출처 : 실무 사례로 배우는 컴퓨터 비전 논문 구현과 알고리즘 성능 최적화
패스트캠퍼스 ViT - Vision in Transformers
비전 훈련중에 transformer을 사용한 모델 입니다.
Transformers for image recognition at scale
ViT
- 모델 사이즈나 크기에 비해 계산량이 적음.
- 모델의 크기를 쉽게 Scale 할 수 있다.
핵심 목표
이미지를 어떻게 시퀀시로 만들 수 있을까? (Input)
- patch단위로 적용한 모델.
Step 1 - CNN to ViT
CNN에서의 이미지 입력으로 (공간정보를 학습) 모델을 학습시켜서 Classification(분류)문제.
CNN의 경우.
- 이미지의 전체 정보를 압축하기 위하여 여러개의 layer를 통과한다. 컨볼루션 필터(컨볼루션 커널)
Trasformer의 경우.
- 하나의 layer로 전체의 이미지 정보를 압축한다. 1d 벡터로 표현(640 X 480 벡터를 => 307,200 1d 벡터)
Inductive bias (주어지지 않은 입력의 출력을 예측)
-
Fully Connected layer의 경우, 모든 입력들이 output에 영향을 미치고 있기에, inductive bias는 약하다.
-
하지만 CNN은 컨볼루션 필터(지역적인 정보)를 적용하며, RNN또한 시간의 개념(순차적 특징)을 반영한다. 따라서 inductive bias를 가진다고 볼 수 있음.
-
