Intro
demand paging(memory를 캐시로 사용)을 효율적으로 하기 위해선 page fault를 줄이는게 가장 중요하다.
왜냐하면 page fault가 일어났을때 disk로 접근하는 시간이 memory 접근 시간보다 훨씬 커서 속도에 큰 영향을 미치기 때문이다.
예를들어, memory access: 200ns, avearge disk access: 8ms 라고 하자.
page fault가 일어나는 빈도는 p = page fault rate, 0 <= p <= 1이고,
실제적으로 memory와 disk에 접근하는 시간은
Effective access time = ppage fault handling time+ (1-p)memory access 와 같다.
만약 p = 0.001이라면 effective access time = 8.2us이다.
momory access time보다 40배가 느려진 것이다.
결국, page fault가 최소로 일어나게 해야 demand paging에 효율이 높아질 수 있다.
Page Replacement
page replacement는 물리 메모리 공간이 부족할때 발생한다. 물리 메모리가 부족하면 사용하던 page를 제거하고 storage에 저장한후에 새로운 page를 PF에 load해야한다.
그렇다면, PF에 있던 어떤 page를 replacement해야 page fault가 최소로 일어날 수 있을까?(page를 찾는데 계속 page fault가 일어나면 효율이 떨어지므로)
결국, 가장 쓸모없는 page를 replacement해야하는데 그렇다면, 가장 쓸모없는 page는 어떻게 정의할 수 있을까?
OPT(optimal page replacement)
Belady's alogrithmr 이라고도 불리는 OPT는 미래에 가장 쓸모없는 page를 replacement 하겠다고 하는 algorithm이다.
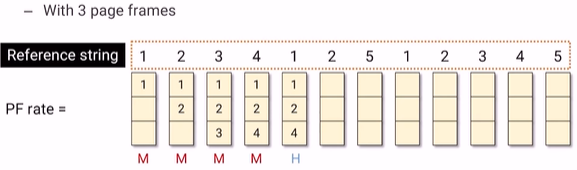
3개의 page frame이 있다고 하자. Reference String은 앞으로 참조하고자 하는 것이다.
1번을 참조할때는 PF가 비어있기 때문에 miss이다.
2번을 참조할때는 PF에 2가 없기 때문에 miss이다.
3번도 마찬가지로 3이 없어서 miss이다.
그렇다면 4번을 참조할때는 어떨까?? 4번을 참조하려고 했더니 PF가 꽉차있다. 1,2,3 중에 어떤걸 빼줘야 할지 결정을 할때 Reference String 중에서 가장 참조가 나중에 되는것을 빼준다. 결국 3이 가장 나중에 참조되기 때문에 3대신 4를 넣어주었다.
cache가 충전되어 있지 않은 상태에서 miss나는 것을 cold miss라고 한다.
page fault가 7번이 났다.
이 replacement가 최적의 solution이라고 belady는 생각했다. 하지만 가장 큰 문제가 있다. OPT는 computer가 미래정보를 알고 있다고 가정했지만 computer는 미래정보를 알 수 없다. 그래서 실제적으로 시스템에 사용할 수는 없다. 다만, program이 돌면서 memory 접근한 정보를 받아서 그중에서 최적의 repalcement를 찾을 수는 있다.
그래서 이방식은, replacemnet 정책에 대해서 효율이 있는지 없는지 판단할 때 쓰인다.
그래서 미래정보 없이 어떻게 replacement할 수 있을까를 생각해보았다.
FIFO
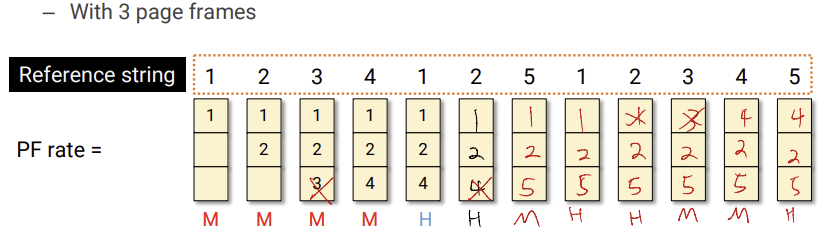
먼저 들어온 page가 제일 쓸모없지 않을까?? 라고 생각한 것에서 나왔다.
