운영체제
1.[운영체제]Interrupt
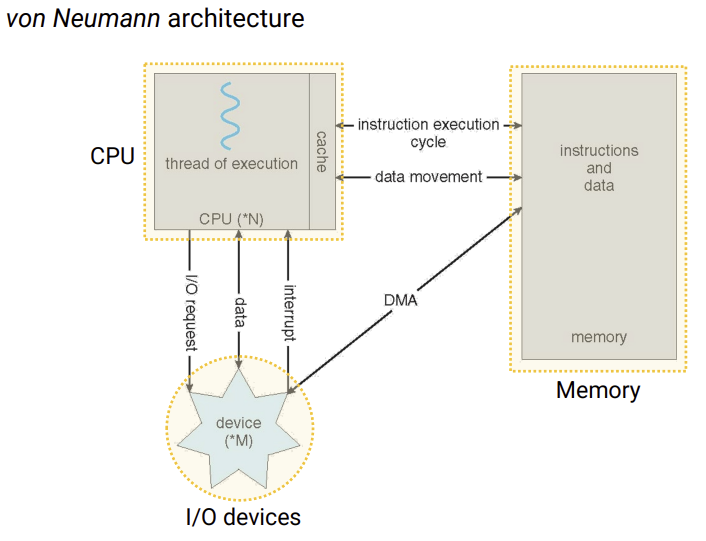
OS는 시스템 resource를 virtualize 한다.processors -> processes,threadsMemory -> virtual memory address spacesstorage -> volumes,directories,filesI/O devices
2.[운영체제]processes
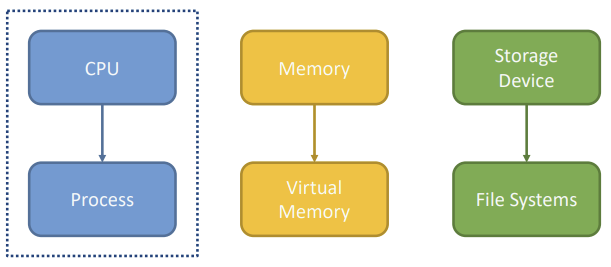
OS는 process,memory,storage를 가상화 시켜준다.덕분에 한정된 메모리 공간안에서 많은 process들을 돌릴 수 있고, 여러가지 일들을 수행할 수 있다.실행중인 프로그램 instance 하나 하나를 process라고한다.정확하게 말하면, .exe 파일
3.[운영체제] System call
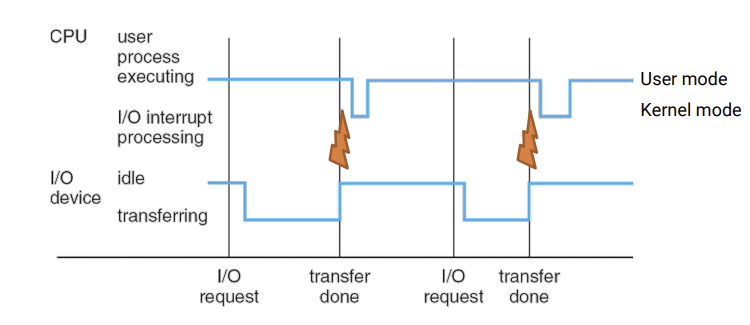
조심스럽게 실행해야 되는 instruction 집합이다.그만큼 중요한 instruction들 이라는 것이다. 잘못 만지면 컴퓨터에 심각한 이상증상을 초래 할 수 있다. 그래서 아무나 실행할 수 없는 instruction 이다.시스템 레지스터 접근/조작interrupt
4.[운영체제]signal & pipe

process의 특정한 event를 알리기 위한 IPC(inter-process-communication) 매커니즘이다.synchronous(e.g., illegal memory access) 혹은 synchronous(e.g., killed) 모두 될 수 있다.sof
