Network layer의 역할
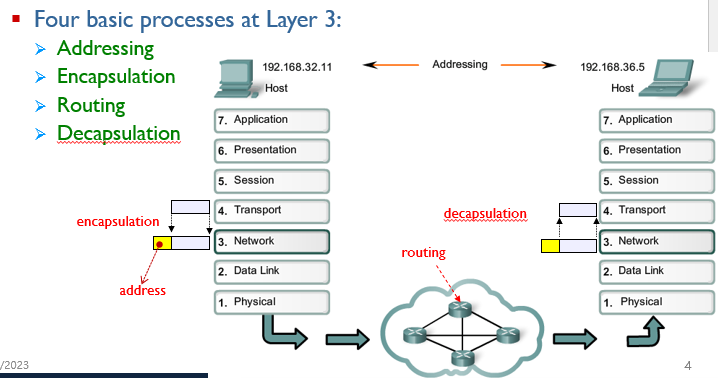
network layer는 encapsulation을 통해서 address를 datagram header에 추가하고 그 address 주소에 맞는 다른 end system의 network layer까지 올라간다.
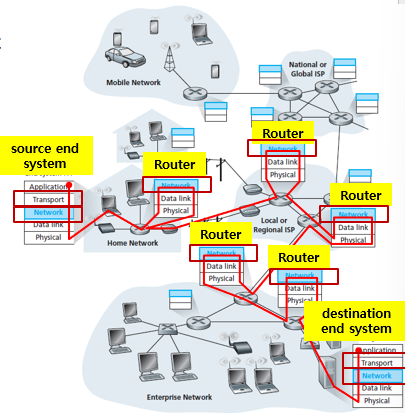
다른 end system을 찾아갈때는 routing과정이 필요하다.
🤔routing이란?
패킷을 source에서 dest까지 전달할 경로를 정하는것이다. 어디 end system으로 갈지 정하는거라고 생각하면 된다.
network layer functions
-
forwarding: router input으로부터 알맞은 router output으로 패킷을 전달하는것을 말한다.
-
routing:패킷을 source에서 dest까지 전달하는 경로를 결정하는것
virtual circuit and datagram networks
- datagram packet
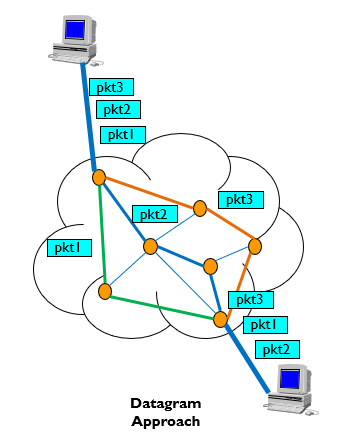
각 패킷은 독립적이기 때문에, 각 패킷은 어느 루트든지 갈 수 있다.
즉, 각 패킷마다 라우팅 결정이 필요하다.
패킷은 비순서적으로 도착할 것이고, 손실되는 패킷도 생길것이다.
그래서 receiver는 패킷을 다시 re-order하고 손실된 패킷을 복구하는것이 필요하다.
✍️no call setup at network layer: 네트워크 계층에서 통화 설정이 없다는 것을 의미한다. 이는 보통 음성 통화나 비디오 통화와 같은 실시간 통신을 처리하는 데 필요한 기능이 없다는 것을 나타낸다. 이 경우, 통화 설정은 애플리케이션 계층에서 처리된다.
✍️routers:
end-to-end connection들에 대한 state가 없다.
네트워크 수준의 연결개념이 없다.
✍️패킷은 dest host address를 이용해서 forward한다.
overview of network layer
✍️data plane(데이터 평면)
- 네트워크에서 데이터를 전송하는 데 사용되는 물리적 경로이다. 데이터 평면은 네트워크 장비에서 패킷을 전달하는 데 사용되는 라우팅 및 스위칭 프로세스를 의미한다. 이러한 프로세스는 주로 라우터, 스위치, 방화벽 등의 네트워크 장비에서 처리된다.
- forwarding을 한다.
- local,router별 기능이다.
- router input port에 도착하는 데이터그램이 router output port로 forward하는 방법을 결정한다.
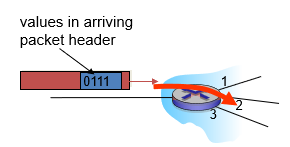
ouput 1,2,3중 어디로 갈지 결정
✍️control plane
- 제어 평면은 네트워크 장비 간에 라우팅 및 스위칭 결정을 수행하는 논리적 프로세스이다. 제어 평면과 데이터 평면의 분리는 일반적으로 네트워크의 확장성과 유지 관리를 개선하는 데 도움이 된다.
- network-wide logic
- source host에서 dest host로 어떤 라우터를 거쳐가 가야할지 결정
- control plane 접근방식 두가지
traditional routing algorithm: router에 구현
software-defined networking(SDN): remote server에서 구현
정리하자면, data plane은 어느 output router로 패킷을 내보낼지, control plane은 어느 라우터에서 어느 라우터로 갈지 결정한다.
Pre-Router Control plane
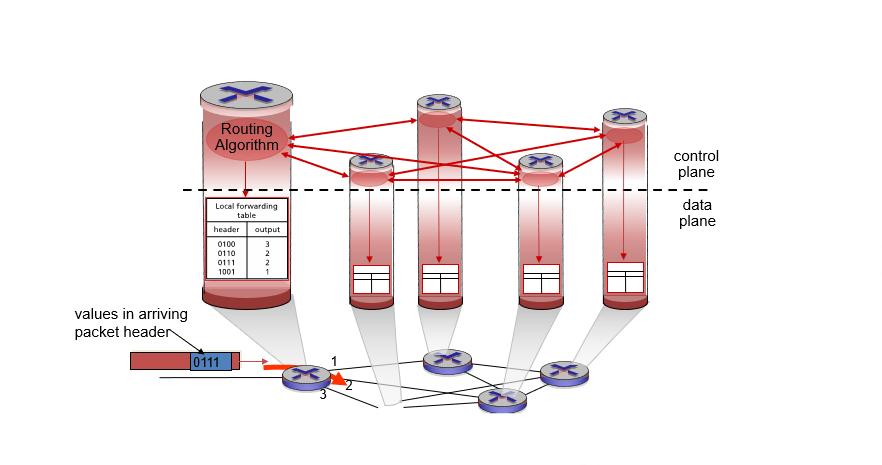
Pre-Control Plane은 네트워크 장비에서 제어 평면과 데이터 평면을 분리하기 전에 사용되던 방식입니다. Pre-Control Plane에서는 각 장비에서 라우팅 프로토콜이 실행되어 다른 장비와 라우팅 정보를 교환하고, 라우팅 테이블을 구축하고 유지합니다.
Pre-Control Plane은 일반적으로 네트워크가 작고 단순한 경우에 사용됩니다. 대규모 네트워크에서는 Pre-Control Plane에서 발생하는 라우팅 정보의 중복, 불일치 및 일관성 문제가 있다.
centralized Control plane
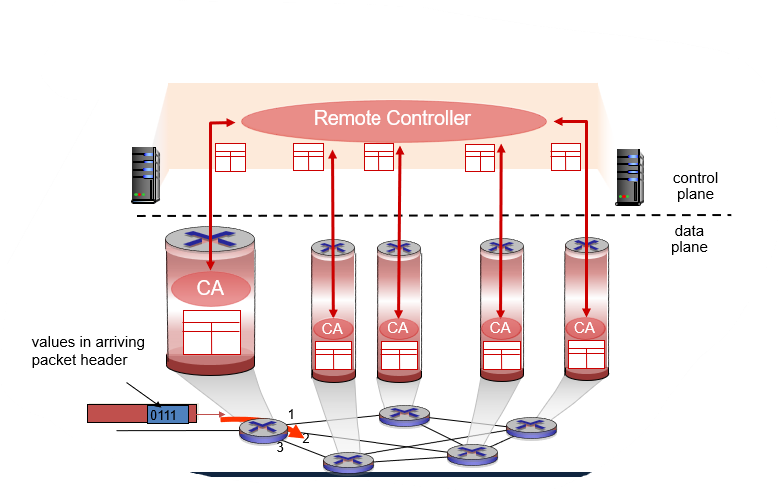
중앙 집중식 제어 평면(Centralized Control Plane)은 네트워크에서 모든 제어 작업이 단일 컨트롤러 노드에서 수행되는 아키텍처이다. 이 아키텍처는 전체 네트워크에서 일관된 정책 및 구성 관리를 제공할 수 있다.
중앙 집중식 제어 평면은 일반적으로 소프트웨어 정의 네트워크(SDN)에서 사용된다. SDN은 네트워크에서 데이터 평면과 제어 평면을 논리적으로 분리하여, 네트워크를 더 유연하고 관리하기 쉽게 만들 수 있다. 중앙 집중식 제어 평면은 SDN에서 중요한 요소 중 하나이다.
