파이프라이닝 개관
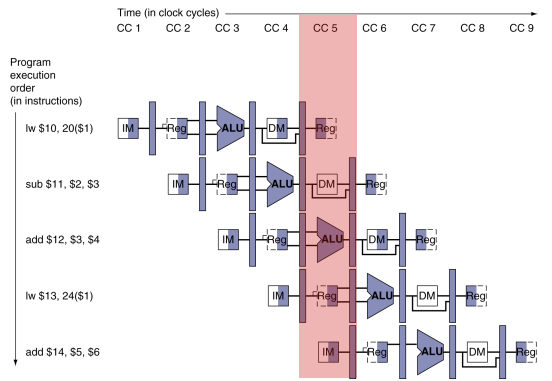
pipelining 예시
파이프라이닝을 예시로 들자면 이런것이다.
가장 유명한 세탁을 예로 들면,
파이프라이닝을 적용시키지 않은 세탁 방법은 다음과 같다.
1. 세탁기에 옷을 넣는다.
2, 세탁기 작동이 끝나면, 건조기에 옷을 넣는다.
3. 건조기가 끝나면 옷을 탁자위에 놓고 접는다.
4. 접는 일이 끝나면 같은 방 친구에게 장롱에 넣어 달라고 부탁한다.
5. 방친구가 일을 끝내면 그다음 친구의 세탁물을 세탁기에 넣어 1번부터 다시 시작한다.
이처럼, 1~5 까지 모두 끝난후, 다시 1부터 시작할 수 있다.
반면, 파이프라이닝을 적용시킨 세탁 방법은 다음과 같다.
시간흐름 ->
1->2->3->4->5
--- 1->2->3->4->5
------- 1->2->3->4->5
이런식으로 세탁기가 동작이 끝나면 곧바로 다음 친구가 세탁기를 사용할수있다.
이러한 방법은 훨씬더 시간이 덜 걸린다.
만약 세탁 한 사이클이 4시간이라면,
non piplelining에서는
4명의 친구가 세탁하려면,4+4+4+4 = 16시간
pipelining에서는
7시간이면 끝난다.
pipelining 특징
- instruction throughput을 개선시켜준다. 하지만 latency를 개선시켜주지는 않는다.
(latency:한 instruction의 시작~종료까지 시간), (throughput: clock수) - 한 clock에서 한가지 instruction을 수행하는데, 파이프라이닝에서는 한 clock에 많은 instruction을 수행한다.
- 목표는 instruction의 latency를 줄이는 것보다는 ,프로그램 자체를 빠르게 하는것이다.
key는 inter-instruction parallism이다.
pipelining 성능
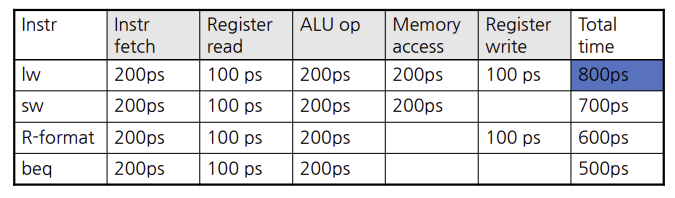
위의 표에서 보면 register read와 write에서는 100ps, 나머지 기능 유닛의 동작시간은 200ps가 걸린다.
single-cycle 설계는 가장 느린 명령어를 수용할 수 있을 만큼 clock cylce이 길어져야 한다.
위 표에서 알 수 있듯, 가장 느린 instruction의 latency는 lw로 800ps 이다.
따라서 모든 명령어에서 필요한 시간은 800ps이다.
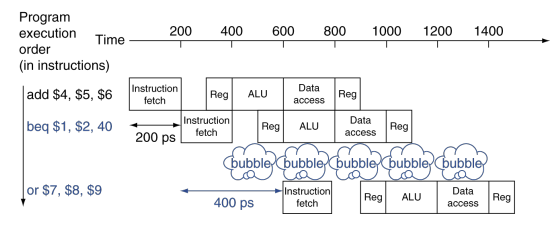
파이프라이닝이 되지 않은 설계에서 첫번째 명령어와 4번째 명령어 사이의 시간은 800ps3 = 2400ps이다.
반면, 파이프라이닝이 된 설계는 앞에 fetch에서 200ps씩 차이가 나므로, 200ps3 = 600ps이다.
파이프라이닝이 4배 더 빠른것을 알수 있다.
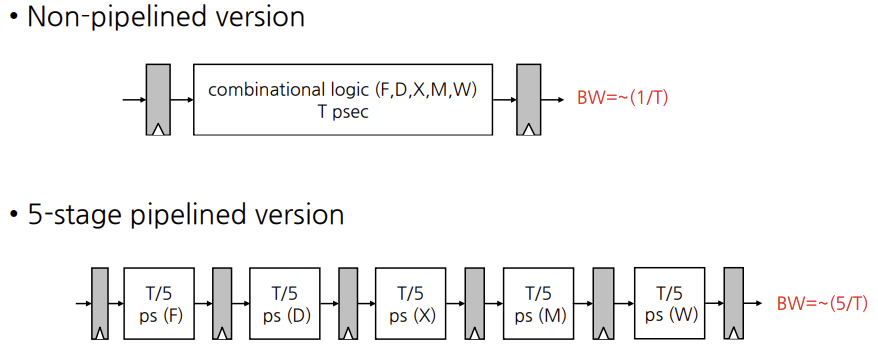
이상적인 조건에서의 식은 위의 그림처럼 non-pipelined에서의 명령어 사이의 시간보다 pipelined 에서가 단계수만큼 더 빨라야 한다. 예를들면 non-pipelined가 latency가 800ps 이므로,pipelined에서는 한 유닛이 160ps가 되어야한다. 하지만 200ps가 나온것을 알 수 있었다. 따라서, 단계가 완전히 균형잡혀 있지 않다는 것을 보여준다. 더군다나 pipelining은 어느정도의 오버헤드를 포함하고 있다.
중요한것은 pipelining은 개별 instruction의 latency를 줄이지는 못하지만 throughput은 줄일 수 있다.
실제로는 프로그램들은 수많은 명령어들을 실행시킴으로 throughput이 더 중요하다.
pipelining을 위한 ISA 설계
MIPS 명령어 집합은 원래 파이프라인 실행을 위해 설계된 것이다.
-
모든 MIPS 명령어는 같은 길이를 갖는다.(32bits)
이같은 조건은 파이프라인 단계에서 명령어를 가져오고 그 명령어들을 두번째 단계에서 해독하는 것을 훨씬쉽게 해준다.(one cycle에 해결)
예를들어, x86같은 경우는 명령어 길이가 1~15byte까지 변하기 때문에 파이프라이닝이 힘들다. -
MIPS는 몇 가지 안 되는 명령어 형식을 가지고 있다. 모든 명령어에서는 근원지 레지스터 필드는 같은 위치에 있다.
이 같은 대칭성은 두 번째 단계에서 하드웨어가 어떤 종류의 명령어가 인출되었는지를 결정하는 동안 레지스터 파일 읽기를 동시에 할 수 있다는 것을 의미한다.만약 MIPS 명령어 형식이 대칭적이 아니면 단계2를 나누어서 총 6개의 파이프라인 단계가 되었을 것이다. -
MIPS에서는 메모리 피연산자가 lw와 sw 명령어에서만 나타난다.
이같은 제한은 메모리 주소를 계산하기 위해 실행 단계를 사용하고 다음 단계에서 메모리에 접근 할 수 있다는 것을 의미한다. x86처럼 메모리에 있는 피연산자에 연산을 할 수 있으면 단계3,4가 주소단계,메모리 단계,실행 단계로 확장되어야 한다. -
피연산자는 메모리에 정렬(align)되어 있어야 한다. 따라서 한 데이터 전송 명령어가 두 번의 데이터 메모리 접근을 요구할까 봐 걱정할 필요가 없다. 파이프라인 단계 하나에서 프로세서와 메모리가 필요한 데이터를 주고 받을 수 있다.
pipeline hazard
다음 instruction이 다음 clock cycle에 실행될 수 없는 경우가 있다. 이걸 hazard라고 한다.
hazard에는 3가지 종류가 있다.
