전체적인 구조는 앞과 같다.
이번 포스트 3줄 요약을 하자면,
- MNIST로 학습을 진행하고 시행착오를 겪음
- Activ function 변경, 정규화 진행, seed 변경, Loss function 변경
- 시행착오 해결!
이다.
MNISTDATASET CLASS 정의
데이터를 로드하고, 개별 이미지와 그 레이블에 접근하며, 레이블을 원-핫 인코딩으로 변환하는 등의 작업을 수행
class MnistDataset(Dataset):
def __init__(self, csv_file):
self.data_df = pandas.read_csv(csv_file, header=None)
pass
def __len__(self):
return len(self.data_df)
def __getitem__(self, index):
# image target (label)
label = self.data_df.iloc[index,0]
target = torch.zeros((10))
target[label] = 1.0
# image data, normalised from 0-255 to 0-1
image_values = torch.FloatTensor(self.data_df.iloc[index,1:].values) / 255.0
# return label, image data tensor and target tensor
return label, image_values, target
def plot_image(self, index):
img = self.data_df.iloc[index,1:].values.reshape(28,28)
plt.title("label = " + str(self.data_df.iloc[index,0]))
plt.imshow(img, interpolation='none', cmap='Blues')
pass
pass
Discriminator Network
class Discriminator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.Sigmoid(),
nn.Linear(200, 1),
nn.Sigmoid()
)
# create loss function
self.loss_function = nn.MSELoss()
# create optimiser, simple stochastic gradient descent
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# counter and accumulator for progress
self.counter = 0;
self.progress = []
pass
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, inputs, targets):
# calculate the output of the network
outputs = self.forward(inputs)
# calculate loss
loss = self.loss_function(outputs, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
pass
pass
판별기 생성.
앞에 봤던 코드랑 다를게 없음.
input size만 변경 (784)
노드 수는 200개
Test Discriminator
%%time
# test discriminator can separate real data from random noise
D = Discriminator()
for label, image_data_tensor, target_tensor in mnist_dataset:
# real data
D.train(image_data_tensor, torch.FloatTensor([1.0]))
# fake data
D.train(generate_random(784), torch.FloatTensor([0.0]))
pass
판별기가 실제 이미지와 노이즈를 잘 구별하는지 한 번 살펴보자.
진짜라고 판단되면 1을 출력하도록 하는 코드임.
generate_random()함수를 통해 노이즈 픽셀값만들고 이건 0으로 출력하도록 설정.
차트를 확인해보자
D.plot_progress()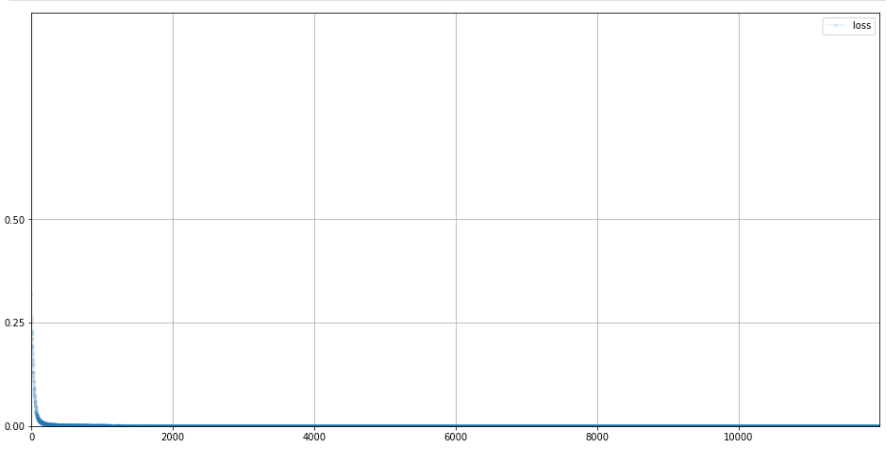
MSE를 사용했기 때문, 거의 0에서 노는걸 볼 수 있다.
