Network Layer - Control Plane
pre-router control plane
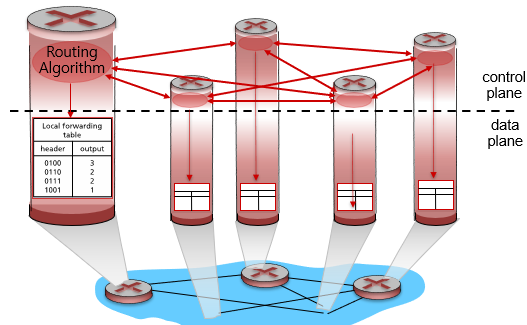
Pre-Router Control Plane은 네트워크에서 데이터 패킷을 전송하기 전에 라우터에서 수행되는 제어 작업을 의미합니다. 이러한 제어 작업은 라우터가 제대로 동작하고 네트워크에서 데이터 패킷이 올바르게 전송되도록 보장합니다.
각각의 모든 라우터의 개별 라우팅 알고리즘 구성 요소는 컨트롤 플레인에서 서로 상호 작용하여 포워딩 테이블을 계산합니다.
Pre-Router Control Plane의 기능
-
라우팅(Routing)
라우터는 라우팅 프로토콜(Routing Protocol)을 사용하여 네트워크에서 최적의 경로를 찾아 데이터 패킷을 전송합니다. 이러한 라우팅 작업은 Pre-Router Control Plane에서 수행됩니다. -
스위칭(Switching)
라우터는 스위칭 프로토콜(Switching Protocol)을 사용하여 데이터 패킷을 전송합니다. 이러한 스위칭 작업은 Pre-Router Control Plane에서 수행됩니다. -
QoS(Quality of Service)
라우터는 QoS 기능을 사용하여 네트워크에서 데이터 패킷의 우선순위를 관리합니다. 이러한 QoS 작업은 Pre-Router Control Plane에서 수행됩니다.
Pre-Router Control Plane은 라우터의 제어 작업을 수행하는 중요한 영역이며, 네트워크의 안정성과 성능을 보장하는 데 중요한 역할을 합니다.
Logical Centralized CP(Control Plane)
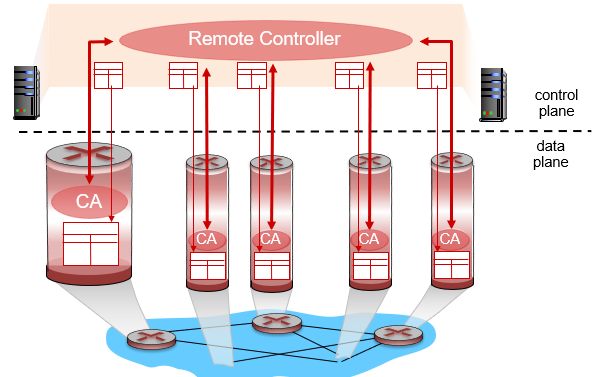
Logical Centralized Control Plane은 분산된 네트워크에서 중앙 집중식으로 제어 작업을 수행하는 제어 평면입니다. 이러한 제어 평면은 네트워크의 전반적인 상태를 모니터링하고, 이를 기반으로 네트워크 장비들의 동작을 조정합니다.
Logical Centralized Control Plane은 SDN(Software-Defined Networking)에서 사용되는 기술 중 하나입니다. 이러한 제어 평면은 네트워크 장비들이 데이터 패킷을 전송하기 전에 최적의 경로를 찾아주는 역할을 합니다. 이를 위해 Logical Centralized Control Plane은 네트워크에서 발생하는 데이터 패킷의 전송 정보를 수집하고, 이를 기반으로 최적의 경로를 계산합니다.
Logical Centralized Control Plane은 분산된 네트워크에서 일관된 정책을 적용하기 위해 필요합니다. 이러한 제어 평면은 네트워크 장비들 간의 통신을 단순화시키고, 관리 작업을 효율적으로 수행할 수 있도록 도와줍니다.
Routing 목표
routing은 라우터를 거쳐서 sending host가 receiving host에게 데이터 패킷을 보낼 수 있는 good path를 결정하는 것입니다.
good 이라는 것은 "가장 적은 비용", "가장 빠른 경로","최소 congest"를 의미합니다.
routing은 현재 network 분야에서 10가지 도전과제 중 하나입니다.
최근에는 인터넷 트래픽이 급격하게 증가하면서, 라우팅 알고리즘의 성능이 더욱 중요해졌다.
network Abstract graph model
Routing 분류
global routing algorithm
네트워크 전체에 대한 완전한 정보를 가지고 출발지와 목적지 사이의 최소 비용 경로를 계산한다. 즉 모든 라우터가 연결 상태와 링크 비용을 알고 있다는 것이다. Link State 알고리즘이 여기에 속하며 주로 다익스트라 알고리즘을 사용한다.
decentralized algorithm
최소 비용 경로의 계산이 라우터들에 의해 반복적이고 분산된 방식으로 수행된다. 어떤 라우터도 모든 링크 비용에 대한 완전한 정보를 갖고 있지 않지만, 각 라우터는 자신에게 연결된 인접 노드에 대한 링크 비용 정보를 알고 있다. 이후 반복된 계산과 인접 노드와의 정보 교환을 통해 목적지까지의 최소 비용 경로를 계산한다. Distance Vector 알고리즘이 여기 속하며 주로 벨만-포드 알고리즘을 사용한다.