- structural hazard
- 같은 clock cycle에 실행되기 원하는 명령어의 조합을 하드웨어가 지원할 수 없다는 것을 의미
다시말하면 주어진 클럭사이클에 실행되도록 되어있는 명령어 조합을 하드웨어가 지원하지 못해서 계획된 명령어가 적절한 클럭 사이클에 실행될 수 없는 사건 - 예 1) 세탁소에서 독립된 세탁기와 건조기를 사용하지 않고 세탁기와 건조기가 붙어있는 기계를 사용하거나, 친구가 다른 일을 하느라고 바빠서 빨래를 치우지 않으면 structure hazard가 발생한다.
- 예 2) lw 명령어로 데이터 메모리에서 read하려고 할때 IF 단계에서 다음 명령어를 메모리에서 가져오려고 한다면 둘이 충돌이 나게 된다.
만약, 메모리가 하나밖에 없다면, 데이터 메모리를 먼저 사용한 다음에, IF에서 바로 명령어를 가져오지 않고 한 타임 쉰다.(pipeline stall이라고 함.)
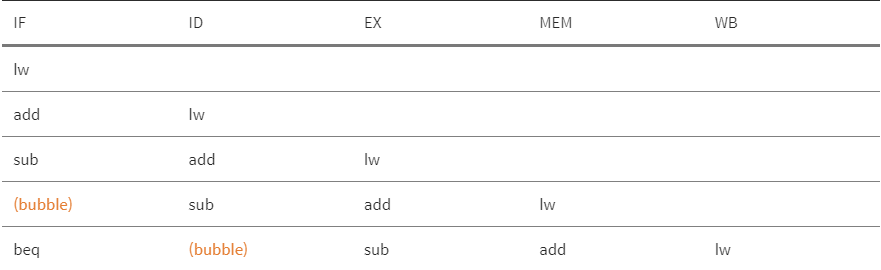
- data hazard
- 어떤 단계가 다른 단계가 끝나기를 기다려야하기 때문에 파이프라인이 지연되어야 하는 경우 일어난다.
- 어떤 명령어가 아직 파이프라인에 있는 앞선 명령어에 defendency 가질 때 data hazard가 일어난다.
- 예 1)
add $s0,$t0,$t1
sub $t2,$s0,$t3위처럼 add 명령어 바로 다음에 add의 합($s0)을 사용하는 뺄셈 명령어가 뒤따르는 경우를 가정하자.
별다른 조치가 없다면 data hazard가 파이프라인을 심각하게 지연시킬 수 있다. add 명령어는 다섯 번째 단계까지는 결과 값을 쓰지 않을텐데 이는 파이프라인이 세 개의 클럭 사이클을 낭비해야 한다는 것을 의미한다.
이럴때, forwarding이라는 것을 사용하는데, forwarding은 별도의 하드웨어를 추가하여 정상적으로는 얻을 수 없는 내부 자원으로부터 일찍 받아 오는 것을 말한다.(우회전달(bypassing))이라고도 함.
때문에 위 문제에서는 명령어를 끝까지 기다릴 필요없이 add명령어 합을 만들어내자마자 이것을 뺄셈의 입력으로 사용할 수 있다.
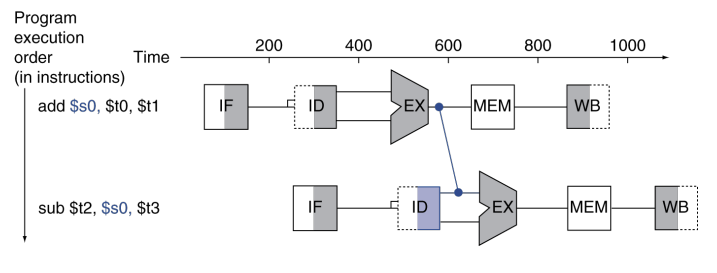
위그림은 forwarding을 나타냈다.
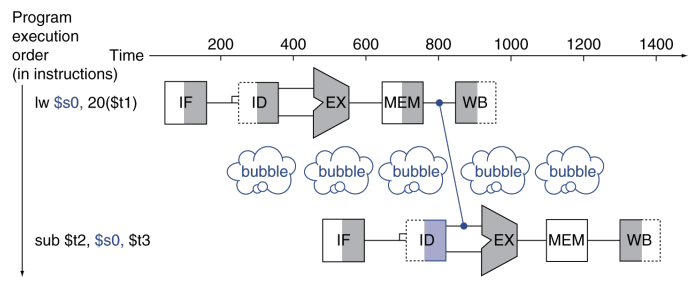
lw 명령어 다음에 나오는 R형식 명령어가 데이터를 사용하려 시도할 때는 forwarding을 해도 지연이 필요하다.
위 그림을 예로 들면, lw를 수행하고 stall 없이 sub를 수행하면 forwarding을 한다고 해도, 너무 늦다. 왜냐하면 lw가 MEM단계를 수행하지 못하고 EX 단계에서 forwarding을 진행하기 때문이다.
때문에, stall로 한 턴을 쉬어준다. 그러면 forwarding으로 sub에 올바른 데이터를 줄 수 있게 된다.
code scheduling to avoid stalls
a = b + e;
c = d + f;라는 코드를 생각해보자. 이코드를 MIPS에 대한 코드로 바꾸면 밑에 그림처럼 된다. lw 다음 add가 나오는 경우 hazard가 발생하므로 code 위치를 바꿔준다.
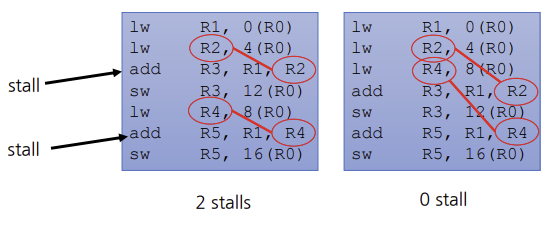
- control hazard
-
다른 명령어들이 실행 중에 한 명령어의 결과 값에 기반을 둔 결정을 할 필요가 있을 때 일어난다.
-
예1) 세탁물을 세탁하려고 하는데, 앞서 파이프라이닝된 세탁소라 물의양, 건조하는정도 등등... 기본값들은 세팅되어 있었다. 새로운 재질의 옷들의 작업요청이 들어와서 그 옷들에 대한 정보가 없어 세팅값을 알 수 없다. 첫번째 세탁을 진행했다. 이러한 경우, 첫번째 세탁에서 2번째 단계, 건조가 끝날때 까지 기다려보고 다음 세탁에서 건조기의 셋팅값을 바꿀지 말지 결정할 수 있다.
-
컴퓨터에서 이러한 작업에 해당되는 것이 바로 branch이다. 바로 다음 clock cycle에서 branch 명령어를 이을 명령어를 가져오기 시작해야 한다. 그러나 파이프라인은 지금 막 branch 명령어를 받아서 다음 명령어가 뭔지 알 수 없다. 이걸 해결하기 위한 방법은, 파이프라인의 branch 결과를 판단하고 어느 주소에서 다음 명령어를 가져올지 알게 될때까지 기다리게 하는 것이다.
이방법은,파이프라인이 긴경우 branch를 두번째 단계에서 다 해결하지 못한다면, branch 명령어마다 지연시키는 것은 훨씬 더 큰 속도 저하를 초래한다. 이방법은 따라서 너무 비효율적이다. -
따라서, branch 명령어를 다루기 위해서
prediction을 사용한다.