이제 훈련된 판별기에 이미지를 수동으로 넣어 결과를 함 보자.
for i in range(4):
image_data_tensor = mnist_dataset[random.randint(0,60000)][1]
print( D.forward( image_data_tensor ).item() )
pass
for i in range(4):
print( D.forward( generate_random(784) ).item() )
pass0.9971165657043457
0.9960340857505798
0.9915605187416077
0.9959281086921692
0.004886912647634745
0.007289243396371603
0.005538861732929945
0.005872515961527824
진짜는 출력값이 높고, 가짜는 출력값이 낮은걸 볼 수 있다.
-> 판별기는 실제와 임의의 노이즈를 구별할 수 있다는걸 확인 할 수 있다.
Generator Network
class Generator(nn.Module):
def __init__(self):
# initialise parent pytorch class
super().__init__()
# define neural network layers
self.model = nn.Sequential(
nn.Linear(1, 200),
nn.Sigmoid(),
nn.Linear(200, 784),
nn.Sigmoid()
)
# create optimiser, simple stochastic gradient descent
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
# counter and accumulator for progress
self.counter = 0;
self.progress = []
pass
def forward(self, inputs):
# simply run model
return self.model(inputs)
def train(self, D, inputs, targets):
# calculate the output of the network
g_output = self.forward(inputs)
# pass onto Discriminator
d_output = D.forward(g_output)
# calculate error
loss = D.loss_function(d_output, targets)
# increase counter and accumulate error every 10
self.counter += 1;
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
# zero gradients, perform a backward pass, update weights
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0), figsize=(16,8), alpha=0.1, marker='.', grid=True, yticks=(0, 0.25, 0.5))
pass
pass앞에서 했던 것과 같음
신경망 레이어 크기만 조금 수정.
Test Generator Output
G = Generator()
output = G.forward(generate_random(1))
img = output.detach().numpy().reshape(28,28)
plt.imshow(img, interpolation='none', cmap='Blues')여기 보면 임의의 시드를 통해 출력 텐서를 만들어준다.
왜 도움이 됨?
어떤 원리로 되는진 모름.
하지만 도움이 됨.
생성기로 입력되는 조금 다른 숫자가 다양한 이미지를 생서하는데 도움을 줌.
예를 들어, 0~0.2 사이의 입력은 3을 만들고, 0.4~0.6 입력은 9를 만든다. 뭐 이런거
이제 저 코드 결과를 봅시다
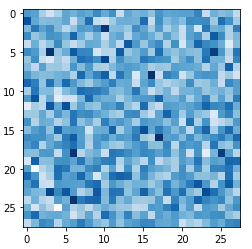
노이즈가 나왔다. 좋은 징조다. 패턴이 있으면 나쁘다. 그냥 테스트니까. 티비 보면 치지직 뜨는 그거다
Train GAN
%%time
# create Discriminator and Generator
D = Discriminator()
G = Generator()
# train Discriminator and Generator
for label, image_data_tensor, target_tensor in mnist_dataset:
# train discriminator on true
D.train(image_data_tensor, torch.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(generate_random(1)).detach(), torch.FloatTensor([0.0]))
# train generator
G.train(D, generate_random(1), torch.FloatTensor([1.0]))
pass손실값 봅시다.
# plot discriminator error
D.plot_progress()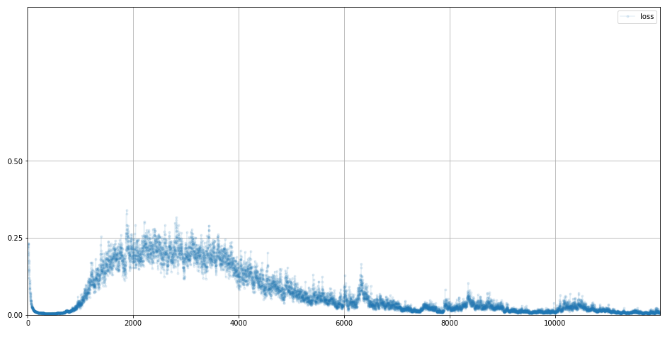
손실은 0에 가까워지고 0으로 유지한다.
이건 판별기가 생성기를 성능으로 앞선거다.
그 다음에 0.25까지 치솟는데, 이건 균형이 맞기 시작했단 의미이다.
이후엔 판별기가 또 앞서나가 0에 머물러있다.
MSE일때 0.25로 유지되는게 좋은거다.
0으로 가면 생성기가 못속이는거임.
