지난 포스트에서의 핵심 아이디어를 조금 더 확장해서 합성곱 신경망을 적용하고, 조건적 GAN을 통해 원하는 클래스의 데이터를 생성해볼거다.
우선 CNN에 익숙해지기 위해 MNIST로 시작해보자.
MNIST_CNN
class Classifier(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
# expand 1 to 10 filters
nn.Conv2d(1, 10, kernel_size=5, stride=2),
nn.LeakyReLU(0.02),
nn.BatchNorm2d(10),
# 10 filters to 10 filters
nn.Conv2d(10, 10, kernel_size=3, stride=2),
nn.LeakyReLU(0.02),
nn.BatchNorm2d(10),
View(250),
nn.Linear(250, 10),
nn.Sigmoid()
)
# create loss function
self.loss_function = nn.BCELoss()
# create optimiser, using simple stochastic gradient descent
self.optimiser = torch.optim.Adam(self.parameters())
# counter and accumulator for progress
self.counter = 0
self.progress = []
pass-
맨 처음 요소는 nn.Conv2d 합성곱 레이어이다.
-
매개변수 차례대로 (입력채널의 개수, 출력채널의 개수, 커널의 크기, 스트라이드)이다.
-
28 X 28크기의 MNIST 이미지에 대해 스트라이드가 2인 5X5 커널을 적용하면 12 X 12가 된다.
-
활성화 함수는 저번에 잘 작동 했던 LeakyReLU를 사용한다.
-
BatchNorm으로 레이어의 전 채널에 정규화를 적용한다.
그럼 구조가 어떻게 되냐면,
[3채널 이미지] -> [커널 10개/피쳐맵 10개] -> [커널 10개/피쳐맵 10개] -> FCLayer -> 10
일케 된다. 자 돌려보자 Let's go!

시간이 4분 정도 빨리짐.

Loss 굿

정확도 1% 좋아짐.
자자 이제 관성을 이용해 CelebA까지 가보자.
CelebA CNN
class CelebADataset(Dataset):
def __init__(self, file):
self.file_object = h5py.File(file, 'r')
self.dataset = self.file_object['img_align_celeba']
pass
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
if (index >= len(self.dataset)):
raise IndexError()
img = numpy.array(self.dataset[str(index)+'.jpg'])
# crop to 128x128 square
img = crop_centre(img, 128, 128)
return torch.cuda.FloatTensor(img).permute(2,0,1).view(1,3,128,128) / 255.0
def plot_image(self, index):
img = numpy.array(self.dataset[str(index)+'.jpg'])
# crop to 128x128 square
img = crop_centre(img, 128, 128)
plt.imshow(img, interpolation='nearest')
pass
passCelebA 이미지는 217 X 178px이다. 128 X 128px로 crop 해주자.
싹 다 crop행
이제 CNN을 활용해 Layer를 쌓아보자.
Discriminator
# define neural network layers
self.model = nn.Sequential(
# expect input of shape (1,3,128,128)
nn.Conv2d(3, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.Conv2d(256, 3, kernel_size=8, stride=2),
nn.LeakyReLU(0.2),
View(3*10*10),
nn.Linear(3*10*10, 1),
nn.Sigmoid()
)
아까랑 원리는 같다. 추가로 설명할게 있다면 View((1, 3, 10, 10))이다.
마지막 피쳐 맵을 다음 Layer에 전달될 수 있도록 단순히 300(3x10x10)개 값으로 이루어진 1차원 텐서로 형태를 바꾸는 역할을 한다.
D = Discriminator()
# move model to cuda device
D.to(device)
for image_data_tensor in celeba_dataset:
# real data
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
# fake data
D.train(generate_random_image((1,3,128,128)), torch.cuda.FloatTensor([0.0]))
passDiscriminator를 판별하기 위해 generate_random_image()가 (1,3,128,128)형태의 4차원 텐서로 형태를 바꾸도록 수정한다.
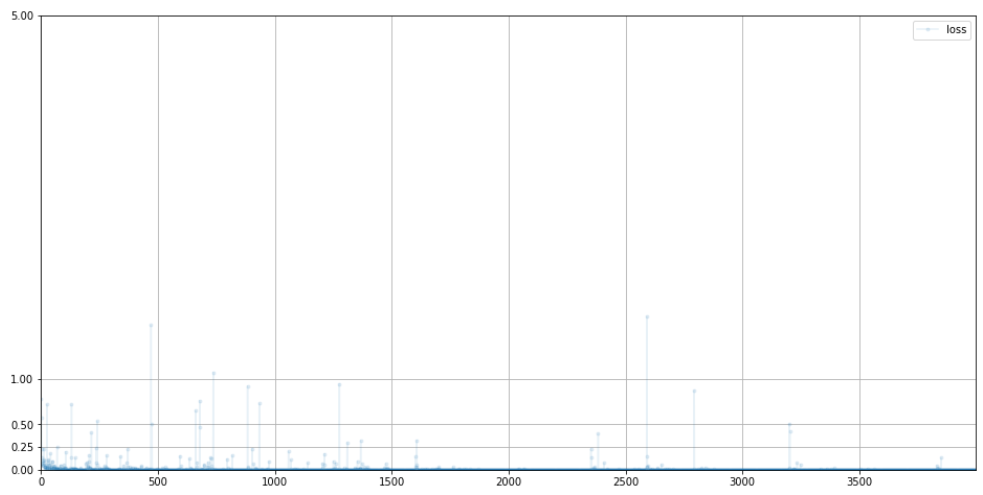
0을 향해 빠르게 수렴한다. 전에 비하면 변동이 작고 노이즈가 적게 발생했다.
Generator
self.model = nn.Sequential(
# input is a 1d array
nn.Linear(100, 3*11*11),
nn.LeakyReLU(0.2),
# reshape to 4d
View((1, 3, 11, 11)),
nn.ConvTranspose2d(3, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 256, kernel_size=8, stride=2),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
nn.ConvTranspose2d(256, 3, kernel_size=8, stride=2, padding=1),
nn.BatchNorm2d(3),
# output should be (1,3,128,128)
nn.Sigmoid()
)
여기서 Transpose가 나온다. 왱?
큰걸 작은걸로 만들어 줬다면, 이제 작은걸 다시 큰 텐서로 바꿔 줘야징.
코드 흐름을 설명하자면,
100개의 시드 값을 3x11x11개 값으로 매핑
(1,3,11,11) 형태의 4차원 텐서로 바꿔 Transpose Layer에 맞게 변형.
마지막은 패딩1을 추가하는데, 중간 격자에서 바깥쪽 테두리를 없앴기 때문임.
이거 안하면 아구가 안맞음.
훈련 전에 이미지 구경 한 번 ㄱㄱ

