upstageAI_패스트캠퍼스
1.upStageAI/패캠(기술통계)
1일차에 해당하는 패스트캠퍼스 AI업스테이지의 내용을 공부하기 위하여공부한 자료를 나중에 다시 보기 위하여 저 혹은 다음에 공부하실 분들과 공유하여 드립니다. 저작권의 문제 때문에, 사진과 자세한 내용 보다는 제가 배우고 느낀 감정, 혹은 나중에 공부할 때, 알아볼 수
2.upStageAI/패캠(기술통계)
2일차 얘기 시작.
3.upStageAI/패캠(기술통계)
3일차 이야기
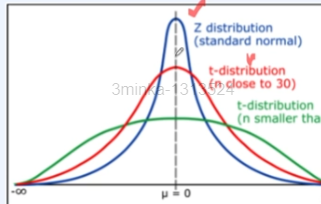
4.upStageAI/패캠(기술통계)

4일차 이야기선형회귀란?회귀 - 평균으로의 회귀(통계적), 머신러닝에서는 예측에 숫자는 회귀, 카테고리는 분류.선형 - 직선의 선형성.<일반화 선형모형>y = ax + b로지스틱 함수<단순선형회귀>데이터들을 잘 설명하는 직선 설명변수 x 1개, 종속변수 y