간단한 방법은, branch가 항상 실패한다고 예측한다. 예측이 맞으면 파이프라인은 그냥 그대로 계속 진행된다. 예측이 틀렸다면 branch가 일어나고 그때만 지연된다. -
branch prediction을 좀더 정교하게 사용하려면, 어떤경우는 branch한다(taken)고 예측하고 어떤 경우는 branch하지 않는다(untaken,not taken)고 예측하는것이다.
-static branch prediction
프로그래밍의 경우 loop문의 끝에는 loop꼭대기로 점프하라는 branch 명령어가 있다. 이 명령어들은 branch가 일어날 가능성이 높고 branch 방향이 후방이므로, 이에 착안하여 현재 위치보다 작은 주소로 점프하는 branch 명령어는 항상 일어난다고 예측할 수 있다. 이러한 branch prediction은 보편적 행동에 의존하고 특정 branch 명령어의 개별성은 고려하지 않는다.
-dynamic hardware predictor는 이와는 정반대로 개별 branch 명령어의 행동에 의존하는 예측을 하며 프로그램이 진행되는 도중에 prediction을 바꿀 수 있다.
dynamic hardware predictor의 보편적인 방법은 각 branch가 일어났는지 안 일어났는지 이력을 기록하고, 최근의 과거 이력을 사용하여 미래를 예측하는 것이다.
파이프라인 데이터패스 및 제어
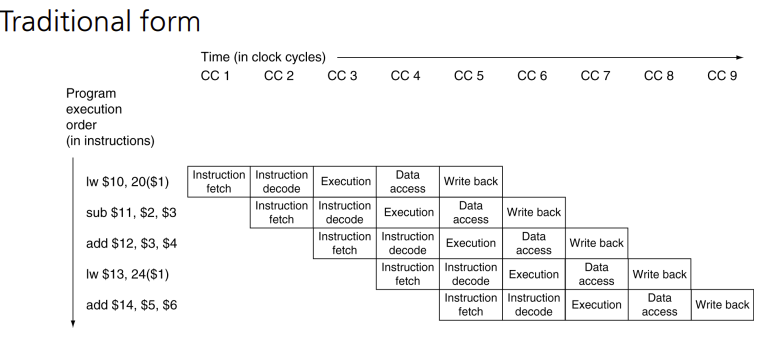
파이프라인 단계
- IF: 명령어 인출(Fetch)
- ID: 명령어 해독 및 레지스터 읽기(Decode)
- EX: 실행 또는 주소 계산 (Excute)
- MEM: 데이터 메모리 접근
- WB: 쓰기(write back)
명령어와 데이터는 실행되면서 다섯 단계를 통해 왼쪽에서 오른쪽으로 움직여간다. 이것의 예외 2가지가 있는데,
1. 쓰기 단계: 이 단계에서는 결과를 데이터패스의 중앙에 있는 레지스터 파일에 다 쓴다.
2. PC의 다음 값 선정: 증가된 PC값과 MEM 단계의 분기 주소 중에서 고른다.
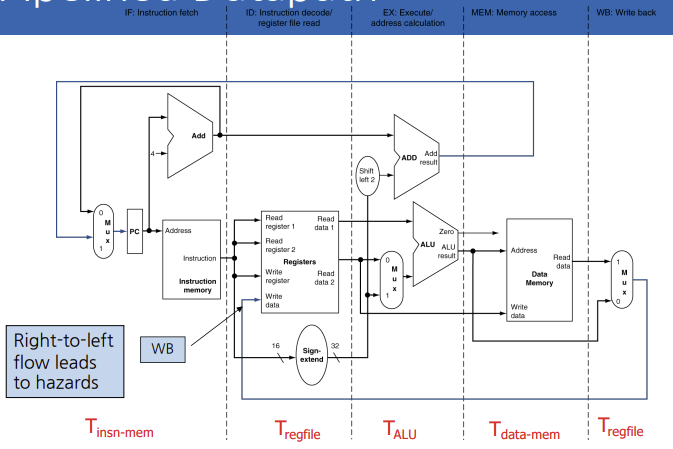
위 그림처럼, 명령어의 실행 단계는 모두 왼쪽->오른쪽으로 움직이지만, 쓰기단계와 PC 갱신에서만 오른쪽->왼쪽으로 간다.
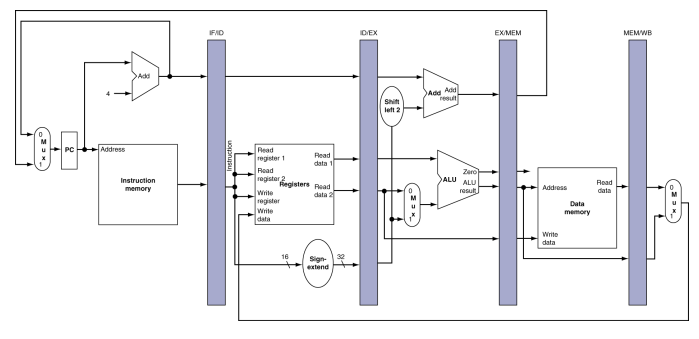
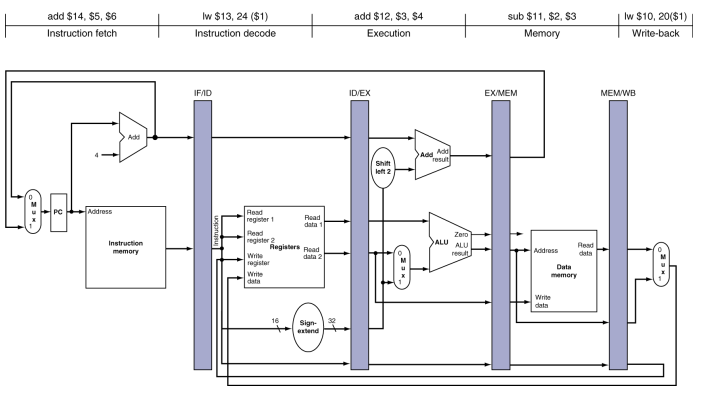
명령어 메모리는 다섯단계중에 한 단계에서만 사용된다. 그러므로 이 명령어가 다른 네 단계에 있는 동안에는 명령어 메모리는 다른 명령어가 사용할 수 있다. 다른 네 단계에서도 이 명령어 값을 유지하기 위해 명령어 메모리에서 읽어 들인 값을 레지스터에 저장해야 한다. 따라서, 각 단계 사이사이에 레지스터를 배치해야 한다.
모든 명령어는 매 clock cycle마다 한 파이프라인 레지스터에서 다음 레지스터로 전진한다. 레지스터는 이 레지스터가 분리하고 있는 두 단계를 따라서 이름을 붙힌다. 예를들면, IF/ID는 IF와 ID단계에 있다는 것이다.
쓰기(write-back) 단계 끝에는 레지스터가 없다. 그이유는,모든 명령어는 컴퓨터의 상태 -레지스터 파일, 메모리, pc- fmf 갱신해야 한다. 이렇게 갱신되는 상태는 별도의 파이프라인 레지스터가 필요없다.
예를들면, lw 명령어는 32개 레지스터 중 하나에다 결과 값을 쓰는데, 뒤에 있는 명령어 중에서 이 데이터를 필요로 하는것이 있으면 그냥 그 레지스터를 읽으면 된다. 따라서 파이프라인 레지스터에 저장할 필요가없다.
lw 명령어
각 그림에서 명령어 약어인 lw와 함께 활성화된 파이프 단계의 이름을 보여 준다.
