
본 노트는 개인적인 공부 정리를 위한 블로그 글입니다.
목차
1. HDFS란 무엇인가?
2. HDFS의 아키텍처
3. HDFS의 File I/O 과정
4. HDFS의 Replica Management
5. Advanced Features
1. HDFS란 무엇인가?
HDFS 란?
빅데이터 처리 플랫폼인 Hadoop 프로젝트의 Distribued File System으로, Comodity Hardware 환경에서 스트리밍 데이터 접근 패턴을 갖는 용량이 매우 큰 파일을 저장하는 목적을 갖는다.
Stream Data Acess: write-once, read-many times 패턴
Commodity Hardware: Commonly available 하드웨어
Hadoop은 빅 데이터 처리 라는 특정 목적을 위해 만들어진 오픈소스 프로젝트이고, 그 중 HDFS는 Hadoop 환경의 데이터 분산 및 저장 처리를 담당한다.
로컬환경에서 처리하기 어려웠던 크기의 데이터 저장을 HDFS는 분산파일시스템 개념을 통해 가능하게 한다.
분산파일시스템은 말 그대로 거대한 파일시스템 을 HDFS 클러스터의 노드들이 분산하여 저장하는 시스템이다.
거대한 파일 시스템을 분산 저장하는 만큼, 기존의 파일 시스템에서 저장하는 Block단위가 아닌 HDFS에서의 별도의 저장단위에 대한 정의가 필요하고, 노드 컴포넌트 별 실패를 관리할 수 있는 Fault Tolerance도 필요하다.
HDFS 디자인
2. HDFS의 아키텍처
1) HDFS Blocks
-
일반적인 물리적 디스크에서 쓰이는 블록과 비슷한 개념으로, HDFS에서 읽기/쓰기를 위한 단위이다.
-
일반적인 디스크 파일 시스템의 블록 단위와 비교했을 때 매우 큰 크기인 128MB
-
파일은 블록 크기의 Chunk로 분할되어 독립된 블록으로 저장된다.
2) NameNode
-
HDFS의 namespace를 관리
-
트리안의 모든 파일 및 디렉토리에 대한
meta data를 저장 -
모든 namespace 정보는
RAM에 저장 -
NameNode에 이상이 발생하면 Hadoop 클러스터는 전체적으로 동작을 멈춘다.
3) DataNode
-
HDFS block이 저장되는 노드
-
하나의 block에 대해서는 여러개의 DataNode에 복제본을 두는 방식으로 유실에 대한 문제를 방지함
4) HDFS Client
- NameNode 및 DataNode와 통신을 통해 사용자를 대신하여 파일 시스템에 액세스
5) System Integrity
-
heartbeats: DataNode는 NameNode에게 용량, 사용되는 데이터 크기등의 정보를 전송 -
