Diffusion Models Beat GANs on Image Synthesis
https://arxiv.org/abs/2105.05233?ref=jaewon.work
https://www.jaewon.work/paper-review-diffusion-models-beat-gans-on-image-synthesis/
Intro
최근 몇 년 동안, 생성 모델 분야는 특히 생성된 출력의 품질과 다양성에서 상당한 발전이 있었다. diffusion 모델은 고품질 이미지를 생성할 수 있는 생성 모델의 주요 클래스로 부상했다. 기존의 생성적 적대 네트워크(GAN)와 달리 diffusion 모델은 향상된 훈련 안정성과 더 나은 배포 범위를 포함한 여러 이점을 제공한다. 본 논문에서는 diffusion 모델이 이미지 합성 작업에서 GAN을 능가할 수 있음을 보여주는 일련의 혁신과 실험을 제시한다.
diffusion모델의 배경
diffusion 모델은 noise 이미지를 반복적으로 noise 제거하여 샘플을 생성한다. 이 과정은 무작위 noise으로 시작하여 점차 일관된 이미지로 미세화한다. 이러한 모델의 훈련은 각 단계에서 noise을 예측하는 방법을 학습하는 것을 포함하여 모델이 diffusion 과정을 효과적으로 되돌릴 수 있도록 한다. 최근 연구에 따르면 diffusion 모델은 여러 벤치마크 데이터 세트에서 최첨단 성능을 달성할 수 있다.
주요 기여 사항
-
개선된 architecture: 저자들은 다양한 architecture 개선 사항을 살펴봄으로써 FID(Fréchet Inception Distance) 점수를 크게 향상시켜 더 나은 이미지 품질을 나타내는 모델을 제안한다.
-
classifier guidance: conditional 이미지 합성을 위한 새로운 방법이 도입되어 classifier의 그래디언트를 사용하여 diffusion 과정을 guidance한다. 이 방법은 이미지 다양성과 충실도 사이의 균형을 유지하여 고품질 샘플을 생성하는 데 유연성을 제공한다.
-
기술: 이 연구는 classifier guidance와 업샘플링 diffusion 모델을 결합하면 고해상도 이미지에서 우수한 FID 점수를 달성하여 이미지 품질을 더욱 향상시킬 수 있음을 보여준다.

실험은 제안된 diffusion 모델이 이미지 품질 및 분포 범위 측면에서 최고의 GAN을 능가한다는 것을 보여준다. 모델은 ImageNet 및 LSUN 데이터 세트에서 눈에 띄는 개선을 달성하여 다양한 이미지 합성 작업에서 diffusion 모델의 잠재력을 보여준다.
2. Background
이 절에서는 diffusion 모델, diffusion 모델의 개발 및 현재의 최첨단 성능을 이끌어 낸 개선점에 대한 개요를 제공한다.
diffusion 모델 개요
diffusion 모델은 noise 과정을 반복적으로 반전시켜 샘플을 생성한다. 기본적인 아이디어는 noise이 많은 이미지로 시작하여 noise을 단계적으로 줄여 선명한 이미지를 생성하는 것이다. 이 과정은 높은 수준의 순서로 설명될 수 있다:
- Noise로 시작. noise가 많은 이미지로 시작.. 여기서 는 총 시간 단계 수.
2.점진적 noise 제거: 에서 1까지의 각 시간 단계 에 대해 모델을 사용하여 에서 이미지의 약간 덜 noise가 많은 버전을 예측. - 최종 샘플: 모든 시간 단계를 처리한 후 최종 이미지인 를 얻음.
diffusion 모델들의 트레이닝은 각각의 시간 단계에서 noise 성분을 예측하는 것을 학습하는 것을 포함하고, 모델은 diffusion 프로세스를 효과적으로 역전시킬 수 있게 한다.
수학적 기초
diffusion 모델의 수학적 토대는 noise 제거의 개념에 있다. 각 시간 단계에서 모델은 현재 이미지의 noise를 예측하며, 이는 다음과 같이 설명할 수 있다:
여기서 는 시간 단계 에서 noise 성분에 대한 모델의 예측이다.
훈련 object는 일반적으로 실제 noise과 예측 noise 사이의 단순 평균 제곱 오차(MSE) 손실이다:
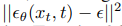
이 object는 noise 제거 diffusion 모델을 변형 자동 인코더(VAE)로 해석함으로써 도출된 변형 하한(VLB)보다 실제로 더 잘 작동한다.
diffusion모델의 개선
- 분산 매개변수화: Nichol과 Dhariwal은 분산 을 신경망으로 매개변수화하여 diffusion 단계가 적은 샘플링 시 더 나은 성능을 제공할 것을 제안했다.
