
본 노트는 개인적인 공부 정리를 위한 블로그 글입니다.
목차
1. MapReduce의 기본 원리
2. MapReduce의 아키텍처
3. Shuffle 과 Sort
4. Reduce task의 개수에 따른 MapReduce DataFlow
1. MapReduce의 기본 원리
MapReduce 란?
MapReduce is a programming model and an associated implementation for processing and generating large data sets.
Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
-
MapReduce는 HDFS와 같이 Hadoop 프로젝트를 통해 만들어진 모델로, 대용량 데이터 처리를 위한 분산 처리 프로그래밍 모델이다.
-
사용자가 정의한 Map 함수와 Reduce 함수를 통해 데이터를 각각 분산처리하고 합치는 과정을 거친다.
-
Map 과정에서 데이터를 key/value 쌍 형식으로 읽어들이며, Reduce 과정에서 같은 키에 해당하는 데이터 끼리 Merge된다.
2. MapReduce의 Architecture
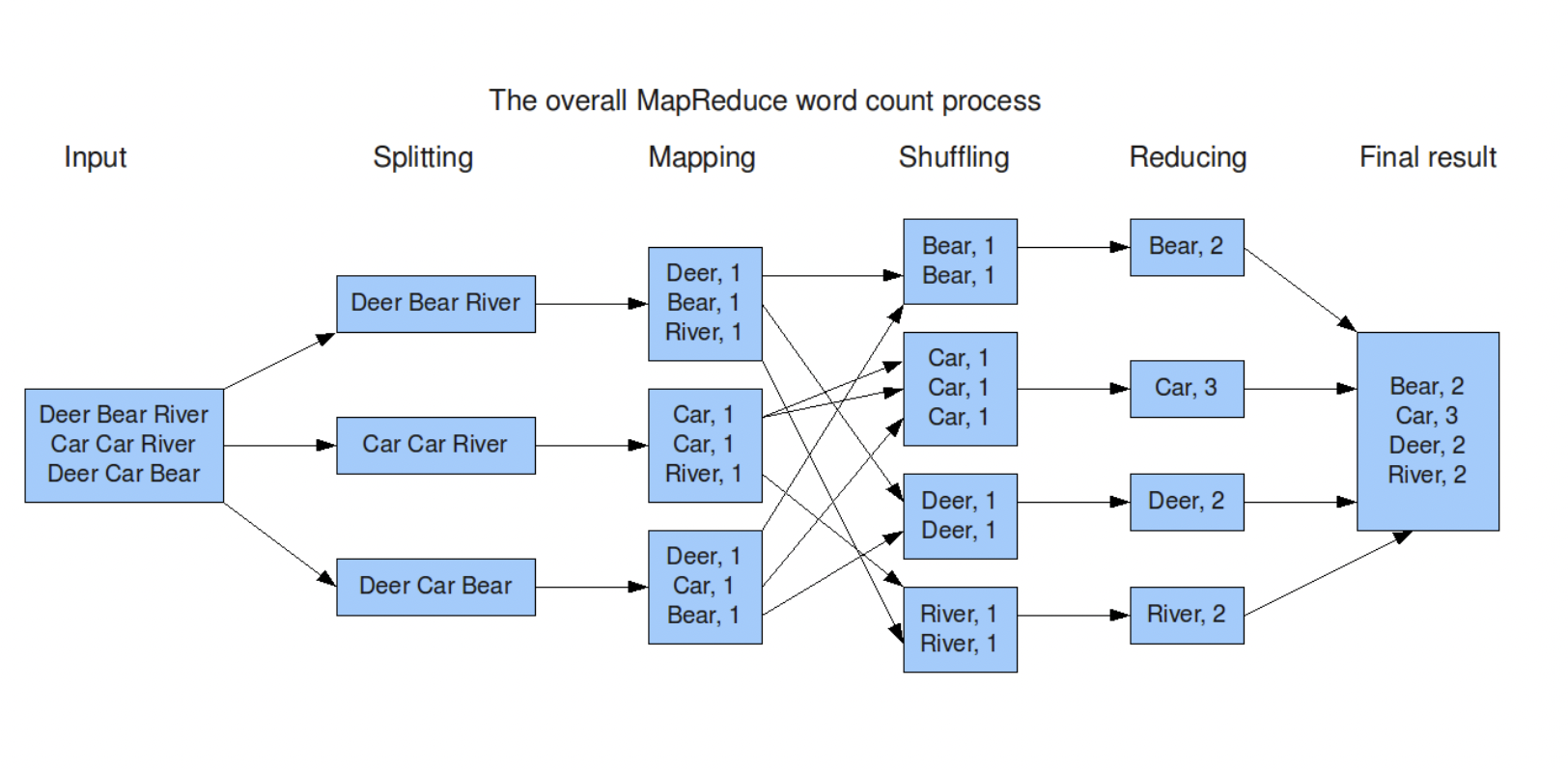
위의 예제는 HDFS의 블록단위 Input에서 단어 별 개수를 출력하는 'WordCount' 예제에서 MapReduce가 작동하는 과정을 나타낸 그림이다.