Router 내부
router architecture
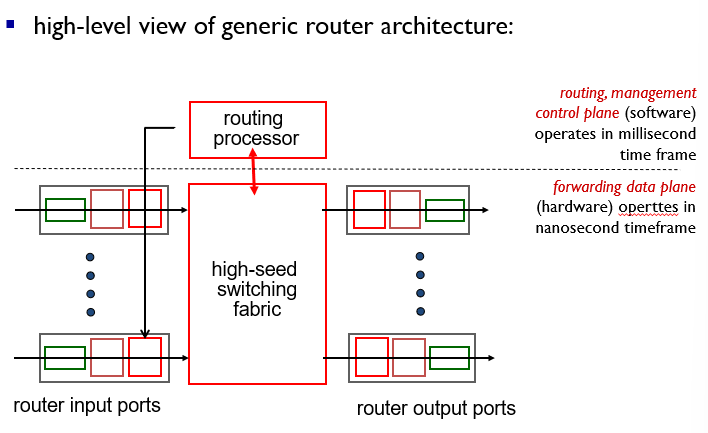
input port functions
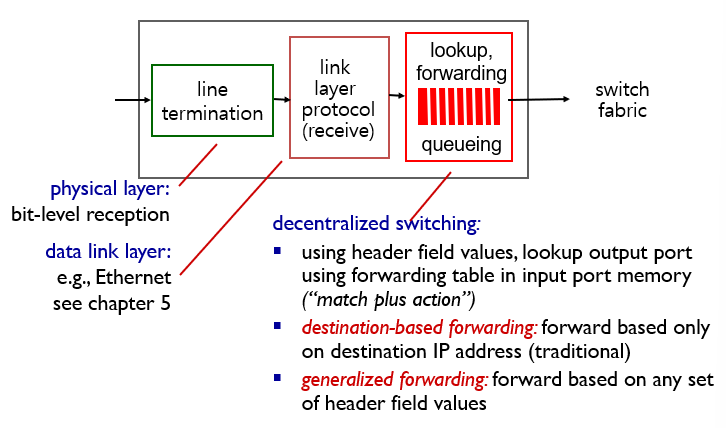
Input Port Function은 스위치나 라우터와 같은 네트워크 장비에서 패킷을 수신하는 포트에서 수행되는 기능이다. 이 기능은 패킷을 처리하여 데이터 평면으로 전달하는 역할을 한다.
Input Port Function에는 다음과 같은 기능이 포함된다.
- 물리적인 신호를 전기 신호로 변환하고, 수신된 패킷을 디코딩하여 데이터 링크 계층에서 사용되는 비트를 추출한다.
- 패킷의 목적지 주소를 확인하고, 목적지 주소를 기반으로 라우팅 결정을 수행한다.
- 패킷의 우선 순위를 확인하고, 우선 순위에 따라 큐잉을 수행한다.
- 패킷을 버리거나 포워딩할 포트를 결정하고, 해당 포트로 패킷을 전달한다.
Input Port Function은 네트워크 장비에서 매우 중요한 기능 중 하나이며, 빠르고 정확한 처리가 요구된다.
Destination-Based Forwarding
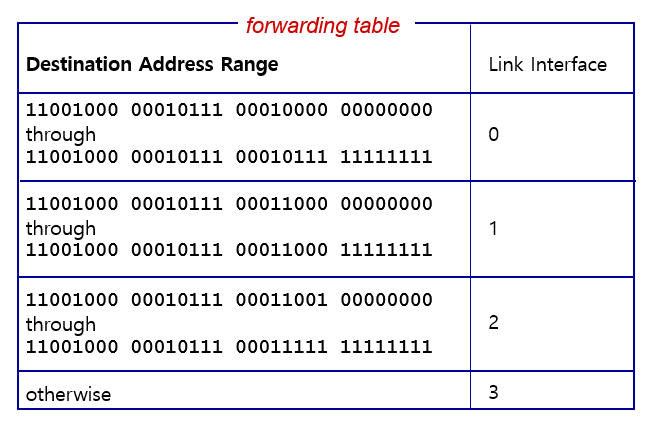
🤔 만약 도착 주소 범위가 깔끔하게 나눠지지 않는다면 무슨일이 일어날까?
✍️Destination-based forwarding에서 대상 주소 범위가 깔끔하게 분할되지 않으면 라우팅 결정이 더 복잡해질 수 있습니다. 대상 주소 범위가 균등하게 분할되지 않으면 일부 경로는 더 많은 트래픽을 처리하게 되고, 다른 경로는 덜 사용될 수 있습니다. 이러한 불균형은 네트워크의 성능을 저하시키고, 일부 경로에서 병목 현상이 발생할 수 있습니다.
따라서 대상 주소 범위를 균등하게 분할하기 위해 가장 일반적인 방법은 가장 긴 접두사 일치(Longest Prefix Match)를 사용하는 것입니다. 이를 통해 각 경로가 최대한 균등하게 분할되어 트래픽이 분산될 수 있습니다.
Longest-prefix Match

가장 긴 접두사 일치(Longest Prefix Match)는 라우팅 테이블에서 패킷의 대상 주소와 가장 일치하는 라우팅 엔트리를 찾는 과정이다. 이를 통해 패킷이 올바른 경로로 전달된다.
가장 긴 접두사 일치를 수행하려면 라우팅 테이블의 모든 엔트리를 대상 주소와 비교해야 한다. 이때 대상 주소는 이진 트리 형태로 구성된 라우팅 테이블을 순회하면서 검색한다. 이진 트리에서는 각 노드가 하위 노드의 비트 값과 다음 노드로 이동할 방향을 나타내는 비트를 포함한다.
예를 들어, 대상 주소가 192.168.1.100인 경우, 이진 트리에서 첫 번째 노드는 192로 시작하는 엔트리를 가리키고, 다음 노드는 168로 시작하는 엔트리를 가리킵니다. 이 과정을 대상 주소와 일치하는 노드가 나올 때까지 계속 반복합니다. 가장 긴 접두사 일치를 찾으면 해당 엔트리에 지정된 인터페이스로 패킷을 전달합니다.
Switching Fabrics
Switching rate는 스위치나 라우터와 같은 네트워크 장비에서 패킷을 처리하는 속도를 의미한다. 즉, 장비가 패킷을 수신하고, 처리하고, 전달하는 데 걸리는 시간이다. Switching rate는 일반적으로 패킷의 크기와 처리 방식에 따라 달라진다.
반면, Line rate는 네트워크 링크에서 전송 가능한 최대 데이터 속도를 의미한다. 이는 링크의 대역폭과 데이터 전송 방식에 따라 달라진다. 예를 들어, 1Gbps 링크의 Line rate는 1Gbps이다.
Switching rate는 장비가 패킷을 처리하는 속도를 나타내고, Line rate는 링크에서 전송 가능한 최대 데이터 속도를 나타낸다.
switching rate는 입력 포트 수에 비례해서 증가하지만,
Line rate는 입력포트 수와 무관하게 일정하다.
예를 들어, 10개의 입력 포트를 가진 스위치에서 Switching rate가 1Tbps이고, Line rate가 10Tbps이라면, 적절한 속도 비율은 1:10이다. 하지만, 입력 포트의 수가 100개인 스위치에서는 Switching rate가 10Tbps로 증가하지만, Line rate는 여전히 10Tbps이므로 적절한 속도 비율은 1:1이 된다.
🤔Switching rate가 입력 포트의 수(N)에 비례하여 증가하는 이유?
입력 포트가 많을수록 스위치나 라우터에서 처리해야 할 패킷의 양이 많아지기 때문이다.
예를 들어, 4개의 입력 포트를 가진 스위치에서는 4개의 입력 포트로부터 들어오는 패킷을 처리해야 하지만, 8개의 입력 포트를 가진 스위치에서는 8개의 입력 포트로부터 들어오는 패킷을 처리해야 한다. 따라서, 입력 포트의 수가 증가할수록 처리해야 할 패킷의 양이 증가하게 되고, 이에 따라 Switching rate가 증가하게 된다.
하지만, 입력 포트의 수가 증가할수록 Switching rate가 선형적으로 증가하지는 않는다. 이는 입력 포트의 수가 증가할수록 스위치나 라우터에서 처리해야 할 패킷의 양이 증가하지만, 장비의 처리 용량이 한계를 가지기 때문이다.
N개의 input이 있을때,
- 다음과 같이 세가지 타입의 switching fabric들이 있다.
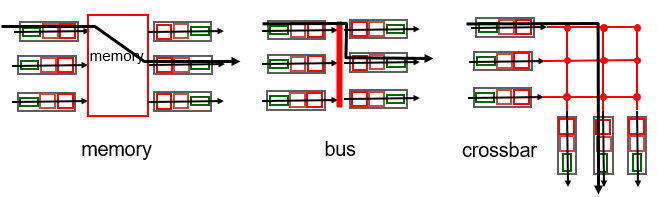
switching via memory
✍️1세대 라우터
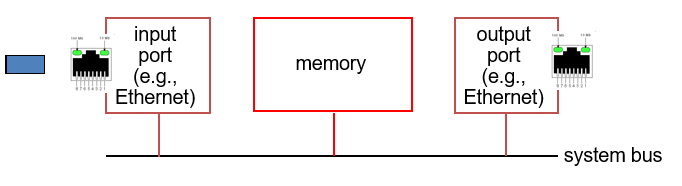
-
cpu가 직접제어하는 switching을 가지는 컴퓨터
-
system의 memory에 패킷을 복사
-
momory bandwidth에 의해 속도가 제한된다.
🤔momory bandwidth?
Memory bandwidth는 메모리 시스템에서 데이터를 전송할 수 있는 속도를 나타내는 지표입니다. 일반적으로 초당 전송 가능한 데이터 양으로 측정됩니다. 높은 메모리 대역폭은 시스템의 성능을 향상시키는 데 중요합니다. -
datagram 하나당 2개의 버스가 지나간다.
switching via bus
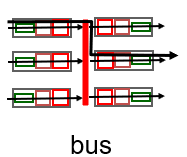
- shared bus를 통해서 input port memory에서 output port memory로 가는 datagram
- bus connection: switching bus는 bus bandwidth 에의해 제한된다.
