오늘은 ML 프로젝트 2조
데이콘 대회에서, 상위 23% 결과를 공유 드립니다.
1. 데이터 설명
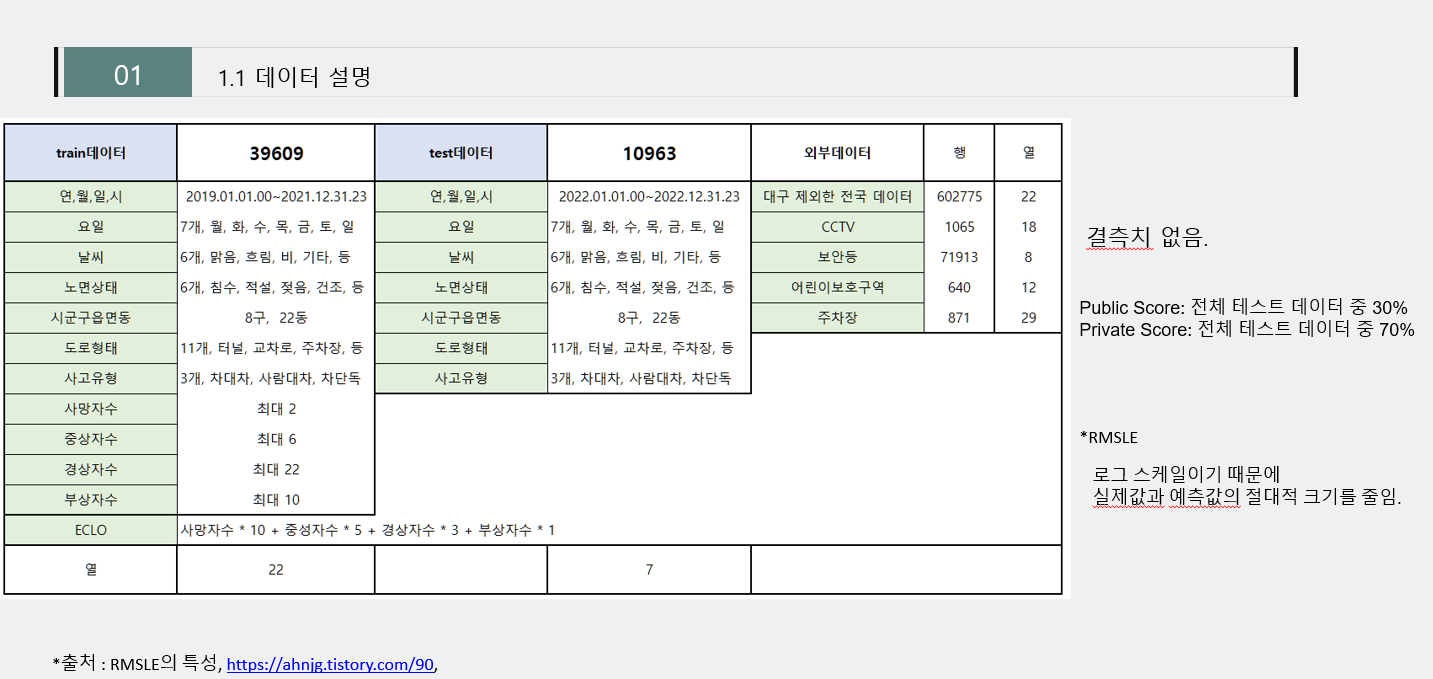
-
다음과 같이, train데이터는 3만9천여개, test데이터는 1만9백개의 데이터로 이루어져 있고, 각각 열은 22, 7개를 가지고 있습니다.
-
이 대회에서는 train데이터의 있는 ECLO, 즉 심각도 예측을 잘하는 것이 목표입니다.
-
또한, 평가 metric같은 경우는 RMSLE로, 로그 스케일로 이루어져 실제값과 예측값의 절대적인 차이의 크기를 줄인다는 특징이 있습니다. 즉, 심각도 예측의 값이 실제값과 차이가 적어야 하므로 가장 좋은 성능은 낮을때 좋은 값이다.
