- quantization in neural networks, specifically focusing on quantization for inference.
- The paper discusses various aspects of quantization, including its benefits and challenges, different quantization methods, and techniques for optimizing quantization for neural network inference.
What is Quantization?
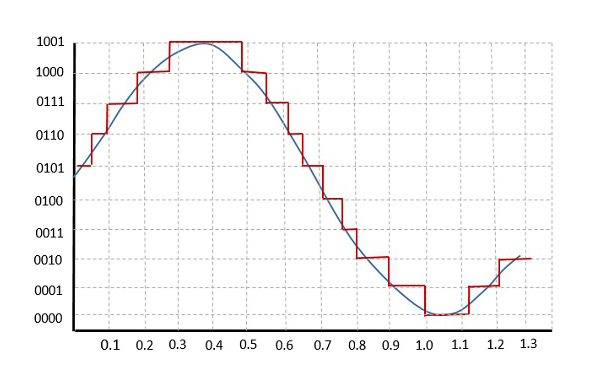
Why is Quantization important?
Quantization reduces the precision of numerical values used in neural network computations, which can significantly reduce the memory and computational requirements of the model without sacrificing too much accuracy.
Quantization
- Symmetric and Asymmetric Quantization
Symmetric quantization partitions the clipping using a symmetric range, which has the advantage of easier implementation but is sub-optimal for cases where the range could be skewed and not symmetric.
Asymmetric quantization, on the other hand, is preferred for such cases because it partitions the clipping using an asymmetric range.
- Dynamic vs Static Quantization
Dynamic quantization involves quantizing the weights and activations of a neural network during inference, while static quantization involves quantizing the weights and activations of a neural network during training.
- advantages and disadvantages of each method (which is more appropriate?)
Quantization Methods
-
Fixed-point quantization: This method represents numerical values using a fixed number of bits, which can reduce memory and computational requirements but may result in some loss of accuracy.
-
Dynamic quantization: This method adjusts the number of bits used to represent numerical values based on the range of values encountered during inference, which can improve accuracy while still reducing memory and computational requirements.
-
Hybrid quantization: This method combines fixed-point and dynamic quantization to achieve a balance between accuracy and efficiency.
-
Logarithmic quantization: This method uses a logarithmic scale to represent numerical values, which can improve accuracy for values that are close to zero.
-
Vector quantization: This method groups weights into clusters and uses the centroid of each cluster as a quantized value during inference, which can reduce memory requirements and improve accuracy.
-
Product quantization: This method divides the weight matrix into smaller sub-matrices and quantizes each sub-matrix separately, which can reduce memory requirements and improve accuracy.
-
Binarization: This method represents numerical values using only binary values (i.e., 0 or 1), which can significantly reduce memory and computational requirements but may result in a significant loss of accuracy.
-
Ternarization: This method represents numerical values using only three values (-1, 0, or 1), which can reduce memory and computational requirements while still maintaining some accuracy.
-
Quantization-aware training: This method trains the neural network model with quantization in mind, which can improve the accuracy of the quantized model.
-
Post-training quantization: This method applies quantization to a pre-trained neural network model, which can reduce memory and computational requirements while still maintaining some accuracy.
