CTAB-GAN
https://proceedings.mlr.press/v157/zhao21a/zhao21a.pdf
https://github.com/Team-TUD
연속형, 범주형, 혼합형 변수를 포함한 다양한 데이터 유형을 처리하도록 설계된 조건부 GAN 아키텍처인 CTAB-GAN을 소개한다. 이 모델은 데이터 불균형 및 롱테일 분포와 같은 문제를 해결하는 것을 목표로 한다.
기존 GAN 기반 방법의 한계, 특히 혼합된 데이터 유형과 불균형 분포를 효과적으로 처리할 수 없음을 지적한다.
Motivation
은행 , 보험 회사 , 의료 같은 데이터 세트는 문제가 있다.
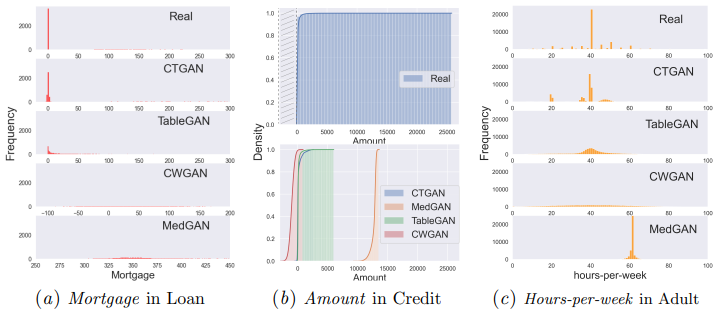
(A) 표로 구성되고 연속형 변수와 범주형 변수 또는 두 가지의 mixed variable (Mortgage: 주택담보대출)로 채워진다. 이 값은 0 또는 연속적인 양수가 될 수 있다. 여기에서 이러한 유형의 변수를 mixed variable라고 한다.
(B) 연속 데이터 변수는 종종 값 범위가 넓고 long-tailed distribution를 보일 수 있다(예: 신용 카드 거래 금액 통계).
모델링, 재현하기 어려움
(C) 연속 데이터 변수는 여러 모드의 왜곡된 주파수가 있는 분포로 구성될 수도 있다 .
모델링이 더 어려움
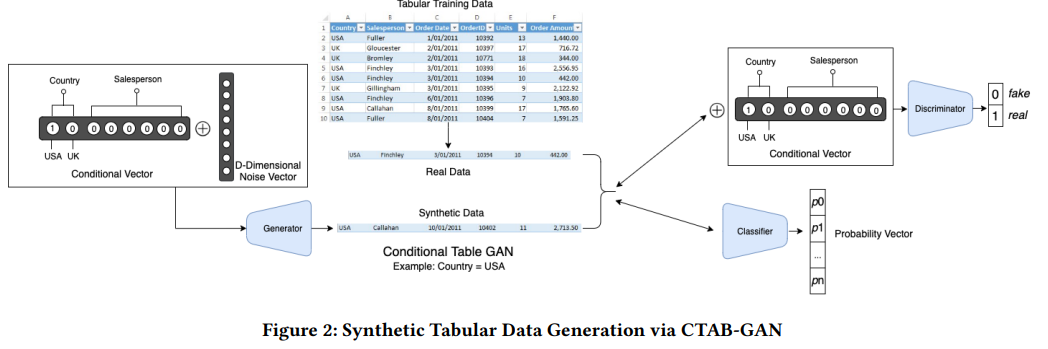
Architecture
(i) 연속 및 범주형 변수의 mixed variable을 인코딩하고
(ii) 롱테일 연속 변수의 효율적인 모델링을 수행하고
(iii) 불균형 범주형 변수와 비대칭 연속 변수에 대한 견고성을 높였다.
conditional GAN 에 classification loss을 도입하고,
mixed variables를 효율적으로 인코딩하고,
연속 변수의 고도로 비대칭된 분포를 처리하는 데 도움이 되는 conditional vector 에 대한 새로운 인코딩을 했다.
Technical Background
CTAB-GAN Enhancements
-
Information Loss: 생성된 데이터가 실제 데이터와 유사한 통계적 속성(평균 및 표준 편차)을 유지하는지 확인
-
Classification Loss:
생성된 데이터의 레이블이 주어진 조건과 일치하는지 확인하기 위해 auxiliary classifier(보조 분류기)를 사용 -
Generator Loss: 생성기가 조건과 일치하는 데이터를 생성
Loss Functions
G loss function 은
original GAN loss + additional information, classification, generator loss
-
Original GAN Loss:
-
Information Loss:
-
Classification Loss:
-
Generator Loss:
이 조합은 실제 데이터와 매우 유사한 high-quality synthetic data 를 생성.
Mixed-type Encoder
인코더는 각 값을 value-mode pair 처리하여 mixed data 처리.
연속 변수는 모드 수를 추정하고 가우스 혼합을 데이터에 맞추는 변형 variational Gaussian mixture model(VGM)을 사용하여 인코딩
Mixed-type Encoder
Encoding Process
continuous regions의 경우 인코더는 각 값을 가장 높은 확률을 갖는 모드와 연관시키고 normalizes.
최종 인코딩은 정규화된 값과 모드를 연결한 것
Handling Categorical Variables
one-hot encoding
Counter Imbalanced Training Datasets
Training-by-Sampling
dataset imbalance를 위해.
-
Sampling Real Data: conditional vector filters and rebalances the training data by giving higher chances to minority classes.
-
Log-Frequency Sampling: The log probability 쓰면 훈련중 minority modes/classes에 더 많은 기회가 옴
Treat Long Tails
로그변환