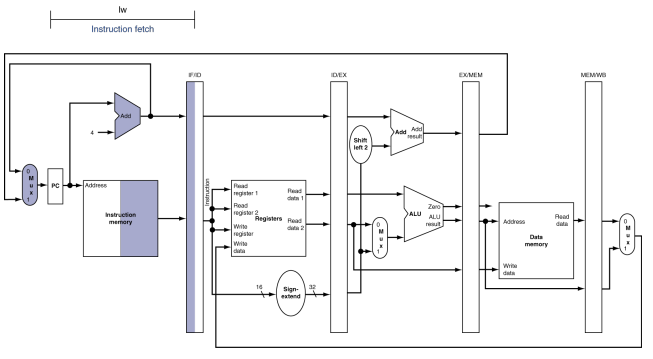
-
명령어 인출(Instrcution fetch): PC에 있는 주소를 사용하여 메모리부터 명령어 읽어오고 IF/ID 파이프라인 레지스터에 저장하는 것을 보여준다. PC 주소는 4만큼 증가되어 pc에 다시 저장됨으로써 다음 클럭 사이클에 사용 될 수 있다. 이증가한 주소는 IF/ID 파이프라인 레지스터에도 쓰이는데 이것은 beq와 같은 명령어처럼 뒤에 필요한 경우를 위해서이다.
컴퓨터는 어떤 정보를 가져올지 모르기때문에, 어떤 명령어에도 대비해야 한다.
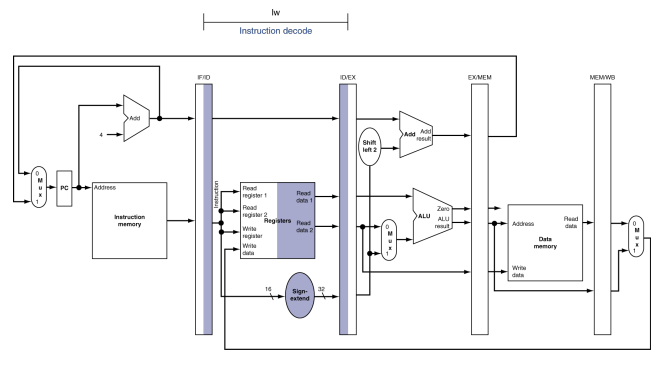
-
Decode & register file read:IF/ID 파이프라인 레지스터의 명령어 부분이 16비트 수치 필드 값과 레지스터 번호 두개를 제공하는것을 보여준다.세 값 모두 증가한 PC주소 값과 더불어 ID/EX 파이프라인 레지스터에 저장된다.차후의 clock cycle에 의해 어느 명령어에 의해 불필요할지 모르는 것은 모두 전달하다.
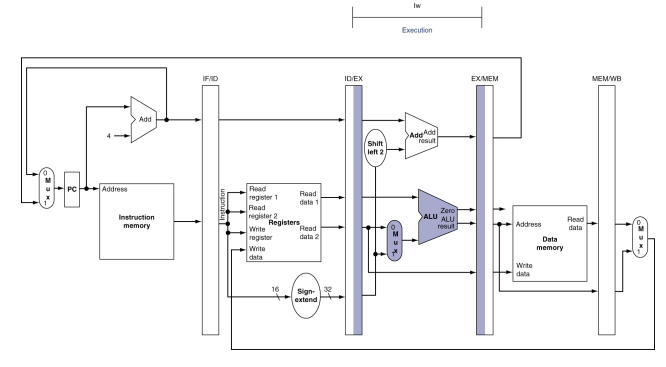
-
excute or address calculation: 그림은 lw가 ID/EX 파이프라인 레지스터로부터 레지스터 1의 내용과 부호확장된 수치를 읽고, ALU를 사용하여 이들을 더하는 것을 보여 준다. 합은 EX/MEM 파이프라인 레지스터에 저장된다.
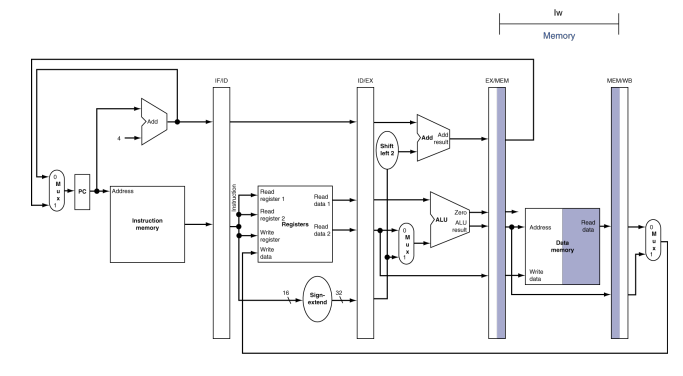
-
메모리 접근(momory access): 위그림은 lw 명령어가 EX/MEM 파이프라인 레지스터에서 주소를 받아서 데이터 메모리를 읽고 이 데이터를 MEM/WB 파이프라인 레지스터에 저장하는 것을 보여준다.
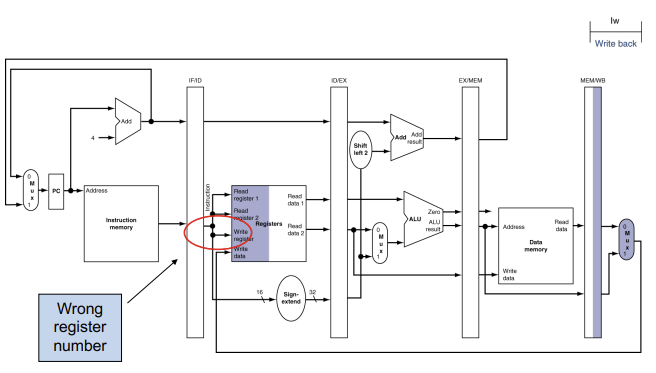
5. 쓰기(write-back): 마지막 단계이다. MEM/WB 파이프라인 레지스터에서 데이터를 읽어서 그 데이터를 그림 중앙에 있는 레지스터 파일에 쓴다.
sw 명령어
1. 명령어 인출(Fetch): PC의 주소를 사용하여 메모리에서 명령어를 읽어서 IF/ID 파이프라인 레지스터에 저장한다.
2.명령어 해독 및 레지스터 파일 읽기:IF/ID 파이프라인 레지스터에 있는 명령어가 레지스터 번호를 공급하여 두개의 레지스터를 읽고 또한 16비트 수치의 부호를 확장한다.이들 세개의 32비트 값들 모두가 ID/EX 파이프라인 레지스터에 저장된다.
첫 두 단계 같은 경우에는 모든 명령어에 의해 실행되는데, 왜냐하면 아직은 명령어 종류를 알기에는 너무 이르기 때문이다.
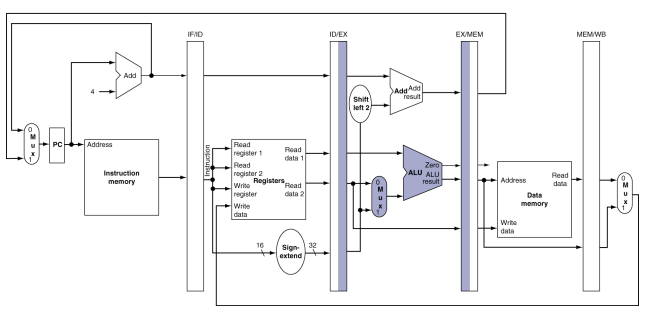
3.실행 주소 및 계산: 실제 주소는 EX/MEM 파이프라인 레지스터에 저장
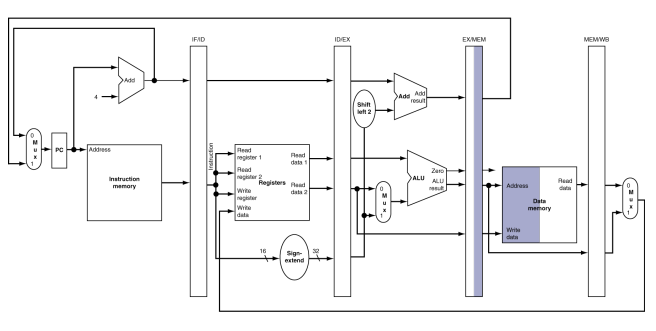
4.메모리접근: 위 그림은 데이터가 메모리에 써지고 있는 것을 보여준다. 저장되어야 할 데이터를 가지고 있는 레지스터는 앞 단계에서 읽혔고 읽힌 값은 ID/EX에 저장되어 있었다. MEM 단계에서 데이터를 쓸 수 있게 하는 유일한 방법은 EX 단계에서 데이터를 EX/MEM 파이프라인 레지스터에 저장하는 것이다. 방금 전 실제 주소를 EX/MEM에다 저장했던 것과 비슷하다.