- access router, enterprise router의 충분한 속도는 32Gbps bus, Cisco 5600이다.
액세스 라우터는 일반적으로 인터넷에 연결된 사용자 또는 장치에 대한 로컬 네트워크 연결을 제공하는 데 사용되며, 기업 라우터는 기업의 네트워크 트래픽을 관리하고 보안을 제공하는 데 사용됩니다. 따라서, 충분한 속도는 이러한 라우터가 효과적으로 작동하고 빠른 데이터 전송을 제공할 수 있도록 보장합니다.
switching via Crossbar
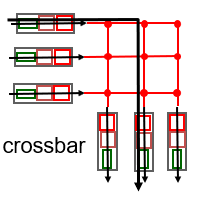
- bus bandwidth 한계를 극복할 수있다.
- banyan network,cross bar 그리고 다른 interconnection net들은 multiprocessor에서 processor들에게 연결하기 위해 개발되었다.
- advanced design:
고정된 길이의 cell들로 datagram을 fragmenting하고, fabric을 통해서 cell들을 switch한다. - Cisco 12000: interconnection network를 통해서 60Gps로 switch 한다.
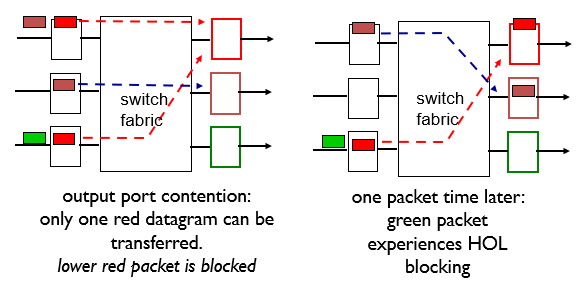
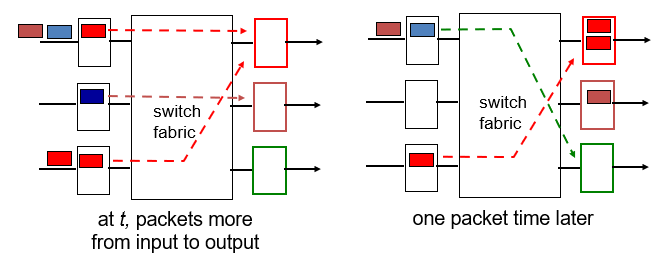
input port queuing
input port에 있는 datagram이 fabric을 통해서 output port로 이동하려고 하는데, 서로 다른 input port에서 동시에 같은 output port로 접근할때, 둘다 갈 수 없으므로, lower packet은 block된다.
그렇게 되면 block된 queue쪽에서는 delay가 일어나게 된다.
queue에 head가 뒤에 있는 다른 queue들을 막아서 delay 되는것을 Head-of-the-Line(HOL) blocking 이라고 한다.
output port queuing
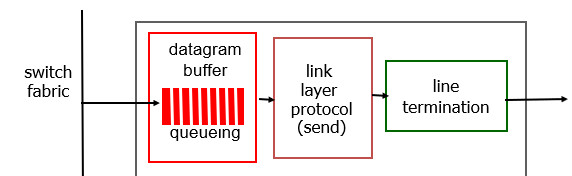
-
congestion이 발생했을때, buffer가 부족해진다면 datagram loss가 일어날 수도 있다.
-
buffering이 발생하는 경우는, output port의 이동속도보다 더 빠르게 fabric으로 부터 datagram이 도착할경우이다.
-
대기중인 datagram들중에서 scheduling 하는 방법은 priority scheduling이다. 즉, performance가 좋은것을 먼저 scheduling 한다.
-
input port에서 fabric을 통해 같은 output port에 도착하는 datagram이 있을때, datagram들을 output port에 buffer에 queue 형태로 저장해 놓는다.
-
datagram의 output port로의 도착 속도가 output line speed보다 빠르다면 buffering이 생기게 된다.
만약, ouputport의 buffer가 overflow 된다면 datagram이 손실될 수 있다.
Scheduling mechanisms
scheduling은 link로 보낼 다음 패킷을 선택하는것이다.
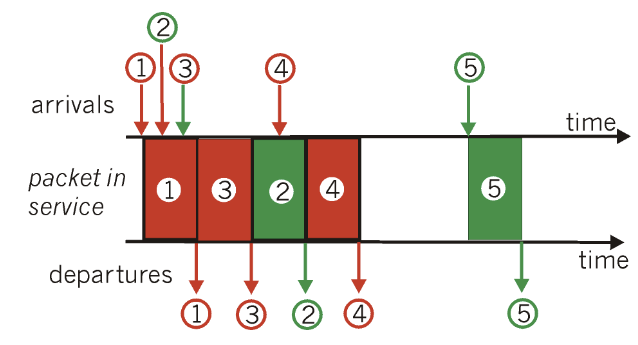
FIFO

FIFO(First In First Out)scheduling은 queue에 도착한 순서대로 내보내는 것이다.
discard policy: 꽉 차있는 queue에 패킷이 도착했을때 어떤걸 지워야할까?
- tali drop: 도착한 패킷을 제거
- priority: 가장 priority가 낮은 것을 제거
- random: 랜덤으로 제거
schduling: priority
가장 높은 priority를 가지는 대기중인 패킷을 보낸다.
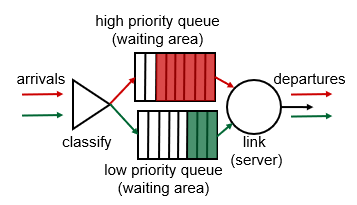
priority에 따라 high priority queue와 low priority queue로 분류된다.
주로 header 정보를 가지고 분류를 하게 된다. IP source/dest, port number등이 그 예이다.
Round Robin(RR scheduling
Round Robin(RR) 스케줄링은 네트워크에서 사용되는 스케줄링 알고리즘 중 하나이다. 이 알고리즘은 여러 대기 중인 작업들 간에 시간을 분할하여 처리하는 방식으로, 각 작업은 일정 시간 동안 CPU 자원을 할당받는다. 이후, CPU는 다른 작업에게 자원을 할당하고, 이전 작업은 대기 상태로 전환된다. 이러한 프로세스가 반복되면서 모든 작업이 처리된다.
네트워크에서 RR 스케줄링은 대부분 트래픽 관리에서 사용된다. 예를 들어, 라우터에서 트래픽을 처리할 때, 여러 개의 패킷이 대기열에 쌓이게 된다. 이때 RR 스케줄링을 사용하면, 각 패킷은 일정 시간 동안 CPU 자원을 할당받아 처리된다. 이러한 방식으로, 모든 패킷이 공평하게 처리된다. 대기열에 쌓인 패킷 중 우선순위가 높은 패킷이 먼저 처리되는 것을 방지할 수 있다.
Weighted Fair Queuing (WFQ)
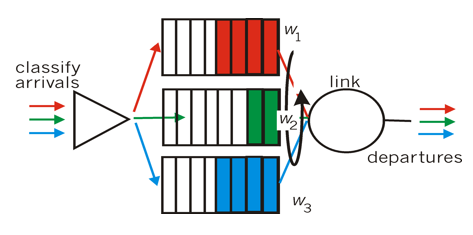
WFQ에서는 각각의 세션 또는 플로우에 대해 가중치를 부여한다. 이 가중치는 세션 또는 플로우의 중요도를 결정하며, 높은 가중치를 가진 세션 또는 플로우는 더 많은 대역폭을 할당받는다. WFQ에서는 각 세션 또는 플로우에 대한 패킷을 여러 개의 가상 큐에 배치하고, 가상 큐에서 패킷을 균등하게 처리하여 대역폭을 공정하게 분배한다.
WFQ는 다양한 네트워크 장비에서 사용되며, VoIP나 스트리밍 등의 대역폭이 중요한곳에 사용된다.
WFQ는 대부분의 라우터에서 지원되며, 다양한 네트워크 환경에서 사용된다. WFQ는 공정성과 우선순위를 모두 고려하는 효율적인 트래픽 관리 알고리즘이며, 대역폭이 한정된 네트워크에서 유용하게 사용된다.
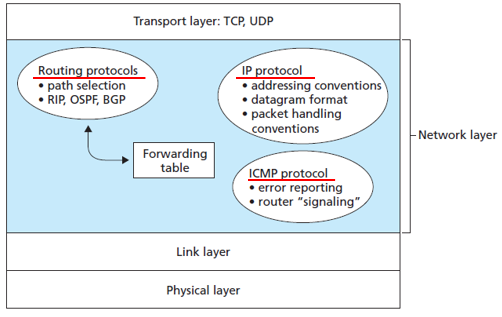
Internet Protocol(IP)
netowrk layer의 주요 구성요소는 다음 세가지 이다.