5.[운영체제]process scheduling
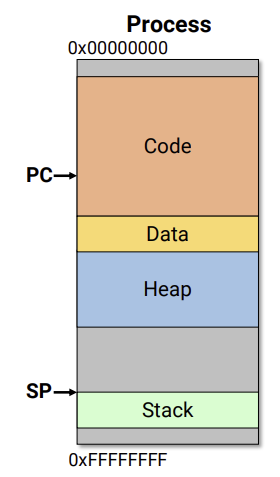
프로세스 스케줄링이란 무엇일까??각 process는 자기 자신의 address space를 갖고 있다. 만약 시스템이 여러 프로세스를 갖는다면위와 같을 것이다.multiple process들이 여러개의 프로세서에서 돌아간다면 프로세서가 프로세스 하나씩 맡아서 실행시키면
6.[운영체제]Process scheduling(2)
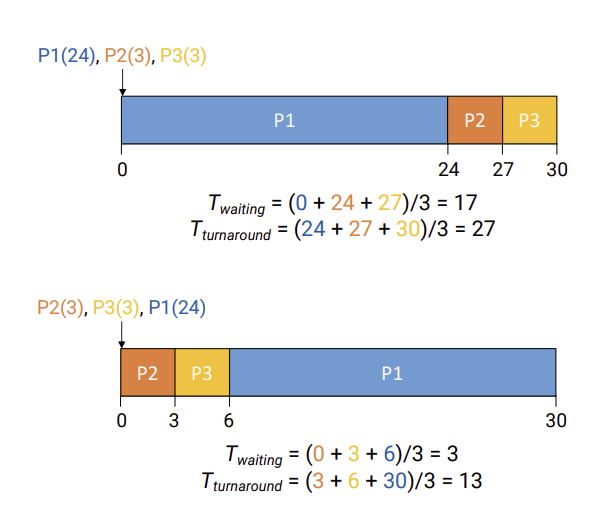
scheduling Alogritm의 목표는 다음과 같다.NO starvationstarvation: queue에서 더큰 우선순위를 가지는 process들이 계속 실행되다가 어떤 process의 차례가 오지않는 현상Fairness: 각 process에게 CPU를 공평하
7.[운영체제]scheduling(3)
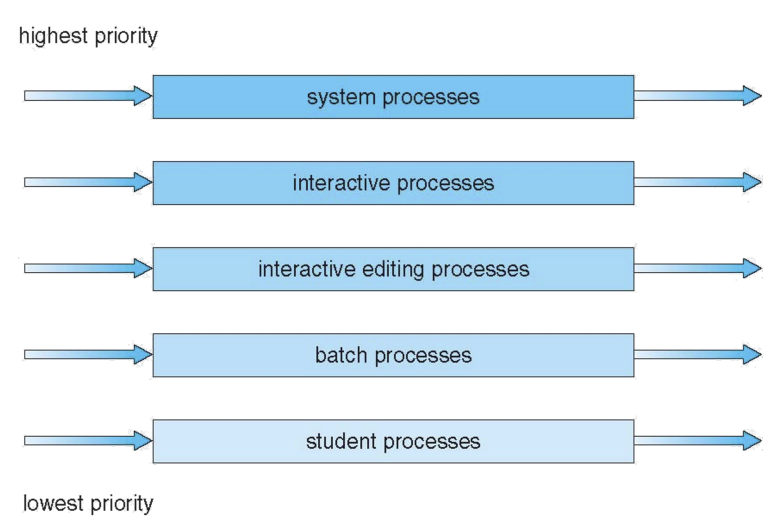
system 에서는 다른 여러 타입의 job들이 있다.ready queue에 있던 process들을 다른 별도의 queue로 나눈다.Foreground queue, background queue...각 process의 특성에 따라서 queue에 job들을 할당한다.fo
8.[운영체제]process scheduling(4)
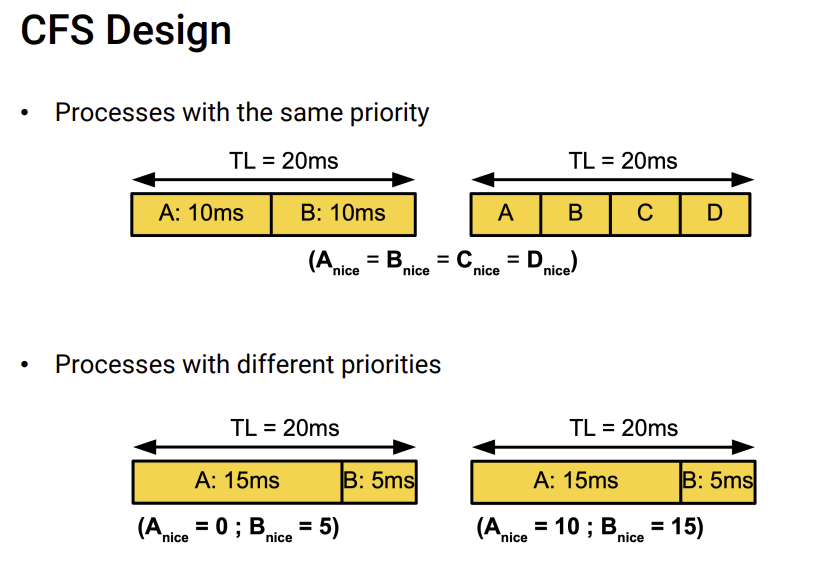