Quantization 실행 과정
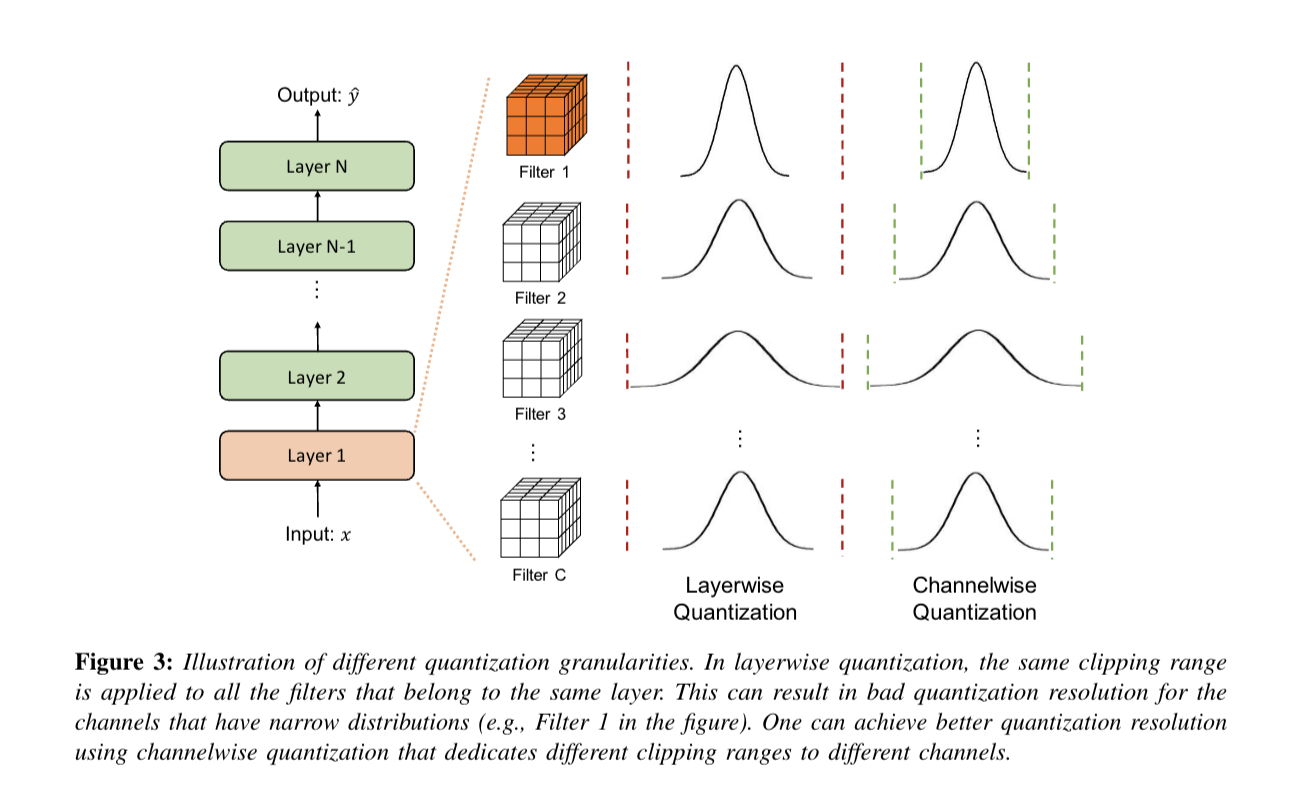
Quantization
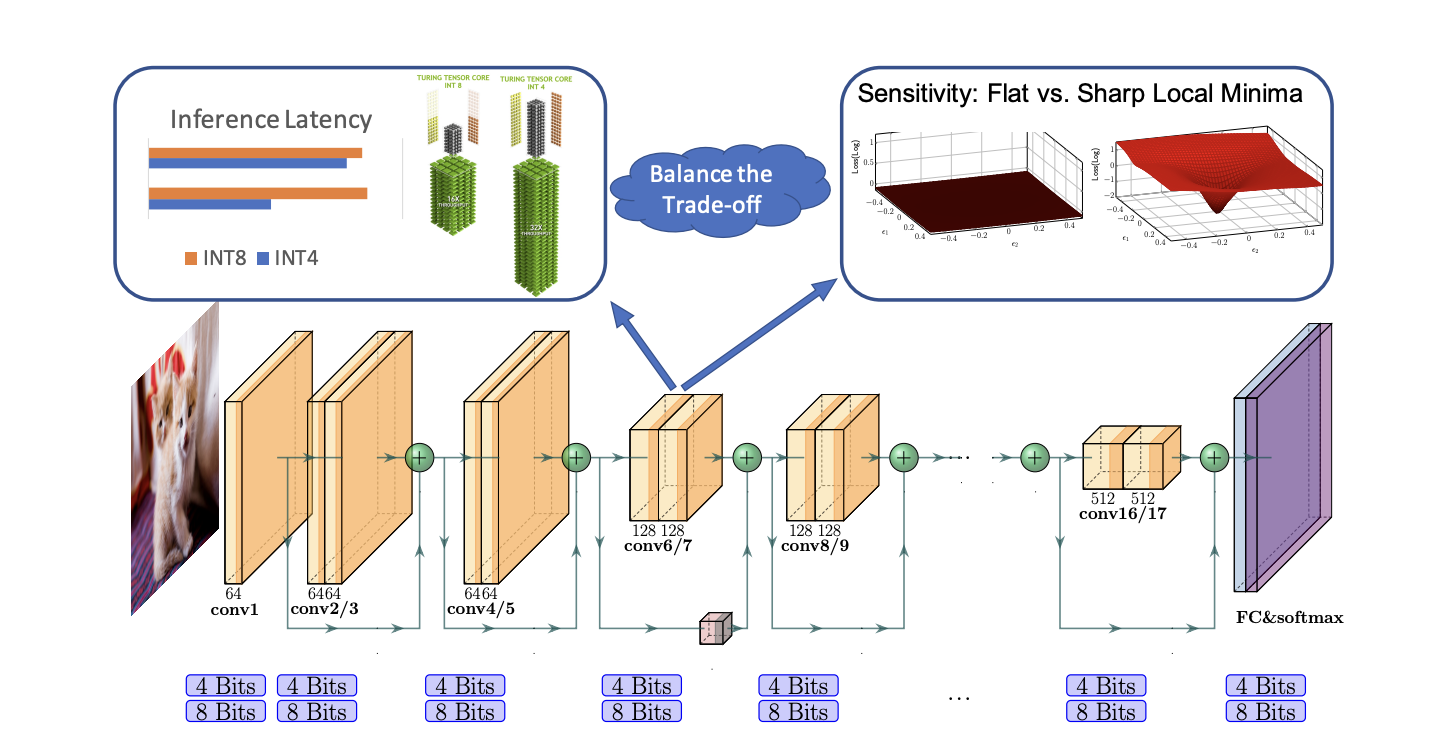
