1. 딥러닝의 개념
- 학습을 통해 연결의 강도(가중치, Weight)를 조정
- 여러 층(layer)으로 구성된 신경망
- 인공 신경망(Artificial Neural Net)
- 신경망을 인공적으로 구현한 것
- 신경망의 깊이(Deep) 쌓아서 학습시키는 방식 -> Deep Learning
- 딥러닝을 활용하여 여러 머신러닝 알고리즘 생성
- 이미지 모델링, 언어 모델링 등 다양한 곳에서 사용
1-1. 가중치
- 값의 중요도
- 어떤 특징이 더 중요한가
- ex) 개와 고양이를 서로 구별할 때 귀 모양에 따라 분류 가능 -> 귀의 가중치가 증가
- 최적의 가중치 -> 오차가 제일 작은 모델의 가중치
- 딥러닝에서 학습이란, '오차를 최소화하는 가중치(parameter)'를 찾는 것
: 가중치
1-2. 가중치 학습 과정
- 가중치 초기값 할당(랜덤으로 초기값 지정)
- 예측 결과 확인 후 오차 계산
- 오차를 줄이는 방향으로 가중치 조정
- 1-3. 반복 진행
1-3. 딥러닝 구조
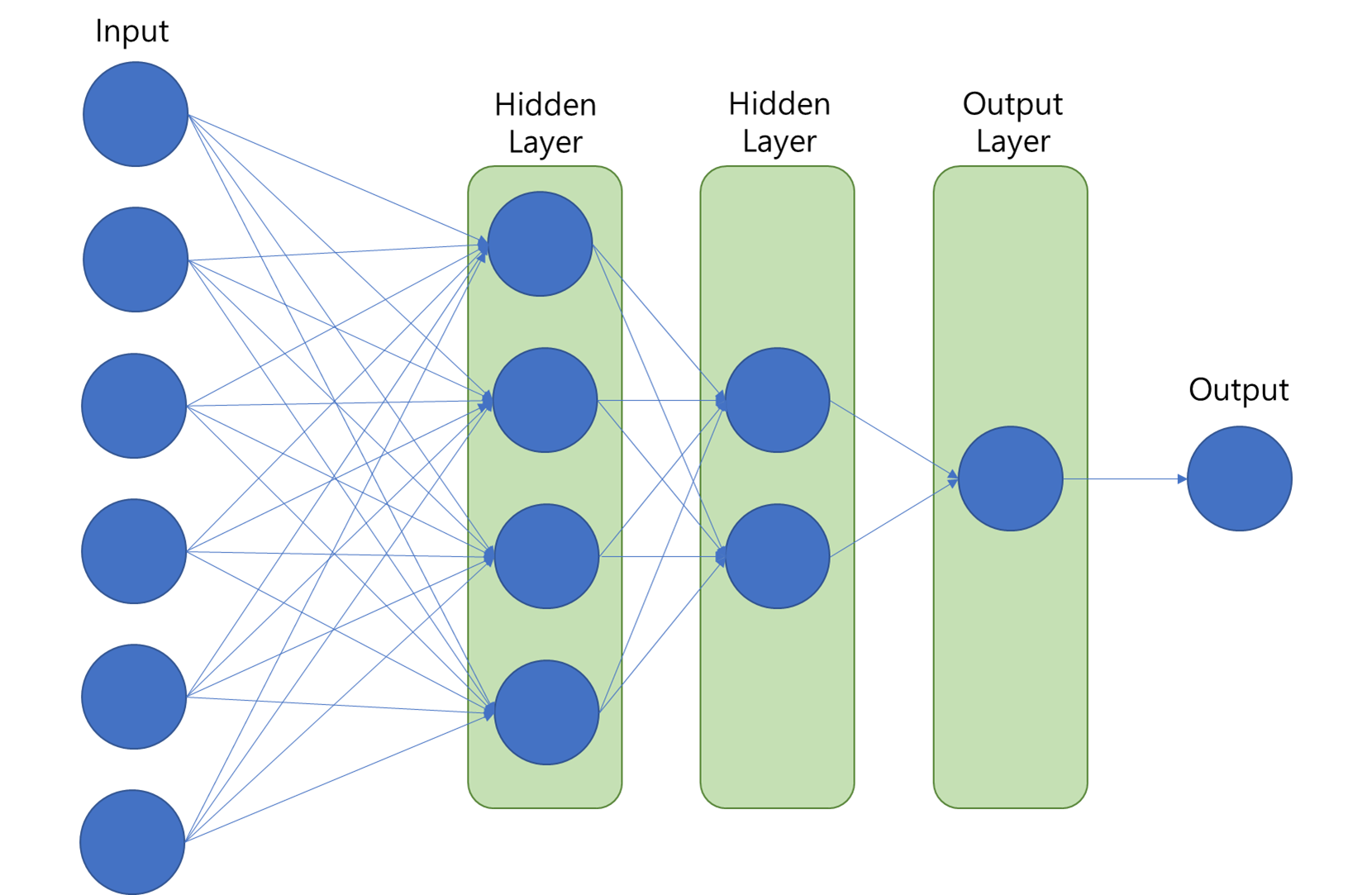
2. Hidden Layer란
- 기존의 특징을 이용하여 새로운 특징 생성
- 해당 특징이 무엇을 의미하는 지 정확히 알 수 없으나 예측된 값과 실제 값 사이의 오차를 최소화함
- 기존 데이터가 새롭게 표현되는 Feature Engineering
3. 주요 용어
- epoch : 전체 데이터를 몇 번 반복하여 학습할 것인지 결정
- Complie : 컴퓨터가 이해할 수 있는 형태로 변환하는 작업
- optimizer : 가중치를 조절하는 방법, adam이 대표적
- learning rate : 가중치를 조절할 때 얼마만큼 조절할 지 결정, 작을 수록 세세하게 조절
- loss function : 오차 계산을 무엇으로 할지 결정
- 회귀모델 : mse
- 분류모델 : cross entropy
- batch size : 전제 데이터를 나눠서 학습할 때 데이터 사이즈
- Acrivation Function : 활성화 함수, 현재 레이어의 결과값을 다음 레이어로 전달할 때 어떤 방식으로 전달할 지 결정, 미 지정시 선형회귀와 다름없음
3. 머신 러닝과 딥 러닝의 코드 차이
| 머신러닝 | 딥러닝 | |
|---|---|---|
| 데이터 전처리 | NaN 조치 가변수화 스케일링(필요시) | NaN 조치 가변수화 스케일링(필수) |
| 모델링 | 모델 선언 학습 예측 및 검증 | 모델구조&컴파일 학습&학습곡선 예측 및 검증 |

데이터 분석가&엔지니어를 희망하는 취준생