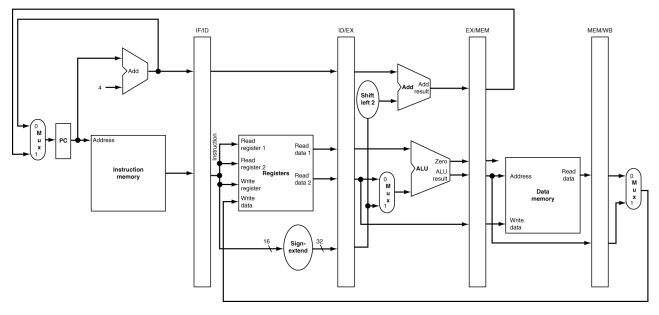
5.쓰기: 위 그림은 sw 명령어의 마지막 단계이다.
이 명령어에 관해서는 쓰기 단계에서는 아무 일도 일어나지 않는다. 저장 명령어를 뒤따르는 명령어가 이미 진행 중이기 때문에 이 명령어들을 더 빨리 수행할 방법은 없다. 따라서 어떤 명령어가 특정 단계에서 아무 일도 하지 않아도 그 단계를 거쳐 가야 한다. 왜냐하면 뒤따르는 명령어들이 최고 속도로 이미 진행 중이기 때문이다.
중요한건 앞선 파이프라인 단계에서 뒤의 파이프라인 단계로 무엇인가를 보내기 위해서는 그 정보가 파이프라인 레지스터에 저장되어야 한다. 그렇지 않으면 다음 단계에 들어섰을때 그 정보는 잃어버리게 된다.
Multi-Cycle pipeline Diagram
single-Cycle Pipeline Diagram
단일 클럭 사이클 파이프라인 다이어그램은 한 클럭 사이클 동안의 전체 데이터 패스의 상태를 표시한다.
파이프라인 제어
첫번째 단계는 기존 데이터패스에 제어선 레이블을 붙이는 것이다.
단일 사이클 구현에서 처럼 매 clock cycle마다 PC에 쓰기가 행해지기 때문에 PC를 위한 쓰기 신호는 따로 없다고 가정한다. 같은 논리로 파이프라인 레지스터들을 위한 쓰기 신호가 따로 없다. 왜냐하면 어차피 매 클럭 사이클마다 쓰기가 행해지기 때문이다.
파이프라인을 위한 제어를 명시하기 위해서는 각 파이프라인 단계 동안의 제어 값들을 정하기만 하면 된다. 각 제어선은 한 파이프라인 단계에서만 활성화되는 구성요소들과 관련 있기 때문에 제어선을 파이프라인 단계에 따라 다섯 그룹으로 나눌 수 있다.
1.fetch: 명령어 메모리를 읽고 PC 값을 쓰기 위한 제어신호들은 항상 인가(assert)되므로 이 파이프라인 단계에는 제어할 것이 없다.
2.decode/read register: 이전 단계에서와 마찬가지로 매 클럭 사이클마다 같은 일이 일어나서 설정할 제어선이 없다.
3.excute/calculate address: 설정할 신호들은 RegDst,ALUOp,ALUSrc이다. 이 신호들은 목적지 레지스터와 ALU연산을 선택하고 Read data와 부호확장된 수치 중 하나를 ALU 입력으로 선택한다.
4.메모리 접근:이 단계에서 설정되는 제어선은 Branch,MemRead,MemWrite이다. 이 신호들은 각각 같을 시 분기,적재,저장 명령어일때 설정된다. 제어가 Branch를 인가(assert)하고 ALU 결과가 0 이 아닌 한 PCSrc는 순차적인 다음 주소를 선택한다.
5.쓰기: 두 제어선은 MemtoReg과 RegWrite인데, MemtoReg는 레지스터 파일에 ALU결과를 보낼 것인가 메모리 값을 보낼 것인가를 결정하며 RegWrite는 선택된 값을 레지스터에 쓰게 하는 신호이다.
data hazard: 전방전달 대 지연
sub $s2,$s1,$s3
and $12,$2,$5
or $13,$6,$2
add $14,$2,$2
sw $15,100($2)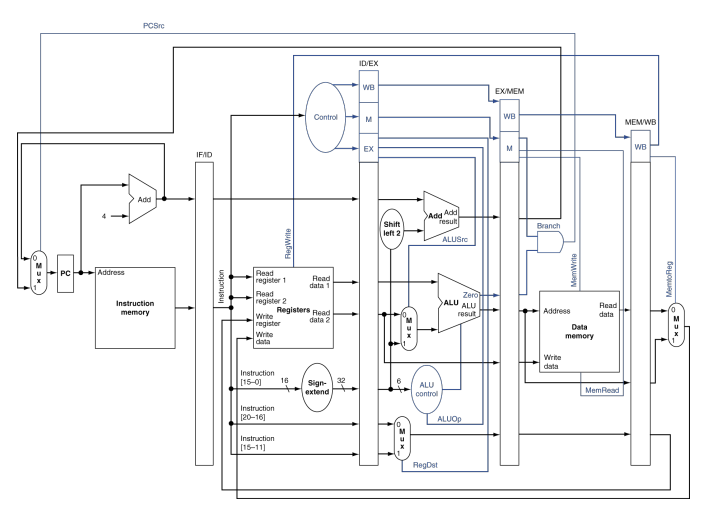
제어 신호들이 파이프라인 레지스터의 제어 부분에 연결된 그림이다.
마지막 세 단계를 위한 제어값이 명령어 해독 단계에서 생성되어 ID/EX 파이프라인 레지스터에 저장된다. 각 단계에서 필요한 제어선은 사용되고 나머지 제어선은 파이프라인 단계로 전달된다.
위 코드를 보면 마지막 네 개의 명령어가 s2가 뺄셈 명령어 이전에는 값 10을 가지고 있었고 뺄셈 명령어 이후에는 -20을 가진다면 프로그래머는 레지스터$2를 참조하는 그 다음 명령어들이 -20을 사용하는 것을 의도했을 것이다.
그렇다면 파이프라인에서는 어떻게 수행될까?
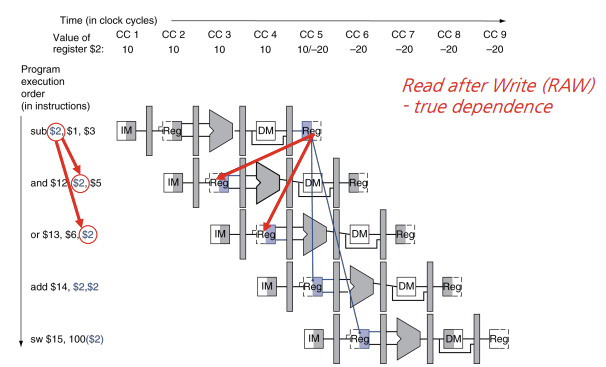
위 그림에서 dependency는 파란색으로 표시했고, 위에 cc1은 clock cycle1을 의미한다. 첫번째 명령어는 $2에 쓰기를 하고 뒤에 나오는 모든 명령어는 $2를 읽는다. 이 레지스터에는 cc5에 쓰기가 행해지기 때문에 올바른 값은 cc5 이전에는 사용할 수 없다.(특정 clock cycle에 레지스터를 읽으면 그 clock의 전반부의 끝에서 쓰기가 이루어진 값을 읽게 되는 것이다.) 시간상 후방으로 가야하는 것들이 파이프라인 데이터 헤저드이다.