위에서 볼 수 있듯이, page fault가 일어났을때 가장 먼저 들어온 page 순으로 replacement를 해준다. 위에서는 9번의 page fault가 나왔다.
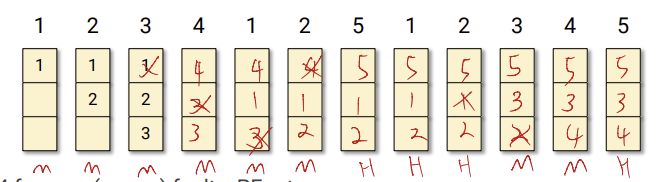
근데 만약, 더 많은 frame을 사용한다면 어떻게 될까? page fault가 더 줄어들지 않을까?? 그런데 반전이 있다. 4 frames 으로 해보자.
page fault가 10번이 나왔다. 충격적인 결과다. 돈을 더써서 frame수를 늘렸지만 오히려 page fault가 증가해버리는 결과가 나왔다.
Belady가 이러한 현상을 보고 연구결과 다음과 같은 결과가 나왔다.
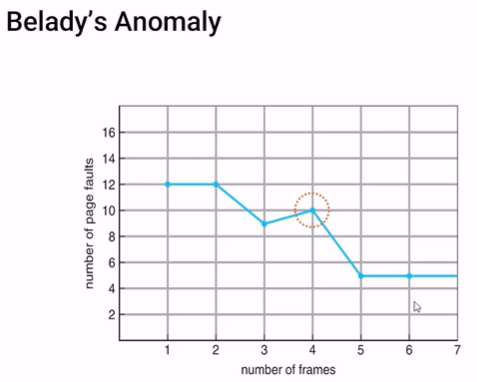
위 처럼 frame수를 증가시켰지만 page fault가 늘어나서 성능이 나빠지는 경우를
Belady anomaly가 있다고 한다.
LRU(Least Recently Used)
그렇다면, 제일 나중에 참조된 page를 빼는것을 어떨까??
MRU(Most Recently Used): 가장 최근 참조.
LRU(Least Recently Used): 가장 나중 참조.
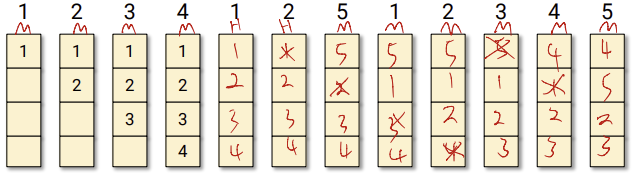
가장 최근에 들어온 page를 MRU에 넣고, PF에 있던 값들은 한칸씩 밑으로 내려간다. 결국, LRU에 있던 page는 빠져나가게 된다.
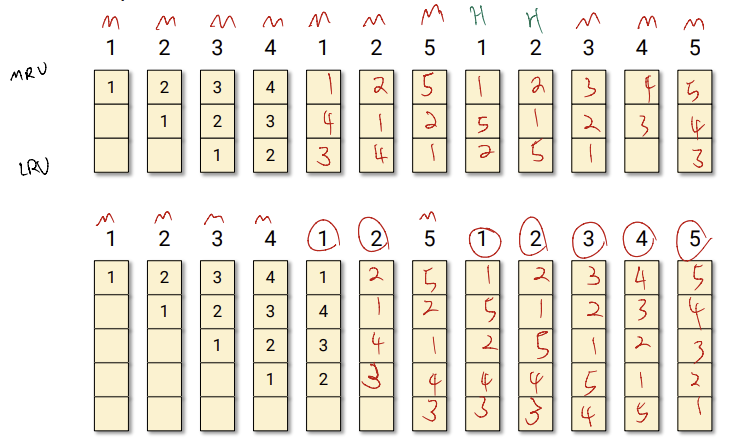
3 frame일때보다 5frame일때가 훨씬 pagefault가 적게 나왔다. 어떻게 다른 alogrithm들과는 다르게 LRU는 frame수가 증가했을때 더 효율적일 수 있을까??