위의 과정을 상세하게 표현하면 아래와 같다.
1. MapReduce 작업이 시작될 때 HDFS로 부터 파일을 가져온다. 이때 데이터를 읽어오는 크기는 Block Size이다.
** 이 때 읽어들이는 Format은 그때마다 다른데, 이 경우에는 텍스트 파일의 각 line을 읽어들여, 각 라인의 바이트 오프셋, 각 라인의 내용이 각각 key 와 value가 되는 TextInputFormat이다.
2. MapTask로 넘어가기 전에 Block Size의 데이터를 input split 단위만큼의 데이터 단위로 분리하여 각 split마다 Mapper 클래스를 매칭시킨다.
3. 모든 Map Task 내에서 각 record별로 map()함수를 처리하여 Key,Value 형식의 data(중간 생성물)을 생성한다.
4. Map Task에서 발생한 중간 생성물을 Key별로 분리하여 저장한다 (Partioning)
5. Key별로 저장된 MapTask의 중간 생성물은 Reduce Task로 전달하기 전에 지정된 비율의 파일 개수 만큼 파일들이 병합된다.
5. Reduce Task에게 중간 결과물이 전달되고 사용자 정의 reduce 함수를 거쳐 (이 경우 key값에 해당하는 value 들을 모두 더한다) 결과물을 생성한다.
6. 최종 결과물을 HDFS에 저장한다.InPut Split: 데이터를 처리하는 단위
Block Size : 데이터를 읽는 단위
3. Shuffle 과 Sort
Shuffle 과 Sort 과정은 아마도 MapReduce의 가장 복잡한 측면의 실행 과정이라고 할 수 있다.
