트랜스포머 완벽 이해하기
기술블로그를 작성할겸 Transformer을 공부하면서 느낀 내 의식의 흐름을 적어 놓을 예정이다.
논문의 제목에서 알 수 있듯이 Transformer라는 아키텍처에는 이 어텐션이라고 하는 것이 메인 아이디어로 사용 된다는걸 알 수 있다.
실제로 Transformer는 Attention이라는 메커니즘을 전적으로 활용하는 아키텍처이다.
등장배경
2021년 기준으로 최신 고성능 모델들은 Transformer아키텍처를 기반으로 하고 있다.
대표적으로 GPT는 Transformer의 Decoder 아키텍처를 활용했고, BERT는 Transformer의 Encoder 아키텍처를 활용했다.
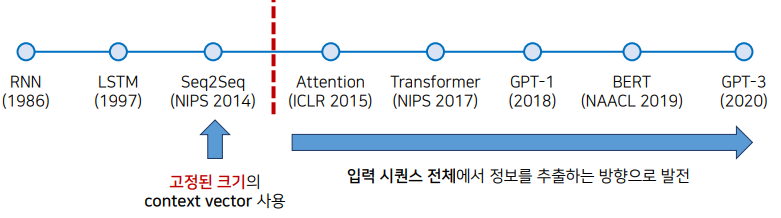
NLP의 Task중에서 가장 대표적이면서 중요한 Task중 하나는 기계번역이다. 실제로 기계번역 기술의 발전 과정을 확인해보면 RNN을 시작으로 10년 뒤에 LSTM이 나왔다. 딥러닝 기술이 빠르게 나오는 2014년도에 LSTM을 활용하여 고정된 크기의 context vector을 사용하는 방식으로 번역을 수행하는 방식인 S2S가 나왔다.
다만, 이런 2014 이 시점만 하더라도 고정된 크기의 context vector에다가 문장 전체를 압축을 할 필요가 있다는 점에서 성능적인 한계가 존재했다. 이후에 어텐션 메커니즘이 제안된 논문이 나오면서 S2S기법의 성능을 끌어올릴 수 있었다.
그 이후에 Transformer 논문에서는 RNN이 필요가 없다는 아이디어로 오직 Attention 기법에 의존하는 아키텍처를 설계했더니 성능이 훨씬 좋아진 것을 보여주었다. 이 시점 이후로 NLP의 Task에서 RNN 기반의 아키텍처를 사용하지 않고 Attention 메커니즘을 더욱 더 많이 사용하게 되었다.
연구 방향이 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전되었다 할 수 있다.
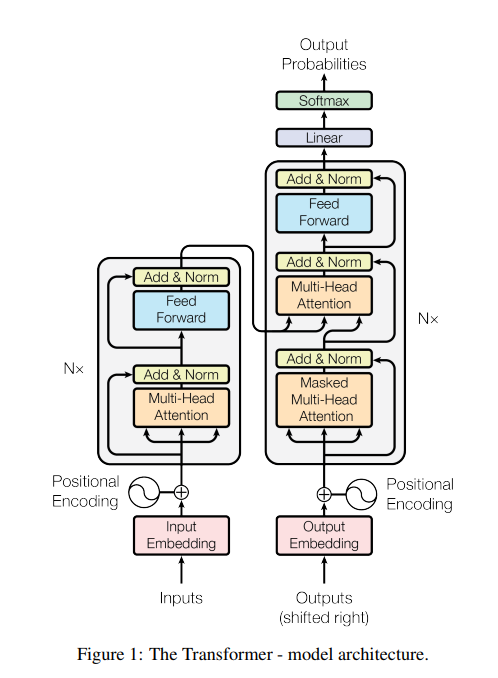
- Transformer는 RNN이나 CNN을 전혀 사용하지 않는다. 그렇기 때문에 Transformer는 문장 내 각각의 단어들에 대한 순서에 대한 정보를 알려주기 위해서 Positional Encoding을 이용한다.
- RNN을 사용하진 않지만 Encoder Part와 Decoder Part로 구성되는건 동일하다.