2. 데이터의 이해
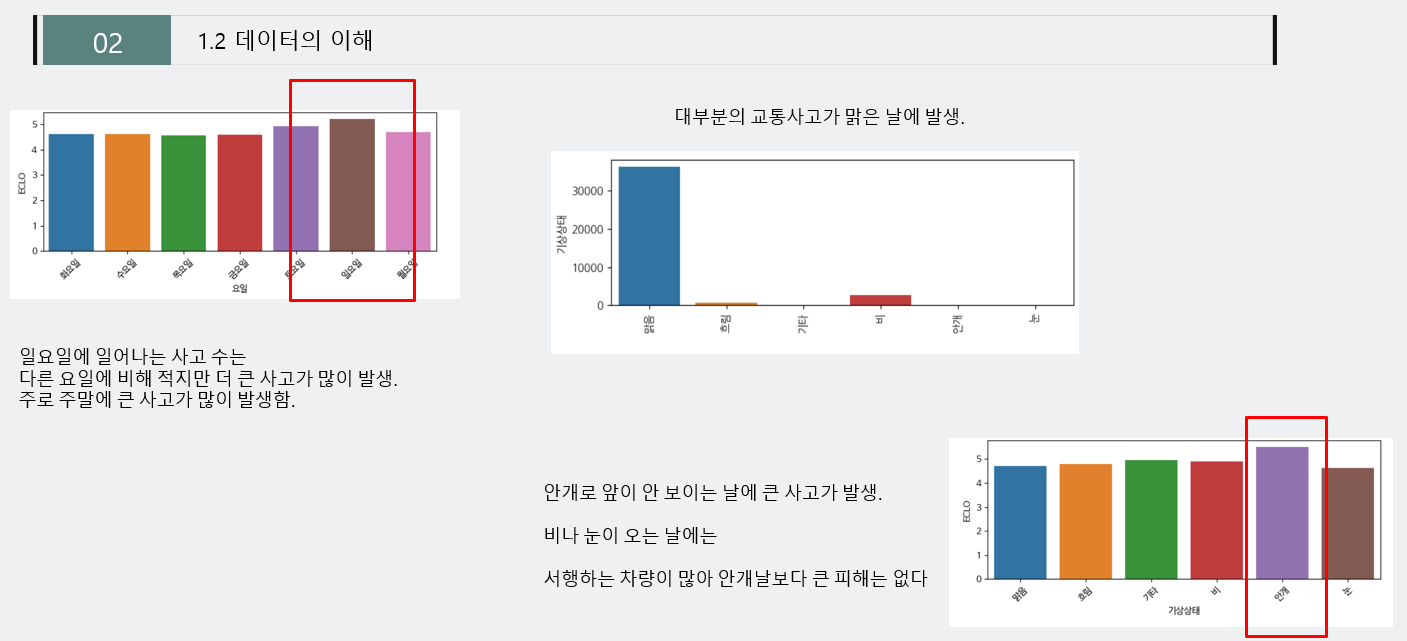
- 주어진 데이터를 이해하기 위해서, 먼저 EDA를 진행해보았습니다.
-데이터는 주말에 비교적 큰 사고가 많이 발생하며, 대부분의 교통사고가 맑은날에 주로 발생하고, 또한 안개날에 비교적 높은 사고(ECLO)가 큰 경향이 보임을 확인할 수 있습니다.