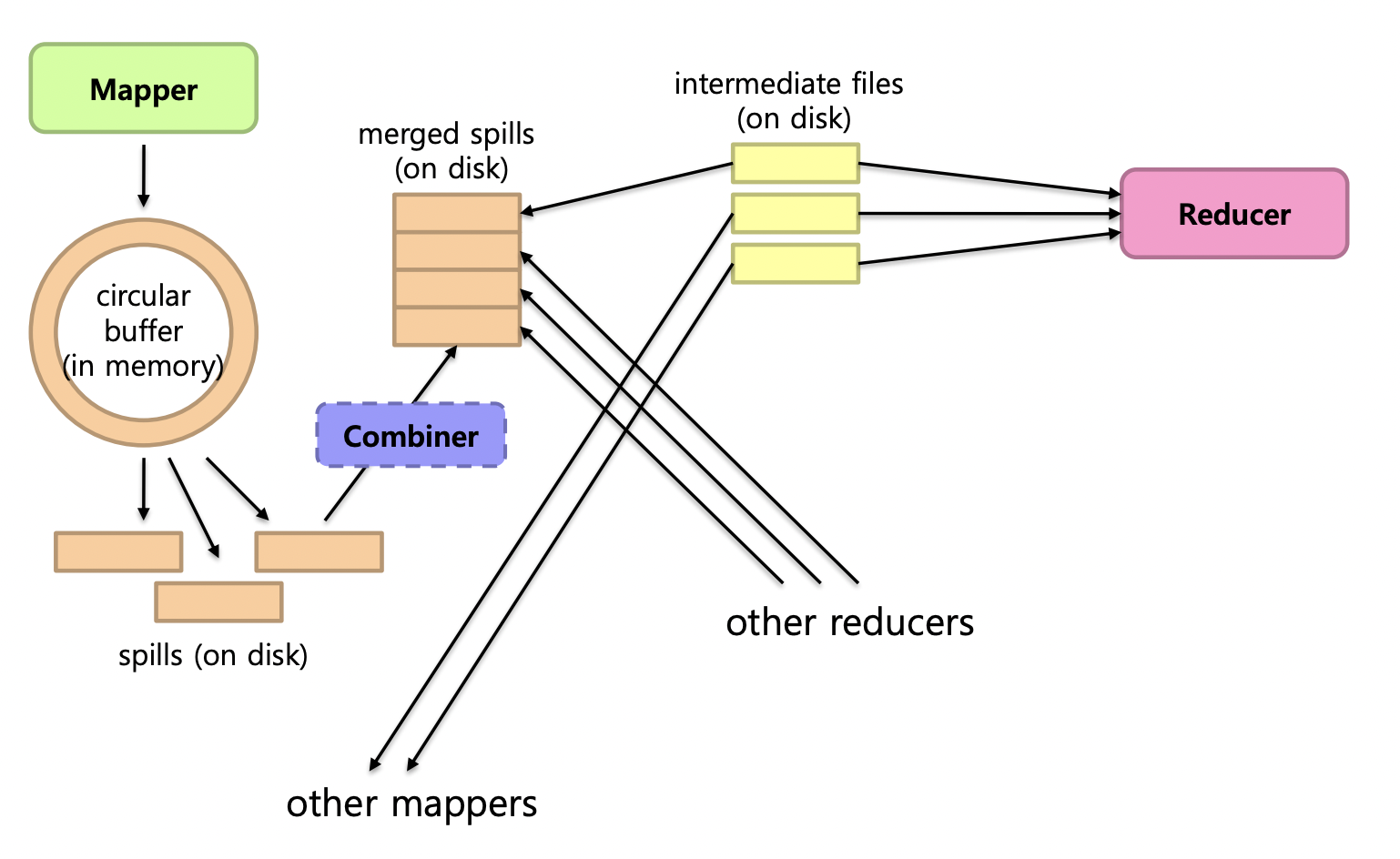
Hadoop의 MapReduce는 크게 두 phase (Map, Reduce)로 구성되며 Shuffle과 Sort 과정은 두가지 측면에서 정의될 수 있다.
Map Side
Map의 출력은 순환 버퍼의 메모리에 버퍼링된다.- 버퍼가 임계값에 도달하면 내용이 디스크로
Spill된다. - 해당 데이터들은 분할된 단일 파일로 병합된다. (Reducer 별 파티션)
Reduce Side
Mapper의 출력은Reducer머신에 복사된다.- 해당 데이터는
multi-pass merge로sort된다. final merge pass는 곧장Reducer에게 전달된다.