static routing algorithm
경로의 변경이 느리고 사람이 직접 링크에 대한 비용을 수정해야 한다. 규모가 큰 네트워크에서 일일이 수정하기 불가능하며 사람이 하기에 역부족이다.
dynamic routing algorithm
네트워크 트래픽 부하나 topology 변화에 따라 라우터가 자체적으로 경로를 바꾼다. 동적 알고리즘은 주기적으로 topology나 링크 비용의 변경에 직접적으로 응답하는 방식으로 수행된다. 동적 알고리즘은 네트워크 변화에 더 빠르게 대응할 수 있지만 경로의 loop나 경로 진동과 같은 문제에 취약하다.
Link state(LS) algorithm
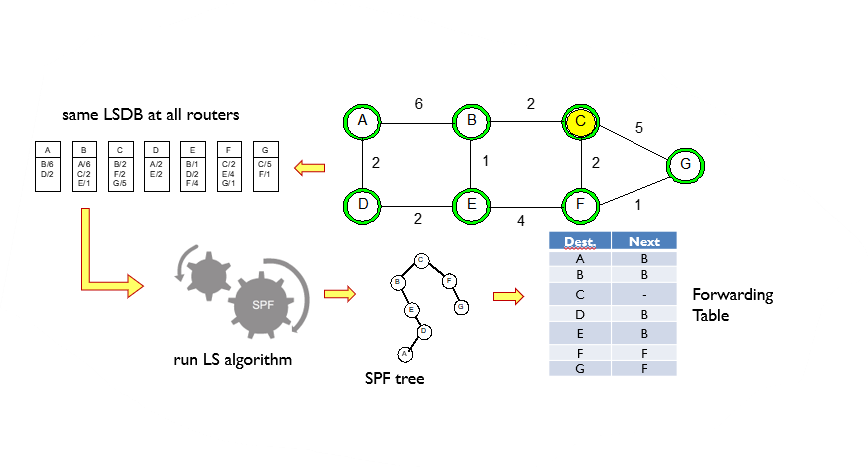
LS 알고리즘은 중앙 집중형 알고리즘에 속한다. 즉 모든 라우터(노드)가 링크(간선)의 비용을 알고 있기 때문에 다익스트라 알고리즘을 이용해 최적의 경로를 계산할 수 있다. 한 노드(source node)에서 다른 모든 노드까지의 최적경로를 계산해 routing table에 저장해 놓는다.
다익스트라 알고리즘
- global 정보를 사용한 알고리즘이다.
- 해당 노드에 대한 forward table을 준다.
- 한 노드에서 모든 다른 노드에 대한 최소 비용 경로를 찾는다.
- c(x,y): node x 에서 y까지 link cost
만약 x에서 y까지 direct link가 없다면 c(x,y) = infinite- D(v): source로부터 dest v까지 경로의 비용의 현재 값
- P(v): v node로 갈때 전 노드가 어디인지
- N' : 최소 비용으로 갈 경로중 정해진 경로를 포함한 집합
example
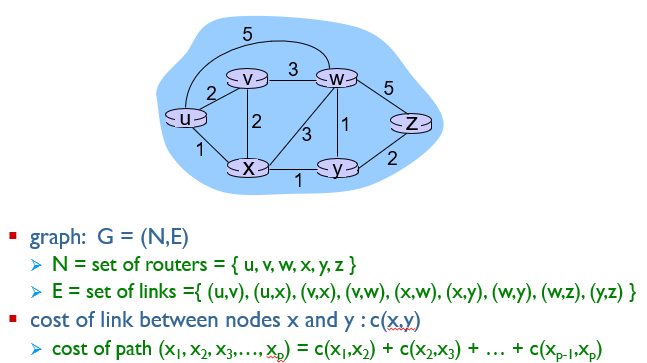
아래 그림의 최소 비용 경로를 찾는다.
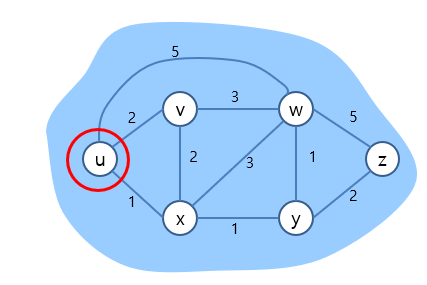
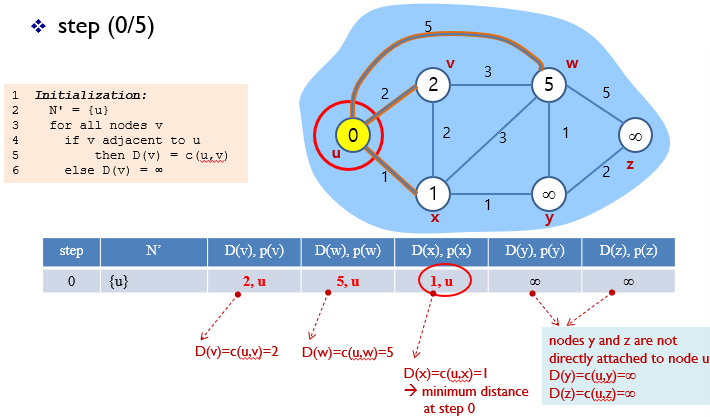
처음 시작 노드는 u이다.