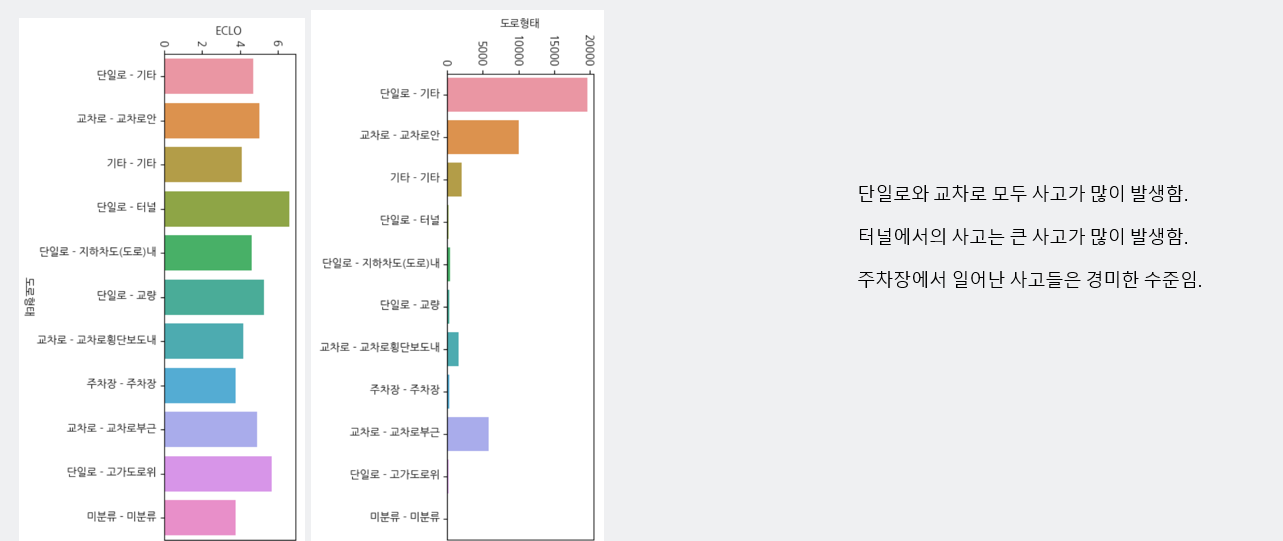
- 또한, 단일로와 교차로 모두 사고가 많이 발생하며, 터널에서의 사고는 ECLO가 높다는 특징을 가지고 있습니다. 반대로 주차장의 경우는 경미한 수준으로 보입니다.

- 날씨의 영향을 보기위해, 도로가 건조할 때, 대부분의 사고가 발생하고, 침수의 발생건수는 적지만 심각도는 높다는 특징을 보임.
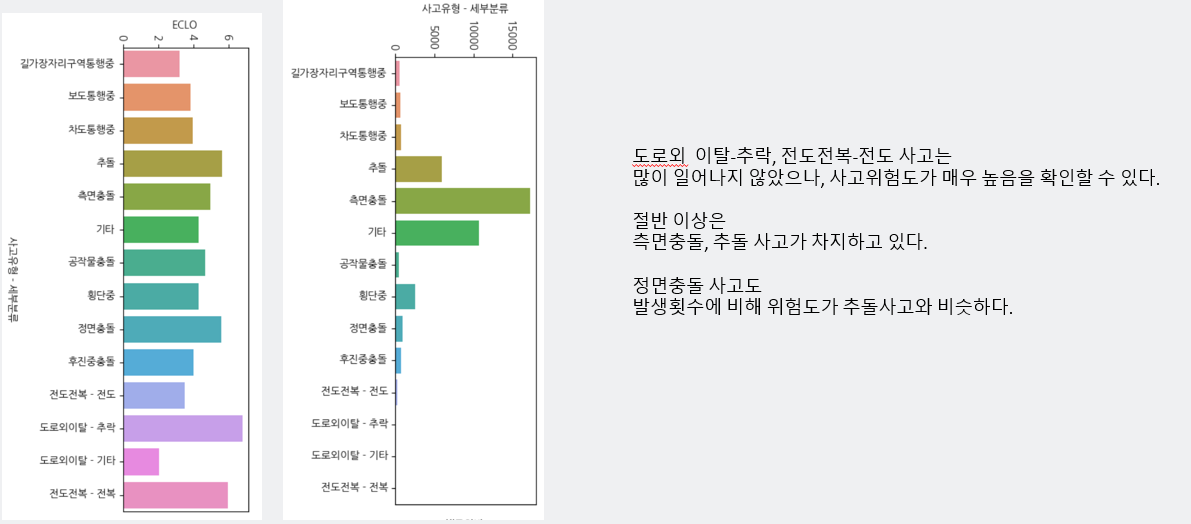
- 도로외 이탈-추락, 전도전복-전도의 사고발생 건수는 적지만, ECLO가 높으며, 측면충돌과 추돌사고가 사고 발생건수의 대부분을 차지하고 있습니다. 추가로 정면 추돌사고도 발생횟수에 비해 위험도는 추돌사고 비슷한 경향을 보입니다.

- 또한, 안전운전 불이행으로 인한 사고가 많이 이뤄지며, 신호위반과 중앙선 침범의 사고는 ECLO(심각도)가 높다. 그리고 과속의 원인으로 ECLO가 높음을 알 수 있습니다.
