Overivew
- 인덱싱이 적용되지않은것과, 인덱싱이 적용됐을때의 속도차이를 알 수 있습니다
근데 먼저 !인덱스 테이블의 각각의 칼럼의 의미하는 바를 파악하여보자
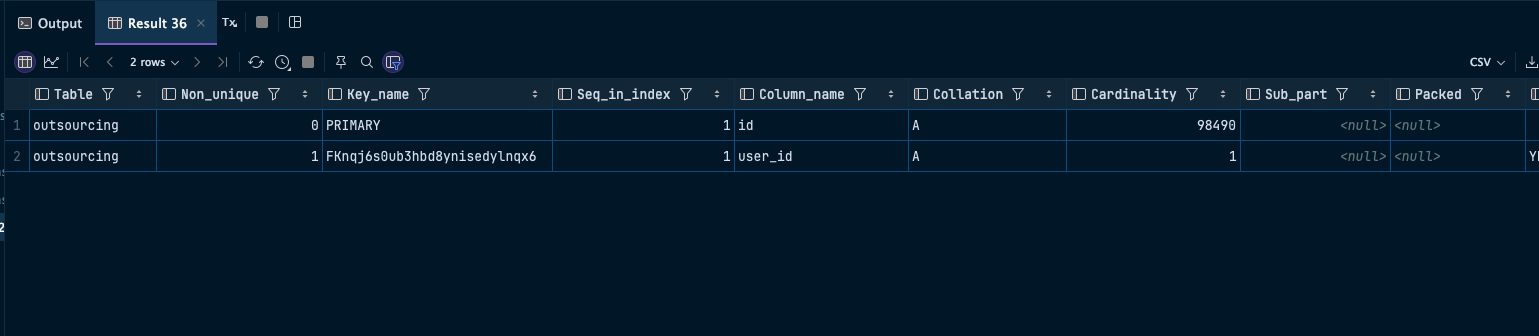
Table
- 테이블명 표기
Non_unique
- 인덱스가 중복된 값이 가능하면 1, 중복값이 허용되지 않는 Unique Index 라면 0을 표기
Unique Index?
중복값을 허용하지 않지만, null 값은 허용함
key_name
- 인덱스의 이름 표기, 인덱스가 해당 테이블의 기본 키 라면, PRIMARY로 표기함
Seq_In_Index
- 멀티칼럼이 인덱스인 경우 해당 필드의 순서표기
이게 먼소릴까..

예를들어 제목(title),우대사항(preferntial)을 가지고 Index를 생성하였다고 가정하자

그렇다면 이런식으로 멀티칼럼 1,2가 생길것이다.
즉 내가 title,preferntial을가지고 where절을 통하여 title과 preferntial을 검색할시
title Index를 가지고 먼저 조회한후, 그 다음 preferntial Index를 가지고 조회하는 개념이다
Column_name
- 해당 필드의 이름 표시
Collation
- 인덱스에서 해당 필드가 정열되는 방법 표시
Cardinality
- 인덱스에 저장된 유일한 값들의 수를 표시
내 DB에 분명 PK가 10만개있는데 왜 PK에 대한 카드이널리티가 10만개가 아닐까?
InnoDB의 특성상 완벽히 계산하지않고, 근사치를 제공하는 방식으로 성능을 최적화 하기 떄문
Sub_Part
- 인덱스 접두어 표시
Packed
- 키가 압축되는 방법을 표시
Null
- 해당 필드가 Null을 저장 할 수 있으면 YES, 아니면 ""을 표시
index_type
- 인덱스가 어떤 형태로 구성되어있는지를 나타낸다
Comment
- 해당 필드를 설명하는것이아닌, 인덱스에 관한 기타 정보 표시
index_comment
- 인덱스에 관한 모든 기타 정보 표시
Common
@Autowired
EntityManager em;
private static final int ROOP_COUNT = 1_000_00;
private static final int BATCH_SIZE = 1_000; @Test
@Transactional
@Rollback(false)
void 외주_배치사이즈_만들기() {
userCreateTest();
User user = userService.findById(1L);
long start = System.currentTimeMillis();
List<Outsourcing> outsourcingList = new ArrayList<>();
for (int i = 0; i < ROOP_COUNT; i++) {
Outsourcing outsourcing = new Outsourcing(
null,
user,
"Mobile App Development" + i,
"Looking for a mobile app developer to build an e-commerce app." + i,
"Experience with Flutter is preferred." + i,
"Remote",
10000L,
LocalDateTime.of(2024, 10, 10, 9, 0, 0),
LocalDateTime.of(2024, 10, 10, 9, 0, 0),
LocalDateTime.of(2024, 10, 10, 9, 0, 0),
LocalDateTime.of(2024, 10, 10, 9, 0, 0),
AreaType.SEOUL
);
outsourcingList.add(outsourcing);
// 1000개가 쌓였다면
if (outsourcingList.size() % BATCH_SIZE == 0) {
outsourcingRepository.saveAll(outsourcingList);
em.flush();
em.clear();
outsourcingList.clear();
}
}
if (!outsourcingList.isEmpty()) {
outsourcingRepository.saveAll(outsourcingList);
}
long end = System.currentTimeMillis();
System.out.println("===========================================");
System.out.println(end - start);
System.out.println("===========================================");
}- 10만 개의 더미데이터를 기준으로 진행해보고자 한다!
인덱싱 미적용, 단일 쿼리 조회 속도

- 97ms
인덱싱 적용(B+Tree), 단일 쿼리 조회 속도

- 34ms 가 걸린 모습이다
오늘 무엇을 알았는가?
-
B-Tree구조는
-
노드의 계층이 높고, 각각의 노드에 인덱스에 찾아야할 데이터가 들어있기 때문에 각 노드안에 인덱스를 많이 넣지 못하기 때문에 계층이 높다
-
B+Tree 구조는
-
상위 노드들에는 인덱스만 저장하고
가장 하단으 노드에 인덱스에 해당하는 데이터를 저장시키는데 각 하단의 노드는 서로 Linked List로 연결되어있어서 서로서로 찾을수있어서 더 성능이 좋고 빠르다
참조 블로그

테러대응전문가