만약 10분간
hearbeats이 전송되지 않을 경우, NameNode는 해당 DataNode가 중단된 것으롶 판단, 새로운 DataNode에 블록들을 옮긴다.
3. HDFS의 File I/O 과정
HDFS에서 데이터 읽기
- 클라이언트는 NameNode와의 질의를 통해 원하는 파일의 블럭이 위치한 데이터노드 목록 (location) 메타데이터를 메모리에서 가져온다.
- 이때 주어진 목록은 여러 replica들이 존재하는 데이터 노드와 Reader와의 거리를 기준으로 정렬되어 주어지며, 클라이언트는 가장 가까운 replica에 대해서 read를 시도한다.
- 이후의 작업은 NameNode의 간섭 없이 DataNode로부터 병렬로 직접 read 작업을 수행한다. 이처럼 NameNode의 관여없이 데이터를 통째로 가져오기 때문에 효율이 높아진다.HDFS에서 데이터 쓰기
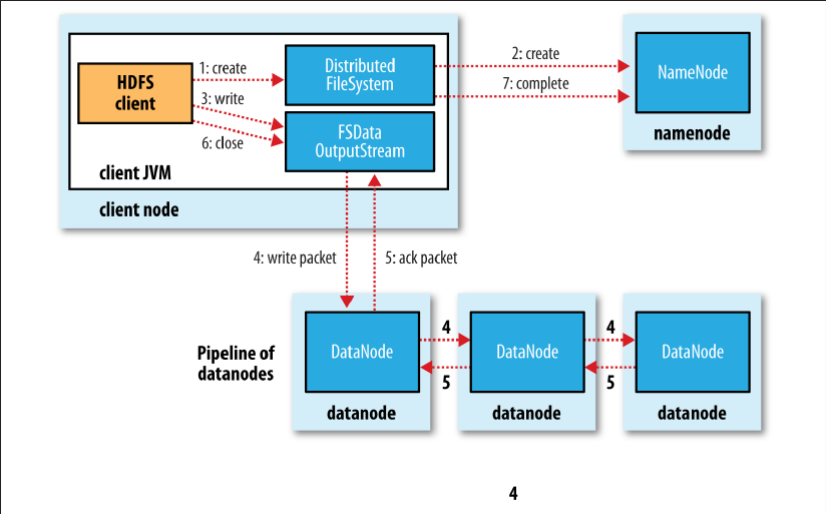
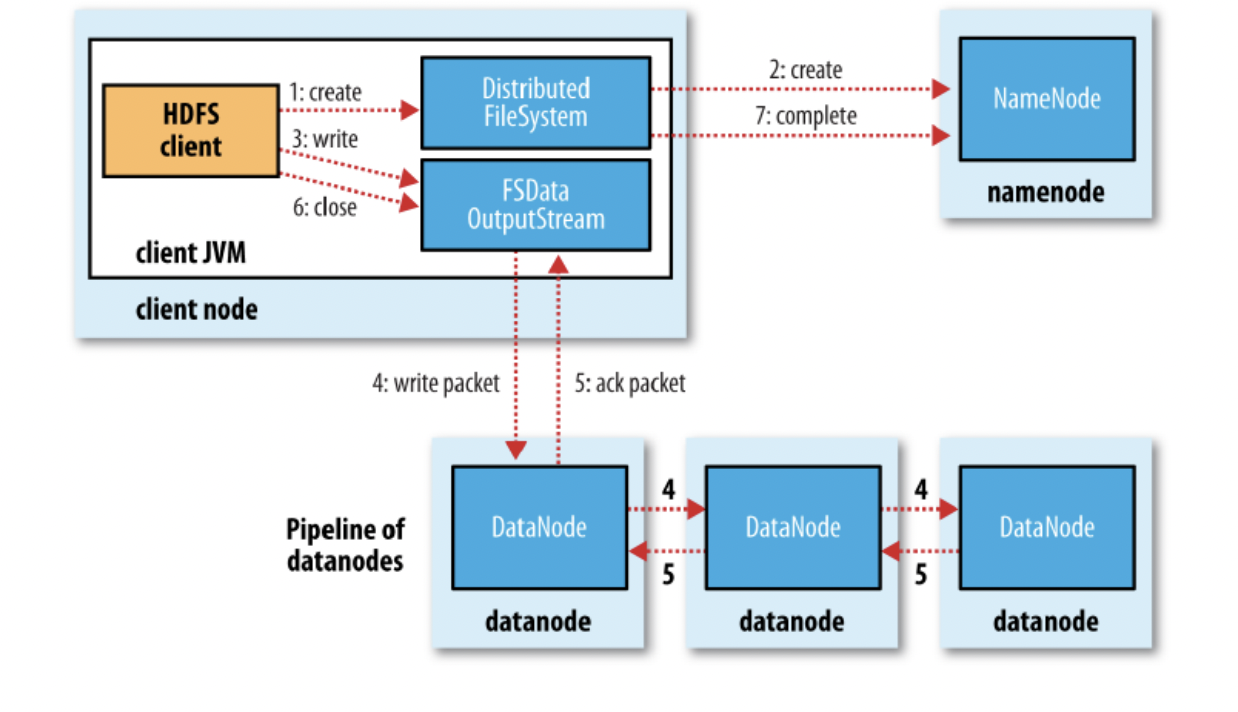
- 클라이언트는 NameNode에게 파일 블록과 이에 대한 복제복들을 저장할 DataNode의 위치를 요청한다.
- NameNode는 네트워크 거리 연산을 통해 최소로 하는 DataNode들의 리스트를 반환한다.
- 클라이언트가 blcok에 데이터를 write하면 DataNode 리스트가 파이프라인을 형성함과 동시에 순차적으로 Replica에 write한다.4. HDFS의 Replica Management
HDFS는 Block들이 손상되었을 때 발생했을 때 이를 복구하는 Fault-Tolerant 기능을 제공하는데, 이에 기반이 되는 개념이 바로 Replication이다.
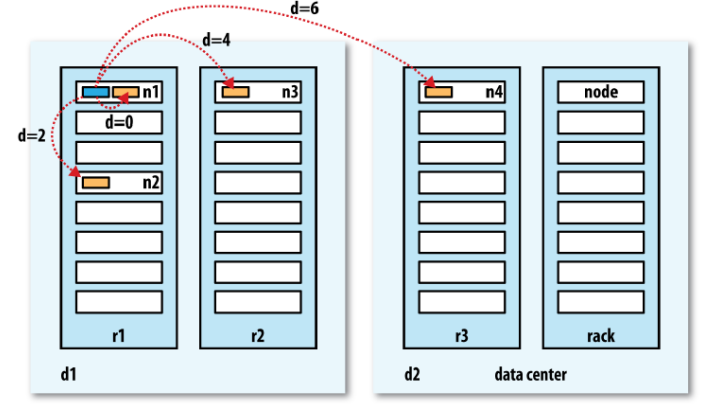
하나의 Block에 대해서 default로 3개의 복제본을 관리하며, 복제본의 위치는 Block이 존재하는 Node들 사이의 관계에 대해서 다음과 같은 조건을 만족하며 관리된다.
- 하나의 노드 내에 두개 이상의 블록 복제본을 갖지 않는다.
- (클러스터 내에 충분한 Rack이 존재한다면) 하나의 랙 내에 세개 이상의 블록 복제본을 갖지 않는다.
** 하둡은 같은 Data Center 내에서 실행되기에 적합하기에 타 Data Center에 복제본을 두는 것은 적합하지 않다. 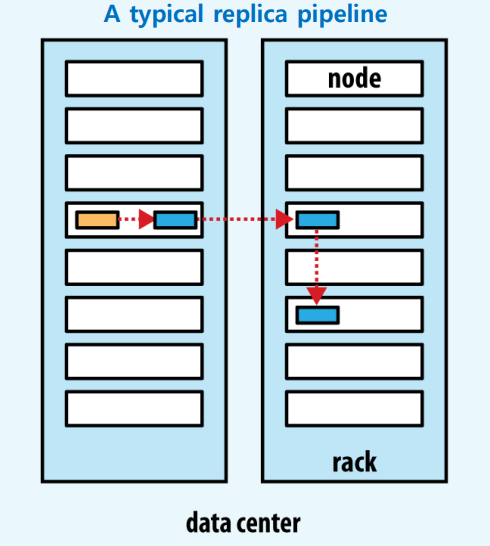
그렇기에 일반적인 블록 복제본에 대한 위치 설정은 다음과 같이 진행된다.
