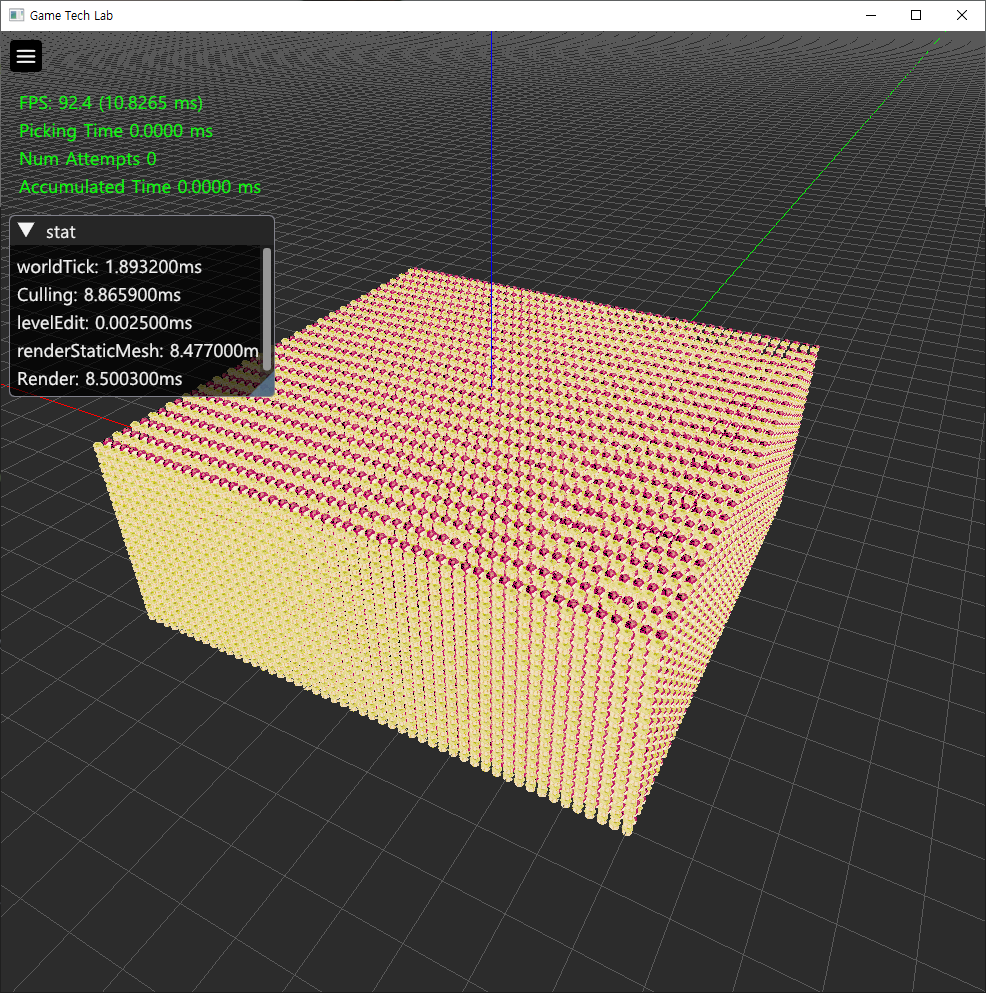
인스턴싱을 쓰지 않고 수만개의 오브젝트를 그리는 과제였다.
SIMD 적용
Matrix, Vector 연산을 SIMD로 대체하였다. SIMD가 없는 조건, SSE, 그리고 AVX에 대응하여 제작하였다.