- Attention을 한 번만 쓰는게 아니라 N번만큼(논문에선 N = 6) 중첩되어 사용한다.
Encoder Part : 입력 값 임베딩
단어 정보를 네트워크에 넣기 위해서는 일반적으로 보통인 임베딩 과정을 거친다. 그렇게 해주는 이유는 일단 맨 처음에 입력 차원은 특정 언어 에서 존재할 수 있는 단어의 개수와 같기 때문이다.
그렇게 차원이 많을 뿐만 아니라 각각의 정보들은 원 핫 인코딩 형태로 표현이 되기 때문에 일반적으로 네트워크 에 넣을 때는 먼저 임베딩 과정을 거쳐서 더욱 더 적은 차원의 값으로 표현한다. 문장을 어떠한 실수 값으로 표현할 수가 있다는거다.
뭐 암튼간에 RNN은 순서에 맞게 들어가기 때문에 각각의 Hidden state값은 순서에 대한 정보를 가지게 된다. 만약에 Transformer와 같이 RNN 자체를 사용하지 않는다면 위치에 대한 정보를 주기 위해서 하나의 문장에 포함되어 있는 각각의 단어 중에서 위치에 대한 정보를 포함하고 있는 Embedding값을 사용할 필요가 있다.
Positional Encoding
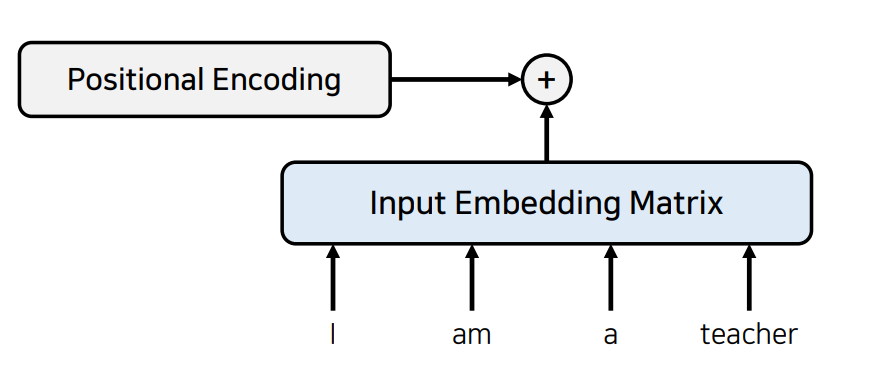
이를 위해 Transformer에서는 위치에 대한 정보를 인코딩하고 있는 위치 인코딩 즉 Positional Encoding을 사용한다. Input Embedding Matrix와 같은 dimension를 가지는 별도의 위치에 대한 정보를 가지고 있는 인코딩 정보(Positional Encoding)를 더해줌으로써 각각의 단어의 순서에 대한 정보를 네트워크가 알 수 있도록 만드는 것입니다
Self-Attention
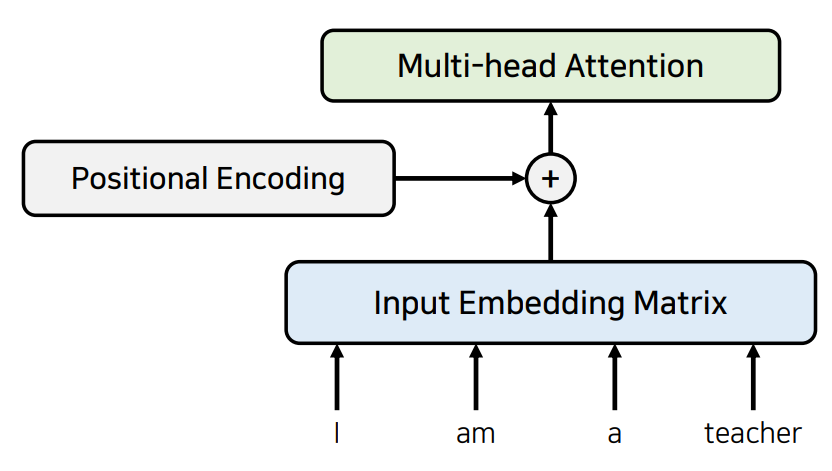
이제 그래서 그런 입력을 받아서 각각의 단어들을 이용해서 어텐션 1트 하고요 이렇게 Encoder Part에서 수행하는 Attention은 Self-Attention이라고 해서 각각의 단어가 서로에게 어떤 연관성을 가지고 있는지를 구하기 위해 사용한다.