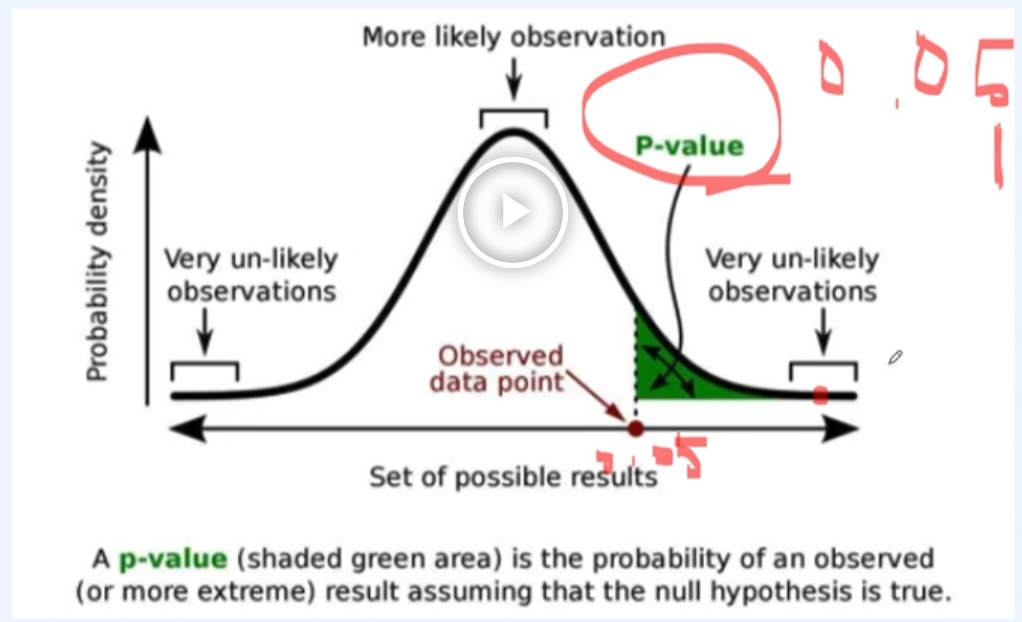
5.upStageAI/패캠(기술통계)
5일차 :: 통계와 머신러닝 23/10/17 upStageAI/패캠(기술통계)통계가정 검토에 엄격하며, 소량의 데이터를 데이터 분리하지 않음. 추론 성능에 강함.머신러닝성능에 더 초점을 두며, 대량의 데이터를 split해서 사용하며 예측 성능이 강력하다.AutoML문제
6.2022년 매출 데이터 분석 : EDA 프로젝트 회고
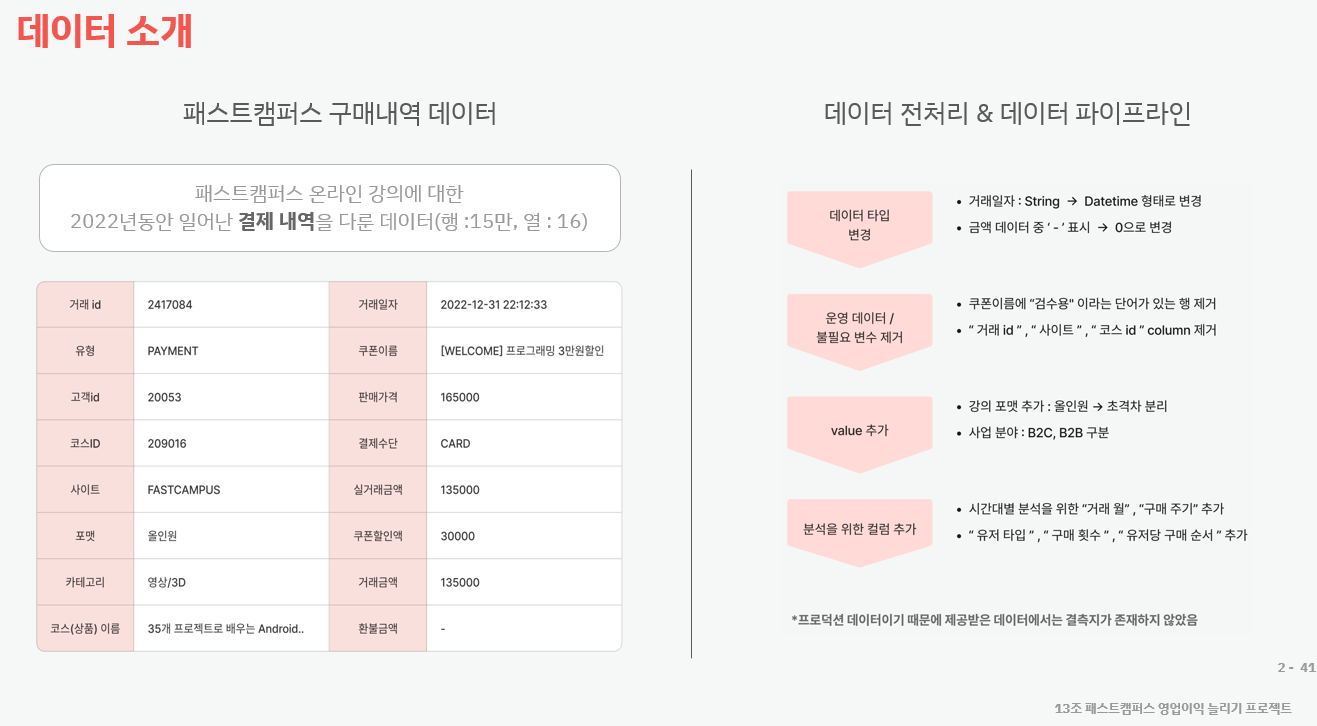
본 프로젝트는 2023 AI업스테이지 & FastCampus AI LAB 과정 중에 데이터 EDA 프로젝트로, 데이터의 설명과 함께, 분석 과정을 담았습니다.
