
212. Word Search II
문제링크: https://leetcode.com/problems/word-search-ii/
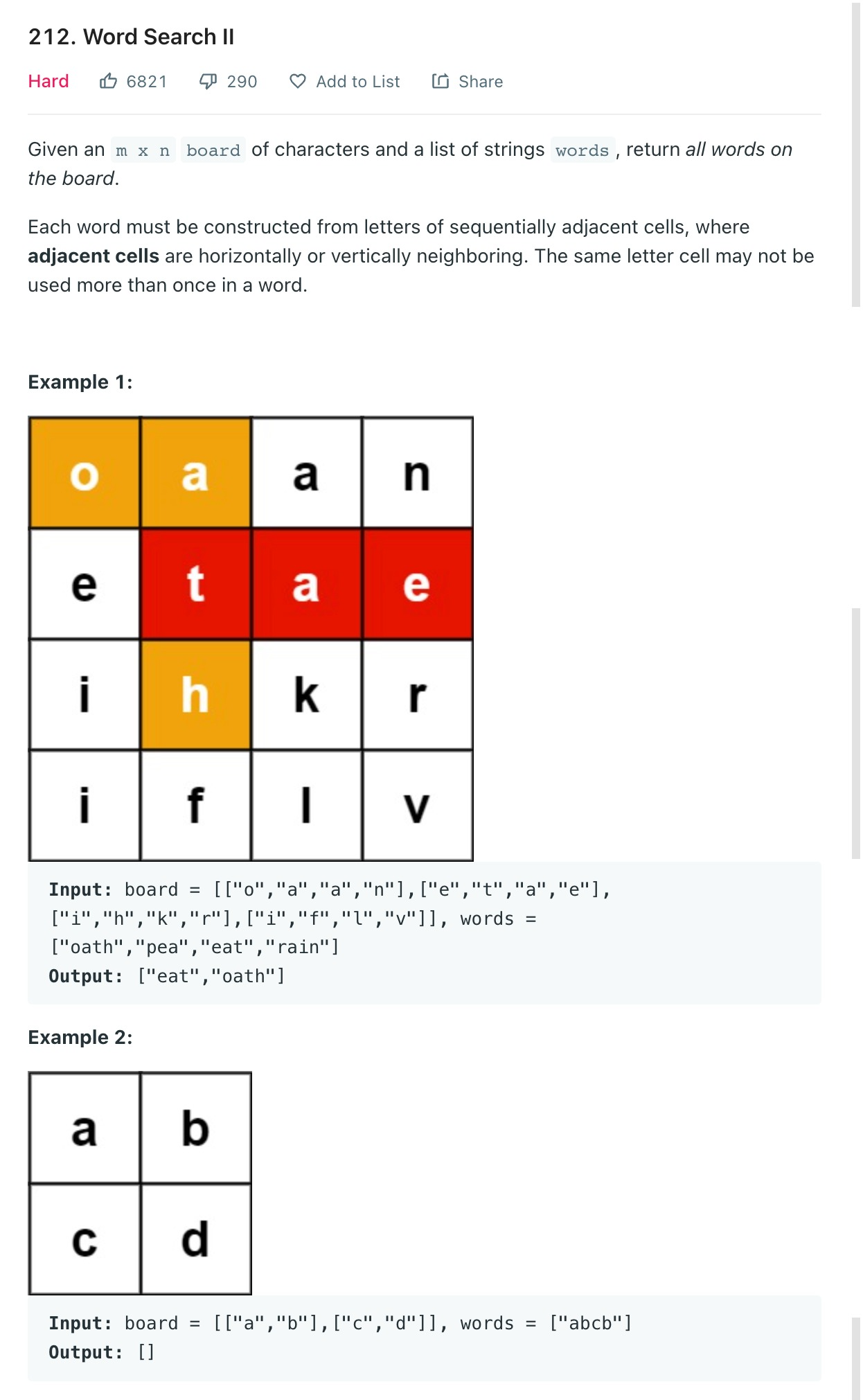
words에 들어있는 단어들이 Matrix에 중복 없이 이어서 표현할 수 있다면 결과에 추가하는 문제다.
Solution
1. Indexmap & backTracking
기존 Word Search I의 방식대로 하되 Index map 을 만들어서 첫 문자를 빠르게 찾아가 matrix를 탐색하도록 했다.