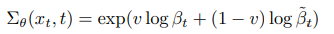
- 하이브리드 object: 단순 MSE 손실과 VLB를 결합한 하이브리드 object는 역프로세스 분산을 보다 효과적으로 학습하는 데 도움이 된다.
- 대체 noise 제거 프로세스: 송 등은 결정론적 샘플링이 가능한 대체 비마르코비안 noise 제거 프로세스인 DDIM을 도입하여 고품질을 유지하면서도 보다 적은 단계로 샘플링할 수 있는 또 다른 방법을 제공하였다.
Sample Quality Metrics
diffusion 모델에 의해 생성된 샘플의 품질은 다음과 같은 여러 메트릭을 사용하여 평가:
- 인셉션 점수(IS): 모델이 클래스의 전체 분포를 얼마나 잘 포착하면서도 설득력 있는 샘플을 생성하는지 측정.
- Frechet Inception Distance(FID): 생성된 이미지와 실제 이미지의 분포 사이의 거리를 측정하여 다양성과 충실도를 더 잘 포착할 수 있.
- sFID: 공간적 특징을 사용하는 FID 버전으로, 높은 수준의 구조를 이미지에 더 잘 포착.
- 정밀도 및 리콜: 정밀도는 생성된 샘플 중 충실도가 높은 샘플의 비율을 측정하는 반면, 리콜은 모델에서 다루는 실제 데이터 분포의 비율을 측정.
3. architecture 개선사항
본 절에서는 diffusion 모델의 성능 향상을 위한 다양한 architecture 수정을 탐색하며, 특히 생성된 이미지의 품질을 측정하는 FID(Fréchet Inception Distance)를 개선하는 데 중점을 둔다.
기본 architecture
비교를 위해 사용되는 기본 architecture는 Ho et al. 에 의해 소개된 UNet architecture이다. 이 architecture는 잔차 레이어의 스택과 다운샘플링 컨볼루션을 사용하고, 이어서 업샘플링 컨볼루션을 갖는 잔차 레이어의 스택을 사용하며, 동일한 공간 해상도의 레이어를 연결하는 스킵 연결을 포함한다. 또한 16×16 해상도에서 글로벌 어텐션 레이어가 사용된다.
변화내용
- Depth vs. Width: 모델의 심도와 너비 중 어느 하나를 증가시키면서 모델 크기를 비교적 일정하게 유지하였다.
- Attention Heads: 이미지의 여러 부분에 집중할 수 있는 모델의 능력을 높이기 위해 Attention Heads의 수를 늘렸다.
- 다중 해상도 attention: attention 메커니즘은 16×16에서만 적용되는 것이 아니라 여러 해상도(32×32, 16×16, 8×8)에서 적용되었다.
- BigGAN Residual Blocks: 활성화를 업샘플링 및 다운샘플링하기 위해 BigGAN의 Residual Blocks가 사용되었다.
- 잔차 연결 재조정: 이전 작업에 따라 $\frac{1}{\sqrt{2}}의 인수를 사용하여 잔여 연결을 재조정했다.
Ablation
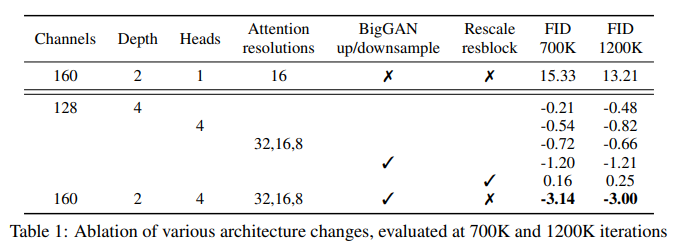
본 논문은 각 architecture 변화가 FID 점수에 미치는 영향을 평가하기 위해 Ablation 연구를 수행한다. 모델들은 배치 크기가 256인 ImageNet 128x128에서 훈련되었고 250개의 단계를 사용하여 샘플링되었다. 평가들은 훈련 프로세스의 두 개의 상이한 지점들, 즉 700K 및 1200K 반복에서 수행되었다.