Vector 내적
// 벡터 내적
float FVector::Dot(const FVector& other) const {
#if defined(__AVX2__)
__m128 vTemp = _mm_dp_ps(_mm_set_ps(0.f, z, y, x), _mm_set_ps(0.f, other.z, other.y, other.x), 0xff);
return vTemp.m128_f32[0];
#elif defined(_XM_SSE_INTRINSICS_)
__m128 vTemp2 = _mm_set_ps(0.f, other.z, other.y, other.x);
__m128 vTemp1 = _mm_set_ps(0.f, z, y, x);
__m128 vTemp = _mm_mul_ps(vTemp1, vTemp2);
vTemp = _mm_hadd_ps(vTemp, vTemp);
vTemp = _mm_hadd_ps(vTemp, vTemp);
return vTemp.m128_f32[0];
#else
return x * other.x + y * other.y + z * other.z;
#endif
}Vector 외적
FVector FVector::Cross(const FVector& Other) const {
#if defined(_XM_SSE_INTRINSICS_)
// reference : https://geometrian.com/resources/cross_product/
__m128 vec0 = _mm_set_ps(0.f, z, y, x);
__m128 vec1 = _mm_set_ps(0.f, Other.z, Other.y, Other.x);
float vTemp[4];
// for intel
__m128 tmp0 = _mm_shuffle_ps(vec0, vec0, _MM_SHUFFLE(3, 0, 2, 1));
__m128 tmp1 = _mm_shuffle_ps(vec1, vec1, _MM_SHUFFLE(3, 1, 0, 2));
__m128 tmp2 = _mm_mul_ps(tmp0, vec1);
__m128 tmp3 = _mm_mul_ps(tmp0, tmp1);
__m128 tmp4 = _mm_shuffle_ps(tmp2, tmp2, _MM_SHUFFLE(3, 0, 2, 1));
_mm_store_ps(vTemp, _mm_sub_ps(tmp3, tmp4));
// for amd
//__m128 tmp0 = _mm_shuffle_ps(vec0, vec0, _MM_SHUFFLE(3, 0, 2, 1));
//__m128 tmp1 = _mm_shuffle_ps(vec1, vec1, _MM_SHUFFLE(3, 1, 0, 2));
//__m128 tmp2 = _mm_shuffle_ps(vec0, vec0, _MM_SHUFFLE(3, 1, 0, 2));
//__m128 tmp3 = _mm_shuffle_ps(vec1, vec1, _MM_SHUFFLE(3, 0, 2, 1));
//__m128 tmp4 = _mm_sub_ps(_mm_mul_ps(tmp0, tmp1), _mm_mul_ps(tmp2, tmp3));
//_mm_store_ps(vTemp, tmp4);
return FVector(vTemp[0], vTemp[1], vTemp[2]);
#else
return FVector{
y * Other.z - z * Other.y,
z * Other.x - x * Other.z,
x * Other.y - y * Other.x
};
#endif
}
참고 : https://geometrian.com/resources/cross_product/
Matrix 덧셈
// 행렬 덧셈.
FMatrix FMatrix::operator+(const FMatrix& Other) const {
#if defined(__AVX2__)
FMatrix m;
m._rowin256[0] = _mm256_add_ps(_rowin256[0], Other._rowin256[0]);
m._rowin256[1] = _mm256_add_ps(_rowin256[1], Other._rowin256[1]);
return m;
#elif defined(_XM_SSE_INTRINSICS_)
FMatrix m;
m.row[0] = _mm_add_ps(row[0], Other.row[0]);
m.row[1] = _mm_add_ps(row[1], Other.row[1]);
m.row[2] = _mm_add_ps(row[2], Other.row[2]);
m.row[3] = _mm_add_ps(row[3], Other.row[3]);
return m;
#else
FMatrix Result;
for (int32 i = 0; i < 4; i++)
for (int32 j = 0; j < 4; j++)
Result.M[i][j] = M[i][j] + Other.M[i][j];
return Result;
#endif
}Matrix 곱셈
// 행렬 곱셈.
FMatrix FMatrix::operator*(const FMatrix& Other) const {
#if defined(_XM_SSE_INTRINSICS_)
FMatrix R;
// B를 column 단위로 분해
__m128 B0 = Other.row[0];
__m128 B1 = Other.row[1];
__m128 B2 = Other.row[2];
__m128 B3 = Other.row[3];
// A의 row들과 B의 columns 내적
for ( int i = 0; i < 4; ++i ) {
__m128 r = row[i];
R.row[i] = _mm_add_ps(
_mm_add_ps(
_mm_mul_ps(_mm_shuffle_ps(r, r, _MM_SHUFFLE(0, 0, 0, 0)), B0),
_mm_mul_ps(_mm_shuffle_ps(r, r, _MM_SHUFFLE(1, 1, 1, 1)), B1)
),
_mm_add_ps(
_mm_mul_ps(_mm_shuffle_ps(r, r, _MM_SHUFFLE(2, 2, 2, 2)), B2),