추가로 Transformer는 self Attention을 통하여 layer를 진행하기에, 인풋(이미지)vector에 따라 weight가 각각 달라짐. 이는 지역적인 정보를 가정할 수 없다. 즉, 다시 말하면 locality를 가정할 수 있는 CNN보다 inductive bias가 적은 모델이다.
예측은 잘하지만, 학습을 잘하기 위해선 데이터셋이 커야한다는 단점을 가지고 있음.

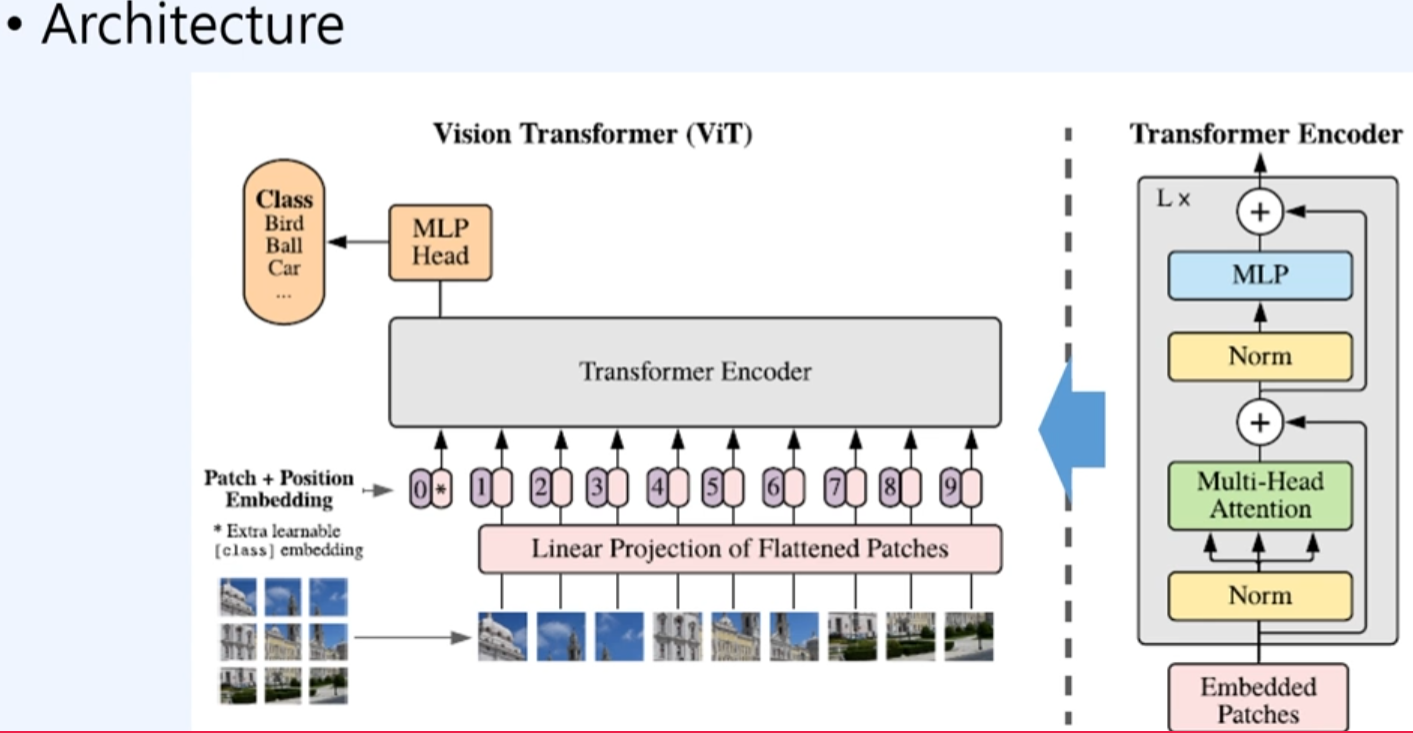
구조
결과
- ResNet 보다는 성능이 낮게 나오지만, 이는 Inductive bias가 부족한 것으로 판단된다.
동작원리
Self attention
- 주어진 문장간의 어떤 영향별 가중치를 계산한다.
- 이는 이미지에서도 각 block(patch별) 영향도를 계산할 수 있음. 선의 굵기가 굵다면 각 patch는 영향도가 높다고 볼 수 있다.
1. Patch embedding
- 핵심은 입력된 이미지를 embedding하는 것이다. 하지만 이미지를 마지 nlp(자연어)처럼 순차적 시퀀시의 토큰처럼 다뤄야 하는 방법으로 다루어야 한다.
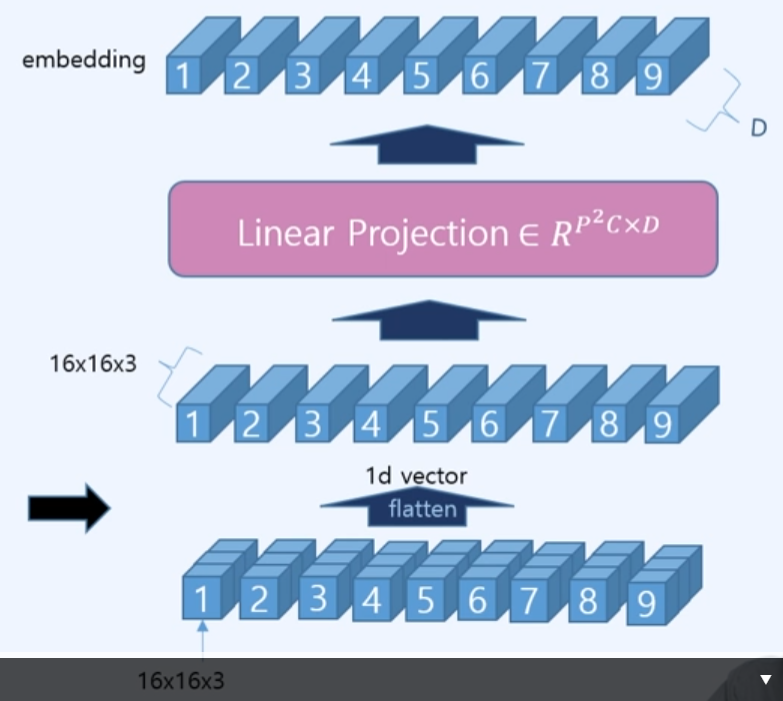
ex) ViT/16

- 16은 (16 x 16)의 이미지 입력 vector를 의미한다. 주어진 이미지의 화소가 (48 x 48 x 1)
- 하나의 이미지를 16x16 이미지로 나오는 이미지를 patch단위라 한다. 총 9개 patch
- RGB 채널로 하나의 patch는 (16x16x3)로 나타낸다. 즉 R(16x16x1), G(16x16x1), B(16x16x1)
- 다음으로, 16x16x3의 하나의 patch를 flatten(1d vector)로 적용하여, 768차원으로 표현한다.
