YOLO v1
기존의 객체 검출(detection) 방식은 2단계로 이루어졌다.
즉, Region Proposal과 classification을 순차적으로 수행했다.
하지만 YOLO는 이를 1단계로 줄였다.
Region Proposal과 classification을 동시에 처리하는 방식을 도입했다.
YOLO는 이 작업을 classification이 아닌 regression 관점에서 접근했다.
이러한 접근으로 YOLO는 매우 빠른 속도를 달성했다.
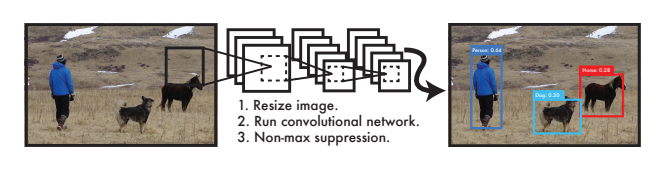
기존 기법들은 2step으로 complex했다
그래서 YOLO는 detection task를 regression task로 reframe하고
cell이 이미지 class와 box coordinate 정보를 갖게끔하여 이미지를 한번보고 객체의 위치와 class를 알 수 있게끔 했다
1step으로 단순화했다
YOLO의 장점
- 진짜 빠르다
- image detection시 이미지 전체를 볼 수있다
→ 기존 slide window는 정해진 region proposal 구역밖에 보지 못했지만 YOLO는 전체 이미지를 보므로 더 풍부하게 정보를 사용할 수 있다
- YOLO는 object의 general한 feature를 학습하므로 새로운 domain이나 unexpected input에 적응할 수 있다
단점
그러나 accuracy는 떨어졌다. accuracy와 speed 의 trade off 발생
2step이 아니라 1step이기에 neural network를 하나로 통합해서 사용한다
또한 이미지 전체를 보고 분류와 bbox regression을 동시에 수행한다
여기서부터는 YOLO의 수행과정을 설명한다
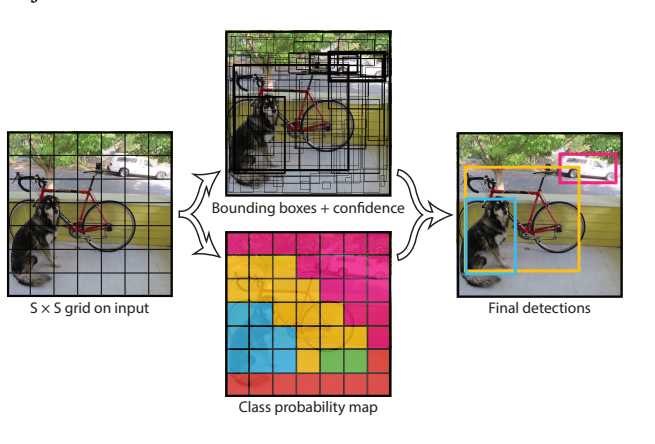
input image가 들어오면 image를 SxS grid로 나눈다
만약 object의 center가 특정 grid cell에 속하게 된다면 그 cell이 그 object를 담당(논문에서는 responsible)한다
각각의 grid cell들은 BBox정보와 BBox의 confidence score을 담당한다
score은 이 BBox가 얼마나 객체를 잘 탐지하고 있는지를 나타낸다
confidence score는 다음의 공식으로 계산된다
그 box가 객체를 포함하고 있지 않으면 =0이 되므로 socre=0이 된다
는 Truth와 predict값이 겹치는 비율이다
이제 box에 대해서 설명한다
BBox 정보는 5개의 벡터 표현된다.(x,y,w,h,c)
x,y= grid cell안에서의 bbox중심을 나타내는 상대적 좌표(0~1)
w,h=전체 이미지에서의 bbox의 width와 height
c=confidece(논문에서는 c로 표현하지 않았지만 내가 그냥 c라고 썼다)
이제 object class에 대해서 설명한다
class확률은 조건부 확률로 계산한다
식에 의해 object를 포함한 cell에 영향을 받는다
논문에서는
S(SxS로 나눌 grid)=7,
B=2(한 cell당 담아낼 bbox정보의 수, bbox정보 2개)
C=20(탐지할 class의 수, PASCAL VOC dataset에서는 class가 20개)
그래서 최종 YOLO모델의 최종 prediction은 7x7x30 tensor이다
7x7=grid cell
30=bbox1정보(x,y,w,h,c) 5개, bbox2정보 5개, class 20개 분류
Network Design
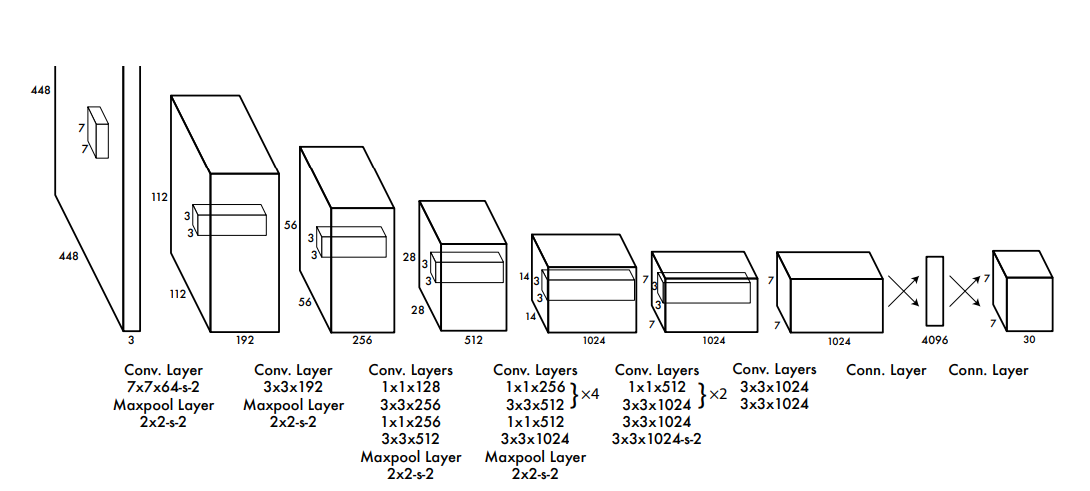
YOLO의 구조는 그림과 같이 24 CNN layer와 2 fc layer로 구성되어있다
또한 1x1 reduction layer를 거친 후 3x3 convolution layer를 수행하도록 했다(그림 참고)