- IP protocol
- Routing protocol
- ICMP protocol
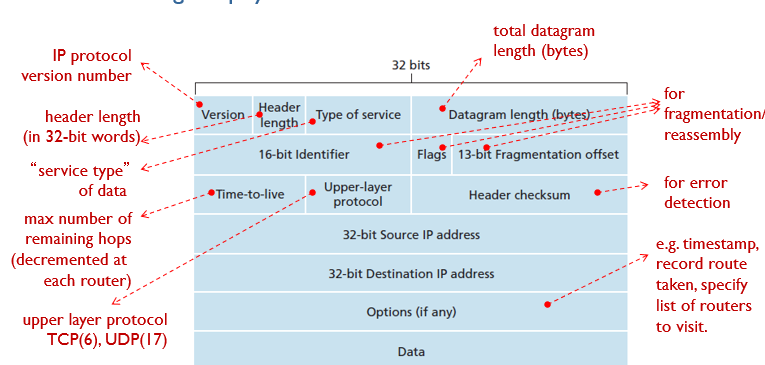
IP datagram format
datagram : network layer packet
🤔 hop?
네트워크에서 hop은 라우터나 스위치와 같은 네트워크 장비를 거치는 것을 의미한다. 데이터 패킷이 출발지에서 목적지로 이동할 때, 중간에 거치는 모든 장비를 1 hop씩 거친다고 한다.
예를 들어, 컴퓨터 A에서 컴퓨터 C로 데이터 패킷을 보내는 경우, 만약 패킷이 라우터 B를 거쳐야 한다면, A에서 B까지 1 hop, B에서 C까지 1 hop이 총 2 hops가 거치게 된다.
hop 수는 대개 네트워크 성능을 평가하는 데 사용된다. 두 지점 사이의 hop 수가 적을수록, 데이터 전송 속도가 더 빠르고 안정적일 가능성이 높다.
MTU(maximum transmission Unit)
link layer frame이 가져갈수있는 데이터의 최대량
경로를 따라 있는 각 링크는 서로 다른 링크 계층 프로토콜을 사용할 수 있으며 프로토콜은 서로 다른 MTU를 가질 수 있다.
IP datagram fragmentation
한 route에서 IP datagram size가 해당 route의 link's MTU를 초과하면 IP datagram은 fragment로 나눠져야 된다. 그리고 fragments는 마지막 도착지에서 재조합된다.
Type of services(ToS)
datagram에 대한 서비스 레벨을 명시한다.
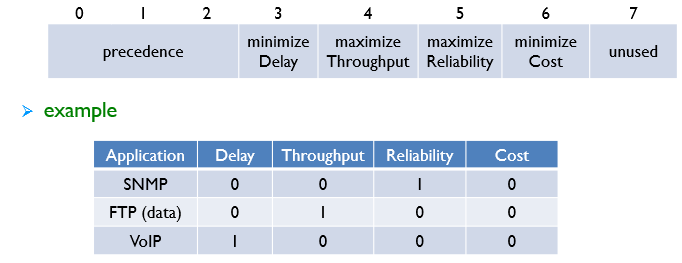
하지만 현대의 router에서는 사용되지 않는다
IP fragmentation and reassembly
✍️IP datagram header에서 연관된 fields
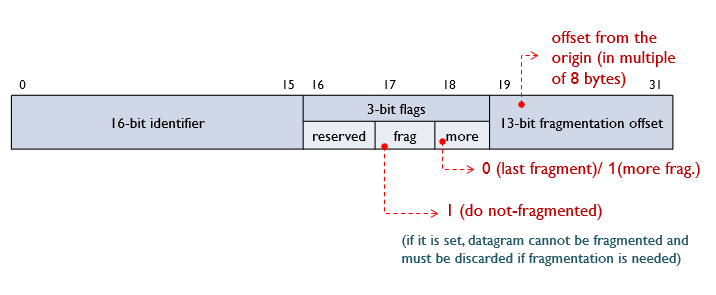
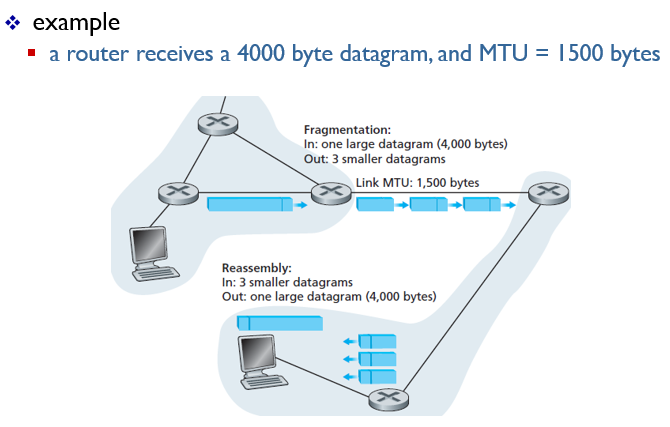
🤔예를들어 한 router가 4000 byte datagram을 받았으며,이 라우터의 MTU는 1500이다.
이 경우에는 datagram이 3조각으로 나뉘어서 다른 라우터로 이동할 것이고, 도착지에서는 3개의 datagram이 reassemble 될것이다.
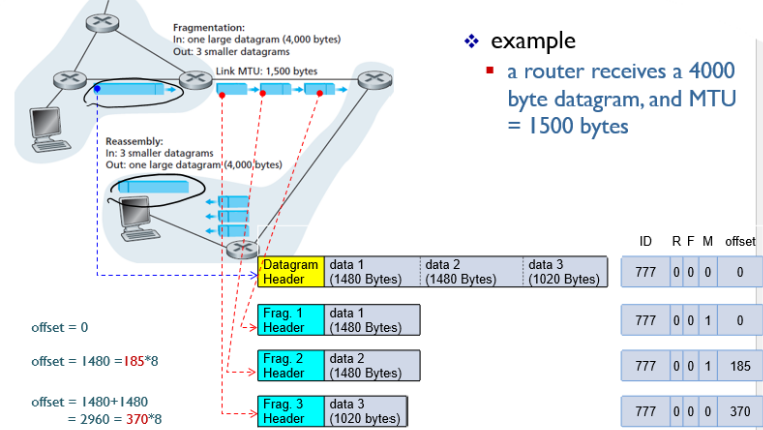
하나의 datagram이 3개의 data로 쪼개지고, 각각의 data에 fragment header를 붙였다. 그리고 각 header에는 ID(같은 데이터인지 구분), M(1이면 뒤에 붙을 추가 데이터 있음/0이면 뒤에 붙을 추가 데이터 없음),offset(데이터 조각의 순서)가 포함되어 있다.
reassemble 되기 위해서는 각 datagram의 순서를 알아야 한다. 순서를 비교하기 위해 사용하는게 offset인데, 첫번째 fragment는 offset이 0이고 두번째 fragment는 185이다. 185인 이유는 1offset당 8byte이므로, 185*8 = 1480 이기때문이다. 따라서 첫번째 fragment 길이만큼이 offset이된다.
세번째도 같은원리로 두번째 fragment 까지가 offset이므로 (1480+1480)/8 = 370 즉, offset은 370이다.
IP Address
🤔 internet에서 컴퓨터의 각 네트워크 인터페이스에 주어지는 유일한 식별자이다.
🤔 interface
- host,router,physical link 사이의 연결이다.
- router들은 일반적으로 다수의 인터페이스를 갖는다.
- host는 일반적으로 하나 혹은 두개의 인터페이스를 갖는다.(e.g wired Ethernet, wireless 802.11)
🤔IP address in IPv4
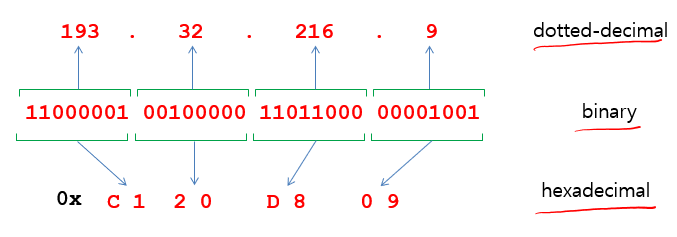
점으로 구별된 10진수 표기법에서 32 bit로 쓰여진다.
ex) 11000001 00100000 11011000 00001001
-> 193 . 32 . 216 . 9
🤔IP address in IPv6
16진수 표기법에서 128bit로 쓰고 colon으로 나눈다.
ex) 3ffe:1900:65455:3:230:f804:7ebf:12c2
각 인터페이스와 연결된 IP 주소
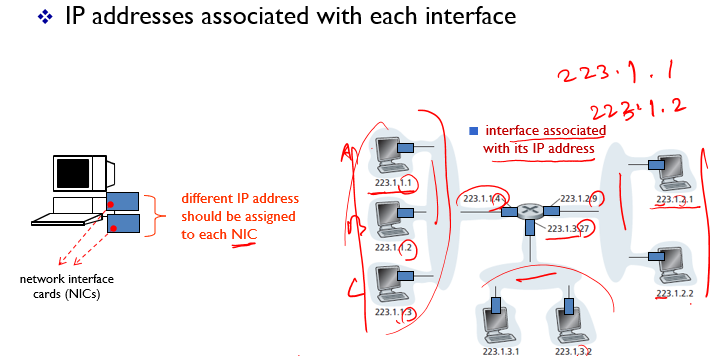
각 컴퓨터에는 network interface cards(NICs) 일명 랜카드가 있다. 이 인터페이스에 서로 다른 ip주소가 할당된다.
IPv4 주소의 두 파트
- network part(network address)
해당 ip주소가 속한 네트워크를 식별하는데 사용된다. - host part
해당 ip 주소가 속한 네트워크 내에서 식별되는 호스트를 나타낸다.
즉 network part는 지역의 network ip주소이고, host part는 우리집의 ip주소라고 생각할 수 있다.
