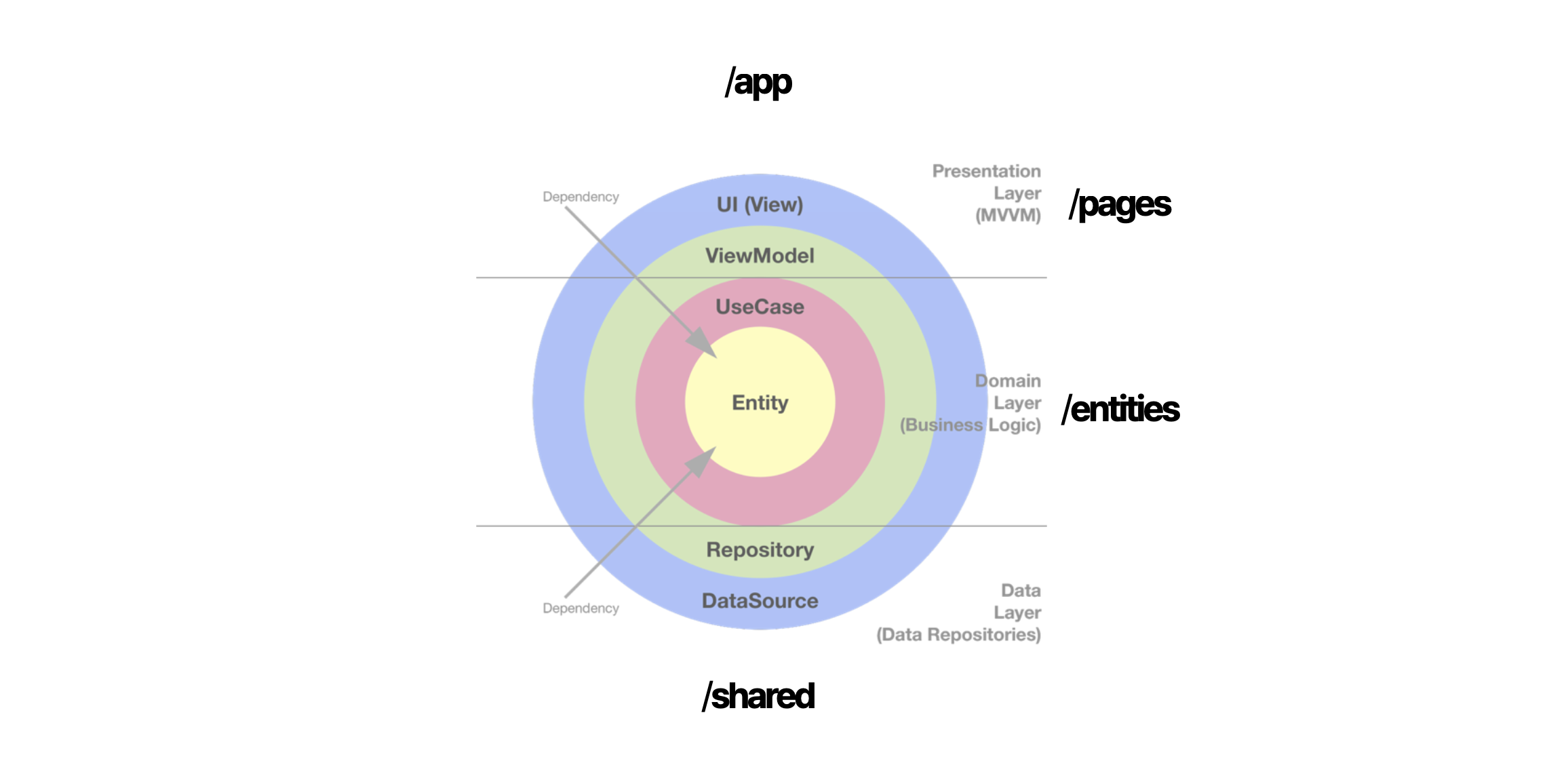
뿐만 아니라 클린아키텍쳐의 관점까지 생각을 한다면 여러가지의 선택들이 있을 수 있겠네요.
그렇지만 우리가 현재 사용하고 있는 세부적인 역할을 중심으로 하고 있는 표준 폴더구조가 있는데 그걸 사용하면 되지 않을까요?
기존 구조의 한계점
사실 기존 폴더구조는 이미 많은 시행착오를 겪고 만들어진 좋은 구조입니다. 그래도 프로젝트의 크기가 크지 않다면 충분히 괜찮은 구조이죠. 언제나 문제는 프로젝트의 규모가 커질때 발생합니다.

프로젝트가 매우 커지게 되는 순간 우리는 기존의 역할대로 멋지게 분리를 했는데 우리가 원하는 관심사로 찾아가려고 하니 특정 관심사(main, order, cart)와 같은 내용들이 갈기갈기 찢어지게 되어버렸습니다. 분명 역할별로 분리를 하면 더 쉽게 찾을 수 있었는데 프로젝트의 규모가 커지다보니 이제 각 역할별 내용들이 섞여서 헷갈리는 상황이 되어버린 것이죠.

그래서 등장한 FSD 아키텍쳐 Feature-Sliced Design
Architectural methodology for frontend projects
역할만으로 구분하던 구조를 조금더 다양한 관심사를 만족하는 구조로 만들어보자.
/entities/post/api
https://feature-sliced.design/kr/
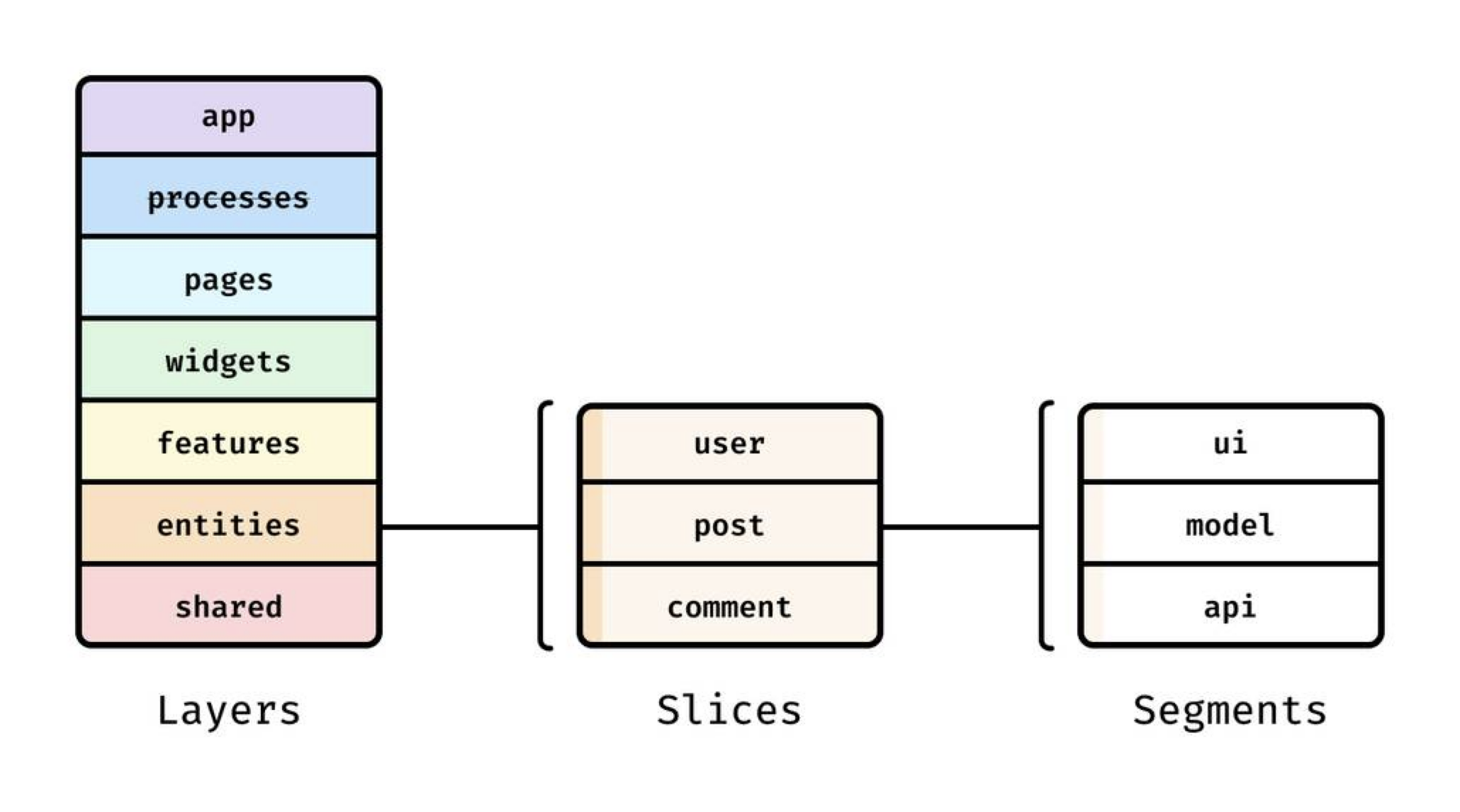
프로젝트의 규모가 커지면서 더 효율적인 구조와 관리 방법에 대한 필요성이 더욱 부각되었습니다. 다양한 관심사와 요구 사항을 충족하기 위해 기존의 역할 중심 폴더 구조만으로는 한계가 명확해졌습니다. 이를 해결하기 위해 등장한 것이 바로 Feature-Sliced Design(FSD) 아키텍처입니다.