그림을 잘보면 3개 frame일때 PF안에 있는 page number들이 5 frame일때 PF에 모두 포함되어 있다. stack algorithm이라고 하는데 n개일때의 결과가 n+1일때 결과에 포함되어 있다는 algorithm이다.
FIFO 같은 경우는 stack algorithm이 아닌걸 볼 수 있다.
결국, stack algorithm은 frame이 증가했을때 성능이 더 좋아지는걸 보장하고(Belady anomaly 발생x, e.g. OPT,LRU) 아닌 것들은 frame이 증가해도 성능이 어떻게 변할지 보장되지 않는다라고 결론지을 수 있다..(Belady algorithm 발생,e.g. FIFO)
LRU 사용한 page replacement
VPN이 PFN을 LRU를 사용해서 page replacement하는 방법에는 두가지가 있다.
clock 사용
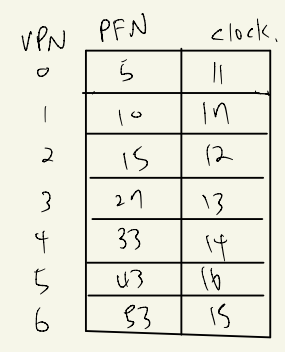
VPN이 PFN을 참조한 clock을 기록한다.(제일 큰 Clock이 현재 시간이다.)
만약 VPN 7(새로운 page) 이 PFN을 참조하려고 하는데 PF가 남는 자리가 없다. 그렇다면 가장 오래된 clock인 11을 가진 page를 storage로 보내고 replacement해준다.
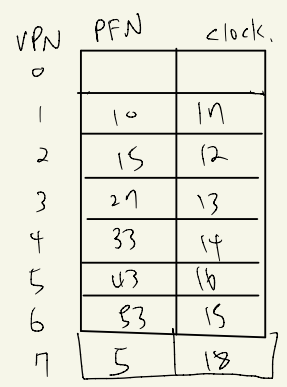
그런데 이런식으로 했을때 큰 문제가 있다.
가장 작은 clock을 찾으려면 page table을 모두 뒤져봐야 한다.
이건 생각보다 많이 오래 걸린다.
그리고, clock은 결국 비트로 표현해야 하는데, 한계가 있으므로, overflow가 발생할 수밖에 없다. 비트수를 늘려주면 memory를 많이 써야하므로 좋지않다.
access 속도는 빠르지만 victim 찾기가 오래걸린다.
linked list 사용
그래서 생각할 수 있는 방법이 linked list이다.
page가 1,2,3,4 page frame에 올라와 있다고 하자.
page 3을 참조하면 헤더로 3을 보내면 된다.
만약 새로운 page인 5를 참조한다면 tail을 제거하고 5를 헤더로 넣으면 된다.(victim 찾기에 빠르다.)
근데 문제가 있다.
1. linked list도 참조할때마다 해당 page를 찾기위해서 linked list를 모두 뒤져봐야 한다.
2. linked list 중간에 껴있는 page를 참조하면 헤더로 보내줘야 하는데, 이런식으로 구현하기 위해서는 doubled linked list로 구현해야하고, page를 header로 옮길때 양옆에있는 포인터를 수정해줘야 한다. 수정해야 하는 포인터만 4개다. 그래서 상당히 비효율 적이게 된다.
victim찾기는 빠르지만 access 속도가 느리다.
LRU Approximation Algorithms
위와 같은 문제들로 인해서 LRU를 구현할때 하드웨어에 도움을 받는다. 완전한 LRU는 아니지만 LRU스러운 algorithm을 만들 수 있다.
Additional-Reference-Bits Alogrithms
위에서 table을 사용해 clock을 기록했던 방식과 비슷한 방식이다.
그렇다면 하드웨어에 어떤 기능을 요구하면 될까?

