데이터 수집하기
API
두 프로그램이 서로 대화하기 위한 방법을 정의한 것
웹 페이지를 전송하기 위한 통신 규약: HTTP
웹 사이트는 웹 페이지를 서비스 하기 위해 웹 서버를 사용 웹서버의 종류는 Apache, Nginx 등이 존재하는데 이런 웹 서버들은 웹 브라우저와 통신할때 HTTP란 프로토콜을 사용
웹 기반 API
HTTP 프로토콜을 사용해 API를 만든 것이 웹 기반 API를 의미하며 일반적으로 CSV, JSON, XML 파일을 사용하는데 주고받는 데이터가 복잡한 구조를 가지면 버그를 유발하기 때문임

JSON
파이썬의 Dictionary 와 List를 중첩해 놓은것과 비슷함며 키와 값을 가지며 아래와 같은 형태의 구조를 가짐
{
name: "송기영",
key: "value",
}파이썬 객체 → JSON 문자열
웹 기반 API로 데이터를 전달하기 위해서는 텍스트의 형태로 전달
import json
# ensure_ascii는 json에 한글이 들어있을때 False로 처리
d_str = json.dumps(d, ensure_ascii=False)
# 출력
{"name":"송기영","key":"value"}JSON 문자열 → 파이썬 객체
JSON 문자열을 파이썬에서 사용하려면 다시 파이썬 딕셔너리로 변환
d2 = json.load(d_str)
print(type(d2))
# 출력
<class 'dict'>세겹 따옴표를 사용하면 다음과 같이 줄바꿈을 하여 입력가능
d4_str = """
[
{"name": "이 코드는 정말 긴 테스트 코드 입니다. 짧아 보이지만 긴 코드에요1"},
{"name": "이 코드는 정말 긴 테스트 코드 입니다. 짧아 보이지만 긴 코드에요2"},
]
"""JSON 문자열 → 데이터 프레임
판다스는 JSON 문자열을 데이터 프레임으로 변환하는 함수를 제공함
import pandas as pd
pd.read_json(d4_str)
# 출력은 아래와 같음
파이썬 객체 → 데이터 프레임
d4 = json.loads(d4_str)
pd.DataFrame(d4)
# 출력은 아래와 같음
XML
HTML은 구조적이지 못하기 때문에 프로그램 간 약속대로 전송하는 API에서는 적절하지 않음,
XML은 컴퓨터와 사람이 모두 읽고 쓰기 편한 문서 포맷을 위해 고안됨
<book>
<name>혼자 공부하는 데이터 분석</name>
<reader>송기영</reader>
<year>2023</year>
</book>XML 문자열 → 파이썬 객체
import xml.etree.ElementTree as et
x_str = """
<book>
<name>혼자 공부하는 데이터 분석</name>
<reader>송기영</reader>
<year>2023</year>
</book>
"""
book = et.formstring(x_str)
print(type(book))
print(book.tag)
# 출력
<class 'xml.etree.ElementTree.Element'>
book자식 엘리먼트 확인
- list xml은 자식 엘리먼트 순서가 항상 일정하다는 것을 보장 하지 않기 때문에 아래와 같은 방식으로 자식 엘리먼트를 찾는 방법은 위험
book_childs = list(book) print(book_childs) name, reader, year = book_childs print(name) print(reader) print(year) # 출력 [<Element 'name' at 0x7f85a14ce950>, <Element 'reader' at 0x7f85a14ceae0>, <Element 'year' at 0x7f85a14cea90>] 혼자 공부하는 데이터 분석 송기영 2023
- findtext() 자식 엘리먼트를 탐색하여 자동으로 텍스트를 반환
name = book.findtext('name') reader = book.findtext('reader') year = book.findtext('year')
XML 문자열 → 데이터 프레임
import pandas as pd
