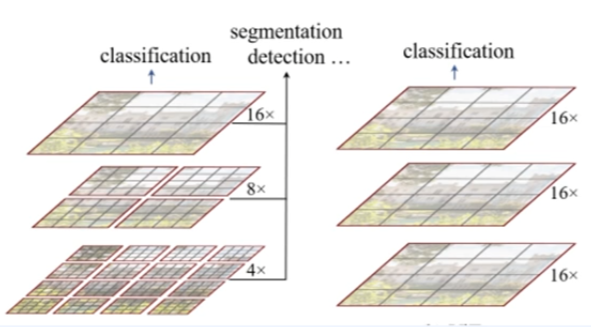
vit의 업그레이드 버전으로 생각하자.
vit
- 연산량이 image 크기의 제곱에 비례함. (high resolution task를 수행하지 못함)
- 계측정 구조가 아님 (Object Detection 못함, 백본의 역할(내부)어려움)
swin transformer
- 연산량이 window 수에 선형적인 증가임. (high resolutuon 수행함)
- 계측적 representation 수행함.(Object Detection, 백본의 역할 모두 가능)
1. patch 분할, 선형 embedding
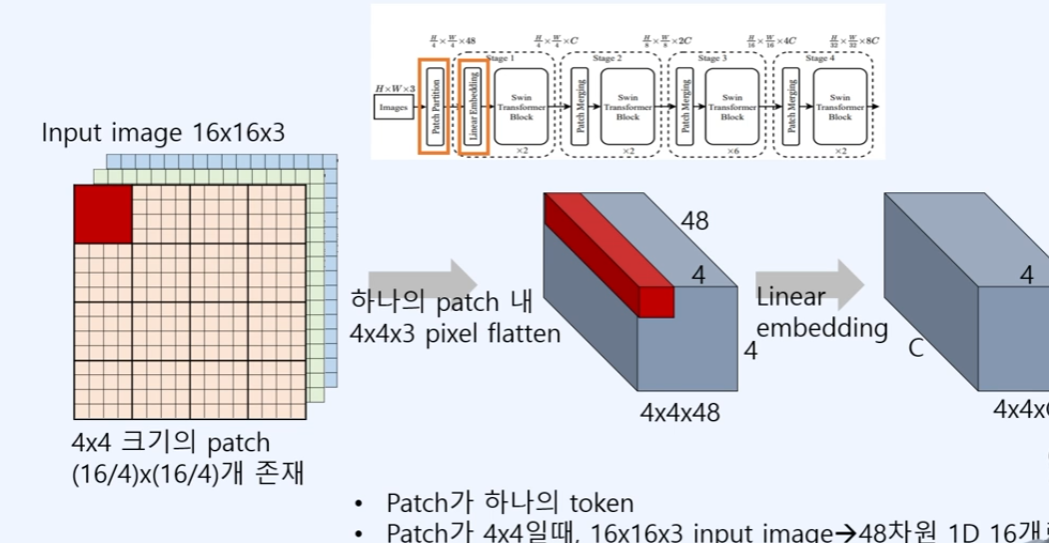
인풋 이미지가 16x16x3이 들어왔다고 가정하면, 하나의 patch크기를 4x4라고 하자.
지금 사진의 왼쪽처럼 16개의 patch가 존재하게 되고, 16개의 patch들을 fatten을 이용하며, 현재 빨강 patch1개을 1-d로 표현하게 되면, input이미지는 가운데 사진처럼 4x4x48의 벡터로 표현되게 된다.(이때 48은 RGB 각 16+16+16)
다음으로 서현 embedding으로 사영하여 4x4xC(채널)로 표현하게 된다. 현재 swin-transformer의 base에서 96을 이용하고 있다. 즉 linear embedding을 거치고 나온 4x4x96으로 되어진 결과이다.
2. patch Merging
다음으로, swin transformer에서는 2번, 3번, 4번 구조에서 patch merging을 진행한다.