_mm_mul_ps(_mm_shuffle_ps(r, r, _MM_SHUFFLE(3, 3, 3, 3)), B3)
)
);
}
return R;
#else
FMatrix Result = {};
for (int32 i = 0; i < 4; i++)
for (int32 j = 0; j < 4; j++)
for (int32 k = 0; k < 4; k++)
Result.M[i][j] += M[i][k] * Other.M[k][j];
return Result;
#endif
}Vector * Matrix
// FVector4를 변환하는 함수
FVector4 FMatrix::TransformVector(const FVector4& v, const FMatrix& m)
{
#if defined(__AVX2__)
FMatrix MT = FMatrix::Transpose(m);
__m256 vec = _mm256_set_ps(
v.a, v.z, v.y, v.x,
v.a, v.z, v.y, v.x
);
float* xy = _mm256_mul_ps(vec, _mm256_loadu_ps(MT.M[0])).m256_f32;
float* zw = _mm256_mul_ps(vec, _mm256_loadu_ps(MT.M[2])).m256_f32;
return FVector4(
xy[0] + xy[1] + xy[2] + xy[3],
xy[4] + xy[5] + xy[6] + xy[7],
zw[0] + zw[1] + zw[2] + zw[3],
zw[4] + zw[5] + zw[6] + zw[7]
);
#elif defined(_XM_SSE_INTRINSICS_)
FMatrix MT = FMatrix::Transpose(m);
__m128 vec = _mm_set_ps(v.a, v.z, v.y, v.x);
float* xx = _mm_mul_ps(vec, MT.row[0]).m128_f32;
float* yy = _mm_mul_ps(vec, MT.row[1]).m128_f32;
float* zz = _mm_mul_ps(vec, MT.row[2]).m128_f32;
float* ww = _mm_mul_ps(vec, MT.row[3]).m128_f32;
return FVector4(
xx[0] + xx[1] + xx[2] + xx[3],
yy[0] + yy[1] + yy[2] + yy[3],
zz[0] + zz[1] + zz[2] + zz[3],
ww[0] + ww[1] + ww[2] + ww[3]
);
#else
FVector4 result;
result.x = v.x * m.M[0][0] + v.y * m.M[1][0] + v.z * m.M[2][0] + v.a * m.M[3][0];
result.y = v.x * m.M[0][1] + v.y * m.M[1][1] + v.z * m.M[2][1] + v.a * m.M[3][1];
result.z = v.x * m.M[0][2] + v.y * m.M[1][2] + v.z * m.M[2][2] + v.a * m.M[3][2];
result.a = v.x * m.M[0][3] + v.y * m.M[1][3] + v.z * m.M[2][3] + v.a * m.M[3][3];
return result;
#endif
}이외
대부분 연산은 DirectXMath를 기준으로 참고하였다. SSE2까지만 적용되어 있어 AVX2는 따로 적용시켜야 했다.
하지만 행렬곱, 역행렬 등에 AVX2를 적용시키기가 어려웠다. 나중에 기회가 되면 적용시켜보고 싶다.
Octree
공간분할 기법으로 크게 BVH, K-d Tree, Octree 등이 있는데 이 중에서 Octree를 사용하였다.
다른 기법들과 마찬가지로 OcTree 역시 트리 구조로 이루어져 있는데, 공간을 각 축으로 이등분해서 총 8개의 작은 공간으로 나눈다. leaf는 Elements에 저장되고, leaf가 아닌 node는 Children에 저장된다.
이를 활용해서 몇 가지 기능을 만들었다.
Ray Collision Test
평가 기준 중 피킹 시간도 있었기 때문에, Ray Collision Test에 걸리는 시간도 줄여야 했다.
- 만약 현재 노드가 Ray와 충돌하지 않으면 return
- 만약 현재 노드가 Ray와 충돌하면
Elements에 대해 충돌 감지.Callback실행 - 만약 현재 노드가 Ray와 충돌하면
Children에 대해 충돌 감지. 재귀 실행.
이런 방식으로 효과적으로 피킹 시간을 줄일 수 있었다. 예상컨대 이 오브젝트 수일 때 에서 최소 으로 줄어들었지 않았을까 한다.
void QueryCollisionRay(
const std::shared_ptr<FOctreeNode<T>> Node,
const FVector& origin,
const FVector& direction,
std::function<void(const FOctreeElement<T>&, float)> Callback
) const {
float hitDistance = FLT_MAX;
if ( !Node->Bounds.IntersectRay(origin, direction, hitDistance) )
return;
// 현재 노드의 요소 검사
for ( const FOctreeElement<T>& elem : Node->Elements ) {
if ( elem.Bounds.IntersectRay(origin, direction, hitDistance) ) {
Callback(elem, hitDistance);
}
}
// 자식 노드 탐색
if ( !Node->IsLeaf ) {
for ( int i = 0; i < 8; ++i ) {
if ( Node->ChildrenCullFlags & 1 << i )
continue;
if ( Node->Children[i] )
QueryCollisionRay(Node->Children[i], origin, direction, Callback);
}
}
}Culling
모든 오브젝트를 batching시켜도 렌더 자체에 시간이 걸려 프레임 드랍이 발생했다. 렌더 부하를 줄이기 위해서라도 Culling이 필요한 상황이었다.