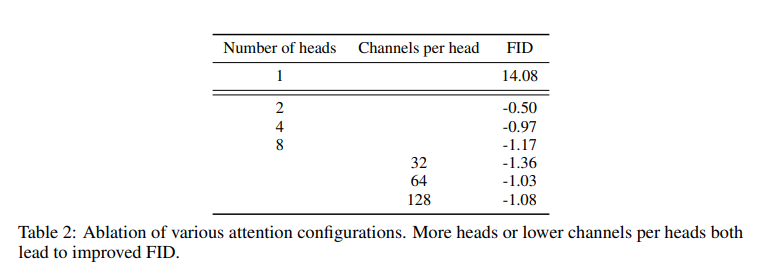
Ablation 연구의 주요 결과는 다음과 같다:
-
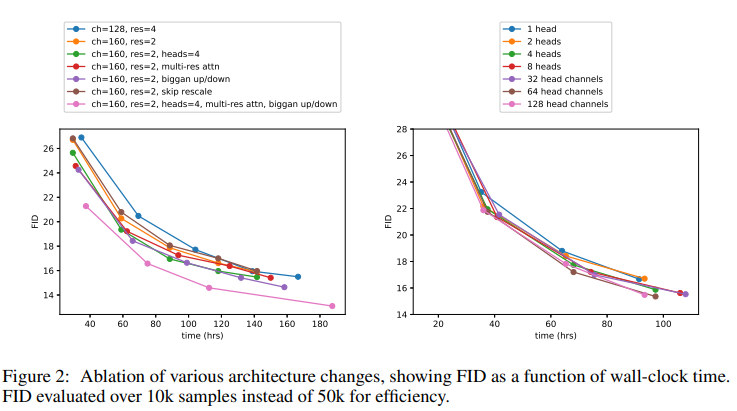
Depth vs. Width: Depth를 증가시킴과 동시에 훈련 시간도 크게 증가시켰다. Wall-clock 시간 측면에서 더 넓은 모델이 더 나은 성능을 발휘하여 유사한 성능 수준에 도달했다.
-
attention 헤드 수: 헤드당 attention 헤드 수가 많거나 채널 수가 적을수록 FID 점수가 향상되었다. 월-클록 시간에 대한 최적 구성은 헤드당 64개 채널인 것으로 나타났다.
-
Multi-Resolution Attention: 여러 해상도에서 Attention을 사용하면 샘플 품질이 크게 향상되었다.
-
BigGAN 잔차 블록: 업샘플링 및 다운샘플링을 위해 BigGAN 잔차 블록을 통합함으로써 FID도 크게 향상되었다.
-
잔여 연결 재조정: 이 수정을 통해 성능이 향상되었으며, 다른 변경 사항과 결합하면 개선 사항이 추가되었다.
Adaptive Group Normalization
적응적 그룹 정규화(Adaptive Group Normalization, AdaGN)라고 불리는 계층을 실험하였는데, 이 계층은 그룹 정규화 작업 후에 각 잔차 블록에 타임스텝과 클래스 임베딩을 통합한다:
여기서 는 중간 활성화이며, 는 시간 단계 및 클래스 임베딩의 선형 투영으로부터 얻어진다.
Adaptive Group Normalization 계층은 FID 점수를 유의하게 향상시키는 것으로 나타났으며, 모든 후속 모델 실행에 기본적으로 포함되었다.
최종 개선 모델 architecture
- 해상도당 2개의 잔여 블록이 있는 가변 폭.
- 헤드당 64개의 채널이 있는 다중 attention 헤드.
- 32×32, 16×16, 8×8 해상도에서의 attention 메커니즘.
- 업샘플링 및 다운샘플링을 위한 BigGAN 잔차 블록.
- 잔여 블록에 타임스텝 및 클래스 임베딩을 주입하기 위한 Adaptive Group Normalization.
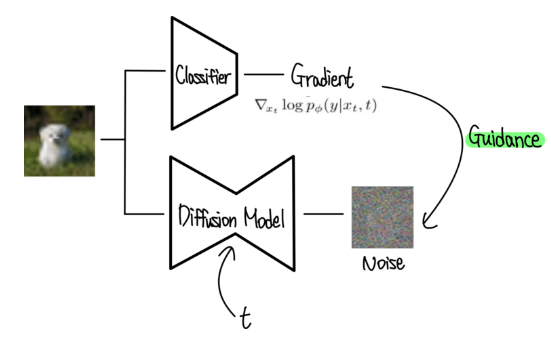
4. classifier guidance
classifier guidance는 특히 conditional 이미지 합성 작업을 위해 diffusion 모델의 성능을 향상시키기 위해 도입된 기술이다. 이 방법은 diffusion 프로세스를 guidance하기 위해 classifier로부터의 그래디언트를 사용하여 이미지 다이버시티와 충실도 사이의 유연한 트레이드오프를 허용한다.
motivation
conditional 이미지 합성을 위한 GAN은 종종 고품질 이미지를 생성하기 위해 클래스 레이블을 활용한다. 이러한 모델은 일반적으로 생성된 이미지로부터 클래스 레이블을 예측하도록 설계된 클래스 conditional 정규화 통계 및 classifier를 사용한다. 이에 영감을 받아 저자는 conditional 작업에 대한 성능을 향상시키기 위해 classifier 지침을 diffusion 모델에 통합하는 것을 탐구했다.
conditional 역noise 공정
클래스 레이블 에서 역noise 프로세스를 조건화하기 위해 저자들은 표준 diffusion 샘플링 프로세스를 수정할 것을 제안한다. 수정된 프로세스는 역diffusion 단계에서 사용되는 가우시안 분포의 평균을 조정함으로써 근사화된다.