pd.read_xml(x2_str)API호출 URL 사용하기
http://data4library.kr/api/loanItemSrch?authKey=[발급받은키]&startDt=2022-01-01&endDt=2022-03-31&
gender=1&age=20®ion=11;31&addCode=0&kdc=6&pageNo=1&pageSize=10-
파라미터
- format: 문서 형식의 포멧으로 기본값은 xml이며 json을 입력 가능
- startDt: 검색 시작 일자
- endDt : 검색 종료 일자
- age: 연령대
- authKey : 인증키💡HTTP GET 방식
웹 브라우저가 웹 서버에 요청을 할때 URL로 데이터를 전달 하는 방법으로 무한정으로 길게는 사용하지 못하며 보통 2,000자 이내면 안전한 길이로 이보다 긴 길이는 POST방식으로 전달을 함

파이썬에서 API 호출하기
import requests
url = "http://data4library.kr/api/loanItemSrch?format=json&startDt=2021-04-01&endDt=2021-04-30&age=20&authKey=c01ec15e4574f74ee45cba2601bad15b82971e606e3b0740977ee4b363ce2fe2"
dr = requests.get(url)
# JSON 문자열을 파이썬 객체로 반환
data = r.json()
print(data)호출한 API 데이터 → 데이터프레임
import pandas as pd
books = []
for d in data['response']['docs']:
books.append(d['doc'])
# 리스트 내포 사용
books = [d['doc'] for d in data['response']['docs']]
books_df = pd.DataFrame(books)
# 출력
books_df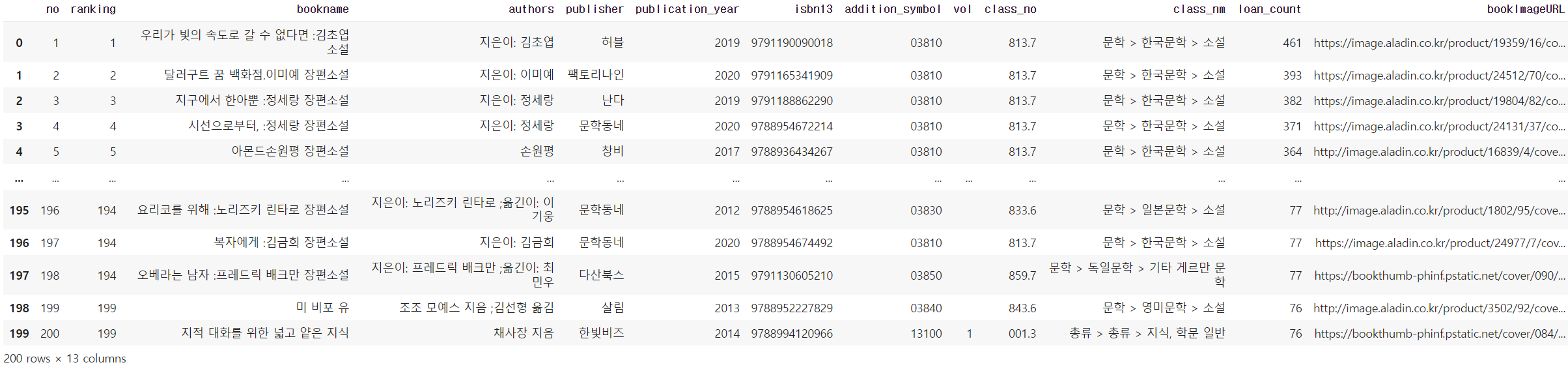
데이터프레임 → JSON 파일
# 한글처리를 위한 force_ascii False
books_df.to_json('20s_best_book.json', force_ascii=False)핵심 함수
| 메서드 | 기능 |
|---|---|
| json.dumps() | 파이썬 객체를 JSON 문자열로 변환 |
| json.loads() | JSON 문자열을 파이썬 객체로 변환 |
| pandas.read_json() | JSON 문자열을 판다스 시리즈/데이터프레임 변환 |
| xml.etree.ElementTree.fromstring() | XML 문자열을 분석 xml.etree.ElementTree 클래스 객체를 반환 |
| xml.etree.ElementTree.Element.findtext() | 지정한 태그 이름과 맞는 첫 번째 자식 엘리먼트의 텍스트를 반환 |
| xml.etree.ElementTree.Element.findall() | 지정한 태그 이름과 맞는 모든 자식 엘리먼트를 반환 |
| requests.get() | HTTP GET 방식으로 URL을 호출하고 requests.Response 객체 반환 |
| requests.Response.json() | 응답받은 JSON 문자열을 파이썬 객체로 변환하여 반환 |
웹 스크래핑
웹 페이지의 HTML을 읽어 원하는 정보를 직접 뽑아내는 방법으로
웹사이트의 페이지를 옮겨 가면서 데이터를 추출하는 작업을 웹스크래핑 혹은 웹 크롤링이라고 함
검색 결과 가져오기
20대가 가장 좋아하는 도서 목록을 사용
import gdown
gdown.download('https://bit.ly/3q9SZix', '20s_best_book.json', quiet=False)
# JSON 데이터 -> 데이터 프레임
import pandas as pd
books_df = pd.read_json('20s_best_book.json')
# 여러개의 열중에 no열 부터 isbn13까지 추출하여 새로운 데이터 프레임 생성
books = books_df.loc[:, 'no':'isbn13']