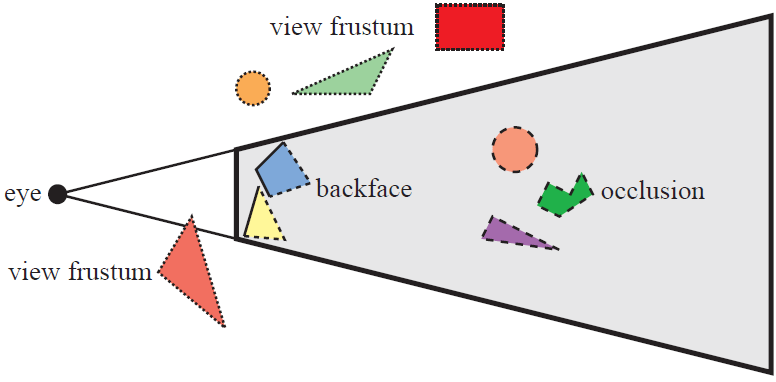
Frustum Culling
절두체 (Frustum) 밖에 있는 (즉 시야에 들어오지 않는) 오브젝트의 렌더를 생략하는 방법이다.
평면의 방정식에 점을 대입하여 (= 평면의 normal과 점을 내적한 값에 D를 더하여) 모든 평면에 대해 0 이상이 나오면, 그 점은 육면체의 내부에 있는 것이다.
이를 이용하여 Octree Node가 가진 Bounding Box의 min, max 두 점이 모두 절두체 바깥에 있다면 culling한다.
bool FFrustum::IsBoxVisible(const FBoundingBox& Box) const
{
for (int i = 0; i < 6; ++i)
{
const FFrustumPlane& Plane = Planes[i];
FVector PositiveVertex(
Plane.Normal.x >= 0 ? Box.max.x : Box.min.x,
Plane.Normal.y >= 0 ? Box.max.y : Box.min.y,
Plane.Normal.z >= 0 ? Box.max.z : Box.min.z
);
if (Plane.Normal.Dot(PositiveVertex) + Plane.D < 0)
{
return false;
}
}
return true;
}void FrustumCullRecursive(const std::shared_ptr<FOctreeNode<T>>& Node, const FFrustum &frustum) const
{
if (Node->IsLeaf)
{
int i = 0;
for ( const auto& elem: Node->Elements )
{
if (!frustum.IsBoxVisible(elem.Bounds)) {
Node->ChildrenCullFlags |= 1 << i;
}
++i;
}
return;
}
for (int i = 0; i < 8; ++i)
{
if (Node->Children[i]) {
if ( frustum.IsBoxVisible(Node->Children[i]->Bounds) ) {
FrustumCullRecursive(Node->Children[i], frustum);
} else {
Node->ChildrenCullFlags |= 1 << i;
}
}
}
}참고
CPU Occlusion Culling
하지만 모든 오브젝트가 절두체 내부에 들어오면 (즉 시야에 들어오게 되면) Frustum Culling이 사실상 적용되지 않는다. 그럼에도 앞의 사물에 가려 보이지 않는 것들이 보이는데 이를 걸러내는 것이 Occlusion Culling이다.
픽셀 단위의 정교한 Occlusion Culling을 위해서는 GPU를 이용하여 비싼 계산을 수행해야 한다. GPU에 Query를 날리거나, Compute Shader를 통해서 계산하거나 하는 방법이 있는데 기본적으로 느리고 최적화는 어렵다고 한다. 참고.
때문에 Query를 날리지 않고 CPU에서 Occlusion을 간단히 계산하는 방법을 찾아보았다.
우선 각 Octree Node에 오브젝트가 빽빽히 밀집해 있다고 가정하였다. 그러면 필연적으로 각도에 따라 다른 Node에 가려지는 Node가 발생한다.
가려지는 Node라면, 그 Node가 가진 Bouding Box의 8점이 모두 카메라에 가려질 것이다. 즉 카메라와 각 점을 잇는 모든 선분이 다른 Node와 하나라도 교차할 것이다.
이를 이용해 재귀적으로 Occlusion을 구현하였다.
