Team : 송해인, 양*령
1.Problem Description
1-1. Background
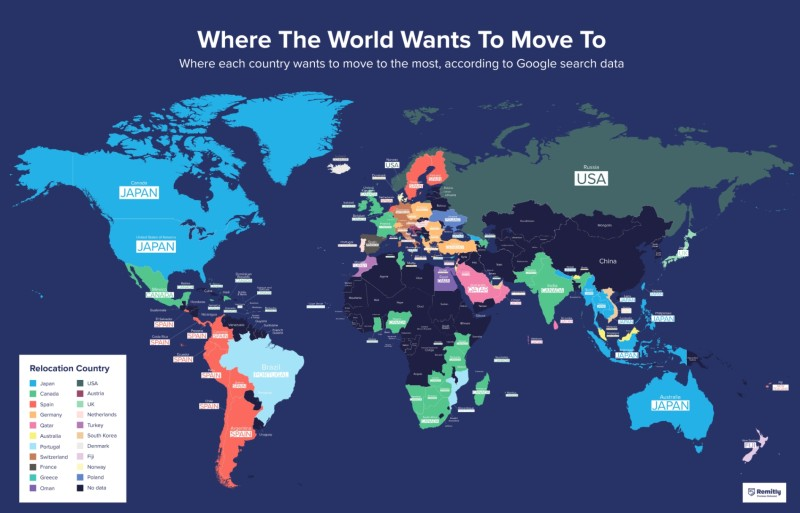
글로벌화로 인해 거주지의 선택이 자유로워진 현대 사회에서 이민은 전보다 익숙한 개념으로 받아들여지고 있다. 사람들은 전통적인 경제적 이유 이외에도 사회적 불안 해소, 노후 보장, 자녀교육 등 다양한 이유로 해외 이민을 고려한다. 2023년 현재, 전세계 재외동포 수는 약 732만명으로 추정되며(외교부, 2021), 코로나 이전 연간 해외 이주 신고자는 약 5000명에 달한다(외교부,2018-2019).
1-2. Problem Definition
외국에서 실제로 거주하는 경험은 시간적, 경제적 소모가 크기 때문에 이민을 결정하기 전 직접경험을 하는 사람은 드물다. 또한 제한 사항과 고려 대상이 다양하기 때문에 정보의 규모가 방대하고, 개인이 직접 계획하는 것은 비효율적이다.따라서, 사용자에게 개인의 성향과 상황, 선호사항 등의 정보를 제공받아 사용자 본인에게 최적화된 이민 국가를 추천해주는 시스템을 개발하고자 한다
1-3. Required Datasets
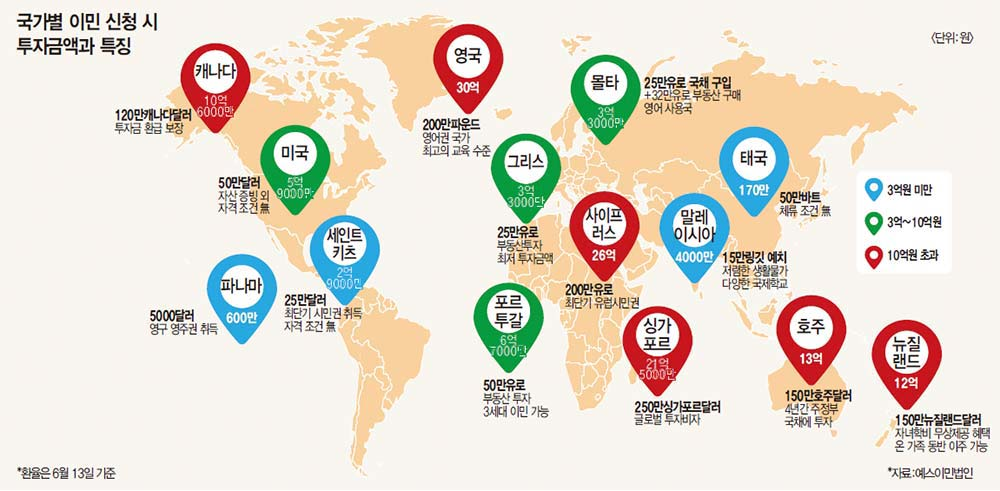
국가(도시) 별 정보 항목
- 이민 조건
- 영주권 획득 조건: 체류기간, 배우자의 국적, 고용, 특별 공로, 고액투자 여부, 연령 등
- 이민 만족도, 거주 지속률, 영주권 획득률, 영주권 획득 실 소요기간, 이민자 커뮤니티, 인종차별 경험 여부, 정착 비용 등
- 인구 및 문화
- 인구: 인구 수, 인구 밀도, 연령 분포, 성별, 유소년 · 노년 비율, 이민자 비율, 행복지수 등
- 문화: 종교, 언어, 주류 스포츠 등
- 생활 환경
- 환경: 기온, 강수량, 한국과의 거리, 미세먼지, 녹지비율 등
- 생활: 이민자 의료보험 여부, 의료 접근성, 의료비, 치안, 범죄 유형, 주거 형태, 교육수준, 교통, 문화시설 접근성 등
-
경제적 요인
환율, GDP, 경제 성장률, 직업유형, 직군 별 연봉, 외국인 고용률, 부동산 정보 등 -
기타
군사, 정치 등
2. Algorithm Description
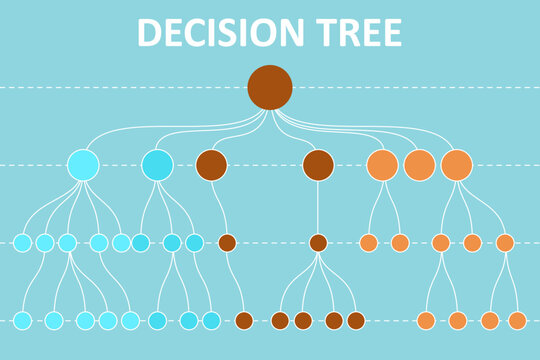
2-1. Decision Tree Algorithm
이 문제를 해결하기 위해 Decision Tree 알고리즘을 선택한다. Decision Tree 알고리즘은 특징들의 조합을 통해 국가를 분류하는 데 유용하며, 각 국가의 중요 특징을 명확하게 표현하는데 탁월하기 때문이다.
