테스트를 위한 파드 배포
192.168.56.30:30000 쿠버네티스 접속 후 + 버튼으로 테스트 APP 생성
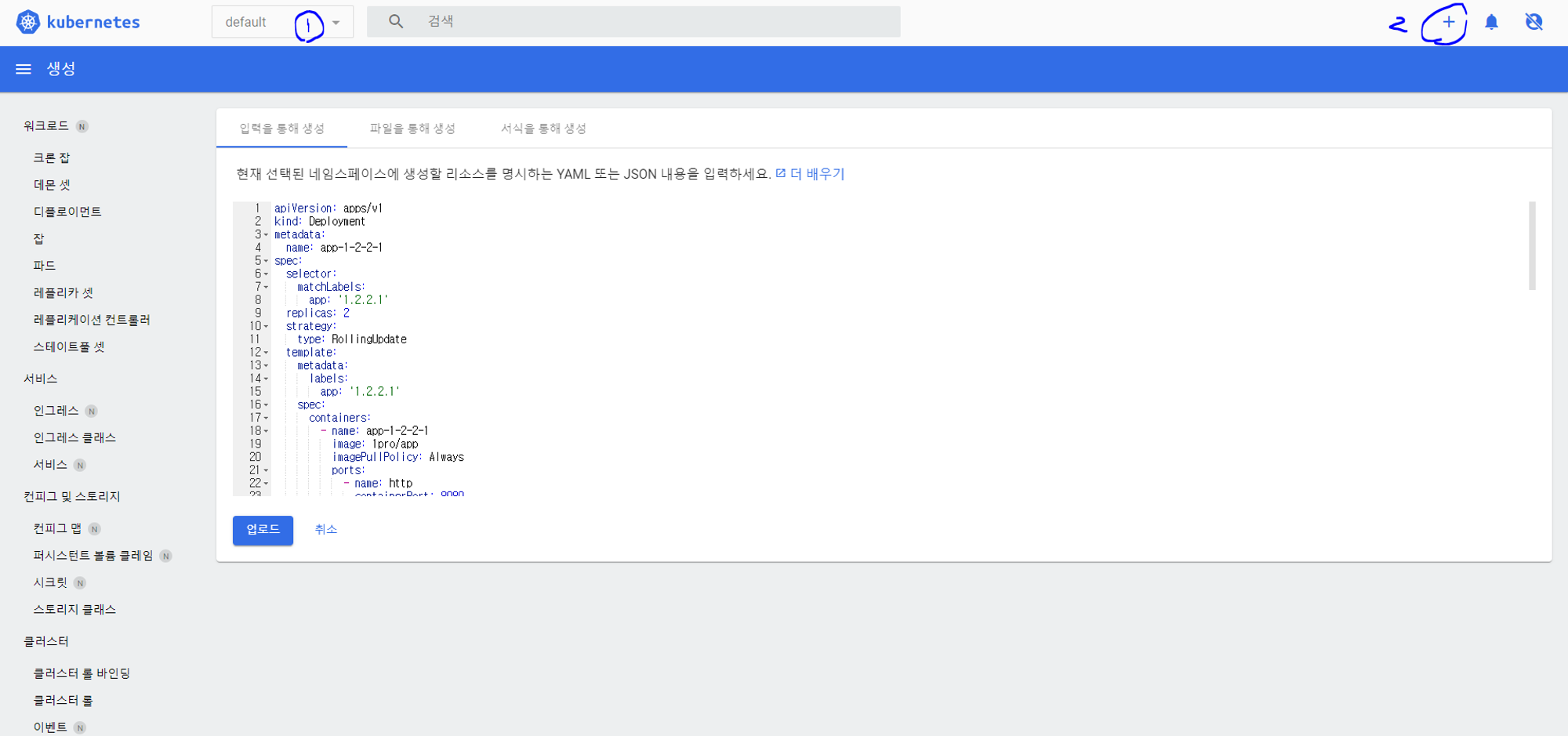
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-1-2-2-1
spec:
selector:
matchLabels:
app: '1.2.2.1'
replicas: 2
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: '1.2.2.1'
spec:
containers:
- name: app-1-2-2-1
image: 1pro/app
imagePullPolicy: Always
ports:
- name: http
containerPort: 8080
startupProbe:
httpGet:
path: "/ready"
port: http
failureThreshold: 10
livenessProbe:
httpGet:
path: "/ready"
port: http
readinessProbe:
httpGet:
path: "/ready"
port: http
resources:
requests:
memory: "100Mi"
cpu: "100m"
limits:
memory: "200Mi"
cpu: "200m"
---
apiVersion: v1
kind: Service
metadata:
name: app-1-2-2-1
spec:
selector:
app: '1.2.2.1'
ports:
- port: 8080
targetPort: 8080
nodePort: 31221
type: NodePort
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: app-1-2-2-1
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: app-1-2-2-1
# 2개에서 4개까지 cpu 평균 40%넘어아 as
minReplicas: 2
maxReplicas: 4
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 40app에 트래픽 보내기 & 부하
Traffic Routing 테스트
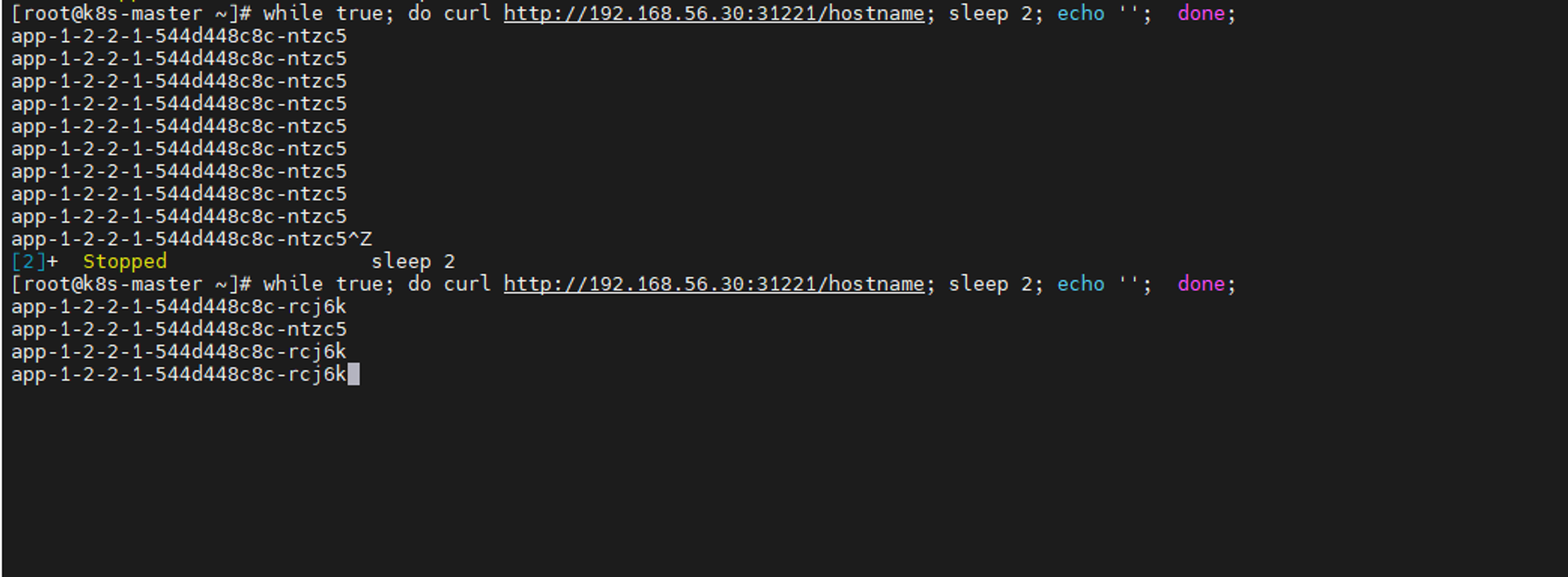
트래식 분산 확인을 위해 터미널에 들어가서
while true; do curl http://192.168.56.30:31221/hostname; sleep 2; echo ''; done;