Residual
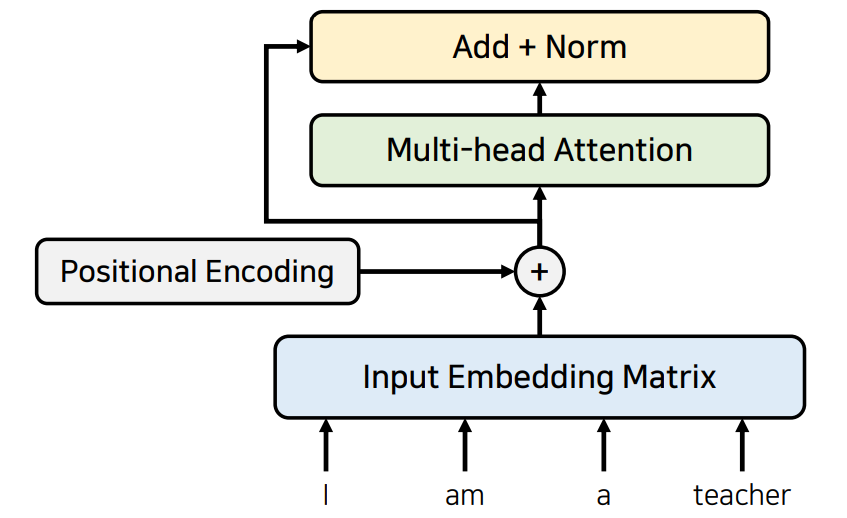
여기에서 추가적으로 Residual Learning 같은 테크닉을 사용된다. 특정 레이어를 건너뛰어서 입력할 수 있도록 만드는 것을 일반적으로 Residual connection 이라고 부른다.
이렇게 해 줌으로써 전체 네트워크 는 기존 정보를 입력 받으면서 추가적으로 잔여 된 부분만
학습하도록 만들기 때문에 전반적인 학습 난이도가 낮고 그렇기 때문에 초기에 모델 수렴 속도가 높게 되고 그로 인해 더욱 더 Global Optimizer을 찾을 확률이 높아지기 때문에 전반적으로 다양한 네트워크에 대해서 Residual을 사용했을때 성능이 좋아지는 걸 많이 목격할 수 있다.
Transformer 또한 마찬가지로 그런 아이디어를 전적으로 채택해서 성능을 높였다고 할 수 있는 겁니다
인코더의 기본 동작 방식
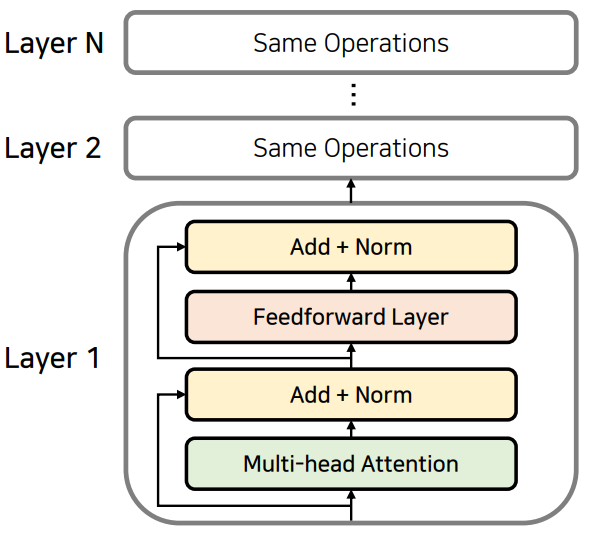
이렇게 Attention을 수행해주고 나온 값과 이렇게 Residual을 이용해서 바로 더해진 값을 같이 받아서 Nomarlization까지 수행한 뒤에 그 결과를 내보낼 수 있도록 만든다.
