Mamba모델이란?
Mamba는 SSM(State Space Models) 계열의 아이디어를 확장한 모델로, 긴 시퀀스 데이터를 다룰 때 효율적입니다.
- 일반적인 autoregressive LLM(Transformer)은 시퀀스 길이를 라고 하면 O()의 시간/메모리 복잡도를 가집니다.
- 반면, Mamba는 O()( 시간 복잡도로 동작하여 긴 시퀀스도 효율적으로 처리할 수 있습니다.
SSM이란?
SSM은 입력과 현재 상태(state)로부터 다음 상태를 계산하는 모델입니다.
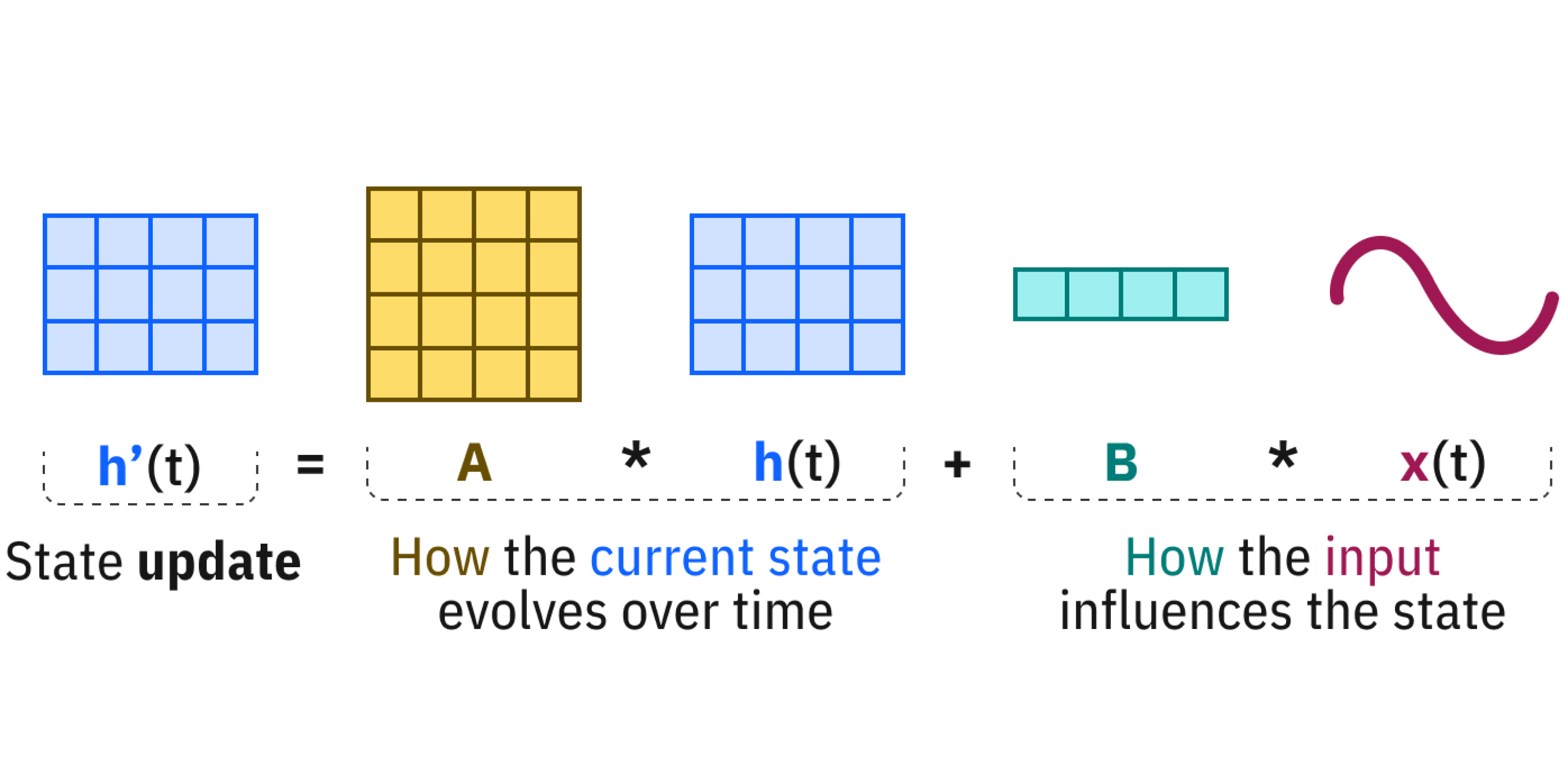
- A*h(t):이전 상태의 영향을 반영
- B*x(t): 입력 가 상태에 얼마나 영향을 주는지
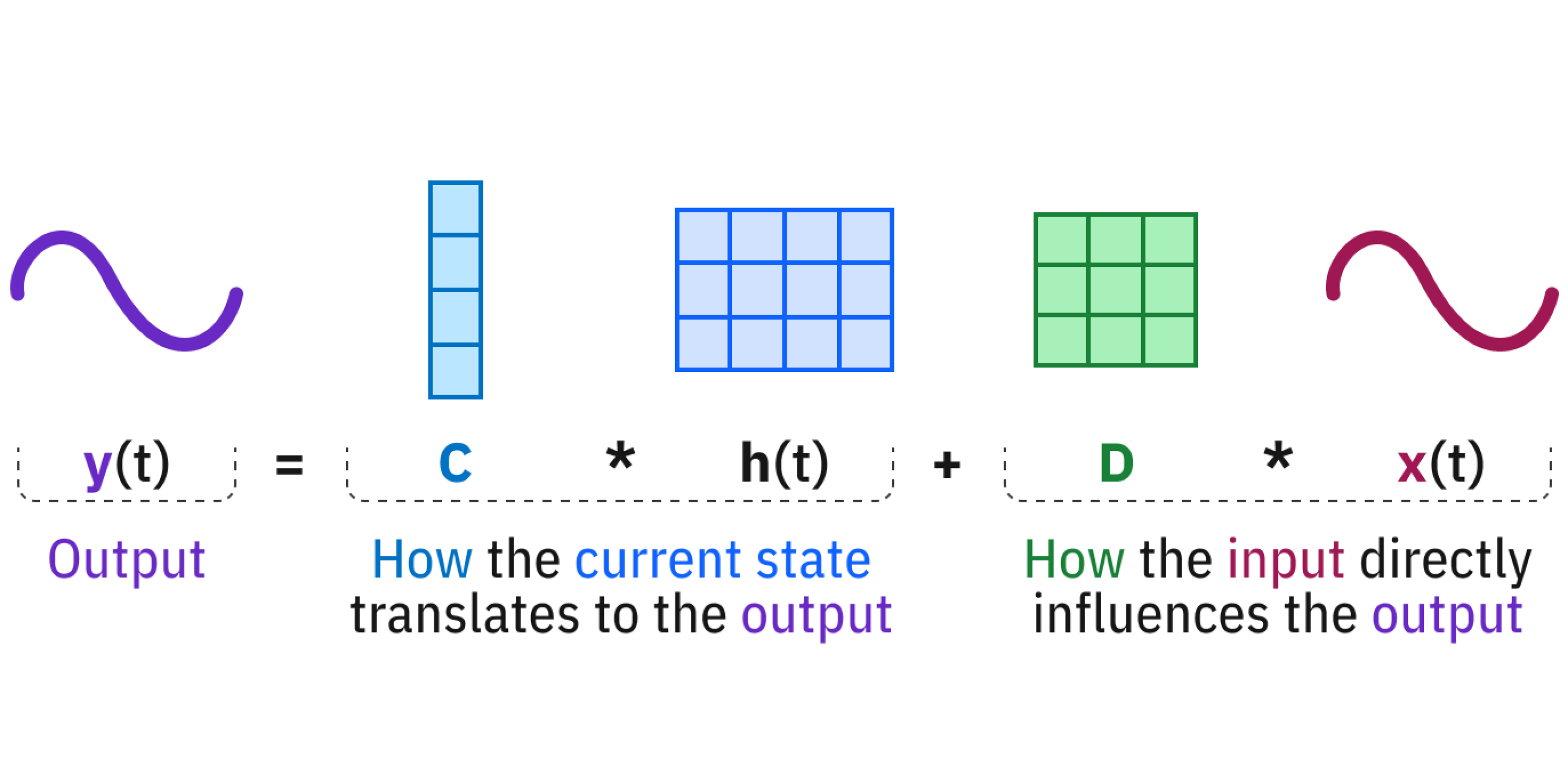
이후 매 시간마다 h(t)를 사용해 y(t)를 계산합니다. 고전적인 SSM에서는 A, B, C가 고정된 매개변수로 학습됩니다.