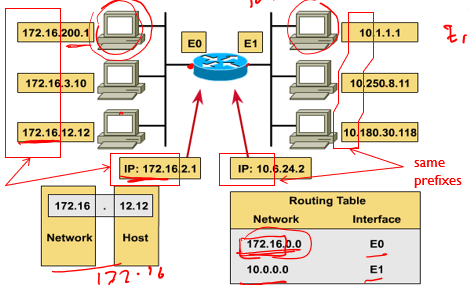
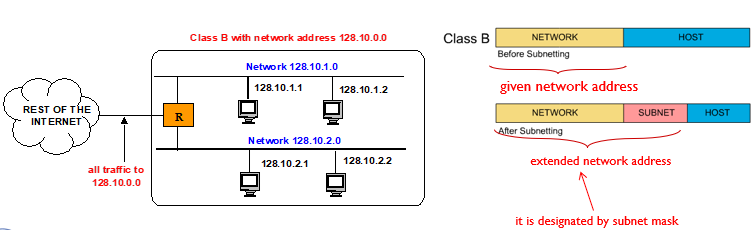
classful IPv4 addressing
- 초기단계
ip address는 두파트: network,host number를 가진다.(최상위 옥텟만 network number로 지정된다.) - 1981년에 classful network address architecture가 소개되었다.
- five classes of A,B,C,D,E
A,B,C classes는 universal unicast addressing
D는 mulicast E는 future use를 위한 것이었다.
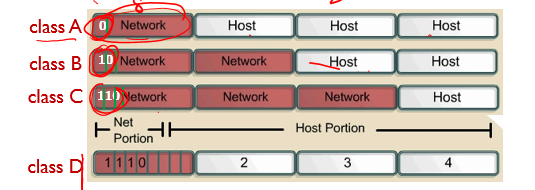
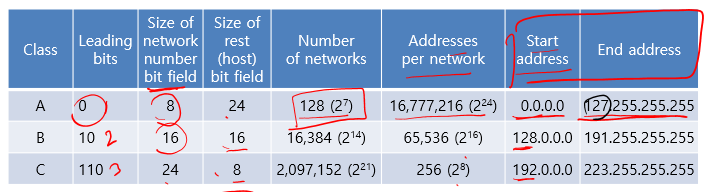
위 그림과 표를 같이 보자.
Leading bits
class A:0 B:10 C:110이다. 클래스가 증가할 때마다 앞에1이 붙는다.
class A를 보면 네트워크 비트 수는 8인데 왜, network의 수는 2^7일까? network portion에 맨첫번째가 Leading bit으로써 1비트를 차지하고 있기 때문이다.
같은 이유로, class B,C도 각각 2^14, 2^21이된다.
network당 address의 수는 host ip의 수를 말하고 network portion을 제외한 나머지 비트로 구한다.
class가 A에서 D로하나씩 이동할때마다 network portion이 하나씩 증가한다.
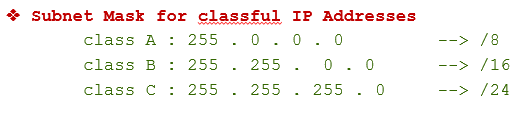
🤔subnet mask?
network portion에대한 비트수이다.
"/number"로 나타낸다.
즉, 네트워크의 비트수를 나타낸것이다.
예를 들어, 192.168.0.0/24라는 IP 주소에서 /24는 서브넷 마스크를 의미하며, 이는 첫 24비트가 네트워크 부분이고 나머지 8비트가 호스트 부분임을 나타낸다. 따라서 이 IP 주소에서 네트워크 부분은 192.168.0이 되고, 호스트 부분은 0이다.
address type
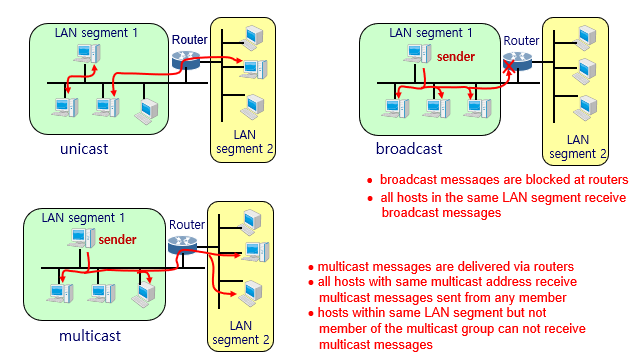
- unicast
- class A,B and C addresses
- point-to-point(1:1) connetcion
- 두 unicast hosts 사이에서는 bi-directional
- Broadcast
- host part는 모두 1이다.
- point-to-multipoint(1:N) unidirectional connection
- broadcast messages는 LAN segment내에 있는 모든 host에 동시에 보내진다. 하지만,LAN router에서는 block 당한다.
즉, 같은 네트워크 상에 있는 host끼리만 통신이 가능하다.
예를 들어, 192.168.0.1과 192.168.0.2는 같은 네트워크 상에 있다. 이는 두 IP 주소가 같은 네트워크 ID인 192.168.0을 가지고 있기 때문이다.
- Multicast
-
class D address
-
group communications에 대한 one-to-many(1:N) unidirectional connection
-
Multicast는 하나의 송신자가 여러 개의 수신자에게 데이터를 전송하는 방식이다. 이는 Broadcasting과는 달리, 전체 네트워크 상의 모든 호스트에게 데이터를 전송하지 않고, 멀티캐스트 그룹에 속한 호스트들만 데이터를 수신할 수 있다.
-
멀티캐스트 그룹은 IP 주소 범위 중 Class D 주소인 224.0.0.0 ~ 239.255.255.255 범위 내에서 할당된다. 이 주소 범위 내에서, 멀티캐스트 주소는 224.0.0.0 ~ 224.0.0.255까지 할당되며, 이는 로컬 네트워크 상에서 사용된다.
-
멀티캐스트는 IPTV, 동영상 스트리밍 등에서 사용되며, 같은 멀티캐스트 그룹에 속한 호스트들끼리만 데이터를 수신하기 때문에, 대역폭을 절약할 수 있다.
public IP addresses
공인 IP 주소는 인터넷 상에서 고유하게 할당되는 IP 주소로, 인터넷 서비스 제공업체(ISP)로부터 할당받는다. 이는 인터넷 상에서 유일한 주소이므로, 인터넷 상에서 컴퓨터나 장치를 식별하는 데 사용된다.
공인 IP 주소는 IPv4와 IPv6 두 가지 버전이 있다. IPv4의 경우, 32비트로 이루어져 있으며, 현재는 대부분의 인터넷 서비스 제공업체에서 고갈되어 IPv6로 전환하고 있다.
공인 IP 주소는 인터넷 상에서 직접 접속 가능하며, 전 세계적으로 고유하다. 이를 통해 인터넷 상에서 컴퓨터나 장치를 식별하고, 다른 컴퓨터나 장치와 통신할 수 있다.
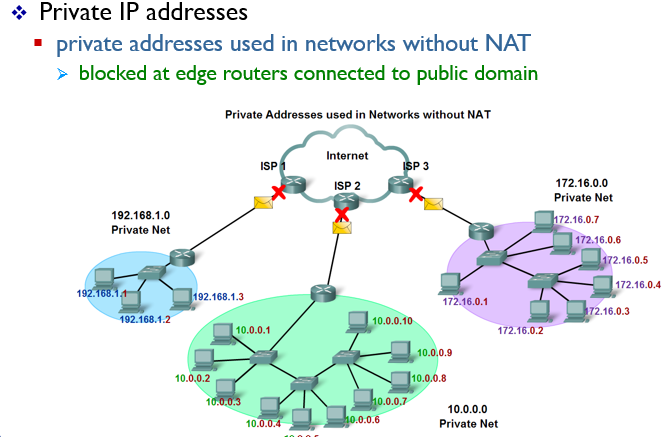
private IP addresses
Private IP 주소는 인터넷 상에서 공인 IP 주소와 구분하기 위해 로컬 네트워크에서 사용되는 IP 주소이다. 이는 인터넷 서비스 제공업체(ISP)에서 할당받은 공인 IP 주소와 달리, 로컬 네트워크에서 직접 할당하거나 DHCP(Dynamic Host Configuration Protocol) 서버를 통해 자동으로 할당된다.
Private IP 주소는 3가지 범위로 나누어져 있다.
첫 번째로, 10.0.0.0 ~ 10.255.255.255 범위 내의 IP 주소는 Class A Private Address로, 대규모 네트워크에서 사용된다.
두 번째로, 172.16.0.0 ~ 172.31.255.255 범위 내의 IP 주소는 Class B Private Address로, 중간 규모의 네트워크에서 사용된다.
세 번째로, 192.168.0.0 ~ 192.168.255.255 범위 내의 IP 주소는 Class C Private Address로, 소규모 네트워크에서 많이 사용된다.
Private IP 주소는 로컬 네트워크 상에서만 유효하며, 인터넷 상에서 직접 접속하려면 NAT(Network Address Translation) 기술을 사용하여 공인 IP 주소로 변환해야 한다. 이를 통해 여러 대의 컴퓨터가 하나의 public IP 주소를 공유하여 인터넷에 접속할 수 있습니다.
Subnets와 subnetting
subnet
서브넷(Subnet)은 IP 네트워크를 더 작은 네트워크로 분할하는 것을 말한다. 이를 통해 네트워크 관리가 용이해지며, 보안성도 향상된다.