검색 결과 HTML 페이지 가져오기
import requests
isbn = 9791190090018
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
r = requests.get(url.format(isbn))HTML에서 데이터 추출하기: 뷰티플수프/스크래피(Scrapy)
from bs4 import BeautifulSoup
# lxml 패키지 대신 파이썬 내장 파서를 사용하기 위해 html.parser
soup = BeautifulSoup(r.text, 'html.parser')태그 위치 찾기 : find() 메서드
지정된 이름을 가진 첫번째 태그를 찾는 함수
# HTML의 a태그중 class이름이 gd_name인 것 찾기
prd_link = soup.find('a', attrs={'class':'gd_name'})
# 출력
prd_link
<a class="gd_name" href="/Product/Goods/74261416" onclick="setSCode('101_005_003_001');setGoodsClickExtraCodeHub('032', '9791190090018', '74261416', '0');">우리가 빛의 속도로 갈 수 없다면</a>
# href 속성값 추출
prd_link['href']도서 상세 페이지 HTML 가져오기
url = 'http://www.yes24.com'+prd_link['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# div 태그중 id가 infoset_spcific 찾기
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})테이블 태그를 리스트로 가져오기 : find_all() 메서드
특정 HTML을 모두 찾아서 리스트로 반환하는 함수
prd_tr_list = prd_detail.find_all('tr')태그 안의 텍스트 가져오기 : get_text() 메서드
for tr in prd_tr_list:
if tr.find('th').get_text() === '쪽수, 무게, 크기':
page_td = tr.find('td').get_text()
break💡 온라인 사이트는 웹 페이지마다 모두 다르게 구성하기 때문에 동일한 HTML 태그를 추출하는 방법을 찾으려면 여러 페이지에서 테스트하고 시행착오를 거쳐야함
전체 도서의 쪽수 구하는 과정
- 온라인 서점의 검색 결과 페이지 URL 구성
- requests.get() 함수로 검색 결과 페이지의 HTML을 가져옴
- 뷰티플수프로 HTML 파싱
- 뷰티플수프 find() 메서드를 통해 상세 페이지 URL 추출
- requests.get() 함수로 도서 상세 페이지의 HTML을 가져옴
- 뷰티플수프로 HTML 파싱
- 뷰티플수프 find() 메서드를 통해 ‘품목정보’ 태그 추출
- 뷰티플수프의 find_all() 메서드로 ‘쪽수’ 태그 추출
- 8에서 추출된 태그를 get_text() 메서드로 태그에 들어있는 ‘쪽수’ 추출
# 쪽수 구하는 함수
def get_page_cnt(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
# 검색 결과에서 해당 도서를 선택합니다.
prd_info = soup.find('a', attrs={'class':'gd_name'})
# 도서 상세 페이지를 가져옵니다.
url = 'http://www.yes24.com'+prd_info['href']
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
# 상품 상세정보 div를 선택합니다.
prd_detail = soup.find('div', attrs={'id':'infoset_specific'})
# 테이블에 있는 tr 태그를 가져옵니다.
prd_tr_list = prd_detail.find_all('tr')