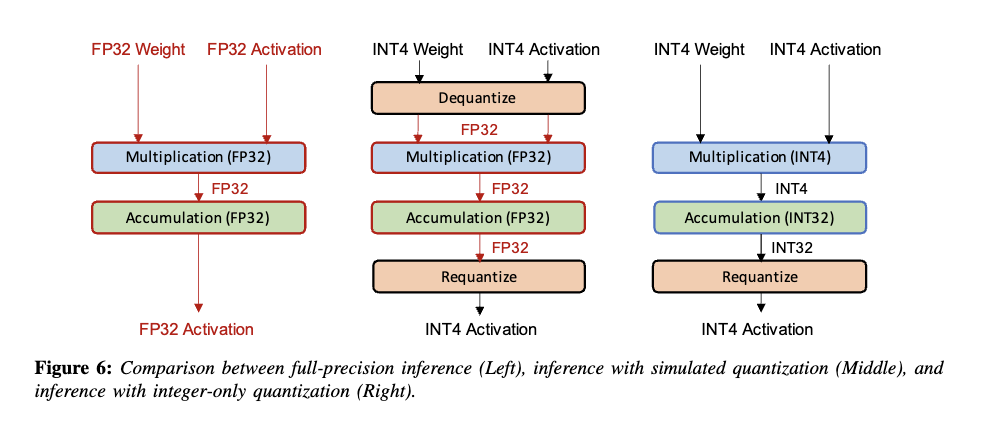
결과
1. the Throughput of various Power for different commercial edge processors for NN inference at the edge.