서브넷 마스크(Subnet Mask)는 IP 주소의 네트워크 부분과 호스트 부분을 구분하는 역할을 합니다. IP 주소와 서브넷 마스크를 AND 연산하면, 해당 IP 주소가 속한 서브넷의 네트워크 주소를 얻을 수 있다.
예를 들어, IP 주소가 192.168.1.100이고 서브넷 마스크가 255.255.255.0인 경우 and 연산하면, 이 IP 주소는 192.168.1.0/24 서브넷에 속한다는 것을 알 수 있다. 여기서 /24는 서브넷 마스크의 비트 수를 나타내며, 255.255.255.0은 24비트가 1로 설정된 것입니다.
서브넷을 사용하면, 하나의 대규모 네트워크를 여러 개의 작은 네트워크로 분할하여 관리할 수 있으며, 보안성도 향상됩니다.
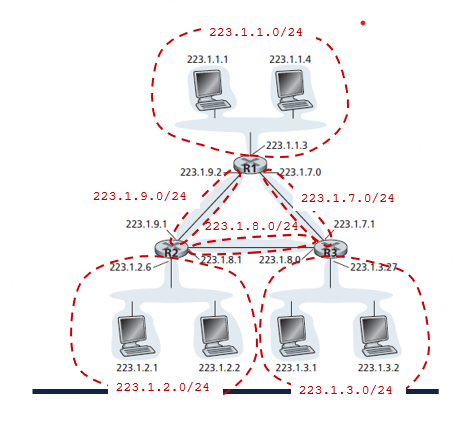
subnetting
단일 IP network address를 더작은 subnetworks로 나눠주기위해 사용되는 기술
- 모든 hosts은 subnet addressing을 위해 필요하다.
- 서브넷팅을 통해 사이트는 여러 물리적 네트워크 간에 하나의 인터넷 주소를 공유할 수 있다.
b가 subnetting을 위해 쓸 bit의 수라면 사용가능한 subnet은 2^b개 이다.
r이 남아있는 host bits의 수라면 사용가능한 host는 2^r-2이다.
🤔그렇다면 host는 왜 2개를 빼야될까?
그 이유는 1. host part에서 전부 0인 부분은 network 자신이 쓰고,
2. host part에서 전체가 1인 부분은 broadcast address이다.
예를들어,
5개의 subnet을 만들기위해, 빌려와야 하는 bit의 최소 수는 3이다 2^3 =8 >5
CIDR(Classless InterDomain Routing)
- 임의 길이 주소의 subnet 부분
- address format:a.b.c.d/x, x가 주소의 서브넷 부분의 비트수이다.

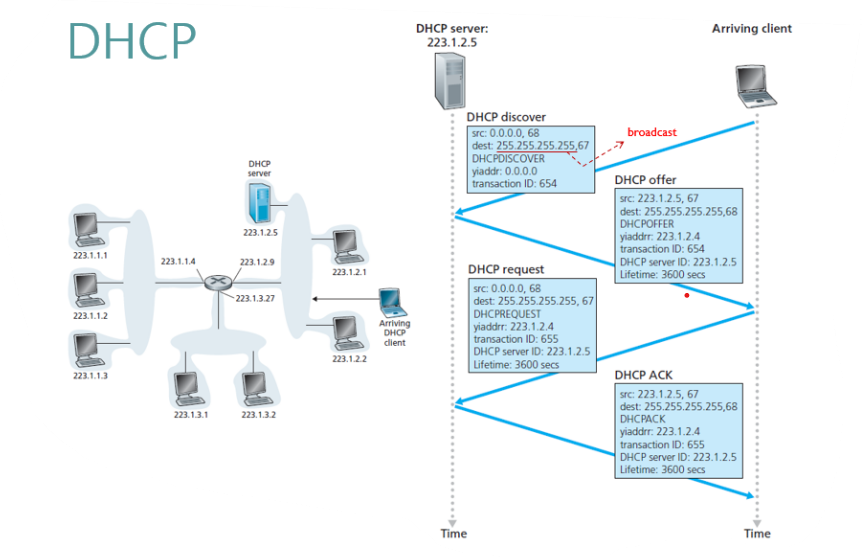
Network Layer Support protocols - DHCP
🤔DHCP(Dynamic Host Configuration Protocol)는 클라이언트가 네트워크에 접속할 때 자동으로 IP 주소, 서브넷 마스크, 기본 게이트웨이 등의 네트워크 정보를 할당해주는 프로토콜이다.
- 사용 중인 주소에 대한 임대를 갱신할 수 있습니다
- 주소들을 재사용하게 해준다.(연결이 켜져있는 동안에 주소를 유지한다.)
- network에 참여하길 원하는 모바일 유저를 지원한다.(더빠르게)
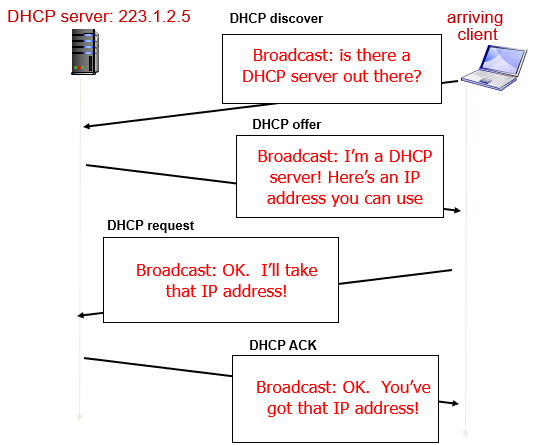
🤔DHCP 작동 개요
클라이언트는 네트워크에 접속하면 DHCP Discover 메시지를 브로드캐스트한다. DHCP 서버는 이를 수신하면 DHCP Offer 메시지를 클라이언트에게 보내며, 이 메시지에는 IP 주소, 서브넷 마스크, 기본 게이트웨이 등의 정보가 포함된다.
클라이언트는 이 정보를 확인한 후 DHCP Request 메시지를 보내며, 이를 수신한 DHCP 서버는 DHCP Acknowledge 메시지를 클라이언트에게 보내 IP 주소를 할당한다. 클라이언트는 이를 확인한 후 할당받은 IP 주소를 사용하여 네트워크에 접속한다.
DHCP Format
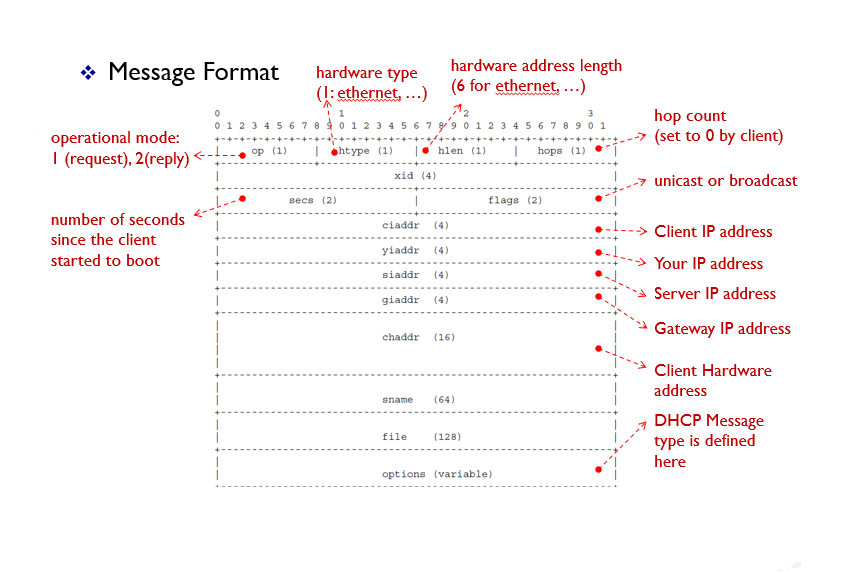
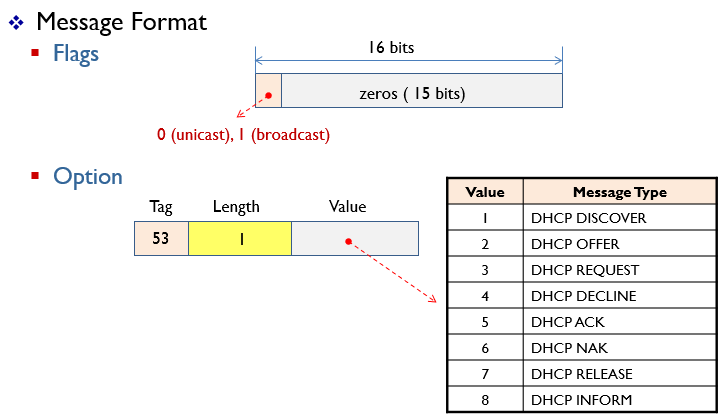
Message Format
DHCP가 IP 말고도 줄 수 있는것
DHCP는 서브넷에 할당된 IP 주소 말고도 더 많은것을 반환할 수 있다.
- 클라이언트의 첫번째 hop 라우터 주소
- DNS server의 name과 IP address
- network mask
🤔network mask란?
네트워크 마스크(Network Mask)는 IP 주소의 네트워크 부분과 호스트 부분을 구분하는 역할을 합니다. 이를 통해 IP 주소가 속한 네트워크를 식별할 수 있습니다.IPv4에서 네트워크 마스크는 32비트로 이루어져 있으며, 보통 255.255.255.0과 같은 형태로 표현됩니다. 이는 32비트 중에서 네트워크 부분이 1로, 호스트 부분이 0으로 설정되어 있음을 나타냅니다.