최소 경로에서 정해진 노드는 u이므로, N' = {u}
v까지 가는데 드는 비용 D(v) = C(u,v)와 같으므로 2
최소 경로중 v 바로전 노드 p(v) = u
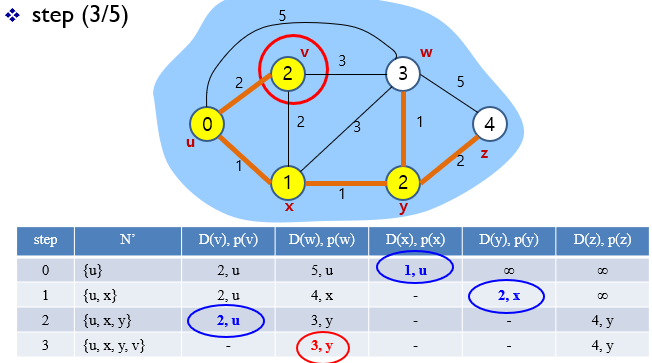
이런식으로 D(w), D(x)까지 진행해주었다.
노드 y와 z는 u에서 인접해있지 않으므로 무한대이다.
최종적으로 D(v),D(x),D(w)중 가장 cost가 적은 값을 다음 경로로 결정한다.
따라서 N' = {u,x}가 된다.
2.
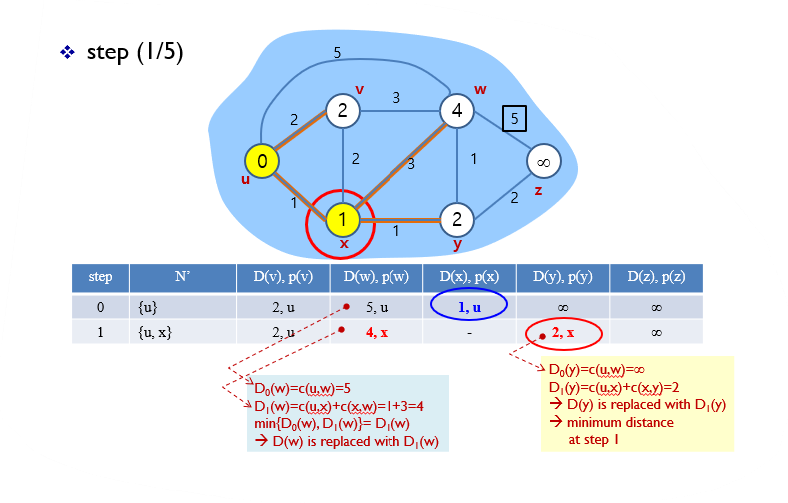
N' = {u,x}까지 결정되어 있는 상황에서 모든 노드에 대한 경로의 cost를 구한다.
그전 step보다 cost가 작아진다면 값을 바꿔준다.
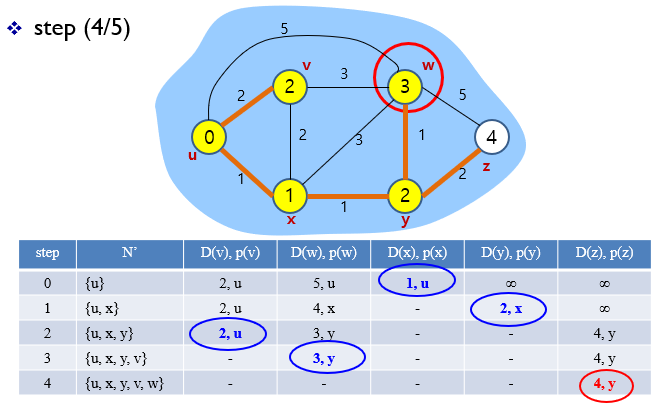
3.
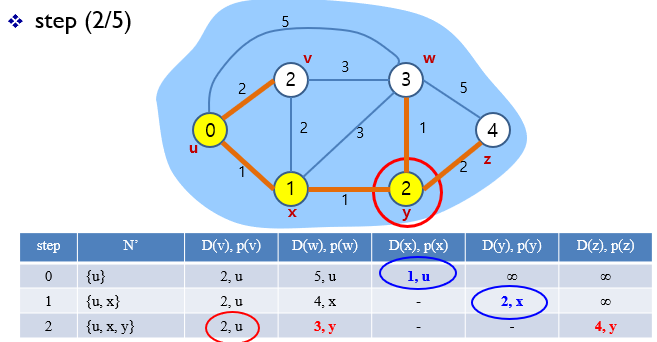
4.