# plot generator error
G.plot_progress()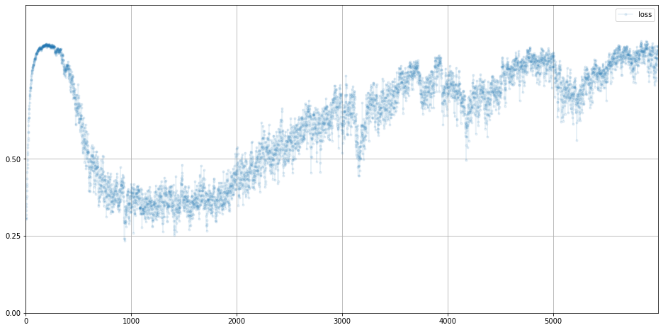
첨에 손실값이 치솟는 이유는 판별기가 잘 구별한거임.
0.25로 잠깐 내려가는데 이건 판별기와 생성기가 균형이 잘 맞는 상태
다시 손실이 또 증가하는데, 이건 판별기가 생성기보다 더 성능이 나은 상태
Run Generator
생성기가 만든걸 확인해볼까?
# plot several outputs from the trained generator
# plot a 3 column, 2 row array of generated images
f, axarr = plt.subplots(2,3, figsize=(16,8))
for i in range(2):
for j in range(3):
output = G.forward(generate_random(1))
img = output.detach().numpy().reshape(28,28)
axarr[i,j].imshow(img, interpolation='none', cmap='Blues')
pass
pass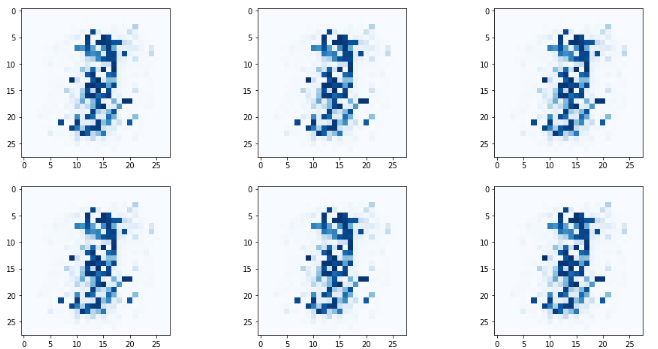
다 비슷하게 생겼다. 시행착오발생!!!!!!
Mode collapse
이게 바로 시행착오다. 자주 맞닥뜨리는 모드 붕괴 현상이다.
다양하게 생성하는게 좋은데, 같은 것만 나온다.
왜 그런진 모르는데 그럴듯한 이론은 꿀지점만 학습해서 그것만 나온다는 것이다.
해결해보자 4가지 아이디어를 통해 해결 할 수 있다.
Improved Training
- BCE로 변경
-> 이진 분류에선, 더 강하게 Loss를 줌. - Activ func LeakyReLU로 변경
-> 큰 값에 대해 기울기 소실 해결 - 정규화 진행. 평균 0으로 맞추고 분산 제한.
-> 극단적인 값 제한 - Optimizer변경
-> SGD단점을 보완한 Adam으로 변경
자 드가자!!!!
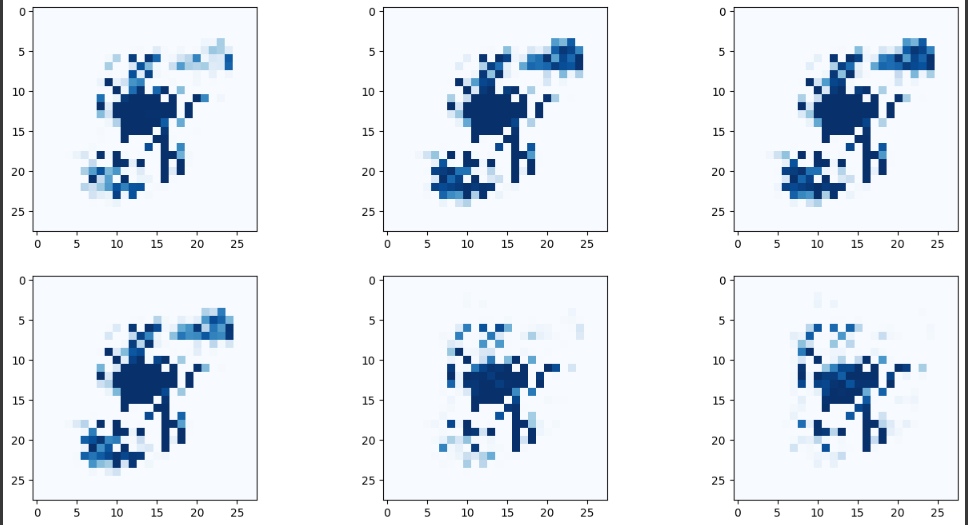
실패.