위 그림을 보면 cc5 이후에 읽기가 일어나야 레지스터 $2를 올바르게 읽고 다음 명령어들을 수행할 수 있다. 첫번째 명령어는 cc3에서 $s2의 결과가 만들어진다.
다음 명령어인 and와 or은 $s2가 언제 필요할까? 각각 cc4와 cc5이다.
sub 명령어가 cc3에서 값을 만들자마자 다음 명령어 cc4와 cc5로 값을 forwarding 하기만 한다면 지연 없이 실행 할 수 있다.
파이프라인 레지스터의 필드에 이름을 붙이면 dependency를 좀 더 자세히 표시할 수 있다. 'ID/EX.RegisterRs'는 파이프라인 레지스터 ID/EX에 있는 한 레지스터의 번호, 즉 레지스터 파일의 첫 번째 읽기 포트에 실린 레지스터 번호를 나타낸다. 이름의 첫번째 부분('.'왼쪽부분)은 파이프라인 레지스터 이름이고, 두 번째 부분은 그 레지스터의 필드 이름이다. 이같은 표기 방법을 이용해서 두 쌍의 헤저드 조건을 표시하면 다음과 같다.
1a.EX/MEM.RegisterRd=ID/EX.RegisterRS
1b.EX/MEM.RegisterRd=ID/EX.RegisterRt
2a.MEM/WB.RegisterRd=ID/EX.RegisterRS
2b.MEM/WB.RegisterRd=ID/EX.RegisterRt
sub $s2,$s1,$s3
and $12,$2,$5
or $13,$6,$2
add $14,$2,$2
sw $15,100($2)위 코드에서 첫번째 hazard는 레지스터$2에 관한 것으로 sub $2,$1,$3의 결과와 and $12,$2,$5의 첫 번째 읽기 피연산자 사이에서 발생한다. 이같은 hazard는 and 명령어가 EX단계에 있고 앞선 명령어(sub)가 MEM 단계에 있을때 검출될수있다. 즉 조건 1a를 만족시킨다.
EX/MEM.RegisterRd=ID/EX.RegisterRs=$2
sub-or은 어떨까??
or이 ID/EX 에 있을때, sub는 MEM/WB 레지스터에 있다. 따라서
MEM/WB.RegisterRd=ID/EX.RegisterRt=$2
sub-add의 두개의 defendency는 hazard가 아니다. 왜냐하면 add 단계에서는 sub가 writeback까지 끝난상황이라 이미 올바른 데이터를 제공하고 있다.
sub-sw도 마찬가지다.
어떤 명령어들은 레지스터에 쓰기를 하지 않기 때문에 이 같은 방침은 정확하지 않다. 필요 없을때도 forwarding을 하는 경우가 있기 때문이다. 한가지 해결책은 RegWrite 신호가 활성화되어 있는지 확인하는 것이다.
EX단계와 MEM단계 동안에 파이프라인 레지스터의 WB제어 필드를 조사하면 RegWrite 신호가 인가(assert)되어 있는지를 알 수 있다. 또 MIPS의 $0는 항상 상수0을 가지고 있어서 그값을 바꿀 수 없다.
파이프라인에 있는 명령어의 목적지가 $0이라면 (ex. sll $0,$1,2) 결과값을 굳이 forwarding할 필요가 없다. 레지스터$0로 가는 값은 forwarding하지 않는다면 어셈블리 프로그래머나 컴파일러에게 $0를 목적지 레지스터로 사용하지 말라고 할 필요도 없다.
다음과 같은 조건을 추가하면 될 것이다.
EX/MEM.RegisterRd != 0, MEM/WB.RegisterRd != 0
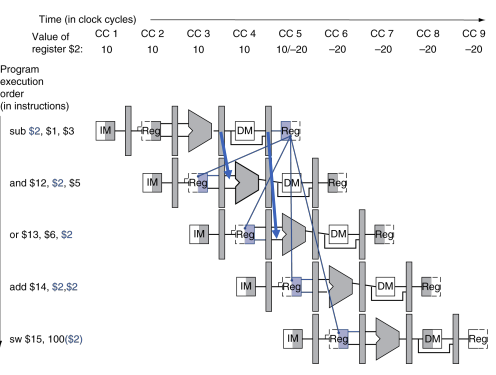
위 그림은 WB단계가 레지스터파일에 쓸 때까지 기다리는 대신 파이프라인 레지스터에서부터 dependency가 시작된다. 파이프라인 레지스터가 forwarding할 데이터를 가지고 있기 때문에 요구한 데이터는 후속 명령어들이 필요한 시간에 맞추어 도착한다.
ID/EX 레지스터뿐만 아니라 어느 파이프라인 레지스터에서라도 ALU 입력을 가져올 수가 있다면 적절한 데이터를 forwarding할 수 있다.
ALU 입력에 멀티플렉서를 추가하고 적절한 제어를 붙이면 이 같은 data dependency가 존재하더라도 파이프라인을 최고속도로 실행할 수 있다.
hazard를 검출하기 위한 조건과 이 hazard를 해결하기 위한 제어신호
- EX hazard
if(EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRs))
ForwardA = 01
if(EX/MEM.RegWrite and (EX/MEM.RegisterRd != 0) and (EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01
이같은 조건이 무슨뜻이냐면
EX/MEM.RegisterRd 필드는 ALU 명령어의 레지스터 목적지나 lw 명령어의 레지스터 목적지이다.
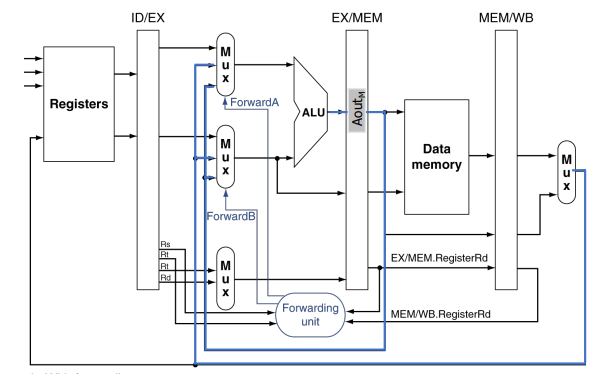
이 경우에는 바로 앞 명령어의 결과를 ALU 입력 중 하나로 forwarding 한다. 바로 앞 명령어가 레지스터 파일에 쓰기를 하는 명령어이고 쓰기 레지스터 번호가 ALU 입력 A나 B의 읽기 레지스터 번호와 같다면(레지스터는 0 이 아니다.) 파이프라인 레지스터 EX/MEM에서 값을 받도록 멀티플렉서를 제어한다.(EX 단계에서 일어남) 아래 그림은 참고 그림이다.
- MEM hazard
if(MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0) and (MEM/WB.RegisterRd != ID/EX.RegisterRs))
ForwardA = 01
if(MEM/WB.RegWrite and(MEM/WB.RegisterRd != 0) and(MEM/WB.RegisterRd = ID/EX.RegisterRt))
ForwardB = 01
WB 단계에는 hazard가 없다. 왜냐하면 WB 단계에 있는 명령어가 값을 저장하는 레지스터를 ID 단계에 있는 명령어가 읽는다면 레지스터 파일은 올바른 값을 제공한다고 가정하기 때문이다. 이러한 레지스터 파일은 다른 형태의 forwarding을 하고 있는 셈이지만 이 일은 레지스터 파일 내에서 일어난다.