3. 데이터 이해 정리
- 주로 주말에 큰 사고가 많이 발생함.
- 안개로 앞이 안 보이는 날에 큰 사고가 발생하며, 비나 눈이 오는 날에는 큰 피해가 적다.
- 단일로와 교차로에서 사고 발생이 많고, 터널에서는 큰 사고가 발생함. 반대로 주차장에서 일어난 사고들은 경미함.
- 대부분의 사고가 도로가 건조할 때 발생하며, 침수시에는 사고위험도(ECLO)가 높음.
- 측면충돌, 추돌 사고가 사고 발생의 대부분을 차지하고, 발생 건수는 적지만 도로외 이탈-추락, 전도전복-전도 사고, 정면충돌 사고는 사고위험도(ECLO)가 높음.
- 대부분이 안전운전 불이행 사고로 발생, 사고 위험도는 신호위반, 중앙선 침범, 과속의 원인이 주로 있었음.
4. 외부 데이터의 이해
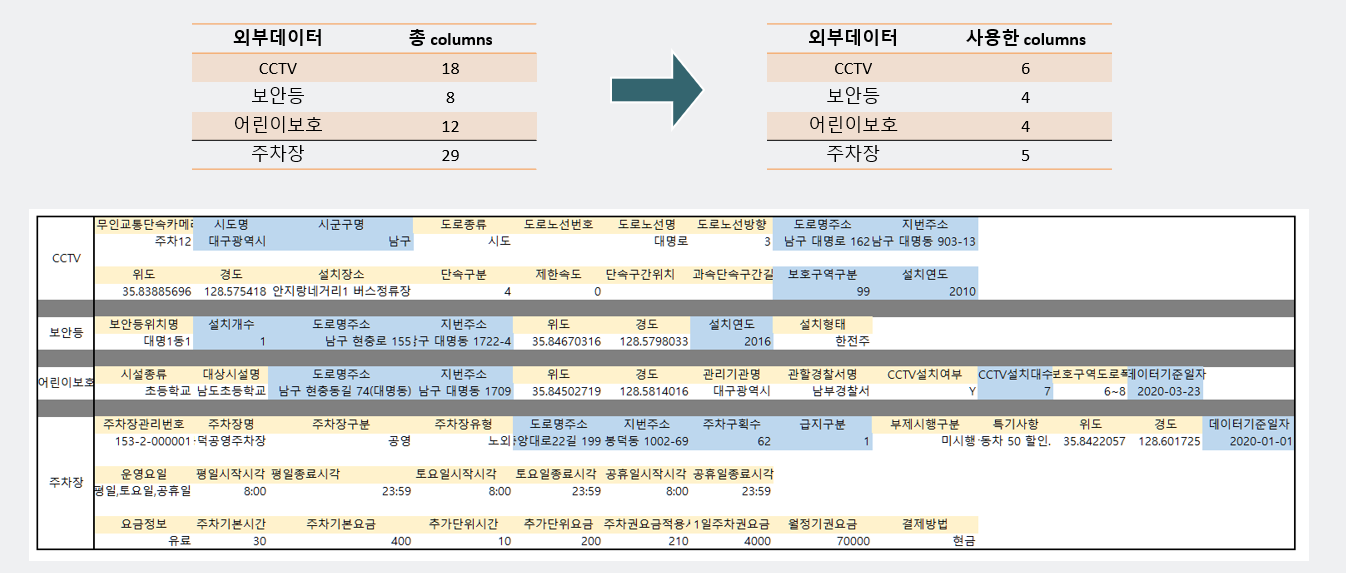
- 외부 데이터는, CCTV, 보안등, 어린이보호, 주차장 등의 데이터가 있으며, 이때 총 columns들 중에 사용되어진 columns는 색칠되어진 곳을 사용하였다.
5. 사용한 모델 - XGBoost, LightGBM, CatBoost, MLP
-
train데이터를 기준으로, Base모델은 Random Forest(RF)의 결과로 Public점수 기준으로 0.4399를 기록한다.
