Faster R-CNN
- 이미지를 VGG16에 넣어 feature map 생성
- feature map을 RPN에 넣어 RoI생성 후 feature map에 project
- 이후 RoI pooling을 거치고 RCNN과 동일
지금까지 region proposal algorithm은 고전적인 방법인 selective search algorithm에 기반을 두고 있었다
그러나 지금부터는 RPN(Region proposal Network) model을 활용하여 RoI를 뽑아낼 것이다
이제 bbox를 뽑아내는 과정에도 CNN을 적용하기 시작한 것이다!
RPN부분을 제외하고는Fast RCNN과 동일하다
그래서 RPN 모델에 집중해보자
지금까지는 region proposal 과정에서 고전적 알고리즘을 적용하였기에 시간이 많이 들고 비효율 적이었다
뿐만 아니라 뒤에 CNN 부분은 GPU를 사용하는데 region proposal은 CPU를 사용하다니…
여기서 속도를 높이려면 region proposal 부분에서도 GPU를 사용하는 것이 명백해보였다
그래서 RPN을 설계하였고 cost를 매우 낮추었다
RPN은 box의 scale과 종횡비 정보로 region proposal이 되도록 설계하였다
이때 scale과 종횡비 정보를 효율적으로 담아내는 “anchor” box라는 개념을 새롭게 도입한다
그림과 같이 한개의 영역이 다양한 scale,종횡비를 가진 box정보들을 가지고 있게끔 하는 것이 anchor이다
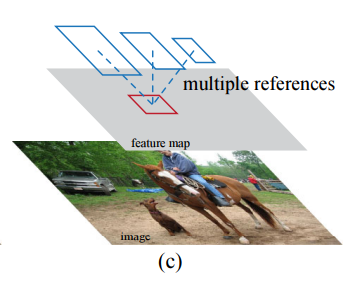
논문의 이 절에서 anchor에 대해 더 자세한 설명은 없지만 나름대로 부가설명을 하자면
예를들어 고양이와 개가 서로 얽혀있는 영상을 상상해보자
그리고 그 교집합에 있는 pixel을 떠올려보자
해당 pixel은 고양이 영역을 제안하는 box와 개 영역 box의 교집합 부분에 존재할 것이다
이때 해당 pixel에 anchor 개념을 도입해 그 pixel이 가질수 있는 다양한 scale과 종횡비를 가진 box정보를 anchor에 담아낸다(pixel이 여러 크기의 box를 갖는다고 생각, 그림참고)
RPN에서는 anchor를 활용하여 해당 pixel에서 어떤 크기,종횡비의 box를 가져야 개 혹은 고양이,즉 object를 담아낼 수 있는지 추론하고 region proposal을 진행한다
(후처리로 non maximum suppression을 진행하여 유의미한 box들만 남긴다)
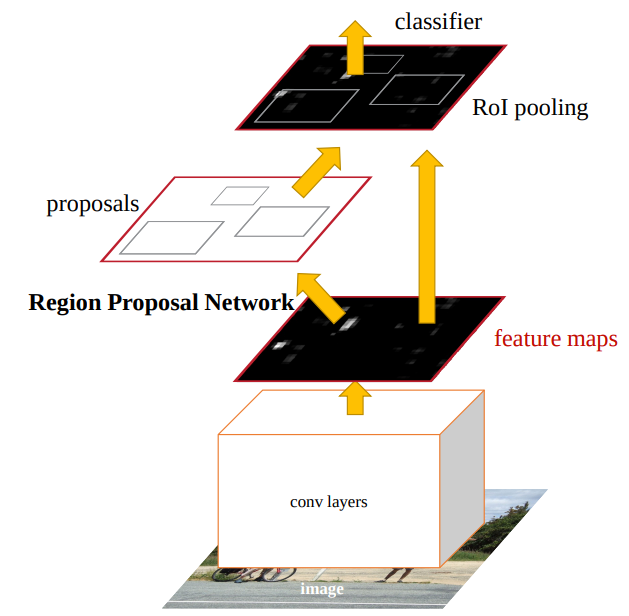
Faster RCNN 모델은 영역을 제안하는 RPN모듈과 제안된 영역을 이용하는 Fast RCNN모듈로 구성되어있다
여기선 RPN에 대해서 설명한다
VGG16 을 거쳐 나온 feature map으로부터 small network를 한번 더 거쳐 feature를 뽑아낸다. 이때 저자는 small network에서 3x3 window를 사용했다
그후 1x1 convolution 연산을 각각 수행하여 객체 여부를 추론하는 cls와 박스를 regression하는 reg 정보를 뽑아낸다
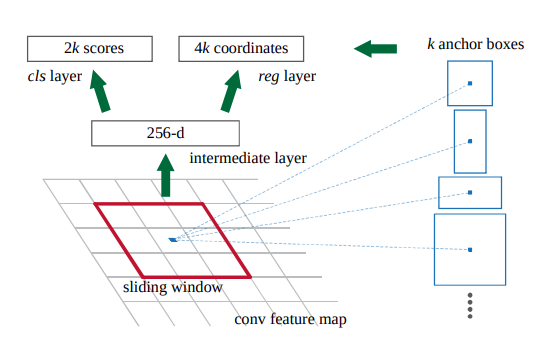
Anchor를 어떻게 활용하는지 설명한다
sliding winow 과정에서 가운데 pixel에 anchor를 도입한다
anchor는 여러 scale과 종횡비를 조합해서 나온 k개의 박스이다
위에서 설명했듯이 RPN은 이 anchor정보를 가지고 해당 anchor 내에 객체가 있냐 없냐(cls)를 나타내고 anchor의 좌표를 나타내는 정보(reg)를 확인하여 추론한다
(cls)객체가 있냐 없냐(1,0) → k개의 박스에 대해 encoding 2k개의 정보
(reg)box의 좌표(x,y,w,h) → k개의 박스에 대하 encoding 4k개의 정보
여기서 저자는 k=9로 설정하였다
scale 3개, 종횡비 3개를 설정하여 3x3 경우의 수 → 9개의 박스를 만들어냈다
정리하자면 영상 입력받아 VGG16을 거쳐 feature map을 만들었고 이후 RPN으로 넘긴다
RPN에서는 VGG16에서 받은 feature map을 3x3 sliding window 적용하고 (이때 padding을 적용하여 크기 유지)pixel이 9개의 anchor box를 참조하도록 한다
그 pixel은 이제 9개의 크기가 다른 박스(anchor)를 가지고 있다