예를 들어, IP 주소가 192.168.1.100이고 네트워크 마스크가 255.255.255.0인 경우, 이 IP 주소는 192.168.1.0/24 네트워크에 속한다는 것을 알 수 있습니다. 이는 IP 주소의 처음 24비트가 네트워크 부분으로 사용되고, 나머지 8비트가 호스트 부분으로 사용되기 때문입니다.
네트워크 마스크는 서브넷(Subnet)을 구분하는 데도 사용됩니다. 서브넷 마스크(Subnet Mask)는 IP 주소의 네트워크 부분과 호스트 부분을 더 작은 네트워크로 분할하는 데 사용됩니다.
DHCP relay
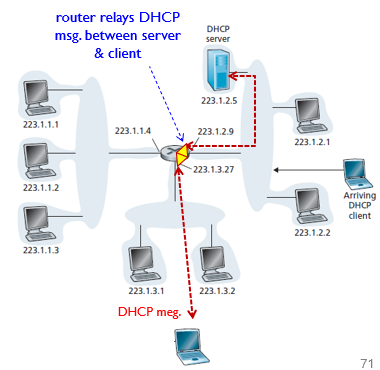
DHCP Relay는 DHCP 클라이언트와 DHCP 서버가 서로 다른 네트워크에 위치한 경우, DHCP Discover 메시지를 브로드캐스트하여 DHCP 서버를 찾을 수 없는 문제를 해결하기 위한 프로토콜입니다.
DHCP Relay는 네트워크의 경계를 넘어 DHCP Discover 메시지를 전달하는 역할을 합니다. 이를 위해 라우터나 스위치 등의 장비에 DHCP Relay 에이전트를 설치해야 합니다. DHCP Relay 에이전트는 DHCP Discover 메시지를 브로드캐스트한 클라이언트의 IP 주소와 MAC 주소를 유지하며, 이를 DHCP 서버에 전달합니다.
DHCP 서버는 DHCP Relay 에이전트로부터 받은 DHCP Discover 메시지에 대해 DHCP Offer 메시지를 만들어 DHCP Relay 에이전트로 전송합니다. DHCP Relay 에이전트는 이를 다시 클라이언트에게 전달합니다. 이 과정에서 DHCP 서버와 클라이언트는 서로 다른 네트워크에 있더라도 IP 주소 등의 네트워크 정보를 주고 받을 수 있습니다.
Network Layer Support Protocols - NAT
NAT(Network Address Translation)
NAT는 private IP 주소를 public IP 주소로 변환하여 하나의 public IP 주소로 여러 대의 private 네트워크 장치에 접속할 수 있도록 해주는 프로세스이다. 일반적으로, NAT는 라우터에서 구현되며, 라우터는 private 네트워크와 public 네트워크 간의 중개자 역할을 담당한다. 라우터는 private 네트워크에서 나가는 패킷의 출발지 IP 주소를 public IP 주소로 변환하고, public 네트워크에서 들어오는 패킷의 목적지 IP 주소를 private IP 주소로 변환한다.
인터넷에 접속할 때, private IP 주소를 가진 호스트에서 나가는 패킷은 public IP 주소를 가진 라우터의 IP 주소로 바뀌어 인터넷 상에서 유효한 주소로 인식된다. 그리고 인터넷 상에서 들어오는 패킷은 라우터에서 private IP 주소로 바뀌어서 private 네트워크 내의 호스트에 전달된다.
Network Layer Support Protocols-ICMP
🤔ICMP(Interent Control Message Protocol)란?
ICMP(Internet Control Message Protocol)는 인터넷 프로토콜 스위트(IP)에서 사용되는 제어 메시지 프로토콜이다. ICMP 메시지는 네트워크 장애 진단, 라우팅 문제 해결, 패킷 전송 실패 알림 등의 목적으로 사용된다.
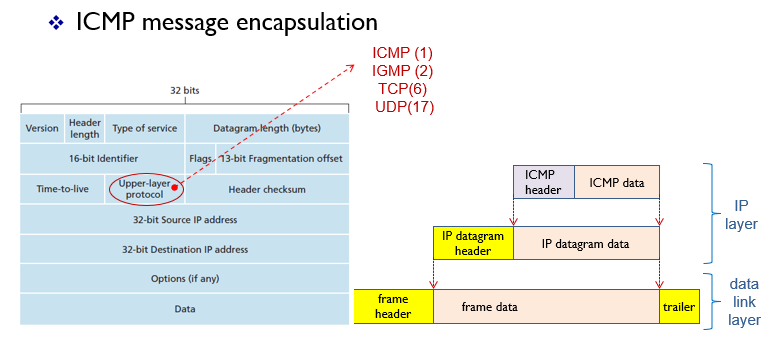
ICMP는 IP 패킷을 이용하여 전송되며, IP 패킷의 데이터 부분에 포함된다. ICMP 메시지는 대부분 IP 패킷 손상, 목적지 도달 불가능, TTL(Time to Live) 초과 등의 오류를 알리는 데 사용된다. 또한, ICMP Echo Request와 Echo Reply 메시지를 이용하여 네트워크 장비 간의 연결 상태를 확인하는 데에도 사용된다. 이러한 ICMP 메시지는 네트워크 관리자가 네트워크 상태를 모니터링하고 문제를 해결하는 데에 매우 유용하게 사용된다.
🤔ICMP의 위치는?
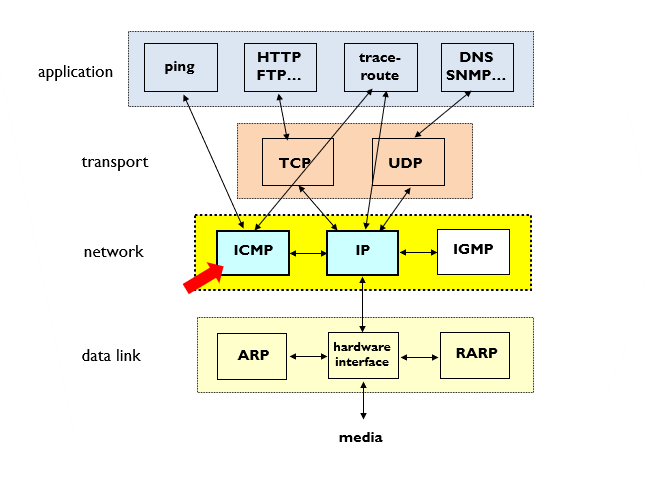
🤔message format

🤔ICMP message encapsulation
🤔ICMP - ping
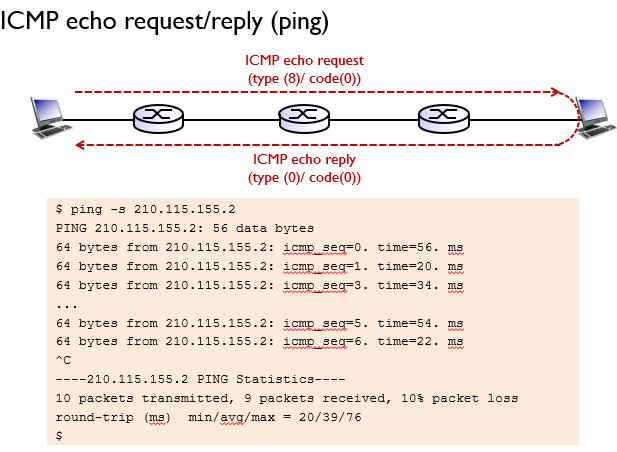
ICMP의 Echo Request와 Echo Reply 메시지를 이용하여 네트워크 장비 간의 연결 상태를 확인하는 것을 'ping'이라고 한다.
ping 명령어를 사용하여 호스트 이름이나 IP 주소를 입력하면, 해당 호스트가 응답하는지 여부와 응답 시간 등의 정보를 확인할 수 있다. ping 명령어는 대부분의 운영 체제에서 지원되며, 네트워크 문제점을 진단하는 데 유용하게 사용된다.
ping 명령어는 목적지 호스트에 ICMP Echo Request 패킷을 보내고, 해당 호스트가 이를 수신하면 ICMP Echo Reply 패킷을 송신자에게 반환한다. 이 때, 송신자는 반환된 ICMP Echo Reply 패킷을 수신하여 목적지 호스트와의 연결 상태를 판단하게 된다.
ICMP-traceroute
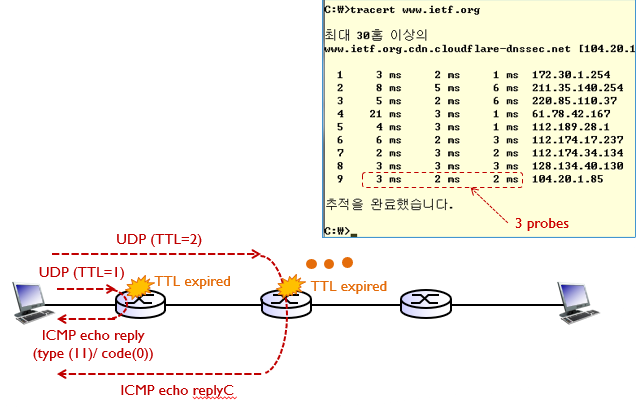
ICMP의 TTL(Time to Live) 필드를 이용하여 네트워크 경로 상의 라우터들을 추적하는 것을 'traceroute'라고 한다.
traceroute 명령어를 사용하여 목적지 호스트에 도달하는 데 거쳐가는 라우터들의 IP 주소와 응답 시간 등의 정보를 확인할 수 있다. traceroute 명령어는 대부분의 운영 체제에서 지원되며, 네트워크 문제점을 진단하는 데 유용하게 사용된다.
traceroute 명령어는 ICMP Echo Request 패킷을 보내고, TTL 값을 점차 증가시켜서 목적지 호스트까지 도달하는 데 거쳐가는 라우터들의 IP 주소를 추적한다. 이때, TTL 값이 각 라우터에서 1씩 감소하며, TTL 값이 0이 되면 해당 패킷은 폐기된다. 이를 통해, 각 라우터가 패킷을 전달하는 데 소요되는 시간을 계산할 수 있다.