-
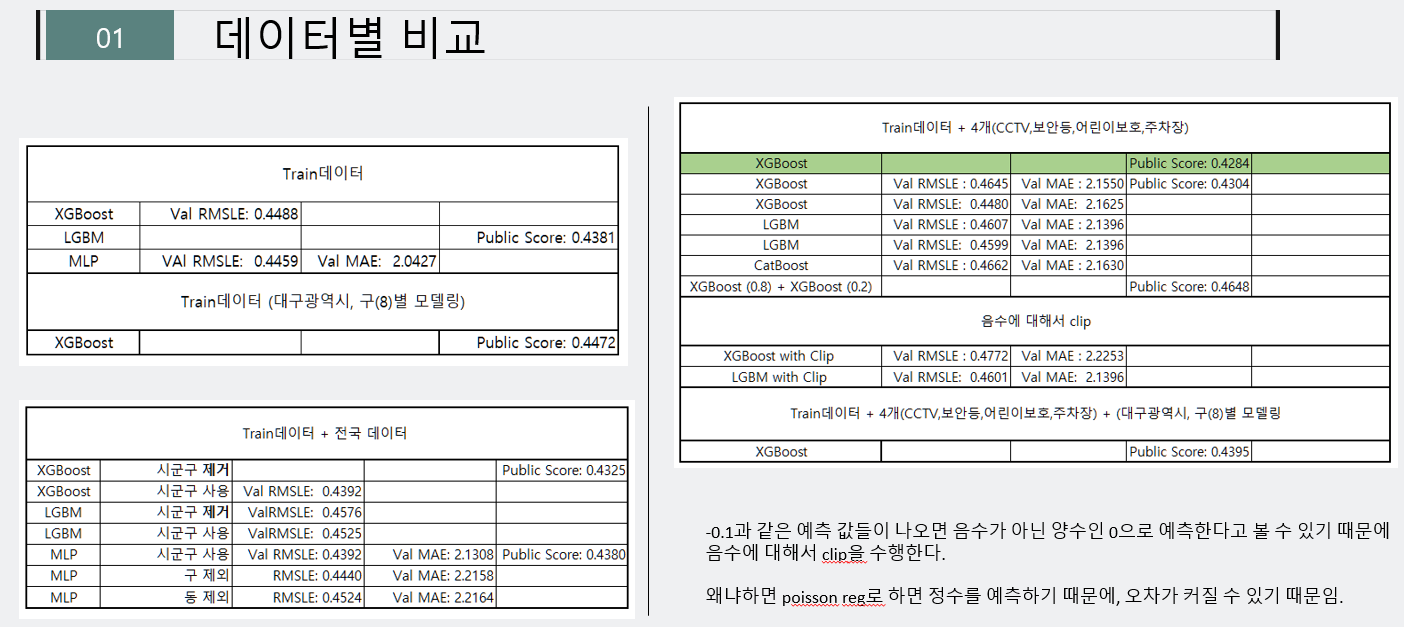
먼저 데이터별, 모델의 결과들을 정리한 표를 보면, train데이터 + 4개의 외부데이터(CCTV, 보안등, 어린이보호, 주차장)의 결과가 Public기준 0.4284이다. 이는 2조의 가장 Best 점수이다.
-
사용된 데이터별 결과들에서 모델별 영향이 큰 영향을 미치지 못하는 것을 파악하고, XGBoost의 값이 가장 좋은 성능을 야기했다.

- 혹시나, 사망자, 중상자, 경상자, 부상자별 XGBoost의 결과와 RF 모델을 이용한 값으로 측정해보았지만, Train에서는 잘 학습되었지만, Public점수는 0.6803으로 과적합된 것을 확인할 수 있었다.
5.1 전처리 데이터의 이용
- 모델학습시에 전처리된 데이터들을 각각 학습하여 어떤 결과를 미치지는 지 확인하기 위해 여러 실험을 돌려 결과를 확인한다.