최종적으로 7x7x30 크기의 tensor를 출력한다
Training
우선 CNN backbone은 ImageNet에서 1000개의 class를 학습한 Darknet을 사용하였다
그리고 detection task에 맞춰 수행하기 위해 model을 위의 그림과 같이 수정했다
또한 이미지의 해상도를 기존 224x224에서 세밀한 부분까지 탐지할 수 있도록 448x448로 resolution을 높였다
이후 fc layer층에서는 class probability와 bbox 정보를 regression한다
x,y정보는 gird cell에서의 offset 좌표이므로 0~1값을 가지고
w,h정보는 0~1값을 갖게끔 normalize 시켜준다
activation function으로는 기울기가 0.1인 Leaky ReLU를 사용하였다
loss로는 optimize가 쉬운 sum-squared error를 사용하였다
그러나 문제가 있었으니 localization error와 classification error의 비중을 동등하게 처리한다는 것이다(박스회귀와 이미지 classification문제에 대해 다른 가중치가 필요하다)
또한 image내 영역의 대부분이 background다보니 “confidence”가 0으로 수렴해버리는 문제도 있었다
이를 해결하기 위해서 람다를 식에 넣었다
bbox coordinate를 더 비중있게 다루기 위해 coordinate 람다는 5로,
no object인 loss 영향력을 줄이기 위해 noobj람다는 0.5로 설정하였다
또한 작은박스와 큰박스를 비교했을 때 큰박스가 살짝 움직여도 큰 객체는 잘 탐지되지만 작은 박스 내 작은 object는 박스가 살짝만 움직여도 영역에서 나가버릴 수 있기 때문에 큰박스와 작은 박스의 loss를 동등하게 처리하면 안된다
그래서 이 격차를 고려하기 위해 bbox의 w,h 구하는 loss에는 root를 넣었다
예를들어 큰박스의 w,h=3,3 작은박스의 w,h=1,1라고 해보자
그리고 gt=그 중간값인 2,2라고 해보자
만약 root를 씌우지 않는다면 동등하게
큰박스 작은 박스 둘다 loss가 1이 되어버릴 것이다
이제 root를 씌워보자
큰 박스는
작은 박스는 으로 작은 박스의 loss가 더 커져 큰박스보다 작은박스에 더 민감하게 반응할수 있게끔한다
grid cell마다 multiple bounding box를 예측한다
YOLO는 train시 하나의 object를 담당할 하나의 box만 필요하므로 multiple box중 ground truth와 가장 큰 IOU값을 갖는 BBOX하나로 학습한다(그러나 최종 출력은 후보 2안까지해서 2개의 bbox 정보를 보여준다, B=2로 설정했다)
grid cell당 1개의 object만 responsible 한다(YOLO v1의 한계가 여기서 드러난다)
sum-squared error를 사용하는 YOLO의 최종 손실함수는 그림과 같다

손실함수를 하나씩 뜯어보자
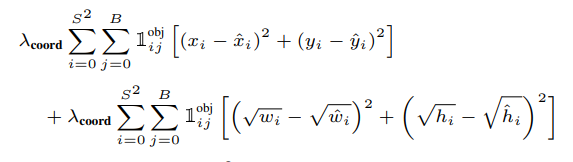
맨 위에 두 줄은 박스를 regression하는 loss이다
위에서 말했던 것처럼 큰박스와 작은박스의 편차를 고려하기 위해 w,h loss에는 root를 씌워서 계산한다
람다를 넣어 가중치를 조정하였다
를 넣어 object가 탐지 되었을 때만 loss를 계산하도록하였다 (1 or 0)
i,j는 i는 grid cell의 index를 j는 i번째 grid cell이 예측한 multiple box중 최고의 IOU 갖는 box의 index이다
즉 grid cell들을 i를 통해 순회하며 j를 통해 최고의 IOU를 갖는 box들만으로 loss를 계산하는식이다
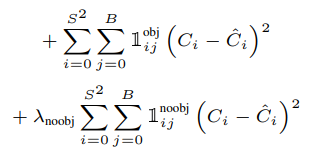
3~4번째는 box의 confidence의 loss를 담당하는 부분이다