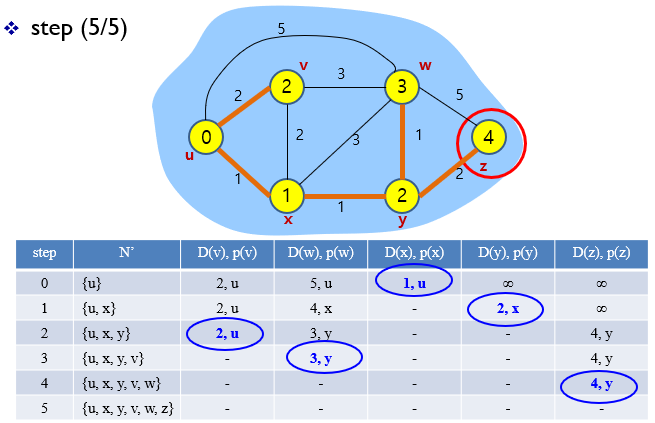
5.
6.
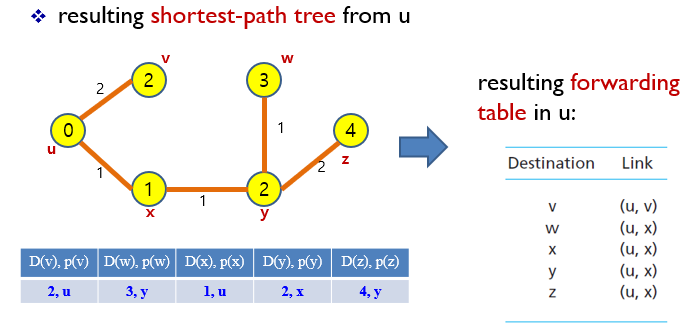
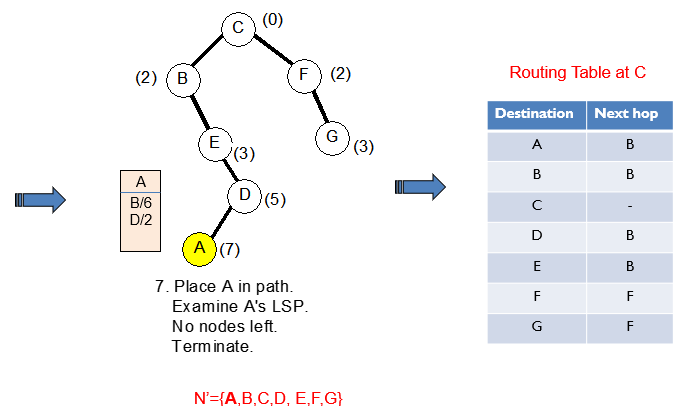
u에서 도착 노드까지 최소 cost를 기록해 놓은 table을 forwarding table 이라고 한다.
LS Algorithm의 complexity
n개의 노드가 주어졌을때
- 첫번재 iteration
- n개의 노드를 모두 search
- N' 에 있는 최소비용 노드는 한개이다.
- 두번째 iteration
- n-1 node가 체크된다.(N' 안에 있는 노드는 제외된다.)
- 세번째 iteration
- n-2 node 체크
...
결국 n+(n-1)+(n-2)+...(1) = n(n+1)/2 = O(n^2)
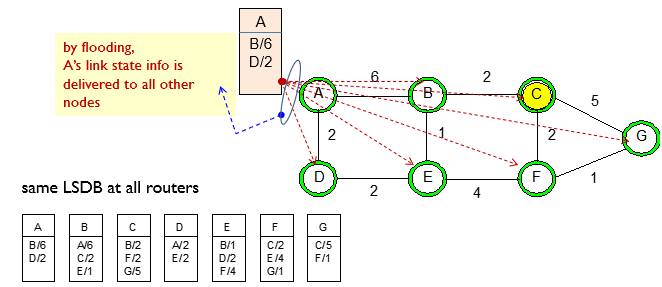
LS(Link State) inforamtion Flooding
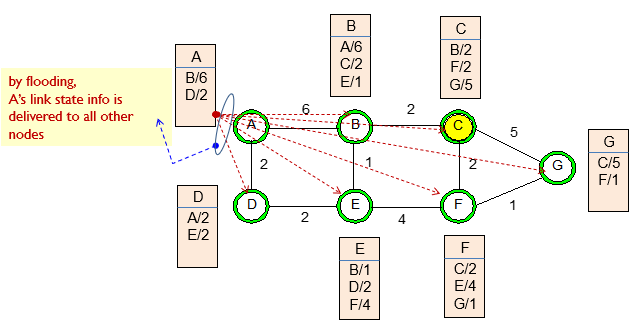
각 노드는 인접한 모든 노드에 대한 자신의 link state 정보를 가지고 있다.
flooding을 사용해서 모든 다른 노드에게 정보를 보낸다.
flooding
- source node에 의해 packet이 모든인접노드에게 보내진다.
- 각 노드로 들어오는 패킷은 들어온 link를 제외하고 모든 link에 재전송된다.
- 복사본의 다수가 도착지에 도착할것이다.