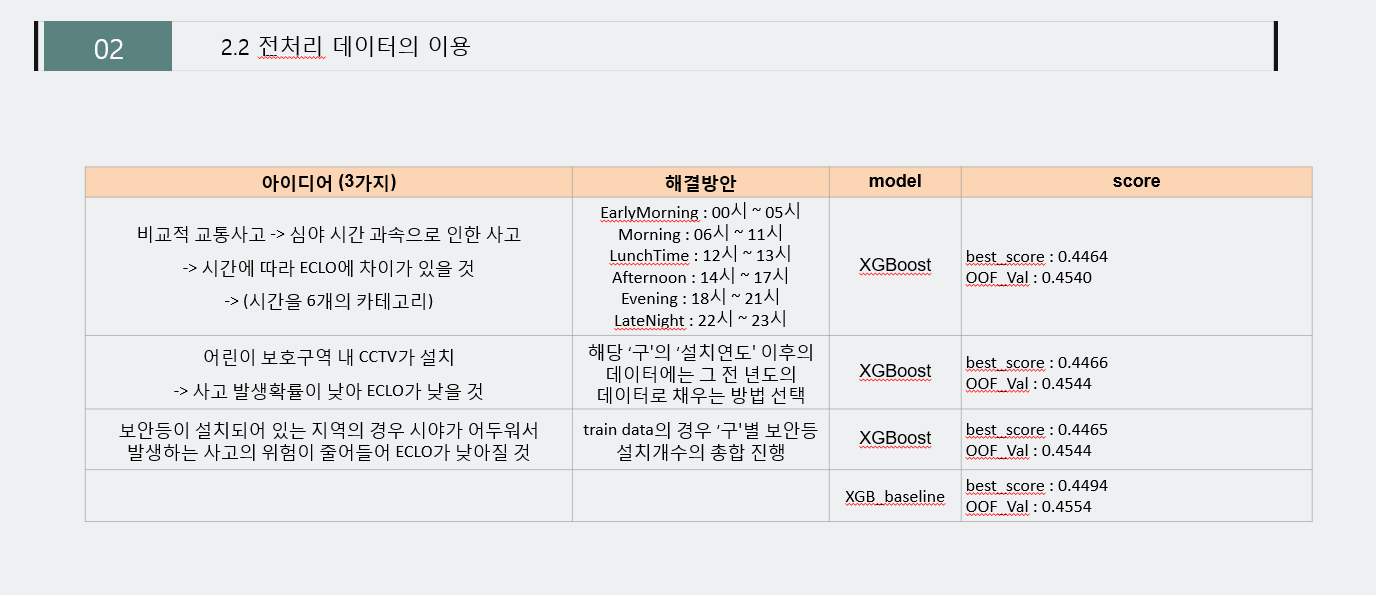
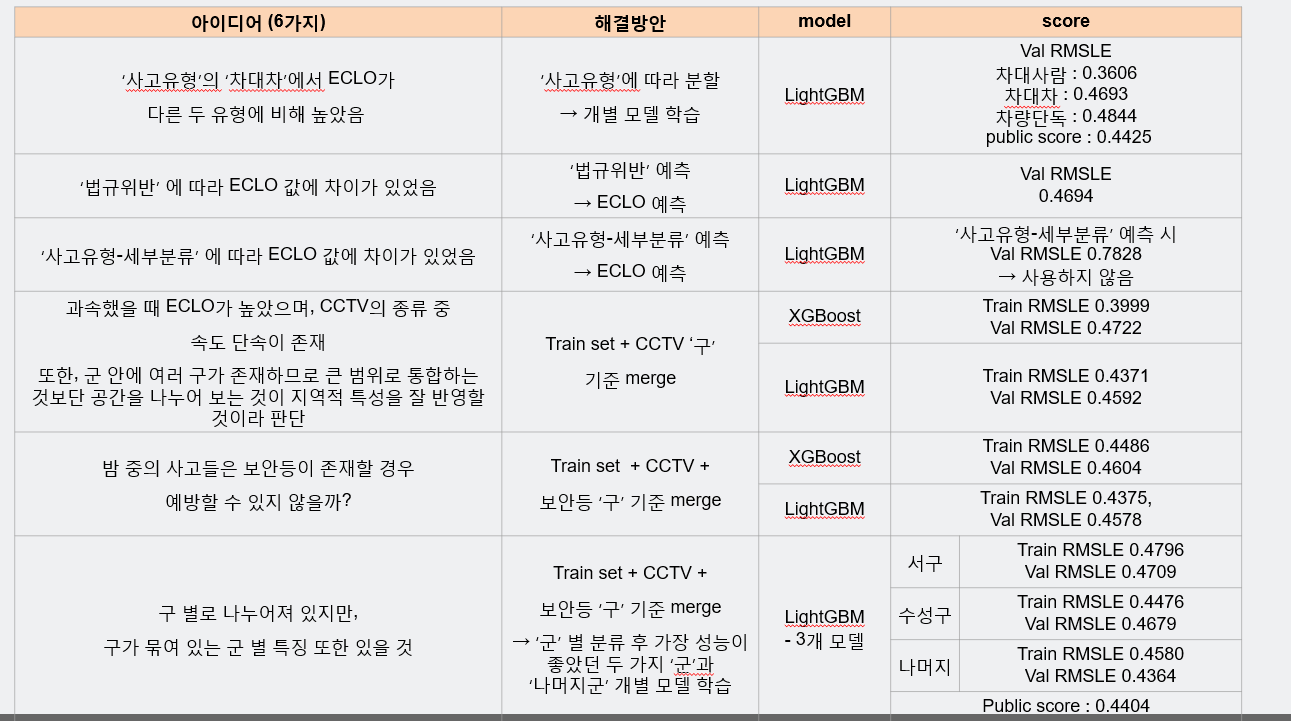
- 위의 결과처럼, 모델 학습시에 사용된 9가지의 아이디어로도 Public 점수의 영향이 뚜렷하게 나오는 값을 확인할 수 없었다.