4. Reduce task의 개수에 따른 MapReduce DataFlow
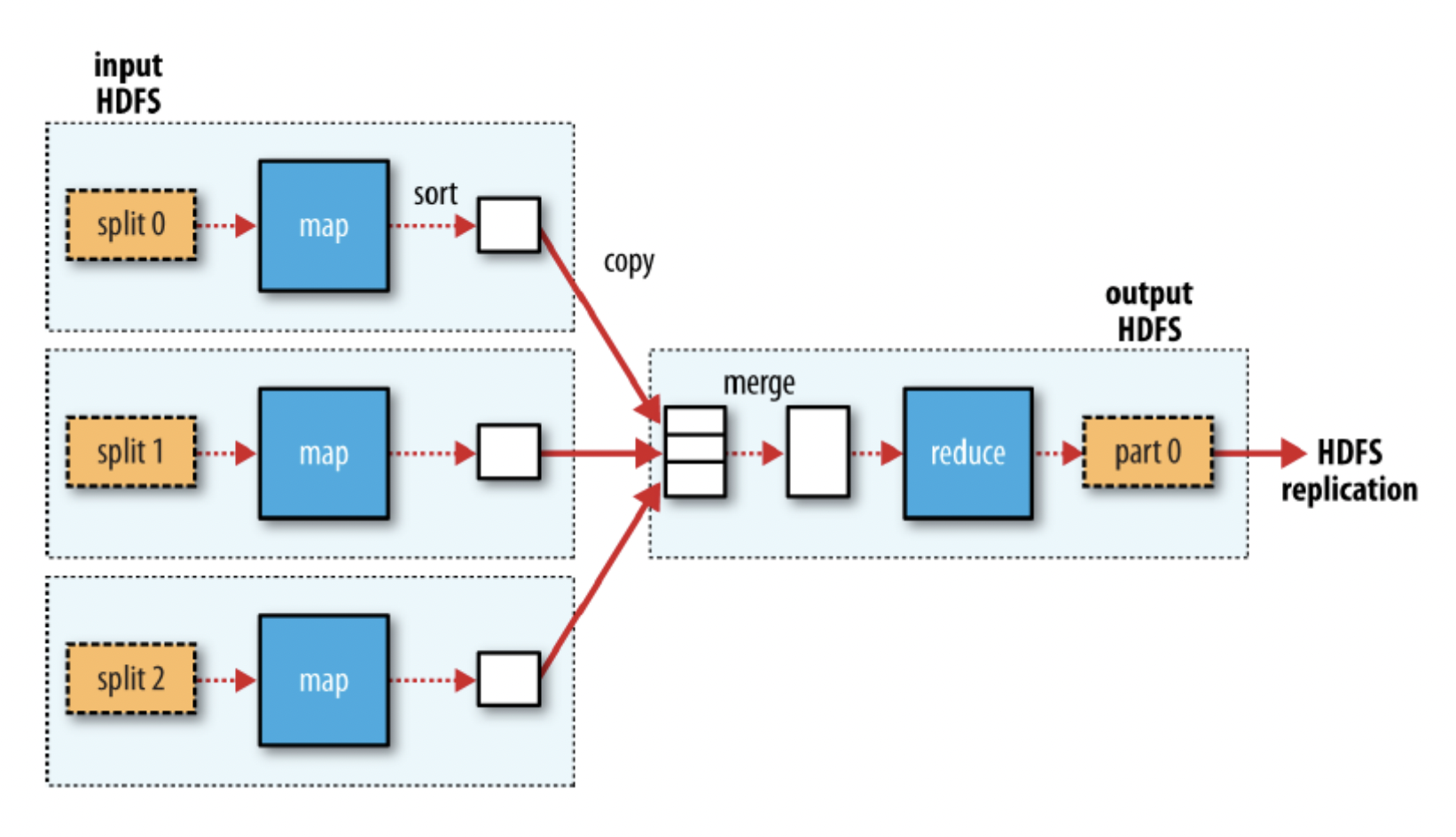
single reduce일 떄:
multiple reduce일 때:
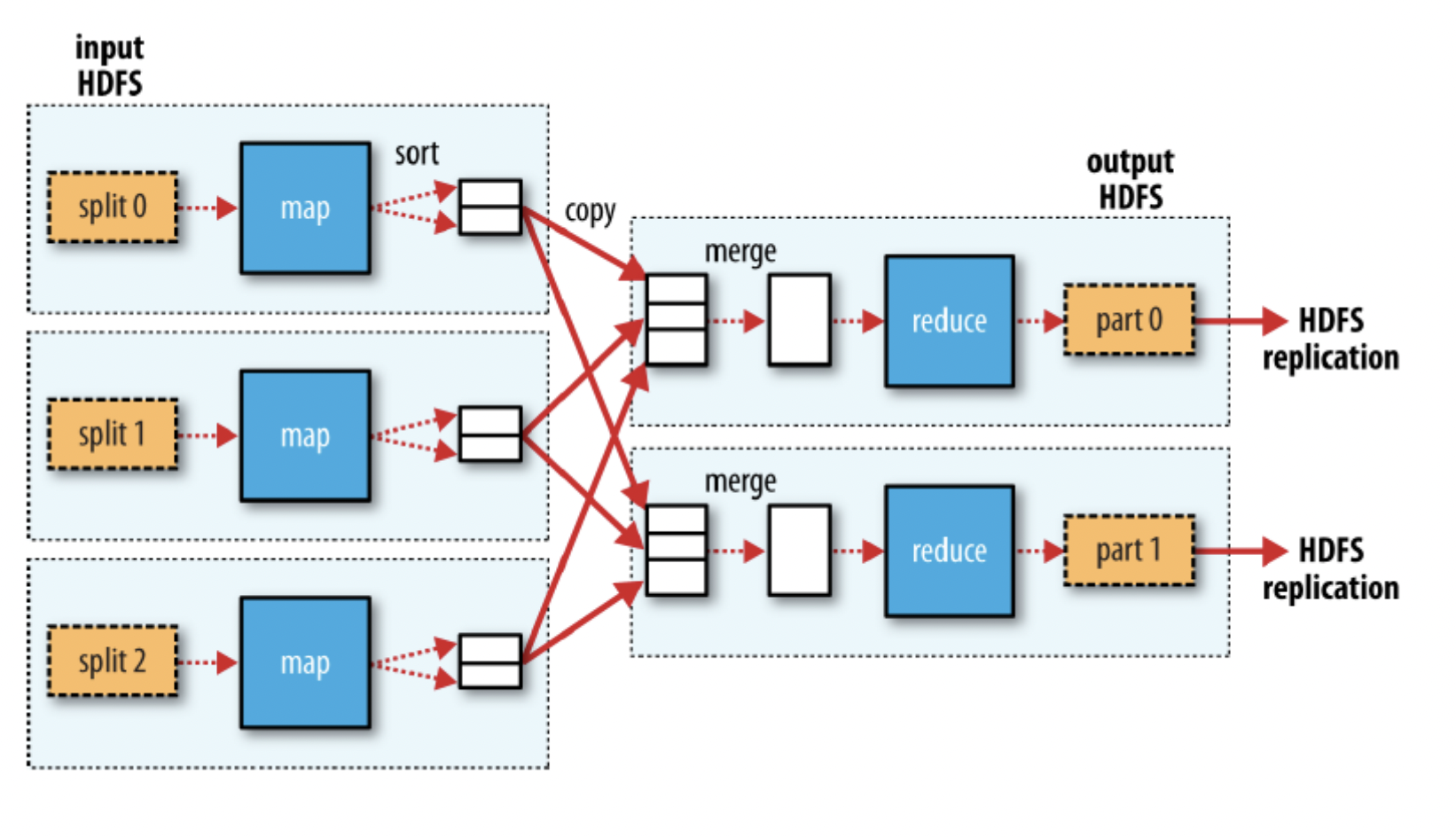
-
Map task은 결과물에 대해 partioning을 적용하게 되며 하나의 reduce task마다 하나의 partion을 갖게된다.
-
하나의 파티션은 하나의 Key에 대한 레코드들만 저장한다.