FSD 아키텍처는 그 이름처럼 기능(Feature)을 기준으로 코드를 분리하는 방식입니다. 기존에는 역할에 따라 파일과 폴더가 구분되었지만, 이제는 하나의 기능 단위로 필요한 모든 파일들을 같은 폴더에 모아 관리하는 것을 목표로 합니다. 이 방식은 프론트엔드 개발에서 복잡성을 줄여주고, 유지보수성과 확장성을 크게 향상시키는 데 도움을 줍니다.
기존의 컴포넌트 기반 개발 방식에서는 역할별로 코드를 분리했지만, 기능 간의 결합도가 높아지는 문제를 완전히 피하기는 어려웠습니다. FSD 아키텍처는 이러한 결합도를 줄이고, 각 기능이 독립적으로 관리되도록 설계되었습니다. 특히, 대규모 프로젝트에서 이러한 방식이 더욱 효과적입니다.
FSD 아키텍쳐의 의의
FSD가 완전 새로운 아키텍쳐는 아닙니다. 다음 그림은 FSD가 제안되기 전에도 많이 제기되었던 내용이며 기존 역할별로 폴더 구조를 만들더라도 프로젝트의 규모가 커진다면 기능별로 묶어내는게 좋다는 제안들이 있었습니다. 일부 규모가 큰 프로젝트에는 일부는 자연스레 아래와 같은 모양을 하고 있을거라 생각합니다. 역할별로만 폴더를 나누다 보면 기능을 관리하기 어려워지기 때문에, 규모가 커지게 되면 기능 단위로 묶어 관리하는 것이 더 효율적이라는 인식이 확산된 것이죠.
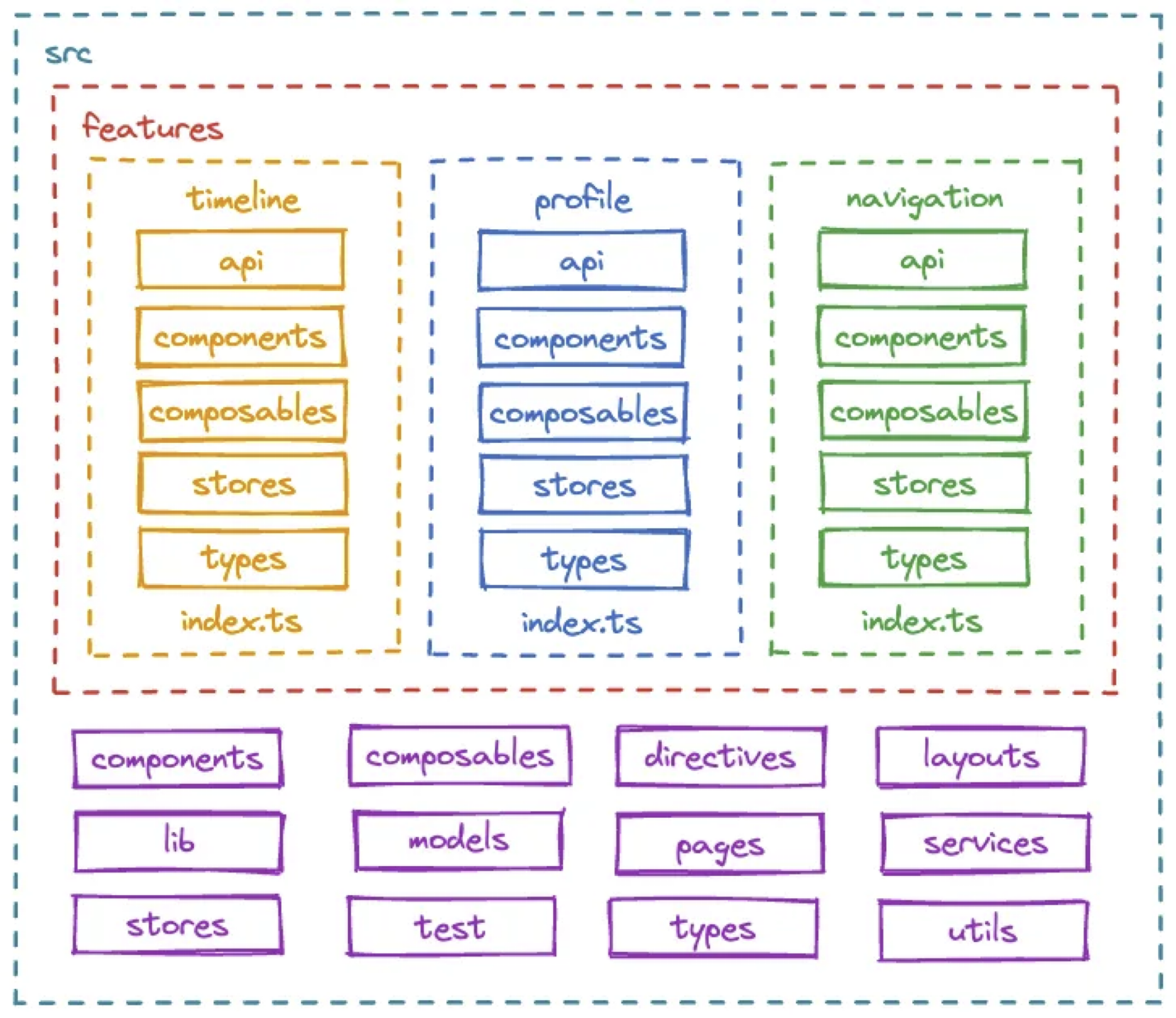
위 그림은 FSD가 아니라 프론트엔드 구조에 대한 제안글에서 가져왔습니다.
FSD가 전혀 새로운 것은 아니지만, FSD를 제안하고 알려드리는 것은 이러한 방식이 어찌되었든 FSD는 공식적인 형태를 갖추고 문서화가 되어 있다는 점입니다.
사실 폴더구조라고 하는 것들은 개인의 제안으로 쉽사리 바꿀 수 있는 것들이 아닙니다. 그리고 절대적으로 "이것이 정답"이라고 할 수 있는 구조도 없습니다. 프로젝트의 특성에 맞추어 발전해야 하며, 이러한 변화 과정에서 팀 내 합의가 매우 중요한데, 이때 커뮤니케이션 비용이 상당할 수 있습니다.
FSD는 이처럼 공식적인 문서화가 되어 있어, 팀원 간의 멘탈 모델을 맞추고 합의를 이끌어내기 용이하다는 장점이 있습니다. 폴더 구조는 프로젝트의 규모에 따라 달라져야 하기에 최종적으로 어떻게 만들어질지 우리의 형태는 어떻게 해야할지 커뮤니케이션을 하는데 도움이 되어줄 것입니다.
어떻게 적용을 할까? 프론트엔드의 핵심 관심사와 폴더 구조의 진화
"...이거 해봤는데 기존 폴더 구조는 역할별로 분리하면 되지만,
효용성도 모르겠고 적용도 어렵고 많이 쪼갠다고 다 좋은 건지 모르겠어요."