명령어를 통해 2초 간격으로 호출받은 파드 출력
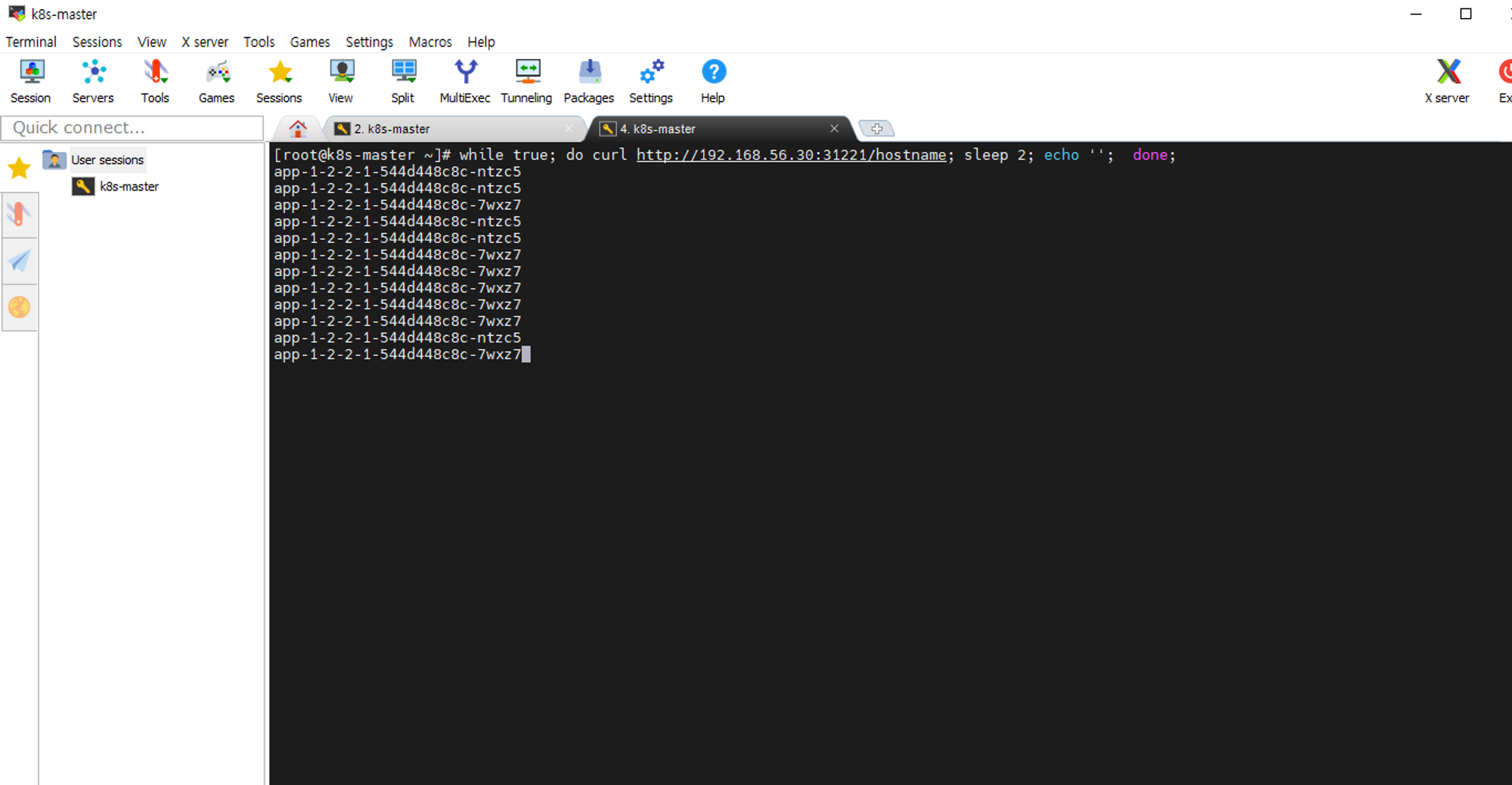
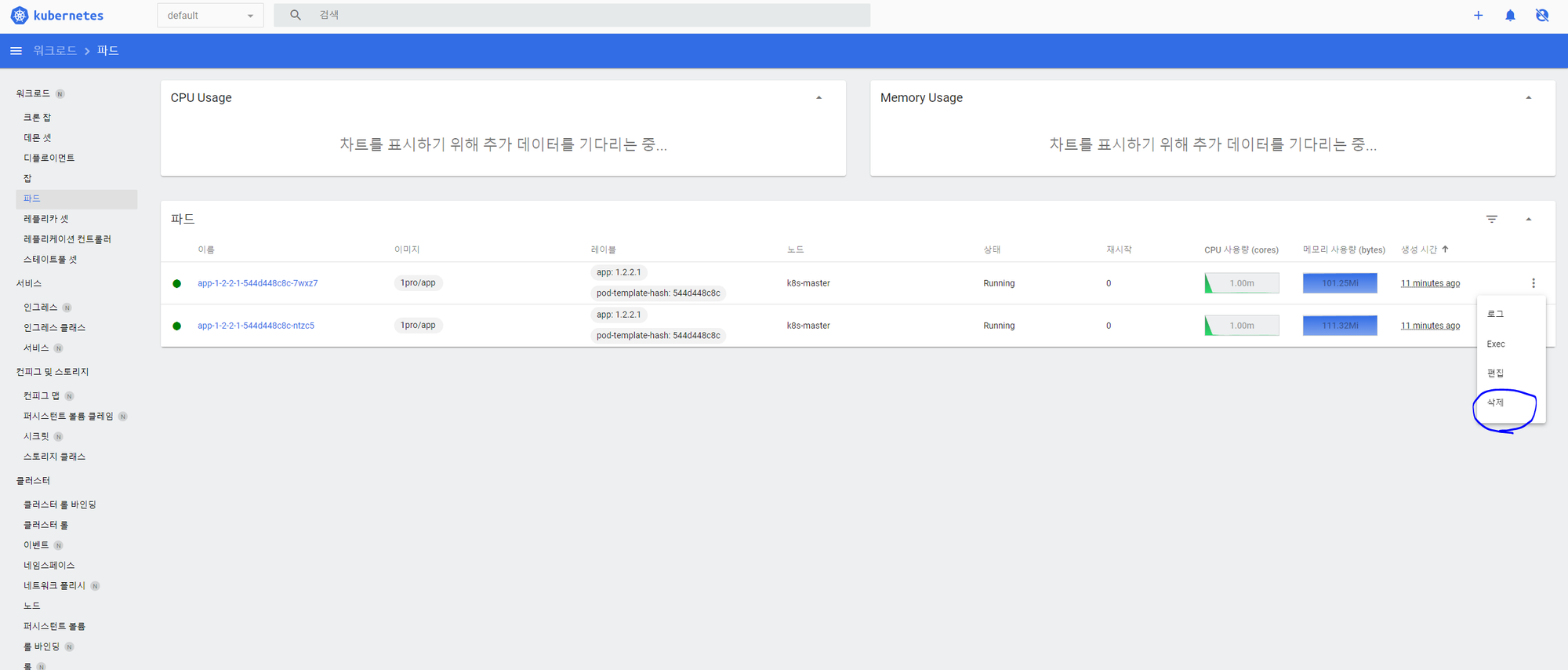

파드를 삭제 하면 파드가 다시 자동적으로 생성되고 생성되면 트래픽도 다시 나눠서 들어가게 된다.
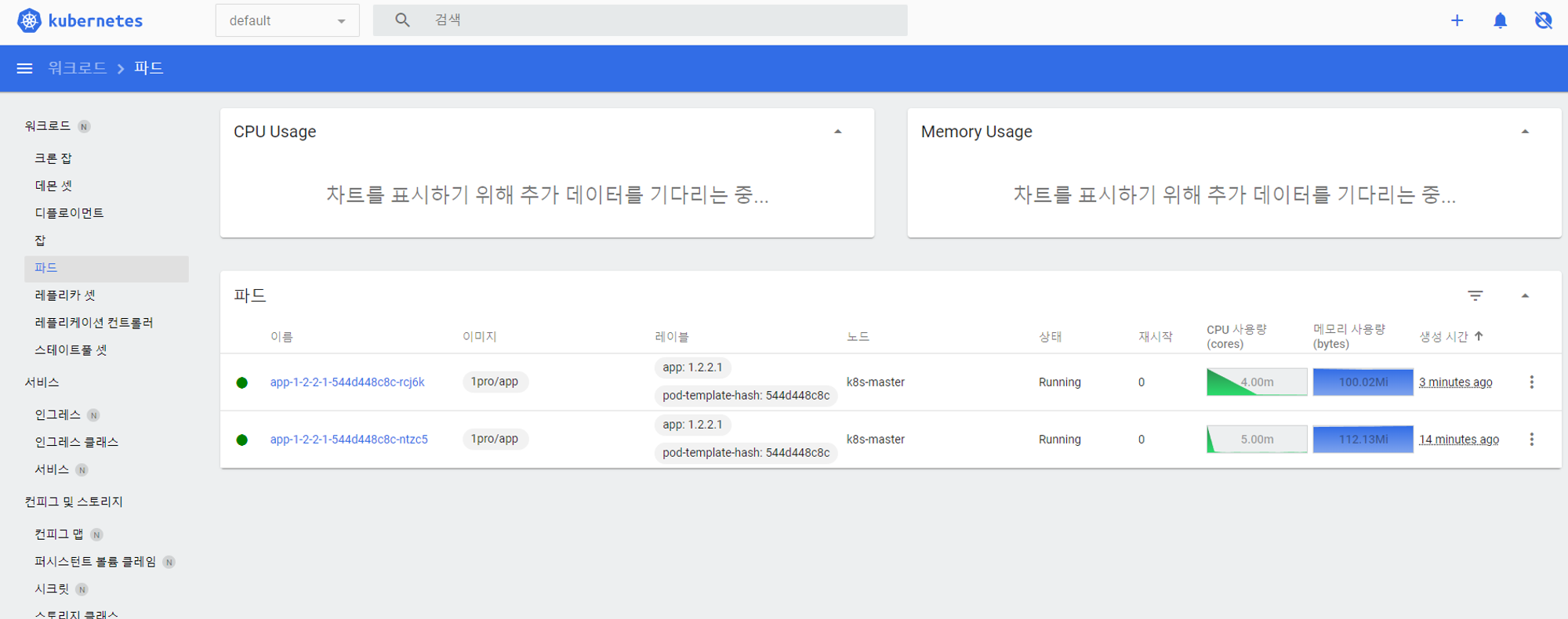
Self-Healing or AutoScaling 테스트
명령어를 통해 Memory Leak을 발생 (Self-Healing)