1.Unconditional Reverse Process: 기본 diffusion 모델은 가우시안 분포를 사용하여 에서 이전 시간 단계 를 예측:
여기서 와 는 모델에 의해 예측된 평균과 분산이다.
- conditional 샘플링: 클래스 정보를 통합하기 위해 다음에 따라 각 전환을 샘플링하도록 프로세스가 수정:여기서 는 정규화 상수이고, 는 classifier에 의해 예측된 바와 같이 가 주어진 등급 의 확률이다.
classifier 그래디언트는 가우시안 분포의 평균을 조정하는 데 사용:
여기서 는 classifier 그래디언트의 척도 인자.
classifier guided 샘플링 알고리즘
classifier guided 샘플링을 위한 두 가지 알고리즘이 제시되어 있는데, 하나는 표준 확률적 diffusion 프로세스를 위한 것이고 하나는 DDIM(Denoising Diffusion Implicit Models)을 사용한 결정론적 샘플링을 위한 것이다.
- 확률적 diffusion 과정:

- DDIM을 사용한 샘플링:


classifier 그라디언트 스케일링
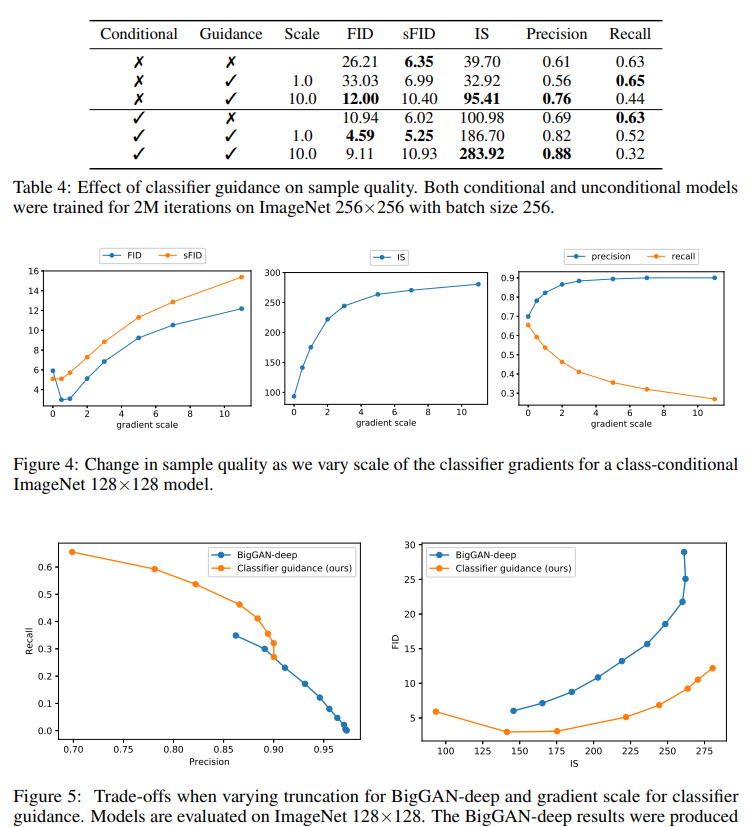
저자들은 classifier 그래디언트를 1보다 큰 인자만큼 스케일링하면 생성된 샘플의 품질이 크게 향상된다는 것을 발견했다. 1의 척도로 classifier는 원하는 클래스에 합리적인 확률을 할당했지만 샘플은 클래스와 시각적으로 일치하지 않았다. 척도 인자를 증가시키면 classifier 분포의 모드가 증폭되어 충실도가 높은 샘플에 더 초점이 맞춰졌다.
- 샘플 품질에 미치는 영향: 그라디언트를 확장하면 리콜 비용으로 Inception Score(IS)와 정밀도가 향상되어 샘플 충실도와 다양성 사이의 균형이 적용.
- Optimal Scaling: 다양성과 충실도 사이의 균형이 이루어진 중간 규모에서 최고의 FID 점수를 얻었다.