1x1 convolution연산을 cls, reg 따로 수행하여 박스들 안에 객체가 있는지 없는지 그리고 박스들의 coordinate 정보를 추출한다
이후는 후처리(non maximum suppress)하여 의미있는 RoI만 남기고 feature map에 projection 시킨후 RoI pooling+Fast RCNN과정과 동일하다
feature map의 크기가 HxW라면 anchor까지 참조하게한다면 anchor의 개수는 WHk이다
< Loss Function>
우선 anchor에 대해 객체가 있음/없음 즉 positive/non-positive를 부여하는 definition을 먼저 말한다
anchor에 대해 p/np를 부여하는 방법 2개를 소개한다
- IoU 0.7 이상인 anchor에들에게 positive를 부여
- IoU최대값을 갖는 anchor에게 positive 부여
저자는 이 두 방식을 혼합하여 사용한다
우선 1번 방식으로 0.7미만인 anchor들을 추려낸고 0.7이상인 anchor들에게 positive를 부여한다.
만약 1번 방식에서 positive가 나오지 않았다면 기준 2를 적용하여 anchors 중 최대 IoU를 갖는 anchor에게 positive를 부여한다.
즉, 무조건 1개의 positive를 갖도록 한다.
이러면 (0.4,0.1,0.1,0.1…) 갖는 anchors에서 0.4가 positive로 선정될 수 있지만 후처리와 손실함수 덕에 보완할 수있다
또 IoU 0.3미만인 경우는 전부 non-positive를 부여한다.
그러면 0.3과0.7사이에 있는 값들은 어떻게 되는 것인가?
→ 아무 label도 붙이지 않는다. 그리고 unlabeld된 anchor는 loss function을 계산할 때 아무런 영향을 끼치지 않는다
예를들어 anchors=[7,1,2,9,5,6,1,5,8] (0.x라고 가정)로 총 9개 있다고 가정하자
그러면 1번 조건에 따라 7과9,8이 postive, 1은 non-positive, 나머지 5,6은 postivie도 non-positive도 아니게 된다
positive/non-positive 부여과정을 이해했으니 이제 손실함수를 이해해보자
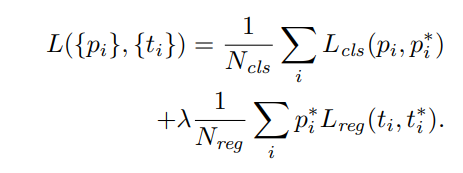
= anchor index
=anchor가 object일 확률
=ground truth(1or0, positive,non-positve)
=predicted bounding box coordinate
=positive anchor 중 ground truth box coordinate
: log loss를 사용한다
: Fast RCNN때와 마찬가지로 smooth L1 Loss를 사용한다
앞에 있는 는 ground truth가 obect일때만 box regression loss를 계산하도록 하기위해 곱해져있다
Loss의 output으로는 cls에 대한 loss와 reg에 대한 loss 각각해서 2개를 output을 내놓는다
은 normalize하는 역할이다 =배치 사이즈 크기 = anchor loacation의 수
람다는 두 loss를 weight를 조정하는 파라미터
논문에서는 =256, =2400정도,람다=10으로 설정했다
저자는 람다값을 바꿔가며 실헝한 결과 10에서 mAP 69.9로 가장 좋은 성능을 얻어냈다
또한 normalize가 필수는 아니라고 말한다
box regression 과정을 더 자세하게 들여다보자
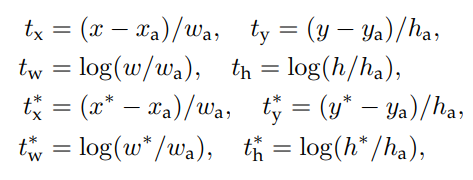
: predicted box coordinate
: anchor boc
: ground truth
즉 anchor box를 어떻게 움직이게 해야지 ground box 위치로 옮길 수 있을지를 고려한 식이다
regression하는 모델은 총 k개로 k개의 anchor의 box를 regression하는 모델들은 가중치를 공유하지 않고 독립적으로 학습한다.
<정리>
- Faster RCNN은 Region proposal 과정에서 고전 기법인 selective search알고리즘이 아닌 RPN model을 도입하여 Fast RCNN보다 학습 cost(비용, 시간)을 낮추었다
- RPN model에서 핵심은 “anchor”를 이용하여 region proposal을 수행한다는 것이다
- anchor는 하나의 pixel이 여러개의 크기를 가진 박스 정보를 담고있게끔 한다
- RPN에서 1x1 콘벌루션을 적용하여 cls와 reg 정보를 뽑아낸다