깊게 생각해 봅시다.
생성의 첫 단계는 시드이다.
고정된 값으로 입력을 주면 항상 같은 값을 결과로 내놓기 때문에 random으로 해결했다.
입력 시드에 좀 더 많은 숫자를 넣어보자.
nn.Linear(1,200) -> nn.Linear(100,200)
깨끗해지기만 할 뿐 모드 붕괴는 그대로.
곰곰이 생각해보면,
판별기엔 random 픽셀 값은 0~1범위로 줘야함. 임의의 숫자에 대해 판별기 성능을 테스트할거라 값도 고르게 선택해야하고 정규분포처럼 경향성을 지니면 안됨
생성기는 0~1사이 값이 아니어도 된다.
평균균이 0이고 분산이 제한된 정규화 값들이 유리함. 표준 정규분포에서 값을 뽑는게 유리하다.
# functions to generate random data
def generate_random_image(size):
random_data = torch.rand(size)
return random_data
def generate_random_seed(size):
random_data = torch.randn(size)
return random_data그래서 이 함수 추가.
판별기엔 generate_random_image(784)
생성기엔 generate_random_seed(100) 사용.
자 드가자!!
D = Discriminator()
G = Generator()
epochs = 4
for epoch in range(epochs):
print ("epoch = ", epoch + 1)
# train Discriminator and Generator
for label, image_data_tensor, target_tensor in mnist_dataset:
# train discriminator on true
D.train(image_data_tensor, torch.FloatTensor([1.0]))
# train discriminator on false
# use detach() so gradients in G are not calculated
D.train(G.forward(generate_random_seed(100)).detach(), torch.FloatTensor([0.0]))
# train generator
G.train(D, generate_random_seed(100), torch.FloatTensor([1.0]))
pass
pass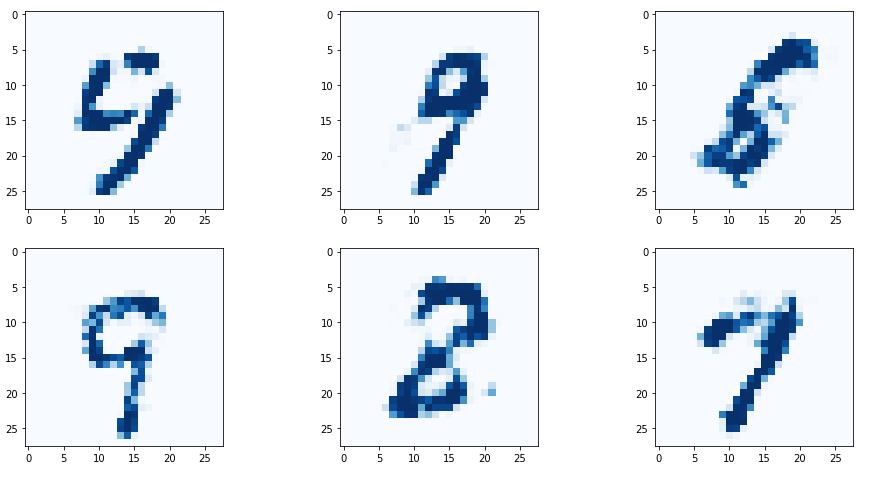
아주 Nice!
+에폭을 높이면 좀 그림이 깔끔해진다
하나의 생성기가 이젠 여러종류의 숫자를 만들 수 있다.
random 시드를 다양하게 바꾸는 것으로 가능해졌다.
모드 붕괴를 고치는 것은 굉장히 어렵고 아예 방법을 못찾을 수도 있다. ㄷ ㄷ
손실차트를 음미해보자
일단 판별기부터!