- 768 * 9의 벡터들을 linear projection(fully Connection layer)을 적용하여 우리가 원하는 D차원으로 embedding을 진행한다.
2. Embedding patch + Positional Embedding
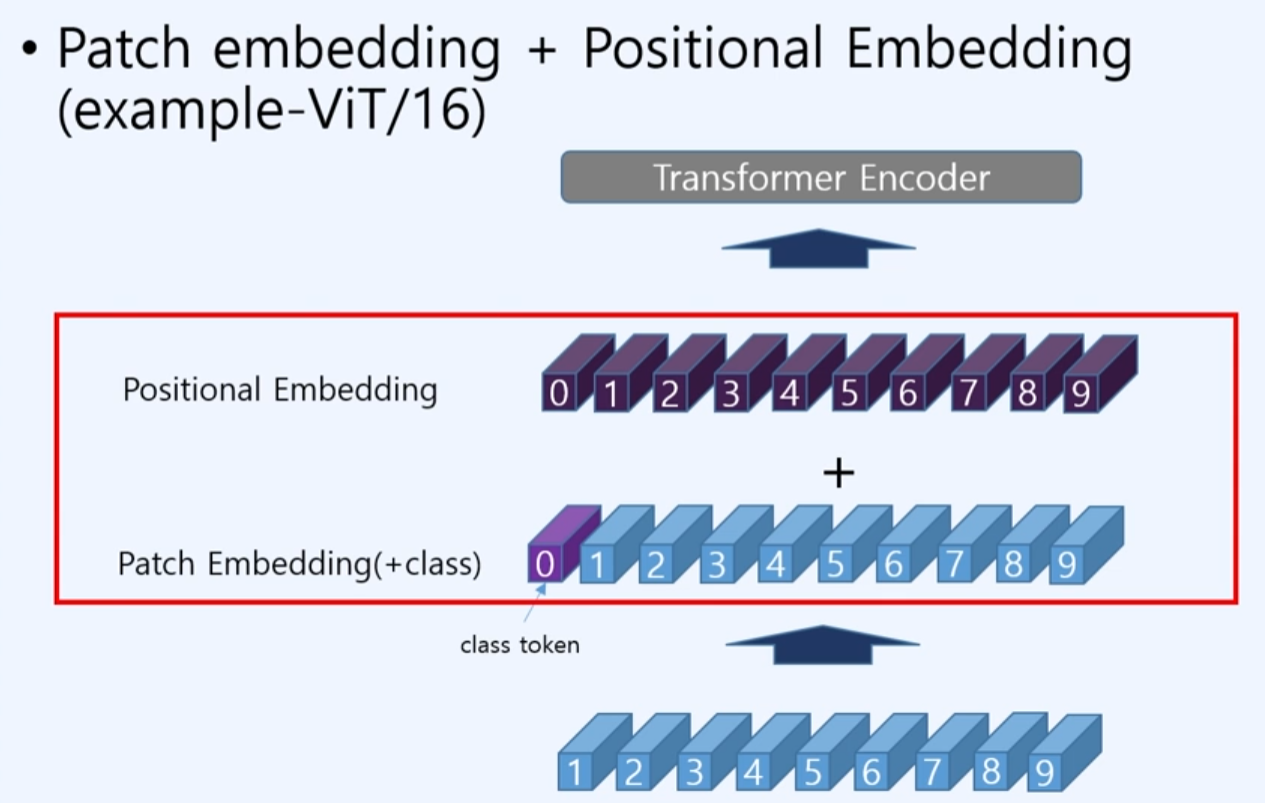
-
우리는 여기서 D차원으로 임베딩된 patch 임베딩에 + <class의 token 0 index로>를 부여하고 추가적으로 positional 임베딩을 sum을 취한다.