2-2. Decision Tree to Solve Problem
이민 국가를 추천하는 추천 시스템과 같은 기계 학습 알고리즘을 사용하여 사용자에게 개인화된 추천을 할 수 있다. 국가에 대한 정보와 사용자의 개인 특성이 포함된 데이터 세트에서 알고리즘을 훈련해야 한다. Decision Tree를 사용하면 사용자의 선호도와 다른 이민 국가의 특성을 통해 추천을 생성할 수 있다.
2-3. Decision Tree Implementation
구체적인 Decision Tree 알고리즘으로는 sklearn의 DecisionTreeClassifier를 사용한다. 여러 특징들을 이용하여 이민 국가를 분류하는 모델을 학습할 예정이며, 특성 중요도를 사용자에게 투명하게 보여줄 수 있다.
이때 과적합을 방지하기 위해 가지치기(pruning) 기법을 사용한다. 특히, 최소 노드 크기(min_samples_leaf) 및 최대 깊이(max_depth)와 같은 매개변수를 조절하며, 검증 세트에서의 성능을 모니터링하여 최적의 하이퍼파라미터를 선택한다.
3. Why Decision Tree is a Good Fit?
3-1. Advantages of Decision Tree and How to Use them
Decision Tree 알고리즘은 다양한 특징을 고려하여 사용자에게 개인화된 추천을 할 수 있다. 이전 추천에 대한 사용자의 선호도 및 피드백에 따라 권장 사항을 조정하고 개선할 수 있다. Decision Tree는 각 특징의 중요성을 명확하게 보여주는 방식으로 작동한다. 이로 인해 사용자는 자신이 선호하는 특징에 따라 이민 국가를 선택하는 데 도움을 받을 수 있다.
3-2. Performance Evaluation and Improvement
모델의 성능은 교차 검증(cross-validation)을 통해 평가한다. 이를 통해 모델이 새로운 데이터에 대해 얼마나 잘 일반화하는지 평가할 수 있다. 성능 지표로는 정확도(accuracy)를 사용하되, 특히 분류 문제에서 불균형 클래스 문제가 있을 수 있으므로, 정밀도(precision), 재현율(recall), F1 스코어 등의 지표도 함께 고려한다.
추가로, 모델의 성능을 향상시키기 위해 특성 엔지니어링(feature engineering) 작업을 수행한다. 이는 원본 데이터에서 새로운 유익한 특성을 도출해내는 과정으로, 모델의 성능 향상에 크게 기여할 수 있다.

4.Expected Result
이 프로젝트의 결과로, 최적의 이주 조건을 가진 국가를 사용자에게 알려줄 수 있다. Decision Tree 알고리즘의 해석 가능성 덕분에 사용자는 본인이 중요하게 생각하는 요소가 이민 국가 선택에 어떤 영향을 끼치는지 이해하게 된다. 그래서 이 알고리즘이 사용자에게 어떤 요소가 이민 국가 선정에 중요한지에 대한 인사이트를 제공하는 것이 중요하다.
개인화된 추천 시스템을 통해 다양한 잠재적 사용자들이 이용할 수 있다:
- 이민을 준비하며, 이민 국가에 대한 조언을 얻고 싶어하는 사람
- 경제적 목적으로 워킹 홀리데이를 가고자 하는 사람
- 관광을 목적으로 장기 여행을 준비하는 사람
- 단순한 호기심으로 본인과 잘 어울리는 국가를 알고 싶어하는 사람
또한 일반적이고 모호한 선호를 가지더라도 본인이 중요하게 생각하는 요소에 따라 개인화된 추천을 받게 된다. 결정 트리 분석을 통해 본인이 제공한 정보를 기반으로 해당 국가의 어떤 요소가 이민 시 장점으로 작용하는지를 손쉽게 알 수 있다.
