- 필요 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.graphics.mosaicplot import mosaic #mosaic plot
import scipy.stats as spst- 사용데이터 : 이직 여부 판단
- enrollee_id: 지원자 고유 ID
- city: 도시 코드
- city_development_index: 도시 개발 지수 (척도)
- gender: 지원자의 성별
- relevent_experience: 지원자의 관련 경험
- enrolled_university: 대학 등록 상태
- education_level: 지원자의 학력 수준
- major_discipline: 지원자의 전공 분야
- experience: 지원자의 총 경력(년)
- company_size: 현재 고용주의 회사 규모 (직원 수)
- company_type: 현재 고용주의 회사 유형
- last_new_job: 이전 직장과 현재 직장 간의 공백 기간(년)
- training_hours: 완료된 교육 시간
- target: 0 – 이직을 고려하지 않음, 1 – 이직을 고려함
1. 교차표
- 범주 feature 별 범주 target 수 확인 가능
# 성별에 따른 이직 고려
pd.crosstab(df['target'], df['gender']) # pd.crosstab(행, 열)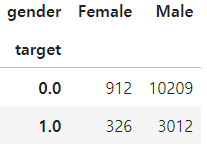
# 비율 출력
print('1.')
# 열의 합이 1
display(pd.crosstab(df['target'], df['gender'], normalize = 'columns'))
print('2.')
# 행의 합이 1
display(pd.crosstab(df['target'], df['gender'], normalize = 'index'))
print('3.')
# 전체의 합이 1
display(pd.crosstab(df['target'], df['gender'], normalize = 'all'))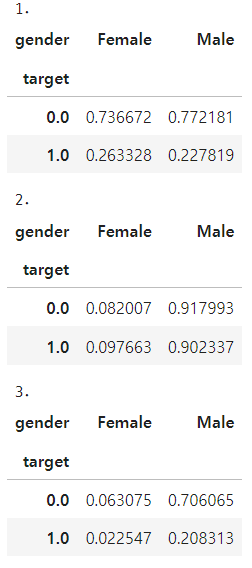
2. mosaic plot
- 교차표의 시각화
- 범주별 양과 비율을 표시
- 성별에 따른 이직 고려율 확인
mosaic(df, ['gender','target']) # mosaic(데이터, [x, y])
plt.axhline(df['target'].mean(), color = 'r') # 평균 이직 고려율 표시
plt.show()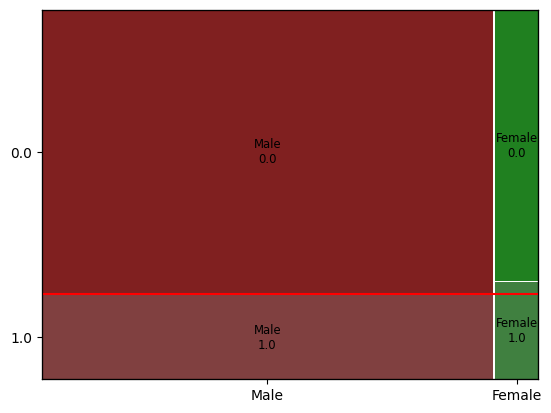
- x축의 길이는 성별의 비율을 표시
- y축은 이직 고려율을 표시
- 그래프를 봤을 때 성별에 따른 이직 고려율이 유의미해보이지 않음
3. 카이제곱검정
- 교차표의 수치화
- 기대빈도와 실제 데이터의 차이를 이용
- 카이제곱 통계량은 클수록 실제 값에 차이가 크다는 의미
- 범주의 수가 늘어날 수록 값이 커지고, 자유도의 약 2배 보다 크면 차이가 있다고 봄
- 자유도 : 범주의 수-1
# 교차표 생성
# normalize를 하면 안됨
table = pd.crosstab(df['target'], df['gender'])
spst.chi2_contingency(table)
'''
Chi2ContingencyResult(statistic=7.839477991576306, pvalue=0.005111736568166407,
dof=1,
expected_freq=array([[ 952.19572585, 10168.80427415],
[ 285.80427415, 3052.19572585]]))
'''
# 카이제곱 통계량, P-value, 자유도(target 자유도(2-1) * gender 자유도(2-1)), 기대빈도- p-value도 0.05보다 작고, 카이제곱 통계량을 볼 경우 성별과 이직 고려율은 유의미하다고 볼 수 있음
- 시각화와 수치가 다른데, 데이터의 남녀 수가 10배가 차이나므로 시각적 차이를 왜곡한 것으로 보임

데이터 분석가&엔지니어를 희망하는 취준생