관심사는 관점에 따라 달라진다고 하였습니다. 스타터 킷의 폴더구조가 역할별로 만들어져있는 것은 프로젝트의 규모가 작을 때에는 그러한 방식이 훨씬 만들기 좋기 때문입니다. FSD의 공식설명에서도 이러한 구조는 프로젝트의 규모가 클때 유용하다고 말하고 있습니다.
폴더 구조는 프로젝트가 커지고 복잡해짐에 따라 함께 진화해야 합니다. 처음에는 작은 프로젝트에서 단순한 역할별로 구분하는 폴더 구조가 적합할 수 있지만, 시간이 지나면서 프로젝트가 성장하고 새로운 요구사항들이 생기면서 기존의 폴더 구조가 비효율적으로 변하기도 하죠. 결국, 프로젝트의 성장과 함께 폴더 구조도 변화해야 합니다.
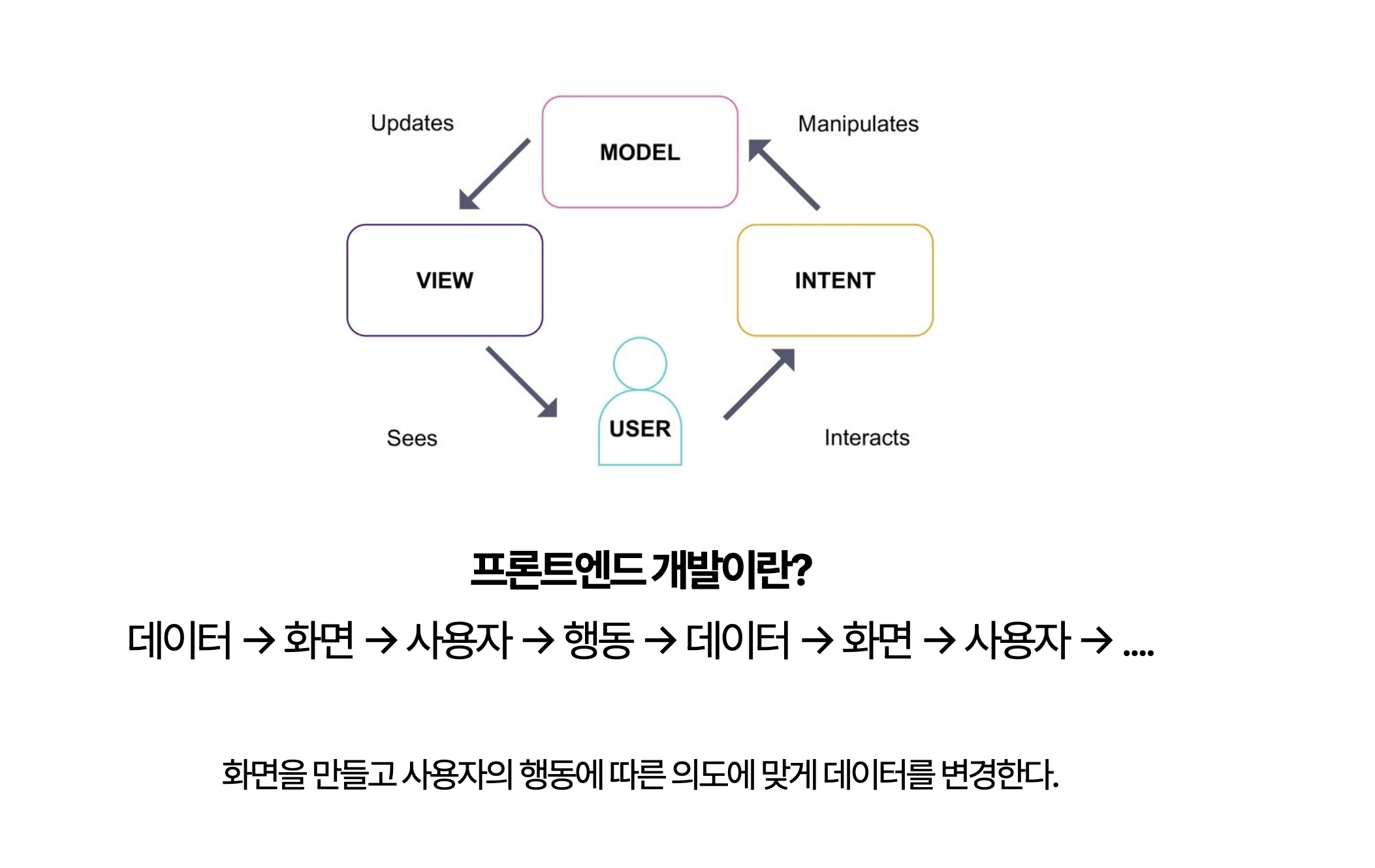
프론트엔드 개발의 핵심은 화면을 만들고, 그 화면에서 사용자의 행동을 바탕으로 데이터를 처리하며 다시 화면에 반영하는 과정입니다. 즉, 데이터 → 화면 → 사용자 → 행동이라는 반복적인 흐름이 프론트엔드 개발의 본질입니다. 이러한 흐름을 중심으로 폴더 구조도 발전하게 되죠.
따라서 지금의 관심사에 따라서 폴더구조와 규모도 적절히 변경이 되어야 합니다. 그렇기에 FSD가 절대적인 기준이 되어야 하는게 아니라 FSD의 구조에 빗대어 프로젝트의 규모에 따라 어떻게 서서히 폴더구조가 적용이 될 수 있는지 함께 알아봅시다.
1. 프로젝트 초창기 시기

프로젝트 초기에는 주로 화면을 구현하는 데 초점을 맞추게 됩니다. 이때는 페이지(route)에 따라 화면을 나누고, 재사용이 필요한 컴포넌트는 /shared 폴더에 두는 방식이 일반적입니다. API 호출도 페이지 내부에서 직접 이루어지며, 로컬 상태 관리를 통해 대부분의 요구를 처리할 수 있습니다.
사실 이때의 구조는 우리가 알고 있는 역할별 방식과 다르지 않습니다. 아직 규모가 작은 프로젝트에는 각 역할에 맞게 만들어주는 편이 훨씬 더 개발자들이 빠르게 작업할 수 있습니다.
2. 프로젝트가 조금씩 커진다.
프로젝트의 규모가 커지면서 서비스적으로는 함께하지만 사실상 페이지별로 독립된 페이지들이 만들어지게 됩니다. 이때부터는 역할보다는 페이지단위로 구분을 하는 편이 좋습니다. 일부 공통로직을 제외한다면 페이지에서 독자적으로 사용되는 것들이 많으니까요.