5.2 클러스터링의 활용
- K-Means, DBSCAN, Hierarchical Cluster Analysis, HDBSCAN을 수행 후 가장 적합해 보이는 클러스터링을 설정
- 개별 클러스터마다 전용 예측 모델을 학습.
- 개별 예측 모델로 예측한 결과를 모아서 최종적으로 테스트 데이터에 대해서 예측
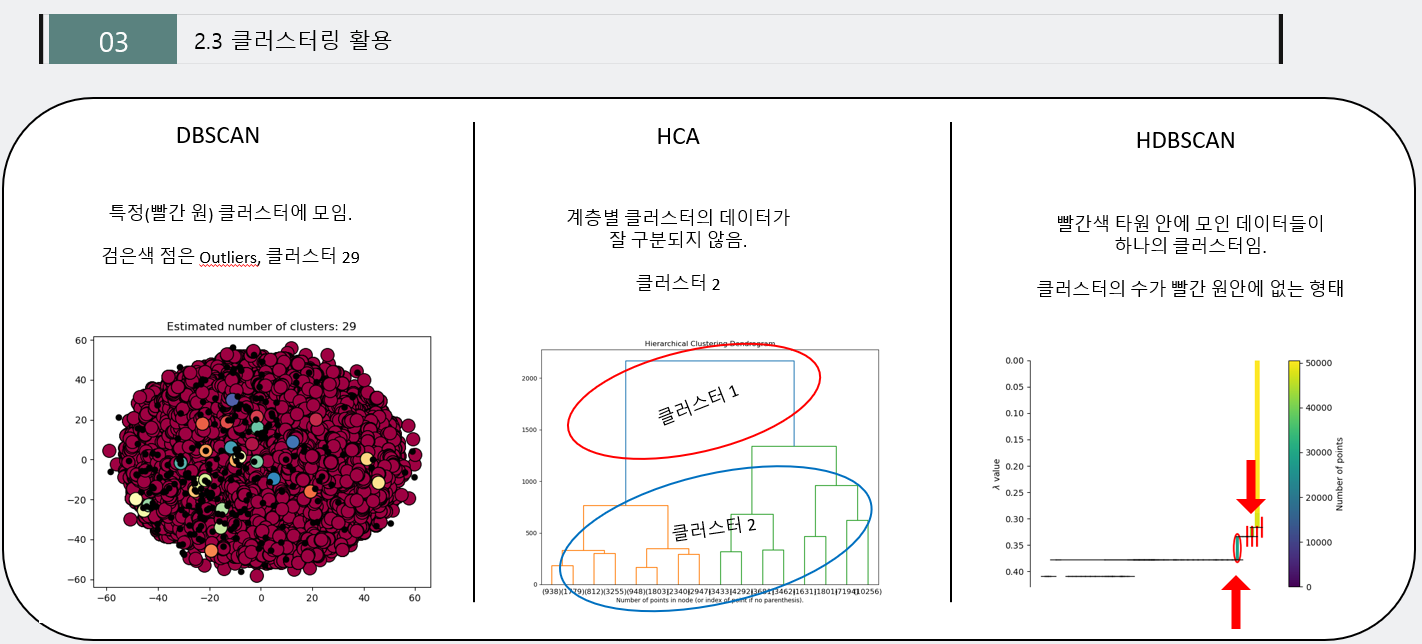
- DBSCAN의 경우, Train데이터에서 특정원(빨간) 클러스터에 집중되어져 있기에, 사용할 수 없었으며,
- HCA의 경우, 클러스터의 개수가 2개의 값으로 데이터을 잘 구분할 수 없었다.