7.ML_프로젝트_2조
오늘은 ML 프로젝트 2조데이콘 - 대구 교통사고 피해, 인명피해 심각도 예측데이콘 대회에서, 상위 23% 결과를 공유 드립니다. 다음과 같이, train데이터는 3만9천여개, test데이터는 1만9백개의 데이터로 이루어져 있고, 각각 열은 22, 7개를 가지고 있습니
8.ML-300제
오늘은 300제 문제 풀면서 회귀 관련 문제들을 정리하겠습니다. 스크래핑 된 dirty 데이터 클리닝다양한 종류의 데이터 정규화 사이킷런 기반의 모델 학습 방법 습득XGBoost, LightGBM 모델 학습 모델 평가 및 시각화 26개의 컬럼(head, info, de
9.upStage_ML_project
학습 데이터의 기간은 2007년 1월 1일부터 2023년 6월 30일까지 1,118,822(약 120만개)평가 데이터는 학습 데이터기간 이후 3개월인 2023년 7월 1일부터 2023년 9월 26일까지의 정보로 구성 (9272개)focus : 이상치 탐지와 보간법(결측
10.upstage_CV_정의_기술_활용사례
비전 : 시각적인 정보들의 집합시각으로 보이는 것을 숫자로 데이터화 하여 저장한 모든 것.시각정보 : 빨강R, 초록G, 파랑B(256, 0, 0), (0, 256, 0), (0, 0, 256)vision 데이터들에서 의미 있는 정보를 추출하고 이를 이해하는 것을 바탕으