object와 background인 경우를 계산하기 위해 와 변수를 넣었다
그리고 마찬가지로 i,j를 통해 가장 높은 IoU를 갖는 box만 loss function에 기여하도록 했다
마지막으로 람다 noobj를 통해 이미지의 대부분이 background라는 사실로 인해 confidence가 0으로 수렴하는 것을 방지했다
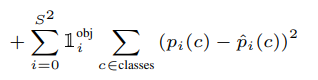
마지막 줄은 class loss를 계산하는 부분이다
를 이용하여 객체가 있을 때 class확률을 구하도록 했다
(위에서 말한 조건부 확률) bbox의 index는 필요 없으므로 i만 있는 것을 확인할 수 있다
이미지당 98개의 bounding box를 만들어낸다
98이 숫자가 어떻게 나왔는지 잠깐 살펴보자
저자는 이 논문에서 S=7(SxS grid cell 분할)로 설정하였다
그래서 이미지가 들어오면 7x7 격자로 분할한다
총 49개의 cell이 생기고
저자는 여기서 B=2로 설정했기 때문에 각 cell당 2개의 multiple box를 만들어낸다
49개의 cell이 2개의 bbox를 만들어 내니 98개의 bounding box가 나오는 것이다
추가적으로 더 정리를 하자면 bbox정보는 총 5개(xywhc)를 갖는다
cell마다 bbox를 2개 담고 있으므로 10 + 클래스 개수 20(PASCAL data set)
따라서 YOLO의 output이 7x7x30 tensor임을 알 수 있다(각 cell마다 30개의 vector갖는다)
또한 학습 시에는 2개의 bbox정보 중 GT와 가장 높은 IoU를 갖는 box만이 loss function에 기여한다
inference시에는 cell 당 박스 2개를 활용하여 추론한다
(다만 최종 출력은 후보군 box까지 같이 출력)
그리고 cell 하나당 1개의 object만을 responsible한다
(YOLO의 한계)
후처리로 NMS를 거쳐 유의미한 박스만 남긴다
- grid cell당 bbox정보를 2개밖에 담아내지 못한다
이전에 소개한 모델들은 bbox를 여러개(RCNN,FastRCNN에서는 약 2000개, Faster RCNN에서는 anchor를 도입하여 pixel당 9개 )를 만들어 냈지만 YOLO는 cell당 bbox 2개, 총 98개밖에 만들어내지 못한다
- grid cell당 1개의 object만을 responsible한다
1개의 cell은 1개의 object만을 담아낸다
2step 모델들(RCNN계열)은 bbox를 많이 만들어내고 그 bbox들을 classifiy하는 2tep이었기에 상관이 없었지만 YOLO는 1step에 하려다 보니 이런 문제가 생긴 것같다
따라서 작은 물체를 detection하는데에 어려움이 있다고 말한다
근데 여기서 문득 드는 생각이 그러면 cell에다가 anchor 개념을 도입하면 어떻게 개선될 수 있을 것같은데…? 라는 생각이 들지 않는가??
찾아보니 이후 YOLO 모델에서 anchor개념을 도입하는 것같았다
- bbox regression 손실함수의 한계
루트를 씌워 큰박스와 작은 박스의 오차 영향력을 고려하여 루트를 사용했지만 어쨌거나 식은 한가지의 식만 사용한다
이러한 문제로 큰박스와 작은박스의 loss를 저자는 완전히 해결하지는 못했다고 한다
YOLO는 속도가 매우 빠르지만 정확도는 이러한 이유로인해 조금 떨어진다고 한다
<정리>
- 한정된 region proposal 영역이 아닌 image를 전체를 보고 grid cell로 나눈후 box regression과 classification을 1stage로 처리한다
- 각 cell에는 30개의 vector(5:bbox1,5:bbox2,20:class)정보를 담고 있다 → 최종 출력 7x7x30 tensor이다
- 속도가 매우 빠르지만 성능이 이전 모델들이 비해 살짝 떨어진다