✍️v1.2실행 가능한 task 관리자에 대한 circular queue(RR)process들을 추가하고 제거하는데 효과적✍️v2.2scheduling classes을 도입실시간 작업, 비실시간 작업, 우선순위 없는 작업에 대한 스케줄링 정책을 사용가능SMP(symme
9.[운영체제] Address spaces
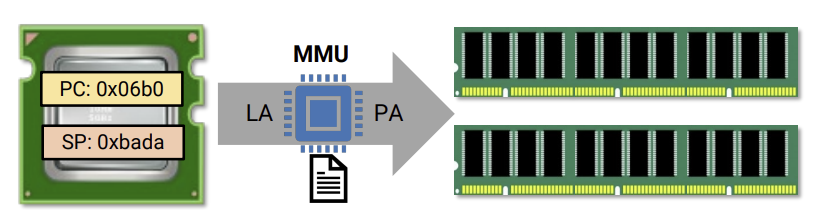
Address in Computers 내가 ABCD란 곳에 데이터를 저장하고나서, 메모리에서 ABCD의 값을 읽으려면 ABCD의 위치를 알아야 한다. ABCD를 지정해야 하는데 어떻게 읽을 수 있을까?? 메모리에 어딘가에 값이 지정되어 있는데 그 어딘가가 addres
10.[운영체제]Paging and Page Tables
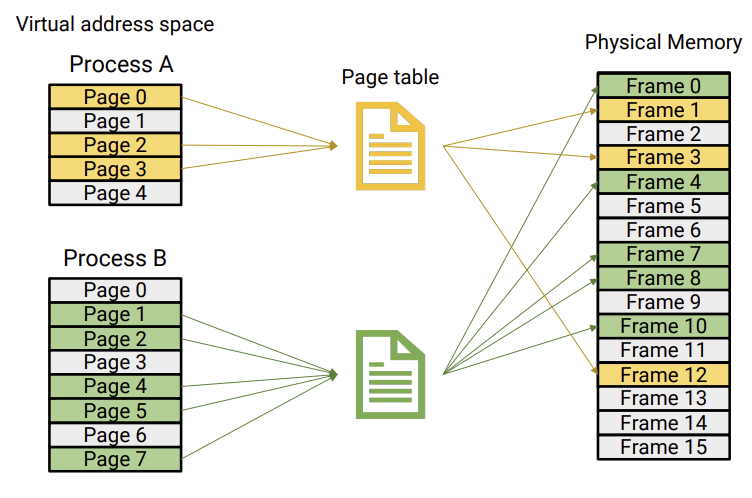
physical memory를 "page frames" 혹은 "frames" 라고 불리는 고정된 사이즈의 블록으로 나눈다.logical(virtual) address space를 "pages"라 불리는 같은 사이즈의 블록들로 나눈다.n size의 program을 실행하
11.[운영체제] Hierarchical page table

이전내용 컴퓨터의 메모리를 사용하려고 하는데, 여러개의 프로세스를 띄우고 싶다. 어떻게 하면 메모리를 효과적으로 잘 사용할 수 있을까??라고 해서 나온 것들이 fixed partitioning, variable partitioning, segmentation 이다.