IP
IPv6
🤔IPv6가 생겨난 이유
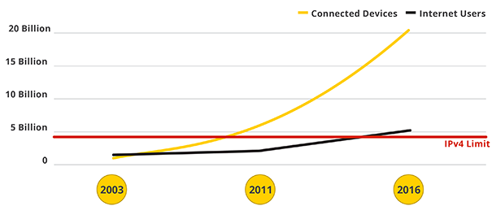
- IPv4의 메모리 고갈이 예상되면서 대책을 찾게 되었다.
- header format이 processing/forwarding에 도움을 준다.
- Oos를 용이하게 하기 위한 헤더 변경
😎Oos란?
OOS(Out of Service)는 일반적으로 시스템, 장비 또는 서비스가 작동하지 않거나 서비스를 제공하지 못하는 상태를 나타내는 용어입니다.
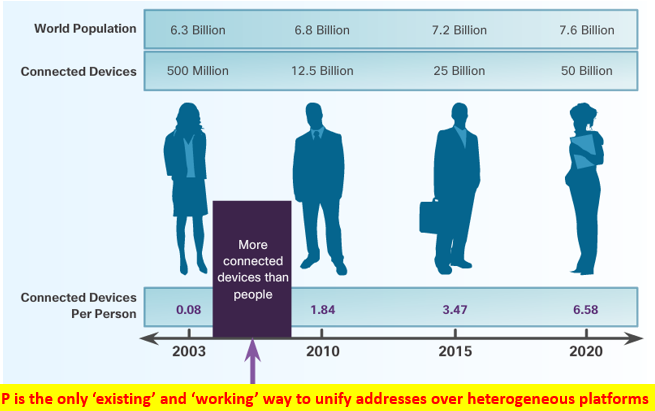
한사람당 network에 연결된 device수가 점점 증가하고 있다.
🤔IPv6 주소
- 16진수로 나타내며 128bit이고, colon으로 구별한다
ex) 3ffe:1900:65455:3:230:f904:7ebf:12c2 - IPv4는 2^32만큼의 IP address수가 있었고, IPv6는 2^128 만큼의 IP address가 있다.
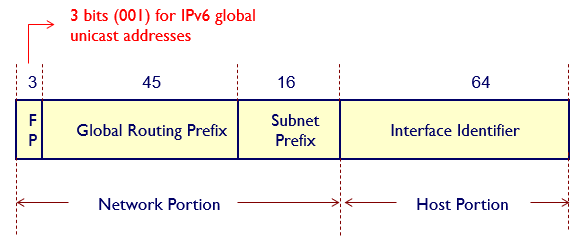
🤔IPv6의 unicast address format
- IANA가 할당한다.
🤔IPv6 datagram
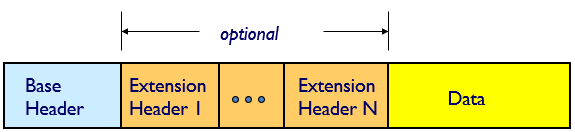
- base header는 40 byte 고정
- Extension header
- optional internet layer 정보를 가져온다.- base header와 upper-layer protocol header 사이에 위치한다.
- options에서 IPv4의 40-byte 제한을 제거
🤔IPv6 header
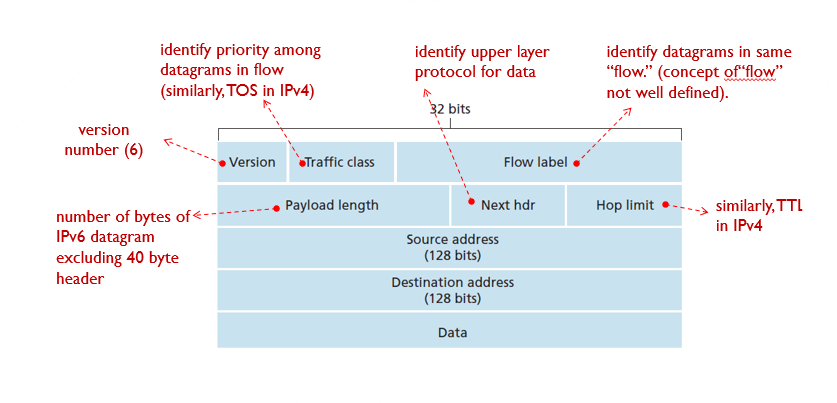
- fragmentation이 허용되지 않는다.
- 각 hop에서 processing 시간을 줄이기 위해 checksum을 삭제했다.
- flow labeling 및 우선 순위 개념이 채택되었다.
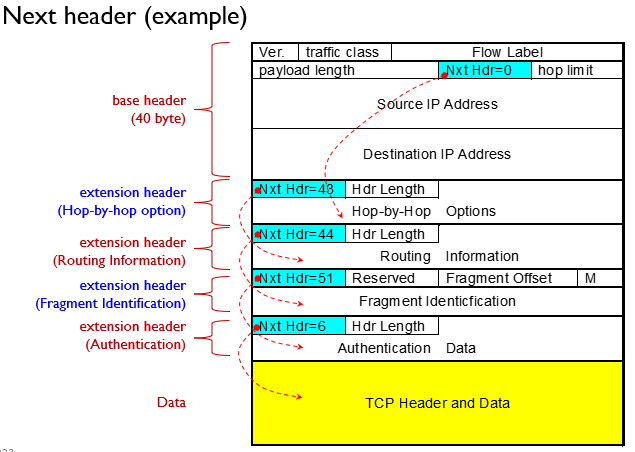
🤔Next header

🤔Ipv6 transition 전략
1. Dual stack
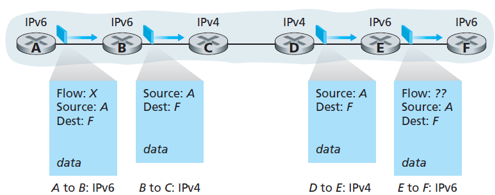
- IPv6 node들은 완성된 IPv4를 구현체를 갖고있다. 이러한 노드를 "IPv6/IPv4 node"라고 부른다.
- IPv6/IPv4 node는 IPv4와 IPv6 모두에서 send와 receive를 할 수 있다.
- Tunneling approach
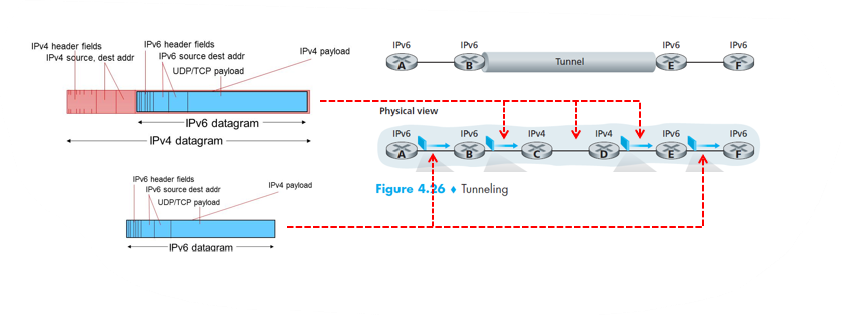
- Tunneling은 인터넷 프로토콜(IP) 기반의 네트워크에서, 하나의 프로토콜 패킷을 다른 프로토콜 패킷으로 캡슐화하여 전송하는 기술이다. 이러한 기술을 사용하면, 서로 다른 네트워크 간에 안전하게 통신할 수 있다.
- IPv6에서 IPv4로, 또는 그 반대로 데이터를 전송하는 기술로도 사용된다. 이를 통해, IPv4와 IPv6 간의 호환성 문제를 해결할 수 있다.
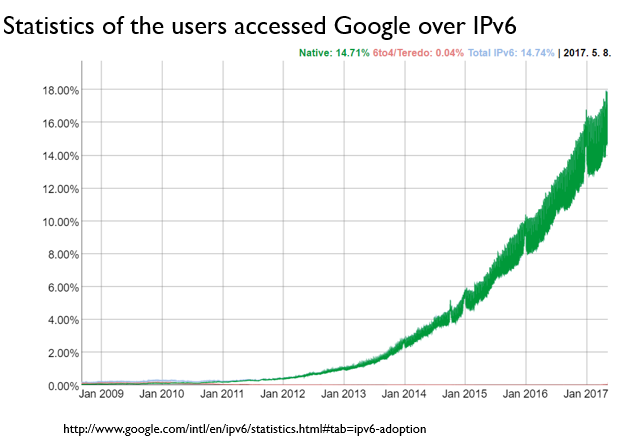
IPv6로 접근하는 비율이 점점 상승하고 있다.