Mamba
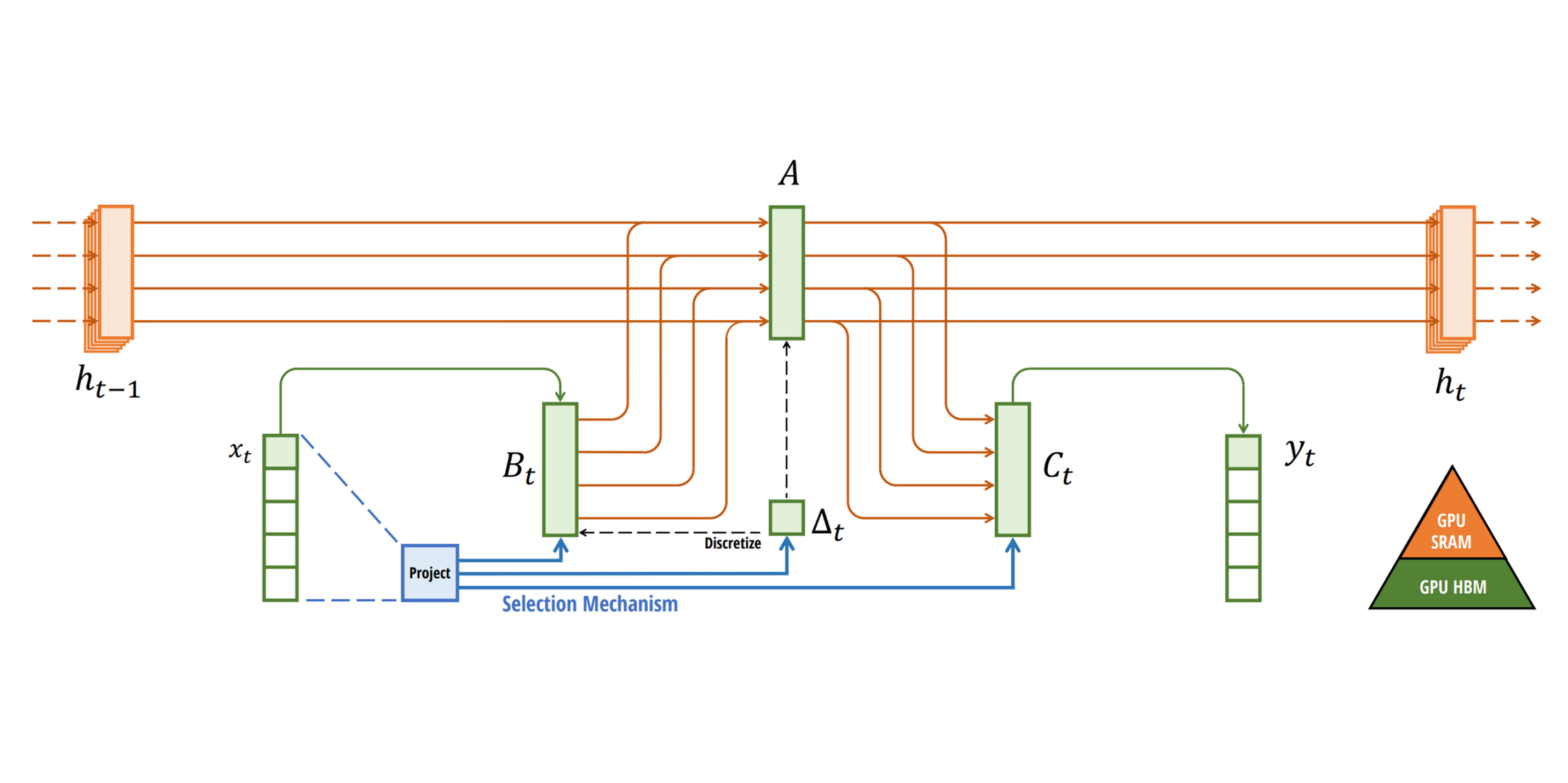
Mamba의 핵심은 Selective SSM입니다.