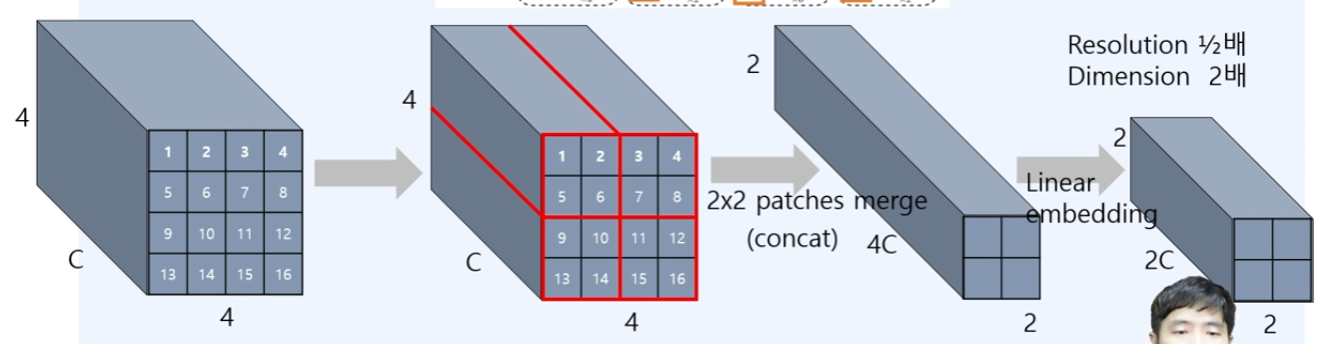
일단 입력으로, 방금 liner embedding으로 인한 4x4x96(C)의 벡터들을, 2x2 patch를 이용하여 merge(concat 4C == C + C + C + C)를 진행하게 된다. 즉 1,2,5,6에 해당하는 4x4xC의 값들을 merge 하게 되어 2x2x4C가 되는 것이다.
다음으로 다시 linear embedding을 사영하여서 4C -> 2C로 한다.
최종적으로는 2x2x2C가 되는 벡터로(Resolutuon 1/2배, 차원은 2배) 이 뜻은, CNN에서 feature map에서 2배 늘리면, channel수를 2배로 늘리게 된 것으로 유사하다고 이해한다.
Transformer Block
Window-transformer block이라고 얘기함.
2개의 연속된 transformer로 구성되어져 있음. Two swin transformer
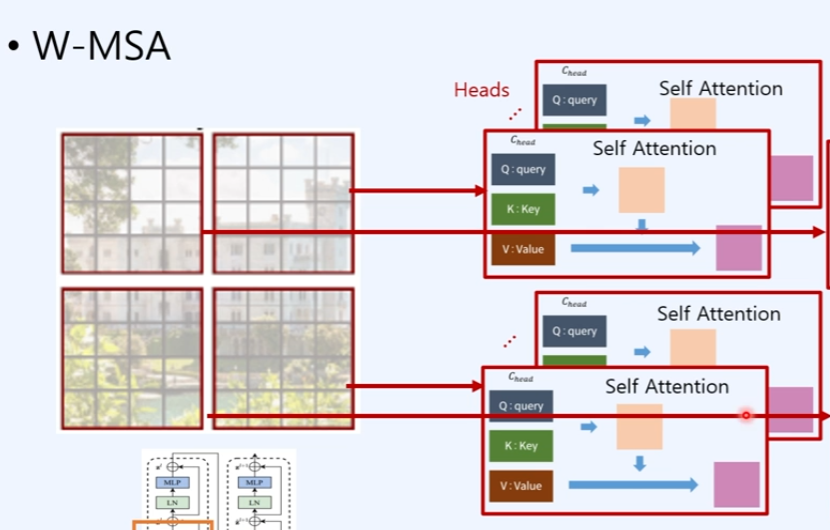
1. 앞쪽(왼쪽)은 인코더 부분의 W-MSA는 self-attention
-
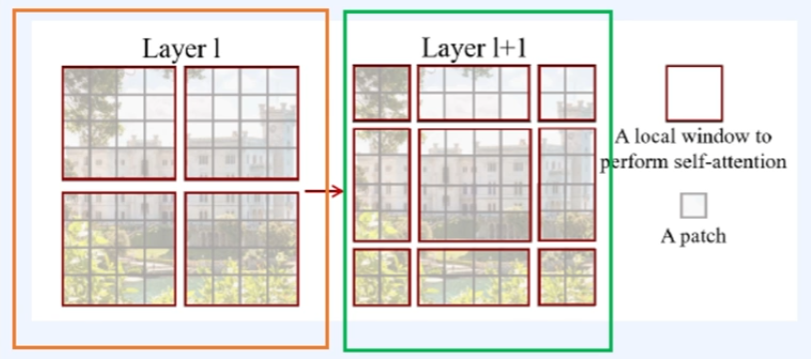
patch내에 해당하는 image들을 여러개의 window(개별적)으로 나눠서 window안에서만 self-attention을 진행하는 것임.
-
local window의 개수만큼 self-attention이 증가한다고 볼 수 있음.
-- 추가로, 같은 window 즉 같은 위치에만 self-attention으로 다른 곳에는 영향을 주는 것인지는 확인할 수 없음. (이를 해결하기 위해 SW-MSA)
-
4개의 window에서 4개의 self 어탠션이 독립적으로 head만큼 계산이된다.