이것이 인코더의 기본 동작 방식이다. 이런식으로 Attention과 정규화 과정을 반복하는 방식으로 여러 개의 레이어를 중첩해서 사용한다. 이 때 한 가지 유의할 점은 각각의 Layer는 서로 다른 파라미터를 가진다.
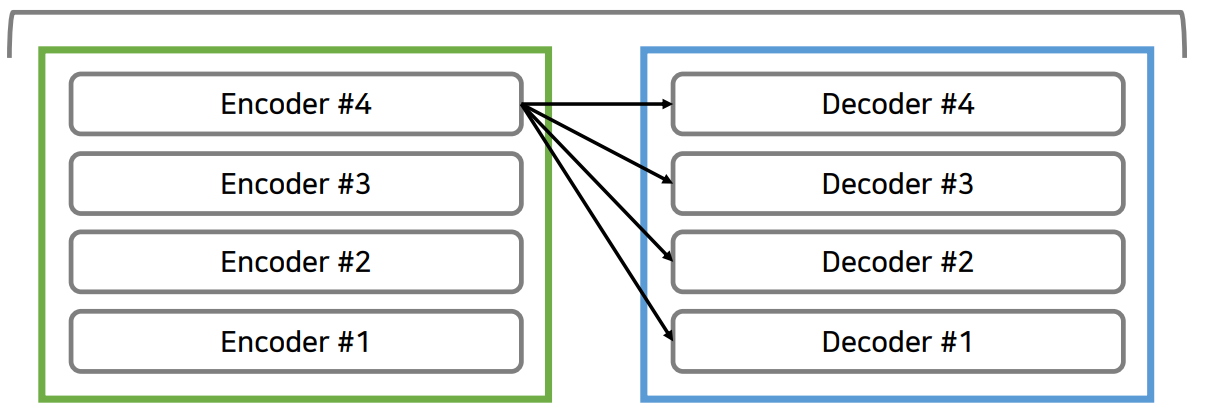
인코더 레이어를 반복해서 가장 마지막에 인코더 에서 나오게 된 그 출력 값은 이렇게 Decoder에 들어가게 된다. 정확히 말하자면, Decoder의 두 번째 Multi-head Attention에 들어간다.
이렇게 해주는 이유는 Decoder part에서는 매번 출력할 때마다 입력소스 문장 중에서 어떤 단어에게 가장 많은 초점을 두어야 되는지를 알려주기 위함이다.
디코더의 기본 동작 방식
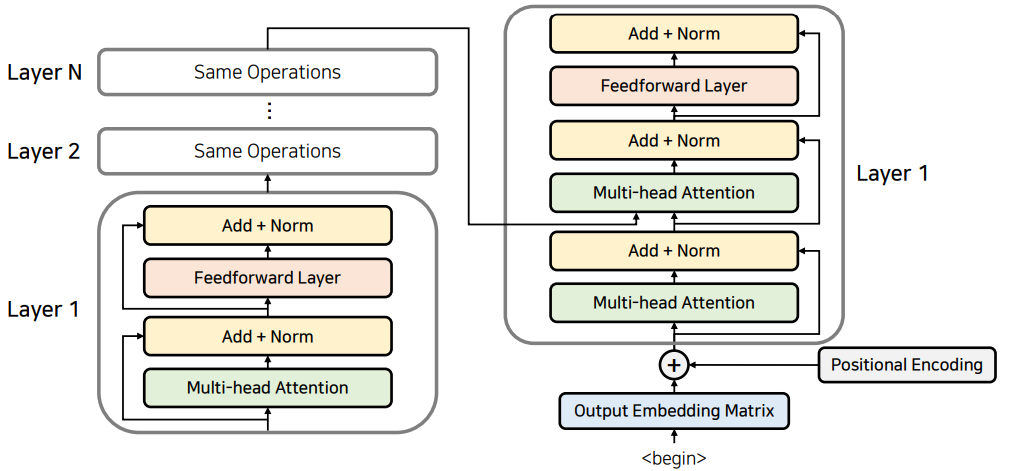
하나의 Decoder Layer는 두 개의 Attention을 사용한다. 첫 번째 어텐션은 Self-Attention 으로 인코더 파트와 마찬가지이다. 각각의 단어들이 서로가 서로에게 어떠한 가중치를 가진 인지를 구하도록만들어서 출력되고 있는 문장에 대한 전반적인 표현을 학습할 수 있도록 만든다.