- 기존 SSM과 달리, 입력 에 따라 , 가 동적으로 변합니다.
- 이를 통해 Mamba는 RNN처럼 순차적 구조를 가지면서도, Attention처럼 입력에 따라 다른 가중치를 줄 수 있습니다.
또한 순차적 계산을 GPU에서 효율적으로 수행하기 위해, Mamba는 chunkscan(병렬 prefix-scan) 알고리즘을 사용하여 전체 연산을 병렬화하고 선형 시간으로 수행합니다.
Mamba 계산
Mamba의 수식을 풀어서 쓰면 다음과 같습니다.:
이 수식을 보면 앞에서부터 곱과 합을 누적하는 과정이라는 걸 알 수 있습니다. 이건 누적합(prefix sum)과 누적곱(prefix product) 문제로 바꿀 수 있습니다.
병렬 알고리즘에서는 이런 누적합/곱을 빠르게 계산하는 prefix-scan(스캔 연산)이 있습니다.
병렬 Prefix-scan
병렬 scan 알고리즘은 크게 두 단계로 나눕니다.
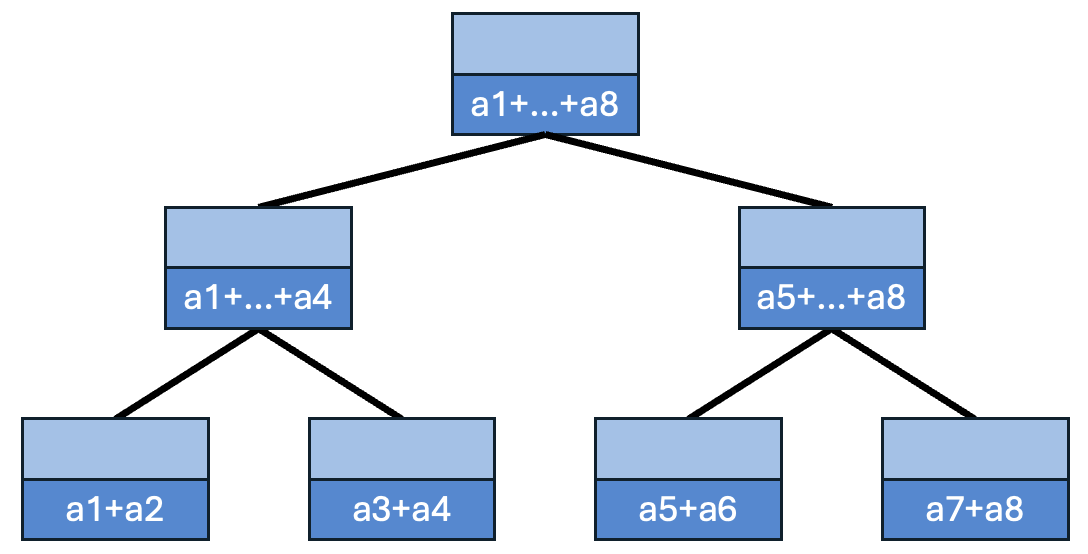
- Upsweep (reduce 단계)
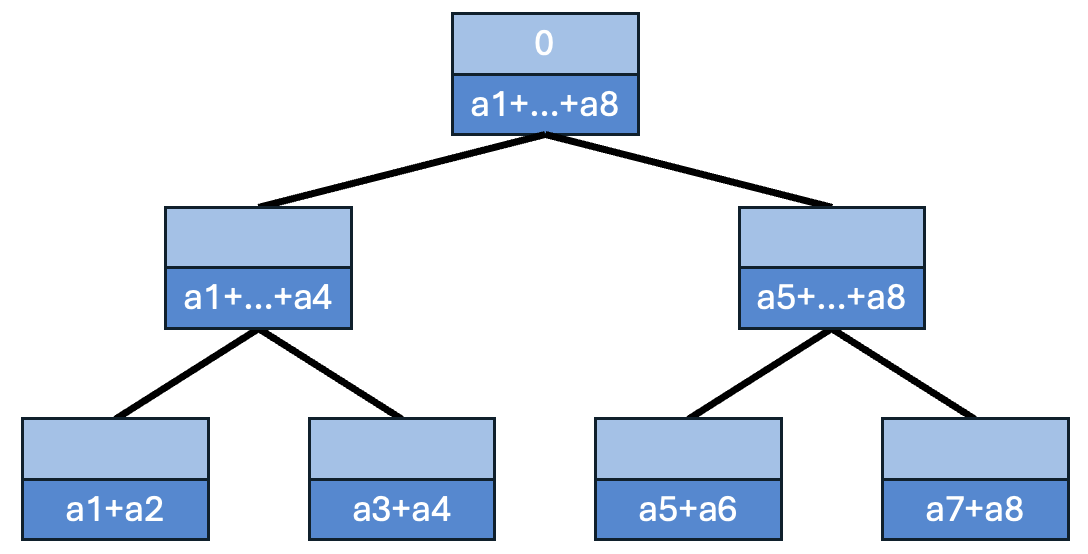
배열을 이진 트리 구조로 합쳐 나가면서 부분합을 계산합니다.
예시: 배열 가 있을 때, 생성된 트리는 다음과 같습니다.
- Downsweep (prefix 전파 단계)
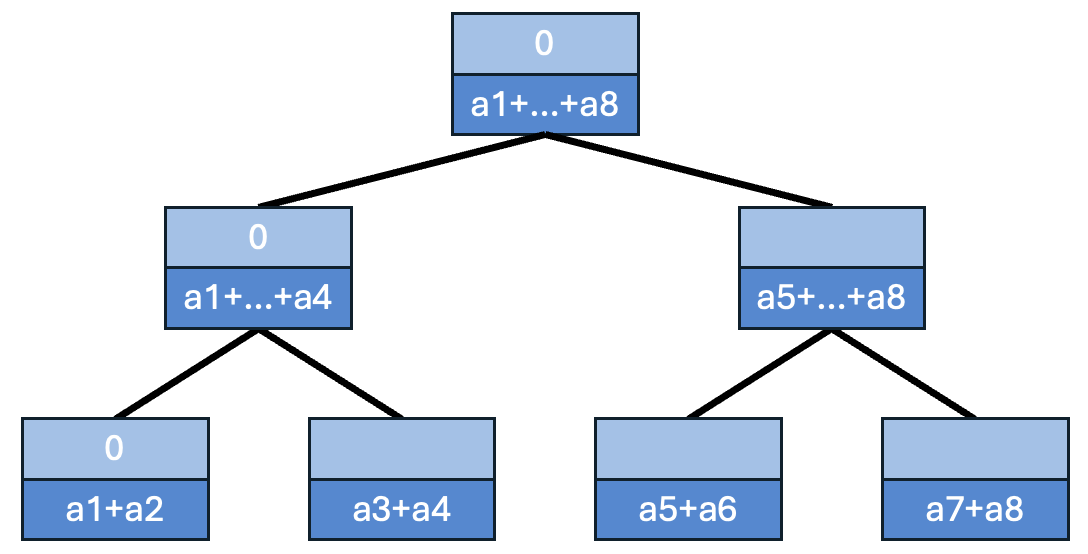
이제 트리 꼭대기에서 다시 내려오면서, 각 노드에 **자신 앞쪽의 누적 합을 갱신합니다.