// Occlusion되지 않으면 ChildrenCullFlag 활성화
void QueryOcclusion(
const std::shared_ptr<FOctreeNode<T>> Node,
const FVector& cameraPos
) const {
// Node가 Leaf면 무시
if ( Node->IsLeaf )
return;
// InOccludee가 나머지 7개의 BoundingBox에 가려지면 true.
auto IsOcclusions = [&cameraPos](
std::shared_ptr<FOctreeNode<T>> InNodes[],
int InOccludeeIdx
)->bool {
constexpr float occluderScale = 0.8f;
constexpr float occludeeScale = 1.2f;
const FBoundingBox scaled = InNodes[InOccludeeIdx]->Bounds.Expanded(occluderScale);
const FVector& max = scaled.max;
const FVector& min = scaled.min;
const FVector occludeePoints[8] = {
FVector(max.x, max.y, max.z),
FVector(min.x, max.y, max.z),
FVector(max.x, min.y, max.z),
FVector(min.x, min.y, max.z),
FVector(max.x, max.y, min.z),
FVector(min.x, max.y, min.z),
FVector(max.x, min.y, min.z),
FVector(min.x, min.y, min.z),
};
int intersectFlags = 0;
for ( int j = 0; j < 8; ++j ) {
if ( j == InOccludeeIdx )
continue;
FBoundingBox bb = InNodes[j]->Bounds.Expanded(occluderScale);
intersectFlags |= bb.IntersectLineMulti(occludeePoints, cameraPos);
}
return (intersectFlags == 0xff);
};
// Node 내에 카메라가 있으면 자식들 다 그려지는걸로 판정
const FVector& max = Node->Bounds.max;
const FVector& min = Node->Bounds.min;
bool bIsCameraConatined = false;
if ( min.x < cameraPos.x && cameraPos.x < max.x &&
min.y < cameraPos.y && cameraPos.y < max.y &&
min.z < cameraPos.z && cameraPos.z < max.z
) {
bIsCameraConatined = true;
}
for ( int i = 0; i < 8; ++i ) {
if ( Node->ChildrenCullFlags & 1 << i )
continue;
if ( bIsCameraConatined ) {
QueryOcclusion(Node->Children[i], cameraPos);
} else if ( IsOcclusions(Node->Children, i) == false ) {
QueryOcclusion(Node->Children[i], cameraPos);
} else {
Node->ChildrenCullFlags |= 1 << i;
}
}
}또한 BoundingBox::IntersectLineMulti(...)에 SIMD를 적용하여 Culling 속도를 조금 더 높였다. Bouding Box 정점이 8개이므로 8개 정점에 대해 한꺼번에 Intersect Text를 진행하는 방식이다.
int FBoundingBox::IntersectLineMulti(const FVector* p1, const FVector& p2) const {
__m256 tmin = _mm256_set1_ps(0.0f);
__m256 tmax = _mm256_set1_ps(1.0f);
__m256 epsilon = _mm256_set1_ps(1e-6);
__m256 minx = _mm256_set1_ps(min.x);
__m256 maxx = _mm256_set1_ps(max.x);
__m256 miny = _mm256_set1_ps(min.y);
__m256 maxy = _mm256_set1_ps(max.y);
__m256 minz = _mm256_set1_ps(min.z);
__m256 maxz = _mm256_set1_ps(max.z);
// 선분의 방향 벡터