page table entry에서 R은 referenc bit을 해당한다. MMU(하드웨어)가 해당 PTE를 참조했을때 참조했다고 표시를 해주게 된다. 이를 통해서 page table entry가 참조되었는지 안되었는지 쉽게 판별할 수 있다.
위에서 clock을 사용한 page table의 문제는 clock을 어떻게 관리할수 있을지에 대한 것이었다.
clock 체크 문제의 어려움을 해결하기 위한게 Additional-Reference-Bit이다.
table에서 clock part를 지우고 ABR(Additional-Reference-Bit),R(Reference) 항목을 추가한다.
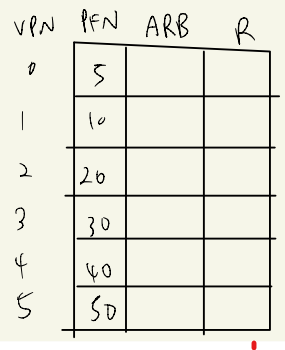
MMU가 돌면서 참조한 page에 대해서는 R을 1로 업데이트 한다.
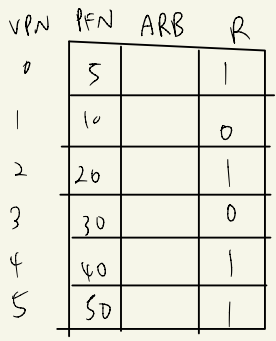
일정시간이후에 운영체제가 R의 비트를 그대로 ARB에서 상위비트로 옮기고 R을 0으로 초기화 한다.
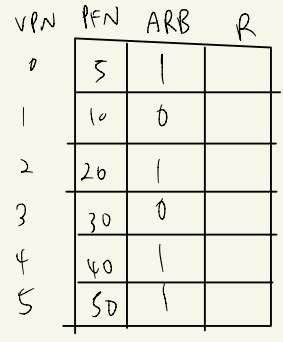
그것을 반복한다.
1. 참조한 page R 업데이트
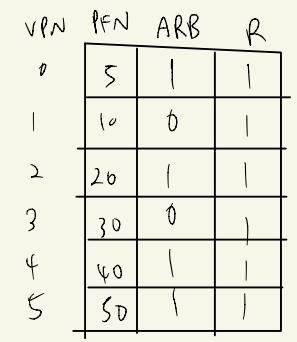
2. ARB 업데이트
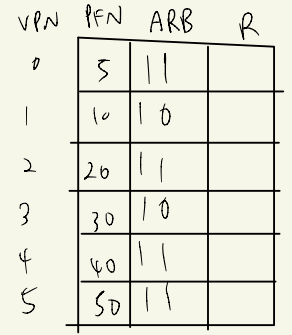
이렇게 하다보면 가장 최근에 참조한 page의 ARB가 가장 클것이다.
결론적으로, ARB중 가장 낮은 bit를 가지고 있는 PTE를 빼준다.
문제는 clock처럼 ARB의 가장 낮은 비트가 뭔지 traveling해야 하는데, 하드웨어로 동작하면 쉽고 빠르게 동작할 수 있다.
Second-Chance Algorithm
clock algorithm 이라고도 불린다.
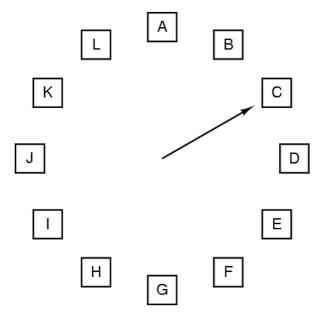
각 알파벳들은 모두 PTE이다. 해당 page가 참조되면 R을 1로 업데이트 해준다.
page fault가 일어난다면 시계바늘이 가리키고 있는 PTE의 R을 본다. R이 1이면 0으로 초기화 하고 다음으로 넘어간다. R이 만약 0이면 해당 PTE를 replacement한다.
물론 모든 PTE가 R이1이면 한바퀴 돌고 클리어하고 replacement 하겠지만 대부분은 그러지 않고 victim을 빠르게 찾는다.