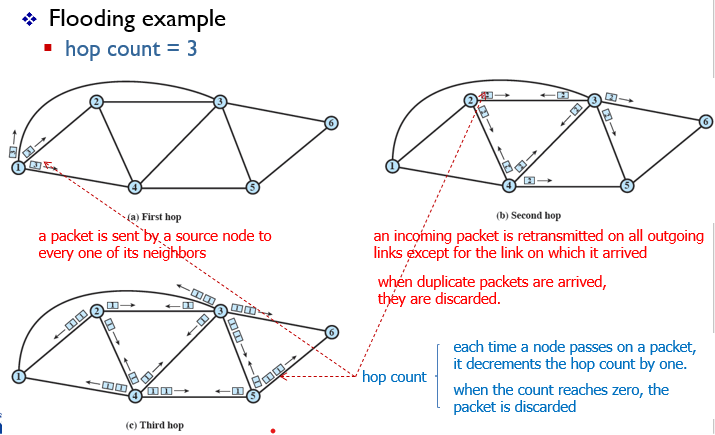
패킷에 적혀있는 숫자는 남은 hop 수이다.
패킷이 노드로 들어가면 들어온 방향의 link를 제외한 나머지 link로 패킷을 복사해서 보내고 hop count를 1 감소시킨다.
hop count가 0이되면 패킷은 소멸한다.
example2
Network에서 Link State를 살펴보자.
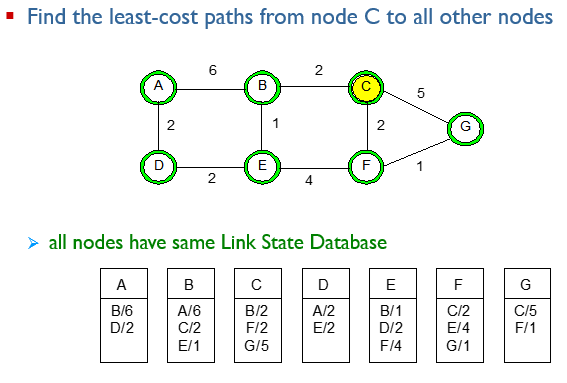
모든 노드(라우터)는 link state Database를 가지고 있다.
1.
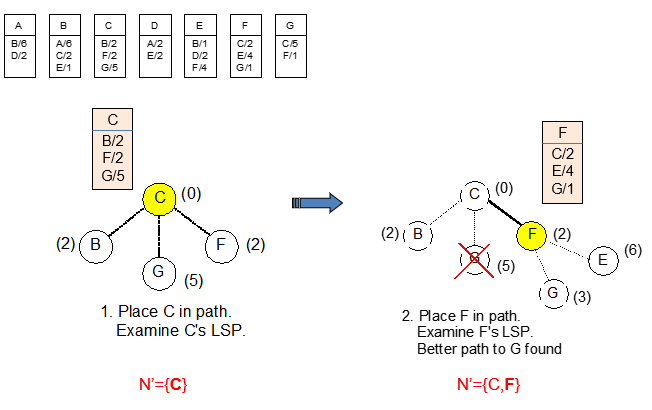
F노드에서 인접노드까지의 cost를 보았을때, C-G보다 C-F-G가 코스트가 낮으므로 C-G에서 G를 지워준다.
2.
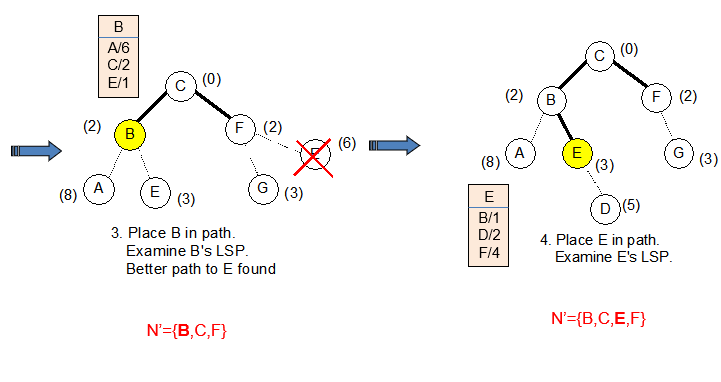
마찬가지로 C-B-E에서가 C-F-E에서 보다 코스트가 낮으므로 E를 지워준다.
3.
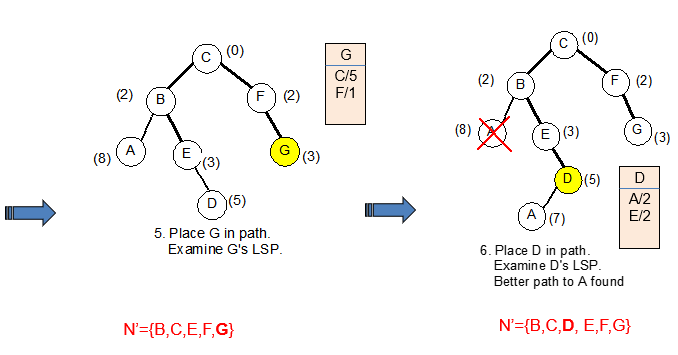
4.
Distance Vector(DV) 알고리즘
DV 알고리즘은 분산형 알고리즘에 속한다. 즉 각 노드는 자신에게 연결된 이웃의 링크의 비용만 알고 있기 때문에 벨만-포드 알고리즘을 이용해 최적의 경로를 계산할 수 있다. DV 알고리즘은 반복적이고 비동기적이며 분산적이다. 이웃끼리 반복해서 정보를 교환해 최적의 경로를 갱신하는 식이다.