__m256 _p1x = _mm256_set_ps(
p1[7].x, p1[6].x, p1[5].x, p1[4].x,
p1[3].x, p1[2].x, p1[1].x, p1[0].x
);
__m256 _p1y = _mm256_set_ps(
p1[7].y, p1[6].y, p1[5].y, p1[4].y,
p1[3].y, p1[2].y, p1[1].y, p1[0].y
);
__m256 _p1z = _mm256_set_ps(
p1[7].z, p1[6].z, p1[5].z, p1[4].z,
p1[3].z, p1[2].z, p1[1].z, p1[0].z
);
__m256 _p2x = _mm256_set1_ps(p2.x);
__m256 _p2y = _mm256_set1_ps(p2.y);
__m256 _p2z = _mm256_set1_ps(p2.z);
__m256 dirx = _mm256_sub_ps(_p2x, _p1x);
__m256 diry = _mm256_sub_ps(_p2y, _p1y);
__m256 dirz = _mm256_sub_ps(_p2z, _p1z);
// X축 처리
int resx1;
__m256 absDirX = _mm256_andnot_ps(_mm256_set1_ps(-0.0f), dirx);
__m256 maskX1 = _mm256_cmp_ps(absDirX, epsilon, _CMP_LT_OS);
__m256 maskX2 = _mm256_andnot_ps(maskX1, _mm256_set1_ps(-1.0f));
__m256 maskXOut = _mm256_or_ps(
_mm256_cmp_ps(_p1x, minx, _CMP_LT_OS),
_mm256_cmp_ps(_p1x, maxx, _CMP_GT_OS)
);
__m256 andres = _mm256_andnot_ps(_mm256_and_ps(maskX1, maskXOut), _mm256_set1_ps(-1.0f));
resx1 = _mm256_movemask_ps(andres);
if ( !resx1 )
return 0;
int resx2;
__m256 t1 = _mm256_div_ps(_mm256_sub_ps(minx, _p1x), dirx);
__m256 t2 = _mm256_div_ps(_mm256_sub_ps(maxx, _p1x), dirx);
__m256 t1min = _mm256_min_ps(t1, t2);
__m256 t1max = _mm256_max_ps(t1, t2);
tmin = _mm256_max_ps(tmin, t1min);
tmax = _mm256_min_ps(tmax, t1max);
__m256 maskRes = _mm256_cmp_ps(tmin, tmax, _CMP_GT_OS);
andres = _mm256_andnot_ps(_mm256_and_ps(maskX2, maskRes), _mm256_set1_ps(-1.0f));
resx2 = _mm256_movemask_ps(andres);
if ( !resx2 )
return 0;
int resx = resx1 & resx2;
// Y축 처리
int resy1;
__m256 absDirY = _mm256_andnot_ps(_mm256_set1_ps(-0.0f), diry);
__m256 maskY1 = _mm256_cmp_ps(absDirY, epsilon, _CMP_LT_OS);
__m256 maskY2 = _mm256_andnot_ps(maskY1, _mm256_set1_ps(-1.0f));
__m256 maskYOut = _mm256_or_ps(
_mm256_cmp_ps(_p1y, miny, _CMP_LT_OS),
_mm256_cmp_ps(_p1y, maxy, _CMP_GT_OS)
);
andres = _mm256_andnot_ps(_mm256_and_ps(maskY1, maskYOut), _mm256_set1_ps(-1.0f));
resy1 = _mm256_movemask_ps(andres);
if ( !resy1 )