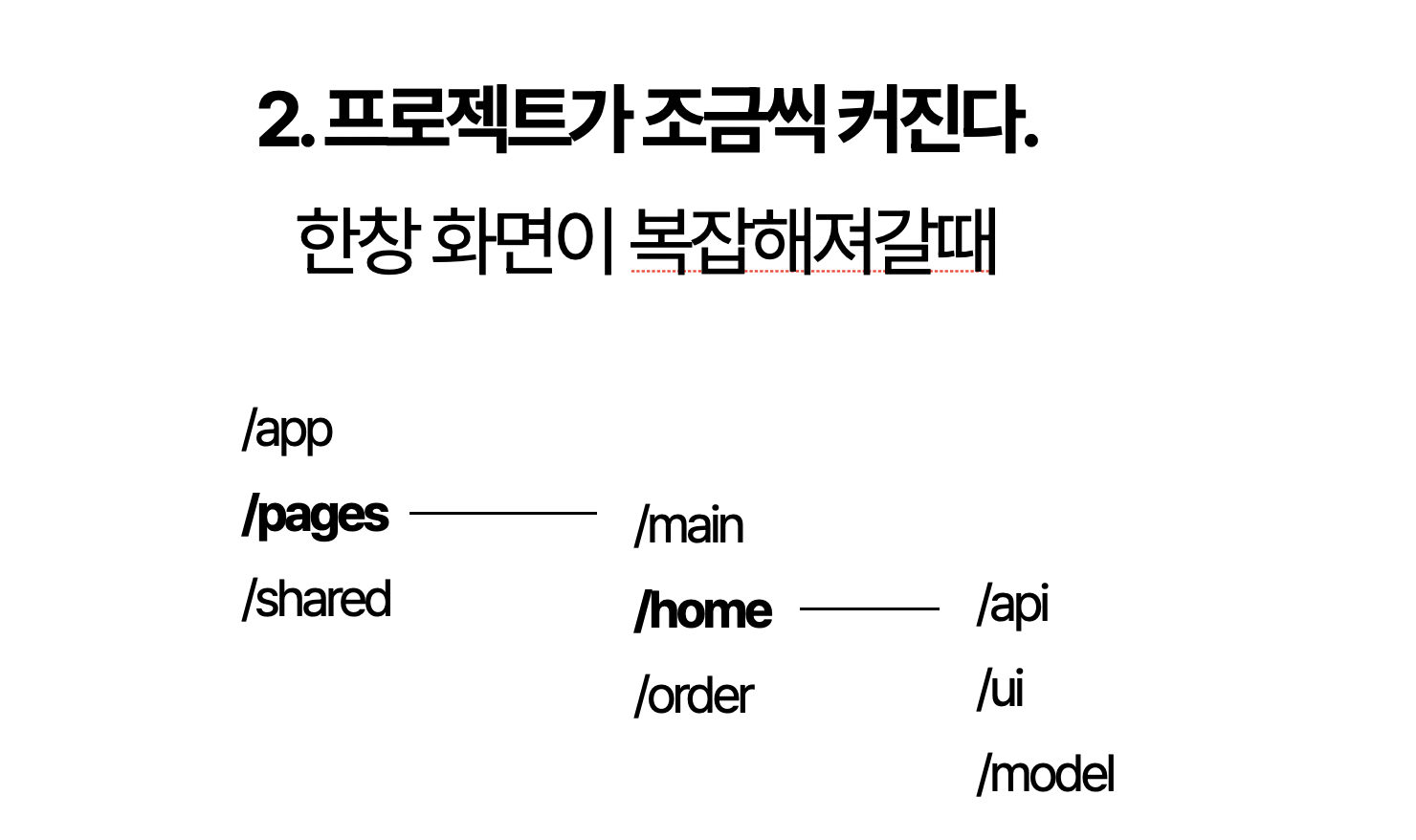
이 시기에는 페이지별로 상태 관리와 API 호출을 함께 묶어 관리하는 것이 훨씬 효율적입니다. 즉, 공통 컴포넌트를 빼기보다는 각 페이지마다 필요한 상태와 API를 그 페이지 안에 포함시키는 방식이 낫습니다. 이렇게 만들경우 폴더내에 책임범위를 명확히 할 수 있기에 app의 공통으로 뽑을 것과 pages에서만 쓰이는 것들을 분리한다면 공통 컴포넌트와 api들이 비대해지는 현상을 막을 수 있습니다.
3. 프로젝트 릴리즈 막바지
프로젝트의 막바지 단계에서는 더 이상 화면을 만드는 것보다 API와 비즈니스 로직의 처리가 주된 작업이 됩니다. 화면 자체는 이미 대부분 구현이 끝난 상태이고 대부분 문제가 발생하고 있는 부분은 복잡한 데이터 흐름이나 상태 관리들입니다. 이제 대화를 나눌때에는 화면보다는 데이터를 중심으로 이야기를 하고 수정을 하게 됩니다.
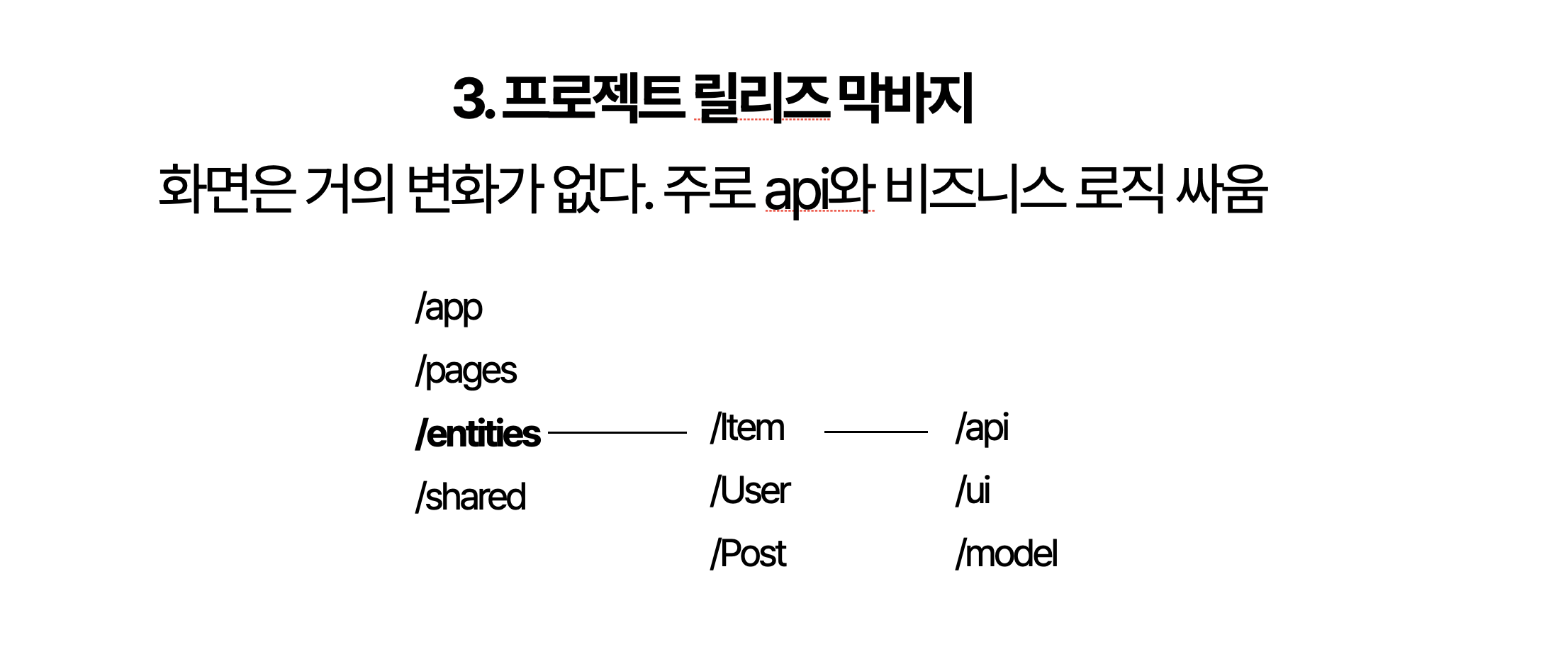
이 시점에서 발생하는 주요 문제 중 하나는, 화면과 도메인이 결합된 만능형 복합 컴포넌트입니다. 멋진(?) 워딩으로 설명했지만 단순한 컴포넌트에 비지니스로직과 도메인 정보들이 결합이 되면서 점차 많은 역할을 하게 되고, 복잡한 상태와 비즈니스 로직이 얽히다 보니 하나의 거대한 컴포넌트를 만들고 있죠. 이러면 점차 디버깅이 어려워집니다.
이럴 때 필요한 것이 바로 도메인 데이터를 중심으로 정리하는 것입니다. 도메인 컴포넌트와 뷰 컴포넌트를 명확히 분리해 각자의 역할을 독립적으로 수행할 수 있도록 만드는 것이 중요합니다. 즉, 화면을 그리는 뷰 컴포넌트와 데이터를 처리하는 비즈니스 로직을 각각 분리하고, 데이터 흐름을 명확하게 정의함으로써 데이터 관리와 화면 관리를 분리하는 것입니다.
이때부터는 서버쪽 도메인 데이터의 구조와 내용들은 잘 변하지 않습니다. 도메인 데이터를 중심으로 api와 ui와 model를 분리하게 되면 재사용이 가능하고 화면과 관심사를 분리하게 되면서 이후 대응하기에도 좋은 구조를 가져갈 수 있게 됩니다. 중요한 건 화면을 다루기 보다는 데이터를 주로 다루는 시점이라는 것이죠.