-
루트에는 0을 놓고 시작.
-
왼쪽 자식은 "부모의 prefix"를 그대로 받음.
-
오른쪽 자식은 "부모의 prefix + 왼쪽 자식 합"을 받음. 이 과정을 트리 아래로 내려가며 반복합니다.
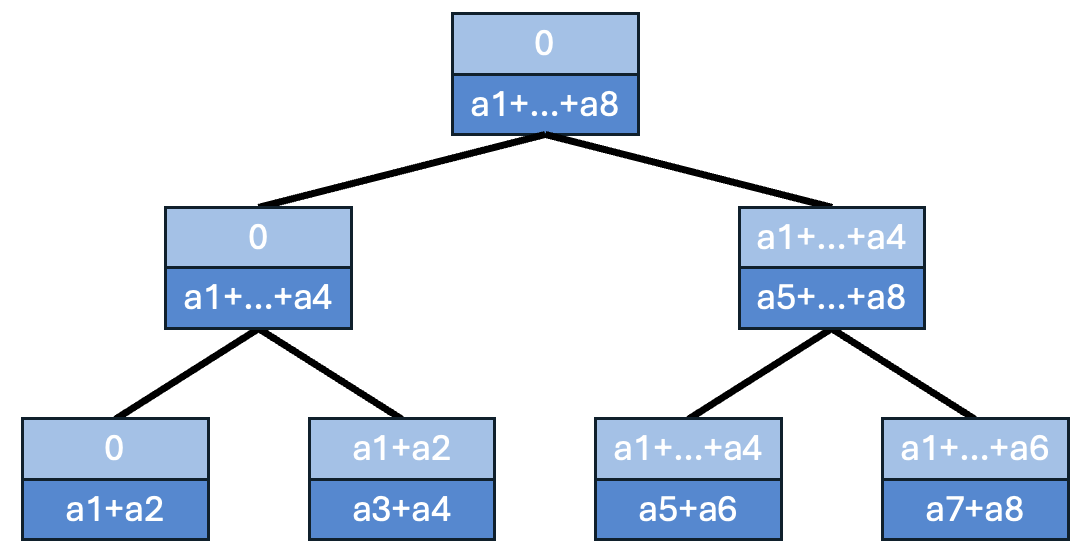
트리의 노드 깊이만큼 병렬 시간 처리 시간이 걸리기 때문에 O(logN)의 시간복잡도가 걸립니다.
Prefix-scan 자체는 log N 단계라도 코스트가 커질 수 있고, GPU는 작은 블록 단위 연산에 최적화되어 있기 때문에 그대로 사용할 수 없습니다.
chunkscan
그래서 Mamba는 chunkscan이라는 변형을 씁니다. 핵심은 시퀀스를 chunk 단위(예: 128 토큰)로 잘라서 scan을 두 번 하는 것입니다.
- Intra-chunk scan
각 chunk(예: 128 길이) 안에서는 prefix-scan을 병렬로 수행합니다. GPU block/thread 단위에서 처리하기 좋습니다. - Inter-chunk scan
각 chunk의 마지막 상태만 모아서 또 한 번 prefix-scan. 이걸로 "앞의 chunk들이 이 chunk에 미치는 영향"을 계산합니다. - Combine
inter-chunk 결과를 다시 각 chunk 내부에 더해줘서 전체 시퀀스 를 완성합니다.
chunkscan 타일 연산은 matmul과 다르게 tile간 결과에 의존성이 생깁니다.
chunkscan 구현 ( Tilelang )
mamba에서 chunkscan 커널 구현을 보면 다음과 같습니다.
- 토큰의 전체 길이를 seqlen이라 할 때,
- 이를 chunk_size 단위로 쪼개서 nchunks = seqlen // chunk_size 개로 만든다.
- intra-chunk scan 커널은 각 chunk 내부에서 병렬적으로 실행된다. 그러나 전체 시퀀스를 처리할 때는 외부 루프에서 이 커널을 chunk 순서대로 호출하고, 이전 chunk에서 나온 요약 상태(prev_states)를 전달받아 더하면서 inter-chunk scan이 이루어진다.