한가지 복잡한 것은 WB단계에 있는 명령어의 결과 값과 MEM 단계에 있는 명령어의 결과 값 모두와 ALU 단계에 있는 명령어의 근원지 피연산자 사이에 데이터 헤저드가 일어날 수 있다는 것이다.
예를들면, 어떤 벡터를 한 레지스터에서 합한다고 할 때 명령어 코드 모두가 같은 레지스터를 읽고 쓰려고 할 것이다.
add $s1,$s1,$s2
add $s1,$s1,$s3
add $s1,$s1,$s4
...이 경우에 결과 값은 MEM 단계로부터 forwarding된다. 왜냐하면 MEM 단계에 있는 결과 값이 더 최근의 것이기 때문이다. 따라서 MEM hazard에 대한 제어는 다음과 같다.(추가된 부분 파란색)
if(MEM/WB.RegWrite and (MEM/WB.RegisterRd != 0)
and not (EX/MEM.RegWrite and(EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd != ID/EX.RegisterRs))
and(MEM/WB.RegisterRd != ID/EX.RegisterRs))
ForwardA = 01
if(MEM/WB.RegWrite and(MEM/WB.RegisterRd != 0)
and not (EX/MEM.RegWrite and(EX/MEM.RegisterRd != 0)
and (EX/MEM.RegisterRd != ID/EX.RegisterRt))
and(MEM/WB.RegisterRd = ID/EX.RegisterRt))
ForwardB = 01
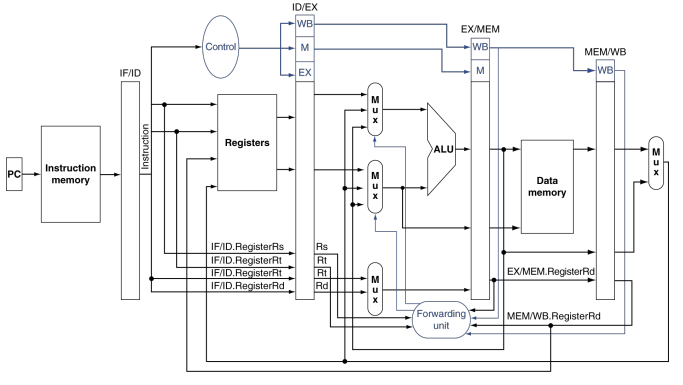
밑의 그림은 EX 단게의 명령어를 위한 전방전달을 지원하기 위해 필요한 하드웨어를 보여준다.
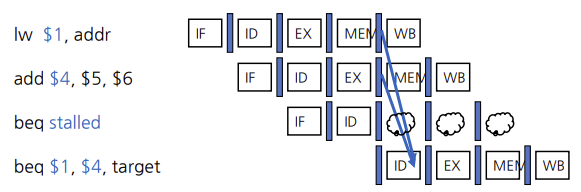
data hazard 와 stall
forwarding이 해결 못하는 경우 중 하나는 lw 명령어를 뒤따르는 명령어가 lw 명령어 에서 쓰기를 행하는 레지스터를 읽으려고 시도할 때 이다. 밑에 그림과 같은경우이다.
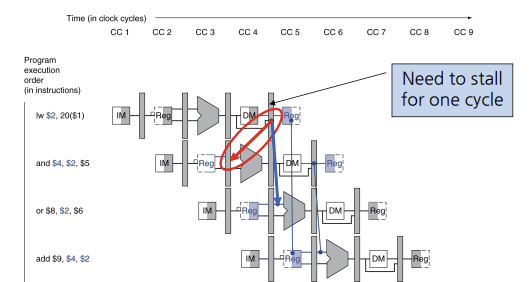
lw 명령어와 다음 명령어 and 사이의 dependency는 시간상 후방으로 간다. 따라서 이 hazard는 forwarding으로는 해결할 수 없다.
이런 명령어 조합이 나왔을 때에는 hazard 검출 유닛이 파이프라인을 지연시킨다.
hazard 검출유닛은 ID 단계에서 동작하여 lw 명령어와 결과 값 사용 사이에 지연을 추가할 수 있도록 한다. lw 명령어만 검사하면 되므로 hazard 검출유닛에 대한 제어는 아래와 같은 단 한가지 조건을 갖는다.
if(ID/EX.MEMRead and
((ID/EX.RegisterRt = IF/ID.RegisterRs)
or (ID/EX.RegisterRt = IF/ID.RegisterRt)))
stall the pipeline
첫째 줄은 명령어가 lw 인지 확인.
다음 줄은 EX단계에 있는 lw 명령어의 목적지 레지스터 필드가 ID단계에 있는 명령어의 근원지 레지스터인지 확인
조건이 충족되면 명령어는 한 clock cycle 만큼 지연(stall)된다.
한 clock cycle 만큼 지연후에는 forwarding 회로가 dependency를 처리할 수 있으므로 실행은 계속 진행된다.
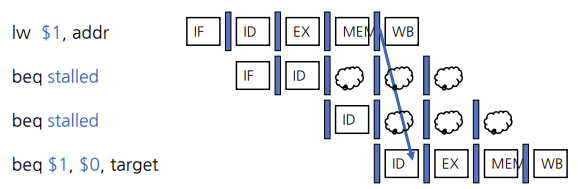
지연되는 방법은 다음과 같다.
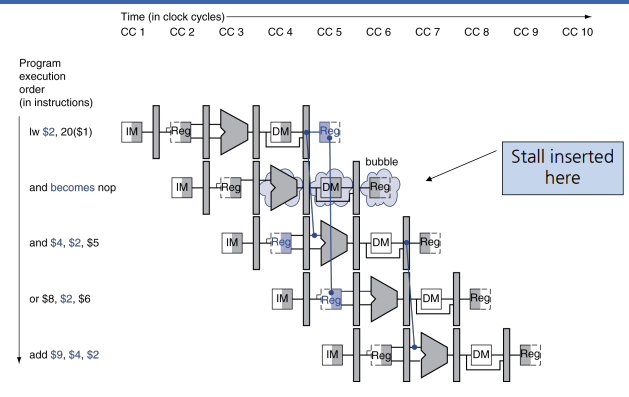
위에 그림처럼 nop이라는 명령어를 실행시킨다.(nop은 아무기능도 하지 않는다.) 원래 and 자리에는 nop이 실행되어 and명령어는 한 사이클씩 지연된다.
그렇다면 이 nop은 어떻게 파이프라인에 삽입 된걸까?
EX,MEM,WB 단계의 9개 신호를 모두 인가하지 않으면 nop 명령어를 만들 수 있다. ID 단계에서 hazard를 찾아내면 ID/EX 파이프라인 레지스터의 EX,MEM,WB 제어 필드 값을 모두 0으로 만들어서 파이프라인에 거품효과를 집어넣을 수 있다.(사실 RegWrite와 MemWrite 신호만 0으로 만들면 되고 나머지 제어신호들은 don't care일 수도 있다.) 모든 제어 값이 0이므로 레지스터나 메모리에는 쓰기가 전혀 행해지지 않는다.
stall은 performance를 줄이지만 올바른 결과값을 갖기 위해서는 필요하다
complier는 대개 하드웨어에 의존해서 hazard를 해결하고 그렇게 함으로써 올바른 실행을 보장받지만, 최고 성능을 얻기 위해서는 compiler가 파이프라인 을 이해해야 한다. 그렇지 않으면 기대하지 않았던 stall이 컴파일된 코드의 성능을 저하시킬 것이다.
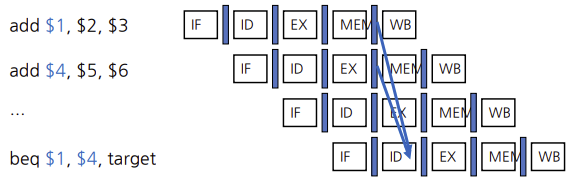
branch hazard
윗부분 까지는 산술연산과 데이터 이동을 포함하는 hazard만 다루었지만, 사실 branch를 포함하는 파이프라인 hazard가 있다.