- HDBSCAN의 경우는, 빨간 화살표에 있는 타원의 원이 하나의 클러스터를 의미하는데, 이 경우에도 클러스터가 잘 구분되어져 있지 않았다.
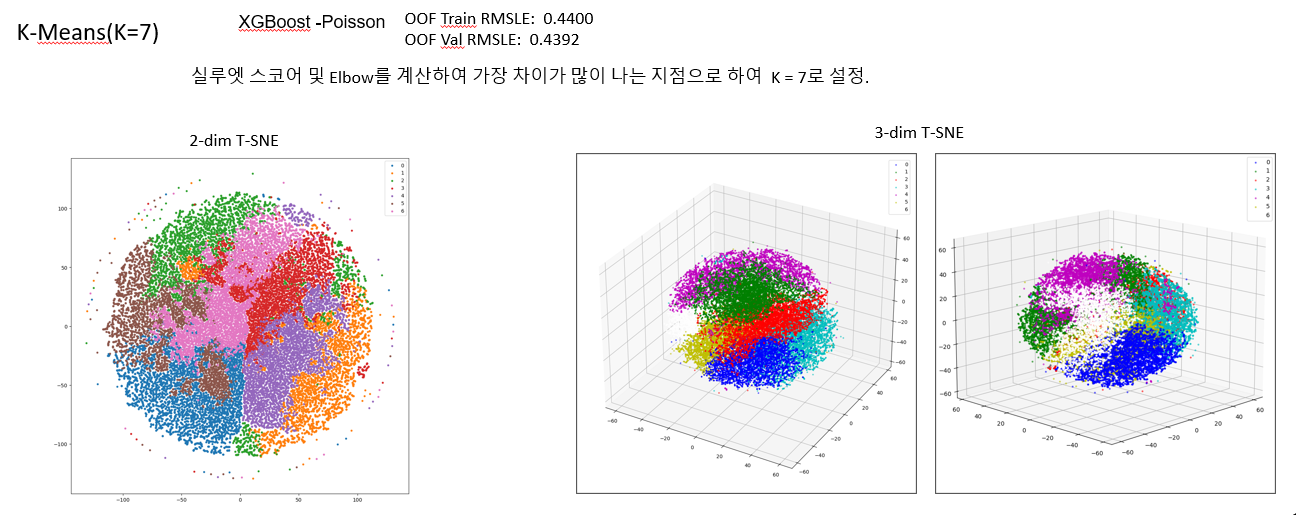
- 마지막, K-Means(K=7)의 경우에서 실루엣 스코어와 ELBOW를 계산하여 가장 차이가 많이 나는 지점을 설정하여, 시각화 결과에서는 데이터를 잘 구분하기에, 클러스터링은 K-means를 이용하였다. 그 결과 RMSLE의 값이 0.4392로 기존과 뚜렷한 차이를 볼 수 없었다는 점을 확인할 수 있었다.
6. 결론

- 시간적 한계로(7일)간의 데이콘 대회를 마무리 하였다. 또한 진행하면서, MAE의 metric으로 변경하여, ECLO를 예측시에 가장 두드러진 변화를 확인하는 것이 필요하였고, 진행사항을 중간에 정리하는 것이 요구되었다.
- 하지만, 우리는 전처리 과정에서 서로 통일성을 유지하도록 하고, 아이디어를 도출하기 위한 시간을 각자 주어지고, 모르는 부분은 서로 번갈아 확인하였다.

- 상위1위, 2위의 모델에서는 보통 공공 데이터의 추가나, 학습에 영향받는 Columns를 추가하여 학습하는 것이 좋은 결과를 보여졌다. 이를 기반으로 다음 대회에서 반영할 수 있도록 하겠다.

행복을 찾아서(크리스 가드너)