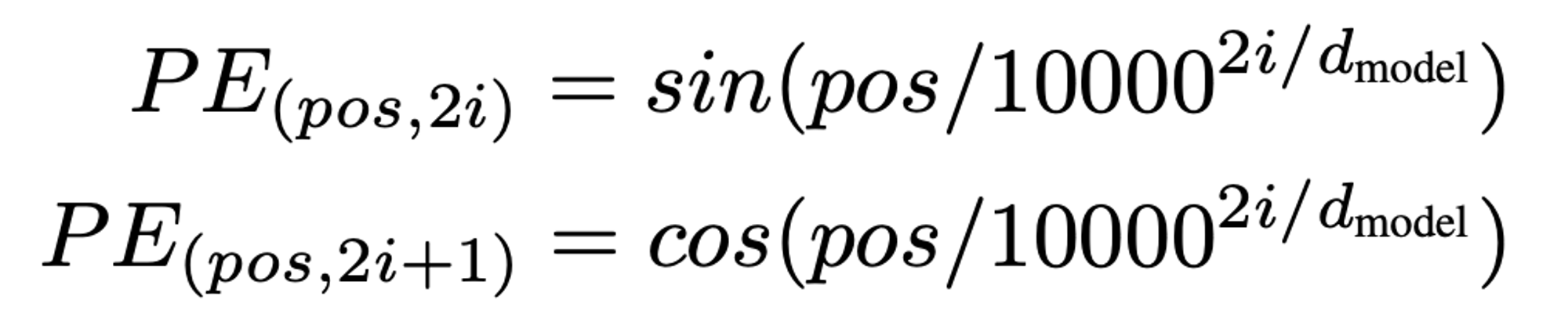
-
positional 임베딩의 경우, 주기함수에서 i가 patch순서의 index를 넣고, D차원의 임베딩된 patch를 넣어서 나온 결과값을 적용한다.
3. Transformer Encoder
-
이미지의 예측이 목표이다. (실제 코드에서는 이미지 class 예측 + 포함된 문맥도 output이 나와야 하는데, 예측만 진행함.)
-
인코더는 개 만큼 이용함.
3.1 Multi-Head Attention
-
q, k, v를 계산함. matrix multiple로 , , 를 곱함.
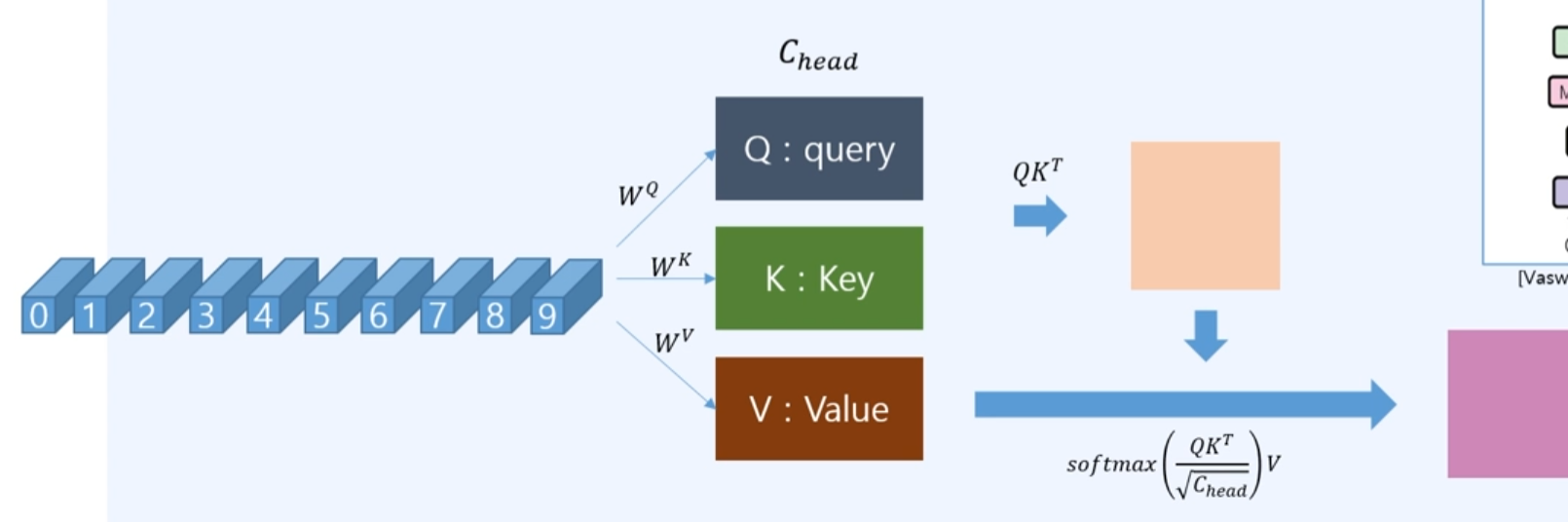
-
계산한 Q와 를 곱하고, head의 차원의 루트로 나눠서 softmax후 V를 곱함.