return 0;
int resy2;
t1 = _mm256_div_ps(_mm256_sub_ps(miny, _p1y), diry);
t2 = _mm256_div_ps(_mm256_sub_ps(maxy, _p1y), diry);
t1min = _mm256_min_ps(t1, t2);
t1max = _mm256_max_ps(t1, t2);
tmin = _mm256_max_ps(tmin, t1min);
tmax = _mm256_min_ps(tmax, t1max);
maskRes = _mm256_cmp_ps(tmin, tmax, _CMP_GT_OS);
andres = _mm256_andnot_ps(_mm256_and_ps(maskY2, maskRes), _mm256_set1_ps(-1.0f));
resy2 = _mm256_movemask_ps(andres);
if ( !resy2 )
return 0;
int resy = resy1 & resy2;
// Z축 처리
int resz1;
__m256 absDirZ = _mm256_andnot_ps(_mm256_set1_ps(-0.0f), dirz);
__m256 maskZ1 = _mm256_cmp_ps(absDirZ, epsilon, _CMP_LT_OS);
__m256 maskZ2 = _mm256_andnot_ps(maskZ1, _mm256_set1_ps(-1.0f));
__m256 maskZOut = _mm256_or_ps(
_mm256_cmp_ps(_p1z, minz, _CMP_LT_OS),
_mm256_cmp_ps(_p1z, maxz, _CMP_GT_OS)
);
andres = _mm256_andnot_ps(_mm256_and_ps(maskZ1, maskZOut), _mm256_set1_ps(-1.0f));
resz1 = _mm256_movemask_ps(andres);
if ( !resz1 )
return 0;
int resz2;
t1 = _mm256_div_ps(_mm256_sub_ps(minz, _p1z), dirz);
t2 = _mm256_div_ps(_mm256_sub_ps(maxz, _p1z), dirz);
t1min = _mm256_min_ps(t1, t2);
t1max = _mm256_max_ps(t1, t2);
tmin = _mm256_max_ps(tmin, t1min);
tmax = _mm256_min_ps(tmax, t1max);
maskRes = _mm256_cmp_ps(tmin, tmax, _CMP_GT_OS);
andres = _mm256_andnot_ps(_mm256_and_ps(maskZ2, maskRes), _mm256_set1_ps(-1.0f));
resz2 = _mm256_movemask_ps(andres);
if ( !resz2 )
return 0;
int resz = resz1 & resz2;
// tmin과 tmax가 선분 범위 [0,1] 내에 있는지 확인
//return (tmin <= 1.0f && tmax >= 0.0f);
maskRes = _mm256_and_ps(
_mm256_cmp_ps(tmin, _mm256_set1_ps(1.0f), _CMP_LE_OS),
_mm256_cmp_ps(tmax, _mm256_set1_ps(0.0f), _CMP_GE_OS)
);
int res = _mm256_movemask_ps(maskRes);
return resx & resy & resz & res;
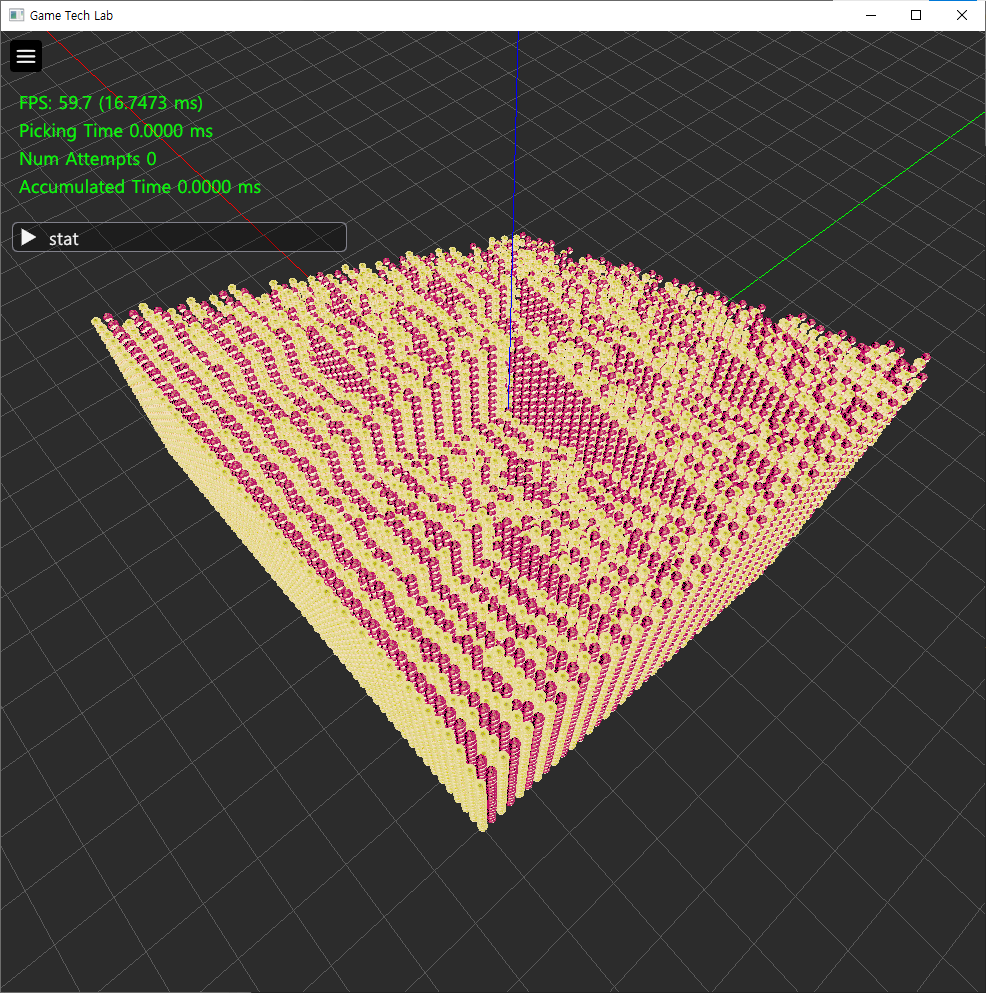
}Culling된 모습은 다음과 같다. 실제 시야의 반대쪽에서 바라본 모습이다.
렌더링 최적화
무조건 Batching 하기?
기존에 진행한 Batching 방식은 매 프레임마다 Vertex Buffer를 생성하고, Culling되지 않은 모든 버텍스를 복사하여 Render하는 방식이었다.
한 번에 그린다는 점에서 Batching은 맞지만, 수십만~수백만 단위의 버텍스를 매 프레임 복사하기엔 부담이 너무 컸다. 실제로 매 프레임마다 계산하기엔 진행이 불가능할 정도라 5초 간격으로 늘리고 테스트를 하곤 했었다.
기존 구조를 가져가며, 버텍스 복사에 드는 비용을 최대한 줄여보려고 했으나 절대적인 숫자 크기의 한계를 체감했다. memcpy를 해봐도, 참조 연산을 해볼려 해도, 결국 복사를 해야 했다.