Enhanced Second-Chance Algorithm

M은 dirty 혹은 modify로 사용하기 위한 bit이다.
기본적으로 Second-Chance Algorithm과 똑같은 알고리즘인데 여기에 PTE마다 M표시를 추가해준다. M은 해당 page에 write가 되었을경우 MMU(하드웨어)가 체크하고 M을 1로 바꿔준다. page fualt가 일어났을때 M이 1이면 버릴때 디스크에 저장을 해줘야 한다.
page fault가 일어났을때 해당 페이지가
!R,!M 이면 replace하기 가장 좋은 경우이고
!R,M 이면 값을 storage에 써주고 replacement해줘야한다.
R,!M 이면 다음으로 바늘이 넘어가고(최근에 참조한적 있어서 다시 참조될것이기 때문)
R, M 이면 다음으로 바늘 넘어간다.(최근에 참조되기도 했고, write되었기 때문에 storage에 값을 써주기에 비용이 많이들어서 replace로는 적합하지 않다.)
Counting-based Page Replacement
- Least Frequently Used(LFU)
count를 PTE마다 놓고 참조될때마다 count를 하나씩 늘려준다.
page fault가 일어나 victim을 선택하게 되면, count가 가장 낮은 page를 replacement 해준다.
하지만 이방법은 count 하는데 메모리를 많이 사용할 수 있다.
예를들어, 8번까지 count하려면 bit가 3개 필요하고 16번하려면 bit가 4개 필요하다. 그리고 overflow가 일어날 가능성이 존재한다. 또한 흐름을 따라가지 못한다. 무슨 얘기냐면, 과거에 많이 참조되어서 200번이 참조되었다고 하자. 그런데 현재 흐름으로는 더 이상 사용하지를 않는 page이다. 하지만 과거에 많은 참조가 일어나 count가 높기 때문에 replacement가 되지 못하고 자리만 차지하고 있게된다.
- Most Frequently Used(MFU)
가장 자주 사용된 페이지를 교체한다.
Paging Virtual Memory
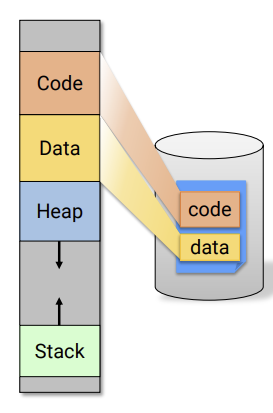
🤔Code(file-backed pages)
-
우리가 프로그램을 실행할때 disk로 부터 메모리로 불러온다.(demand paging)
-
code는 file에서부터 불러온다
file-backed pages: 실행 file에서부터 불러온 page (e.g. code,data)
anonymous pages: 실행될때 만들어짐 어디서부터 오거나 하지 않았다. e.g. Heap,stack -
코드가 실행하면서 바뀌는 경우는 없다. 따라서 code section은 reclaim할때(다시 disk로 돌아갈때) 버리면 된다.
🤔stack,heap(anonymous pages)
- 처음에 reference가 read인 상태에서는 zero page로 맵핑이 된다. 하지만 사용자가 write를 하면 새로운 page를 만들어서 맵핑해준다.
- reclaim을 하려고 하면 값을 swap file에 써놔야 한다.
- heap에 있던 값을 swap file에 써주고 다시 그값을 paging하게 된다면 마치 file-backed page처럼 사용하게 된다. 따라서 해당 heap이 dirty(값이 변경됨)상태가 아니라면 그냥 버리면 되고, dirty면 다시 swap file에 값을 변경해준다.
🤔data
- global variable이 들어간다.
- 프로그램에서 globla 변수 값이 바뀌어도, 프로그램이 꺼지면 다시 초기화 된다. 즉, disk에 변경된 값이 반영되지 않는다.
- 시작은 file-backed로 시작하지만, write가 일어날때 copy-on-write가 일어난다. copy-on-write된 page는 disk로 다시 돌아오면 안된다. 따라서 anonymous 형태로 변경된 값을 swap-file에 써준다.