4. 릴리즈 이후 기능 개선 및 기능 추가
프로젝트가 릴리즈된 후에도 유지보수와 새로운 기능 추가는 계속됩니다. 하지만 이때 문제는, 기존의 폴더 구조로는 각 기능이 어디에서 수정되어야 하는지 파악하기 어려워진다는 점입니다.

신규 기능을 만들고 있는데 기존 폴더구조를 따르면, 페이지와 엔티티 그리고 api와 화면을 다루는 것들이 다시 파편화가 됩니다. 이후 나는 기능을 중심으로 관심을 가지고 있는데 관련된 파일들이 여러 곳에 흩어져 있다 보니 어느 파일을 수정해야 하는지 명확하지 않습니다. 더 나아가, 기능을 추가하거나 수정할 때 커밋 범위가 예상보다 넓어져 불필요한 코드까지 건드리게 되는 상황도 자주 발생하죠.
이런 경우에는 잠시 오픈한 기능을 빠르게 제거하거나, 특정 기능만을 따로 빼달라는 요구가 생길 때도 문제입니다. 기능이 명확하게 구분되어 있지 않다 보니, 어느 부분을 수정해야 기능을 안전하게 제거할 수 있는지 파악하는 것이 쉽지 않게 됩니다.
이러한 시기에는 기능 단위로 코드를 모아두는 것을 진행하게 됩니다. 기존의 역할별 폴더 구조에서 기능 단위로 코드를 나누면, 각 기능이 독립적으로 관리될 수 있고, 수정이 필요한 부분도 쉽게 찾을 수 있습니다.
폴더 구조를 변경하고 건드려야 하는 순간 징후의 변화 : 관심사가 변하는 순간
지금 무엇에 관심을 두고 있는가?
무엇이 변하고 무엇이 변하지 않는가?
프로젝트가 진행됨에 따라 관심사가 변하는 순간이 찾아옵니다. 이때가 바로 폴더 구조를 다시 생각해볼 때입니다. "지금 무엇에 관심을 두고 있는가?"라는 질문을 스스로 던져보세요. 초기에는 화면을 만드는 데 집중했겠지만, 프로젝트가 진행되면서 상태 관리, API 통합, 비즈니스 로직 등 다양한 관심사가 점차 생겨나게 됩니다.
무엇이 변하고 무엇이 변하지 않는가를 파악하는 것이 중요합니다. 예를 들어, 화면 구성이나 컴포넌트는 그대로일 수 있지만, 데이터 처리나 비즈니스 로직이 점점 더 복잡해질 수 있죠. 이처럼 프로젝트에서 변화하는 부분과 변하지 않는 부분을 이해해야만, 적절한 시기에 폴더 구조를 재편할 수 있습니다.
하지만, 중요한 것은 정답은 없다는 것입니다. 프로젝트의 상황에 맞는 폴더 구조는 정해진 답이 아니라, 균형과 시기의 문제입니다. 기능 중심이냐, 역할 중심이냐, 혹은 도메인 중심이냐 하는 구분은 프로젝트의 특성, 규모, 팀의 요구에 따라 달라질 수 있습니다.
그리고 FSD 아키텍처 역시 모든 프로젝트에서 완벽한 해결책이 되지는 않습니다. 상황에 따라서는 기존의 폴더 구조가 더 적합할 수도 있고, 다른 방식이 더 효율적일 수도 있습니다. 관심사는 관점에 따라 달라지기 때문에, 무엇이 중요한지를 지속적으로 고민하고 그에 맞는 구조를 선택하는 것이 필요합니다.
정답을 찾기 위한 과정: 소프트웨어 공학의 원칙들
소프트웨어 개발에는 절대적인 정답이 없지만, 우리가 정답에 가까워지는 원칙들은 존재합니다. 프론트엔드 개발에서 '정답'을 찾는 과정 역시 소프트웨어 공학의 기본 원칙들을 적용하는 과정이라고 볼 수 있습니다. 이러한 원칙들은 코드의 유지보수성과 확장성을 높이는 데 핵심적인 역할을 합니다. 널리 알려진 몇 가지 중요한 소프트웨어 공학 원칙들을 함께 살펴봅시다.
1. 단일 책임 원칙 (Single Responsibility Principle, SRP)
단일 책임 원칙은 관심사의 분리에서 가장 핵심이 되는 원칙입니다. 하나의 모듈이나 클래스는 오직 하나의 역할만을 수행해야 하며, 그 역할에 대해서만 책임을 져야 한다는 것입니다. 프론트엔드에서 이를 적용한다면, 컴포넌트가 화면을 그리는 역할만을 담당하고, 상태 관리나 비즈니스 로직은 별도의 모듈에서 처리하는 방식이 될 수 있습니다. 이렇게 함으로써 각 컴포넌트는 단일 책임을 유지하며, 변경과 수정이 용이해집니다. 사실 모두가 알고 있는 내용일테지만 이걸 지킨다는게 참 어렵습니다. 한번 더 상기하라는 의미로 적어봤습니다.
2. 의존성과 단방향 데이터 흐름
HTML과 CSS에서 우리는 의존성 관리와 단방향 데이터 흐름의 중요성을 배웠습니다. 서로에게 영향을 끼칠 수 있도록 만들었더니 혼돈이 되어버렸습니다. 무엇이 자주 변하고 무엇이 자주 변하지 않는지를 파악해 데이터 흐름이 단방향으로 흐르게 설계할 수 있도록 합시다.
3. OCP 원칙 (Open/Closed Principle)
OCP 원칙은 소프트웨어의 설계에서 중요한 원칙 중 하나로, 확장에는 열려 있고, 변경에는 닫혀 있어야 한다는 개념입니다. 확장을 한다면 기존 코드를 건들지 말아야 하고 수정이라면 기존 코드를 수정해야 합니다. 이 부분도 참 지키기가 어렵습니다. 요구사항이 변경이 되다보면 어느순간 if if if 를 하면서 분기하는 코드를 만들게 되니까요. 뒤에 한번 더 설명을 하겠지만 같은 모양을 하는 컴포넌트에 분명히 다른 데이터를 출력하고 있는데 if if 가 붙은 코드들을 생산하곤 합니다.
4. 응집도는 높게, 결합도는 낮게

응집도는 높게, 결합도는 낮게! 아주 중요한 소프트웨어 설계의 핵심이죠. 언제든지 분리할 수 있도록 만들어라. 그러나 같은 역할이라면 가까이 두어라. 뻔히 아는 내용이지만 코드를 만들다보면 지금 결합도를 높이는 건지 응집도를 높이는 건지를 모른채로 모아두면 나중에 수정이 어렵고 분리해두면 어디에 무엇이 있는지 모르겠는 코드를 만들곤 합니다. 정리정돈은 알지만 참 실천이 어려운 과제죠.
원칙을 벗어나는 FE가 흔히 하는 실수들
: 모양이 같으면 같은 컴포넌트로 만들어 보려고 한다.
소프트웨어 공학 이론들은 대부분 익히 알고 계실 겁니다. 하지만 이 원칙들의 의미를 실제 개발에서 체득하는 것은 여전히 어려운 일입니다. 이제 실수하기 쉬운 상황을 예시로 함께 살펴보겠습니다.