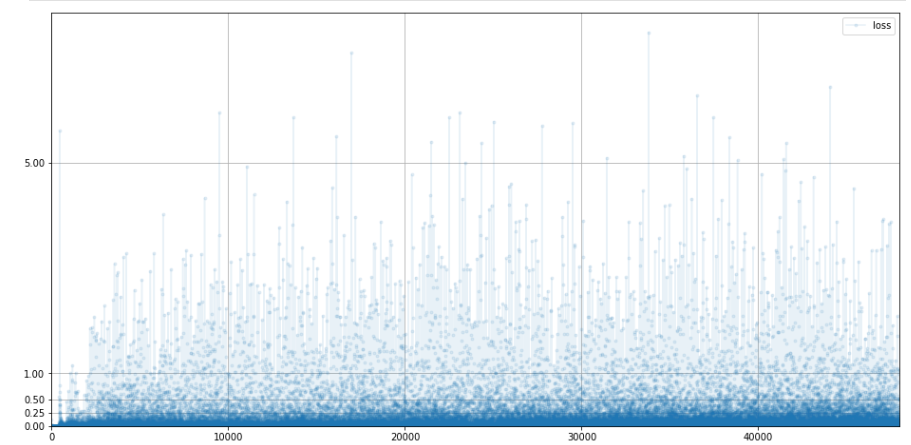
0으로 수렴하고 유지 되지만, 점프가 발생한다.
이건 판별기와 생성기 사이의 균형이 맞춰지지 않았다는 의미이다.
자 다음은 Generater
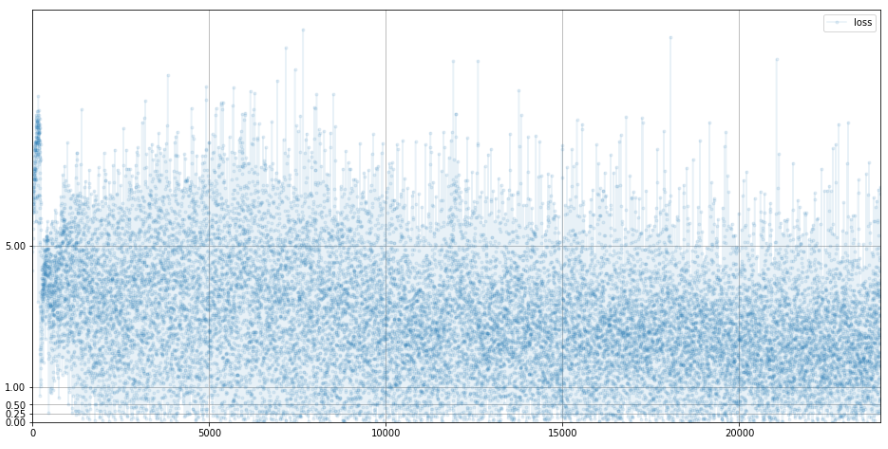
손실이 처음엔 튀어오르는걸 볼 수 있는데 이건 생성을 잘 못하는 거다.
손실이 좀 떨어지면 3 근처에 머무르다.
기존 손실차트는 깔끔하게 0으로 수렴했다. 이러한 깔끔한건 우리가 이루고자 하는 목표와는 좀 거리가 멀다.
생성기의 손실은 어느 정도 고정된 값을 중심으로 약간의 변화가 있는게 오히려 좀 더 바람직하다.
여기서 질문.
MSE에서 좋은 균형점의 값은 0.25이다. BLE에선?
0.69이다. 예상되는 손실은 ln(2)이고 이게 0.69이다.
결론
- GAN을 설계하기 위한 좋은 시작점은 같은 구조로 만들어서 한쪽이 과도하게 성능이 좋아져버리는 현상을 방지하는 것이다.
- 훈련에선 양보다 질이 중요하다.
- 두 시드 값 사이의 시드의 숫자는 중간정도 보간된 이미지가 나온다.
- 시드 끼리 더한 합에서 도출된 이미지는 두 이미지를 합친 형태이지만, 차이에서 도출된 이미지는 직관적인 패턴이 없다.
- MSE의 균형점은 0.25이며, BSE는 ln(2) = 0.69 이다.