Bellman-Ford algorithm
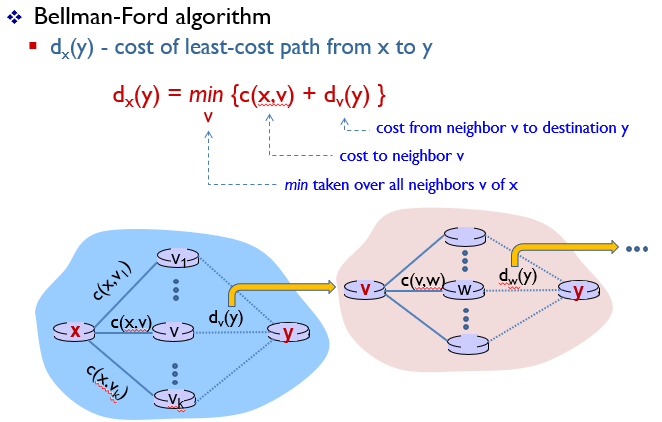
예를 들어서 빠르게 이해해보자.
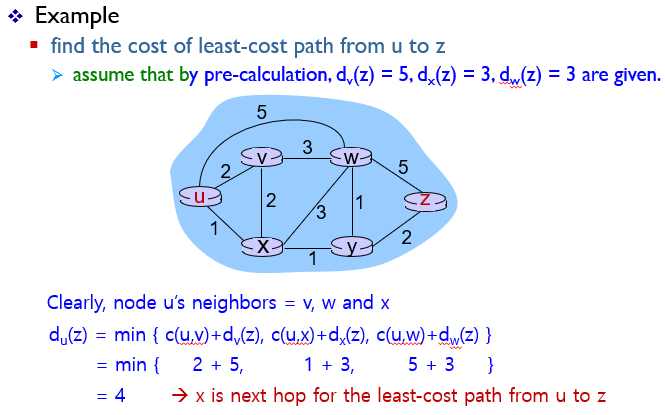
u -> z 의 최소비용 경로를 구해보자.
u의 인접노드는 v,x,w이다.
인접노드들을 거쳐서 u -> z 경로를 구하는 식은
or or 이다.
식을 조금더 자세하게 들여다 보자.
는 x의 인접노드인 u,v,w,y까지 비용 + 인접노드로부터 z까지 비용이라고 할 수 있다. 이중 가장 작은 값은 이다.
에서 y와 z는 인접노드이므로 c(y,z)로 바꿀 수 있다.
따라서 정리하자면
= 1+1+2 = 4이다.
결국 d()에 대해서 recursion이 일어난다고 할 수 있다.
LS와 DV 비교
-
message complexity
LS: n nodes, E links, O(nE) msgs 보낸다.
DV: 인접노드 사이에서만 교환한다. -
speed of convergence(수렴)
LS:O(n^2) algorithm은 O(nE) msgs를 필요로한다.
DV:수렴(convergence)시간이 다르다.
routing loops 있을수있다.
count-to-infinity problem이 있다.
- 만약 라우터가 오작동한다면?
Link State Algorithm에서는 망가진 라우터로부터 정보를 수신하지 못하게 되므로, 해당 라우터와 연결된 링크의 상태를 "링크 다운" 상태로 변경합니다. 그리고 이 상태를 인접 라우터에게 알리기 위해 "LSU(Link State Update)" 메시지를 전송합니다. 이후 인접 라우터는 이 정보를 받아 자신의 라우팅 테이블을 업데이트하게 됩니다.
반면, Distance Vector Algorithm에서는 망가진 라우터로부터 정보를 수신하지 못하더라도, 해당 라우터와 연결된 링크가 "링크 다운" 상태인지를 알지 못합니다. 이 경우, 라우팅 루프가 발생할 가능성이 있으므로, 이를 방지하기 위해 "hold-down timer"라는 메커니즘이 동작합니다. 이 메커니즘은 라우터가 "링크 다운" 상태를 감지하면 일정 시간 동안 정보를 업데이트하지 않도록 하여 라우팅 루프를 방지합니다.
Routing protocol
routing protocol이란?
-
네트워크에서 데이터를 전송하기 위한 경로를 결정하는 프로토콜이다.
라우터 간에 경로 정보를 교환하고, 최적의 경로를 결정하여 데이터를 전송한다. -
Autonomous System(자율 시스템)
✍️인터넷에서 자율 시스템을 말하며, 하나 이상의 IP 주소 범위와 라우팅 정책을 갖는 네트워크 그룹을 의미한다.
✍️AS number: 인터넷에서 자율 시스템을 구분하기 위해 사용되는 고유한 식별자이다. 16bit이다.
routing protocol 분류
- intra-AS routing:IGP(interior gateway protocol)
하나의 자체적인 네트워크에서 라우터 간의 경로 정보를 교환하는 프로토콜입니다. 대표적인 내부 라우팅 프로토콜로는 RIP(Routing Information Protocol), OSPF(Open Shortest Path First), EIGRP(Enhanced Interior Gateway Routing Protocol) 등이 있다. - inter-AS routing:EGP(exterior gateway protocol)
다른 네트워크와의 연결에서 사용되는 프로토콜. 대표적인 외부 라우팅 프로토콜로는 BGP(Border Gateway Protocol)가 있다.