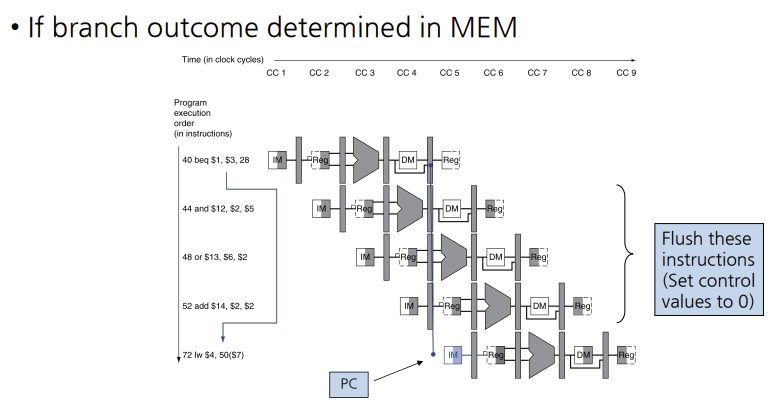
branch가 일어나지 않는다고 가정
branch가 끝날 때까지 지연시키는 것은 너무 느리다. branch stalling 보다 좋은 방법으로 많이 쓰이는 것은 branch가 일어나지 않는다고 예측하고 명령어들을 순서대로 계속 실행하는 것이다. 만약에 branch가 일어나면 fetch되고 decoding되었던 명령어들을 버리고 branch 목적지에서 계속 실행한다.
branch에 따른 지연 줄이기
branch 성능을 향상시키는 한 가지 방법은 branch가 일어났을 때 비용을 줄이는 것이다.
지금까지는 PC가 MEM 단계에서 결정된다고 가정하였다. 만약에 파이프라인에서 branch 결정을 좀더 앞당겨서 할 수 있다면 더 적은 수의 명령어를 없애 버려도 된다.
1 clock cycle의 패널티가 있다.
지연을 줄이는 예들
branch prediction
짧은 파이프라인에서는 branch가 일어나지 않는다고 가정하고 branch가 일어났을경우에는 파이프라인에 있는 데이터를 쓸어내는 방법이 적당한 방법이다. 하지만 파이프라인이 깊어지면 branch 실패로 인한 손실이 증가한다.
이러한 단순한 정적예측 방법은 너무 많은 손실을 초래한다.
dynamic branch prediction
dynamic branch prediction이란 분기 명령어가 지난번에 실행되었을 때 분기가 일어났는지를 알아보기 위해 명령어 주소를 살펴보는 것이다. 즉, 실행 정보를 이용하여 실행 시에 branch를 예측하는 것이다. 만약 분기가 일어났다면 지난번과 같은 주소에서 새로운 명령어를 가져오도록 한다.
이 기법을 구현하는 방법은 분기 예측 버퍼(branch prediction buffer)또는분기 이력표(branch history table)라고 하는 자료구조를 이용하는 것이다. branch prediction buffer는 branch 명령어 주소의 하위 비트에 의해 인덱스되는 작은 메모리이다.
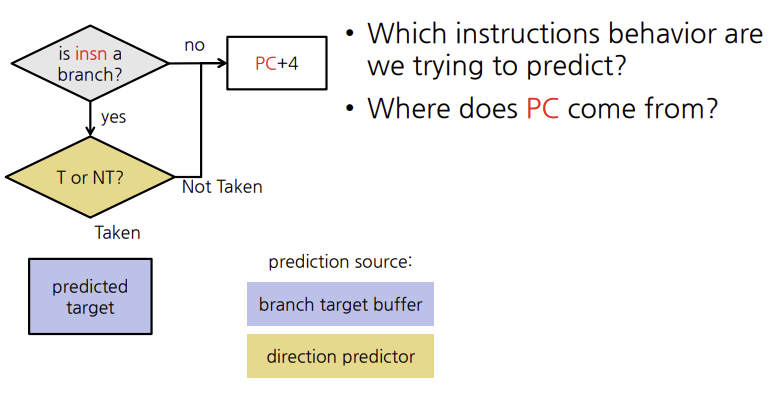
Direction predictor(DIRP)
MAP형태이고, PC의 branch 상태를 taken/not-taken(T/N)으로 결정
branch history table(BHT)
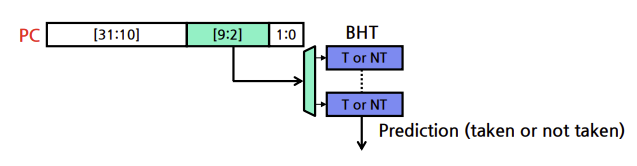
가장 간단한 predictor이다.
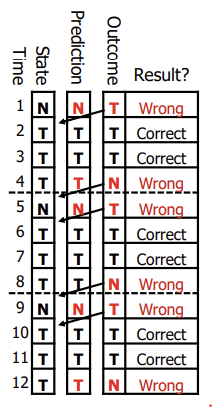
결과값은 항상 다음시간 state로 간다.
prediction이 맞았다면 다음번에도 같은 prediction 값을 가지고, 틀렸다면 prediction을 바꾼다.
이 같은 간단한 1비트 예측 방법은 문제를 가지고 있다. 분기가 거의 항상 일어날지라도 분기가 일어나지 않을 때는 한번이 아닌 두번의 잘못된 예측을 할 가능성이 높다.
TWO- bit Saturating Counters(2bc,2비트 예측 방법)
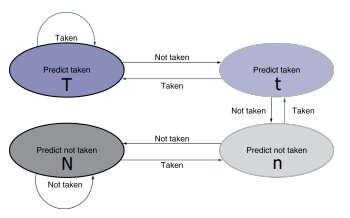
1비트 예측 방법을 보완하기위해 나왔다.
이 방법은 예측이 두번 잘못되면 예측값을 바꾼다.
1비트 예측이 (0,1) = (N,T) 였다면, 2비트 예측은 (0,1,2,3) = (N,n,t,T)이다.
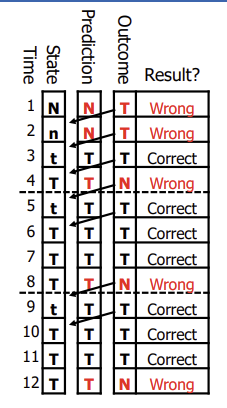
위 그림과 같이 miss 확률이 줄었다.
Branch target buffer(BTB)
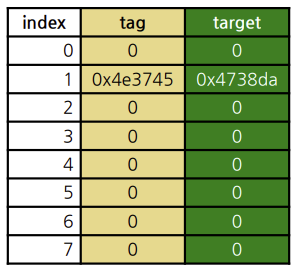
is-a-branch = (BTB[hash(PC)].tag == PC) ? 1 : 0
predicted-target = (BTB[hash(PC)].tag == PC) ? BTB[PC].target:0
Delayed Branching(지연 분기)
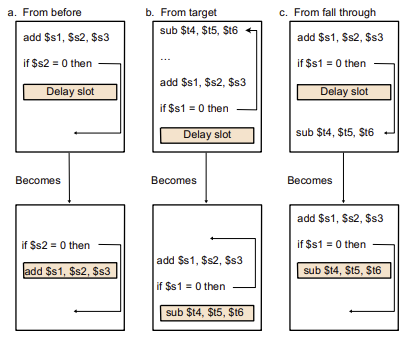
지연 분기는 branch에 대상이 되는 명령어를 Delay slot 자리에 데려온다. 하지만 전체적인 실행에는 재배열된 명령어 순서가 영향을 미치지는 않는다.
