자료구조 정리
우선순위 큐(Priority Queue)
- 우선순위 큐는 우선순위가 가장 높은 데이터를 가장 먼저 삭제하는 자료구조다.
- 우선순위 큐는 데이터를 우선순위에 따라 처리하고 싶을 때 사용한다.
- 스택: 후입선출
- 큐: 선입선출
- 우선순위 큐: 우선순위가 높은 데이터 - 우선순위 큐를 구현하는 방법:
- 단순히 리스트를 이용하여 구현
- 힙을 이용하여 구현 - 데이터의 개수가 N개일 때, 구현방식에 따라서 시간복잡도를 비교하면
| 우선순위 큐 구현 방식 | 삽입 시간 | 삭제 시간 |
|---|---|---|
| 리스트 | O(1) | O(N) |
| 힙(heap) | O(logN) | O(logN) |
- 단순히 N개의 데이터를 힙에 넣었다가 모두 꺼내는 작업은 정렬과 동일하다. (힙 정렬)
- 이 경우 시간 복잡도는 O(NlogN) 이다.
힙
- 완전 이진 트리 자료구조의 일종
- 힙에서는 항상 루트노드를 제거한다.
- 최소힙(min heap)
- 루트노드가 가장 작은 값을 가진다.
- 따라서 값이 작은 데이터가 우선적으로 제거된다.
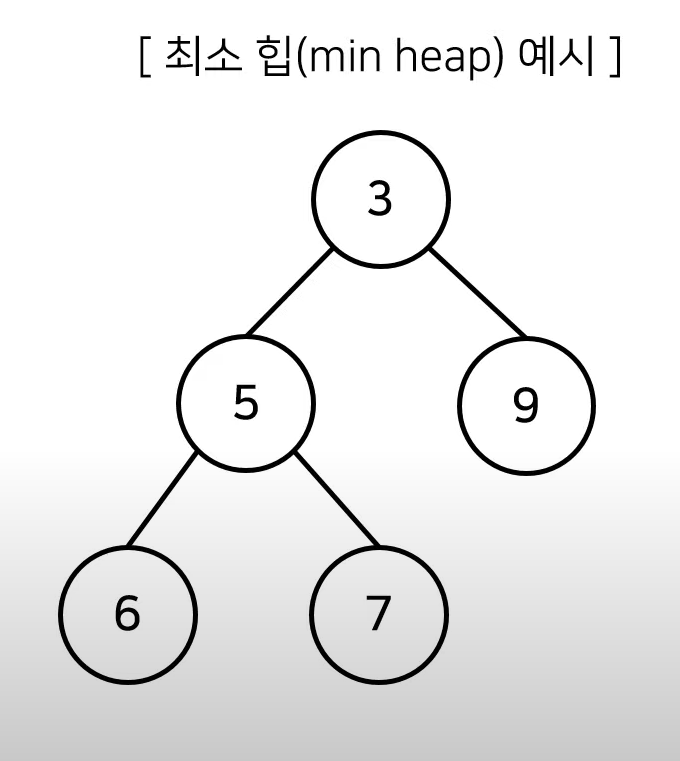
- 최대힙(max heap)
- 루트노드가 가장 큰 값을 가진다.
- 따라서 값이 큰 데이터가 우선적으로 제거된다. - 최소 힙 구성 함수 Min-Heapify()
- 부모노드로 거슬러 올라가며, 부모보다 자신의 값이 더 작은 경우에 위치를 교체한다. - 새로운 원소가 삽입되었을 때 O(logN)의 시간복잡도로 힙 성질을 유지할 수 있다.
- 원소가 제거되었을 때 O(logN)의 시간복잡도로 힙 성질을 유지하도록 할 수 있다.
- 원소를 제거할 때는 가장 마지막 노드가 루트노드의 위치에 오도록 한다.
- 이후에 루트노드에서부터 하향식으로(더 작은 자식 노드로) Heapify()를 진행한다.
import sys
import heapq # heap 라이브러리인 heapq를 가져옴
input = sys.stdin.readline
def heapsort(iterable): # iterable = 리스트 or 튜플
h = []
result = []
# 모든 원소를 차례대로 힙에 삽입
for value in iterable: # 매개변수인 iterable(리스트)에서 하나씩 꺼내어
heapq.heappush(h, value) # h에 heap 자료구조(min-heap)로 담는다. O(logN)
# 힙에 삽입된 모든 원소를 차례대로 꺼내어 담기
for i in range(len(h)): # 파이썬에서는 기본 min-heap으로 저장된다
result.append(heapq.heappop(h)) # 그러므로 오름차순으로 result에 담김
return result # 오름차순으로 정렬된 list를 반환
n = int(input())
arr = []
for i in range(n):
arr.append(int(input()))
res = heapsort(arr)
for i in range(n):
print(res[i])트리
-
가계도와 같은 계층적인 구조를 표현할 때 사용할 수 있는 자료구조다.
- 루트노드(root node): 부모가 없는 최상위 노드
- 단말노드(leaf node): 자식이 없는 노드
- 크기(size): 트리에 포함된 모든 노드의 개수
- 깊이(depth): 루트 노드로부터의 거리
- 높이(height): 깊이 중 최댓값
- 차수(degree): 각 노드의 (자식방향) 간선 개수
-
기본적으로 트리의 크기가 N일 때, 전체 간선의 개수는 N-1개 입니다.