curl 192.168.56.30:31221/memory-leak
명령어를 통해 cpu과부하 (AutoScaling)
curl 192.168.56.30:31221/cpu-load
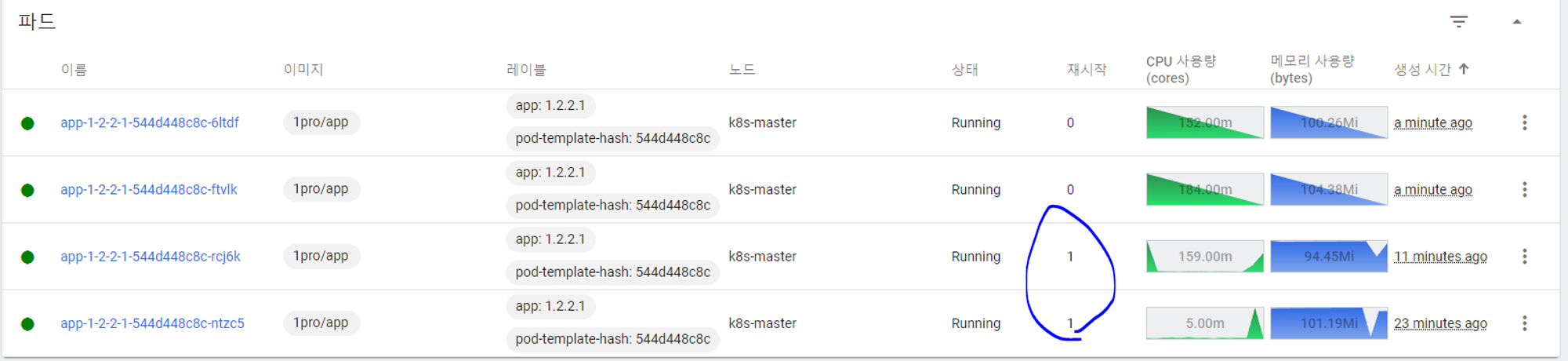
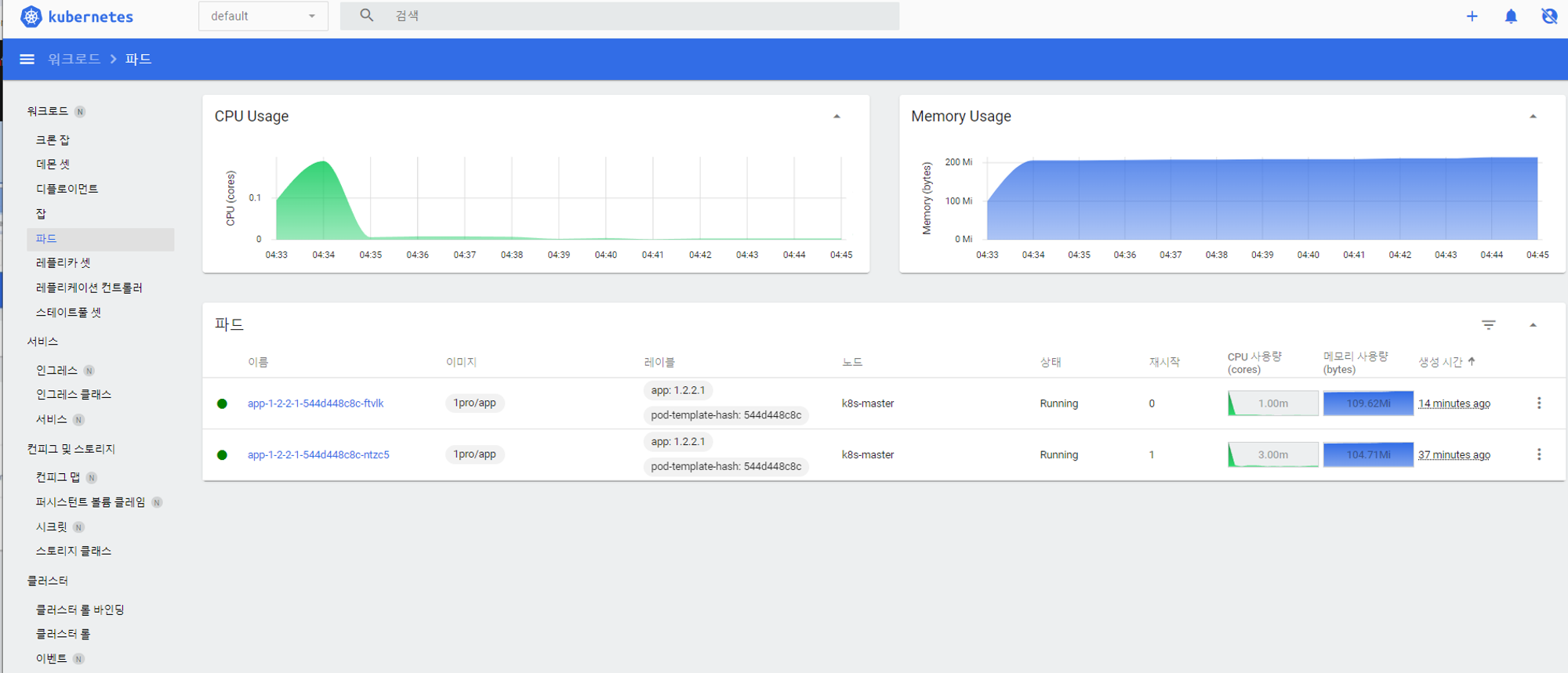
재시작이 1로 바뀌는데 쿠버네티스가 파드의 갯수를 늘림
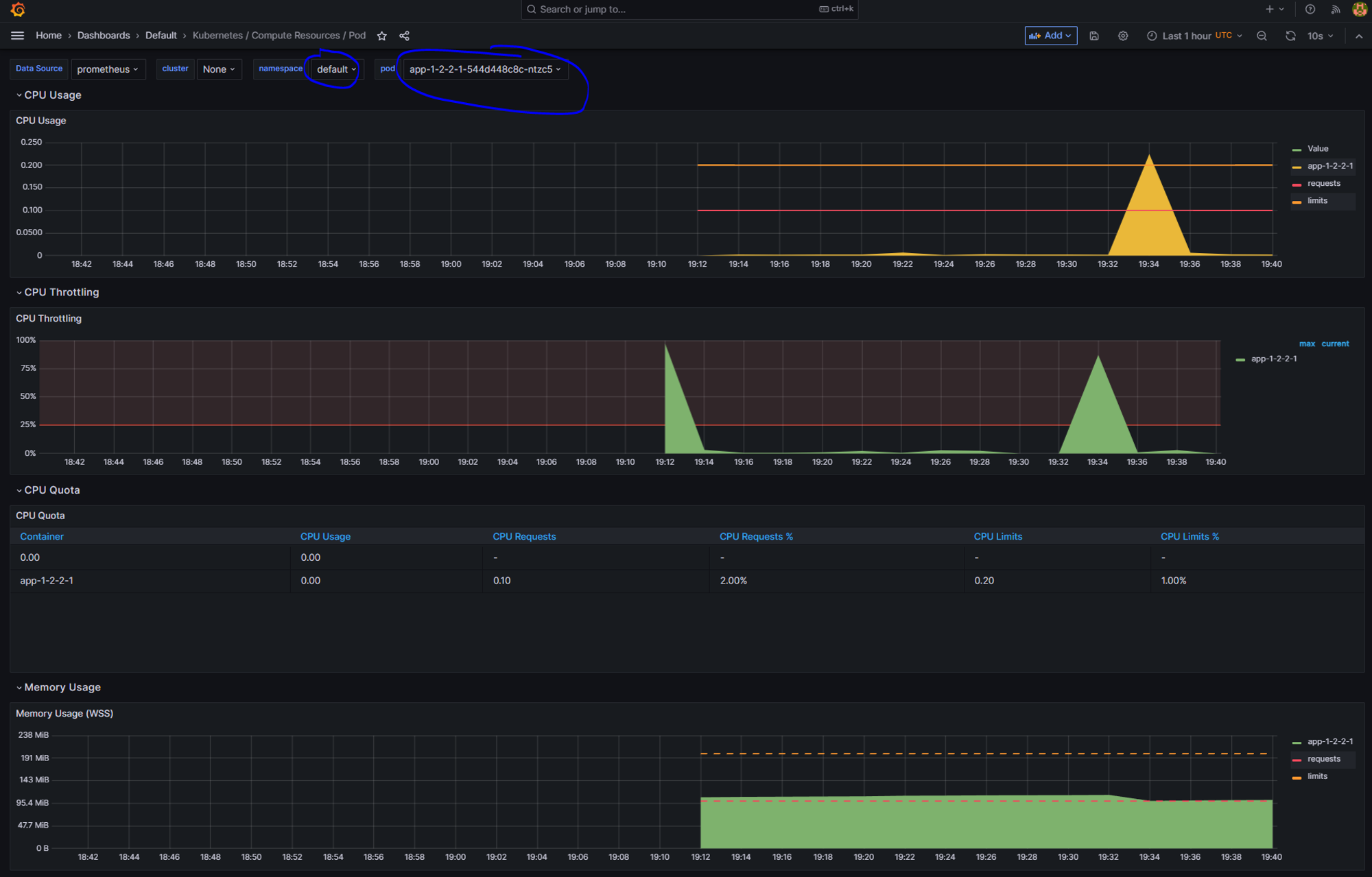
그라파나에서 파드에 들어가 상태에 이상이 있는 구간을 확인하고 이 시간대를 확인해 로키로 로그를 확인