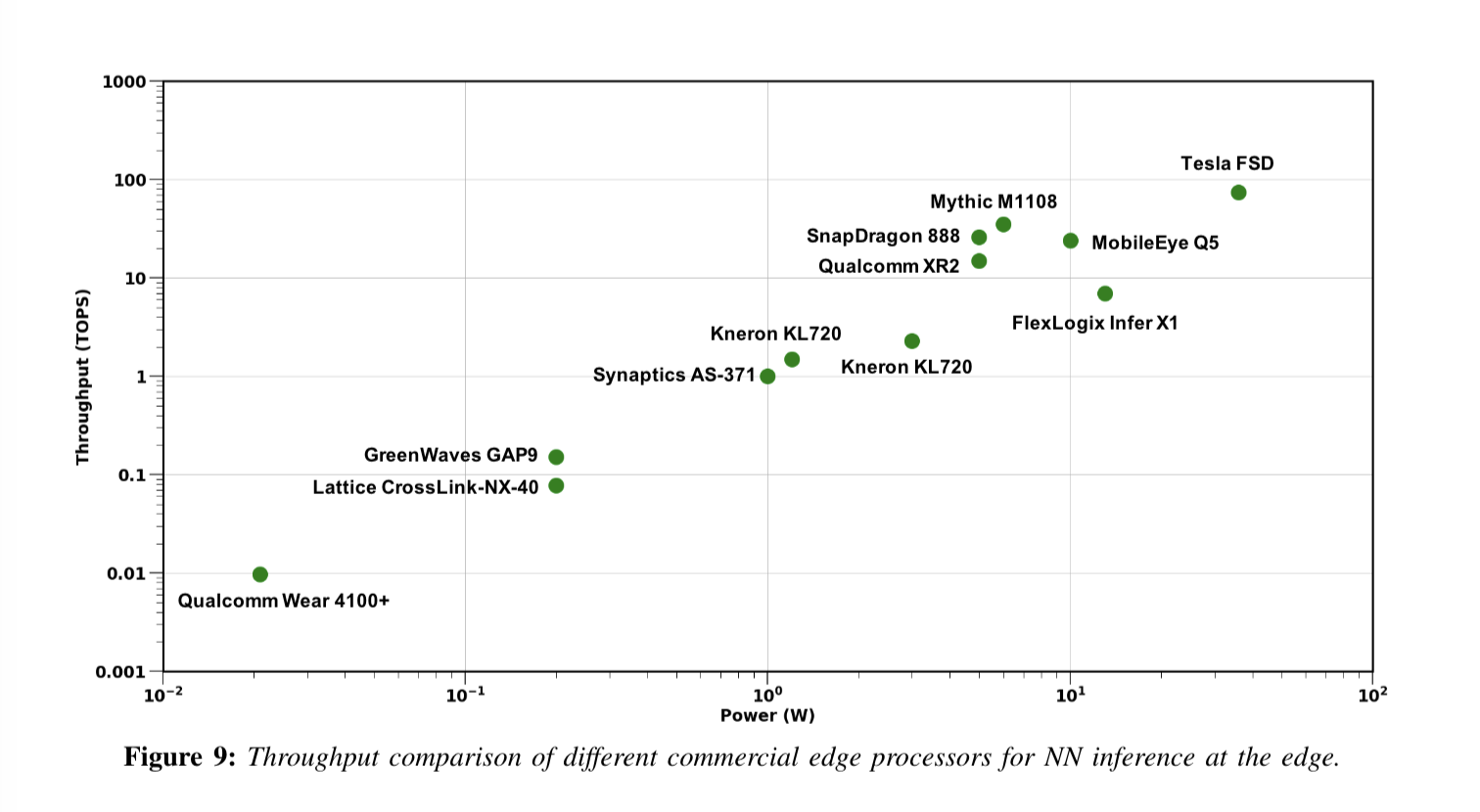
2. from Qualcomm Wear 4100+ to Tesla FSD


2개의 댓글
Reytech Infoways is the epitome of excellence in web development. Their team's skillful execution and attention to detail transformed our online presence. Highly recommend Reytech for top-notch, tailored solutions!
https://www.reytechinfoways.com/
If you want to take the Walgreenslistens.com survey, visit the official website at https://www.walgreensreceiptsurvey.co/ and enter the survey code on your receipt. Then, answer the survey questions based on your experience at Walgreens. It's a quick and easy way to provide feedback and enter a chance to win a $3,000 money reward.