때문에 렌더 구조를 변경할 필요성을 느꼈다.
Greedy Batching
새 방식은 처음 Vertex Buffer에 모든 버텍스를 삽입하고 이를 계속 사용한다. 대신 DrawIndexed의 Index를 잘 조절하여 Culling된 오브젝트만 제외시켜 그리는 방식이다.
단 처음 생성된 vertex buffer와 index buffer의 순서가 계속 유지되어야 한다. 오브젝트가 index offset을 가져 그것을 사용하는 방식도 있겠지만 순회를 위해서는 index buffer 순서를 유지시키는 게 낫다고 생각된다.
// Render
for ( auto& [MaterialName, BatchRenderTargetContext] : BatchRenderTargets )
{
uint32 LODIdx = 0;
uint32 bufferIdx = 0;
uint32 offset = 0;
uint32 length = 0;
// Set Material
UMaterial* Material = FManagerOBJ::GetMaterial(MaterialName);
const auto& MaterialInfo = Material->GetMaterialInfo();
if ( MaterialInfo.bHasTexture == true ) {
std::shared_ptr<FTexture> texture = FEngineLoop::resourceMgr.GetTexture(MaterialInfo.DiffuseTexturePath);
SetPSTextureSRV(0, 1, texture->TextureSRV);
SetPSSamplerState(0, 1, texture->SamplerState);
} else {
SetPSTextureSRV(0, 1, nullptr);
SetPSSamplerState(0, 1, nullptr);
}
// Set Buffers
Graphics->DeviceContext->IASetVertexBuffers(0, 1, &BakedLODBuffers[MaterialName][LODIdx].VertexBuffer[bufferIdx], &stride, &vertexOffset);
Graphics->DeviceContext->IASetIndexBuffer(BakedLODBuffers[MaterialName][LODIdx].IndexBuffer[bufferIdx], DXGI_FORMAT_R32_UINT, 0);
auto& Meshes = BatchRenderTargetContext.StaticMeshes;
// 머터리얼 별로 나뉜 인스턴스 묶음을 순회
for ( int i = 0; i < Meshes.Num(); ++i )
{
const UStaticMeshComponent* pStaticMeshComp = Meshes[i].Value;
const auto& renderDatas = pStaticMeshComp->GetStaticMesh()->GetLODDatas();
const uint32 lodLevel = pStaticMeshComp->GetLODLevel();
const uint32 indicesCount = renderDatas[lodLevel]->Indices.Num();
// 만약 mesh가 culling되었다면
if (!pStaticMeshComp->bIsVisible)
{
// 만약 누적된 lenght가 있어 그릴 게 있다면
if (length > 0) {
// 지금까지의 것을 그리고
Graphics->DeviceContext->DrawIndexed(length, offset, 0);
}
// 현재 것을 건너뛴다.
offset += length + indicesCount;
length = 0;
}
// 만약 mesh가 culling되지 않았다면
else
{
// 지금 것을 length에 누적시킨다.
length += indicesCount;
}
// if end of array
if (offset + length >= BakedLODBuffers[MaterialName][lodLevel].IndexCount[bufferIdx])
{
if ( length > 0 )
Graphics->DeviceContext->DrawIndexed(length, offset, 0);
offset = 0;
length = 0;
++bufferIdx;
if ( BakedLODBuffers[MaterialName][lodLevel].VertexBuffer.Num() > bufferIdx )
{
Graphics->DeviceContext->IASetVertexBuffers(0, 1, &BakedLODBuffers[MaterialName][lodLevel].VertexBuffer[bufferIdx], &stride, &vertexOffset);
Graphics->DeviceContext->IASetIndexBuffer(BakedLODBuffers[MaterialName][lodLevel].IndexBuffer[bufferIdx], DXGI_FORMAT_R32_UINT, 0);
}
}
}
}Octree Traversal 정렬
또한 기존에는 오브젝트가 무작위 순서로 되어 있었는데, 이를 Octree Traversal 순서로 정렬하여 vertex buffer, index buffer에 삽입하였다.
Octree 특성상 순회 순서에 지역성을 가져 Frustum이나 Occlusion에서 효과적이었고 대략 10fps 이상의 이득을 보았다.
TroubleShooting
SIMD Endian 문제
SSE, AVX 등 Intel 기반 SIMD는 리틀 엔디안으로 작동한다. 때문에 인자를 거꾸로 넣어줘야 하며, 또는 _mm_setr_ps 등의 reverse 함수를 사용해야 한다.

brights2ella님의 멋진 도전을 응원합니다! 포스팅 잘보고가요~