-
Map의 OutPut이 Recuce의 Input이 되기까지의 중간과정을 Shuffle이라한다.
zero reduce 일 때:
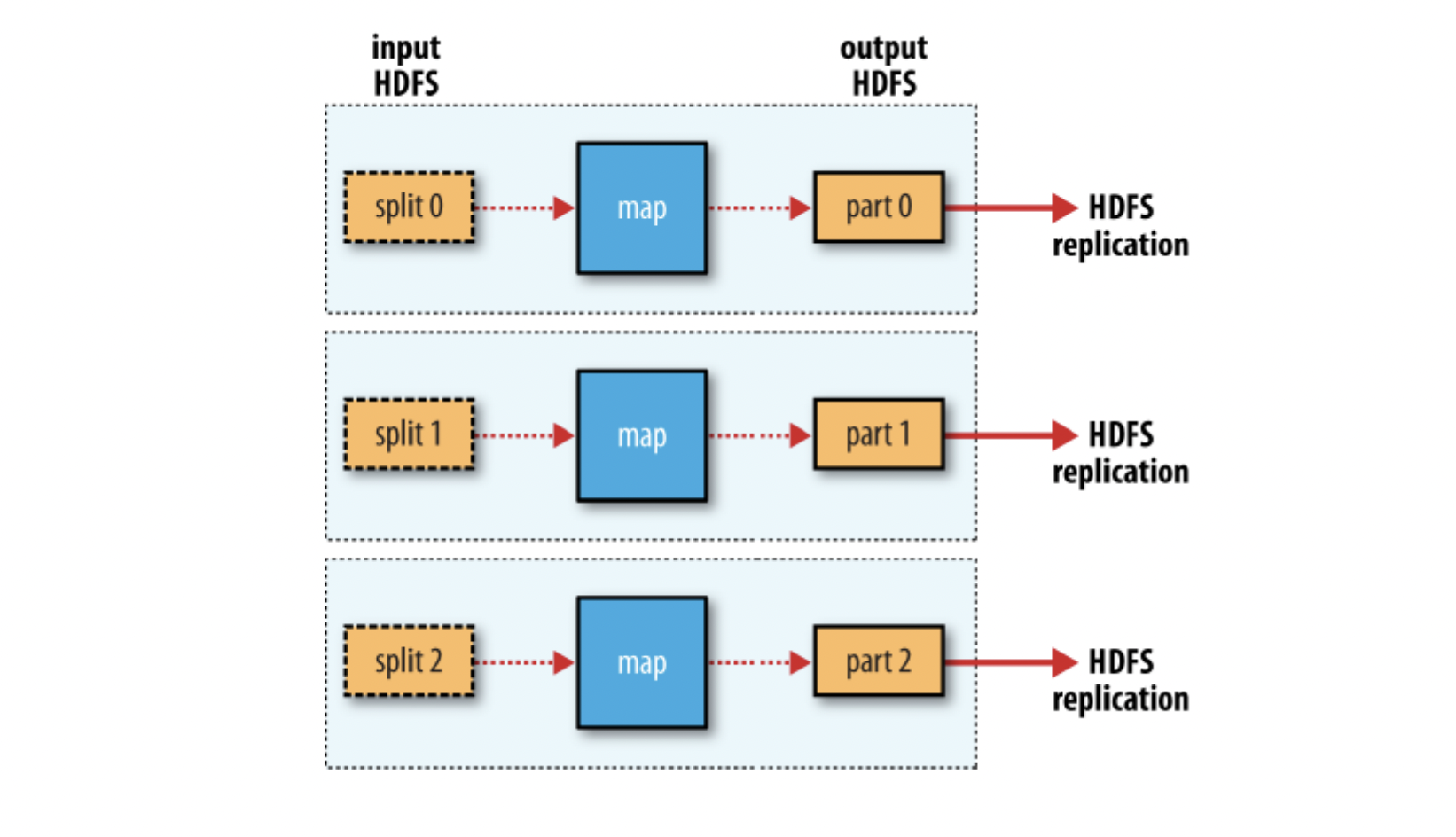
- Shuffle 과정이 필요없는 경우
- Map의 Output이 로컬이 아닌 HDFS에 바로 저장된다.
