import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
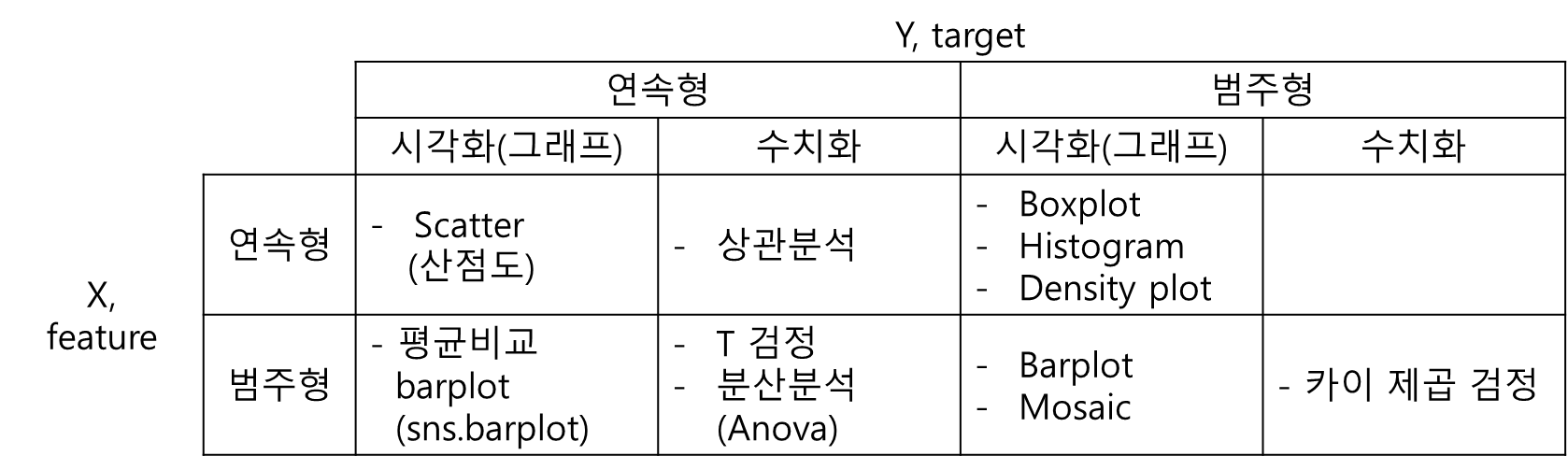
import scipy.stats as spst- 사용 데이터 : diabetes
- Pregnancies : 임신횟수
- Glucose : 포도당 부하 검사 수치
- BloodPressure : 혈압
- SkinThickness : 팔 삼두근 뒤쪽의 피하지방 측정값
- Insulin : 혈청 인슐린
- BMI : 체질량 지수
- DiabetesPedigreeFunction : 당뇨 내력 가중치 값
- Age : 나이
- Outcome : 당뇨여부(0 또는 1)
1. sns.kdeplot()
1-1. common_norm = False
- 당뇨에 걸린 사람, 안 걸린 사람 각각 kde plot 그리기
sns.kdeplot(x='Age', data = diabetes, hue ='Outcome', common_norm = False)
plt.grid()
plt.show()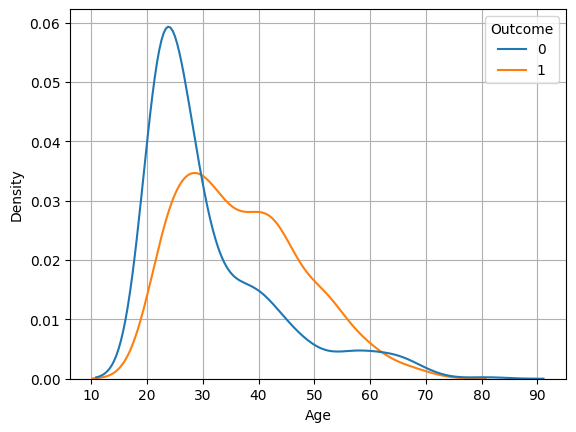
- 평균 지점에서 만남
- common_norm = True(기본값) 일 경우, 각 그래프의 비율에 따라 밑 면적의 넓이가 달라짐 -> 평균지점에서 만나지 않음 -> 정확한 비교가 힘듬
1-2. multiple = 'fill'
- 모든 구간에 대한 100% 비율로 kde plot 그리기
sns.kdeplot(x='Age', data = diabetes, hue ='Outcome', multiple = 'fill')
plt.axhline(diabetes['Outcome'].mean(), color = 'r') # 평균 표시
plt.show()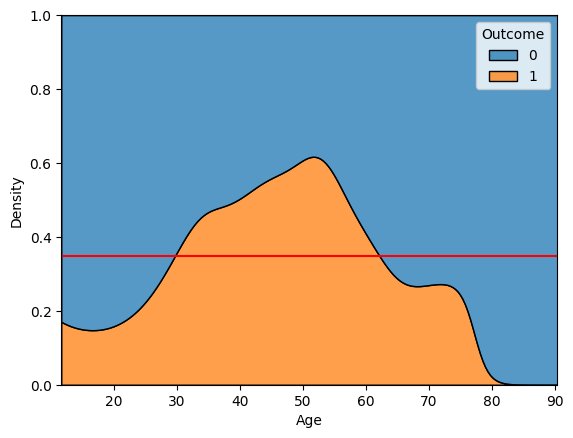
1-2-2. 번외
- histplot 사용
sns.histplot(x='Age', data = diabetes, bins = 16,
hue ='Outcome', multiple = 'fill')
plt.axhline(diabetes['Outcome'].mean(), color = 'r')
plt.show()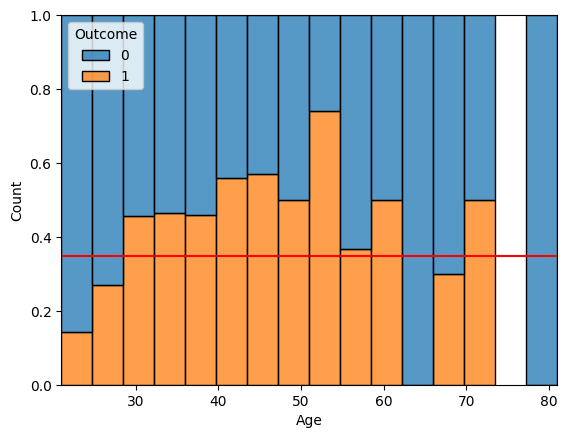

데이터 분석가&엔지니어를 희망하는 취준생