# 쪽수가 들어 있는 th를 찾아 td에 담긴 값을 반환합니다.
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
return ''데이터프레임 행 혹은 열에 함수 적용하기 : apply() 메서드
books_df 데이터 프레임에는 모두 200개의 도서중 10개만 가져와서 쪽수를 구함
apply는 각 행의 반복 작업을 수행하기 위한것으로 첫번째 매개변수는 실행할 함수
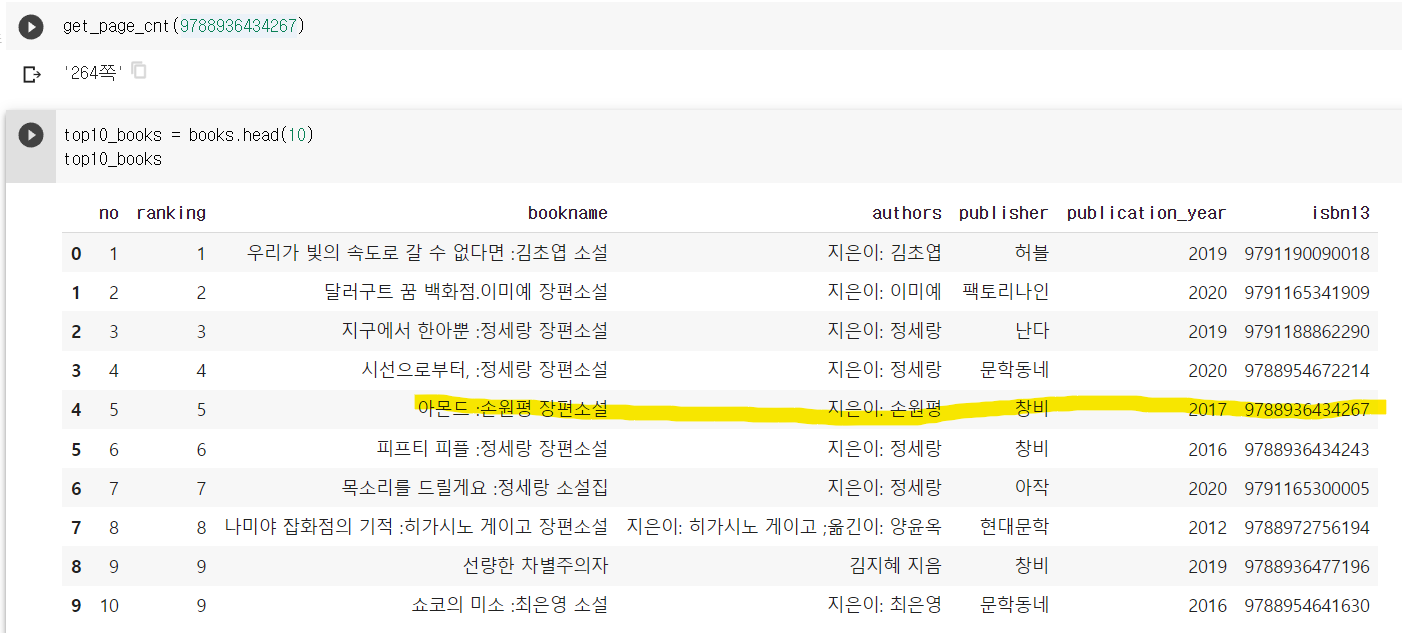
top10_books = books.head(10)
# isbn을 전달하여 쪽수를 구하는 함수
def get_page_cnt2(row):
isbn = row['isbn13']
return get_page_cnt(isbn)
# axis가 1이면 행에 적용 0이면 열에 적용
page_count = top10_books.apply(get_page_cnt2, axis=1)
# 혹은 람다함수 이용
page_count = top10_books.apply(lambda row: get_page_cnt(row['isbn13']), axis=1)데이터 프레임과 시리즈 합치기 : merge() 메서드
추출된 page_count 시리즈 객체를 top10_books를 데이터프레임의 열로 합침
# 시리즈 객체에 이름을 지정, 이름이 없으면 에러
page_count.name = 'page_count'
# 두객체의 인덱스를 기준으로 합칠 경우 left_index와 right_index 매개변수를 True로 지정
top10_with_page_count = pd.merge(top10_books, page_count, left_index=True, right_index=True)- 테스트 프레임
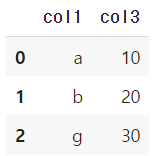
df1 = pd.DataFrame({'col1':['a','b','c'], 'col2':[1,2,3]})
df2 = pd.DataFrame({'col1':['a', 'b', 'g'], 'col': [10,20,30]})df1

df2
- on 매개변수 기준이 되는 열을 지정해야 하며 이 열은 두개의 데이터 프레임에 모두 존재해야하며 기준이되는 열의 데이터가 같은 부분만 출력됨
pd.merge(df1, df2, on='col1')
-
how 매개변수
합쳐질 방식을 지정, 기본값 inner 두 데이터프레임의 값이 같은 행만 합쳐지고 값이 없는 부분은 NaN 표시