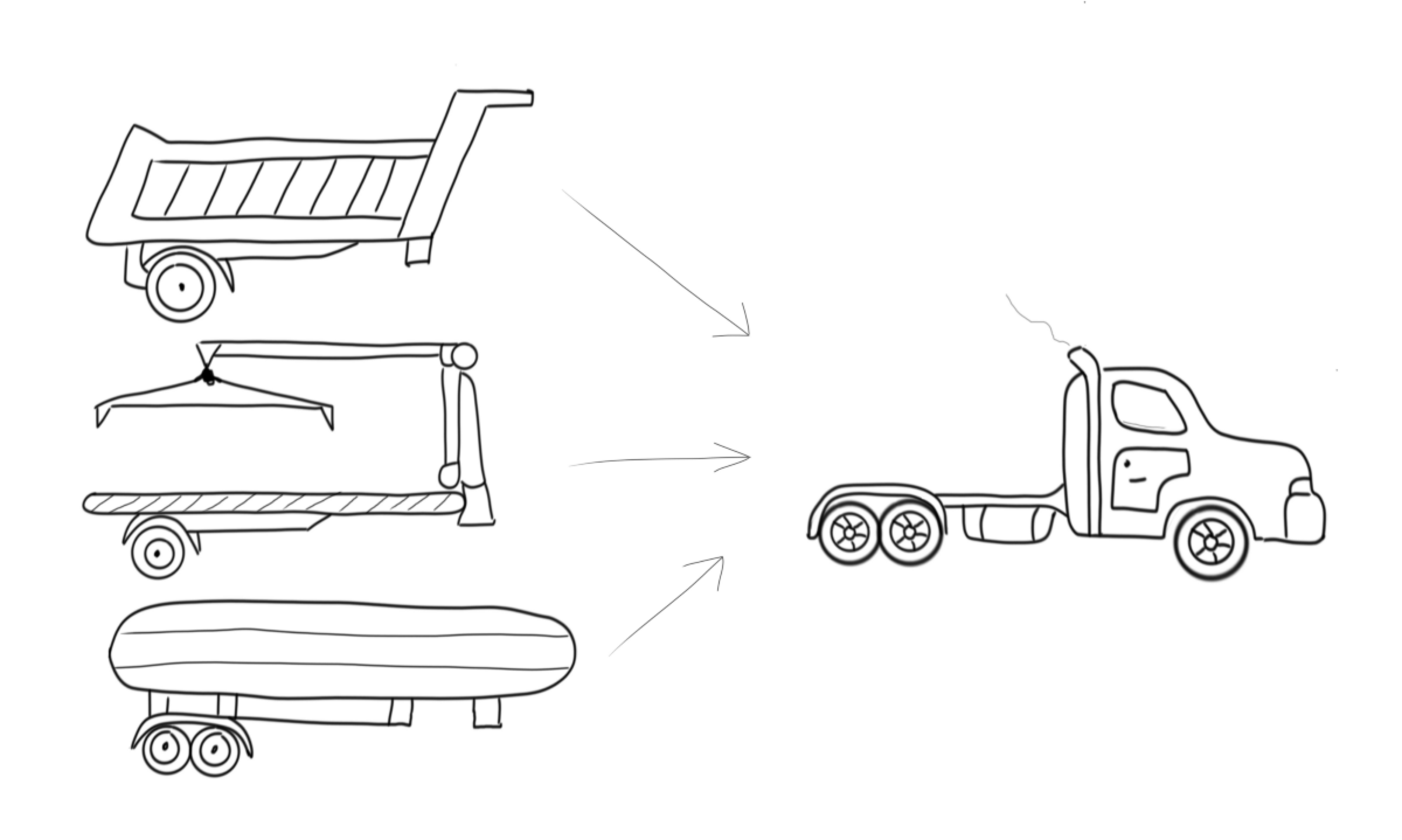
UI 컴포넌트와 도메인 컴포넌트는 하는 역할이 다릅니다. 하지만 개발을 하다 보면, 모양이 비슷하다는 이유로 같은 컴포넌트로 묶어서 재사용하려는 실수를 자주 하게 됩니다. 여기서 놓치는 것은, 데이터가 다르면 UI도 결국 달라진다는 점입니다.
예를 들어, 위와 같이 같은 모양을 하고 있다면 아래와 같이 컴포넌트를 재사용하는 경우를 만들게 됩니다. 처음에는 이런 의도는 아니었겠지만 어느순간 이러한 모습을 하게 되죠.
function ItemCard(props) {
return <div>
if (props.알바) <Badge/> (X)
if (props.중고차) price * 0.1 (X)
</div>
}두 가지 상황에서 UI는 비슷해 보이지만, 실제로는 완전히 다른 데이터를 처리하고 있습니다. 이렇게 모양이 비슷하다는 이유만으로 하나의 컴포넌트로 묶으려 하면, 오히려 코드의 결합도가 높아져 수정과 유지보수가 어려워집니다.
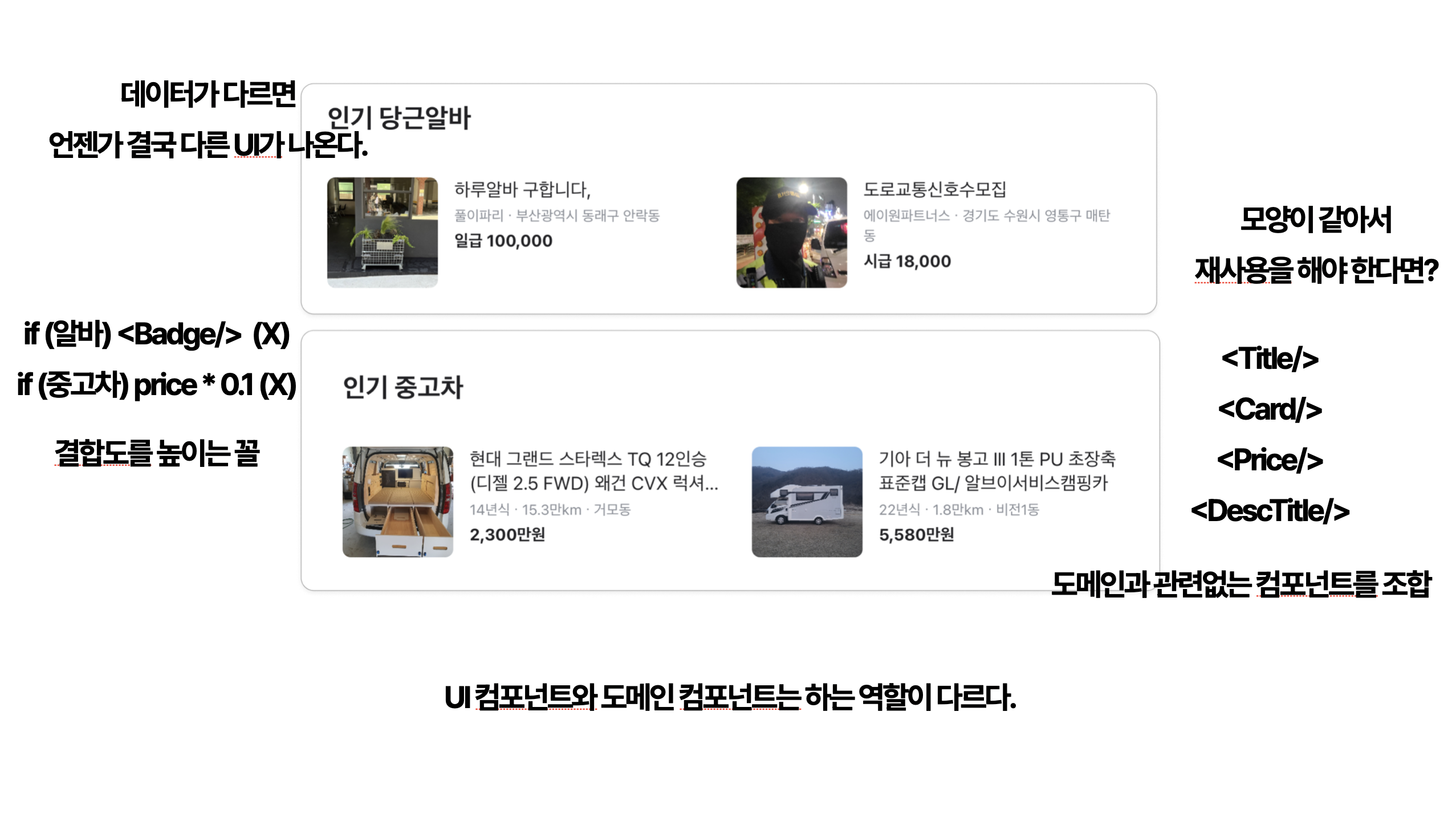
그렇다면 어떻게 해야 할까요? 모양이 비슷하더라도, 각 도메인에 특화된 데이터를 다루는 컴포넌트는 별도로 분리해야 합니다. 공통적으로 재사용할 수 있는 컴포넌트는 도메인과 관련 없는 UI 요소들만으로 구성해야 합니다. 예를 들어, Title, Card, Price, DescTitle 같은 도메인에 종속되지 않는 UI 컴포넌트들을 조합해 응집도 높은 컴포넌트로 만들어야 하죠.