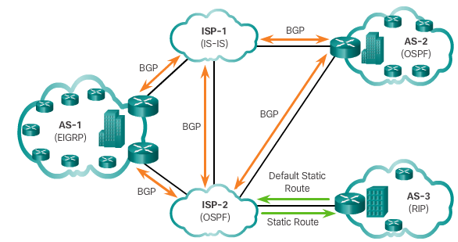
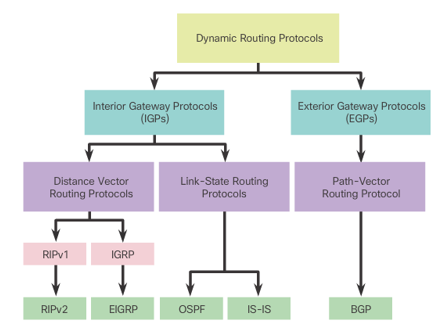
RIP(Routing Information Protocol)
- IGP(interior gateway protocl)에서 가장 많이 사용되는 것중 하나이다.
- Distance vector algorithm
✍️distance: hop의 갯수
✍️각 link는 cost가 1이다.
✍️vertor: next hop router - RIP advertisement
✍️RIP 프로토콜에서 라우터 간에 경로 정보를 교환하기 위해 사용되는 메시지
✍️RIP Advertisement에는 라우터가 가지고 있는 네트워크의 IP 주소, 서브넷 마스크, 라우터까지의 거리 등의 정보가 포함된다.이러한 정보를 교환하여 각 라우터는 최적의 경로를 결정하고, 데이터를 전송한다.
✍️RIP Advertisement는 주기적으로 교환되며, 기본적으로 30초마다 전송된다. 이 때문에 RIP는 반응성이 떨어지는 프로토콜로 알려져 있다. 최근에는 OSPF나 BGP와 같은 라우팅 프로토콜이 RIP에 대한 대안으로 널리 사용되고 있다.
✍️RIP Advertisement는 UDP를 사용하며 포트번호는 520이다.
routing table processing
- RIP routing table
✍️routed라고 불리는 application level process에의해 관리된다.
✍️UDP 패킷에서 알 수 있고, 주기적으로 반복된다.
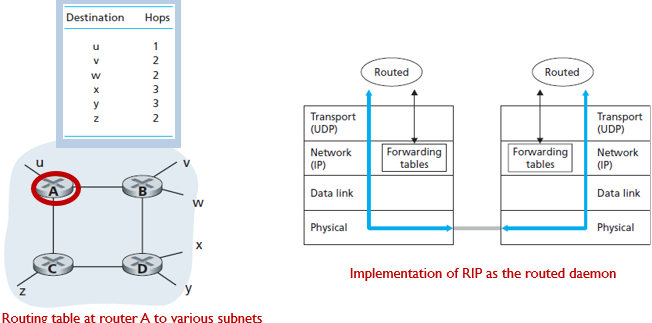
RIP-DV operation example
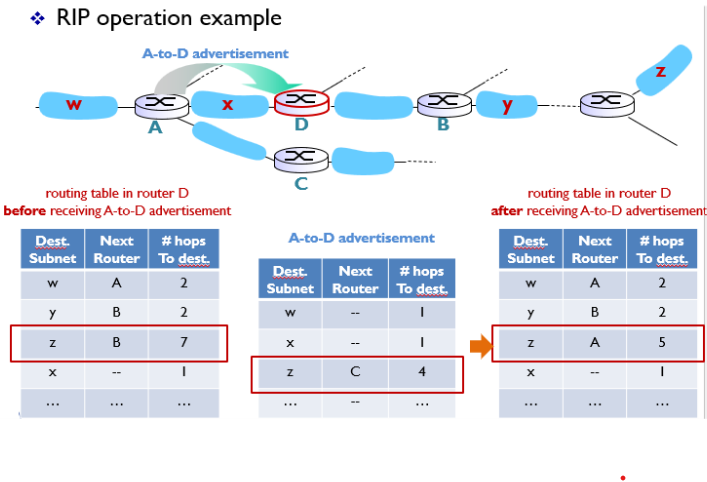
첫번째 표를 보면 라우터 D입장에서의 routing table이다.
z가 도착지일때, 다음라우터가 B인 방향으로 가면 hops가 7이었다.
두번째 표를 보면 A입장에서의 routing table이고
z가 도착지일때, 다음 라우터가 C인 방향으로해서 hops가 4였다.
A에서 D로 라우팅 테이블 정보를 주면 즉,A to D advertisement 하면, 세번째 표처럼 D는 A방향으로 갔을때 z까지 hops가 5밖에 안되는 루트를 알 수 있게 된다.
문제점
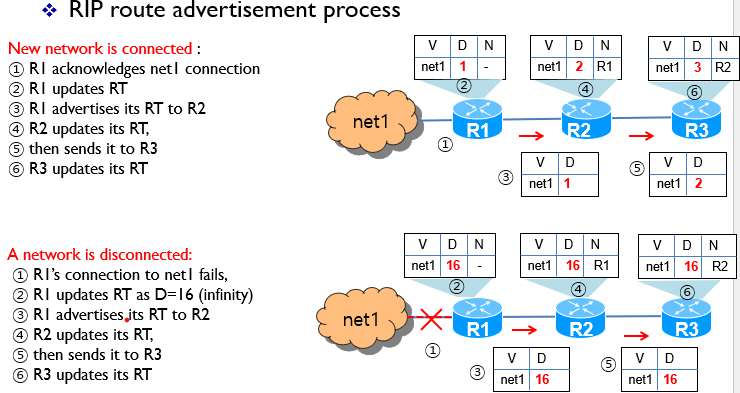
아래와 같은 상황에서 잘못하면 loop에 걸릴 수 있다.