12.[운영체제]Hashed page Table
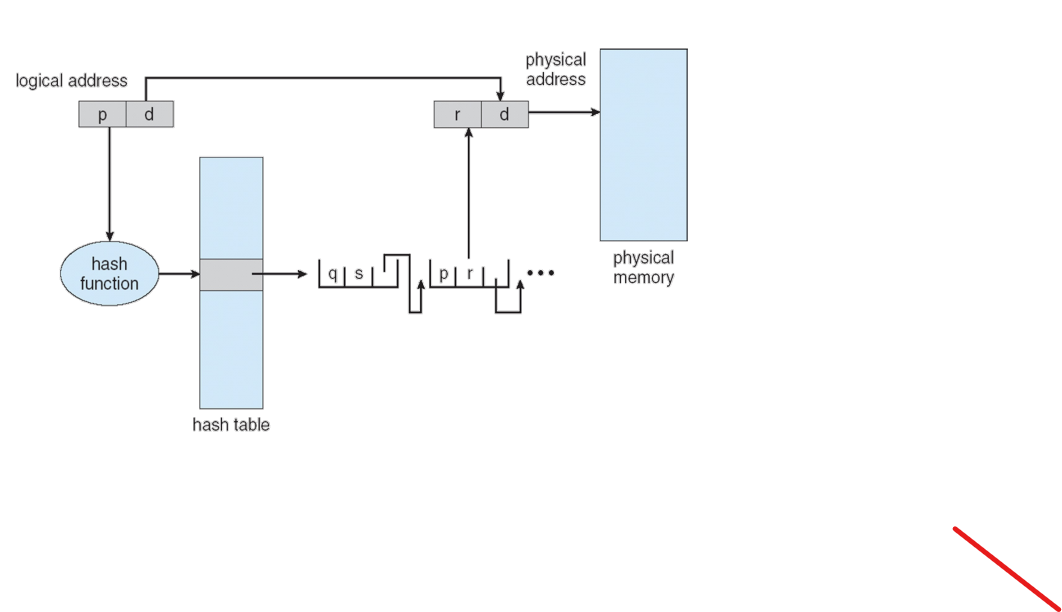
hash의 궁극적인 목표는 더 많은 수의 데이터를 더 적은수로 보관할 수 있게 하는것이다. 예를들어, 10만개의 VPN이 있는데,만개의 Hash Table entry에 넣으려고 하는것이다. 그래서 필요한게 hash function이다. hash function은 어떤
13.[운영체제]TLB
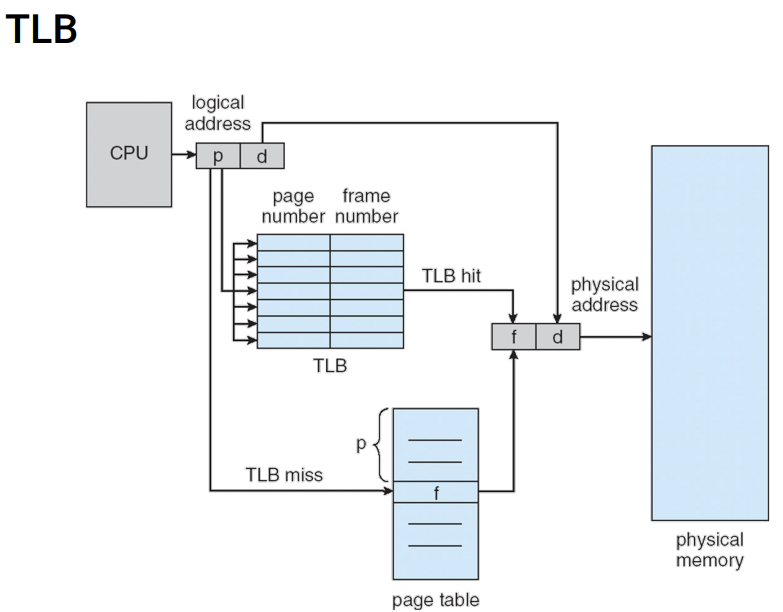
Hierarchical Page Table은 page table을 여러번 계속 접근해야 한다. 그런데 page table은 메모리에 있다. 즉, memory를 계속 접근해야 한다는 것이다. cpu 가 memory에 접근하는 것은 오랜 시간이 걸린다. 그래서 Level이
14.[운영체제] Demand paging & copy on write
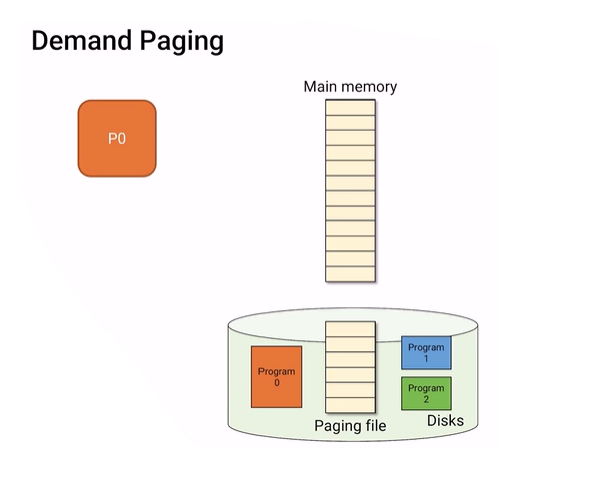
swapping 우리가 프로그램을 실행하기 위해서는 SSD나 HDD 같은 storage device에서 메모리로 프로그램이 모두 올라와야 첫 instruction을 실행할 수 있다. 그렇다면 만약 파일 용량이 커서 메모리로 올리는데 까지만 10초가 걸린다면, 10초
15.[운영체제] Buddy System Allocator
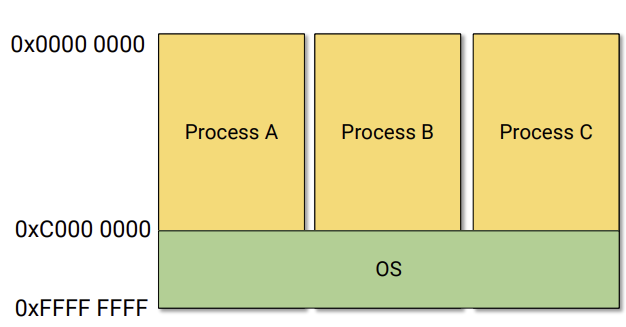
우리가 process를 실행할때 운영체제가 정말 많은 일을 해준다. process는 page table이 있어서 address translation을 통해서 physical table에 접근한다는건 알고 있다. 그렇다면 운영체제는 도대체 어디에 있어서 운영체제가 실행되
16.[운영체제] Page Replacement