11.upstage_CV_고전
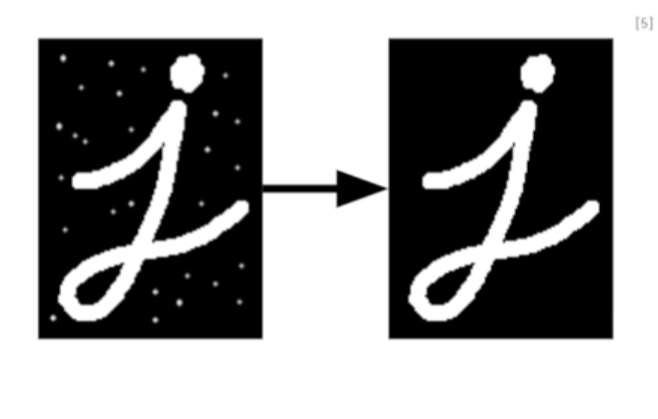
Preliminary - 고전 컴퓨터 비전 기초 이론 심화 예제
12.upstage_CV_모델구성
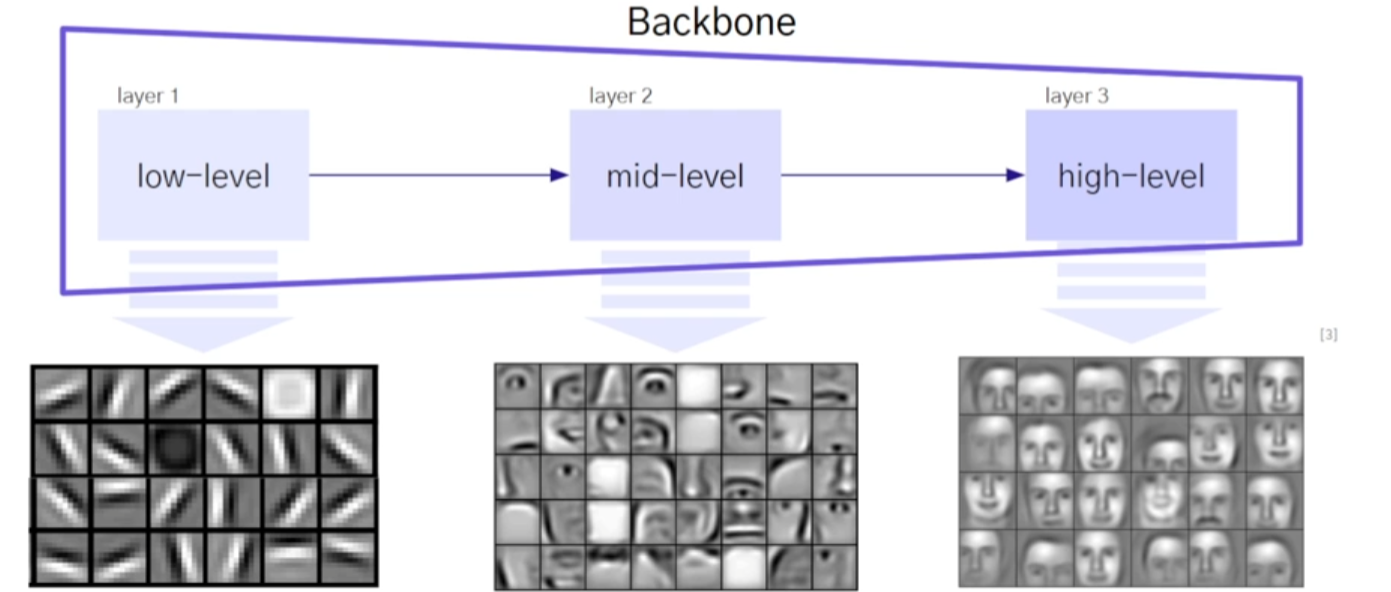
visual feature란?시각적 특징들로 눈으로 감지한 것으로 판단된 feature들컴퓨터 비전의 task를 해결할 때 필요한 이미지의 특성을 담고 있는 정보들을 지칭함.예시) 코끼리의 특징: 긴 코, 큰 귀, 회색빛 피부 이미지에서 중요한 특징을 추출함주어진 비전
13.upStage_CV_CNN
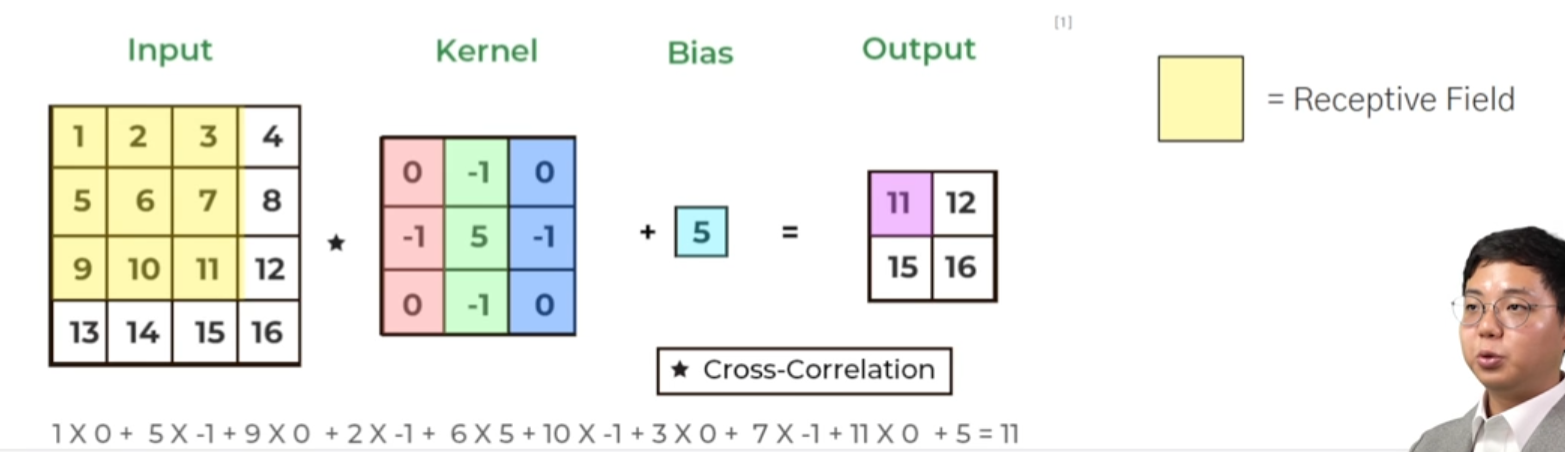
컨볼루션 레이어 : 컴퓨터 비전 task를 수행하는데 유용한 특징들을 학습Activation Func : 네트워크에 비선형성을 가해주는 역할Pooling layer : feat map에 spatial agg를 시켜준다.네트워크가 유용한 feature들을 학습할 수 있도
14.Document Type Classification 문서 타입 분류
Goal of the Competition \- Classification Problem 분류문제로, 17종의 문서타입을 분류하는 Task수행.TimelineJanuary 10, 2024 - Start DateFebruary 20, 2024 - Final s