-
Q와 의 값이 너무 커지면 softmax의 값이 발산될 수 있어서, head로 나눠준다.
-
Scaled Dot-product Attention에서는 head의 개수만큼 concat하여, linear layer로 하나의 head처럼 나오도록 계산함.
3.2 MLP
-
multi layer perceptron를 사용하여 업데이트 함. mlp의 아웃풋은 transformer 인풋과 동일한 크기임.
-
추가로, skipped connection(Resnet배경)을 추가함.
4. MLP head
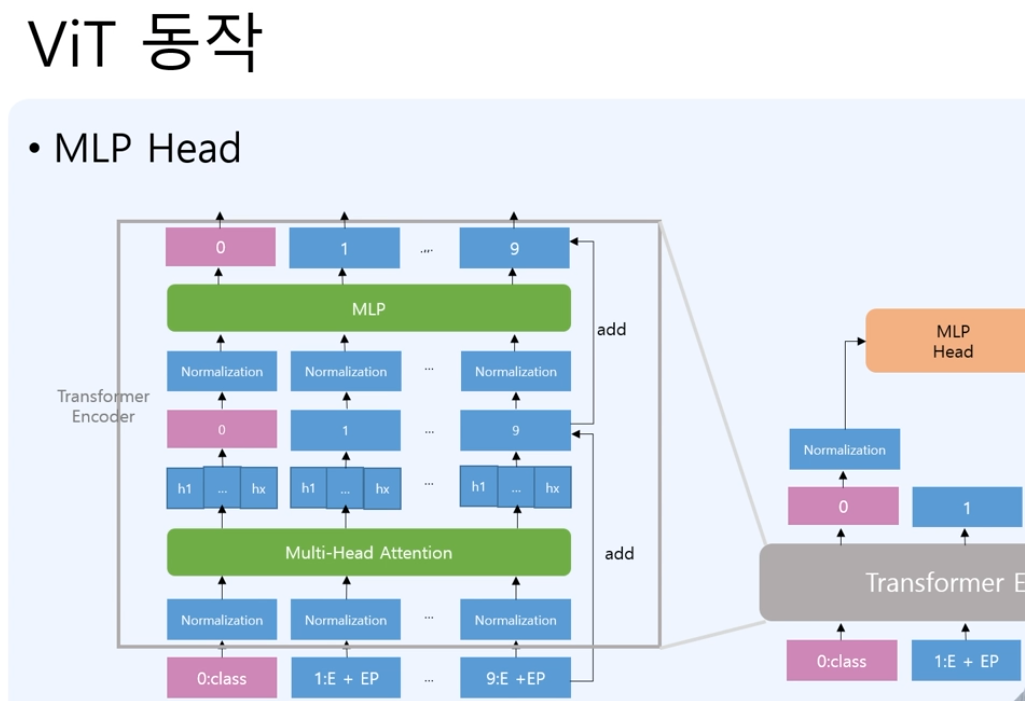
MLP Head에서는 class 토큰으로 나온 값을 normalization후에 class의 예측을 하는 것으로 진행하게 됨. 즉 patch 9개의 결과들을 사용하는 것이 아니라 0번 인덱스가 class의 예측으로 사용한 것이다.