pd.merge(df1, df2, how='left', on='col1')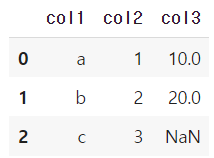
- how가 right면 df2에 df1을 합침
pd.merge(df1, df2, how='right', on='col1')
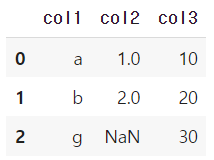
- how가 outer이면 모든 행을 유지하면서 합침
pd.merge(df1, df2, how='outer', on='col1')
-
left_on과 right_on 매개변수
합칠 기준이 되는 열의 이름이 서로 다를경우 left_on과 right_on 매개변수가 각기 지정가능
pd.merge(df1, df2, left_on='df1의 합칠열', right_on='df2의 합칠열') 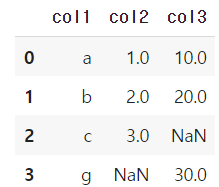
- left_index와 right_index 매개변수
합칠 기준이 열이 아니라 인덱스 일 경우pd.merge(df1, df2, left_on='df1의 기준 열', right_index='df2의 인덱스')
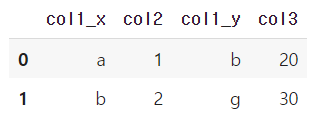
웹 스크래핑 주의사항
-
웹사이트에서 스크래핑을 허락하였는지 확인
yes24.com/robots.txt의 내용을 확인해 Disallow의 경로를 확인
-
HTML 태그를 특정할 수 있는지 확인
SSR 렌더링과 같이 서버에서 데이터를 가져오는 경우에는 셀레니움과 같은 고급 도구를 사용해야함
핵심 함수
| 메서드 | 기능 |
|---|---|
| loc | 레이블(이름) 또는 불리언 배열로 데이터프레임의 행과 열을 선택, 정수로 지정하면 인덱스의 레이블로 간주, 불리언 배열로 지정할 경우 배열의 길이행 또는 열의 전체 길이와 같아야함 |
| BeautifulSoup.find() | 현재 태그 아래의 자식 태그중 지정된 이름에 맞는 첫 번째 태그를 찾음 없을 경우 None 반환 |
| BeautifulSoup.find_all() | 현재 태그 아래의 자식 태그중 지정된 이름에 맞는 모든 태그를 반환 없을 경우 빈 리스트 반환 |
| BeautifulSoup.get_text() | 태그 안의 텍스트를 반환 |
| DataFrame.apply() | 데이터프레임의 행 또는 열에 지정한 함수를 적용 |
| pandas.merge() | 데이터프레임이나 시리즈 객체를 합침 |
미션
- 필수미션

- 선택미션