두번째 어텐션 에서는 인코더 에 대한정보를 어텐션 할 수 있도록 만든다. 각각의 출력 단어가 Encode될 출력 정보를 받아와 사용할 수 있도록 만든다. 다시 말해 각각의 출력되고 있는 단어가 소스 문장에서의 어떤 단어와 연관성이 있는지를 구해주는 것이다.
Attention
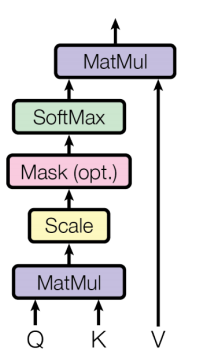
물어보는 주체 Query가들어오고 각각의 어텐션을 수행 할 단어 Key 로 들어간다.
그 다음 행렬곱하고 간단하게 Scaling 해주고 필요하다 싶으면 Masking 씌워 준 다음에 Softmax를 취해서 각각의 Key 중에서 어떤 단어와가장 높은 연관성을 가지는 지 비율을 구할 수 있다.
앞에서 공부 했었던 어텐션 메커니즘과 같다고 할 수 있죠
그렇게 구해진 확률과 실제로 Value 값을 곱해서 가중치가 적용된 결과적인 어텐션 Value를 구할 수가 있는 것이다
얘가 얘네들이랑 얼마나 관련이 있는가?
Query : 얘
Key : 얘네
Value : 관련도
Multi-Head-Attention
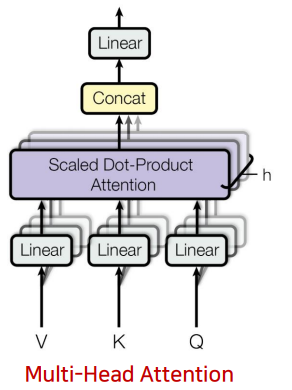
서로 다른 어텐션 컨셉을 학습하도록 h개의 Attetion으로 만들어서 더욱더 구분된 다양한 특징들을 학습할 수 있도록 유도해 준다.
입력으로 들어온 값은 세개로 복제가 되어서 각각 Value, Key, Query로 들어가게 되고 얘네들은 Linear Layer 즉, 행렬곱을 수행해서 h개로 구분된 각각의 쿼리 쌍들을 만든다.
이때 여기에서 h 는 헤드의 개수 이기 때문에 각각 서로 다른 헤드 끼리 Value, Key, Query 쌍을 받아서 어텐션을 수행해서 결과를 내보낸다.
Attention의 입력 값과 출력값의 dimension은 같아야 되기 때문에 각각의 헤드로부터 나오게 된
어텐션 값들을 concat해서 일자로 쭉 붙인 뒤 마지막으로 Linear 레이어를 거쳐서 output값을 내보내게 된다.
입력값과 출력값의 dimension이 같도록 만들어서 Multi-Head Attention을 사용한 뒤에도 dimension이 줄어들지 않도록 만든다.
Multi-Head-Attention은 전체 아키텍처에서 다 동일한 함수로 동작한다
다른 점이라고 한다면 사용되는 위치마다 Value, Key, Query를 어떻게 사용할지 가 달라질 수 있는 건데 그런 점을 제외하고 기본적인 각각의 Attention Layer의 동작 방식은 같다.
각각의 단어를 출력하기 위해서 어떤 정보를 참고 해야 해? 라고 이렇게 인코딩 한테 물어 보는 것이기 때문에 Decode에 있는 Multi-head-Attention 단어가 Query가되고 Encode에 있는 각각의 출력값들이 Value, Key가 된다.
다음 포스팅에선 Transformer의 매운맛을 가져올 예정이다. Attetion의 동작 원리와 수식들을 가져와서 음미하는 시간을 갖도록 하겠다. 새해 복 많이 받으세용