demand paging(memory를 캐시로 사용)을 효율적으로 하기 위해선 page fault를 줄이는게 가장 중요하다.왜냐하면 page fault가 일어났을때 disk로 접근하는 시간이 memory 접근 시간보다 훨씬 커서 속도에 큰 영향을 미치기 때문이다.예를들
17.[운영체제] 쓰레드

single and multithreaded processes thread들은 address space를 모두 공유한다. 즉, 한쪽 쓰레드에서 데이터값을 바꾸면 다른쪽 쓰레드도 바뀐값을 알 수 있다.
18.[운영체제]Synchronization
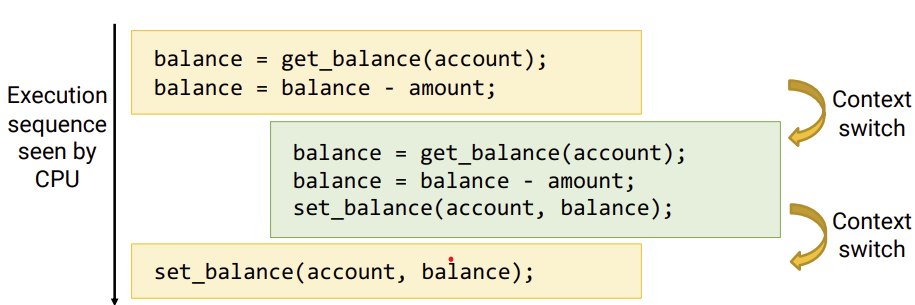
김씨가 ATM기에서 돈을 인출하려고 한다.인출할 수 있는 ATM에 프로그래밍 되어 있는 코드는 다음과 같다.김씨가 20만원이 있었는데 5만원을 뺐다.위에 코드대로라면, 잔액을 조회하고, 잔액에서 인출할 금액을 빼서 잔액을 다시 업데이트 해준다.문제는 ATM기가 하나만
19.[운영체제]Storage Dvices
자석을 이용해서 데이터를 저장한다.자석이 붙어있는 원판이 돌아가면서 헤더가 자석의 방향을 관측하고 0과 1을 쓴다.Seek time: 데이터를 찾기 위해 헤드가 디스크 표면에서 이동하는 데 걸리는 시간이다. 이동 거리가 짧을수록 seek time은 짧아진다. 하드 디스
20.[운영체제] File System
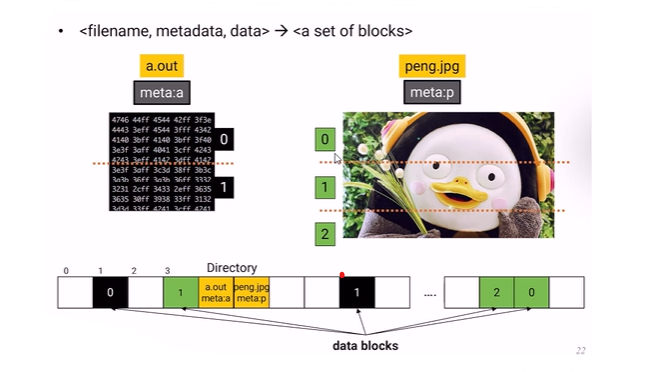
OS 입장에서는 file은 사용자가 만들어놓은 data에다가 이름을 붙여놓은 것이다. data들은 쪼개서 storage 장치에 저장한다. file에 들어가는 정보(meta data) name indentifier : 사람이 file을 맵핑하는것은 name이 될 것이고