- intra-chunk scan 커널의 출력은 "(intra-chunk scan) + (이전 chunk에서 넘어온 상태의 기여) + (잔차 게이트 D·x)"의 합이다.
각 위치 l의 출력 out[l]을 수식으로 표현하면 다음과 같습니다.
첫번째 항: intra-chunk scan
두번째 항: 이전 chunk에서 넘어온 상태의 기여
세번째 항: 잔차 게이트
intra-chunk scan
- : l 위치가 과거 s 위치로부터 받는 기본 점수
- : 시간이 멀면 영향이 줄어드는 감쇠
- : 각 과거 위치의 보정값
- : 과거 토큰의 벡터
이들을 모두 곱한 뒤 s ≤ l (즉 과거만) 모아서 더합니다.
코드로 보면 다음과 같습니다.
def ref_program(cb, x, dt, dA_cumsum, C, prev_states, D):
_, _, ngroups, _, _ = cb.shape
batch, seqlen, nheads, headdim = x.shape
# _, _, ngroups, dstate = B.shape
# assert B.shape == (batch, seqlen, ngroups, dstate)
_, _, nchunks, chunk_size = dt.shape
assert seqlen == nchunks * chunk_size
C = repeat(C, "b l g d -> b l (g h) d", h=nheads // ngroups)
cb = repeat(cb, "b c g l s -> b c (g h) l s", h=nheads // ngroups)
# exp(dA[l] - dA[s])
dt_segment_sum = dA_cumsum[:, :, :, :, None] - dA_cumsum[:, :, :, None, :]
decay = torch.exp(dt_segment_sum)
scores_decay = cb * rearrange(decay, "b h c l s -> b c h l s")
# s ≤ l 덧셈을 위한 마스크
causal_mask = torch.tril(
torch.ones(chunk_size, chunk_size, device=x.device, dtype=bool), diagonal=0)
scores_decay = scores_decay.masked_fill(~causal_mask, 0)
out = torch.einsum('bchls,bhcs,bcshp->bclhp', scores_decay.to(x.dtype), dt.to(x.dtype),
rearrange(x, "b (c s) h p -> b c s h p", c=nchunks))
state_decay_out = torch.exp(rearrange(dA_cumsum, "b h c l -> b c l h 1"))
out_prev = torch.einsum('bclhn,bchpn->bclhp', rearrange(
C, "b (c l) h n -> b c l h n", c=nchunks), prev_states.to(C.dtype)) * state_decay_out
out = out + out_prev
out = rearrange(out, "b c l h p -> b (c l) h p")
if D is not None:
if D.dim() == 1:
D = rearrange(D, "h -> h 1")
out = out + x * D
return outEinstein Summation Convention (아인슈타인 합 표기법)
모든 선형 대수 연산(dot, matmul, batch-matmul, transpose, trace, ...)을 통일된 표기로 표현할 수 있는 도구입니다. 같은 인덱스끼리는 곱한 뒤 sum하고, 남은 인덱스는 그대로 출력으로 남습니다.
이전 chunk에서 넘어온 상태의 기여
- C[l]: 현재 위치 l이 상태를 어떻게 읽을지 결정하는 행렬
- prev_states: 이전 chunk에서 넘어온 상태 벡터들
- exp(dA[l]): l 위치의 decay 스케일
현재 토큰 자신에 대한 잔차 게이트
- D: head마다 정해진 스칼라
- x[l]: 현재 토큰 벡터
- 정확성 확인용 PyTorch 레퍼런스와 성능용 tilelang 커널을 함께 제공
- 오토튜닝/프로파일링으로 최적 블록 크기를 선정
참고자료:
IBM SSM 설명: https://www.ibm.com/think/topics/state-space-model#What+is+a+state+space
IBM Mamba설명: https://www.ibm.com/think/topics/mamba-model
Mamba 논문: https://arxiv.org/pdf/2312.00752