15.[업스테이지] AI심화학습(Generation)
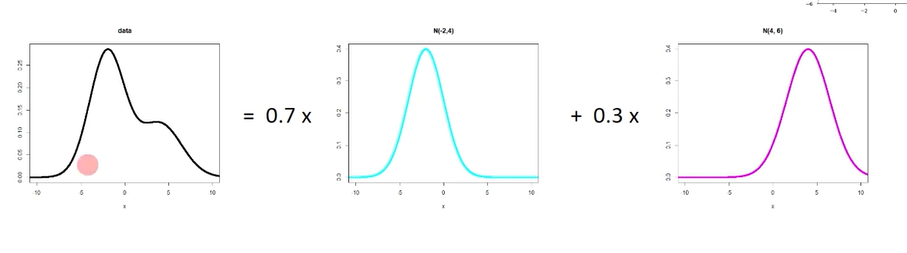
데이터는 저차원의 필수적인 정보로부터 생성 가능하다는 가정하에 분포를 학습. 확률 분포 추정(가우시안 혼합, 볼츠만, 심층, 자기회귀망)여러개의 가우시안 분포를 바꾸면, 주어진 데이터에 fitting 되도록 함. 신경망의 형태로, 특징추출과 비슷하며, 에너지가 낮을 수
16.Generation - 2
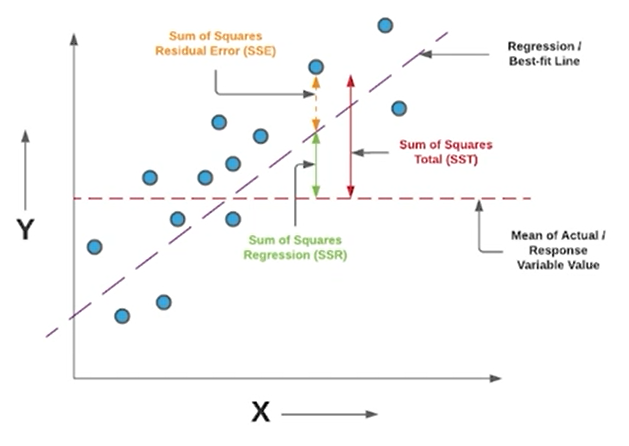
판별 모델의 종류정답(GT)가 존재하므로, 모델의 출력을 정답과 비교하기 용이범주형 데이터를 사용하는 경우 분류문제와 연속형 데이터는 회귀문제각 클레스별 데이터의 정확도 accuracy를 평가함. 각 클래스별 데이터가 불균형한 경우엔, 정확도만으로 평가하지 않고 정밀도
17.Generation - 3(오토인코더, VAE, VQVAE)
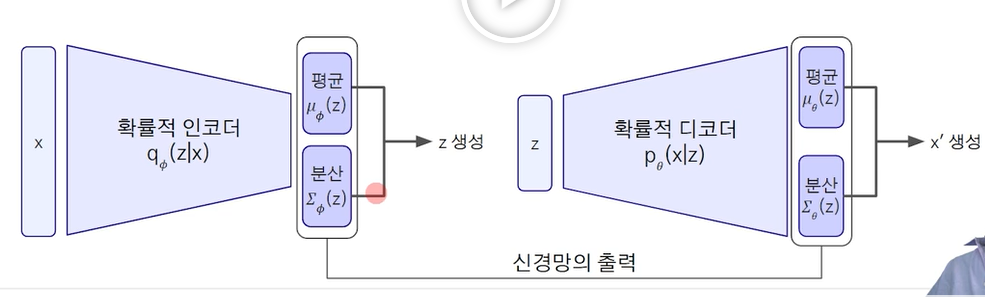
오토인코더는 새로운 데이터를 생성하기 보다는 비지도학습을 통한 특징추출을 하는 방법. 인코딩을 진행해준다. (용량 줄이기, 변환 해주기, 입력 데이터를 받아 N차원으로 데이터 변환후 입력 데이터와 동일한 차원으로 다시 복원하는 과정임.) N차원은 차원축소로 볼 수 있음