하지만 이렇게 하기 위해서는 상당한 귀찮음이 동봉됩니다. 그러고 무작정 이렇게 해버린다면 불편한 보일러플레이트를 만들어내는 셈이 되어버리죠. 적당히 정리정돈이 필요할때 적당히 해야하지만, 화면 컴포넌트와 도메인 컴포넌트를 분리한다는 원칙은 항상 지켜야 합니다.
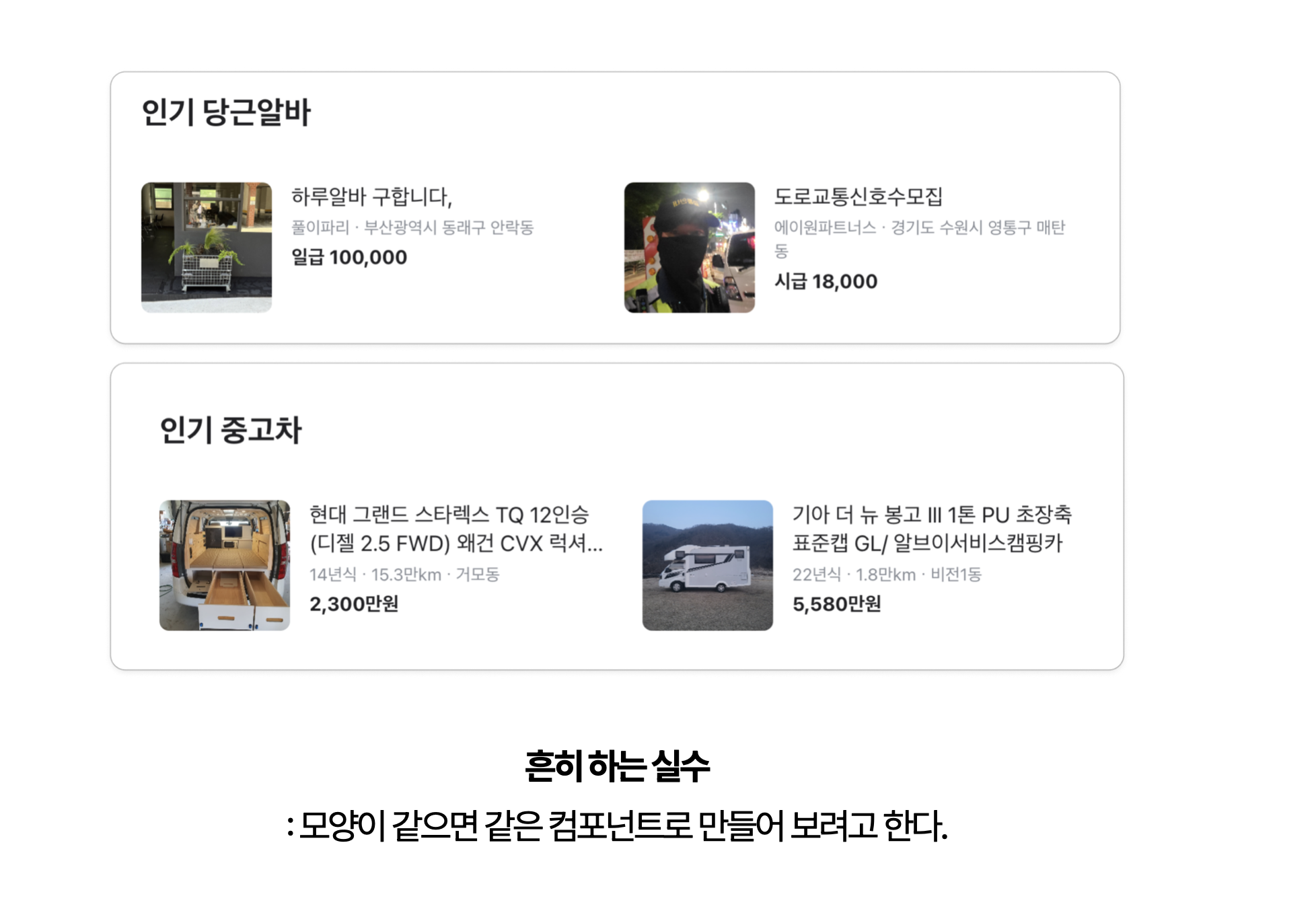
저희는 Admin을 하는데 만능 게시판이 필요한데요?
반면 정말로 모양이 같은데 일부 내용이 달라져야 하는 경우도 있습니다. 가령 Admin 콘솔에서 쓰이는 만능(?) 게시판같은 것들 말이죠. 이런 경우에는 단 하나의 게시판 컴포넌트를 만들어, 모든 상황에서 사용하고 싶은 욕구가 생깁니다. 실제로 이 경우에는 공통으로 재사용되는 화면을 사용하는 것이니까요.
이때에는 화면이 변하지 않기 때문에 하나의 거대한 컴포넌트에 다음과 같이 데이터를 분기하는 로직들을 만들어서 관리를 하게 됩니다. 그러면 어느순간 만능게시판이긴 한데 뭔가 엄청난(!) 것이 만들어지게 됩니다.
if (공지사항) class="notice" (X)
if (Task && isGuest) class="hidden" (X)
화면과 데이터의 의존성 방향은 언제나 데이터에서 화면입니다. 그렇지만 게시판 UI는 모두에서 공통으로 쓰려고 합니다. 그러면 어떻게 데이터의 흐름과 의존성을 만들어야 할까요?
같은 화면을 표시하기 위해서는 같은 데이터를 써야 합니다. 데이터에 따라서 로직은 달라질 수가 있다면 데이터에서 데이터를 변환해야겠죠. 그렇기에 게시판 컴포넌트를 도메인 데이터에 맞추려면, 데이터를 변환하는 어댑터가 필요합니다. 각 도메인의 데이터를 게시판 컴포넌트가 받아들일 수 있는 형태로 변환한 후 전달해야 하죠. 예를 들어, 아래와 같은 방식이 필요합니다.
interface Task {
id: number;
title: string;
description: string;
isComplete: boolean;
}
interface BoardItem {
id: number;
label: string;
status: "Complete" | "Incomplete";
}
function transformTaskToBoard(tasks: Task[]): BoardItem[] {
return tasks.map((task) => ({
id: task.id,
label: task.title,
status: task.isComplete ? "Complete" : "Incomplete",
}));
}
function App() {
const boardItems = transformTaskToBoard(tasks);
return <Board items={boardItems} />;
}마무리
개발에서 관심사의 분리는 복잡성을 줄이고 유지보수를 쉽게 하기 위한 중요한 원칙입니다. 이번 글에서는 HTML, CSS, JavaScript라는 웹의 기본 구성 요소에서부터 시작해, 프론트엔드의 발전과정에서 각자의 역할에 맞게 관심사를 어떻게 분리하는지, 그리고 그 과정에서 마주하게 되는 문제와 해결책을 살펴보았습니다.
관심사의 분리는 단순히 기능을 나누는 것이 아니라, 각 요소가 명확한 책임을 가지고 동작하도록 설계하는 것입니다. 단순히 관심사대로 나눈다고 해서 완벽한 해결책이 되는 것은 아니었습니다. HTML와 CSS의 관계처럼 서로 영향을 주는 방식도 좋지 않았고, 상태관리를 통해서 api를 관리하겠다고 하는 방식도 결국은 좋지 않는 방식이었습니다. 너무 많은 분리는 오히려 복잡도를 높일 수 있기 때문에, 균형을 찾는 것이 중요했습니다.
모듈과 레이어를 기반으로 한 분리, 데이터 흐름을 고려한 설계 등 여러 관점에서 관심사는 달라질 수 있습니다. 프로젝트의 규모가 커짐에 따라 관심사가 달라지다보니 폴더 구조도 단순한 역할 기반에서 벗어나, 기능 중심의 구조로 진화할 필요가 있습니다. FSD 아키텍처는 바로 이런 요구에 대응하기 위해 등장한 하나의 접근법입니다.