OSPF(Open Shortest Path First)
- "open"은 public 하게 이용가능하다는 뜻이다.
- link state algorithm을 사용한다.
✍️각 라우터는 LS packet을 자율시스템에 있는 다른 라우터들모두에게 broadcast(floods)한다.
✍️각 노드는 topology map을 얻고, Dijkstra 알고리즘을 사용해서 라우팅 테이블을 계산한다.
✍️OSPF는 Ip를 거쳐서 직접 운반된다.
✍️모든 OSPF message는 인증기능을 사용해서 라우터 간의 교환된 정보의 안전성을 보장한다.
✍️여러 개의 경로중에서 비용이 같은 경로들을 모두 사용해서 트래픽을 분산시킬 수 있다.
✍️unicast와 multicast routing을 통합적으로 지원한다.
즉, OSPF는 유니캐스트와 멀티캐스트 라우팅 모두를 지원하는 라우팅 프로토콜이다. OSPF는 라우터 간의 경로 정보를 교환하고, 이를 기반으로 최적의 경로를 결정한다. 이 과정에서 유니캐스트와 멀티캐스트 트래픽을 모두 고려하여 최적의 경로를 결정한다.
따라서, OSPF를 사용하면 유니캐스트와 멀티캐스트 트래픽을 모두 효율적으로 라우팅할 수 있다.
✍️single routing domain내에서 계층구조를 지원한다.이를 통해 대규모 네트워크에서도 효율적으로 동작할 수 있습니다. OSPF에서는 라우터를 Area라는 단위로 그룹화하여 계층 구조를 형성한다. 라우터 간의 정보 교환은 Area 단위로 이루어지며, 각 Area는 자체적으로 SPF(Shortest Path First) 알고리즘을 수행한다. 이를 통해 라우팅 테이블의 크기를 줄이고, 라우팅 정보 교환의 효율성을 높일 수 있다.
OSPF operation
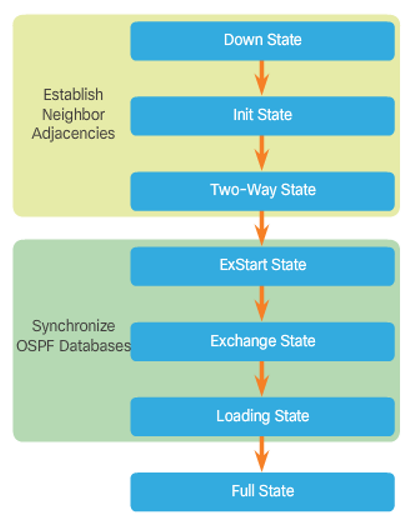
- Neighbor Discovery: OSPF 라우터 간에 인접 관계를 형성한다. 이를 위해 OSPF는 Hello 메시지를 주기적으로 전송하고, 이를 수신한 라우터끼리 인접 관계를 형성한다.
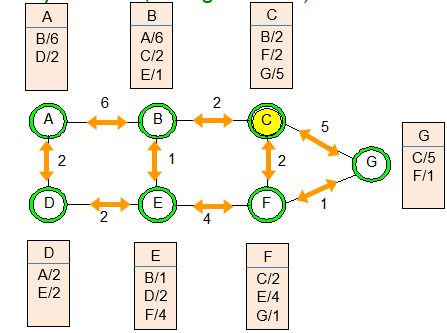
2.Link State Advertisement: OSPF 라우터는 자신의 링크 상태 정보를 생성하여 Link State Advertisement(LSA)라는 형태로 전파한다. 이를 통해 모든 라우터는 전체 네트워크의 링크 상태 정보를 가지게 된다.
3.Shortest Path First Calculation: OSPF 라우터는 수신한 LSA 정보를 기반으로 SPF(Shortest Path First) 알고리즘을 사용하여 최단 경로를 계산한다.
4.Routing Table Update: SPF 알고리즘을 통해 계산된 최단 경로 정보를 라우팅 테이블에 업데이트합니다.
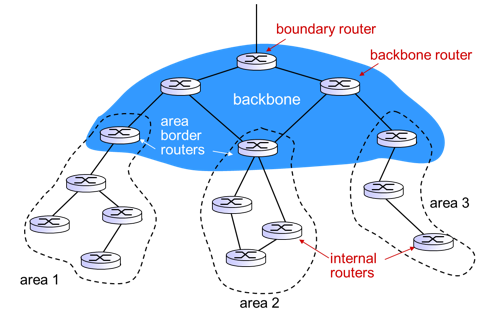
OSPF Area
- OSPF network는 ` area 라고 부르는 sub-domain들로 나눌 수 있다.
- area는 routing database size를 줄여줄 수 있다.
- 네트워크 계층구조를 만드는게 가능하다.