18.Generation - 4(GANs)
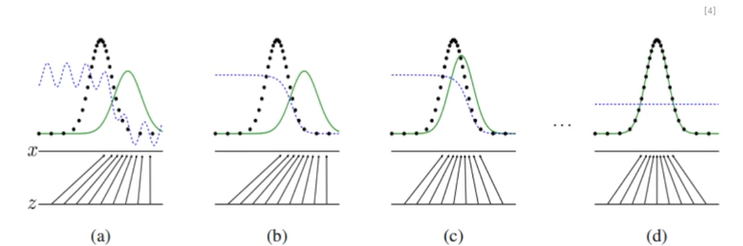
VAE의 생성방식 : 입력 분포를 근사하는 과정에서 규제을 주며 데이터를 생성GANs의 생성방식 : 생성된 데이터와 실제 데이터를 판별하고 속이는 과정을 거치며 생성 모델 개선데이터를 생성하는 생성모델과 데이터의 진위를 구별하는 판별모델생성모델 : 임의의 노이즈를 입력
19.Generation - 5(확산모델) DPM
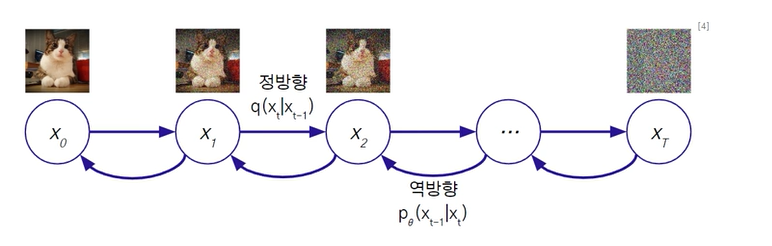
Diffusion Probabilistic Model확산 현상물질(픽셀값)이 섞이고 번져가다가 마지막에는 균일한 농도(노이즈)가 되는 현상임.확산현상을 시간에 따라 확률적 모델리으로, 마르코프 체인(미래는 과거가 아닌 현재에만 의존함)정방향확산 : 데이터 -> 노이즈
20.Natural Language Processing Basic-1
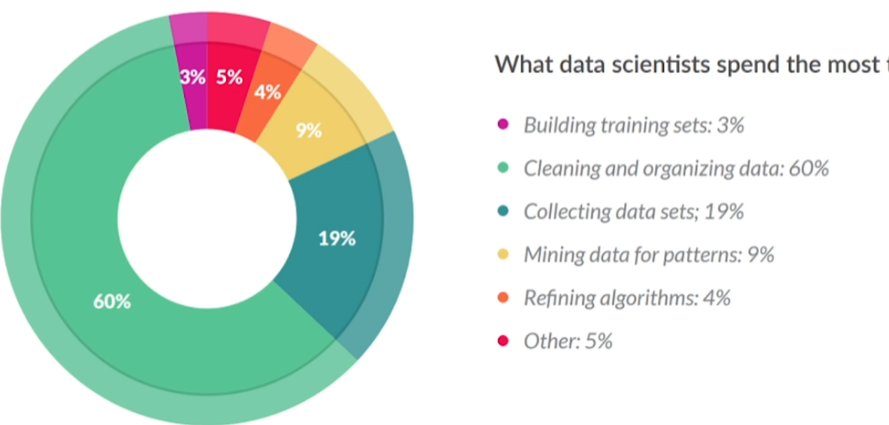
텍스트 전처리란 ?데이터 분석 단계(데이터 - 목표데이터 - 전처리된 데이터 - 변환된 데이터 - 패턴 - 지식)컴퓨터가 텍스트를 이해할 수 있도록 하는 방법.HTML 태그, 특수문자, 이모티콘정규표현식불용어(Stopword)어간추출(Stemming) 실질적의미만 남김