-
어탠션 계산은 버전 1에서는 기존과 같지만, 버전 2에서는 다르다. --> 설명 밑에서 진행.
2. 뒤쪽(오른쪽)은 SW-MSA, shift window self-attention
-
기존의 W-MSA의 같은 window에만 self-attention의 영향이 가기에, 다른 window간에도 영향이 갈 수 있도록 보완해준다.
-
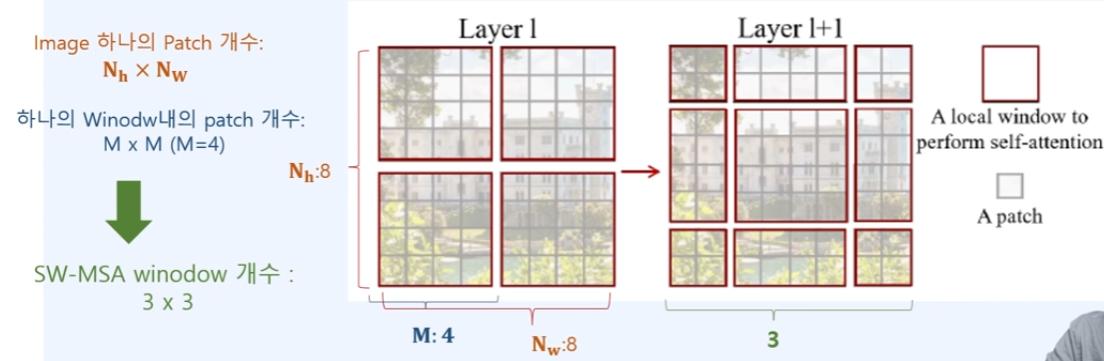
SW-MSA실행시에 Window 개수는 : 증가함( (()+1) * (() + 1))
-
ex) 하나의 image에 patch의 수가 8x8이고, 하나의 window에 patch의 수가 4x4. 이라면, SW-MSA의 Window의 수는 3x3으로 된다.
-
추가, window의 수가 증가하면, 계산량이 증가하는데, 이를 cyclic shift와 attention mask를 통해서 W-MSA와 동일한 window의 개수를 사용하게 된다. 즉 W-MSA와 동일한 계산량으로 한다.
1. cyclic shift
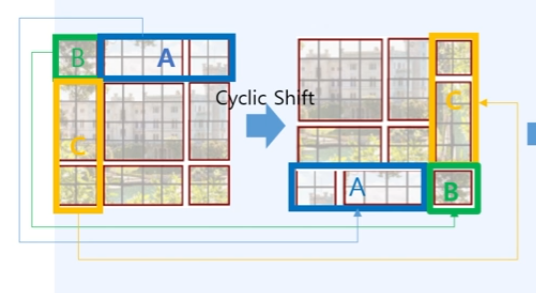
- 3x3 window를 A,B,C에 해당했던 Window들을 sifht를 진행하여 변경함.
2. attention mask
-
cyclic shift를 진행하고서, 같은 내의 window A,B,C는 서로 이웃임에도 서로 이미지내에 영향이없기에 attention을 바로 진행하게 된다면 서로 연관이 없는 이미지가 서로 영향을 주기 때문에, 서로 연관하지 않도록 MASK를 진행하고서, 서로 연관이 없는 부분은 self-attention이 되지 않도록 막아줌.
-
추가로, 다음 swin transformer block에서도 사용할 수 있도록 reverse shift도 진행한다.
swin transformer block V2
기존의 v1에서는 self-attention 계산이 동일하지만, v2에서는 다르게 계산이 된다.
이는 기존의 의 방식에서 scaled Cosine를 반영하도록 한 것이다.
log-spaced CPB
- bias로 더해주는 것으로, log스케일로 변환하여서 기존v1에서 해상도가 커지게 되며, 상대좌표가 커지게 되는 것을 막아주기 위해 진행함.
relative coordinates 상대좌표
-
window 수 3이라 가정하면, x축과 y축의 상대좌표를 구함. x축 기준 아래로 내려가면 -1, 위로 올라가면 +1 // y축으로는 오른쪽 가면 -1, 왼쪽으로가면 +1이 된다.
-
구해진 상대좌표를 log scaled 진행한다.

-
추가로 Continous relative position bias -> MLP
-
Architecture의 하이퍼 파라미터는 실습시, C=96, layer는 2,2,6,2 이지만 사실 layer는 1,1,3,1임 왜냐하면 swin transformer가 2개(W-MSA, SW-MSA)때문이다.