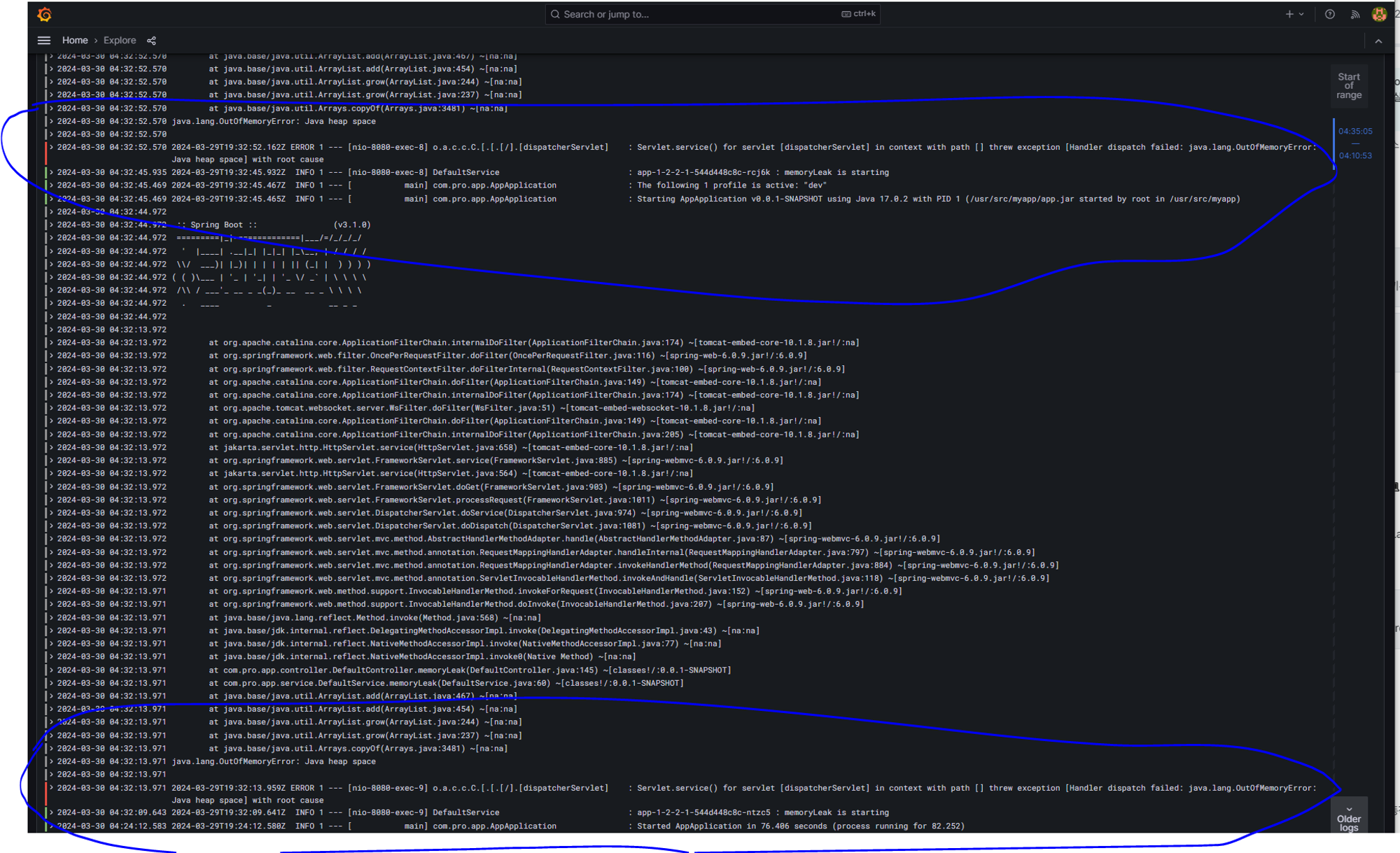
로그를 통해 에러를 확인 할 수 있다.
잠시 후 시간이 지나고 cpu 사용량이 낮아지면 다시 파드의 갯수를 줄인다.
APP 업데이트
Rolling Update 테스트
오류가 없는 app 업데이트
명령어를 통해 app을 업데이트한다
kubectl set image -n default deployment/app-1-2-2-1 app-1-2-2-1=1pro/app-update
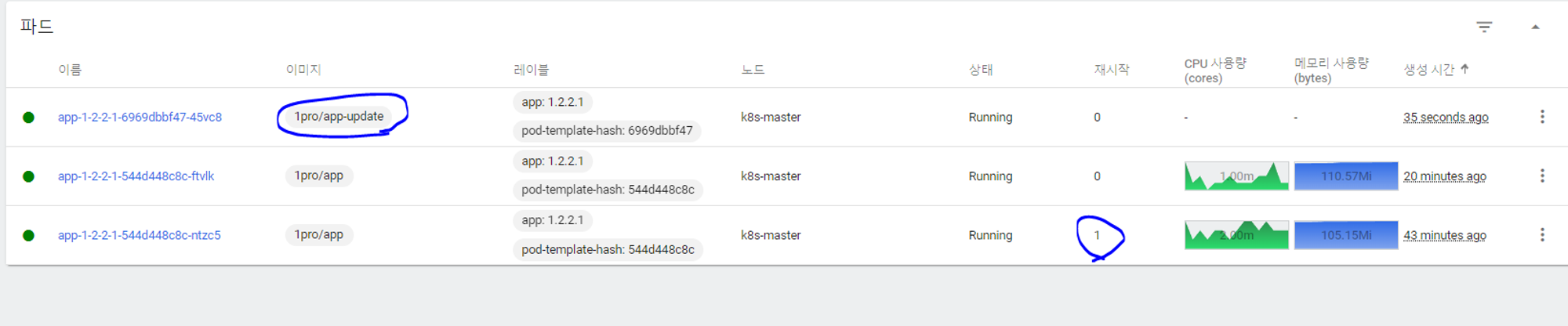
업데이트 동안 트래픽은 기존v1으로 연결되어 끊기지 않고 v2가 업데이트되면 트래픽은 v2로 가게되고 v1은 종료된다.

오류가 있는 app 업데이트
명령어를 통해 정상작동이 되지 않는 app 업데이트
kubectl set image -n default deployment/app-1-2-2-1 app-1-2-2-1=1pro/app-error

파드가 생성이 되지만 기동이 되지 않아 쿠버네티스가 계속 재시작을 하고


kubectl rollout undo -n default deployment/app-1-2-2-1
명령어를 통해 업데이트를 롤백한다.