컴퓨터비전
1.harris detection

출처 https://blog.daum.net/trts1004/12109061
2021년 11월 18일
2.Scale-Invariant-Feature Transform(SIFT)
출처 한국과학기술원 전기 및 전자공학과 최성필 - Scale-Invariant-Feature Transform(SIFT) https://salkuma.files.wordpress.com/2014/04/sifteca095eba6ac.pdf - p16 findS
2021년 12월 9일
3.CNN to ViT

비전 훈련중에 transformer을 사용한 모델 입니다. Transformers for image recognition at scale ViT모델 사이즈나 크기에 비해 계산량이 적음.모델의 크기를 쉽게 Scale 할 수 있다.이미지를 어떻게 시퀀시로 만들 수 있을까?
2023년 12월 2일
4.Swin transformer V2
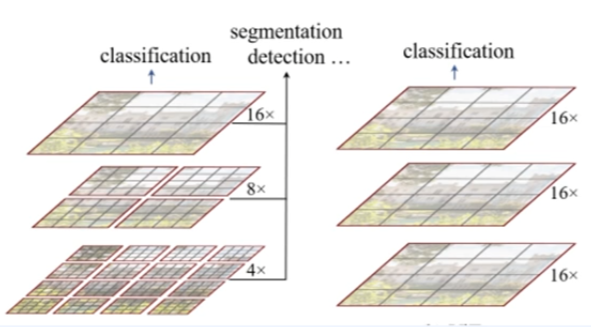
vit의 업그레이드 버전으로 생각하자. 연산량이 image 크기의 제곱에 비례함. (high resolution task를 수행하지 못함)계측정 구조가 아님 (Object Detection 못함, 백본의 역할(내부)어려움)연산량이 window 수에 선형적인 증가임. (
2023년 12월 17일