Algorithm
Index Map을 만들어Matrix에 들어있는 모든 시작 문자의Index를 저장한다.findWord는 기존 방식대로 방문한 좌표의 값을 지우면서dfs로 원하는 문자가 존재하는지 확인한다.- 원하는 문자가
matrix에 존재할 경우 결과에 추가한다.
var findWords = function(board, words) {
// Make map (letter) => [indexes]
const indexMap = new Map();
board.forEach((row, idx1) => row.forEach((letter, idx2) => {
if (indexMap.has(letter)) indexMap.get(letter).push(`${idx1},${idx2}`);
else (indexMap.set(letter, [`${idx1},${idx2}`]));
}));
// console.log(indexMap);
const dir = [0, -1, 0, 1, 0]
const findWord = (word, wordIdx, m, n) => {
// if (wordIdx > word.length - 1) return true;
if (word[wordIdx] !== board[m][n]) return false;
if (word.length - 1 === wordIdx) return true;
// 이런 Matrix에선 hasBeen 보다는 직접 지우고 복구하는게 효율적
board[m][n] = '';
for (let i = 0; i <= 4; i++) {
const newM = m + dir[i], newN = n + dir[i + 1]
if (newM >= 0 && newM < board.length && newN >= 0 && newN < board[0].length) {
if (findWord(word, wordIdx + 1, newM, newN)) {
board[m][n] = word[wordIdx];
return true;
}
}
}
board[m][n] = word[wordIdx];
return false;
}
const result = [];
for (let word of words) {
const indexes = indexMap.get(word[0]);
if (indexes === undefined) continue;
for (let index of indexes) {
const temp = index.split(',');
const m = Number(temp[0]);
const n = Number(temp[1]);
if (findWord(word, 0, m, n)) {
result.push(word);
break;
}
}
}
return result;
};
이 방법은 matrix의 크기가 클 수록 효율적으로 동작한다. 첫 문자를 매번 탐색하지 않고 처음 한 번 map에 저장해 바로 dfs를 시작할 수 있다. 하지만 찾으려는 문자열이 많아질 경우 그대로 시간이 증가하는 단점이 있다. 실제 테스트 데이터는 문자열의 개수가 상당해 이를 절감하는 방법이 필요해 보인다.
2. Trie words & backtracking
기존의 방식은 상관관계가 적은 words에 대해서는 문제 없이 동작하지만 words가 많아질 수록 이를 효율적으로 탐색하는 방식이 필요했다. Trie를 사용해 탐색해야 할 words를 효율적으로 줄여 words가 많아져도 대응할 수 있도록 한다.
Algorithm
buildTrie를 통해words를Trie로 만든다. 이 때, 문자가 끝날 경우에result에 단어를 추가하기 위해 기존에end flag로 동작하던 부분에 전체 단어를 추가해준다.dfs를 통해matrix를 탐색한다.- 먼저 현재
node에end속성을 확인해 단어가 끝나는 경우 이는 가능한 단어로 결과에 추가해준다. - 중복 방지를 위해
end속성을 삭제해준다. - 현재
matrix값이node의 다음 문자에 존재하는지 확인한다. - 가능한
matrix일 경우 현재 값을 방문으로 표시하고 (재방문 금지) 나머지 4방향에 대해 재귀적으로 탐색한다. - 방문을 마치고 방문표시를 원래 문자로 복구한다.
- 모든
matrix를 탐색했다면 결과를 반환한다.
var findWords = function(board, words) {
// words => Trie
const buildTrie = (words) => {
const root = {};
for (let word of words) {
let cur = root;
for (let w of word) {
if (!cur[w]) cur[w] = {};
cur = cur[w];
}
cur.end = word;
}
return root;
}
const result = [];
const dir = [0, -1, 0, 1, 0];
const dfs = (node, m, n) => {
if (node.end) {
result.push(node.end);
node.end = null;
}
if (m < 0 || m >= board.length || n < 0 || n >= board[0].length) return;
if (!node[board[m][n]]) return;
const letter = board[m][n]
board[m][n] = '#'; // Visited
for (let i = 0; i <= 4; i++) {
dfs(node[letter], m + dir[i], n + dir[i + 1]);
}
board[m][n] = letter; // restore
}
const root = buildTrie(words);
for (let i = 0; i < board.length; i++) {
for (let j = 0 ; j < board[0].length; j ++) {
dfs(root, i, j);
}
}
return result;
};
Trie를 만드는 시간은 matrix를 탐색하는 시간에 비해 매우 작다. 이후 1번 방식은 단일 word탐색에는 pruning이 효과적으로 작용하지만 words가 많아질 수록 그만큼 시간이 곱해진다. 2번 방식은 matrix를 한번 탐색할 때 이미 반영된 단어의 Trie node까지 불필요하게 체크하게 되지만 words가 많아져도 시간이 비례해서 늘어나지는 않는다. 따라서 긴 words에 대해 매우 효과적으로 동작한다.

로스트빌드(lostbuilds.com) 개발자, UEFN 도전, 게임이 재밌는 이유를 찾아서