Train
1epoch만 돌려보장
# create Discriminator and Generator
D = Discriminator()
G = Generator()
D.to(device)
G.to(device)
epochs = 1
for epoch in range(epochs):
print ("epoch = ", epoch + 1)
# train Discriminator and Generator
for image_data_tensor in celeba_dataset:
# train discriminator on true
D.train(image_data_tensor, torch.cuda.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(generate_random_seed(100)).detach(), torch.cuda.FloatTensor([0.0]))
# train generator
G.train(D, generate_random_seed(100), torch.cuda.FloatTensor([1.0]))
pass
passDiscriminator

0.693이 Best이긴 한데 0에 수렴한다.
Generator
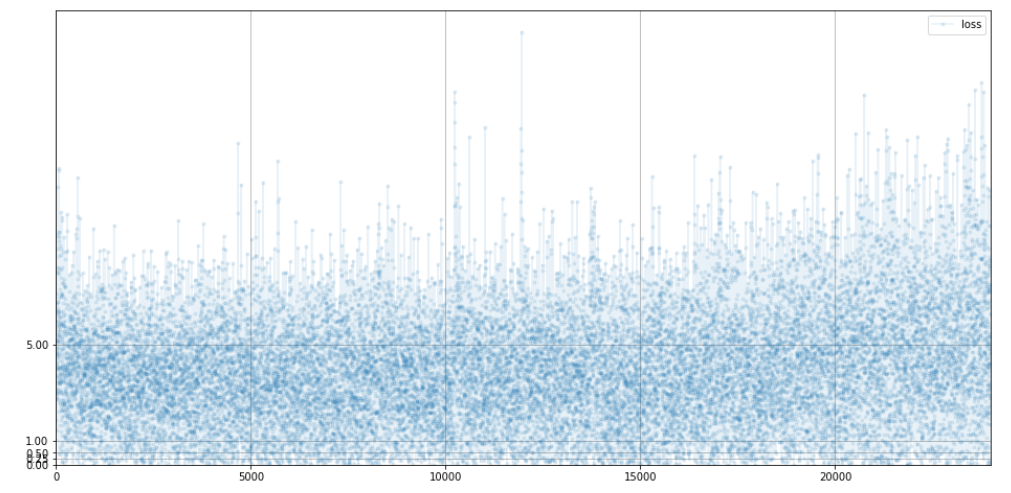
어느정도 안정되어 있는 편이다.
1에폭 돌린 이미지는 어떨까?

뷁
Activ.func을 GELU로 바꾸고 epoch 2번 돌려보장

헷
정리
- 데이터를 줄이는 합성곱의 반대 역할은 TransposeCNN이다. Generator를 만들기 좋음.
- CNN의 단점은 얼굴과 눈이 따로 노는 얼굴 요소들끼리의 조화가 깨질 수 있다. why?
- CNN특성상 지역화된 정보로 전체적인 관계를 학습하지 않게 구현 되었기 때문.