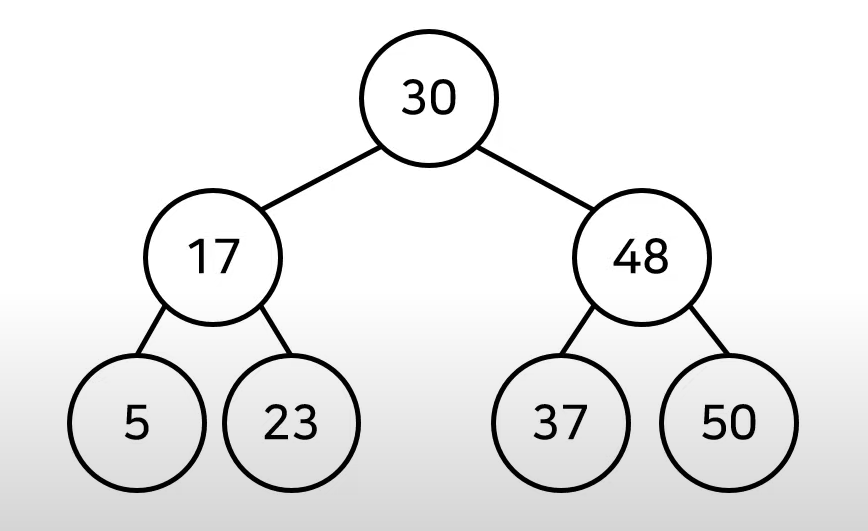
이진 탐색 트리 (Binary Search Tree)
- 이진탐색이 동작할 수 있도록 고안된, 효율적인 탐색이 가능한 자료구조
- 왼쪽 자식노드 < 부모노드 < 오른쪽 자식노드
- 부모노드보다 왼쪽 자식 노드가 작다.
- 부모노드보다 오른쪽 자식 노드가 크다.
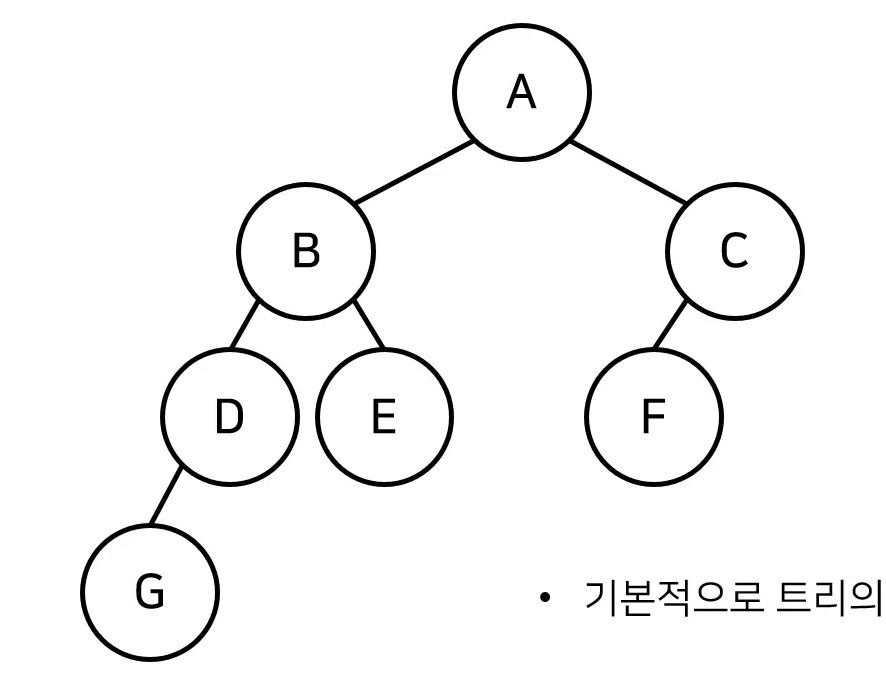
트리의 순회(Tree Traversal)
- 트리 자료구조에 포함된 노드를 특정한 방법으로 한 번씩 방문하는 방법을 의미
- 트리의 정보를 시각적으로 확인할 수 있다. - 대표적인 트리 순회 방법은 다음과 같다.
- 전위 순회(pre-order traverse): 루트 -> 왼쪽 -> 오른쪽
- 중위 순회(in-order traverse): 왼쪽 -> 루트 -> 오른쪽
- 후위 순회(post-order traverse): 왼쪽 -> 오른쪽 -> 루트
class Node:
def __init__(self, data, left_node, right_node):
self.data = data
self.left_node = left_node
self.right_node = right_node
# 전위 순회
def pre_order(node):
print(node.data, end='-')
if node.left_node != None:
pre_order(tree[node.left_node])
if node.right_node != None:
pre_order(tree[node.right_node])
# 중위 순회
def in_order(node):
if node.left_node != None:
in_order(tree[node.left_node])
print(node.data, end='-')
if node.right_node != None:
in_order(tree[node.right_node])
# 후위 순회
def post_order(node):
if node.left_node != None:
post_order(tree[node.left_node])
if node.right_node != None:
post_order(tree[node.right_node])
print(node.data, end='-')
n = int(input()) # 노드의 개수
tree = {} # 딕셔너리로 트리 구현
for i in range(n):
data, left_node, right_node = input().split()
if left_node == "None":
left_node = None
if right_node == "None":
right_node = None
tree[data] = Node(data, left_node, right_node)
pre_order(tree['A'])
print()
in_order(tree['A'])
print()
post_order(tree['A'])
# 7
# A B C
# B D E
# C F G
# D None None
# E None None
# F None None
# G None None
# A-B-D-E-C-F-G-
# D-B-E-A-F-C-G-
# D-E-B-F-G-C-A-
성실하고 꼼꼼하게