컴퓨터 비전 모델 구조 이해하기
visual feature란?
- 시각적 특징들로 눈으로 감지한 것으로 판단된 feature들
- 컴퓨터 비전의 task를 해결할 때 필요한 이미지의 특성을 담고 있는 정보들을 지칭함.
예시) 코끼리의 특징:
- 긴 코, 큰 귀, 회색빛 피부
Backbone의 역할
- 이미지에서 중요한 특징을 추출함
- 주어진 비전 task를 수행할 수 있는 압축된 visual feature를 산출함
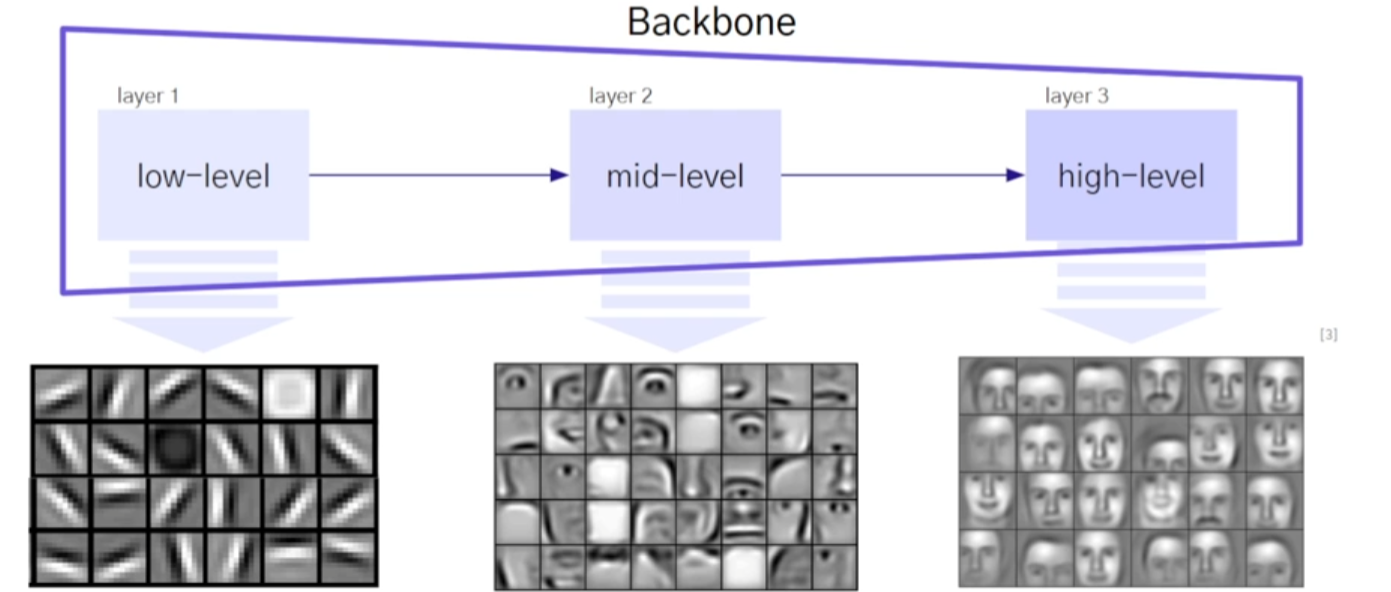
1. 구조
- layer가 길어질수록 -ex 3layer)
하위(맨처음 layer)들은 low-level(픽셀의 선) - 1layer
중간(중간 layer)들은 mid-level(사람의 눈, 귀, 코) - 2layer
상위(마지막 layer)들은 high-level(사람 얼굴의 윤곽전체) - 3layer
모델 구성
Decoder의 역할
-
모델의 쓰임새에 따라 다양한 task들을 decoder를 통해서 task의 출력 형태를 만드는 과정임
-
이미지에 있는 물체는 무엇인지?(분류), 위치를 표시하기 위한(탐지), 특정 물체의 픽셀을 따로 색칠하기(segmentation)
Encoder의 역할
- Encoder는 backbone에서 나온것을 다시 가공하여 decoder에 들어감.
Decoder의 역할
image - backbone - decoder
1. 모델의 전체 구조
2. Task에 따른 decoder 결과
분류
decoder에서 각 클래스의 어떤 클래스가 가장 높은지를 나타내면됨.
-
fc + softmax 로 이루어짐
-
B = batch size
CxWxH 만큼의 벡터가 있는 것임 -
FC = (BxC) (BxC) (Bx # of class) -> Softmax
탐지
강아지의 위츠를 박스로, 클래스별로 확률을 출력해주는 역할
- x1,y1,x2,y2, #of class을 출력해주면 됨.
Segmentation
강아지 혹은 고양이에 해당하는 영역을 픽셀 단위로 출력해주는 역할임.
최종
Backbone은 입력 이미지에서 유의미한 feature를 추출한 뒤 압축하는 역할임. 태스크 종류가 다르더라도 동일한 backbone을 사용할 수 있음

행복을 찾아서(크리스 가드너)