FSD가 완전히 새로운 아키텍처는 아니지만, 다양한 관심사를 만족시키기 위한 문서화된 표준이라는 점에서 유용한 도구가 될 수 있습니다. 프로젝트의 성장과 함께 폴더 구조도 확장되어야 하고, 그 과정에서 각자의 멘탈 모델을 명확히 하여 방향을 정할 수 있게 도움을 줄 수 있습니다. 지금 무엇에 관심을 가지고 있는지 무엇이 변하지 않는지 무엇이 변하고 있는지, 책임 범위가 어떻게 되는지에 따라 적절히 폴더구조도 함께 진화를 해야합니다.
소프트웨어 개발에는 정답이 없지만, 더 나은 구조를 찾아가는 과정에서 지켜야 할 원칙은 분명 존재합니다. 단일 책임, 의존성 최소화, 결합도와 응집도 등 기본 원칙을 바탕으로, 자신의 프로젝트에 맞는 최적의 구조를 찾아가보시길 바랍니다. 원칙은 원칙이고 실전은 실전이니까요.
이 글을 통해 여러분이 진행하고 있는 프로젝트에서 관심사의 분리를 어떻게 적용할 수 있을지, 그리고 어떤 폴더 구조가 적합할지, 그리고 소프트웨어 공학의 원칙들에 대해서 한번쯤 생각해볼 수 있는 기회가 되었길 바랍니다. 감사합니다.

25개의 댓글

컴퍼넌트로 진입 하면서 기능이 유사하다는 이유로 같은 컴퍼넌트를 쓸 때 나오는 로직의 분기처리, 기능 변경, css 처리 등을 하다 보면 오히려 이게 맞나 싶을 정도 깊게 들어 가게 되는 작업이 많아지는 것 같습니다.
편리한 부분도 있지만 오히려 업무의 복잡성이 늘어가는 느낌이 더 크게 느껴지네요.
리액트,뷰 등 프레임워크가 나오고 더 간단하게 작업 가능 하다는 스벨트, 솔리드, htmx 등도 매번 업데이트 대응/수정 등 오히려 배보다 배꼽이 커질 상황이 많아지고, 상태도 달라지면 그에 엮여있는 부분들은 건드리지 않을 수 없는 것 같더라구요.
프론트가 변화는 크지만 쓸 수 있고 활용 할 수 있는 부분은 그대로 받아 들이고 사용하는 부분이 조금더 커져야 하지 않을가 하는데 따라가기도 힘든 부분들이 많은것 같고,
그에 따른 폴더 구조, html, css, js 등 기준 점을 찾기 위한 노력은 프로젝트 마다 달라 질 수 밖에 없는 것 같습니다.
어떠한 데이터를 조작하고 dom을 제어하고 ui/ux 변경 등 할일은 더 많아 지기도 하고, jsx, shadowdom, 기존 html 등 파편화의 심화가 더 커질 것 같아 걱정이 되네요.
뭐 우리나라는 프론트엔트 프레임워크는 리액트가 주류인것 같아서 덜 한 것 같지만요.

좋은 글 잘 읽었습니다. 실무 경험도 많지 않고 feature 단위로 나뉘는 것이 적합할 정도로 커다란 프로젝트에 기여한 적도 없지만, 클린 아키텍쳐의 이론적인 부분과 FSD의 구성에 비슷한 면모가 다소 보여서, FSD를 처음 발견했을 때 호기심을 가져 본 적 있습니다. 글을 읽기 전, 어찌 되었든 feature 단위로 코드를 정돈하며 개발을 시도해 봤는데, 말씀하신 대로 제 프로젝트에 boilerplate가 상당히 많아졌고, 실제로 제공해야 하는 기능보다 그 기능을 정리하는 일에 시간을 더 많이 쏟게 되었습니다... '결국 FSD는 마냥 "한 번 체험해 볼 수 있는" 구조가 아니라, 정말 많은 시간과 노력이 드는 아키텍쳐구나'라고 생각하고 공부를 포기했는데, 이렇게 FSD를 어찌 접근해야 할 지 잘 쓰인 글을 읽고 좀 위로가 되었습니다. 상황에 맞는 프로젝트 구조를 결정하는 방법도 정리해가며 읽었습니다. 아직 부족하지만, 주니어로서 열심히 공부해 보겠습니다. 시간 들여 긴 글 써 주셔서 정말 감사합니다.

글 잘 읽었습니다. 좋은 코드, 좋은 구조란 무엇인가를 생각하기에 앞서 서비스의 품질과 안정성, 유지보수성, 빠른 비즈니스를 따라갈 수 있는 민첩함이 고려되어야 합니다. FSD... 화면을 보며 작업하는 프론트엔드 개발자가 디벨롭하기 좋은 구조는 아니죠. 작성자님이 사용하고 계신 구조에 monorepo를 통하여 관심사를 큰틀로 잘 분류하는 것만으로도 충분히 좋은 구조라고 생각됩니다.
요점은 커진 규모에 대한 관리를 FE 친화적인 구조에 수평적 방식으로 관리하는것. 이로인해 발생할 수 있는 Side Effect에 대한 방안으로 단일책임원칙을 철저히 할 것 입니다.
monorepo가 참 좋은게 서비스 품질과 안정성에 대한 파이를 상당부분 인프라 영역으로 넘길 수 있어 더욱 견고한 서비스를 만들 수 있는것 같습니다.

글에 나온 대로 FSD를 제대로 실천하기 위해서는 현재 프로젝트에서 제일 중요한 관심사(기능, 도메인, 페이지)가 무엇인지 파악하고, 주요 관심사에 맞는 폴더 구조를 만드는것이 제일 중요한것 같습니다.
그리고 ui랑 도메인 컴포넌트를 분리해야하는 이유에 설명한 부분이 가장 인상깊네요. 요즘에 코드를 작성하게 되면 컴포넌트 안에서 분기가 많이 생겨버려서 더러워졌는데 제대로 제가 ui와 도메인을 분리하지 않아서였군요. 도메인 상태에 대한 분기 기능을 굳이 ui가 알고 있을 필요는 없는 것 같습니다. 더 잘 분리할수록 SRP를 더 잘지키게 될 것 같네요.
시간이 갈수록 백엔드쪽의 패턴이나 원칙들이 프론트쪽으로 점점더 많이 넘어오는것 같습니다.
리액트는 자체는 객체지향은 아닌데 객체지향 원칙이 너무 잘 적용되네요.

최근 FSD에 대해 관심이 있어 개발도 해보고 이것저것 찾아보고 있는데 보다 근본적인 문제에 대해서 적어주셔서 재밌게 봤습니다!
몇 주 뒤에 부트캠프에서 FSD 관련 발표를 진행할 예정이라 준비 중인데 써주신 내용 중에 너무 좋은 내용이 많아서 앞 부분의 관심사 분리 설명 중 일부 내용에 대해 참고하여 발표자료에 활용하고 싶은데 출처를 표기하고 활용하여도 괜찮을까요?!


안녕하세요, 좋은 글 감사합니다!
저는 이제 실무를 시작하고 있는 프론트엔드 개발자 입니다.
본문에 적어주신 것 처럼 모양이 같으면 컴포넌트로 만들어 보려고 하는 흔한 개발자가 저인것 같아서 많은 인사이트를 얻을 수 있었습니다.
이전부터 어떤 기준으로 컴포넌트를 구분해야하는지에 대한 기준을 모르겠다는 생각을 해왔습니다.
그래서 데이터가 다르면 언젠간 다른 UI가 될 수 있다는 점이 저에게는 꽤나 좋은 기준으로 생각됐습니다.
다음 문단에서 만능 게시판으로 예시 들어주신 부분에 어댑터를 사용하는 방식으로 데이터의 규격을 동일하게 설정해서 사용하는 방법을 보여주셨는데, 이러한 방식이 같은 UI를 사용하는 다를 규격의 데이터일때 권장되는 방식인지 궁금합니다!

안녕하세요! 개인적으로 가려웠던 부분을 해소할 수 있는 글이라서 정말 많이 도움됐습니다. 혹시 이 글을 읽으며 정리한 내용을 티스토리에 업로드해도 괜찮을까요? 혹시 문제가 될까 싶어 여쭤봅니다. (출처는 당연히 남기겠습니다!)
글 잘 읽었습니다. 글에서 11번째 이미지의 "axios"의 로고는 http 라이브러리가 아닌 "axios"라는 이름의 언론사의 로고 입니다. 참고: https://en.wikipedia.org/wiki/Axios_(website)